


DAOs are legal entities in Marshall Islands.
The Pacific island state recognizes decentralized autonomous organizations.
The Republic of the Marshall Islands has recognized decentralized autonomous organizations (DAOs) as legal entities, giving collectively owned and managed blockchain projects global recognition.
The Marshall Islands' amended the Non-Profit Entities Act 2021 that now recognizes DAOs, which are blockchain-based entities governed by self-organizing communities. Incorporating Admiralty LLC, the island country's first DAO, was made possible thanks to the amendement. MIDAO Directory Services Inc., a domestic organization established to assist DAOs in the Marshall Islands, assisted in the incorporation.
The new law currently allows any DAO to register and operate in the Marshall Islands.
“This is a unique moment to lead,” said Bobby Muller, former Marshall Islands chief secretary and co-founder of MIDAO. He believes DAOs will help create “more efficient and less hierarchical” organizations.
A global hub for DAOs, the Marshall Islands hopes to become a global hub for DAO registration, domicile, use cases, and mass adoption. He added:
"This includes low-cost incorporation, a supportive government with internationally recognized courts, and a technologically open environment."
According to the World Bank, the Marshall Islands is an independent island state in the Pacific Ocean near the Equator. To create a blockchain-based cryptocurrency that would be legal tender alongside the US dollar, the island state has been actively exploring use cases for digital assets since at least 2018.
In February 2018, the Marshall Islands approved the creation of a new cryptocurrency, Sovereign (SOV). As expected, the IMF has criticized the plan, citing concerns that a digital sovereign currency would jeopardize the state's financial stability. They have also criticized El Salvador, the first country to recognize Bitcoin (BTC) as legal tender.
Marshall Islands senator David Paul said the DAO legislation does not pose the same issues as a government-backed cryptocurrency. “A sovereign digital currency is financial and raises concerns about money laundering,” . This is more about giving DAOs legal recognition to make their case to regulators, investors, and consumers.
More on Web3 & Crypto

Alex Bentley
3 years ago
Why Bill Gates thinks Bitcoin, crypto, and NFTs are foolish
Microsoft co-founder Bill Gates assesses digital assets while the bull is caged.

Bill Gates is well-respected.
Reasonably. He co-founded and led Microsoft during its 1980s and 1990s revolution.
After leaving Microsoft, Bill Gates pursued other interests. He and his wife founded one of the world's largest philanthropic organizations, Bill & Melinda Gates Foundation. He also supports immunizations, population control, and other global health programs.
When Gates criticized Bitcoin, cryptocurrencies, and NFTs, it made news.
Bill Gates said at the 58th Munich Security Conference...
“You have an asset class that’s 100% based on some sort of greater fool theory that somebody’s going to pay more for it than I do.”
Gates means digital assets. Like many bitcoin critics, he says digital coins and tokens are speculative.
And he's not alone. Financial experts have dubbed Bitcoin and other digital assets a "bubble" for a decade.
Gates also made fun of Bored Ape Yacht Club and NFTs, saying, "Obviously pricey digital photographs of monkeys will help the world."
Why does Bill Gates dislike digital assets?
According to Gates' latest comments, Bitcoin, cryptos, and NFTs aren't good ways to hold value.
Bill Gates is a better investor than Elon Musk.
“I’m used to asset classes, like a farm where they have output, or like a company where they make products,” Gates said.
The Guardian claimed in April 2021 that Bill and Melinda Gates owned the most U.S. farms. Over 242,000 acres of farmland.
The Gates couple has enough farmland to cover Hong Kong.

Bill Gates is a classic investor. He wants companies with an excellent track record, strong fundamentals, and good management. Or tangible assets like land and property.
Gates prefers the "old economy" over the "new economy"
Gates' criticism of Bitcoin and cryptocurrency ventures isn't surprising. These digital assets lack all of Gates's investing criteria.
Volatile digital assets include Bitcoin. Their costs might change dramatically in a day. Volatility scares risk-averse investors like Gates.
Gates has a stake in the old financial system. As Microsoft's co-founder, Gates helped develop a dominant tech company.
Because of his business, he's one of the world's richest men.
Bill Gates is invested in protecting the current paradigm.
He won't invest in anything that could destroy the global economy.
When Gates criticizes Bitcoin, cryptocurrencies, and NFTs, he's suggesting they're a hoax. These soapbox speeches are one way he protects his interests.
Digital assets aren't a bad investment, though. Many think they're the future.
Changpeng Zhao and Brian Armstrong are two digital asset billionaires. Two crypto exchange CEOs. Binance/Coinbase.
Digital asset revolution won't end soon.
If you disagree with Bill Gates and plan to invest in Bitcoin, cryptocurrencies, or NFTs, do your own research and understand the risks.
But don’t take Bill Gates’ word for it.
He’s just an old rich guy with a lot of farmland.
He has a lot to lose if Bitcoin and other digital assets gain global popularity.
This post is a summary. Read the full article here.

Tim Denning
3 years ago
The Dogecoin millionaire mysteriously disappeared.
The American who bought a meme cryptocurrency.

Cryptocurrency is the financial underground.
I love it. But there’s one thing I hate: scams. Over the last few years the Dogecoin cryptocurrency saw massive gains.
Glauber Contessoto overreacted. He shared his rags-to-riches cryptocurrency with the media.
He's only wealthy on paper. No longer Dogecoin millionaire.
Here's what he's doing now. It'll make you rethink cryptocurrency investing.
Strange beginnings
Glauber once had a $36,000-a-year job.
He grew up poor and wanted to make his mother proud. Tesla was his first investment. He bought GameStop stock after Reddit boosted it.
He bought whatever was hot.
He was a young investor. Memes, not research, influenced his decisions.
Elon Musk (aka Papa Elon) began tweeting about Dogecoin.
Doge is a 2013 cryptocurrency. One founder is Australian. He insists it's funny.
He was shocked anyone bought it LOL.
Doge is a Shiba Inu-themed meme. Now whenever I see a Shiba Inu, I think of Doge.
Elon helped drive up the price of Doge by talking about it in 2020 and 2021 (don't take investment advice from Elon; he's joking and gaslighting you).
Glauber caved. He invested everything in Doge. He borrowed from family and friends. He maxed out his credit card to buy more Doge. Yuck.
Internet dubbed him a genius. Slumdog millionaire and The Dogefather were nicknames. Elon pumped Doge on social media.
Good times.
From $180,000 to $1,000,000+
TikTok skyrocketed Doge's price.
Reddit fueled up. Influencers recommended buying Doge because of its popularity. Glauber's motto:
Scared money doesn't earn.
Glauber was no broke ass anymore.
His $180,000 Dogecoin investment became $1M. He championed investing. He quit his dumb job like a rebellious millennial.
A puppy dog meme captivated the internet.
Rise and fall
Whenever I invest in anything I ask myself “what utility does this have?”
Dogecoin is useless.
You buy it for the cute puppy face and hope others will too, driving up the price. All cryptocurrencies fell in 2021's second half.
Central banks raised interest rates, and inflation became a pain.
Dogecoin fell more than others. 90% decline.
Glauber’s Dogecoin is now worth $323K. Still no sales. His dog god is unshakeable. Confidence rocks. Dogecoin millionaire recently said...
“I should have sold some.”
Yes, sir.
He now avoids speculative cryptocurrencies like Dogecoin and focuses on Bitcoin and Ethereum.
I've long said this. Starbucks is building on Ethereum.
It's useful. Useful. Developers use Ethereum daily. Investing makes you wiser over time, like the Dogecoin millionaire.
When risk b*tch slaps you, humility follows, as it did for me when I lost money.
You have to lose money to make money. Few understand.
Dogecoin's omissions
You might be thinking Dogecoin is crap.
I'll take a contrarian stance. Dogecoin does nothing, but it has a strong community. Dogecoin dominates internet memes.
It's silly.
Not quite. The message of crypto that many people forget is that it’s a change in business model.
Businesses create products and services, then advertise to find customers. Crypto Web3 works backwards. A company builds a fanbase but sells them nothing.
Once the community reaches MVC (minimum viable community), a business can be formed.
Community members are relational versus transactional. They're invested in a cause and care about it (typically ownership in the business via crypto).
In this new world, Dogecoin has the most important feature.
Summary
While Dogecoin does have a community I still dislike it.
It's all shady. Anything Elon Musk recommends is a bad investment (except SpaceX & Tesla are great companies).
Dogecoin Millionaire has wised up and isn't YOLOing into more dog memes.
Don't follow the crowd or the hype. Investing is a long-term sport based on fundamentals and research.
Since Ethereum's inception, I've spent 10,000 hours researching.
Dogecoin will be the foundation of something new, like Pets.com at the start of the dot-com revolution. But I doubt Doge will boom.
Be safe!

Faisal Khan
2 years ago
4 typical methods of crypto market manipulation

Market fraud
Due to its decentralized and fragmented character, the crypto market has integrity difficulties.
Cryptocurrencies are an immature sector, therefore market manipulation becomes a bigger issue. Many research have attempted to uncover these abuses. CryptoCompare's newest one highlights some of the industry's most typical scams.
Why are these concerns so common in the crypto market? First, even the largest centralized exchanges remain unregulated due to industry immaturity. A low-liquidity market segment makes an attack more harmful. Finally, market surveillance solutions not implemented reduce transparency.
In CryptoCompare's latest exchange benchmark, 62.4% of assessed exchanges had a market surveillance system, although only 18.1% utilised an external solution. To address market integrity, this measure must improve dramatically. Before discussing the report's malpractices, note that this is not a full list of attacks and hacks.
Clean Trading
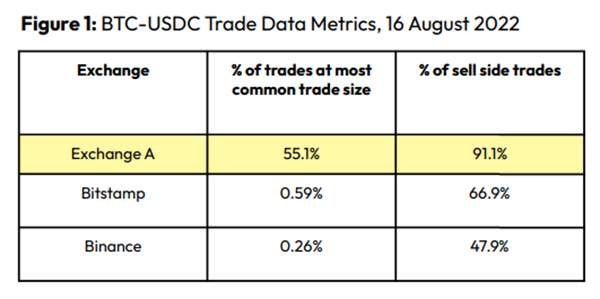
An investor buys and sells concurrently to increase the asset's price. Centralized and decentralized exchanges show this misconduct. 23 exchanges have a volume-volatility correlation < 0.1 during the previous 100 days, according to CryptoCompares. In August 2022, Exchange A reported $2.5 trillion in artificial and/or erroneous volume, up from $33.8 billion the month before.
Spoofing
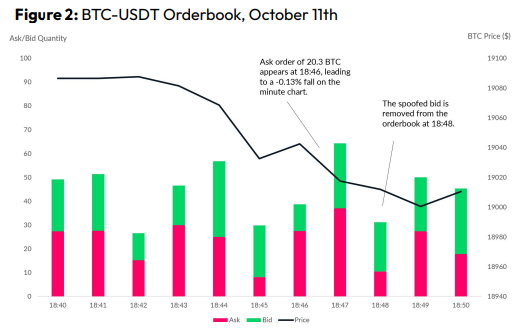
Criminals create and cancel fake orders before they can be filled. Since manipulators can hide in larger trading volumes, larger exchanges have more spoofing. A trader placed a 20.8 BTC ask order at $19,036 when BTC was trading at $19,043. BTC declined 0.13% to $19,018 in a minute. At 18:48, the trader canceled the ask order without filling it.
Front-Running
Most cryptocurrency front-running involves inside trading. Traditional stock markets forbid this. Since most digital asset information is public, this is harder. Retailers could utilize bots to front-run.
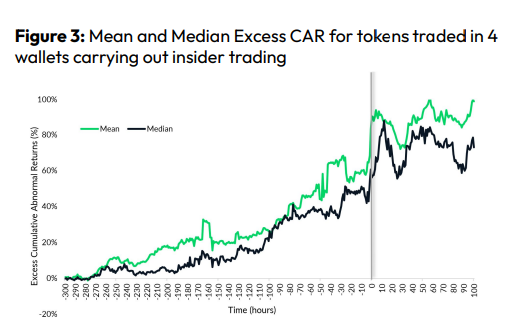
CryptoCompare found digital wallets of people who traded like insiders on exchange listings. The figure below shows excess cumulative anomalous returns (CAR) before a coin listing on an exchange.
Finally, LAYERING is a sequence of spoofs in which successive orders are put along a ladder of greater (layering offers) or lower (layering bids) values. The paper concludes with recommendations to mitigate market manipulation. Exchange data transparency, market surveillance, and regulatory oversight could reduce manipulative tactics.
You might also like

Sanjay Priyadarshi
3 years ago
Meet a Programmer Who Turned Down Microsoft's $10,000,000,000 Acquisition Offer
Failures inspire young developers

Jason citron created many products.
These products flopped.
Microsoft offered $10 billion for one of these products.
He rejected the offer since he was so confident in his success.
Let’s find out how he built a product that is currently valued at $15 billion.
Early in his youth, Jason began learning to code.
Jason's father taught him programming and IT.
His father wanted to help him earn money when he needed it.
Jason created video games and websites in high school.
Jason realized early on that his IT and programming skills could make him money.
Jason's parents misjudged his aptitude for programming.
Jason frequented online programming communities.
He looked for web developers. He created websites for those people.
His parents suspected Jason sold drugs online. When he said he used programming to make money, they were shocked.
They helped him set up a PayPal account.
Florida higher education to study video game creation
Jason never attended an expensive university.
He studied game design in Florida.
“Higher Education is an interesting part of society… When I work with people, the school they went to never comes up… only thing that matters is what can you do…At the end of the day, the beauty of silicon valley is that if you have a great idea and you can bring it to the life, you can convince a total stranger to give you money and join your project… This notion that you have to go to a great school didn’t end up being a thing for me.”
Jason's life was altered by Steve Jobs' keynote address.
After graduating, Jason joined an incubator.
Jason created a video-dating site first.
Bad idea.
Nobody wanted to use it when it was released, so they shut it down.
He made a multiplayer game.
It was released on Bebo. 10,000 people played it.
When Steve Jobs unveiled the Apple app store, he stopped playing.
The introduction of the app store resembled that of a new gaming console.
Jason's life altered after Steve Jobs' 2008 address.
“Whenever a new video game console is launched, that’s the opportunity for a new video game studio to get started, it’s because there aren’t too many games available…When a new PlayStation comes out, since it’s a new system, there’s only a handful of titles available… If you can be a launch title you can get a lot of distribution.”
Apple's app store provided a chance to start a video game company.
They released an app after 5 months of work.
Aurora Feint is the game.
Jason believed 1000 players in a week would be wonderful. A thousand players joined in the first hour.
Over time, Aurora Feints' game didn't gain traction. They don't make enough money to keep playing.
They could only make enough for one month.
Instead of buying video games, buy technology
Jason saw that they established a leaderboard, chat rooms, and multiplayer capabilities and believed other developers would want to use these.
They opted to sell the prior game's technology.
OpenFeint.
Assisting other game developers
They had no money in the bank to create everything needed to make the technology user-friendly.
Jason and Daniel designed a website saying:
“If you’re making a video game and want to have a drop in multiplayer support, you can use our system”
TechCrunch covered their website launch, and they gained a few hundred mailing list subscribers.
They raised seed funding with the mailing list.
Nearly all iPhone game developers started adopting the Open Feint logo.
“It was pretty wild… It was really like a whole social platform for people to play with their friends.”
What kind of a business model was it?
OpenFeint originally planned to make the software free for all games. As the game gained popularity, they demanded payment.
They later concluded it wasn't a good business concept.
It became free eventually.
Acquired for $104 million
Open Feint's users and employees grew tremendously.
GREE bought OpenFeint for $104 million in April 2011.
GREE initially committed to helping Jason and his team build a fantastic company.
Three or four months after the acquisition, Jason recognized they had a different vision.
He quit.
Jason's Original Vision for the iPad
Jason focused on distribution in 2012 to help businesses stand out.
The iPad market and user base were growing tremendously.
Jason said the iPad may replace mobile gadgets.
iPad gamers behaved differently than mobile gamers.
People sat longer and experienced more using an iPad.
“The idea I had was what if we built a gaming business that was more like traditional video games but played on tablets as opposed to some kind of mobile game that I’ve been doing before.”
Unexpected insight after researching the video game industry
Jason learned from studying the gaming industry that long-standing companies had advantages beyond a single release.
Previously, long-standing video game firms had their own distribution system. This distribution strategy could buffer time between successful titles.
Sony, Microsoft, and Valve all have gaming consoles and online stores.
So he built a distribution system.
He created a group chat app for gamers.
He envisioned a team-based multiplayer game with text and voice interaction.
His objective was to develop a communication network, release more games, and start a game distribution business.
Remaking the video game League of Legends
Jason and his crew reimagined a League of Legends game mode for 12-inch glass.
They adapted the game for tablets.
League of Legends was PC-only.
So they rebuilt it.
They overhauled the game and included native mobile experiences to stand out.
Hammer and Chisel was the company's name.
18 people worked on the game.
The game was funded. The game took 2.5 years to make.
Was the game a success?
July 2014 marked the game's release. The team's hopes were dashed.
Critics initially praised the game.
Initial installation was widespread.
The game failed.
As time passed, the team realized iPad gaming wouldn't increase much and mobile would win.
Jason was given a fresh idea by Stan Vishnevskiy.
Stan Vishnevskiy was a corporate engineer.
He told Jason about his plan to design a communication app without a game.
This concept seeded modern strife.
“The insight that he really had was to put a couple of dots together… we’re seeing our customers communicating around our own game with all these different apps and also ourselves when we’re playing on PC… We should solve that problem directly rather than needing to build a new game…we should start making it on PC.”
So began Discord.
Online socializing with pals was the newest trend.
Jason grew up playing video games with his friends.
He never played outside.
Jason had many great moments playing video games with his closest buddy, wife, and brother.
Discord was about providing a location for you and your group to speak and hang out.
Like a private cafe, bedroom, or living room.
Discord was developed for you and your friends on computers and phones.
You can quickly call your buddies during a game to conduct a conference call. Put the call on speaker and talk while playing.
Discord wanted to give every player a unique experience. Because coordinating across apps was a headache.
The entire team started concentrating on Discord.
Jason decided Hammer and Chisel would focus on their chat app.
Jason didn't want to make a video game.
How Discord attracted the appropriate attention
During the first five months, the entire team worked on the game and got feedback from friends.
This ensures product improvement. As a result, some teammates' buddies started utilizing Discord.
The team knew it would become something, but the result was buggy. App occasionally crashed.
Jason persuaded a gamer friend to write on Reddit about the software.
New people would find Discord. Why not?
Reddit users discovered Discord and 50 started using it frequently.
Discord was launched.
Rejecting the $10 billion acquisition proposal
Discord has increased in recent years.
It sends billions of messages.
Discord's users aren't tracked. They're privacy-focused.
Purchase offer
Covid boosted Discord's user base.
Weekly, billions of messages were transmitted.
Microsoft offered $10 billion for Discord in 2021.
Jason sold Open Feint for $104m in 2011.
This time, he believed in the product so much that he rejected Microsoft's offer.
“I was talking to some people in the team about which way we could go… The good thing was that most of the team wanted to continue building.”
Last time, Discord was valued at $15 billion.
Discord raised money on March 12, 2022.
The $15 billion corporation raised $500 million in 2021.

Ian Writes
3 years ago
Rich Dad, Poor Dad is a Giant Steaming Pile of Sh*t by Robert Kiyosaki.
Don't promote it.

I rarely read a post on how Rich Dad, Poor Dad motivated someone to grow rich or change their investing/finance attitude. Rich Dad, Poor Dad is a sham, though. This book isn't worth anyone's attention.
Robert Kiyosaki, the author of this garbage, doesn't deserve recognition or attention. This first finance guru wanted to build his own wealth at your expense. These charlatans only care about themselves.
The reason why Rich Dad, Poor Dad is a huge steaming piece of trash
The book's ideas are superficial, apparent, and unsurprising to entrepreneurs and investors. The book's themes may seem profound to first-time readers.
Apparently, starting a business will make you rich.
The book supports founding or buying a business, making it self-sufficient, and being rich through it. Starting a business is time-consuming, tough, and expensive. Entrepreneurship isn't for everyone. Rarely do enterprises succeed.
Robert says we should think like his mentor, a rich parent. Robert never said who or if this guy existed. He was apparently his own father. Robert proposes investing someone else's money in several enterprises and properties. The book proposes investing in:
“have returns of 100 percent to infinity. Investments that for $5,000 are soon turned into $1 million or more.”
In rare cases, a business may provide 200x returns, but 65% of US businesses fail within 10 years. Australia's first-year business failure rate is 60%. A business that lasts 10 years doesn't mean its owner is rich. These statistics only include businesses that survive and pay their owners.
Employees are depressed and broke.
The novel portrays employees as broke and sad. The author degrades workers.
I've owned and worked for a business. I was broke and miserable as a business owner, working 80 hours a week for absolutely little salary. I work 50 hours a week and make over $200,000 a year. My work is hard, intriguing, and I'm surrounded by educated individuals. Self-employed or employee?
Don't listen to a charlatan's tax advice.
From a bad advise perspective, Robert's tax methods were funny. Robert suggests forming a corporation to write off holidays as board meetings or health club costs as business expenses. These actions can land you in serious tax trouble.
Robert dismisses college and traditional schooling. Rich individuals learn by doing or living, while educated people are agitated and destitute, says Robert.
Rich dad says:
“All too often business schools train employees to become sophisticated bean-counters. Heaven forbid a bean counter takes over a business. All they do is look at the numbers, fire people, and kill the business.”
And then says:
“Accounting is possibly the most confusing, boring subject in the world, but if you want to be rich long-term, it could be the most important subject.”
Get rich by avoiding paying your debts to others.
While this book has plenty of bad advice, I'll end with this: Robert advocates paying yourself first. This man's work with Trump isn't surprising.
Rich Dad's book says:
“So you see, after paying myself, the pressure to pay my taxes and the other creditors is so great that it forces me to seek other forms of income. The pressure to pay becomes my motivation. I’ve worked extra jobs, started other companies, traded in the stock market, anything just to make sure those guys don’t start yelling at me […] If I had paid myself last, I would have felt no pressure, but I’d be broke.“
Paying yourself first shouldn't mean ignoring debt, damaging your credit score and reputation, or paying unneeded fees and interest. Good business owners pay employees, creditors, and other costs first. You can pay yourself after everyone else.
If you follow Robert Kiyosaki's financial and business advice, you might as well follow Donald Trump's, the most notoriously ineffective businessman and swindle artist.
This book's popularity is unfortunate. Robert utilized the book's fame to promote paid seminars. At these seminars, he sold more expensive seminars to the gullible. This strategy was utilized by several conmen and Trump University.
It's reasonable that many believed him. It sounded appealing because he was pushing to get rich by thinking like a rich person. Anyway. At a time when most persons addressing wealth development advised early sacrifices (such as eschewing luxury or buying expensive properties), Robert told people to act affluent now and utilize other people's money to construct their fantasy lifestyle. It's exciting and fast.
I often voice my skepticism and scorn for internet gurus now that social media and platforms like Medium make it easier to promote them. Robert Kiyosaki was a guru. Many people still preach his stuff because he was so good at pushing it.

Leonardo Castorina
3 years ago
How to Use Obsidian to Boost Research Productivity
Tools for managing your PhD projects, reading lists, notes, and inspiration.
As a researcher, you have to know everything. But knowledge is useless if it cannot be accessed quickly. An easy-to-use method of archiving information makes taking notes effortless and enjoyable.
As a PhD student in Artificial Intelligence, I use Obsidian (https://obsidian.md) to manage my knowledge.
The article has three parts:
- What is a note, how to organize notes, tags, folders, and links? This section is tool-agnostic, so you can use most of these ideas with any note-taking app.
- Instructions for using Obsidian, managing notes, reading lists, and useful plugins. This section demonstrates how I use Obsidian, my preferred knowledge management tool.
- Workflows: How to use Zotero to take notes from papers, manage multiple projects' notes, create MOCs with Dataview, and more. This section explains how to use Obsidian to solve common scientific problems and manage/maintain your knowledge effectively.
This list is not perfect or complete, but it is my current solution to problems I've encountered during my PhD. Please leave additional comments or contact me if you have any feedback. I'll try to update this article.
Throughout the article, I'll refer to your digital library as your "Obsidian Vault" or "Zettelkasten".
Other useful resources are listed at the end of the article.
1. Philosophy: Taking and organizing notes
Carl Sagan: “To make an apple pie from scratch, you must first create the universe.”
Before diving into Obsidian, let's establish a Personal Knowledge Management System and a Zettelkasten. You can skip to Section 2 if you already know these terms.
Niklas Luhmann, a prolific sociologist who wrote 400 papers and 70 books, inspired this section and much of Zettelkasten. Zettelkasten means “slip box” (or library in this article). His Zettlekasten had around 90000 physical notes, which can be found here.
There are now many tools available to help with this process. Obsidian's website has a good introduction section: https://publish.obsidian.md/hub/
Notes
We'll start with "What is a note?" Although it may seem trivial, the answer depends on the topic or your note-taking style. The idea is that a note is as “atomic” (i.e. You should read the note and get the idea right away.
The resolution of your notes depends on their detail. Deep Learning, for example, could be a general description of Neural Networks, with a few notes on the various architectures (eg. Recurrent Neural Networks, Convolutional Neural Networks etc..).
Limiting length and detail is a good rule of thumb. If you need more detail in a specific section of this note, break it up into smaller notes. Deep Learning now has three notes:
- Deep Learning
- Recurrent Neural Networks
- Convolutional Neural Networks
Repeat this step as needed until you achieve the desired granularity. You might want to put these notes in a “Neural Networks” folder because they are all about the same thing. But there's a better way:
#Tags and [[Links]] over /Folders/
The main issue with folders is that they are not flexible and assume that all notes in the folder belong to a single category. This makes it difficult to make connections between topics.
Deep Learning has been used to predict protein structure (AlphaFold) and classify images (ImageNet). Imagine a folder structure like this:
- /Proteins/
- Protein Folding
- /Deep Learning/
- /Proteins/
Your notes about Protein Folding and Convolutional Neural Networks will be separate, and you won't be able to find them in the same folder.
This can be solved in several ways. The most common one is to use tags rather than folders. A note can be grouped with multiple topics this way. Obsidian tags can also be nested (have subtags).
You can also link two notes together. You can build your “Knowledge Graph” in Obsidian and other note-taking apps like Obsidian.
My Knowledge Graph. Green: Biology, Red: Machine Learning, Yellow: Autoencoders, Blue: Graphs, Brown: Tags.
My Knowledge Graph and the note “Backrpropagation” and its links.
Backpropagation note and all its links
Why use Folders?
Folders help organize your vault as it grows. The main suggestion is to have few folders that "weakly" collect groups of notes or better yet, notes from different sources.
Among my Zettelkasten folders are:
My Zettelkasten's 5 folders
They usually gather data from various sources:
MOC: Map of Contents for the Zettelkasten.
Projects: Contains one note for each side-project of my PhD where I log my progress and ideas. Notes are linked to these.
Bio and ML: These two are the main content of my Zettelkasten and could theoretically be combined.
Papers: All my scientific paper notes go here. A bibliography links the notes. Zotero .bib file
Books: I make a note for each book I read, which I then split into multiple notes.
Keeping images separate from other files can help keep your main folders clean.
I will elaborate on these in the Workflow Section.
My general recommendation is to use tags and links instead of folders.
Maps of Content (MOC)
Making Tables of Contents is a good solution (MOCs).
These are notes that "signposts" your Zettelkasten library, directing you to the right type of notes. It can link to other notes based on common tags. This is usually done with a title, then your notes related to that title. As an example:
An example of a Machine Learning MOC generated with Dataview.
As shown above, my Machine Learning MOC begins with the basics. Then it's on to Variational Auto-Encoders. Not only does this save time, but it also saves scrolling through the tag search section.
So I keep MOCs at the top of my library so I can quickly find information and see my library. These MOCs are generated automatically using an Obsidian Plugin called Dataview (https://github.com/blacksmithgu/obsidian-dataview).
Ideally, MOCs could be expanded to include more information about the notes, their status, and what's left to do. In the absence of this, Dataview does a fantastic job at creating a good structure for your notes.
In the absence of this, Dataview does a fantastic job at creating a good structure for your notes.
2. Tools: Knowing Obsidian
Obsidian is my preferred tool because it is free, all notes are stored in Markdown format, and each panel can be dragged and dropped. You can get it here: https://obsidian.md/
Obsidian interface.
Obsidian is highly customizable, so here is my preferred interface:
The theme is customized from https://github.com/colineckert/obsidian-things
Alternatively, each panel can be collapsed, moved, or removed as desired. To open a panel later, click on the vertical "..." (bottom left of the note panel).
My interface is organized as follows:
How my Obsidian Interface is organized.
Folders/Search:
This is where I keep all relevant folders. I usually use the MOC note to navigate, but sometimes I use the search button to find a note.
Tags:
I use nested tags and look into each one to find specific notes to link.
cMenu:
Easy-to-use menu plugin cMenu (https://github.com/chetachiezikeuzor/cMenu-Plugin)
Global Graph:
The global graph shows all your notes (linked and unlinked). Linked notes will appear closer together. Zoom in to read each note's title. It's a bit overwhelming at first, but as your library grows, you get used to the positions and start thinking of new connections between notes.
Local Graph:
Your current note will be shown in relation to other linked notes in your library. When needed, you can quickly jump to another link and back to the current note.
Links:
Finally, an outline panel and the plugin Obsidian Power Search (https://github.com/aviral-batra/obsidian-power-search) allow me to search my vault by highlighting text.
Start using the tool and worry about panel positioning later. I encourage you to find the best use-case for your library.
Plugins
An additional benefit of using Obsidian is the large plugin library. I use several (Calendar, Citations, Dataview, Templater, Admonition):
Obsidian Calendar Plugin: https://github.com/liamcain
It organizes your notes on a calendar. This is ideal for meeting notes or keeping a journal.
Calendar addon from hans/obsidian-citation-plugin
Obsidian Citation Plugin: https://github.com/hans/
Allows you to cite papers from a.bib file. You can also customize your notes (eg. Title, Authors, Abstract etc..)
Plugin citation from hans/obsidian-citation-plugin
Obsidian Dataview: https://github.com/blacksmithgu/
A powerful plugin that allows you to query your library as a database and generate content automatically. See the MOC section for an example.
Allows you to create notes with specific templates like dates, tags, and headings.
Templater. Obsidian Admonition: https://github.com/valentine195/obsidian-admonition
Blocks allow you to organize your notes.
Plugin warning. Obsidian Admonition (valentine195)
There are many more, but this list should get you started.
3. Workflows: Cool stuff
Here are a few of my workflows for using obsidian for scientific research. This is a list of resources I've found useful for my use-cases. I'll outline and describe them briefly so you can skim them quickly.
3.1 Using Templates to Structure Notes
3.2 Free Note Syncing (Laptop, Phone, Tablet)
3.3 Zotero/Mendeley/JabRef -> Obsidian — Managing Reading Lists
3.4 Projects and Lab Books
3.5 Private Encrypted Diary
3.1 Using Templates to Structure Notes
Plugins: Templater and Dataview (optional).
To take effective notes, you must first make adding new notes as easy as possible. Templates can save you time and give your notes a consistent structure. As an example:
An example of a note using a template.
### [[YOUR MOC]]
# Note Title of your note
**Tags**::
**Links**::
The top line links to your knowledge base's Map of Content (MOC) (see previous sections). After the title, I add tags (and a link between the note and the tag) and links to related notes.
To quickly identify all notes that need to be expanded, I add the tag “#todo”. In the “TODO:” section, I list the tasks within the note.
The rest are notes on the topic.
Templater can help you create these templates. For new books, I use the following template:
### [[Books MOC]]
# Title
**Author**::
**Date::
**Tags::
**Links::
A book template example.
Using a simple query, I can hook Dataview to it.
dataview
table author as Author, date as “Date Finished”, tags as “Tags”, grade as “Grade”
from “4. Books”
SORT grade DESCENDING
using Dataview to query templates.
3.2 Free Note Syncing (Laptop, Phone, Tablet)
No plugins used.
One of my favorite features of Obsidian is the library's self-contained and portable format. Your folder contains everything (plugins included).
Ordinary folders and documents are available as well. There is also a “.obsidian” folder. This contains all your plugins and settings, so you can use it on other devices.
So you can use Google Drive, iCloud, or Dropbox for free as long as you sync your folder (note: your folder should be in your Cloud Folder).
For my iOS and macOS work, I prefer iCloud. You can also use the paid service Obsidian Sync.
3.3 Obsidian — Managing Reading Lists and Notes in Zotero/Mendeley/JabRef
Plugins: Quotes (required).
3.3 Zotero/Mendeley/JabRef -> Obsidian — Taking Notes and Managing Reading Lists of Scientific Papers
My preferred reference manager is Zotero, but this workflow should work with any reference manager that produces a .bib file. This file is exported to my cloud folder so I can access it from any platform.
My Zotero library is tagged as follows:
My reference manager's tags
For readings, I usually search for the tags “!!!” and “To-Read” and select a paper. Annotate the paper next (either on PDF using GoodNotes or on physical paper).
Then I make a paper page using a template in the Citations plugin settings:
An example of my citations template.
Create a new note, open the command list with CMD/CTRL + P, and find the Citations “Insert literature note content in the current pane” to see this lovely view.
Citation generated by the article https://doi.org/10.1101/2022.01.24.22269144
You can then convert your notes to digital. I found that transcribing helped me retain information better.
3.4 Projects and Lab Books
Plugins: Tweaker (required).
PhD students offering advice on thesis writing are common (read as regret). I started asking them what they would have done differently or earlier.
“Deep stuff Leo,” one person said. So my main issue is basic organization, losing track of my tasks and the reasons for them.
As a result, I'd go on other experiments that didn't make sense, and have to reverse engineer my logic for thesis writing. - PhD student now wise Postdoc
Time management requires planning. Keeping track of multiple projects and lab books is difficult during a PhD. How I deal with it:
- One folder for all my projects
- One file for each project
I use a template to create each project
### [[Projects MOC]]
# <% tp.file.title %>
**Tags**::
**Links**::
**URL**::
**Project Description**::## Notes:
### <% tp.file.last_modified_date(“dddd Do MMMM YYYY”) %>
#### Done:
#### TODO:
#### Notes
You can insert a template into a new note with CMD + P and looking for the Templater option.
I then keep adding new days with another template:
### <% tp.file.last_modified_date("dddd Do MMMM YYYY") %>
#### Done:
#### TODO:
#### Notes:
This way you can keep adding days to your project and update with reasonings and things you still have to do and have done. An example below:
Example of project note with timestamped notes.
3.5 Private Encrypted Diary
This is one of my favorite Obsidian uses.
Mini Diary's interface has long frustrated me. After the author archived the project, I looked for a replacement. I had two demands:
- It had to be private, and nobody had to be able to read the entries.
- Cloud syncing was required for editing on multiple devices.
Then I learned about encrypting the Obsidian folder. Then decrypt and open the folder with Obsidian. Sync the folder as usual.
Use CryptoMator (https://cryptomator.org/). Create an encrypted folder in Cryptomator for your Obsidian vault, set a password, and let it do the rest.
If you need a step-by-step video guide, here it is:
Conclusion
So, I hope this was helpful!
In the first section of the article, we discussed notes and note-taking techniques. We discussed when to use tags and links over folders and when to break up larger notes.
Then we learned about Obsidian, its interface, and some useful plugins like Citations for citing papers and Templater for creating note templates.
Finally, we discussed workflows and how to use Zotero to take notes from scientific papers, as well as managing Lab Books and Private Encrypted Diaries.
Thanks for reading and commenting :)
Read original post here