



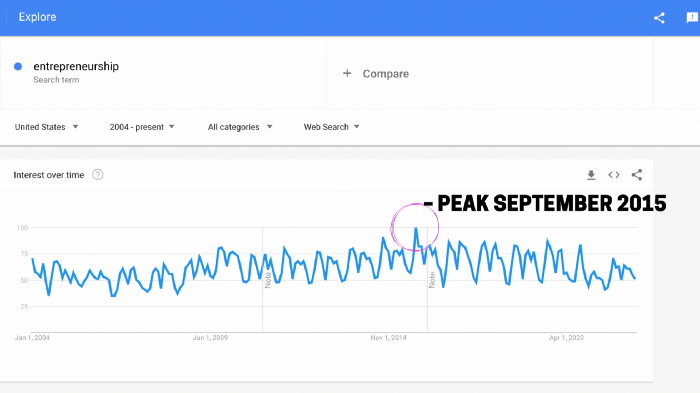
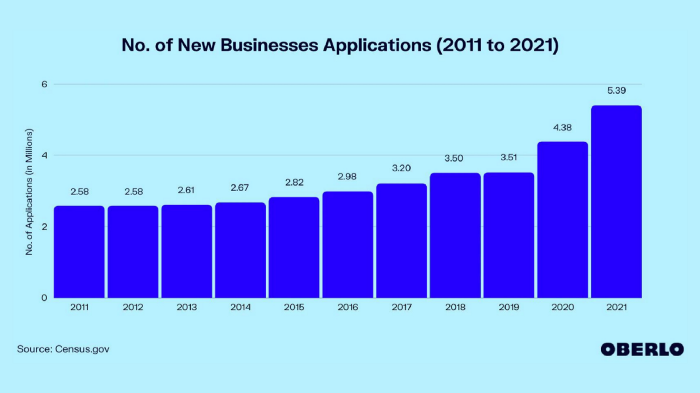

More on Entrepreneurship/Creators

Tim Denning
3 years ago
One of the biggest publishers in the world offered me a book deal, but I don't feel deserving of it.

My ego is so huge it won't fit through the door.
I don't know how I feel about it. I should be excited. Many of you have this exact dream to publish a book with a well-known book publisher and get a juicy advance.
Let me dissect how I'm thinking about it to help you.
How it happened
An email comes in. A generic "can we put a backlink on your website and get a freebie" email.
Almost deleted it.
Then I noticed the logo. It seemed shady. I found the URL. Check. I searched the employee's LinkedIn. Legit. I avoided middlemen. Check.
Mixed feelings. LinkedIn hasn't valued my writing for years. I'm just a guy in an unironed t-shirt whose content they sell advertising against.
They get big dollars. I get $0 and a few likes, plus some email subscribers.
Still, I felt adrenaline for hours.
I texted a few friends to see how they felt. I wrapped them.
Messages like "No shocker. You're entertaining online." I didn't like praises, so I blushed.
The thrill faded after hours. Who knows?
Most authors desire this chance.
"You entitled piece of crap, Denning!"
You may think so. Okay. My job is to stand on the internet and get bananas thrown at me.
I approached writing backwards. More important than a book deal was a social media audience converted to an email list.
Romantic authors think backward. They hope a fantastic book will land them a deal and an audience.
Rarely occurs. So I never pursued it. It's like permission-seeking or the lottery.
Not being a professional writer, I've never written a good book. I post online for fun and to express my opinions.
Writing is therapeutic. I overcome mental illness and rebuilt my life this way. Without blogging, I'd be dead.
I've always dreamed of staying alive and doing something I love, not getting a book contract. Writing is my passion. I'm a winner without a book deal.
Why I was given a book deal
You may assume I received a book contract because of my views or follows. Nope.
They gave me a deal because they like my writing style. I've heard this for eight years.
Several authors agree. One asked me to improve their writer's voice.
Takeaway: highlight your writer's voice.
What if they discover I'm writing incompetently?
An edited book is published. It's edited.
I need to master writing mechanics, thus this concerns me. I need help with commas and sentence construction.
I must learn verb, noun, and adjective. Seriously.
Writing a book may reveal my imposter status to a famous publisher. Imagine the email
"It happened again. He doesn't even know how to spell. He thinks 'less' is the correct word, not 'fewer.' Are you sure we should publish his book?"
Fears stink.

I'm capable of blogging. Even listicles. So what?
Writing for a major publisher feels advanced.
I only blog. I'm good at listicles. Digital media executives have criticized me for this.
It is allegedly clickbait.
Or it is following trends.
Alternately, growth hacking.
Never. I learned copywriting to improve my writing.
Apple, Amazon, and Tesla utilize copywriting to woo customers. Whoever thinks otherwise is the wisest person in the room.
Old-schoolers loathe copywriters.
Their novels sell nothing.
They assume their elitist version of writing is better and that the TikTok generation will invest time in random writing with no subheadings and massive walls of text they can't read on their phones.
I'm terrified of book proposals.
My friend's book proposal suggestion was contradictory and made no sense.
They told him to compose another genre. This book got three Amazon reviews. Is that a good model?
The process disappointed him. I've heard other book proposal horror stories. Tim Ferriss' book "The 4-Hour Workweek" was criticized.
Because he has thick skin, his book came out. He wouldn't be known without that.
I hate book proposals.
An ongoing commitment
Writing a book is time-consuming.
I appreciate time most. I want to focus on my daughter for the next few years. I can't recreate her childhood because of a book.
No idea how parents balance kids' goals.
My silly face in a bookstore. Really?
Genuine thought.
I don't want my face in bookstores. I fear fame. I prefer anonymity.
I want to purchase a property in a bad Australian area, then piss off and play drums. Is bookselling worth it?
Are there even bookstores anymore?
(Except for Ryan Holiday's legendary Painted Porch Bookshop in Texas.)
What's most important about books
Many were duped.
Tweets and TikTok hopscotch vids are their future. Short-form content creates devoted audiences that buy newsletter subscriptions.
Books=depth.
Depth wins (if you can get people to buy your book). Creating a book will strengthen my reader relationships.
It's cheaper than my classes, so more people can benefit from my life lessons.
A deeper justification for writing a book
Mind wandered.
If I write this book, my daughter will follow it. "Look what you can do, love, when you ignore critics."
That's my favorite.
I'll be her best leader and teacher. If her dad can accomplish this, she can too.
My kid can read my book when I'm gone to remember her loving father.
Last paragraph made me cry.
The positive
This book thing might make me sound like Karen.
The upside is... Building in public, like I have with online writing, attracts the right people.
Proof-of-work over proposals, beautiful words, or huge aspirations. If you want a book deal, try writing online instead of the old manner.
Next steps
No idea.
I'm a rural Aussie. Writing a book in the big city is intimidating. Will I do it? Lots to think about. Right now, some level of reflection and gratitude feels most appropriate.
Sometimes when you don't feel worthy, it gives you the greatest lessons. That's how I feel about getting offered this book deal.
Perhaps you can relate.
Tim Denning
3 years ago
Bills are paid by your 9 to 5. 6 through 12 help you build money.
40 years pass. After 14 years of retirement, you die. Am I the only one who sees the problem?

I’m the Jedi master of escaping the rat race.
Not to impress. I know this works since I've tried it. Quitting a job to make money online is worse than Kim Kardashian's internet-burning advice.
Let me help you rethink the move from a career to online income to f*ck you money.
To understand why a job is a joke, do some life math.
Without a solid why, nothing makes sense.
The retirement age is 65. Our processed food consumption could shorten our 79-year average lifespan.
You spend 40 years working.
After 14 years of retirement, you die.
Am I alone in seeing the problem?
Life is too short to work a job forever, especially since most people hate theirs. After-hours skills are vital.
Money equals unrestricted power, f*ck you.
F*ck you money is the answer.
Jack Raines said it first. He says we can do anything with the money. Jack, a young rebel straight out of college, can travel and try new foods.
F*ck you money signifies not checking your bank account before buying.
F*ck you” money is pure, unadulterated freedom with no strings attached.
Jack claims you're rich when you rarely think about money.
Avoid confusion.
This doesn't imply you can buy a Lamborghini. It indicates your costs, income, lifestyle, and bank account are balanced.
Jack established an online portfolio while working for UPS in Atlanta, Georgia. So he gained boundless power.
The portion that many erroneously believe
Yes, you need internet abilities to make money, but they're not different from 9-5 talents.
Sahil Lavingia, Gumroad's creator, explains.
A job is a way to get paid to learn.
Mistreat your boss 9-5. Drain his skills. Defuse him. Love and leave him (eventually).
Find another employment if yours is hazardous. Pick an easy job. Make sure nothing sneaks into your 6-12 time slot.
The dumb game that makes you a sheep
A 9-5 job requires many job interviews throughout life.
You email your résumé to employers and apply for jobs through advertisements. This game makes you a sheep.
You're competing globally. Work-from-home makes the competition tougher. If you're not the cheapest, employers won't hire you.
After-hours online talents (say, 6 pm-12 pm) change the game. This graphic explains it better:
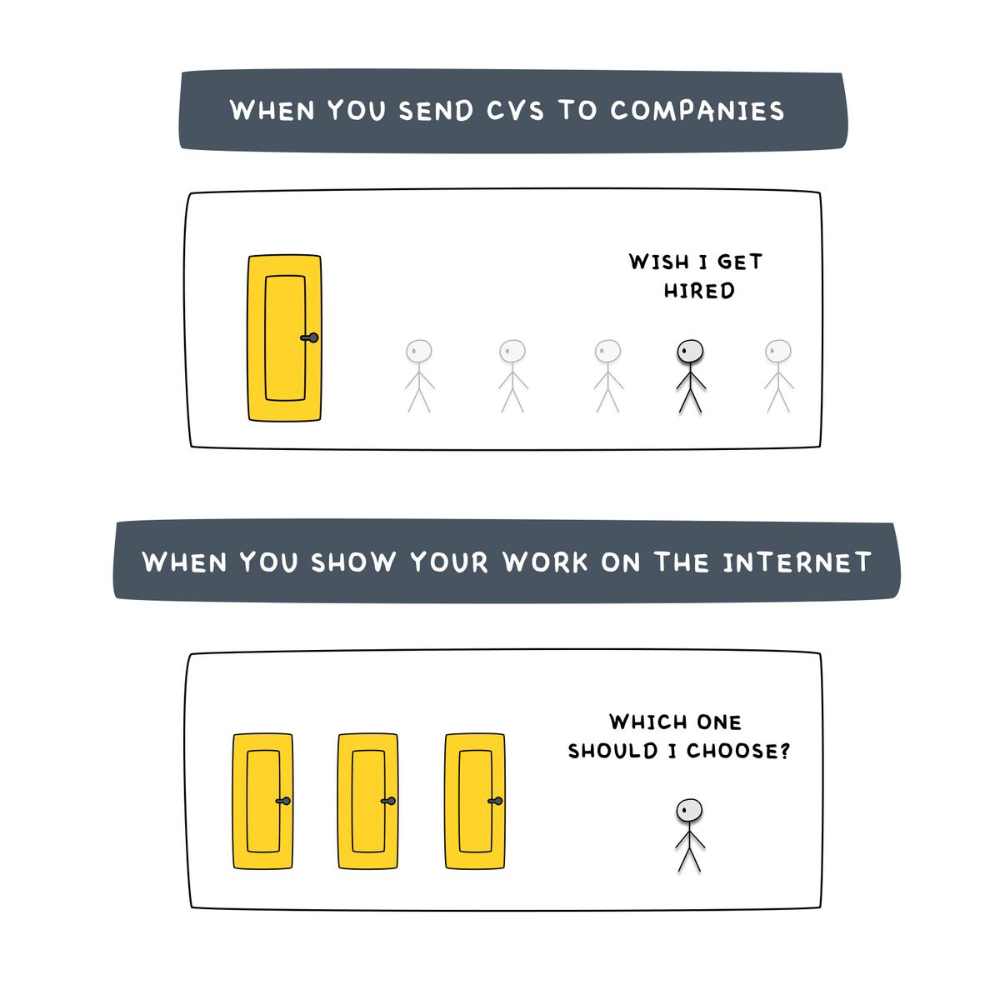
Online talents boost after-hours opportunities.
You go from wanting to be picked to picking yourself. More chances equal more money. Your f*ck you fund gets the extra cash.
A novel method of learning is essential.
College costs six figures and takes a lifetime to repay.
Informal learning is distinct. 6-12pm:
Observe the carefully controlled Twitter newsfeed.
Make use of Teachable and Gumroad's online courses.
Watch instructional YouTube videos
Look through the top Substack newsletters.
Informal learning is more effective because it's not obvious. It's fun to follow your curiosity and hobbies.

The majority of people lack one attitude. It's simple to learn.
One big impediment stands in the way of f*ck you money and time independence. So often.
Too many people plan after 6-12 hours. Dreaming. Big-thinkers. Strategically. They fill their calendar with meetings.
This is after-hours masturb*tion.
Sahil Bloom reminded me that a bias towards action will determine if this approach works for you.
The key isn't knowing what to do from 6-12 a.m. Trust yourself and develop abilities as you go. It's for building the parachute after you jump.
Sounds risky. We've eliminated the risk by finishing this process after hours while you work 9-5.
With no risk, you can have an I-don't-care attitude and still be successful.
When you choose to move forward, this occurs.
Once you try 9-5/6-12, you'll tell someone.
It's bad.
Few of us hang out with problem-solvers.
It's how much of society operates. So they make reasons so they can feel better about not giving you money.
Matthew Kobach told me chasing f*ck you money is easier with like-minded folks.
Without f*ck you money friends, loneliness will take over and you'll think you've messed up when you just need to keep going.
Steal this easy guideline
Let's act. No more fluffing and caressing.
1. Learn
If you detest your 9-5 talents or don't think they'll work online, get new ones. If you're skilled enough, continue.
Easlo recommends these skills:
Designer for Figma
Designer Canva
bubble creators
editor in Photoshop
Automation consultant for Zapier
Designer of Webflow
video editor Adobe
Ghostwriter for Twitter
Idea consultant
Artist in Blender Studio
2. Develop the ability
Every night from 6-12, apply the skill.
Practicing ghostwriting? Write someone's tweets for free. Do someone's website copy to learn copywriting. Get a website to the top of Google for a keyword to understand SEO.
Free practice is crucial. Your 9-5 pays the money, so work for free.
3. Take off stealthily like a badass
Another mistake. Sell to few. Don't be the best. Don't claim expertise.
Sell your new expertise to others behind you.
Two ways:
Using a digital good
By providing a service,
Point 1 also includes digital service examples. Digital products include eBooks, communities, courses, ad-supported podcasts, and templates. It's easy. Your 9-5 job involves one of these.
Take ideas from work.
Why? They'll steal your time for profit.
4. Iterate while feeling awful
First-time launches always fail. You'll feel terrible. Okay. Remember your 9-5?
Find improvements. Ask free and paying consumers what worked.
Multiple relaunches, each 1% better.
5. Discover more
Never stop learning. Improve your skill. Add a relevant skill. Learn copywriting if you write online.
After-hours students earn the most.
6. Continue
Repetition is key.
7. Make this one small change.
Consistently. The 6-12 momentum won't make you rich in 30 days; that's success p*rn.
Consistency helps wage slaves become f*ck you money. Most people can't switch between the two.
Putting everything together
It's easy. You're probably already doing some.
This formula explains why, how, and what to do. It's a 5th-grade-friendly blueprint. Good.
Reduce financial risk with your 9-to-5. Replace Netflix with 6-12 money-making talents.
Life is short; do whatever you want. Today.

Esteban
3 years ago
The Berkus Startup Valuation Method: What Is It?
What Is That?
Berkus is a pre-revenue valuation method based exclusively on qualitative criteria, like Scorecard.
Few firms match their financial estimates, especially in the early stages, so valuation methodologies like the Berkus method are a good way to establish a valuation when the economic measures are not reliable.
How does it work?
This technique evaluates five key success factors.
Fundamental principle
Technology
Execution
Strategic alliances in its primary market
Production, followed by sales
The Berkus technique values the business idea and four success factors. As seen in the matrix below, each of these dimensions poses a danger to the startup's success.
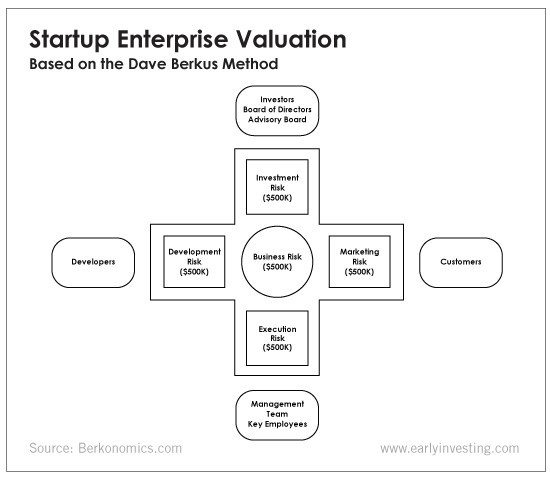
It assigns $0-$500,000 to each of these beginning regions. This approach enables a maximum $2.5M pre-money valuation.
This approach relies significantly on geography and uses the US as a baseline, as it differs in every country in Europe.
A set of standards for analyzing each dimension individually
Fundamental principle (or strength of the idea)
Ideas are worthless; execution matters. Most of us can relate to seeing a new business open in our area or a startup get funded and thinking, "I had this concept years ago!" Someone did it.
The concept remains. To assess the idea's viability, we must consider several criteria.
The concept's exclusivity It is necessary to protect a product or service's concept using patents and copyrights. Additionally, it must be capable of generating large profits.
Planned growth and growth that goes in a specific direction have a lot of potential, therefore incorporating them into a business is really advantageous.
The ability of a concept to grow A venture's ability to generate scalable revenue is a key factor in its emergence and continuation. A startup needs a scalable idea in order to compete successfully in the market.
The attraction of a business idea to a broad spectrum of people is significantly influenced by the current socio-political climate. Thus, the requirement for the assumption of conformity.
Concept Validation Ideas must go through rigorous testing with a variety of audiences in order to lower risk during the implementation phase.
Technology (Prototype)
This aspect reduces startup's technological risk. How good is the startup prototype when facing cyber threats, GDPR compliance (in Europe), tech stack replication difficulty, etc.?
Execution
Check the management team's efficacy. A potential angel investor must verify the founders' experience and track record with previous ventures. Good leadership is needed to chart a ship's course.
Strategic alliances in its primary market
Existing and new relationships will play a vital role in the development of both B2B and B2C startups. What are the startup's synergies? potential ones?
Production, followed by sales (product rollout)
Startup success depends on its manufacturing and product rollout. It depends on the overall addressable market, the startup's ability to market and sell their product, and their capacity to provide consistent, high-quality support.
Example
We're now founders of EyeCaramba, a machine vision-assisted streaming platform. My imagination always goes to poor puns when naming a startup.
Since we're first-time founders and the Berkus technique depends exclusively on qualitative methods and the evaluator's skill, we ask our angel-investor acquaintance for a pre-money appraisal of EyeCaramba.
Our friend offers us the following table:
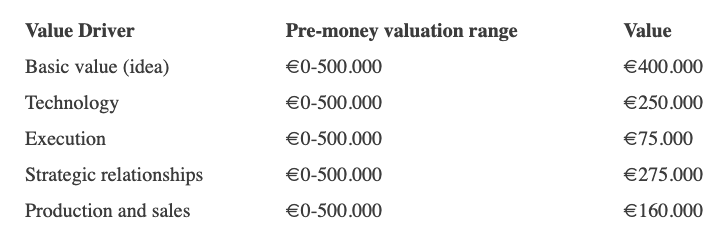
Because we're first-time founders, our pal lowered our Execution score. He knows the idea's value and that the gaming industry is red-hot, with worse startup ideas getting funded, therefore he gave the Basic value the highest value (idea).
EyeCaramba's pre-money valuation is $400,000 + $250,000 + $75,000 + $275,000 + $164,000 (1.16M). Good.
References
https://medium.com/humble-ventures/how-angel-investors-value-pre-revenue-startups-part-iii-8271405f0774#:~:text=pre%2Drevenue%20startups.-,Berkus%20Method,potential%20of%20the%20idea%20itself.%E2%80%9D
https://eqvista.com/berkus-valuation-method-for-startups/
https://www.venionaire.com/early-stage-startup-valuation-part-2-the-berkus-method/
You might also like

Darius Foroux
2 years ago
My financial life was changed by a single, straightforward mental model.
Prioritize big-ticket purchases
I've made several spending blunders. I get sick thinking about how much money I spent.
My financial mental model was poor back then.
Stoicism and mindfulness keep me from attaching to those feelings. It still hurts.
Until four or five years ago, I bought a new winter jacket every year.
Ten years ago, I spent twice as much. Now that I have a fantastic, warm winter parka, I don't even consider acquiring another one. No more spending. I'm not looking for jackets either.
Saving time and money by spending well is my thinking paradigm.
The philosophy is expressed in most languages. Cheap is expensive in the Netherlands. This applies beyond shopping.
In this essay, I will offer three examples of how this mental paradigm transformed my financial life.
Publishing books
In 2015, I presented and positioned my first book poorly.
I called the book Huge Life Success and made a funny Canva cover in 30 minutes. This:

That looks nothing like my present books. No logo or style. The book felt amateurish.
The book started bothering me a few weeks after publication. The advice was good, but it didn't appear professional. I studied the book business extensively.
I created a style for all my designs. Branding. Win Your Inner Wars was reissued a year later.
Title, cover, and description changed. Rearranging the chapters improved readability.
Seven years later, the book sells hundreds of copies a month. That taught me a lot.
Rushing to finish a project is enticing. Send it and move forward.
Avoid rushing everything. Relax. Develop your projects. Perform well. Perform the job well.
My first novel was underfunded and underworked. A bad book arrived. I then invested time and money in writing the greatest book I could.
That book still sells.
Traveling
I hate travel. Airports, flights, trains, and lines irritate me.
But, I enjoy traveling to beautiful areas.
I do it strangely. I make up travel rules. I never go to airports in summer. I hate being near airports on holidays. Unworthy.
No vacation packages for me. Those airline packages with a flight, shuttle, and hotel. I've had enough.
I try to avoid crowds and popular spots. July Paris? Nuts and bolts, please. Christmas in NYC? No, please keep me sane.
I fly business class behind. I accept upgrades upon check-in. I prefer driving. I drove from the Netherlands to southern Spain.
Thankfully, no lines. What if travel costs more? Thus? I enjoy it from the start. I start traveling then.
I rarely travel since I'm so difficult. One great excursion beats several average ones.
Personal effectiveness
New apps, tools, and strategies intrigue most productivity professionals.
No.
I researched years ago. I spent years investigating productivity in university.
I bought books, courses, applications, and tools. It was expensive and time-consuming.
Im finished. Productivity no longer costs me time or money. OK. I worked on it once and now follow my strategy.
I avoid new programs and systems. My stuff works. Why change winners?
Spending wisely saves time and money.
Spending wisely means spending once. Many people ignore productivity. It's understudied. No classes.
Some assume reading a few articles or a book is enough. Productivity is personal. You need a personal system.
Time invested is one-time. You can trust your system for life once you find it.
Concentrate on the expensive choices.
Life's short. Saving money quickly is enticing.
Spend less on groceries today. True. That won't fix your finances.
Adopt a lifestyle that makes you affluent over time. Consider major choices.
Are they causing long-term poverty? Are you richer?
Leasing cars comes to mind. The automobile costs a fortune today. The premium could accomplish a million nice things.
Focusing on important decisions makes life easier. Consider your future. You want to improve next year.

Frank Andrade
3 years ago
I discovered a bug that allowed me to use ChatGPT to successfully web scrape. Here's how it operates.
This method scrapes websites with ChatGPT (demo with Amazon and Twitter)

In a recent article, I demonstrated how to scrape websites using ChatGPT prompts like scrape website X using Python.
But that doesn’t always work.
After scraping dozens of websites with ChatGPT, I realized that simple prompts rarely work for web scraping.
Using ChatGPT and basic HTML, we can scrape any website.
First things first, use ChatGPT's advanced version (Playground)
ChatGPT Playground's enhanced version is needed to scrape websites quickly. It generates code faster and has less constraints.
Here’s how it looks.
The classic ChatGPT display just allows you to type a prompt. Playground is more customizable and generates code faster than the basic version.
No more delays or restrictions.
In this tutorial, we'll write prompts underneath Playground.
How to Use ChatGPT to Scrape Any Website
To show you how to utilize ChatGPT to scrape any website, we'll use subslikescript, which lists movies.
Later in this post, I'll show you how to scrape Amazon and Twitter, but let's start easy.
If we try a basic prompt like “scrape the movie titles on this website: https://subslikescript.com/movies” it won’t scrape anything. Here’s when we need some HTML knowledge to build the right prompt for ChatGPT.Let's scrape the above movie titles. First, check the webpage. Right-click any element and choose Inspect.
Then see below.
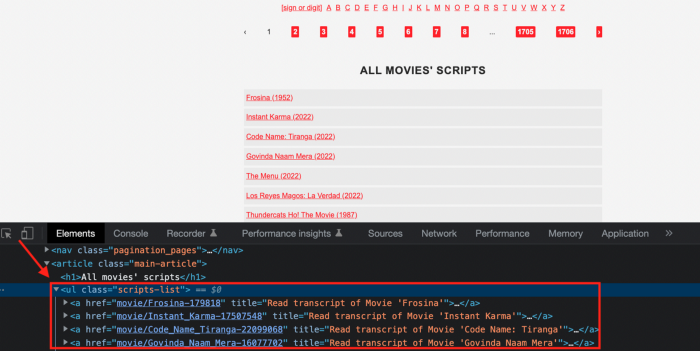
We identify the element to scrape (those in the red box). The data elements are ul, a, and scripts-list.
Here's the prompt for movie titles.
Scrape this website: https://subslikescript.com/movies with Python and Beautiful Soup. Locate the element with tag “ul” and class “scripts-list”. Scrape all the “a” elements inside. Get the text attribute and print it.
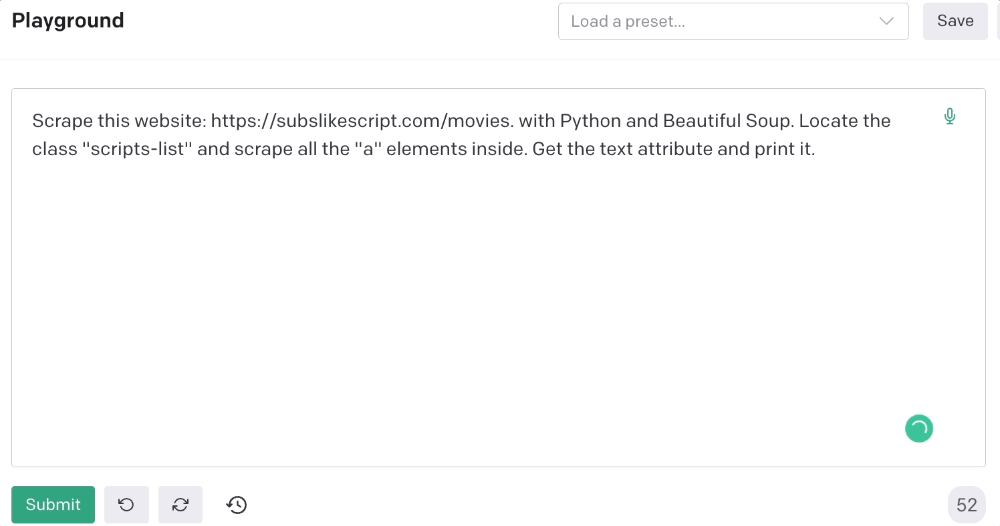
Code generated:
import requests
from bs4 import BeautifulSoup
page = requests.get('https://subslikescript.com/movies/')
soup = BeautifulSoup(page.content, 'html.parser')
scripts_list = soup.find(class_="scripts-list")
all_a_elements = scripts_list.find_all('a')
for element in all_a_elements:
print(element.get_text())It extracts movie titles successfully.
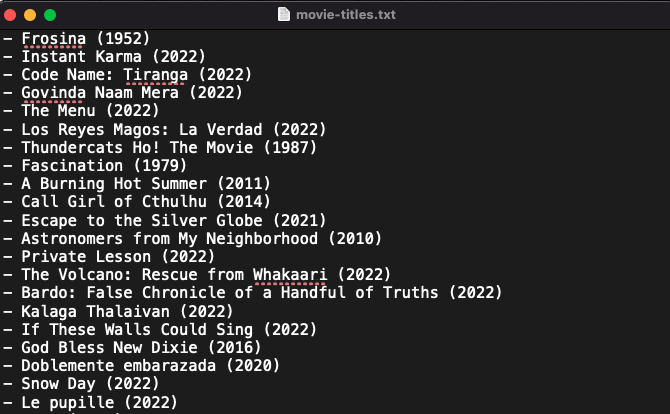
Let's scrape Amazon and Twitter.
ChatGPT's Amazon scraping
Consider scraping Amazon for self-help books. First, copy the Amazon link for self-help books.
Here’s the link I got. Location-dependent connection. Use my link to replicate my results.
Now we'll check book titles. Here's our element.
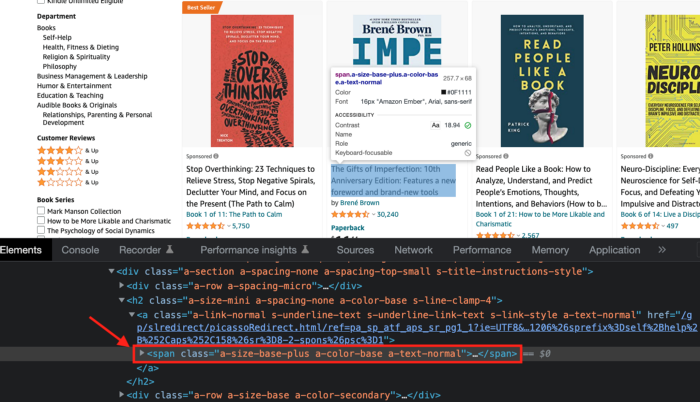
If we want to extract the book titles, we need to use the tag name span, class attribute name and a-size-base-plus a-color-base a-text-normalattribute value.
This time I'll use Selenium. I'll add Selenium-specific commands like wait 5 seconds and generate an XPath.
Scrape this website https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10 with Python and Selenium.
Wait 5 seconds and locate all the elements with the following xpath: “span” tag, “class” attribute name, and “a-size-base-plus a-color-base a-text-normal” attribute value. Get the text attribute and print them.
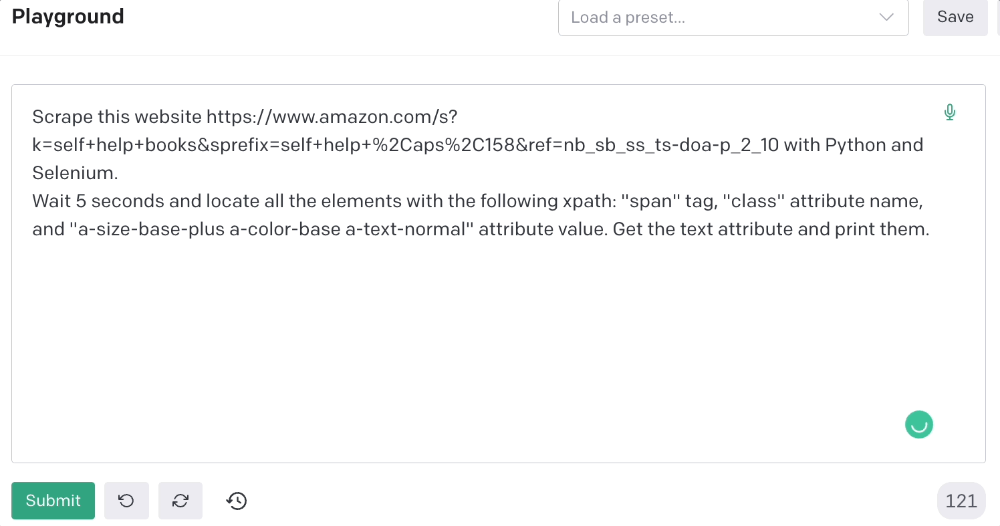
Code generated: (I only had to manually add the path where my chromedriver is located).
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
#initialize webdriver
driver = webdriver.Chrome('<add path of your chromedriver>')
#navigate to the website
driver.get("https://www.amazon.com/s?k=self+help+books&sprefix=self+help+%2Caps%2C158&ref=nb_sb_ss_ts-doa-p_2_10")
#wait 5 seconds to let the page load
sleep(5)
#locate all the elements with the following xpath
elements = driver.find_elements(By.XPATH, '//span[@class="a-size-base-plus a-color-base a-text-normal"]')
#get the text attribute of each element and print it
for element in elements:
print(element.text)
#close the webdriver
driver.close()It pulls Amazon book titles.

Utilizing ChatGPT to scrape Twitter
Say you wish to scrape ChatGPT tweets. Search Twitter for ChatGPT and copy the URL.
Here’s the link I got. We must check every tweet. Here's our element.
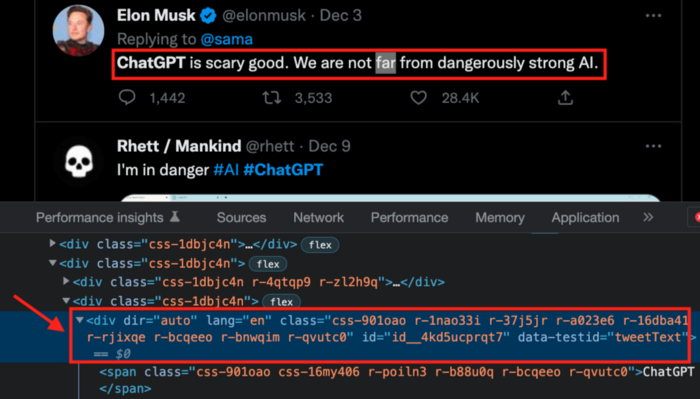
To extract a tweet, use the div tag and lang attribute.
Again, Selenium.
Scrape this website: https://twitter.com/search?q=chatgpt&src=typed_query using Python, Selenium and chromedriver.
Maximize the window, wait 15 seconds and locate all the elements that have the following XPath: “div” tag, attribute name “lang”. Print the text inside these elements.
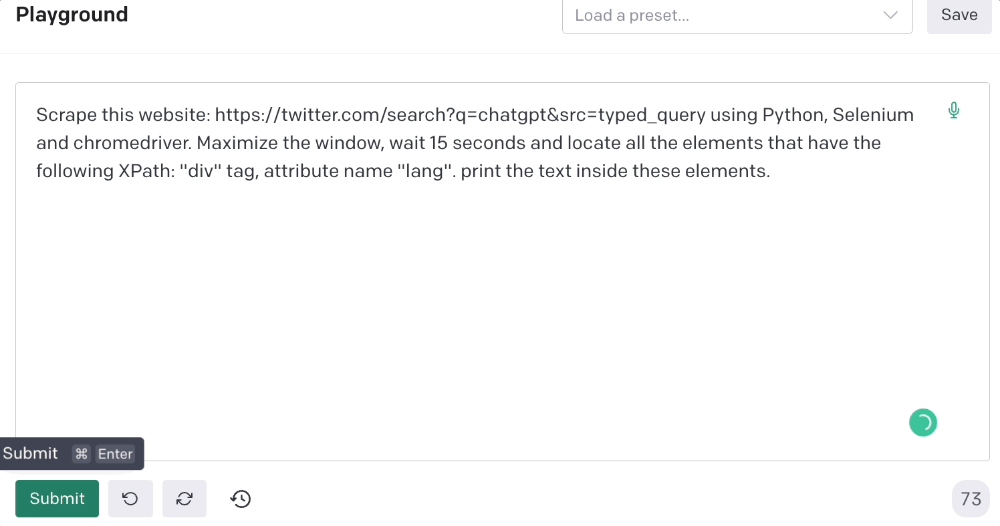
Code generated: (again, I had to add the path where my chromedriver is located)
from selenium import webdriver
import time
driver = webdriver.Chrome("/Users/frankandrade/Downloads/chromedriver")
driver.maximize_window()
driver.get("https://twitter.com/search?q=chatgpt&src=typed_query")
time.sleep(15)
elements = driver.find_elements_by_xpath("//div[@lang]")
for element in elements:
print(element.text)
driver.quit()You'll get the first 2 or 3 tweets from a search. To scrape additional tweets, click X times.
Congratulations! You scraped websites without coding by using ChatGPT.
Trevor Stark
3 years ago
Economics is complete nonsense.
Mainstream economics haven't noticed.

What come to mind when I say the word "economics"?
Probably GDP, unemployment, and inflation.
If you've ever watched the news or listened to an economist, they'll use data like these to defend a political goal.
The issue is that these statistics are total bunk.
I'm being provocative, but I mean it:
The economy is not measured by GDP.
How many people are unemployed is not counted in the unemployment rate.
Inflation is not measured by the CPI.
All orthodox economists' major economic statistics are either wrong or falsified.
Government institutions create all these stats. The administration wants to reassure citizens the economy is doing well.
GDP does not reflect economic expansion.
GDP measures a country's economic size and growth. It’s calculated by the BEA, a government agency.
The US has the world's largest (self-reported) GDP, growing 2-3% annually.
If GDP rises, the economy is healthy, say economists.
Why is the GDP flawed?
GDP measures a country's yearly spending.
The government may adjust this to make the economy look good.
GDP = C + G + I + NX
C = Consumer Spending
G = Government Spending
I = Investments (Equipment, inventories, housing, etc.)
NX = Exports minus Imports
GDP is a country's annual spending.
The government can print money to boost GDP. The government has a motive to increase and manage GDP.
Because government expenditure is part of GDP, printing money and spending it on anything will raise GDP.
They've done this. Since 1950, US government spending has grown 8% annually, faster than GDP.
In 2022, government spending accounted for 44% of GDP. It's the highest since WWII. In 1790-1910, it was 3% of GDP.
Who cares?
The economy isn't only spending. Focus on citizens' purchasing power or quality of life.
Since GDP just measures spending, the government can print money to boost GDP.
Even if Americans are poorer than last year, economists can say GDP is up and everything is fine.
How many people are unemployed is not counted in the unemployment rate.
The unemployment rate measures a country's labor market. If unemployment is high, people aren't doing well economically.
The BLS estimates the (self-reported) unemployment rate as 3-4%.
Why is the unemployment rate so high?
The US government surveys 100k persons to measure unemployment. They extrapolate this data for the country.
They come into 3 categories:
Employed
People with jobs are employed … duh.
Unemployed
People who are “jobless, looking for a job, and available for work” are unemployed
Not in the labor force
The “labor force” is the employed + the unemployed.
The unemployment rate is the percentage of unemployed workers.
Problem is unemployed definition. You must actively seek work to be considered unemployed.
You're no longer unemployed if you haven't interviewed in 4 weeks.
This shit makes no goddamn sense.
Why does this matter?
You can't interview if there are no positions available. You're no longer unemployed after 4 weeks.
In 1994, the BLS redefined "unemployed" to exclude discouraged workers.
If you haven't interviewed in 4 weeks, you're no longer counted in the unemployment rate.
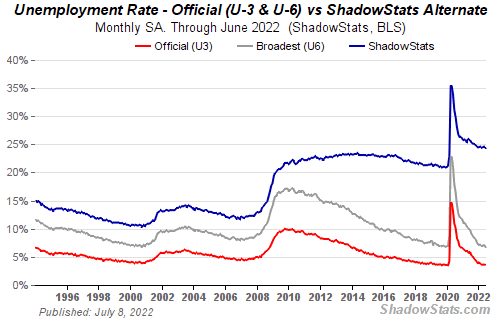
If unemployment were measured by total unemployed, it would be 25%.
Because the government wants to keep the unemployment rate low, they modify the definition.
If every US resident was unemployed and had no job interviews, economists would declare 0% unemployment. Excellent!
Inflation is not measured by the CPI.
The BLS measures CPI. This month was the highest since 1981.
CPI measures the cost of a basket of products across time. Food, energy, shelter, and clothes are included.
A 9.1% CPI means the basket of items is 9.1% more expensive.
What is the CPI problem?
Here's a more detailed explanation of CPI's flaws.
In summary, CPI is manipulated to be understated.
Housing costs are understated to manipulate CPI. Housing accounts for 33% of the CPI because it's the biggest expense for most people.
This signifies it's the biggest CPI weight.
Rather than using actual house prices, the Bureau of Labor Statistics essentially makes shit up. You can read more about the process here.
Surprise! It’s bullshit
The BLS stated Shelter's price rose 5.5% this month.
House prices are up 11-21%. (Source 1, Source 2, Source 3)
Rents are up 14-26%. (Source 1, Source 2)
Why is this important?
If CPI included housing prices, it would be 12-15 percent this month, not 9.1 percent.
9% inflation is nuts. Your money's value halves every 7 years at 9% inflation.
Worse is 15% inflation. Your money halves every 4 years at 15% inflation.
If everyone realized they needed to double their wage every 4-5 years to stay wealthy, there would be riots.
Inflation drains our money's value so the government can keep printing it.
The Solution
Most individuals know the existing system doesn't work, but can't explain why.
People work hard yet lag behind. The government lies about the economy's data.
In reality:
GDP has been down since 2008
25% of Americans are unemployed
Inflation is actually 15%
People might join together to vote out kleptocratic politicians if they knew the reality.
Having reliable economic data is the first step.
People can't understand the situation without sufficient information. Instead of immigrants or billionaires, people would blame liar politicians.
Here’s the vision:
A decentralized, transparent, and global dashboard that tracks economic data like GDP, unemployment, and inflation for every country on Earth.
Government incentives influence economic statistics.
ShadowStats has already started this effort, but the calculations must be transparent, decentralized, and global to be effective.
If interested, email me at trevorstark02@gmail.com.
Here are some links to further your research: