



More on Entrepreneurship/Creators

Tim Denning
3 years ago
One of the biggest publishers in the world offered me a book deal, but I don't feel deserving of it.

My ego is so huge it won't fit through the door.
I don't know how I feel about it. I should be excited. Many of you have this exact dream to publish a book with a well-known book publisher and get a juicy advance.
Let me dissect how I'm thinking about it to help you.
How it happened
An email comes in. A generic "can we put a backlink on your website and get a freebie" email.
Almost deleted it.
Then I noticed the logo. It seemed shady. I found the URL. Check. I searched the employee's LinkedIn. Legit. I avoided middlemen. Check.
Mixed feelings. LinkedIn hasn't valued my writing for years. I'm just a guy in an unironed t-shirt whose content they sell advertising against.
They get big dollars. I get $0 and a few likes, plus some email subscribers.
Still, I felt adrenaline for hours.
I texted a few friends to see how they felt. I wrapped them.
Messages like "No shocker. You're entertaining online." I didn't like praises, so I blushed.
The thrill faded after hours. Who knows?
Most authors desire this chance.
"You entitled piece of crap, Denning!"
You may think so. Okay. My job is to stand on the internet and get bananas thrown at me.
I approached writing backwards. More important than a book deal was a social media audience converted to an email list.
Romantic authors think backward. They hope a fantastic book will land them a deal and an audience.
Rarely occurs. So I never pursued it. It's like permission-seeking or the lottery.
Not being a professional writer, I've never written a good book. I post online for fun and to express my opinions.
Writing is therapeutic. I overcome mental illness and rebuilt my life this way. Without blogging, I'd be dead.
I've always dreamed of staying alive and doing something I love, not getting a book contract. Writing is my passion. I'm a winner without a book deal.
Why I was given a book deal
You may assume I received a book contract because of my views or follows. Nope.
They gave me a deal because they like my writing style. I've heard this for eight years.
Several authors agree. One asked me to improve their writer's voice.
Takeaway: highlight your writer's voice.
What if they discover I'm writing incompetently?
An edited book is published. It's edited.
I need to master writing mechanics, thus this concerns me. I need help with commas and sentence construction.
I must learn verb, noun, and adjective. Seriously.
Writing a book may reveal my imposter status to a famous publisher. Imagine the email
"It happened again. He doesn't even know how to spell. He thinks 'less' is the correct word, not 'fewer.' Are you sure we should publish his book?"
Fears stink.

I'm capable of blogging. Even listicles. So what?
Writing for a major publisher feels advanced.
I only blog. I'm good at listicles. Digital media executives have criticized me for this.
It is allegedly clickbait.
Or it is following trends.
Alternately, growth hacking.
Never. I learned copywriting to improve my writing.
Apple, Amazon, and Tesla utilize copywriting to woo customers. Whoever thinks otherwise is the wisest person in the room.
Old-schoolers loathe copywriters.
Their novels sell nothing.
They assume their elitist version of writing is better and that the TikTok generation will invest time in random writing with no subheadings and massive walls of text they can't read on their phones.
I'm terrified of book proposals.
My friend's book proposal suggestion was contradictory and made no sense.
They told him to compose another genre. This book got three Amazon reviews. Is that a good model?
The process disappointed him. I've heard other book proposal horror stories. Tim Ferriss' book "The 4-Hour Workweek" was criticized.
Because he has thick skin, his book came out. He wouldn't be known without that.
I hate book proposals.
An ongoing commitment
Writing a book is time-consuming.
I appreciate time most. I want to focus on my daughter for the next few years. I can't recreate her childhood because of a book.
No idea how parents balance kids' goals.
My silly face in a bookstore. Really?
Genuine thought.
I don't want my face in bookstores. I fear fame. I prefer anonymity.
I want to purchase a property in a bad Australian area, then piss off and play drums. Is bookselling worth it?
Are there even bookstores anymore?
(Except for Ryan Holiday's legendary Painted Porch Bookshop in Texas.)
What's most important about books
Many were duped.
Tweets and TikTok hopscotch vids are their future. Short-form content creates devoted audiences that buy newsletter subscriptions.
Books=depth.
Depth wins (if you can get people to buy your book). Creating a book will strengthen my reader relationships.
It's cheaper than my classes, so more people can benefit from my life lessons.
A deeper justification for writing a book
Mind wandered.
If I write this book, my daughter will follow it. "Look what you can do, love, when you ignore critics."
That's my favorite.
I'll be her best leader and teacher. If her dad can accomplish this, she can too.
My kid can read my book when I'm gone to remember her loving father.
Last paragraph made me cry.
The positive
This book thing might make me sound like Karen.
The upside is... Building in public, like I have with online writing, attracts the right people.
Proof-of-work over proposals, beautiful words, or huge aspirations. If you want a book deal, try writing online instead of the old manner.
Next steps
No idea.
I'm a rural Aussie. Writing a book in the big city is intimidating. Will I do it? Lots to think about. Right now, some level of reflection and gratitude feels most appropriate.
Sometimes when you don't feel worthy, it gives you the greatest lessons. That's how I feel about getting offered this book deal.
Perhaps you can relate.

Matthew O'Riordan
3 years ago
Trends in SaaS Funding from 2016 to 2022
Christopher Janz of Point Nine Capital created the SaaS napkin in 2016. This post shows how founders have raised cash in the last 6 years. View raw data.
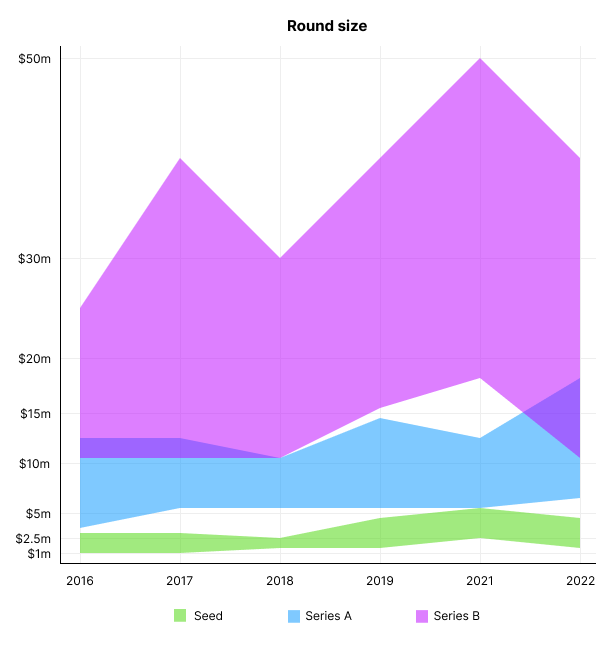
Round size
Unsurprisingly, round sizes have expanded and will taper down in 2022. In 2016, pre-seed rounds were $200k to $500k; currently, they're $1-$2m. Despite the macroeconomic scenario, Series A have expanded from $3m to $12m in 2016 to $6m and $18m in 2022.
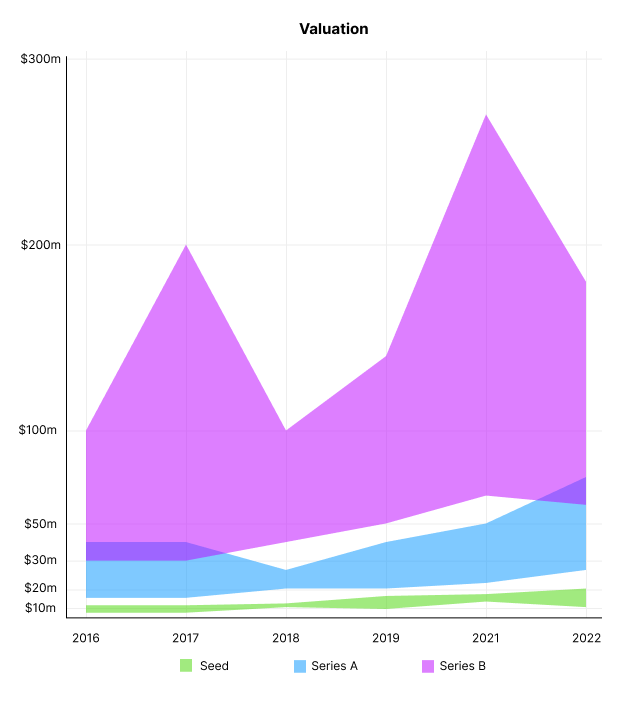
Valuation
There are hints that valuations are rebounding this year. Pre-seed valuations in 2022 are $12m from $3m in 2016, and Series B prices are $270m from $100m in 2016.
Compared to public SaaS multiples, Series B valuations more closely reflect the market, but Seed and Series A prices seem to be inflated regardless of the market.
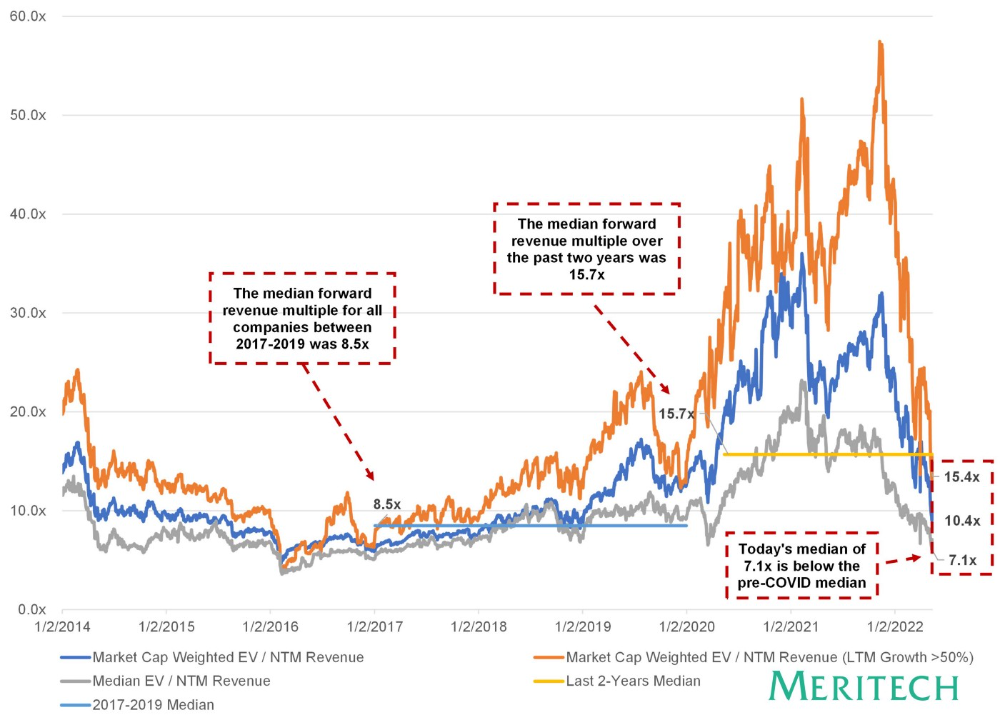
I'd like to know how each annual cohort performed for investors, based on the year they invested and the valuations. I can't access this information.
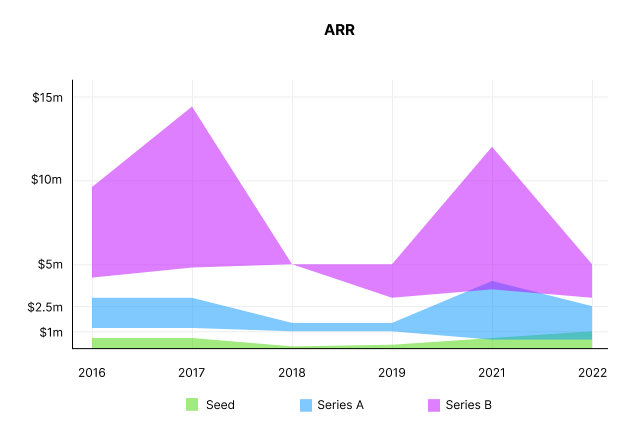
ARR
Seed firms' ARR forecasts have risen from $0 to $0.6m to $0 to $1m. 2016 expected $1.2m to $3m, 2021 $0.5m to $4m, and this year $0.5m to $2.5m, suggesting that Series A firms may raise with less ARR today. Series B minutes fell from $4.2m to $3m.
Capitalization Rate
2022 is the year that VCs start discussing capital efficiency in portfolio meetings. Given the economic shift in the markets and the stealthy VC meltdown, it's not surprising. Christopher Janz added capital efficiency to the SaaS Napkin as a new statistic for Series A (3.5x) and Series B. (2.5x). Your investors must live under a rock if they haven't asked about capital efficiency. If you're unsure:
The Capital Efficiency Ratio is the ratio of how much a company has spent growing revenue and how much they’re receiving in return. It is the broadest measure of company effectiveness in generating ARR
What next?
No one knows what's next, including me. All startup and growing enterprises around me are tightening their belts and extending their runways in anticipation of a difficult fundraising ride. If you're wanting to raise money but can wait, wait till the market is more stable and access to money is easier.

Sarah Bird
3 years ago
Memes Help This YouTube Channel Earn Over $12k Per Month
Take a look at a YouTube channel making anything up to over $12k a month from making very simple videos.
And the best part? Its replicable by anyone. Basic videos can be generated for free without design abilities.
Join me as I deconstruct the channel to estimate how much they make, how they do it, and how you can too.
What Do They Do Exactly?
Happy Land posts memes with a simple caption they wrote. So, it's new. The videos are a slideshow of meme photos with stock music.
The site posts 12 times a day.
8-10-minute videos show 10 second images. Thus, each video needs 48-60 memes.
Memes are video titles (e.g. times a boyfriend was hilarious, back to school fails, funny restaurant signs).
Some stats about the channel:
Founded on October 30, 2020
873 videos were added.
81.8k subscribers
67,244,196 views of the video
What Value Are They Adding?
Everyone can find free memes online. This channel collects similar memes into a single video so you don't have to scroll or click for more. It’s right there, you just keep watching and more will come.
By theming it, the audience is prepared for the video's content.
If you want hilarious animal memes or restaurant signs, choose the video and you'll get up to 60 memes without having to look for them. Genius!
How much money do they make?
According to www.socialblade.com, the channel earns $800-12.8k (image shown in my home currency of GBP).
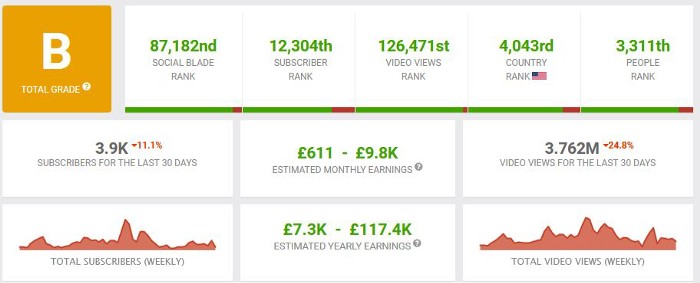
That's a crazy estimate, but it highlights the unbelievable potential of a channel that presents memes.
This channel thrives on quantity, thus putting out videos is necessary to keep the flow continuing and capture its audience's attention.
How Are the Videos Made?
Straightforward. Memes are added to a presentation without editing (so you could make this in PowerPoint or Keynote).
Each slide should include a unique image and caption. Set 10 seconds per slide.
Add music and post the video.
Finding enough memes for the material and theming is difficult, but if you enjoy memes, this is a fun job.
This case study should have shown you that you don't need expensive software or design expertise to make entertaining videos. Why not try fresh, easy-to-do ideas and see where they lead?
You might also like

Alex Mathers
3 years ago
8 guidelines to help you achieve your objectives 5x fast

If you waste time every day, even though you're ambitious, you're not alone.
Many of us could use some new time-management strategies, like these:
Focus on the following three.
You're thinking about everything at once.
You're overpowered.
It's mental. We just have what's in front of us. So savor the moment's beauty.
Prioritize 1-3 things.
To be one of the most productive people you and I know, follow these steps.
Get along with boredom.
Many of us grow bored, sweat, and turn on Netflix.
We shout, "I'm rarely bored!" Look at me! I'm happy.
Shut it, Sally.
You're not making wonderful things for the world. Boredom matters.
If you can sit with it for a second, you'll get insight. Boredom? Breathe.
Go blank.
Then watch your creativity grow.
Check your MacroVision once more.
We don't know what to do with our time, which contributes to time-wasting.
Nobody does, either. Jeff Bezos won't hand-deliver that crap to you.
Daily vision checks are required.
Also:
What are 5 things you'd love to create in the next 5 years?
You're soul-searching. It's food.
Return here regularly, and you'll adore the high you get from doing valuable work.
Improve your thinking.
What's Alex's latest nonsense?
I'm talking about overcoming our own thoughts. Worrying wastes so much time.
Too many of us are assaulted by lies, myths, and insecurity.
Stop letting your worries massage you into a worried coma like a Thai woman.
Optimizing your thoughts requires accepting what you can't control.
It means letting go of unhelpful thoughts and returning to the moment.
Keep your blood sugar level.
I gave up gluten, donuts, and sweets.
This has really boosted my energy.
Blood-sugar-spiking carbs make us irritable and tired.
These day-to-day ups and downs aren't productive. It's crucial.
Know how your diet affects insulin levels. Now I have more energy and can do more without clenching my teeth.
Reduce harmful carbs to boost energy.
Create a focused setting for yourself.
When we optimize the mind, we have more energy and use our time better because we're not tense.
Changing our environment can also help us focus. Disabling alerts is one example.
Too hot makes me procrastinate and irritable.
List five items that hinder your productivity.
You may be amazed at how much you may improve by removing distractions.
Be responsible.
Accountability is a time-saver.
Creating an emotional pull to finish things.
Writing down our goals makes us accountable.
We can engage a coach or work with an accountability partner to feel horrible if we don't show up and finish on time.
‘Hey Jake, I’m going to write 1000 words every day for 30 days — you need to make sure I do.’ ‘Sure thing, Nathan, I’ll be making sure you check in daily with me.’
Tick.
You might also blog about your ambitions to show your dedication.
Now you can't hide when you promised to appear.
Acquire a liking for bravery.
Boldness changes everything.
I sometimes feel lazy and wonder why. If my food and sleep are in order, I should assess my footing.
Most of us live backward. Doubtful. Uncertain. Feelings govern us.
Backfooting isn't living. It's lame, and you'll soon melt. Live boldly now.
Be assertive.
Get disgustingly into everything. Expand.
Even if it's hard, stop being a b*tch.
Those that make Mr. Bold Bear their spirit animal benefit. Save time to maximize your effect.

Ossiana Tepfenhart
3 years ago
Has anyone noticed what an absolute shitshow LinkedIn is?
After viewing its insanity, I had to leave this platform.

I joined LinkedIn recently. That's how I aim to increase my readership and gain recognition. LinkedIn's premise appealed to me: a Facebook-like platform for professional networking.
I don't use Facebook since it's full of propaganda. It seems like a professional, apolitical space, right?
I expected people to:
be more formal and respectful than on Facebook.
Talk about the inclusiveness of the workplace. Studies consistently demonstrate that inclusive, progressive workplaces outperform those that adhere to established practices.
Talk about business in their industry. Yep. I wanted to read articles with advice on how to write better and reach a wider audience.
Oh, sh*t. I hadn't anticipated that.

After posting and reading about inclusivity and pro-choice, I was startled by how many professionals acted unprofessionally. I've seen:
Men have approached me in the DMs in a really aggressive manner. Yikes. huge yikes Not at all professional.
I've heard pro-choice women referred to as infant killers by many people. If I were the CEO of a company and I witnessed one of my employees acting that poorly, I would immediately fire them.
Many posts are anti-LGBTQIA+, as I've noticed. a lot, like, a lot. Some are subtly stating that the world doesn't need to know, while others are openly making fun of transgender persons like myself.
Several medical professionals were posting explicitly racist comments. Even if you are as white as a sheet like me, you should be alarmed by this. Who's to guarantee a patient who is black won't unintentionally die?
I won't even get into how many men in STEM I observed pushing for the exclusion of women from their fields. I shouldn't be surprised considering the majority of those men I've encountered have a passionate dislike for women, but goddamn, dude.
Many people appear entirely too at ease displaying their bigotry on their professional profiles.

As a white female, I'm always shocked by people's open hostility. Professional environments are very important.
I don't know if this is still true (people seem too politicized to care), but if I heard many of these statements in person, I'd suppose they feel ashamed. Really.
Are you not ashamed of being so mean? Are you so weak that competing with others terrifies you? Isn't this embarrassing?
LinkedIn isn't great at censoring offensive comments. These people aren't getting warnings. So they were safe while others were unsafe.
The CEO in me would want to know if I had placed a bigot on my staff.

I always wondered if people's employers knew about their online behavior. If they know how horrible they appear, they don't care.
As a manager, I was picky about hiring. Obviously. In most industries, it costs $1,000 or more to hire a full-time employee, so be sure it pays off.
Companies that embrace diversity and tolerance (and are intolerant of intolerance) are more profitable, likely to recruit top personnel, and successful.
People avoid businesses that alienate them. That's why I don't eat at Chic-Fil-A and why folks avoid MyPillow. Being inclusive is good business.
CEOs are harmed by online bigots. Image is an issue. If you're a business owner, you can fire staff who don't help you.
On the one hand, I'm delighted it makes it simpler to identify those with whom not to do business.

Don’t get me wrong. I'm glad I know who to avoid when hiring, getting references, or searching for a job. When people are bad, it saves me time.
What's up with professionalism?
Really. I need to know. I've crossed the boundary between acceptable and unacceptable behavior, but never on a professional platform. I got in trouble for not wearing bras even though it's not part of my gender expression.
If I behaved like that at my last two office jobs, my supervisors would have fired me immediately. Some of the behavior I've seen is so outrageous, I can't believe these people have employment. Some are even leaders.
Like…how? Is hatred now normalized?
Please pay attention whether you're seeking for a job or even simply a side gig.

Do not add to the tragedy that LinkedIn comments can be, or at least don't make uninformed comments. Even if you weren't banned, the site may still bite you.
Recruiters can and do look at your activity. Your writing goes on your résumé. The wrong comment might lose you a job.
Recruiters and CEOs might reject candidates whose principles contradict with their corporate culture. Bigotry will get you banned from many companies, especially if others report you.
If you want a high-paying job, avoid being a LinkedIn asshole. People care even if you think no one does. Before speaking, ponder. Is this how you want to be perceived?
Better advice:
If your politics might turn off an employer, stop posting about them online and ask yourself why you hold such objectionable ideas.

CyberPunkMetalHead
3 years ago
195 countries want Terra Luna founder Do Kwon
Interpol has issued a red alert on Terraform Labs' CEO, South Korean prosecutors said.

After the May crash of Terra Luna revealed tax evasion issues, South Korean officials filed an arrest warrant for Do Kwon, but he is missing.
Do Kwon is now a fugitive in 195 countries after Seoul prosecutors placed him to Interpol's red list. Do Kwon hasn't commented since then. The red list allows any country's local authorities to apprehend Do Kwon.
Do Dwon and Terraform Labs were believed to have moved to Singapore days before the $40 billion wipeout, but Singapore authorities said he fled the country on September 17. Do Kwon tweeted that he wasn't on the run and cited privacy concerns.
Do Kwon was not on the red list at the time and said he wasn't "running," only to reply to his own tweet saying he hasn't jogged in a while and needed to trim calories.
Whether or not it makes sense to read too much into this, the reality is that Do Kwon is now on Interpol red list, despite the firmly asserts on twitter that he does absolutely nothing to hide.
UPDATE:
South Korean authorities are investigating alleged withdrawals of over $60 million U.S. and seeking to freeze these assets. Korean authorities believe a new wallet exchanged over 3000 BTC through OKX and Kucoin.
Do Kwon and the Luna Foundation Guard (of whom Do Kwon is a key member of) have declined all charges and dubbed this disinformation.
Singapore's Luna Foundation Guard (LFG) manages the Terra Ecosystem.
The Legal Situation
Multiple governments are searching for Do Kwon and five other Terraform Labs employees for financial markets legislation crimes.
South Korean authorities arrested a man suspected of tax fraud and Ponzi scheme.
The U.S. SEC is also examining Terraform Labs on how UST was advertised as a stablecoin. No legal precedent exists, so it's unclear what's illegal.
The future of Terraform Labs, Terra, and Terra 2 is unknown, and despite what Twitter shills say about LUNC, the company remains in limbo awaiting a decision that will determine its fate. This project isn't a wise investment.