


More on Entrepreneurship/Creators

Micah Daigle
3 years ago
Facebook is going away. Here are two explanations for why it hasn't been replaced yet.
And tips for anyone trying.

We see the same story every few years.
BREAKING NEWS: [Platform X] launched a social network. With Facebook's reputation down, the new startup bets millions will switch.
Despite the excitement surrounding each new platform (Diaspora, Ello, Path, MeWe, Minds, Vero, etc.), no major exodus occurred.
Snapchat and TikTok attracted teens with fresh experiences (ephemeral messaging and rapid-fire videos). These features aren't Facebook, even if Facebook replicated them.
Facebook's core is simple: you publish items (typically text/images) and your friends (generally people you know IRL) can discuss them.
It's cool. Sometimes I don't want to, but sh*t. I like it.
Because, well, I like many folks I've met. I enjoy keeping in touch with them and their banter.
I dislike Facebook's corporation. I've been cautiously optimistic whenever a Facebook-killer surfaced.
None succeeded.
Why? Two causes, I think:
People couldn't switch quickly enough, which is reason #1
Your buddies make a social network social.
Facebook started in self-contained communities (college campuses) then grew outward. But a new platform can't.
If we're expected to leave Facebook, we want to know that most of our friends will too.
Most Facebook-killers had bottlenecks. You have to waitlist or jump through hoops (e.g. setting up a server).
Same outcome. Upload. Chirp.
After a week or two of silence, individuals returned to Facebook.
Reason #2: The fundamental experience was different.
Even when many of our friends joined in the first few weeks, it wasn't the same.
There were missing features or a different UX.
Want to reply with a meme? No photos in comments yet. (Trying!)
Want to tag a friend? Nope, sorry. 2019!
Want your friends to see your post? You must post to all your friends' servers. Good luck!
It's difficult to introduce a platform with 100% of the same features as one that's been there for 20 years, yet customers want a core experience.
If you can't, they'll depart.
The causes that led to the causes
Having worked on software teams for 14+ years, I'm not surprised by these challenges. They are a natural development of a few tech sector meta-problems:
Lean startup methodology
Silicon Valley worships lean startup. It's a way of developing software that involves testing a stripped-down version with a limited number of people before selecting what to build.
Billion people use Facebook's functions. They aren't tested. It must work right away*
*This may seem weird to software people, but it's how non-software works! You can't sell a car without wheels.
2. Creativity
Startup entrepreneurs build new things, not copies. I understand. Reinventing the wheel is boring.
We know what works. Different experiences raise adoption friction. Once millions have transferred, more features (and a friendlier UX) can be implemented.
3. Cost scaling
True. Building a product that can sustain hundreds of millions of users in weeks is expensive and complex.
Your lifeboats must have the same capacity as the ship you're evacuating. It's required.
4. Pure ideologies
People who work on Facebook-alternatives are (understandably) critical of Facebook.
They build an open-source, fully-distributed, data-portable, interface-customizable, offline-capable, censorship-proof platform.
Prioritizing these aims can prevent replicating the straightforward experience users expect. Github, not Facebook, is for techies only.
What about the business plan, though?
Facebook-killer attempts have followed three models.
Utilize VC funding to increase your user base, then monetize them later. (If you do this, you won't kill Facebook; instead, Facebook will become you.)
Users must pay to utilize it. (This causes a huge bottleneck and slows the required quick expansion, preventing it from seeming like a true social network.)
Make it a volunteer-run, open-source endeavor that is free. (This typically denotes that something is cumbersome, difficult to operate, and is only for techies.)
Wikipedia is a fourth way.
Wikipedia is one of the most popular websites and a charity. No ads. Donations support them.
A Facebook-killer managed by a good team may gather millions (from affluent contributors and the crowd) for their initial phase of development. Then it might sustain on regular donations, ethical transactions (e.g. fees on commerce, business sites, etc.), and government grants/subsidies (since it would essentially be a public utility).
When you're not aiming to make investors rich, it's remarkable how little money you need.
If you want to build a Facebook competitor, follow these tips:
Drop the lean startup philosophy. Wait until you have a finished product before launching. Build it, thoroughly test it for bugs, and then release it.
Delay innovating. Wait till millions of people have switched before introducing your great new features. Make it nearly identical for now.
Spend money climbing. Make sure that guests can arrive as soon as they are invited. Never keep them waiting. Make things easy for them.
Make it accessible to all. Even if doing so renders it less philosophically pure, it shouldn't require technical expertise to utilize.
Constitute a nonprofit. Additionally, develop community ownership structures. Profit maximization is not the only strategy for preserving valued assets.
Last thoughts
Nobody has killed Facebook, but Facebook is killing itself.
The startup is burying the newsfeed to become a TikTok clone. Meta itself seems to be ditching the platform for the metaverse.
I wish I was happy, but I'm not. I miss (understandably) removed friends' postings and remarks. It could be a ghost town in a few years. My dance moves aren't TikTok-worthy.
Who will lead? It's time to develop a social network for the people.
Greetings if you're working on it. I'm not a company founder, but I like to help hard-working folks.

Aaron Dinin, PhD
2 years ago
The Advantages and Disadvantages of Having Investors Sign Your NDA
Startup entrepreneurs assume what risks when pitching?

Last week I signed four NDAs.
Four!
NDA stands for non-disclosure agreement. A legal document given to someone receiving confidential information. By signing, the person pledges not to share the information for a certain time. If they do, they may be in breach of contract and face legal action.
Companies use NDAs to protect trade secrets and confidential internal information from employees and contractors. Appropriate. If you manage a huge, successful firm, you don't want your employees selling their information to your competitors. To be true, business NDAs don't always prevent corporate espionage, but they usually make employees and contractors think twice before sharing.
I understand employee and contractor NDAs, but I wasn't asked to sign one. I counsel entrepreneurs, thus the NDAs I signed last week were from startups that wanted my feedback on their concepts.
I’m not a startup investor. I give startup guidance online. Despite that, four entrepreneurs thought their company ideas were so important they wanted me to sign a generically written legal form they probably acquired from a shady, spam-filled legal templates website before we could chat.
False. One company tried to get me to sign their NDA a few days after our conversation. I gently rejected, but their tenacity encouraged me. I considered sending retroactive NDAs to everyone I've ever talked to about one of my startups in case they establish a successful company based on something I said.
Two of the other three NDAs were from nearly identical companies. Good thing I didn't sign an NDA for the first one, else they may have sued me for talking to the second one as though I control the firms people pitch me.
I wasn't talking to the fourth NDA company. Instead, I received an unsolicited email from someone who wanted comments on their fundraising pitch deck but required me to sign an NDA before sending it.
That's right, before I could read a random Internet stranger's unsolicited pitch deck, I had to sign his NDA, potentially limiting my ability to discuss what was in it.
You should understand. Advisors, mentors, investors, etc. talk to hundreds of businesses each year. They cannot manage all the companies they deal with, thus they cannot risk legal trouble by talking to someone. Well, if I signed NDAs for all the startups I spoke with, half of the 300+ articles I've written on Medium over the past several years could get me sued into the next century because I've undoubtedly addressed topics in my articles that I discussed with them.
The four NDAs I received last week are part of a recent trend of entrepreneurs sending out NDAs before meetings, despite the practical and legal issues. They act like asking someone to sign away their right to talk about all they see and hear in a day is as straightforward as asking for a glass of water.
Given this inflow of NDAs, I wanted to briefly remind entrepreneurs reading this blog about the merits and cons of requesting investors (or others in the startup ecosystem) to sign your NDA.
Benefits of having investors sign your NDA include:
None. Zero. Nothing.
Disadvantages of requesting investor NDAs:
You'll come off as an amateur who has no idea what it takes to launch a successful firm.
Investors won't trust you with their money since you appear to be a complete amateur.
Printing NDAs will be a waste of paper because no genuine entrepreneur will ever sign one.
I apologize for missing any cons. Please leave your remarks.

Sanjay Priyadarshi
3 years ago
A 19-year-old dropped out of college to build a $2,300,000,000 company in 2 years.
His success was unforeseeable.

2014 saw Facebook's $2.3 billion purchase of Oculus VR.
19-year-old Palmer Luckey founded Oculus. He quit journalism school. His parents worried about his college dropout.
Facebook bought Oculus VR in less than 2 years.
Palmer Luckey started Anduril Industries. Palmer has raised $385 million with Anduril.
The Oculus journey began in a trailer
Palmer Luckey, 19, owned the trailer.
Luckey had his trailer customized. The trailer had all six of Luckey's screens. In the trailer's remaining area, Luckey conducted hardware tests.
At 16, he became obsessed with virtual reality. Virtual reality was rare at the time.
Luckey didn't know about VR when he started.
Previously, he liked "portabilizing" mods. Hacking ancient game consoles into handhelds.
In his city, fewer portabilizers actively traded.
Luckey started "ModRetro" for other portabilizers. Luckey was exposed to VR headsets online.
Luckey:
“Man, ModRetro days were the best.”
Palmer Luckey used VR headsets for three years. His design had 50 prototypes.
Luckey used to work at the Long Beach Sailing Center for minimum salary, servicing diesel engines and cleaning boats.
Luckey worked in a USC Institute for Creative Technologies mixed reality lab in July 2011. (ICT).
Luckey cleaned the lab, did reports, and helped other students with VR projects.
Luckey's lab job was dull.
Luckey chose to work in the lab because he wanted to engage with like-minded folks.
By 2012, Luckey had a prototype he hoped to share globally. He made cheaper headsets than others.
Luckey wanted to sell an easy-to-assemble virtual reality kit on Kickstarter.
He realized he needed a corporation to do these sales legally. He started looking for names. "Virtuality," "virtual," and "VR" are all taken.
Hence, Oculus.
If Luckey sold a hundred prototypes, he would be thrilled since it would boost his future possibilities.
John Carmack, legendary game designer
Carmack has liked sci-fi and fantasy since infancy.
Carmack loved imagining intricate gaming worlds.
His interest in programming and computer science grew with age.
He liked graphics. He liked how mismatching 0 and 1 might create new colors and visuals.
Carmack played computer games as a teen. He created Shadowforge in high school.
He founded Id software in 1991. When Carmack created id software, console games were the best-sellers.
Old computer games have weak graphics. John Carmack and id software developed "adaptive tile refresh."
This technique smoothed PC game scrolling. id software launched 3-D, Quake, and Doom using "adaptive tile refresh."
These games made John Carmack a gaming star. Later, he sold Id software to ZeniMax Media.
How Palmer Luckey met Carmack
In 2011, Carmack was thinking a lot about 3-D space and virtual reality.
He was underwhelmed by the greatest HMD on the market. Because of their flimsiness and latency.
His disappointment was partly due to the view (FOV). Best HMD had 40-degree field of view.
Poor. The best VR headset is useless with a 40-degree FOV.
Carmack intended to show the press Doom 3 in VR. He explored VR headsets and internet groups for this reason.
Carmack identified a VR enthusiast in the comments section of "LEEP on the Cheap." "PalmerTech" was the name.
Carmack approached PalmerTech about his prototype. He told Luckey about his VR demos, so he wanted to see his prototype.
Carmack got a Rift prototype. Here's his May 17 tweet.
John Carmack tweeted an evaluation of the Luckey prototype.
Dan Newell, a Valve engineer, and Mick Hocking, a Sony senior director, pre-ordered Oculus Rift prototypes with Carmack's help.
Everyone praised Luckey after Carmack demoed Rift.
Palmer Luckey received a job offer from Sony.
It was a full-time position at Sony Computer Europe.
He would run Sony’s R&D lab.
The salary would be $70k.
Who is Brendan Iribe?
Brendan Iribe started early with Startups. In 2004, he and Mike Antonov founded Scaleform.
Scaleform created high-performance middleware. This package allows 3D Flash games.
In 2011, Iribe sold Scaleform to Autodesk for $36 million.
How Brendan Iribe discovered Palmer Luckey.
Brendan Iribe's friend Laurent Scallie.
Laurent told Iribe about a potential opportunity.
Laurent promised Iribe VR will work this time. Laurent introduced Iribe to Luckey.
Iribe was doubtful after hearing Laurent's statements. He doubted Laurent's VR claims.
But since Laurent took the name John Carmack, Iribe thought he should look at Luckey Innovation. Iribe was hooked on virtual reality after reading Palmer Luckey stories.
He asked Scallie about Palmer Luckey.
Iribe convinced Luckey to start Oculus with him
First meeting between Palmer Luckey and Iribe.
The Iribe team wanted Luckey to feel comfortable.
Iribe sought to convince Luckey that launching a company was easy. Iribe told Luckey anyone could start a business.
Luckey told Iribe's staff he was homeschooled from childhood. Luckey took self-study courses.
Luckey had planned to launch a Kickstarter campaign and sell kits for his prototype. Many companies offered him jobs, nevertheless.
He's considering Sony's offer.
Iribe advised Luckey to stay independent and not join a firm. Iribe asked Luckey how he could raise his child better. No one sees your baby like you do?
Iribe's team pushed Luckey to stay independent and establish a software ecosystem around his device.
After conversing with Iribe, Luckey rejected every job offer and merger option.
Iribe convinced Luckey to provide an SDK for Oculus developers.
After a few months. Brendan Iribe co-founded Oculus with Palmer Luckey. Luckey trusted Iribe and his crew, so he started a corporation with him.
Crowdfunding
Brendan Iribe and Palmer Luckey launched a Kickstarter.
Gabe Newell endorsed Palmer's Kickstarter video.
Gabe Newell wants folks to trust Palmer Luckey since he's doing something fascinating and answering tough questions.
Mark Bolas and David Helgason backed Palmer Luckey's VR Kickstarter video.
Luckey introduced Oculus Rift during the Kickstarter campaign. He introduced virtual reality during press conferences.
Oculus' Kickstarter effort was a success. Palmer Luckey felt he could raise $250,000.
Oculus raised $2.4 million through Kickstarter. Palmer Luckey's virtual reality vision was well-received.
Mark Zuckerberg's Oculus discovery
Brendan Iribe and Palmer Luckey hired the right personnel after a successful Kickstarter campaign.
Oculus needs a lot of money for engineers and hardware. They needed investors' money.
Series A raised $16M.
Next, Andreessen Horowitz partner Brain Cho approached Iribe.
Cho told Iribe that Andreessen Horowitz could invest in Oculus Series B if the company solved motion sickness.
Mark Andreessen was Iribe's dream client.
Marc Andreessen and his partners gave Oculus $75 million.
Andreessen introduced Iribe to Zukerberg. Iribe and Zukerberg discussed the future of games and virtual reality by phone.
Facebook's Oculus demo
Iribe showed Zuckerberg Oculus.
Mark was hooked after using Oculus. The headset impressed him.
The whole Facebook crew who saw the demo said only one thing.
“Holy Crap!”
This surprised them all.
Mark Zuckerberg was impressed by the team's response. Mark Zuckerberg met the Oculus team five days after the demo.
First meeting Palmer Luckey.
Palmer Luckey is one of Mark's biggest supporters and loves Facebook.
Oculus Acquisition
Zuckerberg wanted Oculus.
Brendan Iribe had requested for $4 billion, but Mark wasn't interested.
Facebook bought Oculus for $2.3 billion after months of drama.
After selling his company, how does Palmer view money?
Palmer loves the freedom money gives him. Money frees him from small worries.
Money has allowed him to pursue things he wouldn't have otherwise.
“If I didn’t have money I wouldn’t have a collection of vintage military vehicles…You can have nice hobbies that keep you relaxed when you have money.”
He didn't start Oculus to generate money. His virtual reality passion spanned years.
He didn't have to lie about how virtual reality will transform everything until he needed funding.
The company's success was an unexpected bonus. He was merely passionate about a good cause.
After Oculus' $2.3 billion exit, what changed?
Palmer didn't mind being rich. He did similar things.
After Facebook bought Oculus, he moved to Silicon Valley and lived in a 12-person shared house due to high rents.
Palmer might have afforded a big mansion, but he prefers stability and doing things because he wants to, not because he has to.
“Taco Bell is never tasted so good as when you know you could afford to never eat taco bell again.”
Palmer's leadership shifted.
Palmer changed his leadership after selling Oculus.
When he launched his second company, he couldn't work on his passions.
“When you start a tech company you do it because you want to work on a technology, that is why you are interested in that space in the first place. As the company has grown, he has realized that if he is still doing optical design in the company it’s because he is being negligent about the hiring process.”
Once his startup grows, the founder's responsibilities shift. He must recruit better firm managers.
Recruiting talented people becomes the top priority. The founder must convince others of their influence.
A book that helped me write this:
The History of the Future: Oculus, Facebook, and the Revolution That Swept Virtual Reality — Blake Harris
*This post is a summary. Read the full article here.
You might also like
Trevor Stark
3 years ago
Economics is complete nonsense.
Mainstream economics haven't noticed.

What come to mind when I say the word "economics"?
Probably GDP, unemployment, and inflation.
If you've ever watched the news or listened to an economist, they'll use data like these to defend a political goal.
The issue is that these statistics are total bunk.
I'm being provocative, but I mean it:
The economy is not measured by GDP.
How many people are unemployed is not counted in the unemployment rate.
Inflation is not measured by the CPI.
All orthodox economists' major economic statistics are either wrong or falsified.
Government institutions create all these stats. The administration wants to reassure citizens the economy is doing well.
GDP does not reflect economic expansion.
GDP measures a country's economic size and growth. It’s calculated by the BEA, a government agency.
The US has the world's largest (self-reported) GDP, growing 2-3% annually.
If GDP rises, the economy is healthy, say economists.
Why is the GDP flawed?
GDP measures a country's yearly spending.
The government may adjust this to make the economy look good.
GDP = C + G + I + NX
C = Consumer Spending
G = Government Spending
I = Investments (Equipment, inventories, housing, etc.)
NX = Exports minus Imports
GDP is a country's annual spending.
The government can print money to boost GDP. The government has a motive to increase and manage GDP.
Because government expenditure is part of GDP, printing money and spending it on anything will raise GDP.
They've done this. Since 1950, US government spending has grown 8% annually, faster than GDP.
In 2022, government spending accounted for 44% of GDP. It's the highest since WWII. In 1790-1910, it was 3% of GDP.
Who cares?
The economy isn't only spending. Focus on citizens' purchasing power or quality of life.
Since GDP just measures spending, the government can print money to boost GDP.
Even if Americans are poorer than last year, economists can say GDP is up and everything is fine.
How many people are unemployed is not counted in the unemployment rate.
The unemployment rate measures a country's labor market. If unemployment is high, people aren't doing well economically.
The BLS estimates the (self-reported) unemployment rate as 3-4%.
Why is the unemployment rate so high?
The US government surveys 100k persons to measure unemployment. They extrapolate this data for the country.
They come into 3 categories:
Employed
People with jobs are employed … duh.
Unemployed
People who are “jobless, looking for a job, and available for work” are unemployed
Not in the labor force
The “labor force” is the employed + the unemployed.
The unemployment rate is the percentage of unemployed workers.
Problem is unemployed definition. You must actively seek work to be considered unemployed.
You're no longer unemployed if you haven't interviewed in 4 weeks.
This shit makes no goddamn sense.
Why does this matter?
You can't interview if there are no positions available. You're no longer unemployed after 4 weeks.
In 1994, the BLS redefined "unemployed" to exclude discouraged workers.
If you haven't interviewed in 4 weeks, you're no longer counted in the unemployment rate.
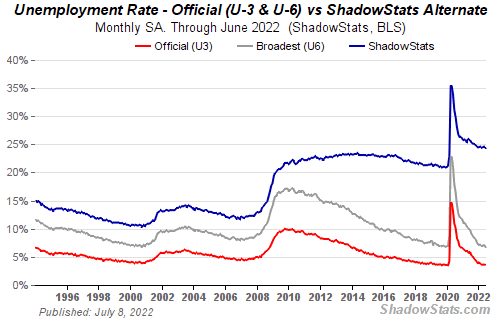
If unemployment were measured by total unemployed, it would be 25%.
Because the government wants to keep the unemployment rate low, they modify the definition.
If every US resident was unemployed and had no job interviews, economists would declare 0% unemployment. Excellent!
Inflation is not measured by the CPI.
The BLS measures CPI. This month was the highest since 1981.
CPI measures the cost of a basket of products across time. Food, energy, shelter, and clothes are included.
A 9.1% CPI means the basket of items is 9.1% more expensive.
What is the CPI problem?
Here's a more detailed explanation of CPI's flaws.
In summary, CPI is manipulated to be understated.
Housing costs are understated to manipulate CPI. Housing accounts for 33% of the CPI because it's the biggest expense for most people.
This signifies it's the biggest CPI weight.
Rather than using actual house prices, the Bureau of Labor Statistics essentially makes shit up. You can read more about the process here.
Surprise! It’s bullshit
The BLS stated Shelter's price rose 5.5% this month.
House prices are up 11-21%. (Source 1, Source 2, Source 3)
Rents are up 14-26%. (Source 1, Source 2)
Why is this important?
If CPI included housing prices, it would be 12-15 percent this month, not 9.1 percent.
9% inflation is nuts. Your money's value halves every 7 years at 9% inflation.
Worse is 15% inflation. Your money halves every 4 years at 15% inflation.
If everyone realized they needed to double their wage every 4-5 years to stay wealthy, there would be riots.
Inflation drains our money's value so the government can keep printing it.
The Solution
Most individuals know the existing system doesn't work, but can't explain why.
People work hard yet lag behind. The government lies about the economy's data.
In reality:
GDP has been down since 2008
25% of Americans are unemployed
Inflation is actually 15%
People might join together to vote out kleptocratic politicians if they knew the reality.
Having reliable economic data is the first step.
People can't understand the situation without sufficient information. Instead of immigrants or billionaires, people would blame liar politicians.
Here’s the vision:
A decentralized, transparent, and global dashboard that tracks economic data like GDP, unemployment, and inflation for every country on Earth.
Government incentives influence economic statistics.
ShadowStats has already started this effort, but the calculations must be transparent, decentralized, and global to be effective.
If interested, email me at trevorstark02@gmail.com.
Here are some links to further your research:

Amelia Winger-Bearskin
3 years ago
Reasons Why AI-Generated Images Remind Me of Nightmares
AI images are like funhouse mirrors.
Google's AI Blog introduced the puppy-slug in the summer of 2015.

Puppy-slug isn't a single image or character. "Puppy-slug" refers to Google's DeepDream's unsettling psychedelia. This tool uses convolutional neural networks to train models to recognize dataset entities. If researchers feed the model millions of dog pictures, the network will learn to recognize a dog.
DeepDream used neural networks to analyze and classify image data as well as generate its own images. DeepDream's early examples were created by training a convolutional network on dog images and asking it to add "dog-ness" to other images. The models analyzed images to find dog-like pixels and modified surrounding pixels to highlight them.
Puppy-slugs and other DeepDream images are ugly. Even when they don't trigger my trypophobia, they give me vertigo when my mind tries to reconcile familiar features and forms in unnatural, physically impossible arrangements. I feel like I've been poisoned by a forbidden mushroom or a noxious toad. I'm a Lovecraft character going mad from extradimensional exposure. They're gross!
Is this really how AIs see the world? This is possibly an even more unsettling topic that DeepDream raises than the blatant abjection of the images.
When these photographs originally circulated online, many friends were startled and scandalized. People imagined a computer's imagination would be literal, accurate, and boring. We didn't expect vivid hallucinations and organic-looking formations.
DeepDream's images didn't really show the machines' imaginations, at least not in the way that scared some people. DeepDream displays data visualizations. DeepDream reveals the "black box" of convolutional network training.
Some of these images look scary because the models don't "know" anything, at least not in the way we do.
These images are the result of advanced algorithms and calculators that compare pixel values. They can spot and reproduce trends from training data, but can't interpret it. If so, they'd know dogs have two eyes and one face per head. If machines can think creatively, they're keeping it quiet.
You could be forgiven for thinking otherwise, given OpenAI's Dall-impressive E's results. From a technological perspective, it's incredible.
Arthur C. Clarke once said, "Any sufficiently advanced technology is indistinguishable from magic." Dall-magic E's requires a lot of math, computer science, processing power, and research. OpenAI did a great job, and we should applaud them.
Dall-E and similar tools match words and phrases to image data to train generative models. Matching text to images requires sorting and defining the images. Untold millions of low-wage data entry workers, content creators optimizing images for SEO, and anyone who has used a Captcha to access a website make these decisions. These people could live and die without receiving credit for their work, even though the project wouldn't exist without them.
This technique produces images that are less like paintings and more like mirrors that reflect our own beliefs and ideals back at us, albeit via a very complex prism. Due to the limitations and biases that these models portray, we must exercise caution when viewing these images.
The issue was succinctly articulated by artist Mimi Onuoha in her piece "On Algorithmic Violence":
As we continue to see the rise of algorithms being used for civic, social, and cultural decision-making, it becomes that much more important that we name the reality that we are seeing. Not because it is exceptional, but because it is ubiquitous. Not because it creates new inequities, but because it has the power to cloak and amplify existing ones. Not because it is on the horizon, but because it is already here.

Sea Launch
3 years ago
📖 Guide to NFT terms: an NFT glossary.
NFT lingo can be overwhelming. As the NFT market matures and expands so does its own jargon, slang, colloquialisms or acronyms.
This ever-growing NFT glossary goal is to unpack key NFT terms to help you better understand the NFT market or at least not feel like a total n00b in a conversation about NFTs on Reddit, Discord or Twitter.
#
1:1 Art
Art where each piece is one of a kind (1 of 1). Unlike 10K projects, PFP or Generative Art collections have a cap of NFTs released that can range from a few hundreds to 10K.
1/1 of X
Contrary to 1:1 Art, 1/1 of X means each NFT is unique, but part of a large and cohesive collection. E.g: Fidenzas by Tyler Hobbs or Crypto Punks (each Punk is 1/1 of 10,000).
10K Project
A type of NFT collection that consists of approximately 10,000 NFTs (but not strictly).
A
AB
ArtBlocks, the most important platform for generative art currently.
AFAIK
As Far As I Know.
Airdrop
Distribution of an NFT token directly into a crypto wallet for free. Can be used as a marketing campaign or as scam by airdropping fake tokens to empty someone’s wallet.
Alpha
The first or very primitive release of a project. Or Investment term to track how a certain investment outdoes the market. E.g: Alpha of 1.0 = 1% improvement or Alpha of 20.0 = 20% improvement.
Altcoin
Any other crypto that is not Bitcoin. Bitcoin Maximalists can also refer to them as shitcoins.
AMA
Ask Me Anything. NFT creators or artists do sessions where anyone can ask questions about the NFT project, team, vision, etc. Usually hosted on Discord, but also on Reddit or even Youtube.
Ape
Someone can be aping, ape in or aped on an NFT meaning someone is taking a large position relative to its own portfolio size. Some argue that when someone apes can mean that they're following the hype, out of FOMO or without due diligence. Not related directly to the Bored Ape Yatch Club.
ATH
All-Time High. When a NFT project or token reaches the highest price to date.
Avatar project
An NFT collection that consists of avatars that people can use as their profile picture (see PFP) in social media to show they are part of an NFT community like Crypto Punks.
Axie Infinity
ETH blockchain-based game where players battle and trade Axies (digital pets). The main ERC-20 tokens used are Axie Infinity Shards (AXS) and Smooth Love Potions (formerly Small Love Potion) (SLP).
Axie Infinity Shards
AXS is an Eth token that powers the Axie Infinity game.
B
Bag Holder
Someone who holds its position in a crypto or keeps an NFT until it's worthless.
BAYC
Bored Ape Yacht Club. A very successful PFP 1/1 of 10,000 individual ape characters collection. People use BAYC as a Twitter profile picture to brag about being part of this NFT community.
Bearish
Borrowed finance slang meaning someone is doubtful about the current market and that it will crash.
Bear Market
When the Crypto or NFT market is going down in value.
Bitcoin (BTC)
First and original cryptocurrency as outlined in a whitepaper by the anonymous creator(s) Satoshi Nakamoto.
Bitcoin Maximalist
Believer that Bitcoin is the only cryptocurrency needed. All other cryptocurrencies are altcoins or shitcoins.
Blockchain
Distributed, decentralized, immutable database that is the basis of trust in Web 3.0 technology.
Bluechip
When an NFT project has a long track record of success and its value is sustained over time, therefore considered a solid investment.
BTD
Buy The Dip. A bear market can be an opportunity for crypto investors to buy a crypto or NFT at a lower price.
Bullish
Borrowed finance slang meaning someone is optimistic that a market will increase in value aka moon.
Bull market
When the Crypto or NFT market is going up and up in value.
Burn
Common crypto strategy to destroy or delete tokens from the circulation supply intentionally and permanently in order to limit supply and increase the value.
Buying on secondary
Whenever you don’t mint an NFT directly from the project, you can always buy it in secondary NFT marketplaces like OpenSea. Most NFT sales are secondary market sales.
C
Cappin or Capping
Slang for lying or faking. Opposed to no cap which means “no lie”.
Coinbase
Nasdaq listed US cryptocurrency exchange. Coinbase Wallet is one of Coinbase’s products where users can use a Chrome extension or app hot wallet to store crypto and NFTs.
Cold wallet
Otherwise called hardware wallet or cold storage. It’s a physical device to store your cryptocurrencies and/or NFTs offline. They are not connected to the Internet so are at less risk of being compromised.
Collection
A set of NFTs under a common theme as part of a NFT drop or an auction sale in marketplaces like OpenSea or Rarible.
Collectible
A collectible is an NFT that is a part of a wider NFT collection, usually part of a 10k project, PFP project or NFT Game.
Collector
Someone who buys NFTs to build an NFT collection, be part of a NFT community or for speculative purposes to make a profit.
Cope
The opposite of FOMO. When someone doesn’t buy an NFT because one is still dealing with a previous mistake of not FOMOing at a fraction of the price. So choosing to stay out.
Consensus mechanism
Method of authenticating and validating a transaction on a blockchain without the need to trust or rely on a central authority. Examples of consensus mechanisms are Proof of Work (PoW) or Proof of Stake (PoS).
Cozomo de’ Medici
Twitter alias used by Snoop Dogg for crypto and NFT chat.
Creator
An NFT creator is a person that creates the asset for the NFT idea, vision and in many cases the art (e.g. a jpeg, audio file, video file).
Crowsale
Where a crowdsale is the sale of a token that will be used in the business, an Initial Coin Offering (ICO) is the sale of a token that’s linked to the value of the business. Buying an ICO token is akin to buying stock in the company because it entitles you a share of the earnings and profits. Also, some tokens give you voting rights similar to holding stock in the business. The US Securities and Exchange Commission recently ruled that ICOs, but not crowdselling, will be treated as the sale of a security. This basically means that all ICOs must be registered like IPOs and offered only to accredited investors. This dramatically increases the costs and limits the pool of potential buyers.
Crypto Bags/Bags
Refers to how much cryptocurrencies someone holds, as in their bag of coins.
Cryptocurrency
The native coin of a blockchain (or protocol coin), secured by cryptography to be exchanged within a Peer 2 Peer economic system. E.g: Bitcoin (BTC) for the Bitcoin blockchain, Ether (ETH) for the Ethereum blockchain, etc.
Crypto community
The community of a specific crypto or NFT project. NFT communities use Twitter and Discord as their primary social media to hang out.
Crypto exchange
Where someone can buy, sell or trade cryptocurrencies and tokens.
Cryptography
The foundation of blockchain technology. The use of mathematical theory and computer science to encrypt or decrypt information.
CryptoKitties
One of the first and most popular NFT based blockchain games. In 2017, the NFT project almost broke the Ethereum blockchain and increased the gas prices dramatically.
CryptoPunk
Currently one of the most valuable blue chip NFT projects. It was created by Larva Labs. Crypto Punk holders flex their NFT as their profile picture on Twitter.
CT
Crypto Twitter, the crypto-community on Twitter.
Cypherpunks
Movement in the 1980s, advocating for the use of strong cryptography and privacy-enhancing technologies as a route to social and political change. The movement contributed and shaped blockchain tech as we know today.
D
DAO
Stands for Decentralized Autonomous Organization. When a NFT project is structured like a DAO, it grants all the NFT holders voting rights, control over future actions and the NFT’s project direction and vision. Many NFT projects are also organized as DAO to be a community-driven project.
Dapp
Mobile or web based decentralized application that interacts on a blockchain via smart contracts. E.g: Dapp is the frontend and the smart contract is the backend.
DCA
Acronym for Dollar Cost Averaging. An investment strategy to reduce the impact of crypto market volatility. E.g: buying into a crypto asset on a regular monthly basis rather than a big one time purchase.
Ded
Abbreviation for dead like "I sold my Punk for 90 ETH. I am ded."
DeFi
Short for Decentralized Finance. Blockchain alternative for traditional finance, where intermediaries like banks or brokerages are replaced by smart contracts to offer financial services like trading, lending, earning interest, insure, etc.
Degen
Short for degenerate, a gambler who buys into unaudited or unknown NFT or DeFi projects, without proper research hoping to chase high profits.
Delist
No longer offer an NFT for sale on a secondary market like Opensea. NFT Marketplaces can delist an NFT that infringes their rules. Or NFT owners can choose to delist their NFTs (has long as they have sufficient funds for the gas fees) due to price surges to avoid their NFT being bought or sold for a higher price.
Derivative
Projects derived from the original project that reinforces the value and importance of the original NFT. E.g: "alternative" punks.
Dev
A skilled professional who can build NFT projects using smart contracts and blockchain technology.
Dex
Decentralised Exchange that allows for peer-to-peer trustless transactions that don’t rely on a centralized authority to take place. E.g: Uniswap, PancakeSwap, dYdX, Curve Finance, SushiSwap, 1inch, etc.
Diamond Hands
Someone who believes and holds a cryptocurrency or NFT regardless of the crypto or NFT market fluctuations.
Discord
Chat app heavily used by crypto and NFT communities for knowledge sharing and shilling.
DLT
Acronym for Distributed Ledger Technology. It’s a protocol that allows the secure functioning of a decentralized database, through cryptography. This technological infrastructure scraps the need for a central authority to keep in check manipulation or exploitation of the network.
Dog coin
It’s a memecoin based on the Japanese dog breed, Shiba Inu, first popularised by Dogecoin. Other notable coins are Shiba Inu or Floki Inu. These dog coins are frequently subjected to pump and dumps and are extremely volatile. The original dog coin DOGE was created as a joke in 2013. Elon Musk is one of Dogecoin's most famous supporters.
Doxxed/Doxed
When the identity of an NFT team member, dev or creator is public, known or verifiable. In the NFT market, when a NFT team is doxed it’s a usually sign of confidence and transparency for NFT collectors to ensure they will not be scammed for an anonymous creator.
Drop
The release of an NFT (single or collection) into the NFT market.
DYOR
Acronym for Do Your Own Research. A common expression used in the crypto or NFT community to disclaim responsibility for the financial/strategy advice someone is providing the community and to avoid being called out by others in theNFT or crypto community.
E
EIP-1559 EIP
Referring to Ethereum Improvement Proposal 1559, commonly known as the London Fork. It’s an upgrade to the Ethereum protocol code to improve the blockchain security and scalability. The major change consists in shifting from a proof-of-work consensus mechanism (PoW) to a low energy and lower gas fees proof-of-stake system (PoS).
ERC-1155
Stands for Ethereum Request for Comment-1155. A multi-token standard that can represent any number of fungible (ERC-20) and non-fungible tokens (ERC-721).
ERC-20
Ethereum Request for Comment-20 is a standard defining a fungible token like a cryptocurrency.
ERC-721
Ethereum Request for Comment-721 is a standard defining a non-fungible token (NFT).
ETH
Aka Ether, the currency symbol for the native cryptocurrency of the Ethereum blockchain.
ETH2.0
Also known as the London Fork or EIP-1559 EIP. It’s an upgrade to the Ethereum network to improve the network’s security and scalability. The most dramatic change is the shift from the proof-of-work consensus mechanism (PoW) to proof-of-stake system (PoS).
Ether
Or ETH, the native cryptocurrency of the Ethereum blockchain.
Ethereum
Network protocol that allows users to create and run smart contracts over a decentralized network.
F
FCFS
Acronym for First Come First Served. Commonly used strategy in a NFT collection drop when the demand surpasses the supply.
Few
Short for "few understand". Similar to the irony behind the "probably nothing" expression. Like X person bought into a popular NFT, because it understands its long term value.
Fiat Currencies or Money
National government-issued currencies like the US Dollar (USD), Euro (EUR) or Great British Pound (GBP) that are not backed by a commodity like silver or gold. FIAT means an authoritative or arbitrary order like a government decree.
Flex
Slang for showing off. In the crypto community, it’s a Lamborghini or a gold Rolex. In the NFT world, it’s a CryptoPunk or BAYC PFP on Twitter.
Flip
Quickly buying and selling crypto or NFTs to make a profit.
Flippening
Colloquial expression coined in 2017 for when Ethereum’s market capitalisation surpasses Bitcoin’s.
Floor Price
It means the lowest asking price for an NFT collection or subset of a collection on a secondary market like OpenSea.
Floor Sweep
Refers when a NFT collector or investor buys all the lowest listed NFTs on a secondary NFT marketplace.
FOMO
Acronym for Fear Of Missing Out. Buying a crypto or NFT out of fear of missing out on the next big thing.
FOMO-in
Buying a crypto or NFT regardless if it's at the top of the market for FOMO.
Fractionalize
Turning one NFT like a Crypto Punk into X number of fractions ERC-20 tokens that prove ownership of that Punk. This allows for i) collective ownership of an NFT, ii) making an expensive NFT affordable for the common NFT collector and iii) adds more liquidity to a very illiquid NFT market.
FR
Abbreviation for For Real?
Fren
Means Friend and what people in the NFT community call each other in an endearing and positive way.
Foundation
An exclusive, by invitation only, NFT marketplace that specializes in NFT art.
Fungible
Means X can be traded for another X and still hold the same value. E.g: My dollars = your dollars. My 1 ether = your 1 ether. My casino chip = your casino chip. On Ethereum, fungible tokens are defined by the ERC-20 standard.
FUD
Acronym for Fear Uncertainty Doubt. It can be a) when someone spreads negative and sometimes false news to discredit a certain crypto or NFT project. Or b) the overall negative feeling regarding the future of the NFT/Crypto project or market, especially when going through a bear market.
Fudder
Someone who has FUD or engages in FUD about a NFT project.
Fudding your own bags
When an NFT collector or crypto investor speaks negatively about an NFT or crypto project he/she has invested in or has a stake in. Usually negative comments about the team or vision.
G
G
Means Gangster. A term of endearment used amongst the NFT Community.
Gas/Gas fees/Gas prices
The fee charged to complete a transaction in a blockchain. These gas prices vary tremendously between the blockchains, the consensus mechanism used to validate transactions or the number of transactions being made at a specific time.
Gas war
When a lot of NFT collectors (or bots) are trying to mint an NFT at once and therefore resulting in gas price surge.
Generative art
Artwork that is algorithmically created by code with unique traits and rarity.
Genesis drop
It refers to the first NFT drop a creator makes on an NFT auction platform.
GG
Interjection for Good Game.
GM
Interjection for Good Morning.
GMI
Acronym for Going to Make It. Opposite of NGMI (NOT Going to Make It).
GOAT
Acronym for Greatest Of All Time.
GTD
Acronym for Going To Dust. When a token or NFT project turns out to be a bad investment.
GTFO
Get The F*ck Out, as in “gtfo with that fud dude” if someone is talking bull.
GWEI
One billionth of an Ether (ETH) also known as a Shannon / Nanoether / Nano — unit of account used to price Ethereum gas transactions.
H
HEN (Hic Et Nunc)
A popular NFT art marketplace for art built on the Tezos blockchain. Big NFT marketplace for inexpensive NFTs but not a very user-friendly UI/website.
HODL
Misspelling of HOLD coined in an old Reddit post. Synonym with “Hold On for Dear Life” meaning hold your coin or NFT until the end, whether that they’ll moon or dust.
Hot wallet
Wallets connected to the Internet, less secure than cold wallet because they’re more susceptible to hacks.
Hype
Term used to show excitement or anticipation about an upcoming crypto project or NFT.
I
ICO
Acronym for Initial Coin Offering. It’s the crypto equivalent to a stocks’ IPO (Initial Public Offering) but with far less scrutiny or regulation (leading to a lot of scams). ICO’s are a popular way for crypto projects to raise funds.
IDO
Acronym for Initial Dex Offering. To put it simply it means to launch NFTs or tokens via a decentralized liquidity exchange. It’s a common fundraising method used by upcoming crypto or NFT projects. Many consider IDOs a far better fundraising alternative to ICOs.
IDK
Acronym for I Don’t Know.
IDEK
Acronym for I Don’t Even Know.
Imma
Short for I’m going to be.
IRL
Acronym for In Real Life. Refers to the physical world outside of the online/virtual world of crypto, NFTs, gaming or social media.
IPFS
Acronym for Interplanetary File System. A peer-to-peer file storage system using hashes to recall and preserve the integrity of the file, commonly used to store NFTs outside of the blockchain.
It’s Money Laundering
Someone can use this expression to suggest that NFT prices aren’t real and that actually people are using NFTs to launder money, without providing much proof or explanation on how it works.
IYKYK
Stands for If You Know, You Know This. Similar to the expression "few", used when someone buys into a popular crypto or NFT project, slightly because of FOMO but also because it believes in its long term value.
J
JPEG/JPG
File format typically used to encode NFT art. Some people also use Jpeg to mock people buying NFTs as in “All that money for a jpeg”.
K
KMS
Short for Kill MySelf.
L
Larva Labs/ LL
NFT Creators behind the popular NFT projects like Cryptopunks,Meebits or Autoglyphs.
Laser eyes
Bitcoin meme signalling support for BTC and/or it will break the $100k per coin valuation.
LFG
Acronym for Let’s F*cking Go! A common rallying call used in the crypto or NFT community to lead people into buying an NFT or a crypto.
Liquidity
Term that means that a token or NFT has a high volume activity in the crypto/NFT market. It’s easily sold and resold. But usually the NFT market it’s illiquid when compared to the general crypto market, due to the non-fungibility nature of an NFT (there are less buyers for every NFTs out there).
LMFAO
Stands for Laughing My F*cking Ass Off.
Looks Rare
Ironic expression commonly used in the NFT Community. Rarity is a driver of an NFT’s value.
London Hard Fork
Known as EIP-1559, was an Ethereum code upgrade proposal designed to improve the blockchain security and scalability. It’s major change is to shift from PoW to PoS consensus mechanism.
Long run
Means someone is committed to the NFT market or an NFT project in the long term.
M
Maximalist
Typically refers to Bitcoin Maximalists. People who only believe that Bitcoin is the most secure and resilient blockchain. For Maximalists, all other cryptocurrencies are shitcoins therefore a waste of time, development and money.
McDonald's
Common and ironic expression amongst the crypto community. It means that Mcdonald’s is always a valid backup plan or career in the case all cryptocurrencies crash and disappear.
Meatspace
Synonymous with IRL - In Real Life.
Memecoin
Cryptocurrency like Dogecoin that is based on an internet joke or meme.
Metamask
Popular crypto hot wallet platform to store crypto and NFTs.
Metaverse
Term was coined by writer Neal Stephenson in the 1992 dystopian novel “Snow Crash”. It’s an immersive and digital place where people interact via their avatars. Big tech players like Meta (formerly known as Facebook) and other independent players have been designing their own version of a metaverse. NFTs can have utility for users like buying, trading, winning, accessing, experiencing or interacting with things inside a metaverse.
Mfer
Short for “mother fker”.
Miners
Single person or company that mines one or more cryptocurrencies like Bitcoin or Ethereum. Both blockchains need computing power for their Proof of Work consensus mechanism. Miners provide the computing power and receive coins/tokens in return as payment.
Mining
Mining is the process by which new tokens enter in circulation as for example in the Bitcoin blockchain. Also, mining ensures the validity of new transactions happening in a given blockchain that uses the PoW consensus mechanism. Therefore, the ones who mine are rewarded by ensuring the validity of a blockchain.
Mint/Minting
Mint an NFT is the act of publishing your unique instance to a specific blockchain like Ethereum or Tezos blockchain. In simpler terms, a creator is adding a one-of-kind token (NFT) into circulation in a specific blockchain.
Once the NFT is minted - aka created - NFT collectors can i) direct mint, therefore purchase the NFT by paying the specified amount directly into the project’s wallet. Or ii) buy it via an intermediary like an NFT marketplace (e.g: OpenSea, Foundation, Rarible, etc.). Later, the NFT owner can choose to resell the NFT, most NFT creators set up a royalty for every time their NFT is resold.
Minting interval
How often an NFT creator can mint or create tokens.
MOAR
A misspelling that means “more”.
Moon/Mooning
When a coin (e.g. ETH), or token, like an NFT goes exponential in price and the price graph sees a vertical climb. Crypto or NFT users then use the expression that “X token is going to the moon!”.
Moon boys
Slang for crypto or NFT holders who are looking to pump the price dramatically - taking a token to the moon - for short term gains and with no real long term vision or commitment.
N
Never trust, always verify
Treat everyone or every project like something potentially malicious.
New coiner
Crypto slang for someone new to the cryptocurrency space. Usually newcomers can be more susceptible to FUD or scammers.
NFA
Acronym for Not Financial Advice.
NFT
Acronym for Non-Fungible Token. The type of token that can be created, bought, sold, resold and viewed in different dapps. The ERC-721 smart contract standard (Ethereum blockchain) is the most popular amongst NFTs.
NFT Marketplace / NFT Auction platform
Platforms where people can sell and buy NFTs, either via an auction or pay the seller’s price. The largest NFT marketplace is OpenSea. But there are other popular NFT marketplace examples like Foundation, SuperRare, Nifty Gateway, Rarible, Hic et Nunc (HeN), etc.
NFT Whale
A NFT collector or investor who buys a large amount of NFTs.
NGMI
Acronym for Not Going to Make It. For example, something said to someone who has paper hands.
NMP
Acronym for Not My Problem.
Nocoiner
It can be someone who simply doesn’t hold cryptocurrencies, mistrust the crypto market or believes that crypto is either a scam or a ponzi scheme.
Noob/N00b/Newbie
Slang for someone new or not experienced in cryptocurrency or NFTs. These people are more susceptible to scams, drawn into pump and dumps or getting rekt on bad coins.
Normie/Normy
Similar expression for a nocoiner.
NSFW
Acronym for Not Suitable For Work. Referring to online content inappropriate for viewing in public or at work. It began as mostly a tag for sexual content, nudity, or violence, but it has envolved to range a number of other topics that might be delicate or trigger viewers.
Nuclear NFTs
An NFT or collectible with more than 1,000 owners. For the NFT to be sold or resold, every co-owners must give their permission beforehand. Otherwise, the NFT transaction can’t be made.
O
OG
Acronym for Original Gangster and it popularized by 90s Hip Hop culture. It means the first, the original or the person who has been around since the very start and earned respect in the community. In NFT terms, Cryptopunks are the OG of NFTs.
On-chain vs Off-chain
An on-chain NFT is when the artwork (like a jpeg, video or music file) is stored directly into the blockchain making it more secure and less susceptible to being stolen. But, note that most blockchains can only store small amounts of data.
Off-chain NFTs means that the high quality image, music or video file is not stored in the blockchain. But, the NFT data is stored on an external party like a) a centralized server, highly vulnerable to the server being shut down/exploited. Or b) an InterPlanetary File System (IPFS), also an external party but more secure way of finding data because it utilizes a distributed, decentralized system.
OpenSea
By far the largest NFT marketplace in the world, currently.
P
Paper Hands
A crypto or NFT holder who is permeable to negative market sentiment or FUD. And does not hold their crypto or NFT for long. Expression used to describe someone who sells as soon as NFTs enter a bear market.
PFP
Stands for Picture For Profile. Twitter users who hold popular NFTs like Crypto Punk or BAYC use their punk or monkey avatar as their profile picture.
POAP NFT
Stands for Proof of Attendance Protocol. These types of NFTs are awarded to attendees of events, regardless if they’re physical or virtual, as proof you attended.
PoS
Stands for Proof of Stake. A consensus mechanism used by blockchains like Bitcoin or Ethereum to achieve agreement, trust and security in every transaction and keep the integrity of the blockchain intact. PoS mechanisms are considered more environmentally friendly than PoW as they’re lower energy and in emissions.
PoW
Stands for Proof of Work. A consensus mechanism used by blockchains like Bitcoin to achieve agreement, trust and security and keep the transactional integrity of the blockchain intact. PoW mechanism requires a lot of computational power, therefore uses more energy resources and higher CO2 emissions than the PoS mechanism.
Private Key
It can be similar to a password. It’s a secret number that allows users to access their cold or hot wallet funds, prove ownership of a certain address and sign transactions on the blockchain.
It’s not advisable to share a private key with anyone as it makes a person vulnerable to thefts. In case someone loses or forgets its private key, it can use a recovery phrase to restore access to a crypto or NFT wallet.
Pre-mine
A term used in crypto to refer to the act of creating a set amount of tokens before their public launch. It can also be known as a Genesis Sale and is usually associated with Initial Coin Offerings (ICOs) in order to compensate founders, developers or early investors.
Probably nothing
It’s an ironic expression used by NFT enthusiasts to refer to an important or soon to be big news, project or person in the NFT space. Meaning when someone says probably nothing it actually means that it is probably something.
Protocol Coin
Stands for the native coin of a blockchain. As in Ether for the Ethereum blockchain or BTC on the Bitcoin blockchain.
Pump & Dump
The term pump means when a person or a group of people buy or convince others to buy large quantities of a crypto or an NFT with the single goal to drive the price to a peak. When the price peaks, these people sell their position high and for a hefty profit, therefore dumping the price and leaving other slower investors or newbies rekt or at a loss.
R
Rarity
Rarity in NFT terms refers to how rare an NFT is. The rarity can be defined by the number of traits, scarcity or properties of an NFT.
Reaching
Slang for an exaggeration over something to make it sound worse than what it actually is or to take a point/scenario too far.
Recovery phrase
A 12-word phrase that acts like backup for your crypto private keys. A person can recover all of the crypto wallet accounts’ private keys from the recovery phrase. Is not advisable to share the recovery phrase with anyone.
Rekt
Slang for wrecked. When a crypto or NFT project goes wrong or down in value sharply. Or more broadly, when something goes wrong like a person is price out by the gas surge or an NFT floor price goes down.
Right Click Save As
An Ironic expression used by people who don’t understand the value or potential unlocked by NFTs. Person who makes fun that she/he can easily get a digital artwork by Right Click Save As and mock the NFT space and its hype.
Roadmap
The strategy outlined by an NFT project. A way to explain to the NFT community or a potential NFT investor, the different stages, value and the long term vision of the NFT project.
Royalties
NFT creators can set up their NFT so each time their NFT is resold, the creator gets paid a percentage of the sale price.
RN
Acronym for Right Now.
Rug Pull/Rugged
Slang for a scam when the founders, team or developers suddenly leave a crypto project and run away with all the investors’ funds leaving them with nothing.
S
Satoshi Nakamoto
The anonymous creator of the Bitcoin whitepaper and whose identity has never been verified.
Scammer
Someone actively trying to steal other people’s crypto or NFTs.
Secondary
Secondary refers to secondary NFT marketplaces, where NFT collectors or investors can resell NFTs after they’ve been minted. The price of an NFT or NFT collection is determined by those who list them.
Seed phrase
Another name for recovery phrase is the 12-word phrase that allows you to recover all of the crypto wallet accounts’ private keys and regain control of the wallet. Is not advisable to share the seed phrase with anyone.
Seems legit
When an NFT project or a person in the NFT community looks promising and the real deal, meaning seems legitimate. Depending on the context can also be used ironically.
Seems rare
An ironic expression or dismissive comment used by the NFT community. For example, It can be used sarcastically when someone asks for feedback on an NFT they own or created.
Ser
Slang for sir and a polite way of addressing others in an NFT community.
Shill
Expression when someone wants to promote or get exposure to an NFT they own or created.
Shill Thread
It’s a common Twitter strategy to gain traction by encouraging NFT creators to share a link to their NFT project in the hopes of getting bought or noticed by the NFT Community and potential buyers.
Simp/Simping
A NFT holder or creator who comes off as trying to hard impress an NFT whale or investor.
Sh*tposter
A person who mostly posts meme content on Twitter for fun.
SLP
Acronym for Smooth Love Potion. It’s a token players can earn as a reward in the NFT game Axie Infinity.
Smart Contract
A self-executing contract where the terms of the agreement between buyer and seller are directly written into the code and without third party or human intervention. Ethereum is a blockchain that can execute smart contracts, on the contrary to Bitcoin which does not have that capability.
SMFH
Acronym for Shaking My F*cking Head. Common reply to a person showing unbelievable idiocy.
Sock Puppet
Scam account used to lure noob investors into fake investment services.
Snag
It means to buy an NFT quickly and for a very low price. Can also be known as sniping.
Sotheby’s
Very famous auction house that has recently auctioned Beeple’s NFTs or Bored Ape Yacht Club and Crypto Punks’ NFT collections.
Stake
Crypto term for locking up a certain amount of crypto tokens for a set period of time to earn interest. In the NFT space, there are popping up a lot of projects or services that allow NFT holders to earn interest for holding a certain NFT.
Szn
Stands for season referring to crypto or NFT market cycles.
T
TINA
Acronym for There Is No Alternative. Example: someone asks “why are you investing in BTC?”, to which the reply is “TINA”.
TINA RIF
Acronym for There Is No Alternative Resistance Is Futile.
This is the way
A commendation for positive behavior by someone in the NFT Community.
Tokenomics
Referring to the economics of cryptocurrencies, DeFi or NFT projects.
V
Valhalla
Ironic use of the Viking “heaven”. Meaning someone’s NFT collection is either going to be a profitable and blue chip project, therefore they can ascend to Valhalla or is going to tank and that person will have to work at a Mcdonald’s.
Vibe
Term used to express a positive emotional state.
Volatile/Volatility
Term used to describe rapid market fluctuations and crypto or NFT prices go up and down quickly in a short period.
W
WAGMI
Acronym for We Are Going to Make It. Rally cry to build momentum for a crypto or NFT project and lead even more people into buying, shilling or supporting a specific project.
Wallet
There can be a hot or cold wallet, but both are a place where someone can store their cryptocurrency and tokens. Hot wallets are always connected to the Internet like MetaMask, Trust wallet or Phantom. On the contrary cold wallets are hardware wallets to store crypto or NFTs offline like Nano Ledger.
Weak Hands
Synonymous with Paper Hands. Someone who immediately sells their crypto or NFT because of a bear market, FUD or any other negative sentiment.
Web 1.0
Refers to the beginning of the Web. A period from around 1990 to 2005, also known as the read-only web.
Web 2.0
Refers to an iteration of Web 1.0. From 2005 to the present moment, where social media platforms like Facebook, Instagram, TikTok, Google, Twitter, etc reshaped the web, therefore becoming the read-write web.
Web 3.0
A term coined by Ethereum co-founder Gavin Wood and it’s an idea of what the future of the web could look like. Most peoples’ data, info or content would no longer be centralized in Web 2.0 giants - the Big Tech - but decentralized, mostly thanks to blockchain technology. Web 3.0 could be known as read-write-trust web.
Wen
As in When.
Wen Moon
Popular expression from crypto Twitter not so much in the NFT space. Refers to the still distant future when a token will moon.
Whitepaper
Document released by a crypto or NFT project where it lays the technical information behind the concept, vision, roadmap and plans to grow a certain project.
Whale
Someone who owns a large position on a specific or many cryptos or NFTs.
Y
Yodo
Acronym for You Only Die Once. The opposite of Yolo.
Yolo
Acronym for You Only Live Once. A person can use this when they just realized they bought a shitcoin or crap NFT and they’re getting rekt.
Original post