




More on Web3 & Crypto

Rishi Dean
3 years ago
Coinbase's web3 app
Use popular Ethereum dapps with Coinbase’s new dapp wallet and browser
Tl;dr: This post highlights the ability to access web3 directly from your Coinbase app using our new dapp wallet and browser.
Decentralized autonomous organizations (DAOs) and decentralized finance (DeFi) have gained popularity in the last year (DAOs). The total value locked (TVL) of DeFi investments on the Ethereum blockchain has grown to over $110B USD, while NFTs sales have grown to over $30B USD in the last 12 months (LTM). New innovative real-world applications are emerging every day.
Today, a small group of Coinbase app users can access Ethereum-based dapps. Buying NFTs on Coinbase NFT and OpenSea, trading on Uniswap and Sushiswap, and borrowing and lending on Curve and Compound are examples.
Our new dapp wallet and dapp browser enable you to access and explore web3 directly from your Coinbase app.
Web3 in the Coinbase app
Users can now access dapps without a recovery phrase. This innovative dapp wallet experience uses Multi-Party Computation (MPC) technology to secure your on-chain wallet. This wallet's design allows you and Coinbase to share the 'key.' If you lose access to your device, the key to your dapp wallet is still safe and Coinbase can help recover it.
Set up your new dapp wallet by clicking the "Browser" tab in the Android app's navigation bar. Once set up, the Coinbase app's new dapp browser lets you search, discover, and use Ethereum-based dapps.
Looking forward
We want to enable everyone to seamlessly and safely participate in web3, and today’s launch is another step on that journey. We're rolling out the new dapp wallet and browser in the US on Android first to a small subset of users and plan to expand soon. Stay tuned!

Ann
3 years ago
These new DeFi protocols are just amazing.
I've never seen this before.
Focus on native crypto development, not price activity or turmoil.
CT is boring now. Either folks are still angry about FTX or they're distracted by AI. Plus, it's year-end, and people rest for the holidays. 2022 was rough.
So DeFi fans can get inspired by something fresh. Who's building? As I read the Defillama daily roundup, many updates are still on FTX and its contagion.
I've used the same method on their Raises page. Not much happened :(. Maybe my high standards are to fault, but the business may be resting. OK.
The handful I locate might last us till the end of the year. (If another big blowup occurs.)
Hashflow
An on-chain monitor account I follow reported a huge transfer of $HFT from Binance to Jump Tradings.
I was intrigued. Stacking? So I checked and discovered out the project was launched through Binance Launchpad, which has introduced many 100x tokens (although momentarily) in the past, such as GALA and STEPN.
Hashflow appears to be pumpable. Binance launchpad, VC backers, CEX listing immediately. What's the protocol?
Hasflow is intriguing and timely, I discovered. After the FTX collapse, people looked more at DEXs.
Hashflow is a decentralized exchange that connects traders with professional market makers, according to its Binance launchpad description. Post-FTX, market makers lost their MM-ing chance with the collapse of the world's third-largest exchange. Jump and Wintermute back them?
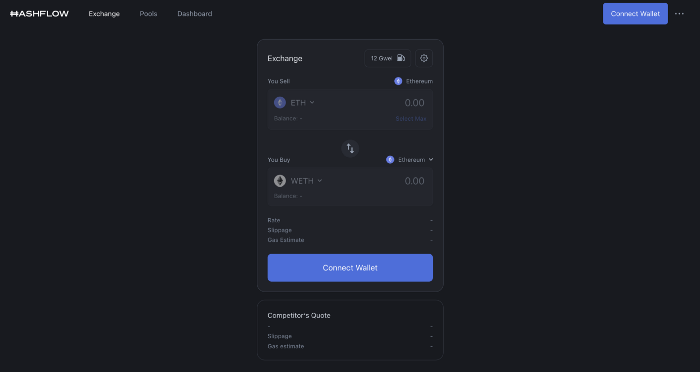
Why is that the case? Hashflow doesn't use bonding curves like standard AMM. On AMMs, you pay more for the following trade because the prior trade reduces liquidity (supply and demand). With market maker quotations, you get a CEX-like experience (fewer coins in the pool, higher price). Stable prices, no MEV frontrunning.
Hashflow is innovative because...
DEXs gained from the FTX crash, but let's be honest: DEXs aren't as good as CEXs. Hashflow will change this.
Hashflow offers MEV protection, which major dealers seek in DEXs. You can trade large amounts without front running and sandwich assaults.
Hasflow offers a user-friendly swapping platform besides MEV. Any chain can be traded smoothly. This is a benefit because DEXs lag CEXs in UX.
Status, timeline:
Wintermute wrote in August that prominent market makers will work on Hashflow. Binance launched a month-long farming session in December. Jump probably participated in this initial sell, therefore we witnessed a significant transfer after the introduction.
Binance began trading HFT token on November 11 (the day FTX imploded). coincidence?)
Tokens are used for community rewards. Perhaps they'd copy dYdX. (Airdrop?). Read their documents about their future plans. Tokenomics doesn't impress me. Governance, rewards, and NFT.
Their stat page details their activity. First came Ethereum, then Arbitrum. For a new protocol in a bear market, they handled a lot of unique users daily.
It’s interesting to see their future. Will they be thriving? Not only against DEXs, but also among the CEXs too.
STFX
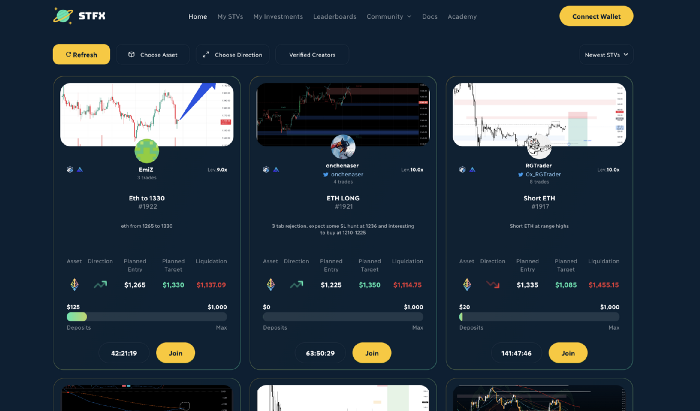
I forget how I found STFX. Possibly a Twitter thread concerning Arbitrum applications. STFX was the only new protocol I found interesting.
STFX is a new concept and trader problem-solver. I've never seen this protocol.
STFX allows you copy trades. You give someone your money to trade for you.
It's a marketplace. Traders are everywhere. You put your entry, exit, liquidation point, and trading theory. Twitter has a verification system for socials. Leaderboards display your trading skill.
This service could be popular. Staying disciplined is the hardest part of trading. Sometimes you take-profit too early or too late, or sell at a loss when an asset dumps, then it soon recovers (often happens in crypto.) It's hard to stick to entry-exit and liquidation plans.
What if you could hire someone to run your trade for a little commission? Set-and-forget.
Trading money isn't easy. Trust how? How do you know they won't steal your money?
Smart contracts.
STFX's trader is a vault maker/manager. One trade=one vault. User sets long/short, entrance, exit, and liquidation point. Anyone who agrees can exchange instantly. The smart contract will keep the fund during the trade and limit the manager's actions.
Here's STFX's transaction flow.
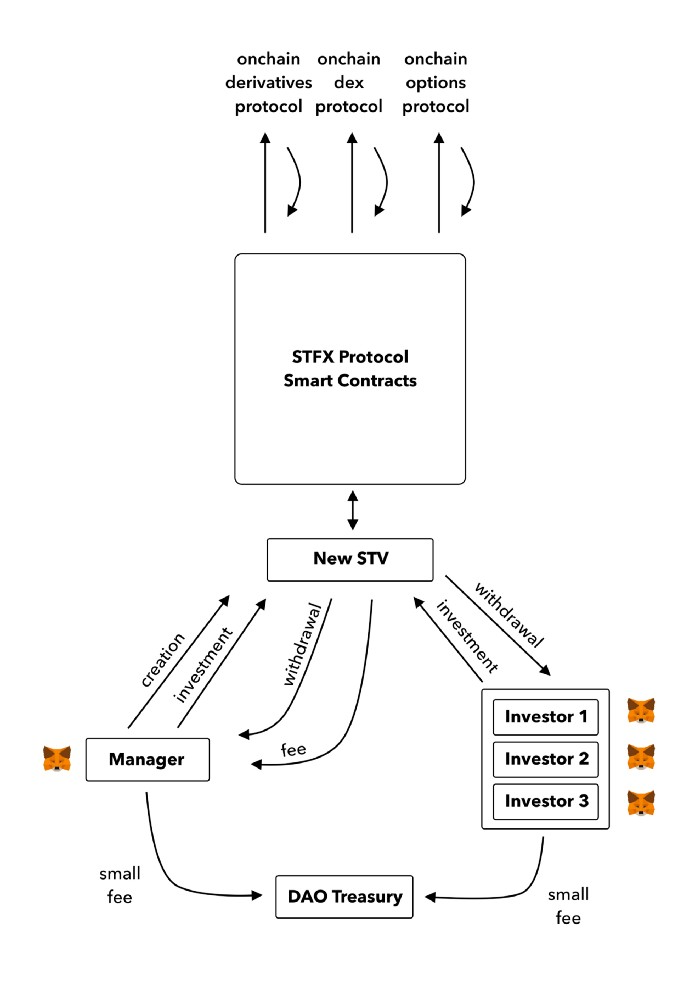
Managers and the treasury receive fees. It's a sustainable business strategy that benefits everyone.
I'm impressed by $STFX's planned use. Brilliant priority access. A crypto dealer opens a vault here. Many would join. STFX tokens offer VIP access over those without tokens.

STFX provides short-term trading, which is mind-blowing to me. I agree with their platform's purpose. Crypto market pricing actions foster short-termism. When you trade, the turnover could be larger than long-term holding or trading. 2017 BTC buyers waited 5 years to complete their holdings.
STFX teams simply adapted. Volatility aids trading.
All things about STFX scream Degen. The protocol fully embraces the degen nature of some, if not most, crypto natives.

An enjoyable dApp. Leaderboards are fun for reputation-building. FLEXING COMPETITIONS. You can join for as low as $10. STFX uses Arbitrum, therefore gas costs are low. Alpha procedure completes the degen feeling.
Despite looking like they don't take themselves seriously, I sense a strong business plan below. There is a real demand for the solution STFX offers.

Jeff John Roberts
3 years ago
Jack Dorsey and Jay-Z Launch 'Bitcoin Academy' in Brooklyn rapper's home
The new Bitcoin Academy will teach Jay-Marcy Z's Houses neighbors "What is Cryptocurrency."
Jay-Z grew up in Brooklyn's Marcy Houses. The rapper and Block CEO Jack Dorsey are giving back to his hometown by creating the Bitcoin Academy.
The Bitcoin Academy will offer online and in-person classes, including "What is Money?" and "What is Blockchain?"
The program will provide participants with a mobile hotspot and a small amount of Bitcoin for hands-on learning.
Students will receive dinner and two evenings of instruction until early September. The Shawn Carter Foundation will help with on-the-ground instruction.
Jay-Z and Dorsey announced the program Thursday morning. It will begin at Marcy Houses but may be expanded.
Crypto Blockchain Plug and Black Bitcoin Billionaire, which has received a grant from Block, will teach the classes.
Jay-Z, Dorsey reunite
Jay-Z and Dorsey have previously worked together to promote a Bitcoin and crypto-based future.
In 2021, Dorsey's Block (then Square) acquired the rapper's streaming music service Tidal, which they propose using for NFT distribution.
Dorsey and Jay-Z launched an endowment in 2021 to fund Bitcoin development in Africa and India.
Dorsey is funding the new Bitcoin Academy out of his own pocket (as is Jay-Z), but he's also pushed crypto-related charitable endeavors at Block, including a $5 million fund backed by corporate Bitcoin interest.
This post is a summary. Read full article here
You might also like

Laura Sanders
3 years ago
Xenobots, tiny living machines, can duplicate themselves.
Strange and complex behavior of frog cell blobs
A xenobot “parent,” shaped like a hungry Pac-Man (shown in red false color), created an “offspring” xenobot (green sphere) by gathering loose frog cells in its opening.
Tiny “living machines” made of frog cells can make copies of themselves. This newly discovered renewal mechanism may help create self-renewing biological machines.
According to Kirstin Petersen, an electrical and computer engineer at Cornell University who studies groups of robots, “this is an extremely exciting breakthrough.” She says self-replicating robots are a big step toward human-free systems.
Researchers described the behavior of xenobots earlier this year (SN: 3/31/21). Small clumps of skin stem cells from frog embryos knitted themselves into small spheres and started moving. Cilia, or cellular extensions, powered the xenobots around their lab dishes.
The findings are published in the Proceedings of the National Academy of Sciences on Dec. 7. The xenobots can gather loose frog cells into spheres, which then form xenobots.
The researchers call this type of movement-induced reproduction kinematic self-replication. The study's coauthor, Douglas Blackiston of Tufts University in Medford, Massachusetts, and Harvard University, says this is typical. For example, sexual reproduction requires parental sperm and egg cells. Sometimes cells split or budded off from a parent.
“This is unique,” Blackiston says. These xenobots “find loose parts in the environment and cobble them together.” This second generation of xenobots can move like their parents, Blackiston says.
The researchers discovered that spheroid xenobots could only produce one more generation before dying out. The original xenobots' shape was predicted by an artificial intelligence program, allowing for four generations of replication.
A C shape, like an openmouthed Pac-Man, was predicted to be a more efficient progenitor. When improved xenobots were let loose in a dish, they began scooping up loose cells into their gaping “mouths,” forming more sphere-shaped bots (see image below). As many as 50 cells clumped together in the opening of a parent to form a mobile offspring. A xenobot is made up of 4,000–6,000 frog cells.
Petersen likes the Xenobots' small size. “The fact that they were able to do this at such a small scale just makes it even better,” she says. Miniature xenobots could sculpt tissues for implantation or deliver therapeutics inside the body.
Beyond the xenobots' potential jobs, the research advances an important science, says study coauthor and Tufts developmental biologist Michael Levin. The science of anticipating and controlling the outcomes of complex systems, he says.
“No one could have predicted this,” Levin says. “They regularly surprise us.” Researchers can use xenobots to test the unexpected. “This is about advancing the science of being less surprised,” Levin says.

Desiree Peralta
3 years ago
Why Now Is Your Chance To Create A Millionaire Career
People don’t believe in influencers anymore; they need people like you.

Social media influencers have dominated for years. We've seen videos, images, and articles of *famous* individuals unwrapping, reviewing, and endorsing things.
This industry generates billions. This year, marketers spent $2.23 billion on Instagram, $1 million on Youtube, and $775 million on Tiktok. This marketing has helped start certain companies.
Influencers are dying, so ordinary people like us may take over this billion-dollar sector. Why?
Why influencers are perishing
Most influencers lie to their fans, especially on Instagram. Influencers' first purpose was to make their lives so flawless that others would want to buy their stuff.
In 2015, an Australian influencer with 600,000 followers went viral for revealing all her photos and everything she did to seem great before deleting her account.
“I dramatically edited the pictures, I manipulated the environements, and made my life look perfect in social media… I remember I obsessively checked the like count for a full week since uploading it, a selfie that now has close to 2,500 likes. It got 5 likes. This was when I was so hungry for social media validation … This was the reason why I quit social media: for me, personally, it consumed me. I wasn’t living in a 3D world.”
Influencers then lost credibility.
Influencers seem to live in a bubble, separate from us. Thanks to self-popularity love's and constant awareness campaigns, people find these people ridiculous.
Influencers are praised more for showing themselves as natural and common than for showing luxuries and lies.
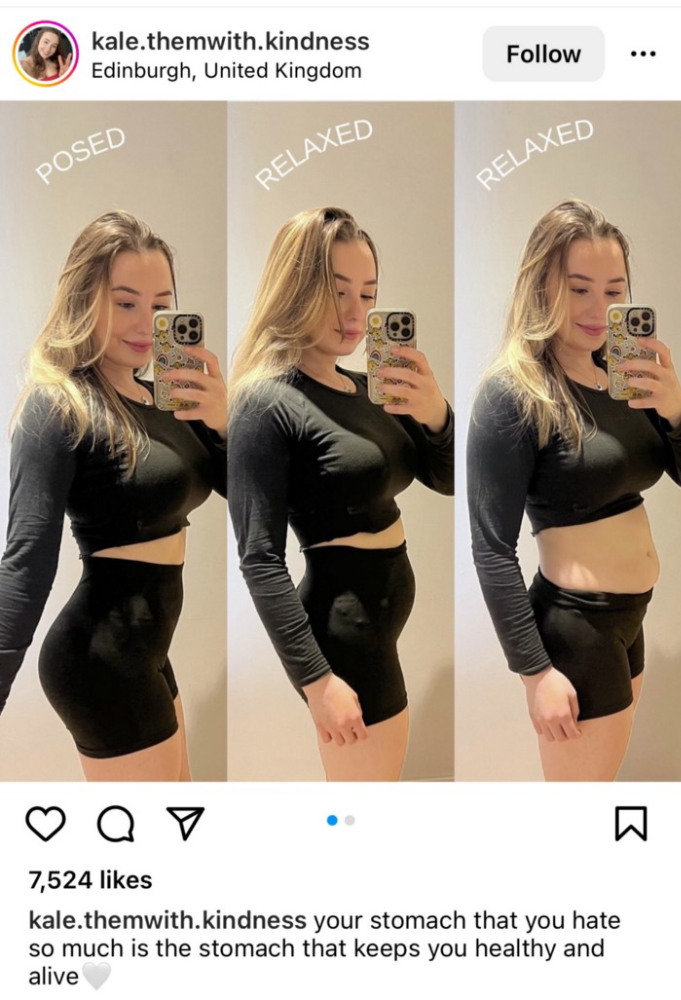
Little by little, they are dying, making room for a new group to take advantage of this multi-million dollar business, which gives us (ordinary people) a big opportunity to grow on any content creation platform we want.
Why this is your chance to develop on any platform for creating content
In 2021, I wrote “Not everyone who talks about money is a Financial Advisor, be careful of who you take advice from,”. In it, I warned that not everyone with a large following is a reputable source of financial advice.
Other writers hated this post and said I was wrong.
People don't want Jeff Bezos or Elon Musk's counsel, they said. They prefer to hear about their neighbor's restroom problems or his closest friend's terrible business.
Real advice from regular folks.
And I found this was true when I returned to my independent YouTube channel and had more than 1000 followers after having abandoned it with fewer than 30 videos in 2021 since there were already many personal finance and travel channels and I thought mine wasn't special.
People appreciated my videos because I was a 20-something girl trying to make money online, and they believed my advice more than that of influencers with thousands of followers.
I think today is the greatest time to grow on any platform as an ordinary person. Normal individuals give honest recommendations about what works for them and look easier to make because they have the same options as us.
Nobody cares how a millionaire acquired a Lamborghini unless it's entertaining. Education works now. Real counsel from average people is replicable.
Many individuals don't appreciate how false influencers seem (unreal bodies and excessive surgery and retouching) since it makes them feel uneasy.
That's why body-positive advertisements have been so effective, but they've lost ground in places like Tiktok, where the audience wants more content from everyday people than influencers living amazing lives. More people will relate to your content if you appear genuine.
Last thoughts
Influencers are dwindling. People want more real people to give real advice and demonstrate an ordinary life.
People will enjoy anything you tell about your daily life as long as you provide value, and you can build a following rapidly if you're honest.
This is a millionaire industry that is getting more expensive and will go with what works, so stand out immediately.

Scott Galloway
3 years ago
First Health
ZERO GRACE/ZERO MALICE
Amazon's purchase of One Medical could speed up American healthcare
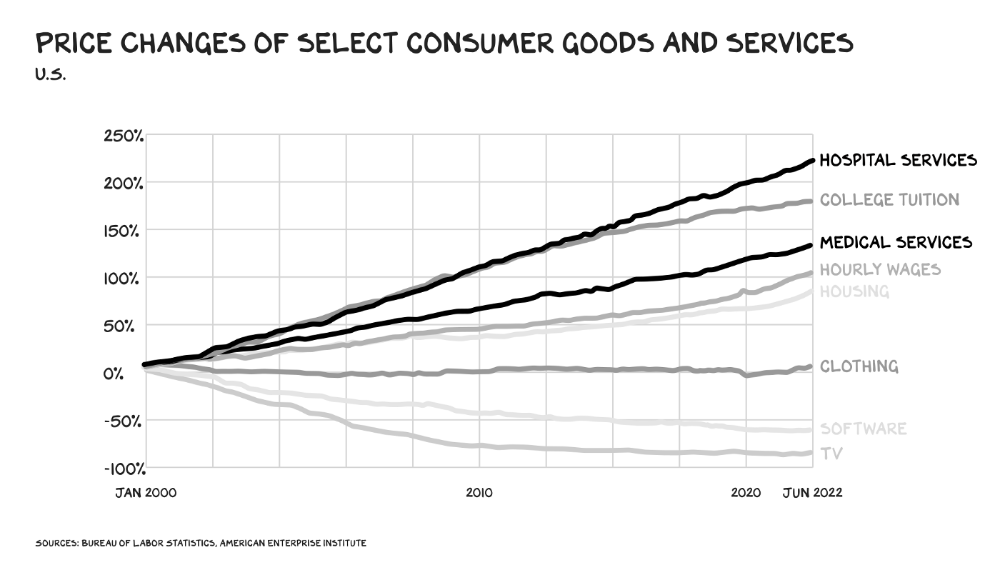
The U.S. healthcare industry is a 7-ton seal bleeding at sea. Predators are circling. Unearned margin: price increases relative to inflation without quality improvements. Amazon is the 11-foot megalodon with 7-inch teeth. Amazon is no longer circling... but attacking.
In 2020 dollars, per capita U.S. healthcare spending increased from $2,968 in 1980 to $12,531. The result is a massive industry with 13% of the nation's workers and a fifth of GDP.
Doctor No
In 40 years, healthcare has made progress. From 73.7 in 1980 to 78.8 in 2019, life expectancy rose (before Covid knocked it back down a bit). Pharmacological therapies have revolutionized, and genetic research is paying off. The financial return, improvement split by cost increases, is terrible. No country has expense rises like the U.S., and no one spends as much per capita as we do. Developed countries have longer life expectancies, healthier populations, and less economic hardship.
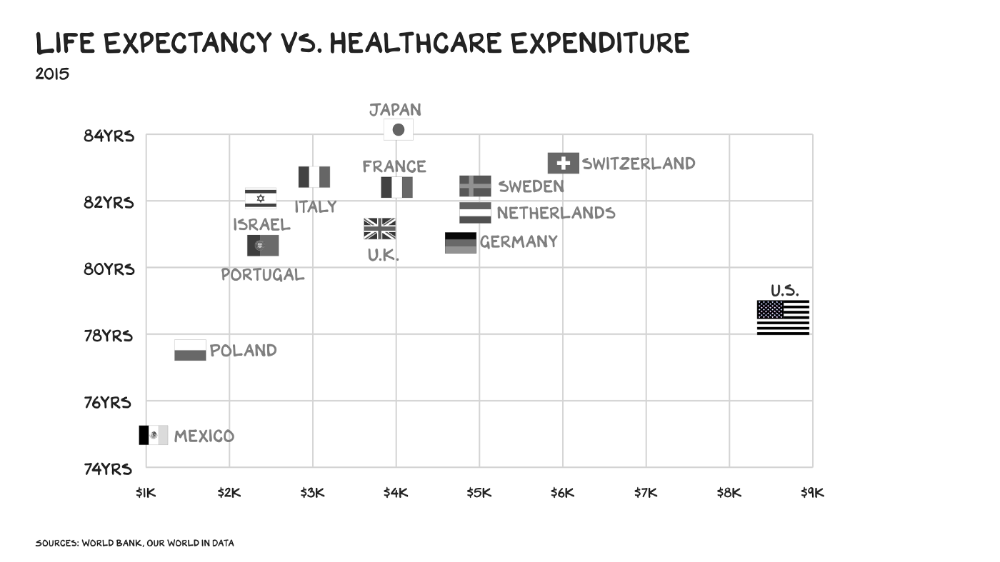
Two-thirds of U.S. personal bankruptcies are due to medical expenses and/or missed work. Mom or Dad getting cancer could bankrupt many middle-class American families. 40% of American adults delayed or skipped needed care due to cost. Every healthcare improvement seems to have a downside. Same pharmacological revolution that helped millions caused opioid epidemic. Our results are poor in many areas: The U.S. has a high infant mortality rate.
Healthcare is the second-worst retail industry in the country. Gas stations are #1. Imagine walking into a Best Buy to buy a TV and a Blue Shirt associate requests you fill out the same 14 pages of paperwork you filled out yesterday. Then you wait in a crowded room until they call you, 20 minutes after the scheduled appointment you were asked to arrive early for, to see the one person in the store who can talk to you about TVs, who has 10 minutes for you. The average emergency room wait time in New York is 6 hours and 10 minutes.
If it's bad for the customer, it's worse for the business. Physicians spend 27% of their time helping patients; 49% on EHRs. Documentation, order entry, billing, and inbox management. Spend a decade getting an M.D., then become a bureaucrat.
No industry better illustrates scale diseconomies. If we got the same return on healthcare spending as other countries, we'd all live to 100. We could spend less, live longer and healthier, and pay off the national debt in 15 years. U.S. healthcare is the worst ever.
What now? Competition is at the heart of capitalism, the worst system of its kind.
Priority Time
Amazon is buying One Medical for $3.9 billion. I think this deal will liberate society. Two years in, I think One Medical is great. When I got Covid, I pressed the One Medical symbol on my phone; a nurse practitioner prescribed Paxlovid and told me which pharmacies had it in stock.
Amazon enables the company's vision. One Medical's stock is down to $10 from $40 at the start of 2021. Last year, it lost $250 million and needs cash (Amazon has $60 billion). ONEM must grow. The service has 736,000 members. Half of U.S. households have Amazon Prime. Finally, delivery. One Medical is a digital health/physical office hybrid, but you must pick up medication at the pharmacy. Upgrade your Paxlovid delivery time after a remote consultation. Amazon's core competency means it'll happen. Healthcare speed and convenience will feel alien.
It's been a long, winding road to disruption. Amazon, JPMorgan, and Berkshire Hathaway formed Haven four years ago to provide better healthcare for their 1.5 million employees. It rocked healthcare stocks the morning of the press release, but folded in 2021.
Amazon Care is an employee-focused service. Home-delivered virtual health services and nurses. It's doing well, expanding nationwide, and providing healthcare for other companies. Hilton is Amazon Care's biggest customer. The acquisition of One Medical will bring 66 million Prime households capital, domain expertise, and billing infrastructure. Imagine:
"Alexa, I'm hot and my back hurts."
"Connecting you to a Prime doctor now."
Want to vs. Have to
I predicted Amazon entering healthcare years ago. Why? For the same reason Apple is getting into auto. Amazon's P/E is 56, double Walmart's. The corporation must add $250 billion in revenue over the next five years to retain its share price. White-label clothes or smart home products won't generate as much revenue. It must enter a huge market without scale, operational competence, and data skills.
Current Situation
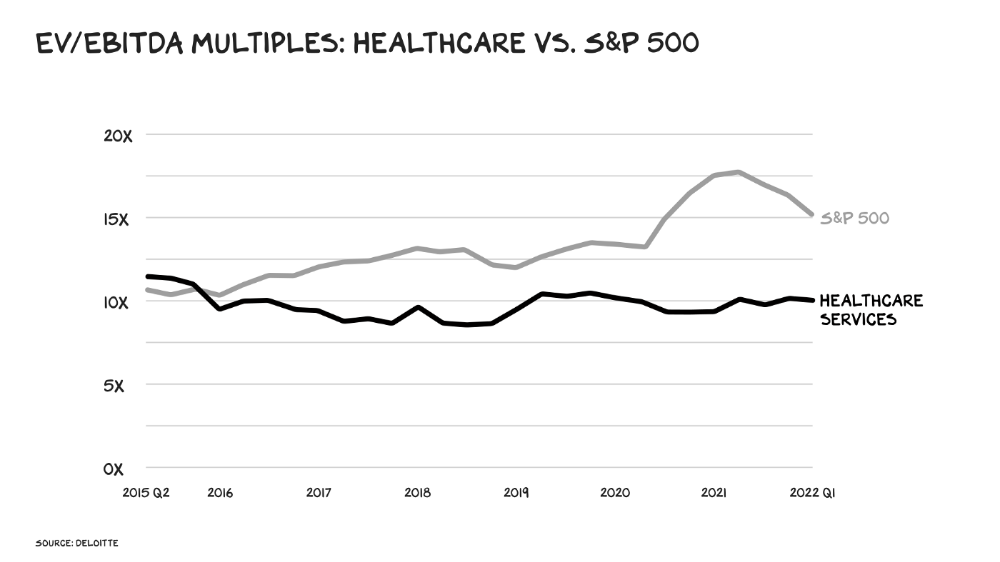
Healthcare reform benefits both consumers and investors. In 2015, healthcare services had S&P 500-average multiples. The market is losing faith in public healthcare businesses' growth. Healthcare services have lower EV/EBITDA multiples than the S&P 500.
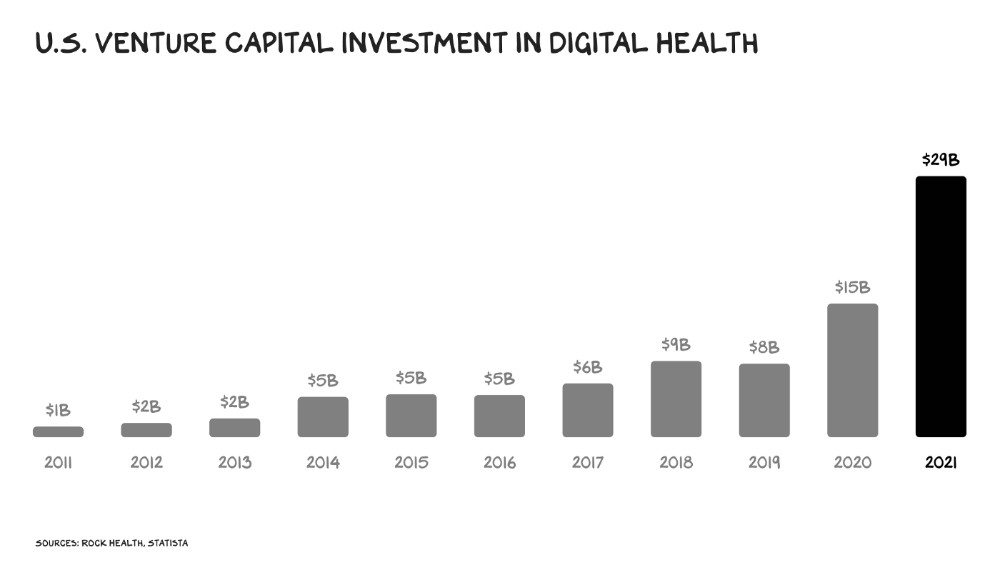
Amazon isn't the only prey-hunter. Walmart and Alibaba are starting pharmacies. Uber is developing medical transportation. Private markets invested $29 billion in telehealth last year, up 95% from 2020.
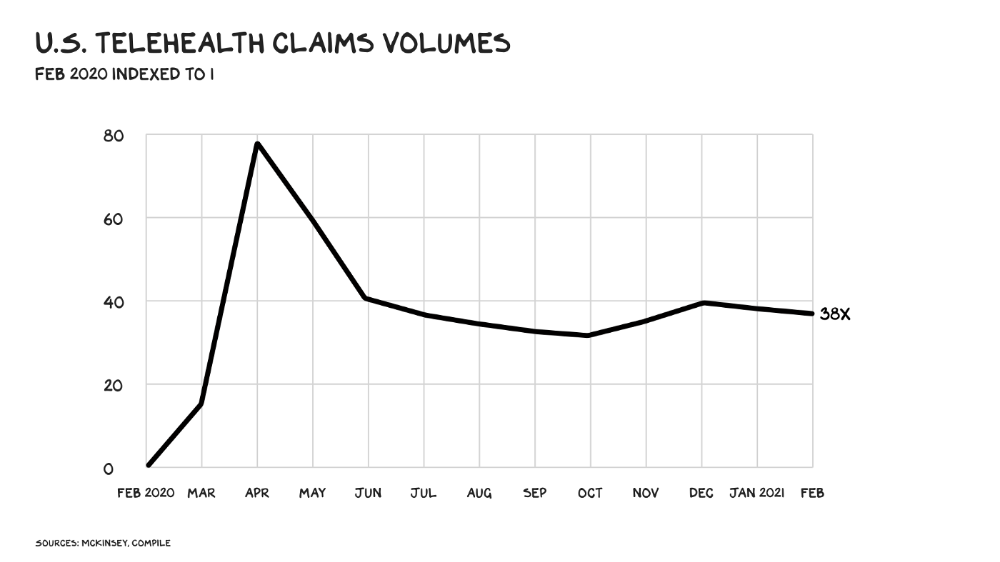
The pandemic accelerated telehealth, the immediate unlock. After the first positive Covid case in the U.S., services that had to be delivered in person shifted to Zoom... We lived. We grew. Video house calls continued after in-person visits were allowed. McKinsey estimates telehealth visits are 38 times pre-pandemic levels. Doctors adopted the technology, regulators loosened restrictions, and patients saved time. We're far from remote surgery, but many patient visits are unnecessary. A study of 40 million patients during lockdown found that for chronic disease patients, online visits didn't affect outcomes. This method of care will only improve.
Amazon's disruption will be significant and will inspire a flood of capital, startups, and consumer brands. Mark Cuban launched a pharmacy that eliminates middlemen in January. Outcome? A 90-day supply of acid-reflux medication costs $17. Medicare could have saved $3.6 billion by buying generic drugs from Cuban's pharmacy. Other apex predators will look at different limbs of the carcass for food. Nike could enter healthcare via orthopedics, acupuncture, and chiropractic. LVMH, L'Oréal, and Estée Lauder may launch global plastic surgery brands. Hilton and Four Seasons may open hospitals. Lennar and Pulte could build "Active Living" communities that Nana would leave feet first, avoiding the expense and tragedy of dying among strangers.
Risks
Privacy matters: HIV status is different from credit card and billing address. Most customers (60%) feel fine sharing personal health data via virtual technologies, though. Unavoidable. 85% of doctors believe data-sharing and interoperability will become the norm. Amazon is the most trusted tech company for handling personal data. Not Meta: Amazon.
What about antitrust, then?
Amazon should be required to spin off AWS and/or Amazon Fulfillment and banned from promoting its own products. It should be allowed to acquire hospitals. One Medical's $3.9 billion acquisition is a drop in the bucket compared to UnitedHealth's $498 billion market valuation.
Antitrust enforcement shouldn't assume some people/firms are good/bad. It should recognize that competition is good and focus on making markets more competitive in each deal. The FTC should force asset divestitures in e-commerce, digital marketing, and social media. These companies can also promote competition in a social ill.
U.S. healthcare makes us fat, depressed, and broke. Competition has produced massive value and prosperity across most of our economy.
Dear Amazon … bring it.