

Technology

Paul DelSignore
3 years ago
The stunning new free AI image tool is called Leonardo AI.
Leonardo—The New Midjourney?
Users are comparing the new cowboy to Midjourney.
Leonardo.AI creates great photographs and has several unique capabilities I haven't seen in other AI image systems.
Midjourney's quality photographs are evident in the community feed.

Create Pictures Using Models
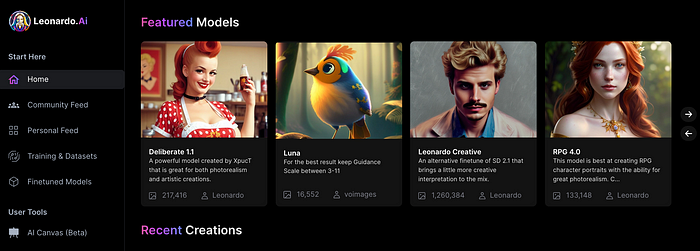
You can make graphics using platform models when you first enter the app (website):
Luma, Leonardo creative, Deliberate 1.1.
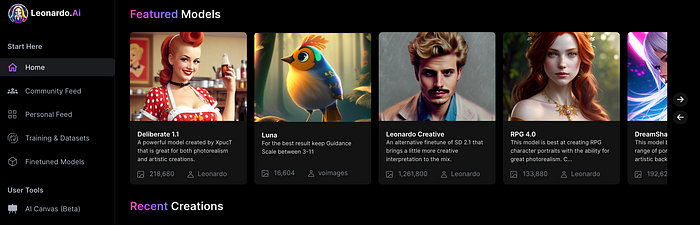
Clicking a model displays its description and samples:
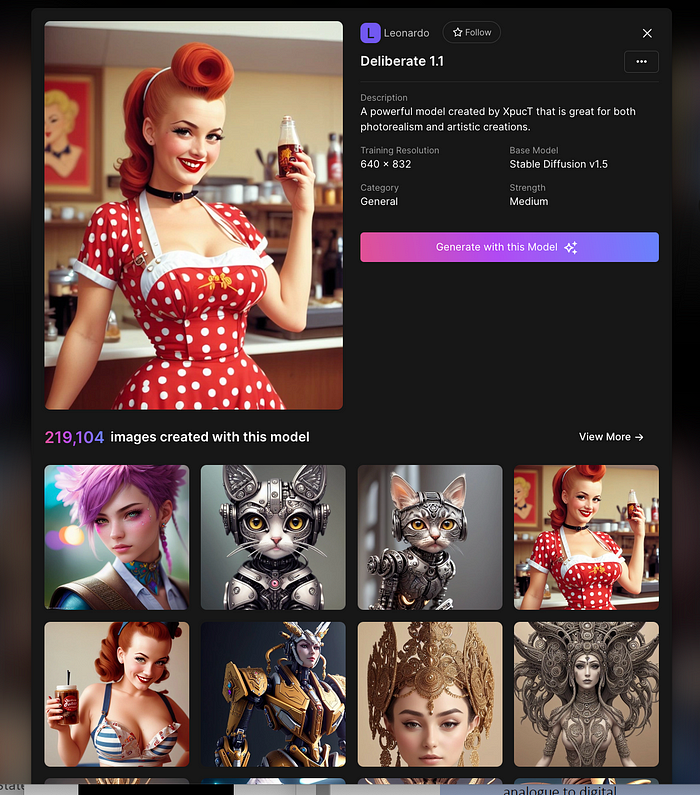
Click Generate With This Model.
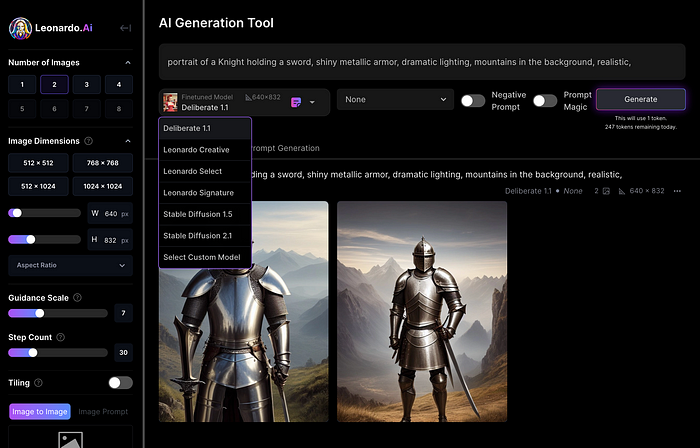
Then you can add your prompt, alter models, photos, sizes, and guide scale in a sleek UI.
Changing Pictures
Leonardo's Canvas editor lets you change created images by hovering over them:

The editor opens with masking, erasing, and picture download.

Develop Your Own Models
I've never seen anything like Leonardo's model training feature.
Upload a handful of similar photographs and save them as a model for future images. Share your model with the community.
You can make photos using your own model and a community-shared set of fine-tuned models:
Obtain Leonardo access
Leonardo is currently free.
Visit Leonardo.ai and click "Get Early Access" to receive access.
Add your email to receive a link to join the discord channel. Simply describe yourself and fill out a form to join the discord channel.
Please go to 👑│introductions to make an introduction and ✨│priority-early-access will be unlocked, you must fill out a form and in 24 hours or a little more (due to demand), the invitation will be sent to you by email.
I got access in two hours, so hopefully you can too.
Last Words
I know there are many AI generative platforms, some free and some expensive, but Midjourney produces the most artistically stunning images and art.
Leonardo is the closest I've seen to Midjourney, but Midjourney is still the leader.
It's free now.
Leonardo's fine-tuned model selections, model creation, image manipulation, and output speed and quality make it a great AI image toolbox addition.

Dmitrii Eliuseev
3 years ago
Creating Images on Your Local PC Using Stable Diffusion AI
Deep learning-based generative art is being researched. As usual, self-learning is better. Some models, like OpenAI's DALL-E 2, require registration and can only be used online, but others can be used locally, which is usually more enjoyable for curious users. I'll demonstrate the Stable Diffusion model's operation on a standard PC.

Let’s get started.
What It Does
Stable Diffusion uses numerous components:
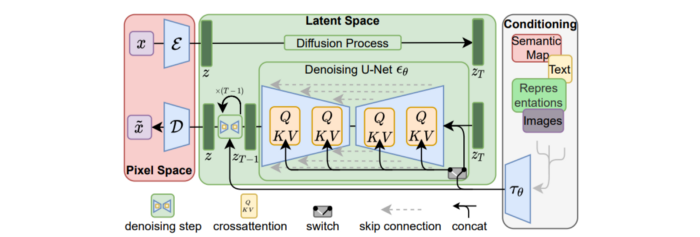
A generative model trained to produce images is called a diffusion model. The model is incrementally improving the starting data, which is only random noise. The model has an image, and while it is being trained, the reversed process is being used to add noise to the image. Being able to reverse this procedure and create images from noise is where the true magic is (more details and samples can be found in the paper).
An internal compressed representation of a latent diffusion model, which may be altered to produce the desired images, is used (more details can be found in the paper). The capacity to fine-tune the generation process is essential because producing pictures at random is not very attractive (as we can see, for instance, in Generative Adversarial Networks).
A neural network model called CLIP (Contrastive Language-Image Pre-training) is used to translate natural language prompts into vector representations. This model, which was trained on 400,000,000 image-text pairs, enables the transformation of a text prompt into a latent space for the diffusion model in the scenario of stable diffusion (more details in that paper).
This figure shows all data flow:
The weights file size for Stable Diffusion model v1 is 4 GB and v2 is 5 GB, making the model quite huge. The v1 model was trained on 256x256 and 512x512 LAION-5B pictures on a 4,000 GPU cluster using over 150.000 NVIDIA A100 GPU hours. The open-source pre-trained model is helpful for us. And we will.
Install
Before utilizing the Python sources for Stable Diffusion v1 on GitHub, we must install Miniconda (assuming Git and Python are already installed):
wget https://repo.anaconda.com/miniconda/Miniconda3-py39_4.12.0-Linux-x86_64.sh
chmod +x Miniconda3-py39_4.12.0-Linux-x86_64.sh
./Miniconda3-py39_4.12.0-Linux-x86_64.sh
conda update -n base -c defaults condaInstall the source and prepare the environment:
git clone https://github.com/CompVis/stable-diffusion
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
pip3 install transformers --upgradeDownload the pre-trained model weights next. HiggingFace has the newest checkpoint sd-v14.ckpt (a download is free but registration is required). Put the file in the project folder and have fun:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Almost. The installation is complete for happy users of current GPUs with 12 GB or more VRAM. RuntimeError: CUDA out of memory will occur otherwise. Two solutions exist.
Running the optimized version
Try optimizing first. After cloning the repository and enabling the environment (as previously), we can run the command:
python3 optimizedSD/optimized_txt2img.py --prompt "hello world" --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Stable Diffusion worked on my visual card with 8 GB RAM (alas, I did not behave well enough to get NVIDIA A100 for Christmas, so 8 GB GPU is the maximum I have;).
Running Stable Diffusion without GPU
If the GPU does not have enough RAM or is not CUDA-compatible, running the code on a CPU will be 20x slower but better than nothing. This unauthorized CPU-only branch from GitHub is easiest to obtain. We may easily edit the source code to use the latest version. It's strange that a pull request for that was made six months ago and still hasn't been approved, as the changes are simple. Readers can finish in 5 minutes:
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available at line 20 of ldm/models/diffusion/ddim.py ().
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available in line 20 of ldm/models/diffusion/plms.py ().
Replace device=cuda in lines 38, 55, 83, and 142 of ldm/modules/encoders/modules.py with device=cuda if torch.cuda.is available(), otherwise cpu.
Replace model.cuda() in scripts/txt2img.py line 28 and scripts/img2img.py line 43 with if torch.cuda.is available(): model.cuda ().
Run the script again.
Testing
Test the model. Text-to-image is the first choice. Test the command line example again:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1The slow generation takes 10 seconds on a GPU and 10 minutes on a CPU. Final image:

Hello world is dull and abstract. Try a brush-wielding hamster. Why? Because we can, and it's not as insane as Napoleon's cat. Another image:

Generating an image from a text prompt and another image is interesting. I made this picture in two minutes using the image editor (sorry, drawing wasn't my strong suit):
I can create an image from this drawing:
python3 scripts/img2img.py --prompt "A bird is sitting on a tree branch" --ckpt sd-v1-4.ckpt --init-img bird.png --strength 0.8It was far better than my initial drawing:

I hope readers understand and experiment.
Stable Diffusion UI
Developers love the command line, but regular users may struggle. Stable Diffusion UI projects simplify image generation and installation. Simple usage:
Unpack the ZIP after downloading it from https://github.com/cmdr2/stable-diffusion-ui/releases. Linux and Windows are compatible with Stable Diffusion UI (sorry for Mac users, but those machines are not well-suitable for heavy machine learning tasks anyway;).
Start the script.
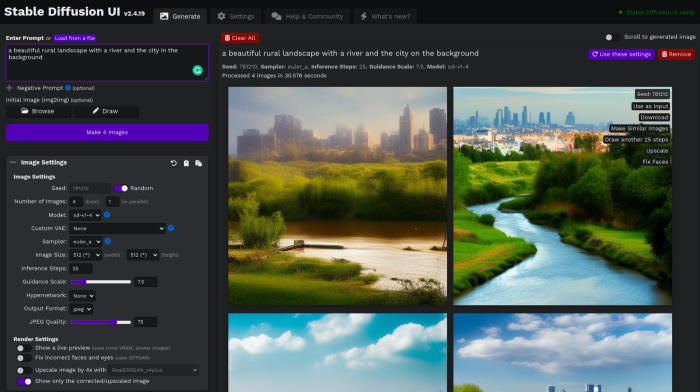
Done. The web browser UI makes configuring various Stable Diffusion features (upscaling, filtering, etc.) easy:
V2.1 of Stable Diffusion
I noticed the notification about releasing version 2.1 while writing this essay, and it was intriguing to test it. First, compare version 2 to version 1:
alternative text encoding. The Contrastive LanguageImage Pre-training (CLIP) deep learning model, which was trained on a significant number of text-image pairs, is used in Stable Diffusion 1. The open-source CLIP implementation used in Stable Diffusion 2 is called OpenCLIP. It is difficult to determine whether there have been any technical advancements or if legal concerns were the main focus. However, because the training datasets for the two text encoders were different, the output results from V1 and V2 will differ for the identical text prompts.
a new depth model that may be used to the output of image-to-image generation.
a revolutionary upscaling technique that can quadruple the resolution of an image.
Generally higher resolution Stable Diffusion 2 has the ability to produce both 512x512 and 768x768 pictures.
The Hugging Face website offers a free online demo of Stable Diffusion 2.1 for code testing. The process is the same as for version 1.4. Download a fresh version and activate the environment:
conda deactivate
conda env remove -n ldm # Use this if version 1 was previously installed
git clone https://github.com/Stability-AI/stablediffusion
cd stablediffusion
conda env create -f environment.yaml
conda activate ldmHugging Face offers a new weights ckpt file.
The Out of memory error prevented me from running this version on my 8 GB GPU. Version 2.1 fails on CPUs with the slow conv2d cpu not implemented for Half error (according to this GitHub issue, the CPU support for this algorithm and data type will not be added). The model can be modified from half to full precision (float16 instead of float32), however it doesn't make sense since v1 runs up to 10 minutes on the CPU and v2.1 should be much slower. The online demo results are visible. The same hamster painting with a brush prompt yielded this result:

It looks different from v1, but it functions and has a higher resolution.
The superresolution.py script can run the 4x Stable Diffusion upscaler locally (the x4-upscaler-ema.ckpt weights file should be in the same folder):
python3 scripts/gradio/superresolution.py configs/stable-diffusion/x4-upscaling.yaml x4-upscaler-ema.ckptThis code allows the web browser UI to select the image to upscale:
The copy-paste strategy may explain why the upscaler needs a text prompt (and the Hugging Face code snippet does not have any text input as well). I got a GPU out of memory error again, although CUDA can be disabled like v1. However, processing an image for more than two hours is unlikely:
Stable Diffusion Limitations
When we use the model, it's fun to see what it can and can't do. Generative models produce abstract visuals but not photorealistic ones. This fundamentally limits The generative neural network was trained on text and image pairs, but humans have a lot of background knowledge about the world. The neural network model knows nothing. If someone asks me to draw a Chinese text, I can draw something that looks like Chinese but is actually gibberish because I never learnt it. Generative AI does too! Humans can learn new languages, but the Stable Diffusion AI model includes only language and image decoder brain components. For instance, the Stable Diffusion model will pull NO WAR banner-bearers like this:
V1:

V2.1:

The shot shows text, although the model never learned to read or write. The model's string tokenizer automatically converts letters to lowercase before generating the image, so typing NO WAR banner or no war banner is the same.
I can also ask the model to draw a gorgeous woman:
V1:

V2.1:

The first image is gorgeous but physically incorrect. A second one is better, although it has an Uncanny valley feel. BTW, v2 has a lifehack to add a negative prompt and define what we don't want on the image. Readers might try adding horrible anatomy to the gorgeous woman request.
If we ask for a cartoon attractive woman, the results are nice, but accuracy doesn't matter:
V1:

V2.1:

Another example: I ordered a model to sketch a mouse, which looks beautiful but has too many legs, ears, and fingers:
V1:

V2.1: improved but not perfect.

V1 produces a fun cartoon flying mouse if I want something more abstract:

I tried multiple times with V2.1 but only received this:

The image is OK, but the first version is closer to the request.
Stable Diffusion struggles to draw letters, fingers, etc. However, abstract images yield interesting outcomes. A rural landscape with a modern metropolis in the background turned out well:
V1:

V2.1:

Generative models help make paintings too (at least, abstract ones). I searched Google Image Search for modern art painting to see works by real artists, and this was the first image:

I typed "abstract oil painting of people dancing" and got this:
V1:

V2.1:

It's a different style, but I don't think the AI-generated graphics are worse than the human-drawn ones.
The AI model cannot think like humans. It thinks nothing. A stable diffusion model is a billion-parameter matrix trained on millions of text-image pairs. I input "robot is creating a picture with a pen" to create an image for this post. Humans understand requests immediately. I tried Stable Diffusion multiple times and got this:

This great artwork has a pen, robot, and sketch, however it was not asked. Maybe it was because the tokenizer deleted is and a words from a statement, but I tried other requests such robot painting picture with pen without success. It's harder to prompt a model than a person.
I hope Stable Diffusion's general effects are evident. Despite its limitations, it can produce beautiful photographs in some settings. Readers who want to use Stable Diffusion results should be warned. Source code examination demonstrates that Stable Diffusion images feature a concealed watermark (text StableDiffusionV1 and SDV2) encoded using the invisible-watermark Python package. It's not a secret, because the official Stable Diffusion repository's test watermark.py file contains a decoding snippet. The put watermark line in the txt2img.py source code can be removed if desired. I didn't discover this watermark on photographs made by the online Hugging Face demo. Maybe I did something incorrectly (but maybe they are just not using the txt2img script on their backend at all).
Conclusion
The Stable Diffusion model was fascinating. As I mentioned before, trying something yourself is always better than taking someone else's word, so I encourage readers to do the same (including this article as well;).
Is Generative AI a game-changer? My humble experience tells me:
I think that place has a lot of potential. For designers and artists, generative AI can be a truly useful and innovative tool. Unfortunately, it can also pose a threat to some of them since if users can enter a text field to obtain a picture or a website logo in a matter of clicks, why would they pay more to a different party? Is it possible right now? unquestionably not yet. Images still have a very poor quality and are erroneous in minute details. And after viewing the image of the stunning woman above, models and fashion photographers may also unwind because it is highly unlikely that AI will replace them in the upcoming years.
Today, generative AI is still in its infancy. Even 768x768 images are considered to be of a high resolution when using neural networks, which are computationally highly expensive. There isn't an AI model that can generate high-resolution photographs natively without upscaling or other methods, at least not as of the time this article was written, but it will happen eventually.
It is still a challenge to accurately represent knowledge in neural networks (information like how many legs a cat has or the year Napoleon was born). Consequently, AI models struggle to create photorealistic photos, at least where little details are important (on the other side, when I searched Google for modern art paintings, the results are often even worse;).
When compared to the carefully chosen images from official web pages or YouTube reviews, the average output quality of a Stable Diffusion generation process is actually less attractive because to its high degree of randomness. When using the same technique on their own, consumers will theoretically only view those images as 1% of the results.
Anyway, it's exciting to witness this area's advancement, especially because the project is open source. Google's Imagen and DALL-E 2 can also produce remarkable findings. It will be interesting to see how they progress.
Monroe Mayfield
3 years ago
CES 2023: A Third Look At Upcoming Trends
Las Vegas hosted CES 2023. This third and last look at CES 2023 previews upcoming consumer electronics trends that will be crucial for market share.

Definitely start with ICT. Qualcomm CEO Cristiano Amon spoke to CNBC from Las Vegas on China's crackdown and the company's automated driving systems for electric vehicles (EV). The business showed a concept car and its latest Snapdragon processor designs, which offer expanded digital interactions through SalesForce-partnered CRM platforms.
Electrification is reviving Michigan's automobile industry. Michigan Local News reports that $14 billion in EV and battery manufacturing investments will benefit the state. The report also revealed that the Strategic Outreach and Attraction Reserve (SOAR) fund had generated roughly $1 billion for the state's automotive sector.
Ars Technica is great for technology, society, and the future. After CES 2023, Jonathan M. Gitlin published How many electric car chargers are enough? Read about EV charging network issues and infrastructure spending. Politics aside, rapid technological advances enable EV charging network expansion in American cities and abroad.
Finally, the UNEP's The Future of Electric Vehicles and Material Resources: A Foresight Brief. Understanding how lithium-ion batteries will affect EV sales is crucial. Climate change affects EVs in various ways, but electrification and mining trends stand out because more EVs demand more energy-intensive metals and rare earths. Areas & Producers has been publishing my electrification and mining trends articles. Follow me if you wish to write for the publication.
The Weekend Brief (TWB) will routinely cover tech, industrials, and global commodities in global markets, including stock markets. Read more about the future of key areas and critical producers of the global economy in Areas & Producers.

Techletters
3 years ago
Using Synthesia, DALL-E 2, and Chat GPT-3, create AI news videos
Combining AIs creates realistic AI News Videos.

Powerful AI tools like Chat GPT-3 are trending. Have you combined AIs?
The 1-minute fake news video below is startlingly realistic. Artificial Intelligence developed NASA's Mars exploration breakthrough video (AI). However, integrating the aforementioned AIs generated it.
AI-generated text for the Chat GPT-3 based on a succinct tagline
DALL-E-2 AI generates an image from a brief slogan.
Artificial intelligence-generated avatar and speech
This article shows how to use and mix the three AIs to make a realistic news video. First, watch the video (1 minute).
Talk GPT-3
Chat GPT-3 is an OpenAI NLP model. It can auto-complete text and produce conversational responses.
Try it at the playground. The AI will write a comprehensive text from a brief tagline. Let's see what the AI generates with "Breakthrough in Mars Project" as the headline.

Amazing. Our tagline matches our complete and realistic text. Fake news can start here.
DALL-E-2
OpenAI's huge transformer-based language model DALL-E-2. Its GPT-3 basis is geared for image generation. It can generate high-quality photos from a brief phrase and create artwork and images of non-existent objects.
DALL-E-2 can create a news video background. We'll use "Breakthrough in Mars project" again. Our AI creates four striking visuals. Last.
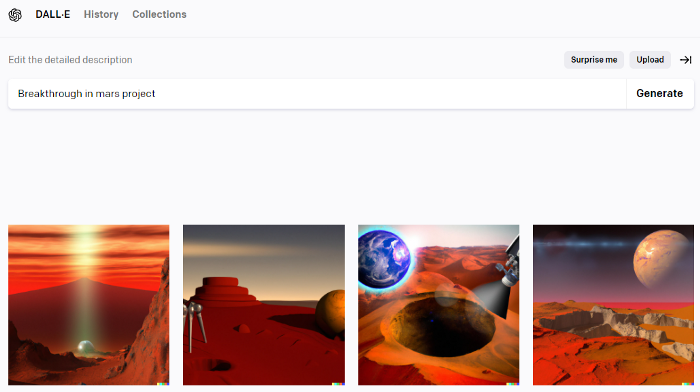
Synthesia
Synthesia lets you quickly produce videos with AI avatars and synthetic vocals.
Avatars are first. Rosie it is.

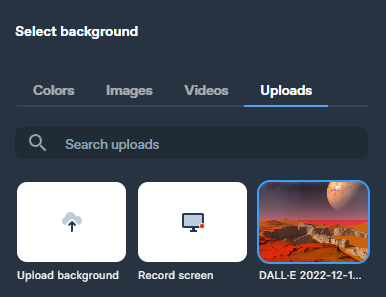
Upload and select DALL-backdrop. E-2's
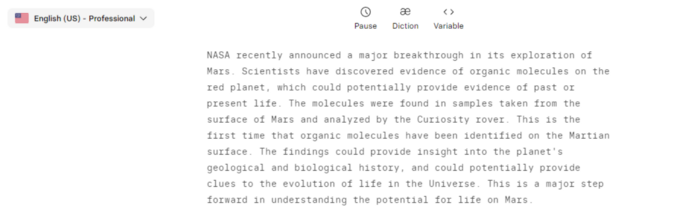
Copy the Chat GPT-3 content and choose a synthetic voice.
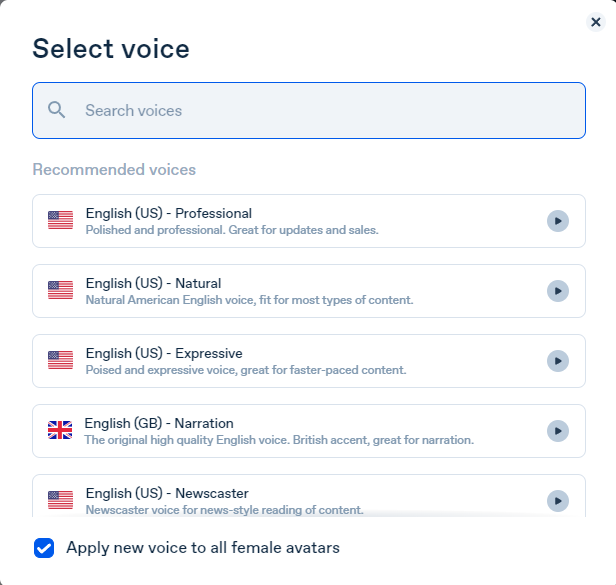
Voice: English (US) Professional.
Finally, we generate and watch or download our video.
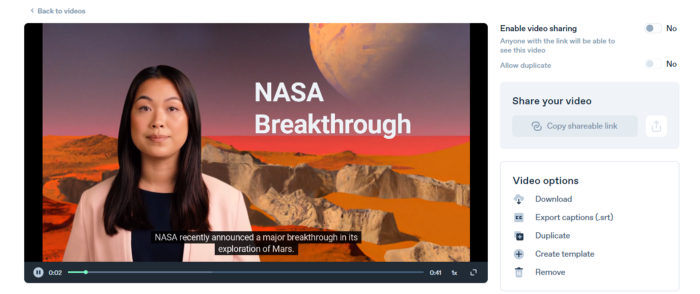
Synthesia AI completes the AI video.
Overview & Resources
We used three AIs to make surprisingly realistic NASA Mars breakthrough fake news in this post. Synthesia generates an avatar and a synthetic voice, therefore it may be four AIs.
These AIs created our fake news.
AI-generated text for the Chat GPT-3 based on a succinct tagline
DALL-E-2 AI generates an image from a brief slogan.
Artificial intelligence-generated avatar and speech

Nick Babich
3 years ago
Is ChatGPT Capable of Generating a Complete Mobile App?

TL;DR: It'll be harder than you think.
Mobile app development is a complicated product design sector. You require broad expertise to create a mobile app. You must write Swift or Java code and consider mobile interactions.
When ChatGPT was released, many were amazed by its capabilities and wondered if it could replace designers and developers. This article will use ChatGPT to answer a specific query.
Can ChatGPT build an entire iOS app?
This post will use ChatGPT to construct an iOS meditation app. Video of the article is available.
App concepts for meditation
After deciding on an app, think about the user experience. What should the app offer?
Let's ask ChatGPT for the answer.
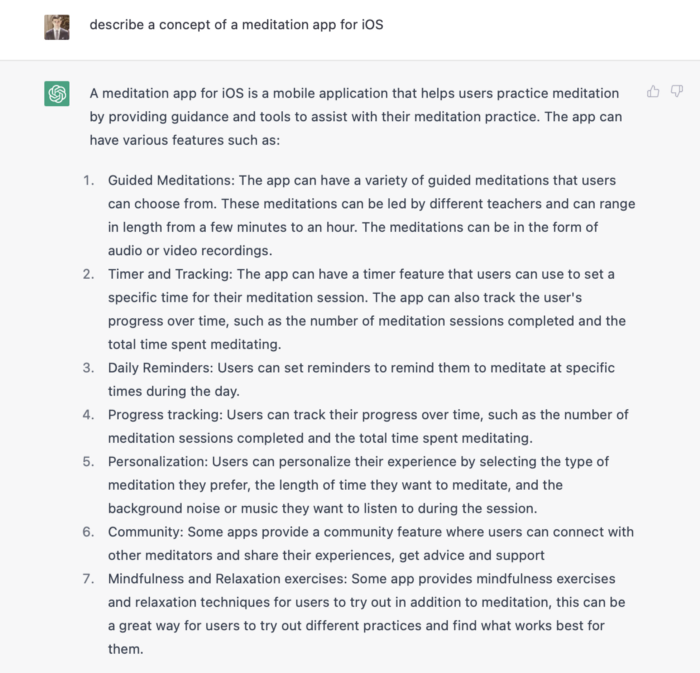
ChatGPT described a solid meditation app with various exercises. Use this list to plan product design. Our first product iteration will have few features. A simple, one-screen software will let users set the timeframe and play music during meditation.
Structure of information
Information architecture underpins product design. Our app's navigation mechanism should be founded on strong information architecture, so we need to identify our mobile's screens first.
ChatGPT can define our future app's information architecture since we already know it.

ChatGPT uses the more complicated product's structure. When adding features to future versions of our product, keep this information picture in mind.
Color palette
Meditation apps need colors. We want to employ relaxing colors in a meditation app because colors affect how we perceive items. ChatGPT can suggest product colors.

See the hues in person:
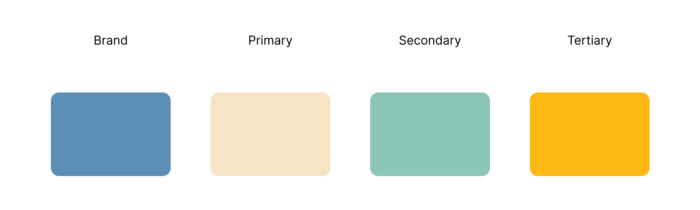
Neutral colors dominate the color scheme. Playing with color opacity makes this scheme useful.
Ambiance music
Meditation involves music. Well-chosen music calms the user.
Let ChatGPT make music for us.
ChatGPT can only generate text. It directs us to Spotify or YouTube to look for such stuff and makes precise recommendations.
Fonts
Fonts can impress app users. Round fonts are easier on the eyes and make a meditation app look friendlier.
ChatGPT can suggest app typefaces. I compare two font pairs when making a product. I'll ask ChatGPT for two font pairs.

See the hues in person:

Despite ChatGPT's convincing font pairing arguments, the output is unattractive. The initial combo (Open Sans + Playfair Display) doesn't seem to work well for a mediation app.
Content
Meditation requires the script. Find the correct words and read them calmly and soothingly to help listeners relax and focus on each region of their body to enhance the exercise's effect.
ChatGPT's offerings:
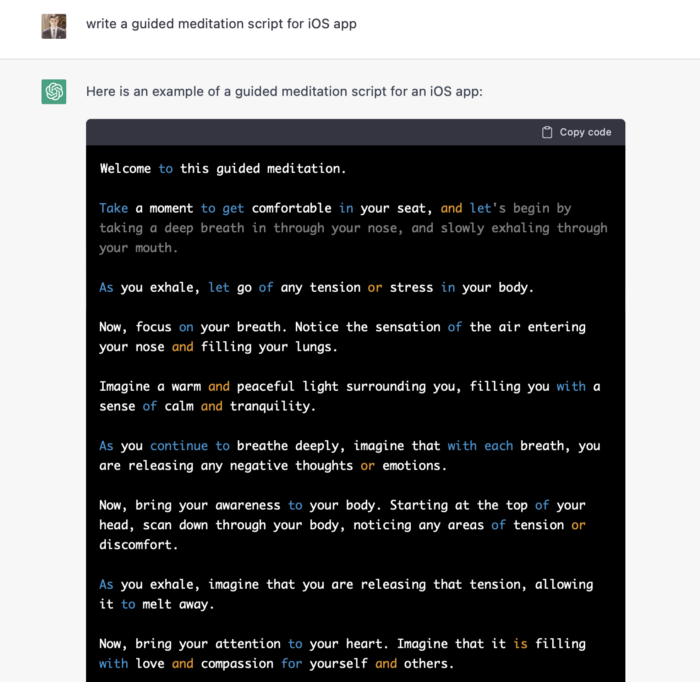
ChatGPT outputs code. My prompt's word script may cause it.
Timer
After fonts, colors, and content, construct functional pieces. Timer is our first functional piece. The meditation will be timed.
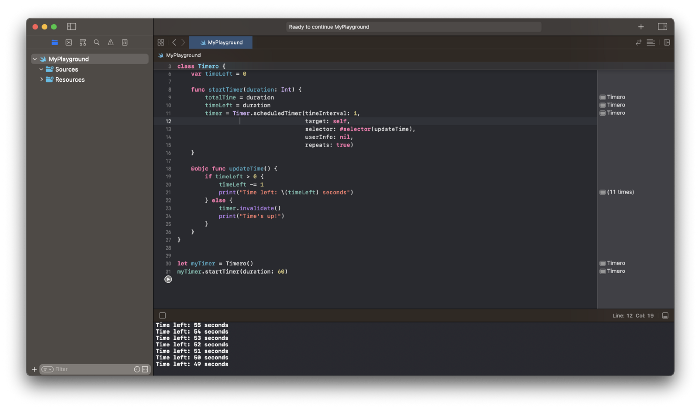
Let ChatGPT write Swift timer code (since were building an iOS app, we need to do it using Swift language).
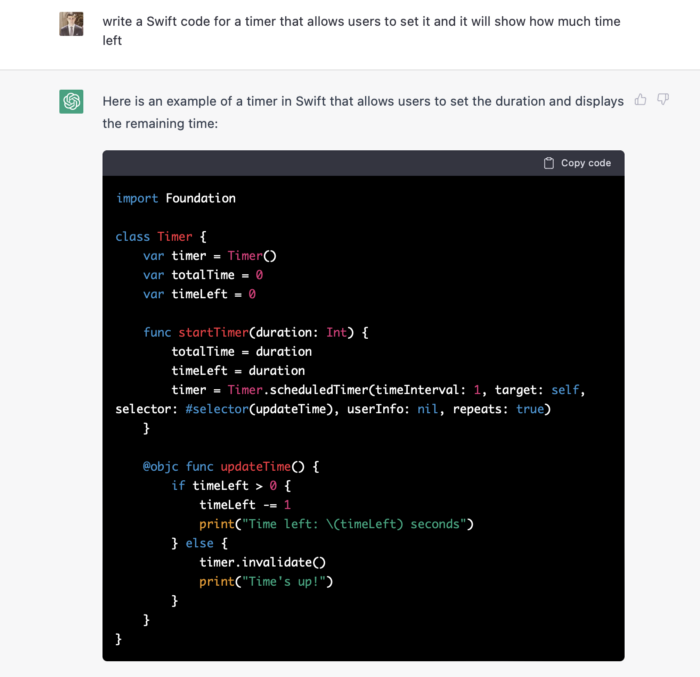
ChatGPT supplied a timer class, initializer, and usage guidelines.

Apple Xcode requires a playground to test this code. Xcode will report issues after we paste the code to the playground.
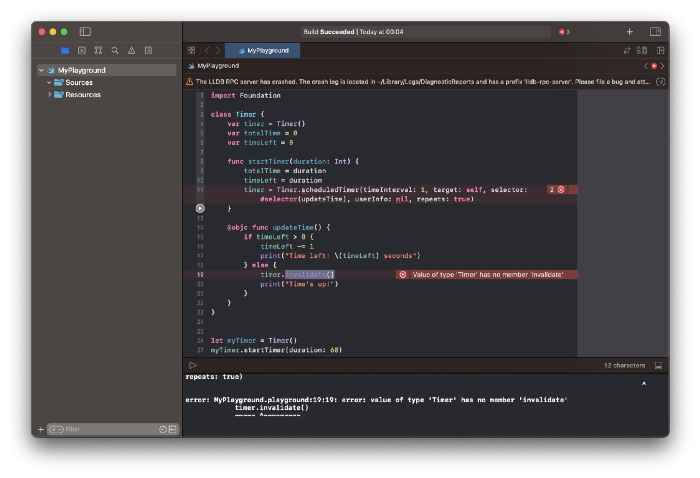
Fixing them is simple. Just change Timer to another class name (Xcode shows errors because it thinks that we access the properties of the class we’ve created rather than the system class Timer; it happens because both classes have the same name Timer). I titled our class Timero and implemented the project. After this quick patch, ChatGPT's code works.
Can ChatGPT produce a complete app?
Since ChatGPT can help us construct app components, we may question if it can write a full app in one go.
Question ChatGPT:
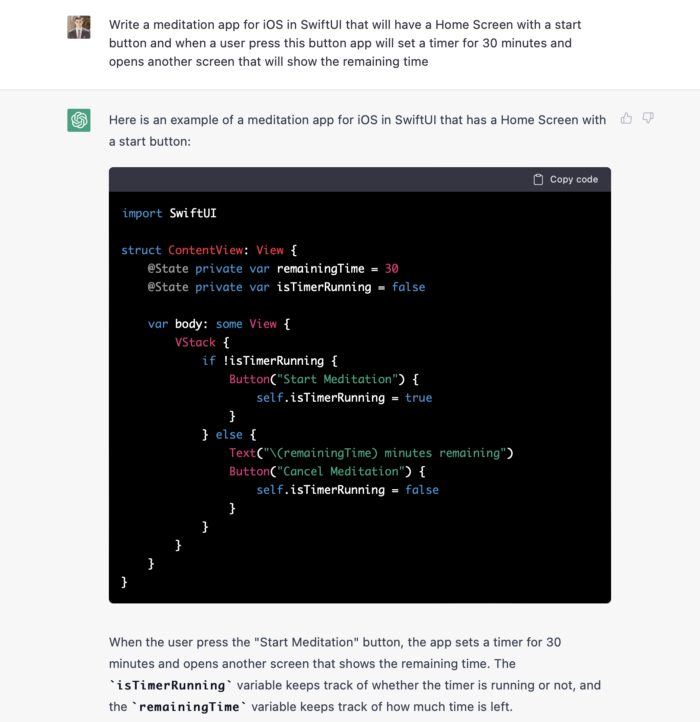
ChatGPT supplied basic code and instructions. It's unclear if ChatGPT purposely limits output or if my prompt wasn't good enough, but the tool cannot produce an entire app from a single prompt.
However, we can contact ChatGPT for thorough Swift app construction instructions.
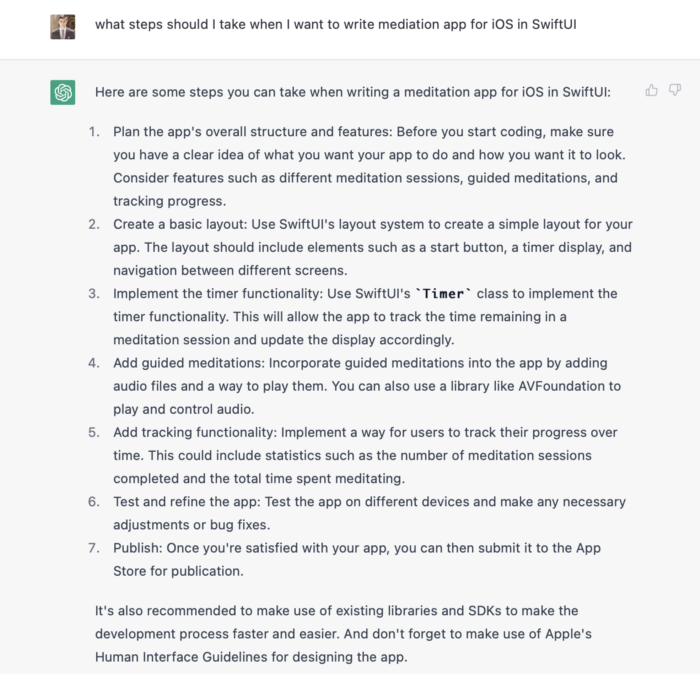
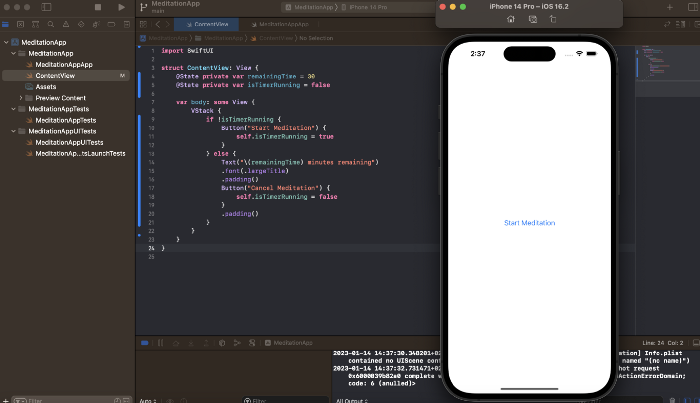
We can ask ChatGPT for step-by-step instructions now that we know what to do. Request a basic app layout from ChatGPT.
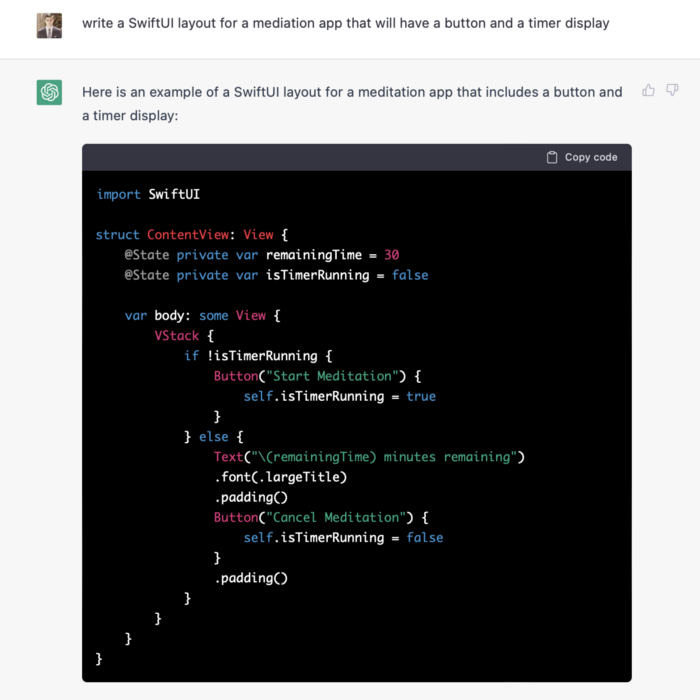
Copying this code to an Xcode project generates a functioning layout.
Takeaways
ChatGPT may provide step-by-step instructions on how to develop an app for a specific system, and individual steps can be utilized as prompts to ChatGPT. ChatGPT cannot generate the source code for the full program in one go.
The output that ChatGPT produces needs to be examined by a human. The majority of the time, you will need to polish or adjust ChatGPT's output, whether you develop a color scheme or a layout for the iOS app.
ChatGPT is unable to produce media material. Although ChatGPT cannot be used to produce images or sounds, it can assist you build prompts for programs like midjourney or Dalle-2 so that they can provide the appropriate images for you.