
























More on NFTs & Art

CyberPunkMetalHead
2 years ago
Why Bitcoin NFTs Are Incomprehensible yet Likely Here to Stay

I'm trying to understand why Bitcoin NFTs aren't ready.
Ordinals, a new Bitcoin protocol, has been controversial. NFTs can be added to Bitcoin transactions using the protocol. They are not tokens or fungible. Bitcoin NFTs are transaction metadata. Yes. They're not owned.
In January, the Ordinals protocol allowed data like photos to be directly encoded onto sats, the smallest units of Bitcoin worth 0.00000001 BTC, on the Bitcoin blockchain. Ordinals does not need a sidechain or token like other techniques. The Ordinals protocol has encoded JPEG photos, digital art, new profile picture (PFP) projects, and even 1993 DOOM onto the Bitcoin network.
Ordinals inscriptions are permanent digital artifacts preserved on the Bitcoin blockchain. It differs from Ethereum, Solana, and Stacks NFT technologies that allow smart contract creators to change information. Ordinals store the whole image or content on the blockchain, not just a link to an external server, unlike centralized databases, which can change the linked image, description, category, or contract identifier.
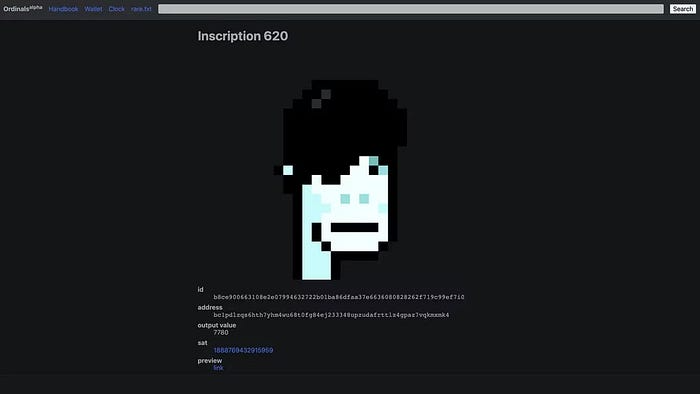
So far, more than 50,000 ordinals have been produced on the Bitcoin blockchain, and some of them have already been sold for astronomical amounts. The Ethereum-based CryptoPunks NFT collection spawned Ordinal Punk. Inscription 620 sold for 9.5 BTC, or $218,000, the most.
Segwit and Taproot, two important Bitcoin blockchain updates, enabled this. These protocols store transaction metadata, unlike Ethereum, where the NFT is the token. Bitcoin's NFT is a sat's transaction details.
What effects do ordinary values and NFTs have on the Bitcoin blockchain?
Ordinals will likely have long-term effects on the Bitcoin Ecosystem since they store, transact, and compute more data.
Charges Ordinals introduce scalability challenges. The Bitcoin network has limited transaction throughput and increased fees during peak demand. NFTs could make network transactions harder and more expensive. Ordinals currently occupy over 50% of block space, according to Glassnode.
One of the protocols that supported Ordinals Taproot has also seen a huge uptick:
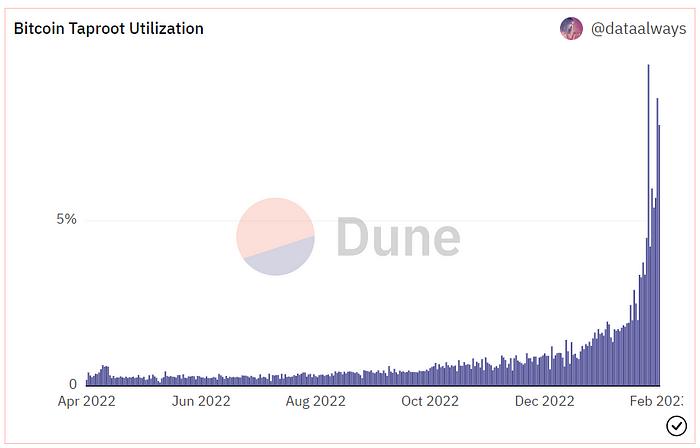
Taproot use increases block size and transaction costs.

This could cause network congestion but also support more L2s with Ordinals-specific use cases. Dune info here.
Storage Needs The Bitcoin blockchain would need to store more data to store NFT data directly. Since ordinals were introduced, blocksize has tripled from 0.7mb to over 2.2mb, which could increase storage costs and make it harder for nodes to join the network.
Use Case Diversity On the other hand, NFTs on the Bitcoin blockchain could broaden Bitcoin's use cases beyond storage and payment. This could expand Bitcoin's user base. This is two-sided. Bitcoin was designed to be trustless, decentralized, peer-to-peer money.
Chain to permanently store NFTs as ordinals will change everything.
Popularity rise This new use case will boost Bitcoin appeal, according to some. This argument fails since Bitcoin is the most popular cryptocurrency. Popularity doesn't require a new use case. Cryptocurrency adoption boosts Bitcoin. It need not compete with Ethereum or provide extra benefits to crypto investors. If there was a need for another chain that supports NFTs (there isn't), why would anyone choose the slowest and most expensive network? It appears contradictory and unproductive.
Nonetheless, holding an NFT on the Bitcoin blockchain is more secure than any other blockchain, but this has little utility.
Bitcoin NFTs are undoubtedly controversial. NFTs are strange and perhaps harmful to Bitcoin's mission. If Bitcoin NFTs are here to stay, I hope a sidechain or rollup solution will take over and leave the base chain alone.
Dmytro Spilka
3 years ago
Why NFTs Have a Bright Future Away from Collectible Art After Punks and Apes

After a crazy second half of 2021 and significant trade volumes into 2022, the market for NFT artworks like Bored Ape Yacht Club, CryptoPunks, and Pudgy Penguins has begun a sharp collapse as market downturns hit token values.
DappRadar data shows NFT monthly sales have fallen below $1 billion since June 2021. OpenSea, the world's largest NFT exchange, has seen sales volume decline 75% since May and is trading like July 2021.
Prices of popular non-fungible tokens have also decreased. Bored Ape Yacht Club (BAYC) has witnessed volume and sales drop 63% and 15%, respectively, in the past month.
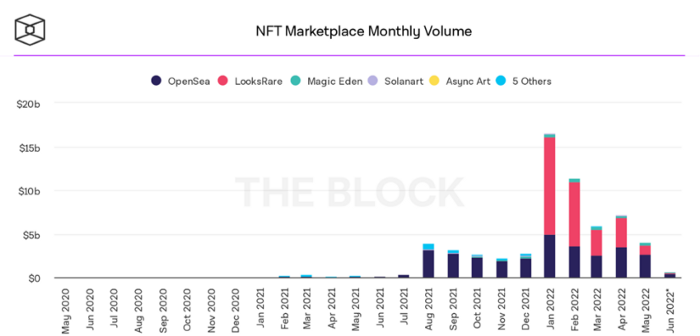
BeInCrypto analysis shows market decline. May 2022 cryptocurrency marketplace volume was $4 billion, according to a news platform. This is a sharp drop from April's $7.18 billion.
OpenSea, a big marketplace, contributed $2.6 billion, while LooksRare, Magic Eden, and Solanart also contributed.
NFT markets are digital platforms for buying and selling tokens, similar stock trading platforms. Although some of the world's largest exchanges offer NFT wallets, most users store their NFTs on their favorite marketplaces.
In January 2022, overall NFT sales volume was $16.57 billion, with LooksRare contributing $11.1 billion. May 2022's volume was $12.57 less than January, a 75% drop, and June's is expected to be considerably smaller.
A World Based on Utility
Despite declines in NFT trading volumes, not all investors are negative on NFTs. Although there are uncertainties about the sustainability of NFT-based art collections, there are fewer reservations about utility-based tokens and their significance in technology's future.
In June, business CEO Christof Straub said NFTs may help artists monetize unreleased content, resuscitate catalogs, establish deeper fan connections, and make processes more efficient through technology.
We all know NFTs can't be JPEGs. Straub noted that NFT music rights can offer more equitable rewards to musicians.
Music NFTs are here to stay if they have real value, solve real problems, are trusted and lawful, and have fair and sustainable business models.
NFTs can transform numerous industries, including music. Market opinion is shifting towards tokens with more utility than the social media artworks we're used to seeing.
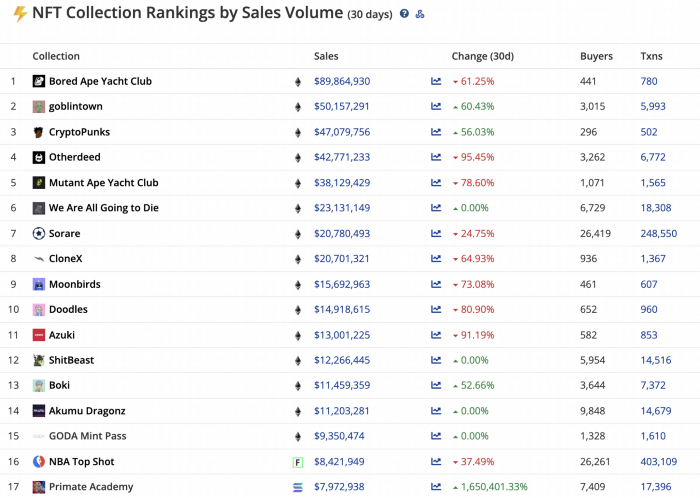
While the major NFT names remain dominant in terms of volume, new utility-based initiatives are emerging as top 20 collections.
Otherdeed, Sorare, and NBA Top Shot are NFT-based games that rank above Bored Ape Yacht Club and Cryptopunks.
Users can switch video NFTs of basketball players in NBA Top Shot. Similar efforts are emerging in the non-fungible landscape.
Sorare shows how NFTs can support a new way of playing fantasy football, where participants buy and swap trading cards to create a 5-player team that wins rewards based on real-life performances.
Sorare raised 579.7 million in one of Europe's largest Series B financing deals in September 2021. Recently, the platform revealed plans to expand into Major League Baseball.
Strong growth indications suggest a promising future for NFTs. The value of art-based collections like BAYC and CryptoPunks may be questioned as markets become diluted by new limited collections, but the potential for NFTs to become intrinsically linked to tangible utility like online gaming, music and art, and even corporate reward schemes shows the industry has a bright future.

Jennifer Tieu
3 years ago
Why I Love Azuki
Azuki Banner (www.azuki.com)
Disclaimer: This is my personal viewpoint. I'm not on the Azuki team. Please keep in mind that I am merely a fan, community member, and holder. Please do your own research and pardon my grammar. Thanks!
Azuki has changed my view of NFTs.
When I first entered the NFT world, I had no idea what to expect. I liked the idea. So I invested in some projects, fought for whitelists, and discovered some cool NFTs projects (shout-out to CATC). I lost more money than I earned at one point, but I hadn't invested excessively (only put in what you can afford to lose). Despite my losses, I kept looking. I almost waited for the “ah-ha” moment. A NFT project that changed my perspective on NFTs. What makes an NFT project more than a work of art?
Answer: Azuki.
The Art
The Azuki art drew me in as an anime fan. It looked like something out of an anime, and I'd never seen it before in NFT.
The project was still new. The first two animated teasers were released with little fanfare, but I was impressed with their quality. You can find them on Instagram or in their earlier Tweets.
The teasers hinted that this project could be big and that the team could deliver. It was amazing to see Shao cut the Azuki posters with her katana. Especially at the end when she sheaths her sword and the music cues. Then the live action video of the young boy arranging the Azuki posters seemed movie-like. I felt like I was entering the Azuki story, brand, and dope theme.
The team did not disappoint with the Azuki NFTs. The level of detail in the art is stunning. There were Azukis of all genders, skin and hair types, and more. These 10,000 Azukis have so much representation that almost anyone can find something that resonates. Rather than me rambling on, I suggest you visit the Azuki gallery
The Team
If the art is meant to draw you in and be the project's face, the team makes it more. The NFT would be a JPEG without a good team leader. Not that community isn't important, but no community would rally around a bad team.
Because I've been rugged before, I'm very focused on the team when considering a project. While many project teams are anonymous, I try to find ones that are doxxed (public) or at least appear to be established. Unlike Azuki, where most of the Azuki team is anonymous, Steamboy is public. He is (or was) Overwatch's character art director and co-creator of Azuki. I felt reassured and could trust the project after seeing someone from a major game series on the team.
Then I tried to learn as much as I could about the team. Following everyone on Twitter, reading their tweets, and listening to recorded AMAs. I was impressed by the team's professionalism and dedication to their vision for Azuki, led by ZZZAGABOND.
I believe the phrase “actions speak louder than words” applies to Azuki. I can think of a few examples of what the Azuki team has done, but my favorite is ERC721A.
With ERC721A, Azuki has created a new algorithm that allows minting multiple NFTs for essentially the same cost as minting one NFT.
I was ecstatic when the dev team announced it. This fascinates me as a self-taught developer. Azuki released a product that saves people money, improves the NFT space, and is open source. It showed their love for Azuki and the NFT community.
The Community
Community, community, community. It's almost a chant in the NFT space now. A community, like a team, can make or break a project. We are the project's consumers, shareholders, core, and lifeblood. The team builds the house, and we fill it. We stay for the community.
When I first entered the Azuki Discord, I was surprised by the calm atmosphere. There was no news about the project. No release date, no whitelisting requirements. No grinding or spamming either. People just wanted to hangout, get to know each other, and talk. It was nice. So the team could pick genuine people for their mintlist (aka whitelist).
But nothing fundamental has changed since the release. It has remained an authentic, fun, and helpful community. I'm constantly logging into Discord to chat with others or follow conversations. I see the community's openness to newcomers. Everyone respects each other (barring a few bad apples) and the variety of people passing through is fascinating. This human connection and interaction is what I enjoy about this place. Being a part of a group that supports a cause.
Finally, I want to thank the amazing Azuki mod team and the kissaten channel for their contributions.
The Brand
So, what sets Azuki apart from other projects? They are shaping a brand or identity. The Azuki website, I believe, best captures their vision. (This is me gushing over the site.)
If you go to the website, turn on the dope playlist in the bottom left. The playlist features a mix of Asian and non-Asian hip-hop and rap artists, with some lo-fi thrown in. The songs on the playlist change, but I think you get the vibe Azuki embodies just by turning on the music.
The Garden is our next stop where we are introduced to Azuki.
A brand.
We're creating a new brand together.
A metaverse brand. By the people.
A collection of 10,000 avatars that grant Garden membership. It starts with exclusive streetwear collabs, NFT drops, live events, and more. Azuki allows for a new media genre that the world has yet to discover. Let's build together an Azuki, your metaverse identity.
The Garden is a magical internet corner where art, community, and culture collide. The boundaries between the physical and digital worlds are blurring.
Try a Red Bean.
The text begins with Azuki's intention in the space. It's a community-made metaverse brand. Then it goes into more detail about Azuki's plans. Initiation of a story or journey. "Would you like to take the red bean and jump down the rabbit hole with us?" I love the Matrix red pill or blue pill play they used. (Azuki in Japanese means red bean.)
Morpheus, the rebel leader, offers Neo the choice of a red or blue pill in The Matrix. “You take the blue pill... After the story, you go back to bed and believe whatever you want. Your red pill... Let me show you how deep the rabbit hole goes.” Aware that the red pill will free him from the enslaving control of the machine-generated dream world and allow him to escape into the real world, he takes it. However, living the “truth of reality” is harsher and more difficult.
It's intriguing and draws you in. Taking the red bean causes what? Where am I going? I think they did well in piqueing a newcomer's interest.
Not convinced by the Garden? Read the Manifesto. It reinforces Azuki's role.
Here comes a new wave…
And surfing here is different.
Breaking down barriers.
Building open communities.
Creating magic internet money with our friends.
To those who don’t get it, we tell them: gm.
They’ll come around eventually.
Here’s to the ones with the courage to jump down a peculiar rabbit hole.
One that pulls you away from a world that’s created by many and owned by few…
To a world that’s created by more and owned by all.
From The Garden come the human beans that sprout into your family.
We rise together.
We build together.
We grow together.
Ready to take the red bean?
Not to mention the Mindmap, it sets Azuki apart from other projects and overused Roadmaps. I like how the team recognizes that the NFT space is not linear. So many of us are still trying to figure it out. It is Azuki's vision to adapt to changing environments while maintaining their values. I admire their commitment to long-term growth.
Conclusion
To be honest, I have no idea what the future holds. Azuki is still new and could fail. But I'm a long-term Azuki fan. I don't care about quick gains. The future looks bright for Azuki. I believe in the team's output. I love being an Azuki.
Thank you! IKUZO!
Full post here
You might also like

Chris Newman
3 years ago
Clean Food: Get Over Yourself If You Want to Save the World.

I’m a permaculture farmer. I want to create food-producing ecosystems. My hope is a world with easy access to a cuisine that nourishes consumers, supports producers, and leaves the Earth joyously habitable.
Permaculturists, natural farmers, plantsmen, and foodies share this ambition. I believe this group of green thumbs, stock-folk, and food champions is falling to tribalism, forgetting that rescuing the globe requires saving all of its inhabitants, even those who adore cheap burgers and Coke. We're digging foxholes and turning folks who disagree with us or don't understand into monsters.
Take Dr. Daphne Miller's comments at the end of her Slow Money Journal interview:
“Americans are going to fall into two camps when all is said and done: People who buy cheap goods, regardless of quality, versus people who are willing and able to pay for things that are made with integrity. We are seeing the limits of the “buying cheap crap” approach.”
This is one of the most judgmental things I've read outside the Bible. Consequences:
People who purchase inexpensive things (food) are ignorant buffoons who prefer to choose fair trade coffee over fuel as long as the price is correct.
It all depends on your WILL to buy quality or cheaply. Both those who are WILLING and those who ARE NOT exist. And able, too.
People who are unwilling and unable are purchasing garbage. You're giving your kids bad food. Both the Earth and you are being destroyed by your actions. Your camp is the wrong one. You’re garbage! Disgrace to you.
Dr. Miller didn't say it, but words are worthless until interpreted. This interpretation depends on the interpreter's economic, racial, political, religious, family, and personal history. Complementary language insults another. Imagine how that Brown/Harvard M.D.'s comment sounds to a low-income household with no savings.

Dr. Miller's comment reflects the echo chamber into which nearly all clean food advocates speak. It asks easy questions and accepts non-solutions like raising food prices and eating less meat. People like me have cultivated an insular world unencumbered by challenges beyond the margins. We may disagree about technical details in rotationally-grazing livestock, but we short circuit when asked how our system could supply half the global beef demand. Most people have never seriously considered this question. We're so loved and affirmed that challenging ourselves doesn't seem necessary. Were generals insisting we don't need to study the terrain because God is on our side?
“Yes, the $8/lb ground beef is produced the way it should be. Yes, it’s good for my body. Yes it’s good for the Earth. But it’s eight freaking dollars, and my kid needs braces and protein. Bye Felicia, we’re going to McDonald’s.”
-Bobby Q. Homemaker
Funny clean foodies. People don't pay enough for food; they should value it more. Turn the concept of buying food with integrity into a wedge and drive it into the heart of America, dividing the willing and unwilling.
We go apeshit if you call our products high-end.
I've heard all sorts of gaslighting to defend a $10/lb pork chop as accessible (things I’ve definitely said in the past):
At Whole Foods, it costs more.
The steak at the supermarket is overly affordable.
Pay me immediately or the doctor gets paid later.
I spoke with Timbercreek Market and Local Food Hub in front of 60 people. We were asked about local food availability.
They came to me last, after my co-panelists gave the same responses I would have given two years before.
I grumbled, "Our food is inaccessible." Nope. It's beyond the wallets of nearly everyone, and it's the biggest problem with sustainable food systems. We're criminally unserious about being leaders in sustainability until we propose solutions beyond economic relativism, wishful thinking, and insisting that vulnerable, distracted people do all the heavy lifting of finding a way to afford our food. And until we talk about solutions, all this preserve the world? False.
The room fell silent as if I'd revealed a terrible secret. Long, thunderous applause followed my other remarks. But I’m probably not getting invited back to any VNRLI events.
I make pricey cuisine. It’s high-end. I have customers who really have to stretch to get it, and they let me know it. They're forgoing other creature comforts to help me make a living and keep the Earth of my grandmothers alive, and they're doing it as an act of love. They believe in us and our work.
I remember it when I'm up to my shoulders in frigid water, when my vehicle stinks of four types of shit, when I come home covered in blood and mud, when I'm hauling water in 100-degree heat, when I'm herding pigs in a rainstorm and dodging lightning bolts to close the chickens. I'm reminded I'm not alone. Their enthusiasm is worth more than money; it helps me make a life and a living. I won't label that gift less than it is to make my meal seem more accessible.
Not everyone can sacrifice.
Let's not pretend we want to go back to peasant fare, despite our nostalgia. Industrial food has leveled what rich and poor eat. How food is cooked will be the largest difference between what you and a billionaire eat. Rich and poor have access to chicken, pork, and beef. You might be shocked how recently that wasn't the case. This abundance, particularly of animal protein, has helped vulnerable individuals.

Industrial food causes environmental damage, chronic disease, and distribution inequities. Clean food promotes non-industrial, artisan farming. This creates a higher-quality, more expensive product than the competition; we respond with aggressive marketing and the "people need to value food more" shtick geared at consumers who can spend the extra money.
The guy who is NOT able is rendered invisible by clean food's elitist marketing, which is bizarre given a.) clean food insists it's trying to save the world, yet b.) MOST PEOPLE IN THE WORLD ARE THAT GUY. No one can help him except feel-good charities. That's crazy.
Also wrong: a foodie telling a kid he can't eat a 99-cent fast food hamburger because it lacks integrity. Telling him how easy it is to save his ducketts and maybe have a grass-fed house burger at the end of the month as a reward, but in the meantime get your protein from canned beans you can't bake because you don't have a stove and, even if you did, your mom works two jobs and moonlights as an Uber driver so she doesn't have time to heat that shitup anyway.
A wealthy person's attitude toward the poor is indecent. It's 18th-century Versailles.

Human rights include access to nutritious food without social or environmental costs. As a food-forest-loving permaculture farmer, I no longer balk at the concept of cultured beef and hydroponics. My food is out of reach for many people, but access to decent food shouldn't be. Cultures and hydroponics could scale to meet the clean food affordability gap without externalities. If technology can deliver great, affordable beef without environmental negative effects, I can't reject it because it's new, unusual, or might endanger my business.
Why is your farm needed if cultured beef and hydroponics can feed the world? Permaculture food forests with trees, perennial plants, and animals are crucial to economically successful environmental protection. No matter how advanced technology gets, we still need clean air, water, soil, greenspace, and food.
Clean Food cultivated in/on live soil, minimally processed, and eaten close to harvest is part of the answer, not THE solution. Clean food advocates must recognize the conflicts at the intersection of environmental, social, and economic sustainability, the disproportionate effects of those conflicts on the poor and lower-middle classes, and the immorality and impracticality of insisting vulnerable people address those conflicts on their own and judging them if they don't.
Our clients, relatives, friends, and communities need an honest assessment of our role in a sustainable future. If we're serious about preserving the world, we owe honesty to non-customers. We owe our goal and sanity to honesty. Future health and happiness of the world left to the average person's pocketbook and long-term moral considerations is a dismal proposition with few parallels.
Let's make soil and grow food. Let the lab folks do their thing. We're all interdependent.

Keagan Stokoe
3 years ago
Generalists Create Startups; Specialists Scale Them
There’s a funny part of ‘Steve Jobs’ by Walter Isaacson where Jobs says that Bill Gates was more a copier than an innovator:
“Bill is basically unimaginative and has never invented anything, which is why I think he’s more comfortable now in philanthropy than technology. He just shamelessly ripped off other people’s ideas….He’d be a broader guy if he had dropped acid once or gone off to an ashram when he was younger.”
Gates lacked flavor. Nobody ever got excited about a Microsoft launch, despite their good products. Jobs had the world's best product taste. Apple vs. Microsoft.
A CEO's core job functions are all driven by taste: recruiting, vision, and company culture all require good taste. Depending on the type of company you want to build, know where you stand between Microsoft and Apple.
How can you improve your product judgment? How to acquire taste?

Test and refine
Product development follows two parallel paths: the ‘customer obsession’ path and the ‘taste and iterate’ path.
The customer obsession path involves solving customer problems. Lean Startup frameworks show you what to build at each step.
Taste-and-iterate doesn't involve the customer. You iterate internally and rely on product leaders' taste and judgment.
Creative Selection by Ken Kocienda explains this method. In Creative Selection, demos are iterated and presented to product leaders. Your boss presents to their boss, and so on up to Steve Jobs. If you have good product taste, you can be a panelist.
The iPhone follows this path. Before seeing an iPhone, consumers couldn't want one. Customer obsession wouldn't have gotten you far because iPhone buyers didn't know they wanted one.
In The Hard Thing About Hard Things, Ben Horowitz writes:
“It turns out that is exactly what product strategy is all about — figuring out the right product is the innovator’s job, not the customer’s job. The customer only knows what she thinks she wants based on her experience with the current product. The innovator can take into account everything that’s possible, but often must go against what she knows to be true. As a result, innovation requires a combination of knowledge, skill, and courage.“
One path solves a problem the customer knows they have, and the other doesn't. Instead of asking a person what they want, observe them and give them something they didn't know they needed.
It's much harder. Apple is the world's most valuable company because it's more valuable. It changes industries permanently.
If you want to build superior products, use the iPhone of your industry.
How to Improve Your Taste
I. Work for a company that has taste.
People with the best taste in products, markets, and people are rewarded for building great companies. Tasteful people know quality even when they can't describe it. Taste isn't writable. It's feel-based.
Moving into a community that's already doing what you want to do may be the best way to develop entrepreneurial taste. Most company-building knowledge is tacit.
Joining a company you want to emulate allows you to learn its inner workings. It reveals internal patterns intuitively. Many successful founders come from successful companies.
Consumption determines taste. Excellence will refine you. This is why restauranteurs visit the world's best restaurants and serious painters visit Paris or New York. Joining a company with good taste is beneficial.
2. Possess a wide range of interests
“Edwin Land of Polaroid talked about the intersection of the humanities and science. I like that intersection. There’s something magical about that place… The reason Apple resonates with people is that there’s a deep current of humanity in our innovation. I think great artists and great engineers are similar, in that they both have a desire to express themselves.” — Steve Jobs
I recently discovered Edwin Land. Jobs modeled much of his career after Land's. It makes sense that Apple was inspired by Land.
A Triumph of Genius: Edwin Land, Polaroid, and the Kodak Patent War notes:
“Land was introverted in person, but supremely confident when he came to his ideas… Alongside his scientific passions, lay knowledge of art, music, and literature. He was a cultured person growing even more so as he got older, and his interests filtered into the ethos of Polaroid.”
Founders' philosophies shape companies. Jobs and Land were invested. It showed in the products their companies made. Different. His obsession was spreading Microsoft software worldwide. Microsoft's success is why their products are bland and boring.
Experience is important. It's probably why startups are built by generalists and scaled by specialists.
Jobs combined design, typography, storytelling, and product taste at Apple. Some of the best original Mac developers were poets and musicians. Edwin Land liked broad-minded people, according to his biography. Physicist-musicians or physicist-photographers.
Da Vinci was a master of art, engineering, architecture, anatomy, and more. He wrote and drew at the same desk. His genius is remembered centuries after his death. Da Vinci's statue would stand at the intersection of humanities and science.
We find incredibly creative people here. Superhumans. Designers, creators, and world-improvers. These are the people we need to navigate technology and lead world-changing companies. Generalists lead.

Sofien Kaabar, CFA
3 years ago
How to Make a Trading Heatmap
Python Heatmap Technical Indicator

Heatmaps provide an instant overview. They can be used with correlations or to predict reactions or confirm the trend in trading. This article covers RSI heatmap creation.
The Market System
Market regime:
Bullish trend: The market tends to make higher highs, which indicates that the overall trend is upward.
Sideways: The market tends to fluctuate while staying within predetermined zones.
Bearish trend: The market has the propensity to make lower lows, indicating that the overall trend is downward.
Most tools detect the trend, but we cannot predict the next state. The best way to solve this problem is to assume the current state will continue and trade any reactions, preferably in the trend.
If the EURUSD is above its moving average and making higher highs, a trend-following strategy would be to wait for dips before buying and assuming the bullish trend will continue.
Indicator of Relative Strength
J. Welles Wilder Jr. introduced the RSI, a popular and versatile technical indicator. Used as a contrarian indicator to exploit extreme reactions. Calculating the default RSI usually involves these steps:
Determine the difference between the closing prices from the prior ones.
Distinguish between the positive and negative net changes.
Create a smoothed moving average for both the absolute values of the positive net changes and the negative net changes.
Take the difference between the smoothed positive and negative changes. The Relative Strength RS will be the name we use to describe this calculation.
To obtain the RSI, use the normalization formula shown below for each time step.
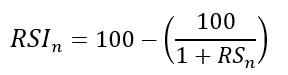
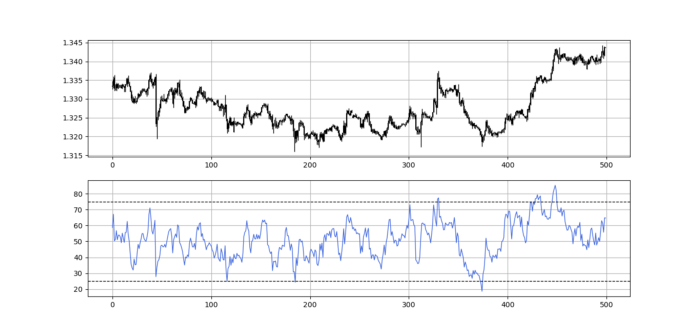
The 13-period RSI and black GBPUSD hourly values are shown above. RSI bounces near 25 and pauses around 75. Python requires a four-column OHLC array for RSI coding.
import numpy as np
def add_column(data, times):
for i in range(1, times + 1):
new = np.zeros((len(data), 1), dtype = float)
data = np.append(data, new, axis = 1)
return data
def delete_column(data, index, times):
for i in range(1, times + 1):
data = np.delete(data, index, axis = 1)
return data
def delete_row(data, number):
data = data[number:, ]
return data
def ma(data, lookback, close, position):
data = add_column(data, 1)
for i in range(len(data)):
try:
data[i, position] = (data[i - lookback + 1:i + 1, close].mean())
except IndexError:
pass
data = delete_row(data, lookback)
return data
def smoothed_ma(data, alpha, lookback, close, position):
lookback = (2 * lookback) - 1
alpha = alpha / (lookback + 1.0)
beta = 1 - alpha
data = ma(data, lookback, close, position)
data[lookback + 1, position] = (data[lookback + 1, close] * alpha) + (data[lookback, position] * beta)
for i in range(lookback + 2, len(data)):
try:
data[i, position] = (data[i, close] * alpha) + (data[i - 1, position] * beta)
except IndexError:
pass
return data
def rsi(data, lookback, close, position):
data = add_column(data, 5)
for i in range(len(data)):
data[i, position] = data[i, close] - data[i - 1, close]
for i in range(len(data)):
if data[i, position] > 0:
data[i, position + 1] = data[i, position]
elif data[i, position] < 0:
data[i, position + 2] = abs(data[i, position])
data = smoothed_ma(data, 2, lookback, position + 1, position + 3)
data = smoothed_ma(data, 2, lookback, position + 2, position + 4)
data[:, position + 5] = data[:, position + 3] / data[:, position + 4]
data[:, position + 6] = (100 - (100 / (1 + data[:, position + 5])))
data = delete_column(data, position, 6)
data = delete_row(data, lookback)
return dataMake sure to focus on the concepts and not the code. You can find the codes of most of my strategies in my books. The most important thing is to comprehend the techniques and strategies.
My weekly market sentiment report uses complex and simple models to understand the current positioning and predict the future direction of several major markets. Check out the report here:
Using the Heatmap to Find the Trend
RSI trend detection is easy but useless. Bullish and bearish regimes are in effect when the RSI is above or below 50, respectively. Tracing a vertical colored line creates the conditions below. How:
When the RSI is higher than 50, a green vertical line is drawn.
When the RSI is lower than 50, a red vertical line is drawn.
Zooming out yields a basic heatmap, as shown below.
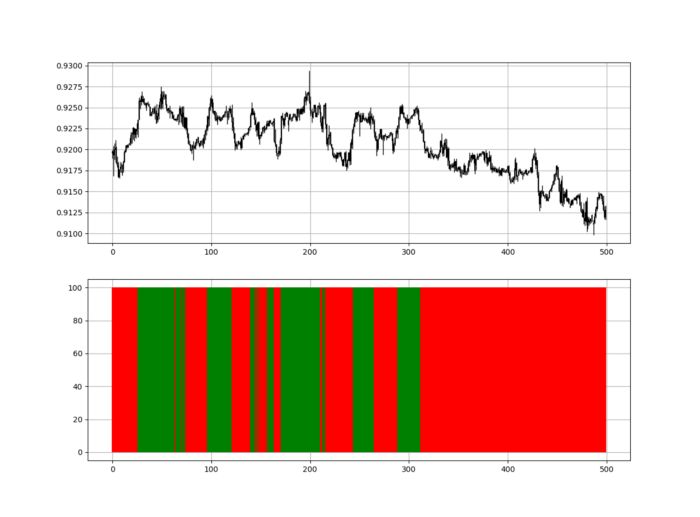
Plot code:
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
if sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)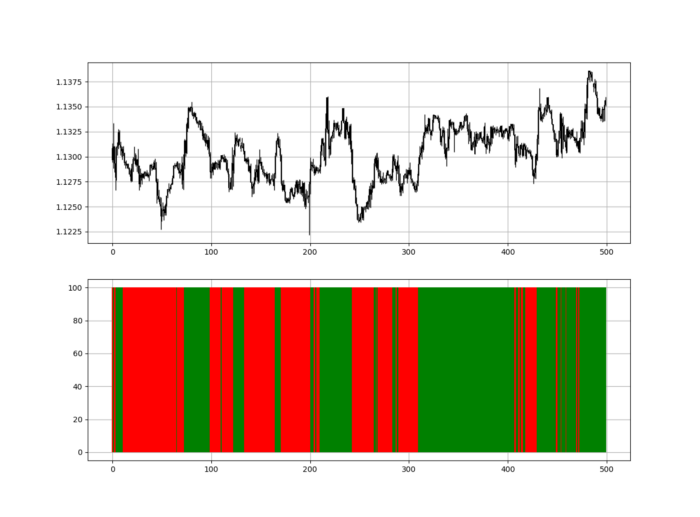
Call RSI on your OHLC array's fifth column. 4. Adjusting lookback parameters reduces lag and false signals. Other indicators and conditions are possible.
Another suggestion is to develop an RSI Heatmap for Extreme Conditions.
Contrarian indicator RSI. The following rules apply:
Whenever the RSI is approaching the upper values, the color approaches red.
The color tends toward green whenever the RSI is getting close to the lower values.
Zooming out yields a basic heatmap, as shown below.
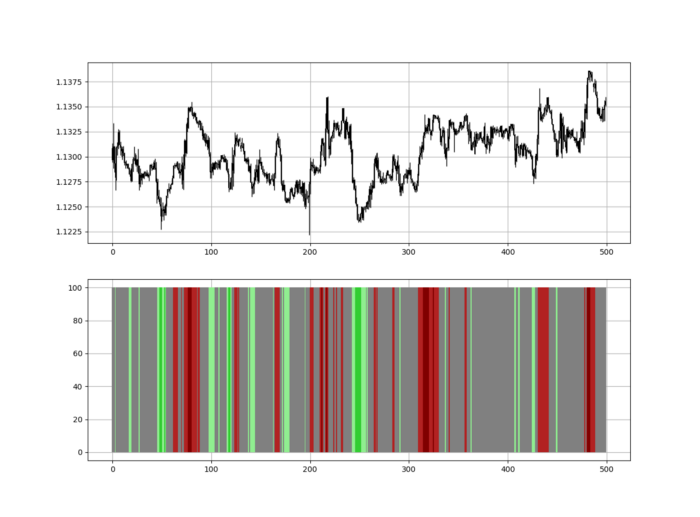
Plot code:
import matplotlib.pyplot as plt
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
if sample[i, second_panel] > 80 and sample[i, second_panel] < 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'darkred', linewidth = 1.5)
if sample[i, second_panel] > 70 and sample[i, second_panel] < 80:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'maroon', linewidth = 1.5)
if sample[i, second_panel] > 60 and sample[i, second_panel] < 70:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'firebrick', linewidth = 1.5)
if sample[i, second_panel] > 50 and sample[i, second_panel] < 60:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 40 and sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 30 and sample[i, second_panel] < 40:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'lightgreen', linewidth = 1.5)
if sample[i, second_panel] > 20 and sample[i, second_panel] < 30:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'limegreen', linewidth = 1.5)
if sample[i, second_panel] > 10 and sample[i, second_panel] < 20:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'seagreen', linewidth = 1.5)
if sample[i, second_panel] > 0 and sample[i, second_panel] < 10:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)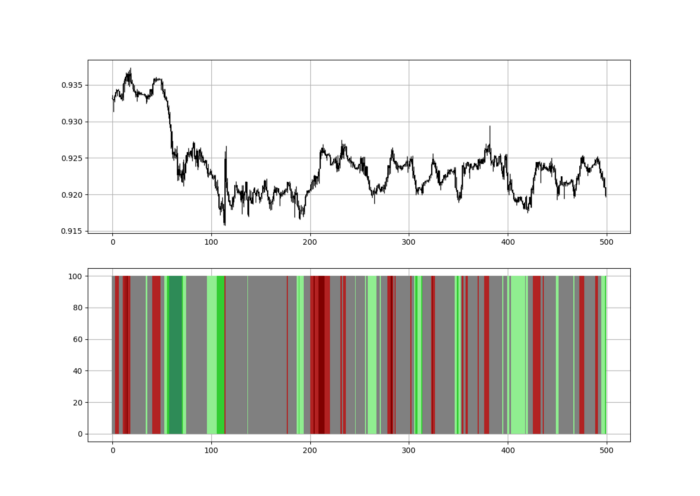
Dark green and red areas indicate imminent bullish and bearish reactions, respectively. RSI around 50 is grey.
Summary
To conclude, my goal is to contribute to objective technical analysis, which promotes more transparent methods and strategies that must be back-tested before implementation.
Technical analysis will lose its reputation as subjective and unscientific.
When you find a trading strategy or technique, follow these steps:
Put emotions aside and adopt a critical mindset.
Test it in the past under conditions and simulations taken from real life.
Try optimizing it and performing a forward test if you find any potential.
Transaction costs and any slippage simulation should always be included in your tests.
Risk management and position sizing should always be considered in your tests.
After checking the above, monitor the strategy because market dynamics may change and make it unprofitable.