



More on Economics & Investing

Justin Kuepper
3 years ago
Day Trading Introduction
Historically, only large financial institutions, brokerages, and trading houses could actively trade in the stock market. With instant global news dissemination and low commissions, developments such as discount brokerages and online trading have leveled the playing—or should we say trading—field. It's never been easier for retail investors to trade like pros thanks to trading platforms like Robinhood and zero commissions.
Day trading is a lucrative career (as long as you do it properly). But it can be difficult for newbies, especially if they aren't fully prepared with a strategy. Even the most experienced day traders can lose money.
So, how does day trading work?
Day Trading Basics
Day trading is the practice of buying and selling a security on the same trading day. It occurs in all markets, but is most common in forex and stock markets. Day traders are typically well educated and well funded. For small price movements in highly liquid stocks or currencies, they use leverage and short-term trading strategies.
Day traders are tuned into short-term market events. News trading is a popular strategy. Scheduled announcements like economic data, corporate earnings, or interest rates are influenced by market psychology. Markets react when expectations are not met or exceeded, usually with large moves, which can help day traders.
Intraday trading strategies abound. Among these are:
- Scalping: This strategy seeks to profit from minor price changes throughout the day.
- Range trading: To determine buy and sell levels, range traders use support and resistance levels.
- News-based trading exploits the increased volatility around news events.
- High-frequency trading (HFT): The use of sophisticated algorithms to exploit small or short-term market inefficiencies.
A Disputed Practice
Day trading's profit potential is often debated on Wall Street. Scammers have enticed novices by promising huge returns in a short time. Sadly, the notion that trading is a get-rich-quick scheme persists. Some daytrade without knowledge. But some day traders succeed despite—or perhaps because of—the risks.
Day trading is frowned upon by many professional money managers. They claim that the reward rarely outweighs the risk. Those who day trade, however, claim there are profits to be made. Profitable day trading is possible, but it is risky and requires considerable skill. Moreover, economists and financial professionals agree that active trading strategies tend to underperform passive index strategies over time, especially when fees and taxes are factored in.
Day trading is not for everyone and is risky. It also requires a thorough understanding of how markets work and various short-term profit strategies. Though day traders' success stories often get a lot of media attention, keep in mind that most day traders are not wealthy: Many will fail, while others will barely survive. Also, while skill is important, bad luck can sink even the most experienced day trader.
Characteristics of a Day Trader
Experts in the field are typically well-established professional day traders.
They usually have extensive market knowledge. Here are some prerequisites for successful day trading.
Market knowledge and experience
Those who try to day-trade without understanding market fundamentals frequently lose. Day traders should be able to perform technical analysis and read charts. Charts can be misleading if not fully understood. Do your homework and know the ins and outs of the products you trade.
Enough capital
Day traders only use risk capital they can lose. This not only saves them money but also helps them trade without emotion. To profit from intraday price movements, a lot of capital is often required. Most day traders use high levels of leverage in margin accounts, and volatile market swings can trigger large margin calls on short notice.
Strategy
A trader needs a competitive advantage. Swing trading, arbitrage, and trading news are all common day trading strategies. They tweak these strategies until they consistently profit and limit losses.
Strategy Breakdown:
Type | Risk | Reward
Swing Trading | High | High
Arbitrage | Low | Medium
Trading News | Medium | Medium
Mergers/Acquisitions | Medium | High
Discipline
A profitable strategy is useless without discipline. Many day traders lose money because they don't meet their own criteria. “Plan the trade and trade the plan,” they say. Success requires discipline.
Day traders profit from market volatility. For a day trader, a stock's daily movement is appealing. This could be due to an earnings report, investor sentiment, or even general economic or company news.
Day traders also prefer highly liquid stocks because they can change positions without affecting the stock's price. Traders may buy a stock if the price rises. If the price falls, a trader may decide to sell short to profit.
A day trader wants to trade a stock that moves (a lot).
Day Trading for a Living
Professional day traders can be self-employed or employed by a larger institution.
Most day traders work for large firms like hedge funds and banks' proprietary trading desks. These traders benefit from direct counterparty lines, a trading desk, large capital and leverage, and expensive analytical software (among other advantages). By taking advantage of arbitrage and news events, these traders can profit from less risky day trades before individual traders react.
Individual traders often manage other people’s money or simply trade with their own. They rarely have access to a trading desk, but they frequently have strong ties to a brokerage (due to high commissions) and other resources. However, their limited scope prevents them from directly competing with institutional day traders. Not to mention more risks. Individuals typically day trade highly liquid stocks using technical analysis and swing trades, with some leverage.
Day trading necessitates access to some of the most complex financial products and services. Day traders usually need:
Access to a trading desk
Traders who work for large institutions or manage large sums of money usually use this. The trading or dealing desk provides these traders with immediate order execution, which is critical during volatile market conditions. For example, when an acquisition is announced, day traders interested in merger arbitrage can place orders before the rest of the market.
News sources
The majority of day trading opportunities come from news, so being the first to know when something significant happens is critical. It has access to multiple leading newswires, constant news coverage, and software that continuously analyzes news sources for important stories.
Analytical tools
Most day traders rely on expensive trading software. Technical traders and swing traders rely on software more than news. This software's features include:
-
Automatic pattern recognition: It can identify technical indicators like flags and channels, or more complex indicators like Elliott Wave patterns.
-
Genetic and neural applications: These programs use neural networks and genetic algorithms to improve trading systems and make more accurate price predictions.
-
Broker integration: Some of these apps even connect directly to the brokerage, allowing for instant and even automatic trade execution. This reduces trading emotion and improves execution times.
-
Backtesting: This allows traders to look at past performance of a strategy to predict future performance. Remember that past results do not always predict future results.
Together, these tools give traders a competitive advantage. It's easy to see why inexperienced traders lose money without them. A day trader's earnings potential is also affected by the market in which they trade, their capital, and their time commitment.
Day Trading Risks
Day trading can be intimidating for the average investor due to the numerous risks involved. The SEC highlights the following risks of day trading:
Because day traders typically lose money in their first months of trading and many never make profits, they should only risk money they can afford to lose.
Trading is a full-time job that is stressful and costly: Observing dozens of ticker quotes and price fluctuations to spot market trends requires intense concentration. Day traders also spend a lot on commissions, training, and computers.
Day traders heavily rely on borrowing: Day-trading strategies rely on borrowed funds to make profits, which is why many day traders lose everything and end up in debt.
Avoid easy profit promises: Avoid “hot tips” and “expert advice” from day trading newsletters and websites, and be wary of day trading educational seminars and classes.
Should You Day Trade?
As stated previously, day trading as a career can be difficult and demanding.
- First, you must be familiar with the trading world and know your risk tolerance, capital, and goals.
- Day trading also takes a lot of time. You'll need to put in a lot of time if you want to perfect your strategies and make money. Part-time or whenever isn't going to cut it. You must be fully committed.
- If you decide trading is for you, remember to start small. Concentrate on a few stocks rather than jumping into the market blindly. Enlarging your trading strategy can result in big losses.
- Finally, keep your cool and avoid trading emotionally. The more you can do that, the better. Keeping a level head allows you to stay focused and on track.
If you follow these simple rules, you may be on your way to a successful day trading career.
Is Day Trading Illegal?
Day trading is not illegal or unethical, but it is risky. Because most day-trading strategies use margin accounts, day traders risk losing more than they invest and becoming heavily in debt.
How Can Arbitrage Be Used in Day Trading?
Arbitrage is the simultaneous purchase and sale of a security in multiple markets to profit from small price differences. Because arbitrage ensures that any deviation in an asset's price from its fair value is quickly corrected, arbitrage opportunities are rare.
Why Don’t Day Traders Hold Positions Overnight?
Day traders rarely hold overnight positions for several reasons: Overnight trades require more capital because most brokers require higher margin; stocks can gap up or down on overnight news, causing big trading losses; and holding a losing position overnight in the hope of recovering some or all of the losses may be against the trader's core day-trading philosophy.
What Are Day Trader Margin Requirements?
Regulation D requires that a pattern day trader client of a broker-dealer maintain at all times $25,000 in equity in their account.
How Much Buying Power Does Day Trading Have?
Buying power is the total amount of funds an investor has available to trade securities. FINRA rules allow a pattern day trader to trade up to four times their maintenance margin excess as of the previous day's close.
The Verdict
Although controversial, day trading can be a profitable strategy. Day traders, both institutional and retail, keep the markets efficient and liquid. Though day trading is still popular among novice traders, it should be left to those with the necessary skills and resources.

Liam Vaughan
3 years ago
Investors can bet big on almost anything on a new prediction market.
Kalshi allows five-figure bets on the Grammys, the next Covid wave, and future SEC commissioners. Worst-case scenario
On Election Day 2020, two young entrepreneurs received a call from the CFTC chairman. Luana Lopes Lara and Tarek Mansour spent 18 months trying to start a new type of financial exchange. Instead of betting on stock prices or commodity futures, people could trade instruments tied to real-world events, such as legislation, the weather, or the Oscar winner.
Heath Tarbert, a Trump appointee, shouted "Congratulations." "You're competing with 1840s-era markets. I'm sure you'll become a powerhouse too."
Companies had tried to introduce similar event markets in the US for years, but Tarbert's agency, the CFTC, said no, arguing they were gambling and prone to cheating. Now the agency has reversed course, approving two 24-year-olds who will have first-mover advantage in what could become a huge new asset class. Kalshi Inc. raised $30 million from venture capitalists within weeks of Tarbert's call, his representative says. Mansour, 26, believes this will be bigger than crypto.
Anyone who's read The Wisdom of Crowds knows prediction markets' potential. Well-designed markets can help draw out knowledge from disparate groups, and research shows that when money is at stake, people make better predictions. Lopes Lara calls it a "bullshit tax." That's why Google, Microsoft, and even the US Department of Defense use prediction markets internally to guide decisions, and why university-linked political betting sites like PredictIt sometimes outperform polls.
Regulators feared Wall Street-scale trading would encourage investors to manipulate reality. If the stakes are high enough, traders could pressure congressional staffers to stall a bill or bet on whether Kanye West's new album will drop this week. When Lopes Lara and Mansour pitched the CFTC, senior regulators raised these issues. Politically appointed commissioners overruled their concerns, and one later joined Kalshi's board.
Will Kanye’s new album come out next week? Yes or no?
Kalshi's victory was due more to lobbying and legal wrangling than to Silicon Valley-style innovation. Lopes Lara and Mansour didn't invent anything; they changed a well-established concept's governance. The result could usher in a new era of market-based enlightenment or push Wall Street's destructive tendencies into the real world.
If Kalshi's founders lacked experience to bolster their CFTC application, they had comical youth success. Lopes Lara studied ballet at the Brazilian Bolshoi before coming to the US. Mansour won France's math Olympiad. They bonded over their work ethic in an MIT computer science class.
Lopes Lara had the idea for Kalshi while interning at a New York hedge fund. When the traders around her weren't working, she noticed they were betting on the news: Would Apple hit a trillion dollars? Kylie Jenner? "It was anything," she says.
Are mortgage rates going up? Yes or no?
Mansour saw the business potential when Lopes Lara suggested it. He interned at Goldman Sachs Group Inc., helping investors prepare for the UK leaving the EU. Goldman sold clients complex stock-and-derivative combinations. As he discussed it with Lopes Lara, they agreed that investors should hedge their risk by betting on Brexit itself rather than an imperfect proxy.
Lopes Lara and Mansour hypothesized how a marketplace might work. They settled on a "event contract," a binary-outcome instrument like "Will inflation hit 5% by the end of the month?" The contract would settle at $1 (if the event happened) or zero (if it didn't), but its price would fluctuate based on market sentiment. After a good debate, a politician's election odds may rise from 50 to 55. Kalshi would charge a commission on every trade and sell data to traders, political campaigns, businesses, and others.
In October 2018, five months after graduation, the pair flew to California to compete in a hackathon for wannabe tech founders organized by the Silicon Valley incubator Y Combinator. They built a website in a day and a night and presented it to entrepreneurs the next day. Their prototype barely worked, but they won a three-month mentorship program and $150,000. Michael Seibel, managing director of Y Combinator, said of their idea, "I had to take a chance!"
Will there be another moon landing by 2025?
Seibel's skepticism was rooted in America's historical wariness of gambling. Roulette, poker, and other online casino games are largely illegal, and sports betting was only legal in a few states until May 2018. Kalshi as a risk-hedging platform rather than a bookmaker seemed like a good idea, but convincing the CFTC wouldn't be easy. In 2012, the CFTC said trading on politics had no "economic purpose" and was "contrary to the public interest."
Lopes Lara and Mansour cold-called 60 Googled lawyers during their time at Y Combinator. Everyone advised quitting. Mansour recalls the pain. Jeff Bandman, a former CFTC official, helped them navigate the agency and its characters.
When they weren’t busy trying to recruit lawyers, Lopes Lara and Mansour were meeting early-stage investors. Alfred Lin of Sequoia Capital Operations LLC backed Airbnb, DoorDash, and Uber Technologies. Lin told the founders their idea could capitalize on retail trading and challenge how the financial world manages risk. "Come back with regulatory approval," he said.
In the US, even small bets on most events were once illegal. Under the Commodity Exchange Act, the CFTC can stop exchanges from listing contracts relating to "terrorism, assassination, war" and "gaming" if they are "contrary to the public interest," which was often the case.
Will subway ridership return to normal? Yes or no?
In 1988, as academic interest in the field grew, the agency allowed the University of Iowa to set up a prediction market for research purposes, as long as it didn't make a profit or advertise and limited bets to $500. PredictIt, the biggest and best-known political betting platform in the US, also got an exemption thanks to an association with Victoria University of Wellington in New Zealand. Today, it's a sprawling marketplace with its own subculture and lingo. PredictIt users call it "Rules Cuck Panther" when they lose on a technicality. Major news outlets cite PredictIt's odds on Discord and the Star Spangled Gamblers podcast.
CFTC limits PredictIt bets to $850. To keep traders happy, PredictIt will often run multiple variations of the same question, listing separate contracts for two dozen Democratic primary candidates, for example. A trader could have more than $10,000 riding on a single outcome. Some of the site's traders are current or former campaign staffers who can answer questions like "How many tweets will Donald Trump post from Nov. 20 to 27?" and "When will Anthony Scaramucci's role as White House communications director end?"
According to PredictIt co-founder John Phillips, politicians help explain the site's accuracy. "Prediction markets work well and are accurate because they attract people with superior information," he said in a 2016 podcast. “In the financial stock market, it’s called inside information.”
Will Build Back Better pass? Yes or no?
Trading on nonpublic information is illegal outside of academia, which presented a dilemma for Lopes Lara and Mansour. Kalshi's forecasts needed to be accurate. Kalshi must eliminate insider trading as a regulated entity. Lopes Lara and Mansour wanted to build a high-stakes PredictIt without the anarchy or blurred legal lines—a "New York Stock Exchange for Events." First, they had to convince regulators event trading was safe.
When Lopes Lara and Mansour approached the CFTC in the spring of 2019, some officials in the Division of Market Oversight were skeptical, according to interviews with people involved in the process. For all Kalshi's talk of revolutionizing finance, this was just a turbocharged version of something that had been rejected before.
The DMO couldn't see the big picture. The staff review was supposed to ensure Kalshi could complete a checklist, "23 Core Principles of a Designated Contract Market," which included keeping good records and having enough money. The five commissioners decide. With Trump as president, three of them were ideologically pro-market.
Lopes Lara, Mansour, and their lawyer Bandman, an ex-CFTC official, answered the DMO's questions while lobbying the commissioners on Zoom about the potential of event markets to mitigate risks and make better decisions. Before each meeting, they would write a script and memorize it word for word.
Will student debt be forgiven? Yes or no?
Several prediction markets that hadn't sought regulatory approval bolstered Kalshi's case. Polymarket let customers bet hundreds of thousands of dollars anonymously using cryptocurrencies, making it hard to track. Augur, which facilitates private wagers between parties using blockchain, couldn't regulate bets and hadn't stopped users from betting on assassinations. Kalshi, by comparison, argued it was doing everything right. (The CFTC fined Polymarket $1.4 million for operating an unlicensed exchange in January 2022. Polymarket says it's now compliant and excited to pioneer smart contract-based financial solutions with regulators.
Kalshi was approved unanimously despite some DMO members' concerns about event contracts' riskiness. "Once they check all the boxes, they're in," says a CFTC insider.
Three months after CFTC approval, Kalshi announced funding from Sequoia, Charles Schwab, and Henry Kravis. Sequoia's Lin, who joined the board, said Tarek, Luana, and team created a new way to invest and engage with the world.
The CFTC hadn't asked what markets the exchange planned to run since. After approval, Lopes Lara and Mansour had the momentum. Kalshi's March list of 30 proposed contracts caused chaos at the DMO. The division handles exchanges that create two or three new markets a year. Kalshi’s business model called for new ones practically every day.
Uncontroversial proposals included weather and GDP questions. Others, on the initial list and later, were concerning. DMO officials feared Covid-19 contracts amounted to gambling on human suffering, which is why war and terrorism markets are banned. (Similar logic doomed ex-admiral John Poindexter's Policy Analysis Market, a Bush-era plan to uncover intelligence by having security analysts bet on Middle East events.) Regulators didn't see how predicting the Grammy winners was different from betting on the Patriots to win the Super Bowl. Who, other than John Legend, would need to hedge the best R&B album winner?
Event contracts raised new questions for the DMO's product review team. Regulators could block gaming contracts that weren't in the public interest under the Commodity Exchange Act, but no one had defined gaming. It was unclear whether the CFTC had a right or an obligation to consider whether a contract was in the public interest. How was it to determine public interest? Another person familiar with the CFTC review says, "It was a mess." The agency didn't comment.
CFTC staff feared some event contracts could be cheated. Kalshi wanted to run a bee-endangerment market. The DMO pushed back, saying it saw two problems symptomatic of the asset class: traders could press government officials for information, and officials could delay adding the insects to the list to cash in.
The idea that traders might manipulate prediction markets wasn't paranoid. In 2013, academics David Rothschild and Rajiv Sethi found that an unidentified party lost $7 million buying Mitt Romney contracts on Intrade, a now-defunct, unlicensed Irish platform, in the runup to the 2012 election. The authors speculated that the trader, whom they dubbed the “Romney Whale,” may have been looking to boost morale and keep donations coming in.
Kalshi said manipulation and insider trading are risks for any market. It built a surveillance system and said it would hire a team to monitor it. "People trade on events all the time—they just use options and other instruments. This brings everything into the open, Mansour says. Kalshi didn't include election contracts, a red line for CFTC Democrats.
Lopes Lara and Mansour were ready to launch kalshi.com that summer, but the DMO blocked them. Product reviewers were frustrated by spending half their time on an exchange that represented a tiny portion of the derivatives market. Lopes Lara and Mansour pressed politically appointed commissioners during the impasse.
Tarbert, the chairman, had moved on, but Kalshi found a new supporter in Republican Brian Quintenz, a crypto-loving former hedge fund manager. He was unmoved by the DMO's concerns, arguing that speculation on Kalshi's proposed events was desirable and the agency had no legal standing to prevent it. He supported a failed bid to allow NFL futures earlier this year. Others on the commission were cautious but supportive. Given the law's ambiguity, they worried they'd be on shaky ground if Kalshi sued if they blocked a contract. Without a permanent chairman, the agency lacked leadership.
To block a contract, DMO staff needed a majority of commissioners' support, which they didn't have in all but a few cases. "We didn't have the votes," a reviewer says, paraphrasing Hamilton. By the second half of 2021, new contract requests were arriving almost daily at the DMO, and the demoralized and overrun division eventually accepted defeat and stopped fighting back. By the end of the year, three senior DMO officials had left the agency, making it easier for Kalshi to list its contracts unimpeded.
Today, Kalshi is growing. 32 employees work in a SoHo office with big windows and exposed brick. Quintenz, who left the CFTC 10 months after Kalshi was approved, is on its board. He joined because he was interested in the market's hedging and risk management opportunities.
Mid-May, the company's website had 75 markets, such as "Will Q4 GDP be negative?" Will NASA land on the moon by 2025? The exchange recently reached 2 million weekly contracts, a jump from where it started but still a small number compared to other futures exchanges. Early adopters are PredictIt and Polymarket fans. Bets on the site are currently capped at $25,000, but Kalshi hopes to increase that to $100,000 and beyond.
With the regulatory drawbridge down, Lopes Lara and Mansour must move quickly. Chicago's CME Group Inc. plans to offer index-linked event contracts. Kalshi will release a smartphone app to attract customers. After that, it hopes to partner with a big brokerage. Sequoia is a major investor in Robinhood Markets Inc. Robinhood users could have access to Kalshi so that after buying GameStop Corp. shares, they'd be prompted to bet on the Oscars or the next Fed commissioner.
Some, like Illinois Democrat Sean Casten, accuse Robinhood and its competitors of gamifying trading to encourage addiction, but Kalshi doesn't seem worried. Mansour says Kalshi's customers can't bet more than they've deposited, making debt difficult. Eventually, he may introduce leveraged bets.
Tension over event contracts recalls another CFTC episode. Brooksley Born proposed regulating the financial derivatives market in 1994. Alan Greenspan and others in the government opposed her, saying it would stifle innovation and push capital overseas. Unrestrained, derivatives grew into a trillion-dollar industry until 2008, when they sparked the financial crisis.
Today, with a midterm election looming, it seems reasonable to ask whether Kalshi plans to get involved. Elections have historically been the biggest draw in prediction markets, with 125 million shares traded on PredictIt for 2020. “We can’t discuss specifics,” Mansour says. “All I can say is, you know, we’re always working on expanding the universe of things that people can trade on.”
Any election contracts would need CFTC approval, which may be difficult with three Democratic commissioners. A Republican president would change the equation.

Quant Galore
3 years ago
I created BAW-IV Trading because I was short on money.
More retail traders means faster, more sophisticated, and more successful methods.
Tech specifications
Only requires a laptop and an internet connection.
We'll use OpenBB's research platform for data/analysis.
Pricing and execution on Options-Quant

Background
You don't need to know the arithmetic details to use this method.
Black-Scholes is a popular option pricing model. It's best for pricing European options. European options are only exercisable at expiration, unlike American options. American options are always exercisable.
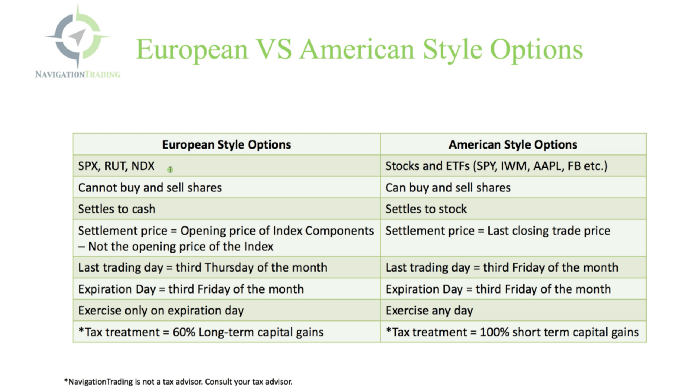
American options carry a premium to cover for the risk of early exercise. The Black-Scholes model doesn't account for this premium, hence it can't price genuine, traded American options.
Barone-Adesi-Whaley (BAW) model. BAW modifies Black-Scholes. It accounts for exercise risk premium and stock dividends. It adds the option's early exercise value to the Black-Scholes value.
The trader need not know the formulaic derivations of this model.
https://ir.nctu.edu.tw/bitstream/11536/14182/1/000264318900005.pdf
Strategy
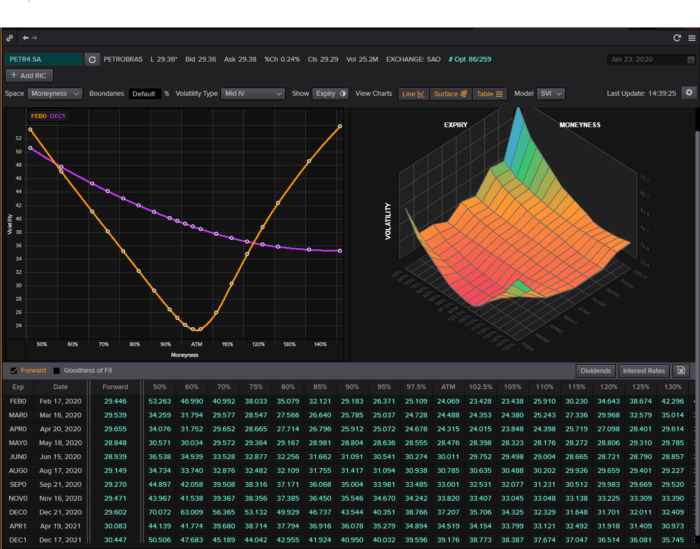
This strategy targets implied volatility. First, we'll locate liquid options that expire within 30 days and have minimal implied volatility.
After selecting the option that meets the requirements, we price it to get the BAW implied volatility (we choose BAW because it's a more accurate Black-Scholes model). If estimated implied volatility is larger than market volatility, we'll capture the spread.
(Calculated IV — Market IV) = (Profit)
Some approaches to target implied volatility are pricey and inaccessible to individual investors. The best and most cost-effective alternative is to acquire a straddle and delta hedge. This may sound terrifying and pricey, but as shown below, it's much less so.
The Trade
First, we want to find our ideal option, so we use OpenBB terminal to screen for options that:
Have an IV at least 5% lower than the 20-day historical IV
Are no more than 5% out-of-the-money
Expire in less than 30 days
We query:
stocks/options/screen/set low_IV/scr --export Output.csv
This uses the screener function to screen for options that satisfy the above criteria, which we specify in the low IV preset (more on custom presets here). It then saves the matching results to a csv(Excel) file for viewing and analysis.
Stick to liquid names like SPY, AAPL, and QQQ since getting out of a position is just as crucial as getting in. Smaller, illiquid names have higher inefficiencies, which could restrict total profits.

We calculate IV using the BAWbisection model (the bisection is a method of calculating IV, more can be found here.) We price the IV first.

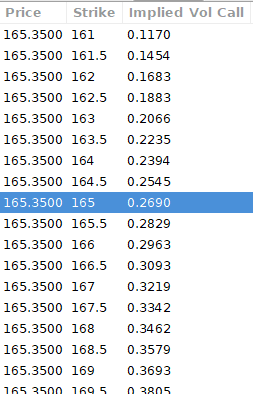
According to the BAW model, implied volatility at this level should be priced at 26.90%. When re-pricing the put, IV is 24.34%, up 3%.
Now it's evident. We must purchase the straddle (long the call and long the put) assuming the computed implied volatility is more appropriate and efficient than the market's. We just want to speculate on volatility, not price fluctuations, thus we delta hedge.
The Fun Starts
We buy both options for $7.65. (x100 multiplier). Initial delta is 2. For every dollar the stock price swings up or down, our position value moves $2.

We want delta to be 0 to avoid price vulnerability. A delta of 0 suggests our position's value won't change from underlying price changes. Being delta-hedged allows us to profit/lose from implied volatility. Shorting 2 shares makes us delta-neutral.

That's delta hedging. (Share price * shares traded) = $330.7 to become delta-neutral. You may have noted that delta is not truly 0.00. This is common since delta-hedging means getting as near to 0 as feasible, since it is rare for deltas to align at 0.00.
Now we're vulnerable to changes in Vega (and Gamma, but given we're dynamically hedging, it's not a big risk), or implied volatility. We wanted to gamble that the position's IV would climb by at least 2%, so we'll maintain it delta-hedged and watch IV.
Because the underlying moves continually, the option's delta moves continuously. A trader can short/long 5 AAPL shares at most. Paper trading lets you practice delta-hedging. Being quick-footed will help with this tactic.
Profit-Closing
As expected, implied volatility rose. By 10 minutes before market closure, the call's implied vol rose to 27% and the put's to 24%. This allowed us to sell the call for $4.95 and the put for $4.35, creating a profit of $165.

You may pull historical data to see how this trade performed. Note the implied volatility and pricing in the final options chain for August 5, 2022 (the position date).

Final Thoughts
Congratulations, that was a doozy. To reiterate, we identified tickers prone to increased implied volatility by screening OpenBB's low IV setting. We double-checked the IV by plugging the price into Options-BAW Quant's model. When volatility was off, we bought a straddle and delta-hedged it. Finally, implied volatility returned to a normal level, and we profited on the spread.
The retail trading space is very quickly catching up to that of institutions. Commissions and fees used to kill this method, but now they cost less than $5. Watching momentum, technical analysis, and now quantitative strategies evolve is intriguing.
I'm not linked with these sites and receive no financial benefit from my writing.
Tell me how your experience goes and how I helped; I love success tales.
You might also like

Katharine Valentino
3 years ago
A Gun-toting Teacher Is Like a Cook With Rat Poison
Pink or blue AR-15s?
A teacher teaches; a gun kills. Killing isn't teaching. Killing is opposite of teaching.
Without 27 school shootings this year, we wouldn't be talking about arming teachers. Gun makers, distributors, and the NRA cause most school shootings. Gun makers, distributors, and the NRA wouldn't be huge business if weapons weren't profitable.
Guns, ammo, body armor, holsters, concealed carriers, bore sights, cleaner kits, spare magazines and speed loaders, gun safes, and ear protection are sold. And more guns.
And lots more profit.
Guns aren't bread. You eat a loaf of bread in a week or so and then must buy more. Bread makers will make money. Winchester 94.30–30 1899 Lever Action Rifle from 1894 still kills. (For safety, I won't link to the ad.) Gun makers don't object if you collect antique weapons, but they need you to buy the latest, in-style killing machine. The youngster who killed 19 students and 2 teachers at Robb Elementary School in Uvalde, Texas, used an AR-15. Better yet, two.
Salvador Ramos, the Robb Elementary shooter, is a "killing influencer" He pushes consumers to buy items, which benefits manufacturers and distributors. Like every previous AR-15 influencer, he profits Colt, the rifle's manufacturer, and 52,779 gun dealers in the U.S. Ramos and other AR-15 influences make us fear for our safety and our children's. Fearing for our safety, we acquire 20 million firearms a year and live in a gun culture.
So now at school, we want to arm teachers.
Consider. Which of your teachers would you have preferred in body armor with a gun drawn?
Miss Summers? Remember her bringing daisies from her yard to second grade? She handed each student a beautiful flower. Miss Summers loved everyone, even those with AR-15s. She can't shoot.
Frasier? Mr. Frasier turned a youngster over down to explain "invert." Mr. Frasier's hands shook when he wasn't flipping fifth-graders and fractions. He may have shot wrong.
Mrs. Barkley barked in high school English class when anyone started an essay with "But." Mrs. Barkley dubbed Abie a "Jewboy" and gave him terrible grades. Arming Miss Barkley is like poisoning the chef.
Think back. Do you remember a teacher with a gun? No. Arming teachers so the gun industry can make more money is the craziest idea ever.
Or maybe you agree with Ted Cruz, the gun lobby-bought senator, that more guns reduce gun violence. After the next school shooting, you'll undoubtedly talk about arming teachers and pupils. Colt will likely develop a backpack-sized, lighter version of its popular killing machine in pink and blue for kids and boys. The MAR-15? (M for mini).
This post is a summary. Read the full one here.

Sanjay Priyadarshi
3 years ago
Meet a Programmer Who Turned Down Microsoft's $10,000,000,000 Acquisition Offer
Failures inspire young developers

Jason citron created many products.
These products flopped.
Microsoft offered $10 billion for one of these products.
He rejected the offer since he was so confident in his success.
Let’s find out how he built a product that is currently valued at $15 billion.
Early in his youth, Jason began learning to code.
Jason's father taught him programming and IT.
His father wanted to help him earn money when he needed it.
Jason created video games and websites in high school.
Jason realized early on that his IT and programming skills could make him money.
Jason's parents misjudged his aptitude for programming.
Jason frequented online programming communities.
He looked for web developers. He created websites for those people.
His parents suspected Jason sold drugs online. When he said he used programming to make money, they were shocked.
They helped him set up a PayPal account.
Florida higher education to study video game creation
Jason never attended an expensive university.
He studied game design in Florida.
“Higher Education is an interesting part of society… When I work with people, the school they went to never comes up… only thing that matters is what can you do…At the end of the day, the beauty of silicon valley is that if you have a great idea and you can bring it to the life, you can convince a total stranger to give you money and join your project… This notion that you have to go to a great school didn’t end up being a thing for me.”
Jason's life was altered by Steve Jobs' keynote address.
After graduating, Jason joined an incubator.
Jason created a video-dating site first.
Bad idea.
Nobody wanted to use it when it was released, so they shut it down.
He made a multiplayer game.
It was released on Bebo. 10,000 people played it.
When Steve Jobs unveiled the Apple app store, he stopped playing.
The introduction of the app store resembled that of a new gaming console.
Jason's life altered after Steve Jobs' 2008 address.
“Whenever a new video game console is launched, that’s the opportunity for a new video game studio to get started, it’s because there aren’t too many games available…When a new PlayStation comes out, since it’s a new system, there’s only a handful of titles available… If you can be a launch title you can get a lot of distribution.”
Apple's app store provided a chance to start a video game company.
They released an app after 5 months of work.
Aurora Feint is the game.
Jason believed 1000 players in a week would be wonderful. A thousand players joined in the first hour.
Over time, Aurora Feints' game didn't gain traction. They don't make enough money to keep playing.
They could only make enough for one month.
Instead of buying video games, buy technology
Jason saw that they established a leaderboard, chat rooms, and multiplayer capabilities and believed other developers would want to use these.
They opted to sell the prior game's technology.
OpenFeint.
Assisting other game developers
They had no money in the bank to create everything needed to make the technology user-friendly.
Jason and Daniel designed a website saying:
“If you’re making a video game and want to have a drop in multiplayer support, you can use our system”
TechCrunch covered their website launch, and they gained a few hundred mailing list subscribers.
They raised seed funding with the mailing list.
Nearly all iPhone game developers started adopting the Open Feint logo.
“It was pretty wild… It was really like a whole social platform for people to play with their friends.”
What kind of a business model was it?
OpenFeint originally planned to make the software free for all games. As the game gained popularity, they demanded payment.
They later concluded it wasn't a good business concept.
It became free eventually.
Acquired for $104 million
Open Feint's users and employees grew tremendously.
GREE bought OpenFeint for $104 million in April 2011.
GREE initially committed to helping Jason and his team build a fantastic company.
Three or four months after the acquisition, Jason recognized they had a different vision.
He quit.
Jason's Original Vision for the iPad
Jason focused on distribution in 2012 to help businesses stand out.
The iPad market and user base were growing tremendously.
Jason said the iPad may replace mobile gadgets.
iPad gamers behaved differently than mobile gamers.
People sat longer and experienced more using an iPad.
“The idea I had was what if we built a gaming business that was more like traditional video games but played on tablets as opposed to some kind of mobile game that I’ve been doing before.”
Unexpected insight after researching the video game industry
Jason learned from studying the gaming industry that long-standing companies had advantages beyond a single release.
Previously, long-standing video game firms had their own distribution system. This distribution strategy could buffer time between successful titles.
Sony, Microsoft, and Valve all have gaming consoles and online stores.
So he built a distribution system.
He created a group chat app for gamers.
He envisioned a team-based multiplayer game with text and voice interaction.
His objective was to develop a communication network, release more games, and start a game distribution business.
Remaking the video game League of Legends
Jason and his crew reimagined a League of Legends game mode for 12-inch glass.
They adapted the game for tablets.
League of Legends was PC-only.
So they rebuilt it.
They overhauled the game and included native mobile experiences to stand out.
Hammer and Chisel was the company's name.
18 people worked on the game.
The game was funded. The game took 2.5 years to make.
Was the game a success?
July 2014 marked the game's release. The team's hopes were dashed.
Critics initially praised the game.
Initial installation was widespread.
The game failed.
As time passed, the team realized iPad gaming wouldn't increase much and mobile would win.
Jason was given a fresh idea by Stan Vishnevskiy.
Stan Vishnevskiy was a corporate engineer.
He told Jason about his plan to design a communication app without a game.
This concept seeded modern strife.
“The insight that he really had was to put a couple of dots together… we’re seeing our customers communicating around our own game with all these different apps and also ourselves when we’re playing on PC… We should solve that problem directly rather than needing to build a new game…we should start making it on PC.”
So began Discord.
Online socializing with pals was the newest trend.
Jason grew up playing video games with his friends.
He never played outside.
Jason had many great moments playing video games with his closest buddy, wife, and brother.
Discord was about providing a location for you and your group to speak and hang out.
Like a private cafe, bedroom, or living room.
Discord was developed for you and your friends on computers and phones.
You can quickly call your buddies during a game to conduct a conference call. Put the call on speaker and talk while playing.
Discord wanted to give every player a unique experience. Because coordinating across apps was a headache.
The entire team started concentrating on Discord.
Jason decided Hammer and Chisel would focus on their chat app.
Jason didn't want to make a video game.
How Discord attracted the appropriate attention
During the first five months, the entire team worked on the game and got feedback from friends.
This ensures product improvement. As a result, some teammates' buddies started utilizing Discord.
The team knew it would become something, but the result was buggy. App occasionally crashed.
Jason persuaded a gamer friend to write on Reddit about the software.
New people would find Discord. Why not?
Reddit users discovered Discord and 50 started using it frequently.
Discord was launched.
Rejecting the $10 billion acquisition proposal
Discord has increased in recent years.
It sends billions of messages.
Discord's users aren't tracked. They're privacy-focused.
Purchase offer
Covid boosted Discord's user base.
Weekly, billions of messages were transmitted.
Microsoft offered $10 billion for Discord in 2021.
Jason sold Open Feint for $104m in 2011.
This time, he believed in the product so much that he rejected Microsoft's offer.
“I was talking to some people in the team about which way we could go… The good thing was that most of the team wanted to continue building.”
Last time, Discord was valued at $15 billion.
Discord raised money on March 12, 2022.
The $15 billion corporation raised $500 million in 2021.

Jari Roomer
3 years ago
10 Alternatives to Smartphone Scrolling
"Don't let technology control you; manage your phone."
"Don't become a slave to technology," said Richard Branson. "Manage your phone, don't let it manage you."
Unfortunately, most people are addicted to smartphones.
Worrying smartphone statistics:
46% of smartphone users spend 5–6 hours daily on their device.
The average adult spends 3 hours 54 minutes per day on mobile devices.
We check our phones 150–344 times per day (every 4 minutes).
During the pandemic, children's daily smartphone use doubled.
Having a list of productive, healthy, and fulfilling replacement activities is an effective way to reduce smartphone use.
The more you practice these smartphone replacements, the less time you'll waste.
Skills Development
Most people say they 'don't have time' to learn new skills or read more. Lazy justification. The issue isn't time, but time management. Distractions and low-quality entertainment waste hours every day.
The majority of time is spent in low-quality ways, according to Richard Koch, author of The 80/20 Principle.
What if you swapped daily phone scrolling for skill-building?
There are dozens of skills to learn, from high-value skills to make more money to new languages and party tricks.
Learning a new skill will last for years, if not a lifetime, compared to scrolling through your phone.
Watch Docs
Love documentaries. It's educational and relaxing. A good documentary helps you understand the world, broadens your mind, and inspires you to change.
Recent documentaries I liked include:
14 Peaks: Nothing Is Impossible
The Social Dilemma
Jim & Andy: The Great Beyond
Fantastic Fungi
Make money online
If you've ever complained about not earning enough money, put away your phone and get to work.
Instead of passively consuming mobile content, start creating it. Create something worthwhile. Freelance.
Internet makes starting a business or earning extra money easier than ever.
(Grand)parents didn't have this. Someone made them work 40+ hours. Few alternatives existed.
Today, all you need is internet and a monetizable skill. Use the internet instead of letting it distract you. Profit from it.
Bookworm
Jack Canfield, author of Chicken Soup For The Soul, said, "Everyone spends 2–3 hours a day watching TV." If you read that much, you'll be in the top 1% of your field."
Few people have more than two hours per day to read.
If you read 15 pages daily, you'd finish 27 books a year (as the average non-fiction book is about 200 pages).
Jack Canfield's quote remains relevant even though 15 pages can be read in 20–30 minutes per day. Most spend this time watching TV or on their phones.
What if you swapped 20 minutes of mindless scrolling for reading? You'd gain knowledge and skills.
Favorite books include:
The 7 Habits of Highly Effective People — Stephen R. Covey
The War of Art — Steven Pressfield
The Psychology of Money — Morgan Housel
A New Earth — Eckart Tolle
Get Organized
All that screen time could've been spent organizing. It could have been used to clean, cook, or plan your week.
If you're always 'behind,' spend 15 minutes less on your phone to get organized.
"Give me six hours to chop down a tree, and I'll spend the first four sharpening the ax," said Abraham Lincoln. Getting organized is like sharpening an ax, making each day more efficient.
Creativity
Why not be creative instead of consuming others'? Do something creative, like:
Painting
Musically
Photography\sWriting
Do-it-yourself
Construction/repair
Creative projects boost happiness, cognitive functioning, and reduce stress and anxiety. Creative pursuits induce a flow state, a powerful mental state.
This contrasts with smartphones' effects. Heavy smartphone use correlates with stress, depression, and anxiety.
Hike
People spend 90% of their time indoors, according to research. This generation is the 'Indoor Generation'
We lack an active lifestyle, fresh air, and vitamin D3 due to our indoor lifestyle (generated through direct sunlight exposure). Mental and physical health issues result.
Put away your phone and get outside. Go on nature walks. Explore your city on foot (or by bike, as we do in Amsterdam) if you live in a city. Move around! Outdoors!
You can't spend your whole life staring at screens.
Podcasting
Okay, a smartphone is needed to listen to podcasts. When you use your phone to get smarter, you're more productive than 95% of people.
Favorite podcasts:
The Pomp Podcast (about cryptocurrencies)
The Joe Rogan Experience
Kwik Brain (by Jim Kwik)
Podcasts can be enjoyed while walking, cleaning, or doing laundry. Win-win.
Journalize
I find journaling helpful for mental clarity. Writing helps organize thoughts.
Instead of reading internet opinions, comments, and discussions, look inward. Instead of Twitter or TikTok, look inward.
“It never ceases to amaze me: we all love ourselves more than other people, but care more about their opinion than our own.” — Marcus Aurelius
Give your mind free reign with pen and paper. It will highlight important thoughts, emotions, or ideas.
Never write for another person. You want unfiltered writing. So you get the best ideas.
Find your best hobbies
List your best hobbies. I guarantee 95% of people won't list smartphone scrolling.
It's often low-quality entertainment. The dopamine spike is short-lived, and it leaves us feeling emotionally 'empty'
High-quality leisure sparks happiness. They make us happy and alive. Everyone has different interests, so these activities vary.
My favorite quality hobbies are:
Nature walks (especially the mountains)
Video game party
Watching a film with my girlfriend
Gym weightlifting
Complexity learning (such as the blockchain and the universe)
This brings me joy. They make me feel more fulfilled and 'rich' than social media scrolling.
Make a list of your best hobbies to refer to when you're spending too much time on your phone.