



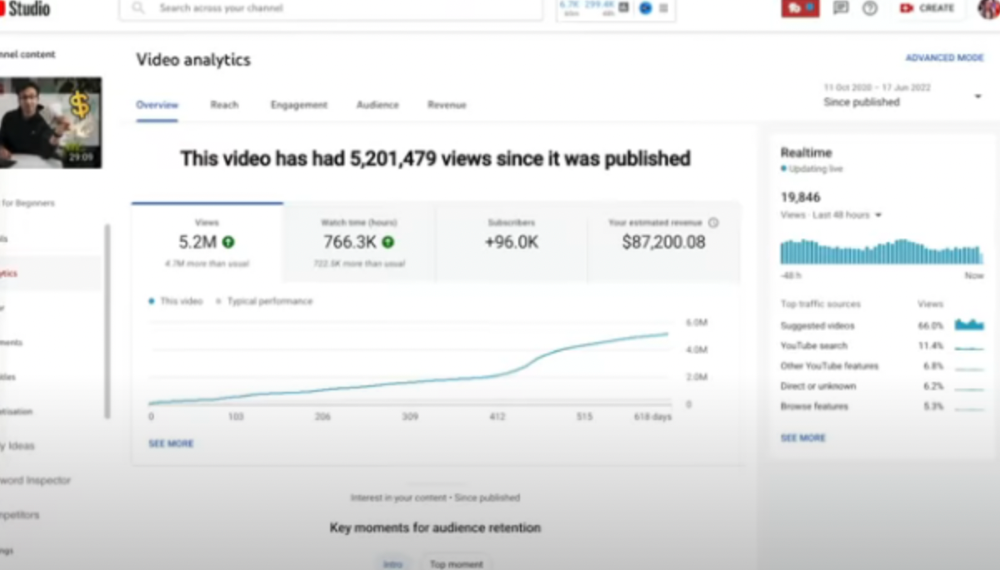
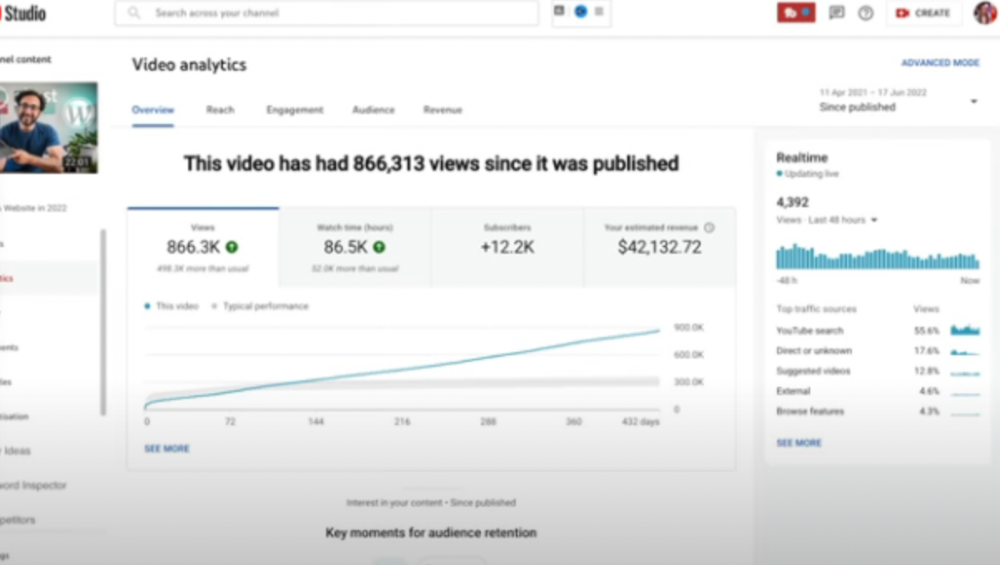

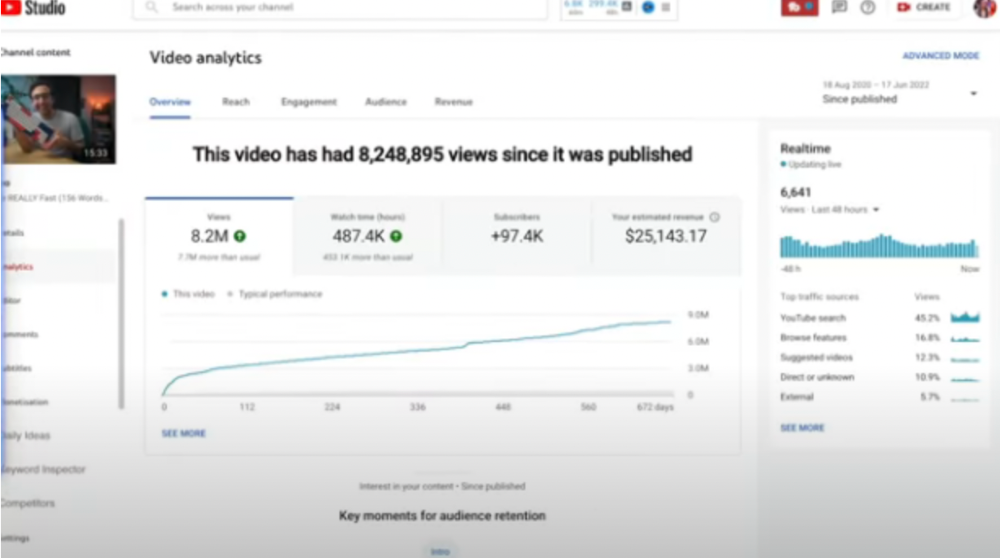





More on Entrepreneurship/Creators

Aaron Dinin, PhD
2 years ago
Are You Unintentionally Creating the Second Difficult Startup Type?
Most don't understand the issue until it's too late.

My first startup was what entrepreneurs call the hardest. A two-sided marketplace.
Two-sided marketplaces are the hardest startups because founders must solve the chicken or the egg conundrum.
A two-sided marketplace needs suppliers and buyers. Without suppliers, buyers won't come. Without buyers, suppliers won't come. An empty marketplace and a founder striving to gain momentum result.
My first venture made me a struggling founder seeking to achieve traction for a two-sided marketplace. The company failed, and I vowed never to start another like it.
I didn’t. Unfortunately, my second venture was almost as hard. It failed like the second-hardest startup.
What kind of startup is the second-hardest?
The second-hardest startup, which is almost as hard to develop, is rarely discussed in the startup community. Because of this, I predict more founders fail each year trying to develop the second-toughest startup than the hardest.
Fairly, I have no proof. I see many startups, so I have enough of firsthand experience. From what I've seen, for every entrepreneur developing a two-sided marketplace, I'll meet at least 10 building this other challenging startup.
I'll describe a startup I just met with its two co-founders to explain the second hardest sort of startup and why it's so hard. They created a financial literacy software for parents of high schoolers.
The issue appears plausible. Children struggle with money. Parents must teach financial responsibility. Problems?
It's possible.
Buyers and users are different.
Buyer-user mismatch.
The financial literacy app I described above targets parents. The parent doesn't utilize the app. Child is end-user. That may not seem like much, but it makes customer and user acquisition and onboarding difficult for founders.
The difficulty of a buyer-user imbalance
The company developing a product faces a substantial operational burden when the buyer and end customer are different. Consider classic firms where the buyer is the end user to appreciate that responsibility.
Entrepreneurs selling directly to end users must educate them about the product's benefits and use. Each demands a lot of time, effort, and resources.
Imagine selling a financial literacy app where the buyer and user are different. To make the first sale, the entrepreneur must establish all the items I mentioned above. After selling, the entrepreneur must supply a fresh set of resources to teach, educate, or train end-users.
Thus, a startup with a buyer-user mismatch must market, sell, and train two organizations at once, requiring twice the work with the same resources.
The second hardest startup is hard for reasons other than the chicken-or-the-egg conundrum. It takes a lot of creativity and luck to solve the chicken-or-egg conundrum.
The buyer-user mismatch problem cannot be overcome by innovation or luck. Buyer-user mismatches must be solved by force. Simply said, when a product buyer is different from an end-user, founders have a lot more work. If they can't work extra, their companies fail.

Alex Mathers
3 years ago
400 articles later, nobody bothered to read them.
Writing for readers:
14 years of daily writing.
I post practically everything on social media. I authored hundreds of articles, thousands of tweets, and numerous volumes to almost no one.
Tens of thousands of readers regularly praise me.
I despised writing. I'm stuck now.
I've learned what readers like and what doesn't.
Here are some essential guidelines for writing with impact:
Readers won't understand your work if you can't.
Though obvious, this slipped me up. Share your truths.
Stories engage human brains.
Showing the journey of a person from worm to butterfly inspires the human spirit.
Overthinking hinders powerful writing.
The best ideas come from inner understanding in between thoughts.
Avoid writing to find it. Write.
Writing a masterpiece isn't motivating.
Write for five minutes to simplify. Step-by-step, entertaining, easy steps.
Good writing requires a willingness to make mistakes.
So write loads of garbage that you can edit into a good piece.
Courageous writing.
A courageous story will move readers. Personal experience is best.
Go where few dare.
Templates, outlines, and boundaries help.
Limitations enhance writing.
Excellent writing is straightforward and readable, removing all the unnecessary fat.
Use five words instead of nine.
Use ordinary words instead of uncommon ones.
Readers desire relatability.
Too much perfection will turn it off.
Write to solve an issue if you can't think of anything to write.
Instead, read to inspire. Best authors read.
Every tweet, thread, and novel must have a central idea.
What's its point?
This can make writing confusing.
️ Don't direct your reader.
Readers quit reading. Demonstrate, describe, and relate.
Even if no one responds, have fun. If you hate writing it, the reader will too.

Rachel Greenberg
3 years ago
The Unsettling Fact VC-Backed Entrepreneurs Don't Want You to Know
What they'll do is scarier.

My acquaintance recently joined a VC-funded startup. Money, equity, and upside possibilities were nice, but he had a nagging dread.
They just secured a $40M round and are hiring like crazy to prepare for their IPO in two years. All signals pointed to this startup's (a B2B IT business in a stable industry) success, and its equity-holding workers wouldn't pass that up.
Five months after starting the work, my friend struggled with leaving. We might overlook the awful culture and long hours at the proper price. This price plus the company's fate and survival abilities sent my friend departing in an unpleasant unplanned resignation before jumping on yet another sinking ship.
This affects founders. This affects VC-backed companies (and all businesses). This affects anyone starting, buying, or running a business.
Here's the under-the-table approach that's draining VC capital, leaving staff terrified (or jobless), founders rattled, and investors upset. How to recognize, solve, and avoid it
The unsettling reality behind door #1
You can't raise money off just your looks, right? If "looks" means your founding team's expertise, then maybe. In my friend's case, the founding team's strong qualifications and track records won over investors before talking figures.
They're hardly the only startup to raise money without a profitable customer acquisition strategy. Another firm raised money for an expensive sleep product because it's eco-friendly. They were off to the races with a few keywords and key players.
Both companies, along with numerous others, elected to invest on product development first. Company A employed all the tech, then courted half their market (they’re a tech marketplace that connects two parties). Company B spent millions on R&D to create a palatable product, then flooded the world with marketing.
My friend is on Company B's financial team, and he's seen where they've gone wrong. It's terrible.
Company A (tech market): Growing? Not quite. To achieve the ambitious expansion they (and their investors) demand, they've poured much of their little capital into salespeople: Cold-calling commission and salary salesmen. Is it working? Considering attrition and companies' dwindling capital, I don't think so.
Company B (green sleep) has been hiring, digital marketing, and opening new stores like crazy. Growing expenses should result in growing revenues and a favorable return on investment; if you grow too rapidly, you may neglect to check that ROI.
Once Company A cut headcount and Company B declared “going concerned”, my friend realized both startups had the same ailment and didn't recognize it.
I shouldn't have to ask a friend to verify a company's cash reserves and profitability to spot a financial problem. It happened anyhow.
The frightening part isn't that investors were willing to invest millions without product-market fit, CAC, or LTV estimates. That's alarming, but not as scary as the fact that startups aren't understanding the problem until VC rounds have dried up.
When they question consultants if their company will be around in 6 months. It’s a red flag. How will they stretch $20M through a 2-year recession with a $3M/month burn rate and no profitability? Alarms go off.
Who's in danger?
In a word, everyone who raised money without a profitable client acquisition strategy or enough resources to ride out dry spells.
Money mismanagement and poor priorities affect every industry (like sinking all your capital into your product, team, or tech, at the expense of probing what customer acquisition really takes and looks like).
This isn't about tech, real estate, or recession-proof luxury products. Fast, cheap, easy money flows into flashy-looking teams with buzzwords, trending industries, and attractive credentials.
If these companies can't show progress or get a profitable CAC, they can't raise more money. They die if they can't raise more money (or slash headcount and find shoestring budget solutions until they solve the real problem).
The kiss of death (and how to avoid it)
If you're running a startup and think raising VC is the answer, pause and evaluate. Do you need the money now?
I'm not saying VC is terrible or has no role. Founders have used it as a Band-Aid for larger, pervasive problems. Venture cash isn't a crutch for recruiting consumers profitably; it's rocket fuel to get you what and who you need.
Pay-to-play isn't a way to throw money at the wall and hope for a return. Pay-to-play works until you run out of money, and if you haven't mastered client acquisition, your cash will diminish quickly.
How can you avoid this bottomless pit? Tips:
Understand your burn rate
Keep an eye on your growth or profitability.
Analyze each and every marketing channel and initiative.
Make lucrative customer acquisition strategies and satisfied customers your top two priorities. not brand-new products. not stellar hires. avoid the fundraising rollercoaster to save time. If you succeed in these two tasks, investors will approach you with their thirsty offers rather than the other way around, and your cash reserves won't diminish as a result.
Not as much as your grandfather
My family friend always justified expensive, impractical expenditures by saying it was only monopoly money. In business, startups, and especially with money from investors expecting a return, that's not true.
More founders could understand that there isn't always another round if they viewed VC money as their own limited pool. When the well runs dry, you must refill it or save the day.
Venture financing isn't your grandpa's money. A discerning investor has entrusted you with dry powder in the hope that you'll use it wisely, strategically, and thoughtfully. Use it well.
You might also like

Taher Batterywala
3 years ago
Do You Have Focus Issues? Use These 5 Simple Habits

Many can't concentrate. The first 20% of the day isn't optimized.
Elon Musk, Tony Robbins, and Bill Gates share something:
Morning Routines.
A repeatable morning ritual saves time.
The result?
Time for hobbies.
I'll discuss 5 easy morning routines you can use.
1. Stop pressing snooze
Waking up starts the day. You disrupt your routine by hitting snooze.
One sleep becomes three. Your morning routine gets derailed.
Fix it:
Hide your phone. This disables snooze and wakes you up.
Once awake, staying awake is 10x easier. Simple trick, big results.
2. Drink water
Chronic dehydration is common. Mostly urban, air-conditioned workers/residents.
2% cerebral dehydration causes short-term memory loss.
Dehydration shrinks brain cells.
Drink 3-4 liters of water daily to avoid this.
3. Improve your focus
How to focus better?
Meditation.
Improve your mood
Enhance your memory
increase mental clarity
Reduce blood pressure and stress
Headspace helps with the habit.
Here's a meditation guide.
Sit comfortably
Shut your eyes.
Concentrate on your breathing
Breathe in through your nose
Breathe out your mouth.
5 in, 5 out.
Repeat for 1 to 20 minutes.
Here's a beginner's video:
4. Workout
Exercise raises:
Mental Health
Effort levels
focus and memory
15-60 minutes of fun:
Exercise Lifting
Running
Walking
Stretching and yoga
This helps you now and later.
5. Keep a journal
You have countless thoughts daily. Many quietly steal your focus.
Here’s how to clear these:
Write for 5-10 minutes.
You'll gain 2x more mental clarity.
Recap
5 morning practices for 5x more productivity:
Say no to snoozing
Hydrate
Improve your focus
Exercise
Journaling
Conclusion
One step starts a thousand-mile journey. Try these easy yet effective behaviors if you have trouble concentrating or have too many thoughts.
Start with one of these behaviors, then add the others. Its astonishing results are instant.

Jari Roomer
3 years ago
10 Alternatives to Smartphone Scrolling
"Don't let technology control you; manage your phone."
"Don't become a slave to technology," said Richard Branson. "Manage your phone, don't let it manage you."
Unfortunately, most people are addicted to smartphones.
Worrying smartphone statistics:
46% of smartphone users spend 5–6 hours daily on their device.
The average adult spends 3 hours 54 minutes per day on mobile devices.
We check our phones 150–344 times per day (every 4 minutes).
During the pandemic, children's daily smartphone use doubled.
Having a list of productive, healthy, and fulfilling replacement activities is an effective way to reduce smartphone use.
The more you practice these smartphone replacements, the less time you'll waste.
Skills Development
Most people say they 'don't have time' to learn new skills or read more. Lazy justification. The issue isn't time, but time management. Distractions and low-quality entertainment waste hours every day.
The majority of time is spent in low-quality ways, according to Richard Koch, author of The 80/20 Principle.
What if you swapped daily phone scrolling for skill-building?
There are dozens of skills to learn, from high-value skills to make more money to new languages and party tricks.
Learning a new skill will last for years, if not a lifetime, compared to scrolling through your phone.
Watch Docs
Love documentaries. It's educational and relaxing. A good documentary helps you understand the world, broadens your mind, and inspires you to change.
Recent documentaries I liked include:
14 Peaks: Nothing Is Impossible
The Social Dilemma
Jim & Andy: The Great Beyond
Fantastic Fungi
Make money online
If you've ever complained about not earning enough money, put away your phone and get to work.
Instead of passively consuming mobile content, start creating it. Create something worthwhile. Freelance.
Internet makes starting a business or earning extra money easier than ever.
(Grand)parents didn't have this. Someone made them work 40+ hours. Few alternatives existed.
Today, all you need is internet and a monetizable skill. Use the internet instead of letting it distract you. Profit from it.
Bookworm
Jack Canfield, author of Chicken Soup For The Soul, said, "Everyone spends 2–3 hours a day watching TV." If you read that much, you'll be in the top 1% of your field."
Few people have more than two hours per day to read.
If you read 15 pages daily, you'd finish 27 books a year (as the average non-fiction book is about 200 pages).
Jack Canfield's quote remains relevant even though 15 pages can be read in 20–30 minutes per day. Most spend this time watching TV or on their phones.
What if you swapped 20 minutes of mindless scrolling for reading? You'd gain knowledge and skills.
Favorite books include:
The 7 Habits of Highly Effective People — Stephen R. Covey
The War of Art — Steven Pressfield
The Psychology of Money — Morgan Housel
A New Earth — Eckart Tolle
Get Organized
All that screen time could've been spent organizing. It could have been used to clean, cook, or plan your week.
If you're always 'behind,' spend 15 minutes less on your phone to get organized.
"Give me six hours to chop down a tree, and I'll spend the first four sharpening the ax," said Abraham Lincoln. Getting organized is like sharpening an ax, making each day more efficient.
Creativity
Why not be creative instead of consuming others'? Do something creative, like:
Painting
Musically
Photography\sWriting
Do-it-yourself
Construction/repair
Creative projects boost happiness, cognitive functioning, and reduce stress and anxiety. Creative pursuits induce a flow state, a powerful mental state.
This contrasts with smartphones' effects. Heavy smartphone use correlates with stress, depression, and anxiety.
Hike
People spend 90% of their time indoors, according to research. This generation is the 'Indoor Generation'
We lack an active lifestyle, fresh air, and vitamin D3 due to our indoor lifestyle (generated through direct sunlight exposure). Mental and physical health issues result.
Put away your phone and get outside. Go on nature walks. Explore your city on foot (or by bike, as we do in Amsterdam) if you live in a city. Move around! Outdoors!
You can't spend your whole life staring at screens.
Podcasting
Okay, a smartphone is needed to listen to podcasts. When you use your phone to get smarter, you're more productive than 95% of people.
Favorite podcasts:
The Pomp Podcast (about cryptocurrencies)
The Joe Rogan Experience
Kwik Brain (by Jim Kwik)
Podcasts can be enjoyed while walking, cleaning, or doing laundry. Win-win.
Journalize
I find journaling helpful for mental clarity. Writing helps organize thoughts.
Instead of reading internet opinions, comments, and discussions, look inward. Instead of Twitter or TikTok, look inward.
“It never ceases to amaze me: we all love ourselves more than other people, but care more about their opinion than our own.” — Marcus Aurelius
Give your mind free reign with pen and paper. It will highlight important thoughts, emotions, or ideas.
Never write for another person. You want unfiltered writing. So you get the best ideas.
Find your best hobbies
List your best hobbies. I guarantee 95% of people won't list smartphone scrolling.
It's often low-quality entertainment. The dopamine spike is short-lived, and it leaves us feeling emotionally 'empty'
High-quality leisure sparks happiness. They make us happy and alive. Everyone has different interests, so these activities vary.
My favorite quality hobbies are:
Nature walks (especially the mountains)
Video game party
Watching a film with my girlfriend
Gym weightlifting
Complexity learning (such as the blockchain and the universe)
This brings me joy. They make me feel more fulfilled and 'rich' than social media scrolling.
Make a list of your best hobbies to refer to when you're spending too much time on your phone.

Jano le Roux
3 years ago
Never Heard Of: The Apple Of Email Marketing Tools
Unlimited everything for $19 monthly!?
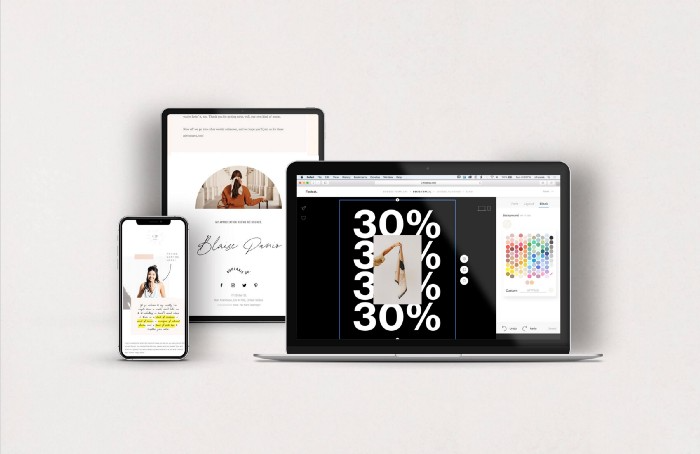
Even with pretty words, no one wants to read an ugly email.
Not Gen Z
Not Millennials
Not Gen X
Not Boomers
I am a minimalist.
I like Mozart. I like avos. I love Apple.
When I hear seamlessly, effortlessly, or Apple's new adverb fluidly, my toes curl.
No email marketing tool gave me that feeling.
As a marketing consultant helping high-growth brands create marketing that doesn't feel like marketing, I've worked with every email marketing platform imaginable, including that naughty monkey and the expensive platform whose sales teams don't stop calling.
Most email marketing platforms are flawed.
They are overpriced.
They use dreadful templates.
They employ a poor visual designer.
The user experience there is awful.
Too many useless buttons are present. (Similar to the TV remote!)
I may have finally found the perfect email marketing tool. It creates strong flows. It helps me focus on storytelling.
It’s called Flodesk.
It’s effortless. It’s seamless. It’s fluid.
Here’s why it excites me.
Unlimited everything for $19 per month
Sends unlimited. Emails unlimited. Signups unlimited.
Most email platforms penalize success.
Pay for performance?
$87 for 10k contacts
$605 for 100K contacts
$1,300+ for 200K contacts
In the 1990s, this made sense, but not now. It reminds me of when ISPs capped internet usage at 5 GB per month.
Flodesk made unlimited email for a low price a reality. Affordable, attractive email marketing isn't just for big companies.
Flodesk doesn't penalize you for growing your list. Price stays the same as lists grow.
Flodesk plans cost $38 per month, but I'll give you a 30-day trial for $19.
Amazingly strong flows
Foster different people's flows.
Email marketing isn't one-size-fits-all.
Different times require different emails.
People don't open emails because they're irrelevant, in my experience. A colder audience needs a nurturing sequence.
Flodesk automates your email funnels so top-funnel prospects fall in love with your brand and values before mid- and bottom-funnel email flows nudge them to take action.
I wish I could save more custom audience fields to further customize the experience.
Dynamic editor
Easy. Effortless.
Flodesk's editor is Apple-like.
You understand how it works almost instantly.
Like many Apple products, it's intentionally limited. No distractions. You can focus on emotional email writing.
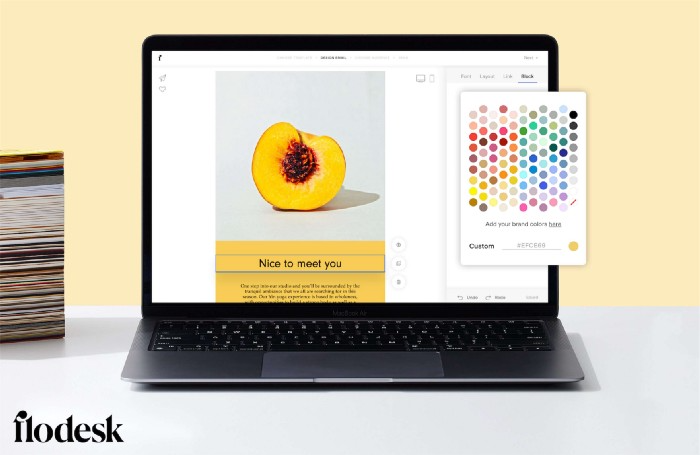
Flodesk's inability to add inline HTML to emails is my biggest issue with larger projects. I wish I could upload HTML emails.
Simple sign-up procedures
Dream up joining.
I like how easy it is to create conversion-focused landing pages. Linkly lets you easily create 5 landing pages and A/B test messaging.
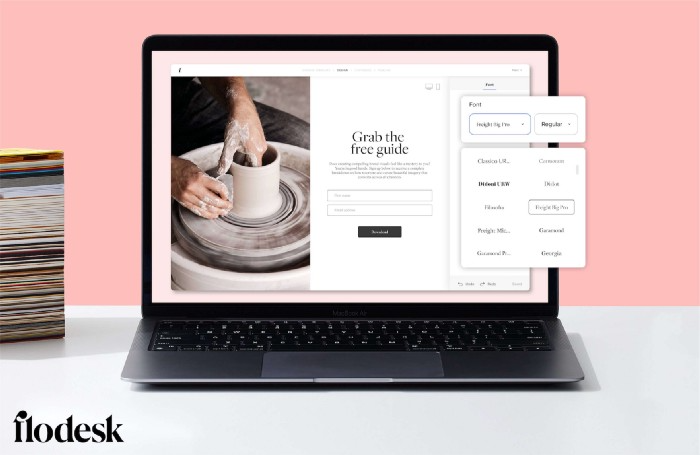
I like that you can use signup forms to ask people what they're interested in so they get relevant emails instead of mindless mass emails nobody opens.
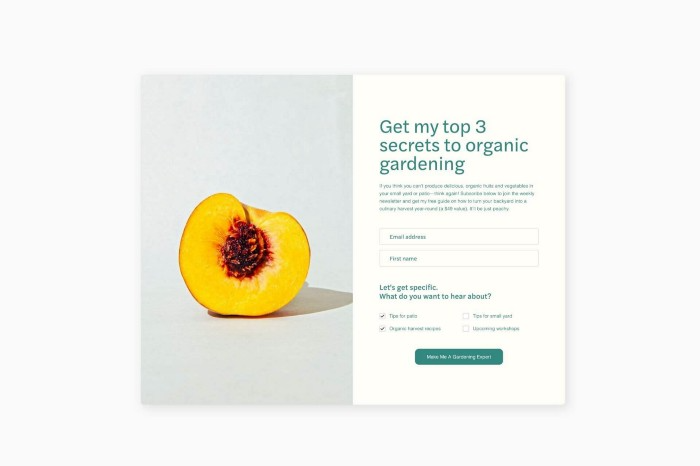
I love how easy it is to embed in-line on a website.
Wonderful designer templates
Beautiful, connecting emails.
Flodesk has calm email templates. My designer's eye felt at rest when I received plain text emails with big impacts.
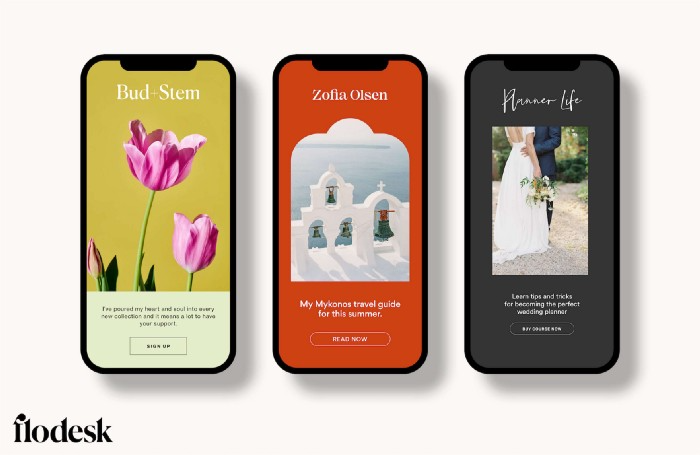
As a typography nerd, I love Flodesk's handpicked designer fonts. It gives emails a designer feel that is hard to replicate on other platforms without coding and custom font licenses.
Small adjustments can have a big impact
Details matter.
Flodesk remembers your brand colors. Flodesk automatically adds your logo and social handles to emails after signup.
Flodesk uses Zapier. This lets you send emails based on a user's action.
A bad live chat can trigger a series of emails to win back a customer.
Flodesk isn't for everyone.
Flodesk is great for Apple users like me.