


Fairness alternatives to selling below market clearing prices (or community sentiment, or fun)
When a seller has a limited supply of an item in high (or uncertain and possibly high) demand, they frequently set a price far below what "the market will bear." As a result, the item sells out quickly, with lucky buyers being those who tried to buy first. This has happened in the Ethereum ecosystem, particularly with NFT sales and token sales/ICOs. But this phenomenon is much older; concerts and restaurants frequently make similar choices, resulting in fast sell-outs or long lines.
Why do sellers do this? Economists have long wondered. A seller should sell at the market-clearing price if the amount buyers are willing to buy exactly equals the amount the seller has to sell. If the seller is unsure of the market-clearing price, they should sell at auction and let the market decide. So, if you want to sell something below market value, don't do it. It will hurt your sales and it will hurt your customers. The competitions created by non-price-based allocation mechanisms can sometimes have negative externalities that harm third parties, as we will see.
However, the prevalence of below-market-clearing pricing suggests that sellers do it for good reason. And indeed, as decades of research into this topic has shown, there often are. So, is it possible to achieve the same goals with less unfairness, inefficiency, and harm?
Selling at below market-clearing prices has large inefficiencies and negative externalities
An item that is sold at market value or at an auction allows someone who really wants it to pay the high price or bid high in the auction. So, if a seller sells an item below market value, some people will get it and others won't. But the mechanism deciding who gets the item isn't random, and it's not always well correlated with participant desire. It's not always about being the fastest at clicking buttons. Sometimes it means waking up at 2 a.m. (but 11 p.m. or even 2 p.m. elsewhere). Sometimes it's just a "auction by other means" that's more chaotic, less efficient, and has far more negative externalities.
There are many examples of this in the Ethereum ecosystem. Let's start with the 2017 ICO craze. For example, an ICO project would set the price of the token and a hard maximum for how many tokens they are willing to sell, and the sale would start automatically at some point in time. The sale ends when the cap is reached.
So what? In practice, these sales often ended in 30 seconds or less. Everyone would start sending transactions in as soon as (or just before) the sale started, offering higher and higher fees to encourage miners to include their transaction first. Instead of the token seller receiving revenue, miners receive it, and the sale prices out all other applications on-chain.
The most expensive transaction in the BAT sale set a fee of 580,000 gwei, paying a fee of $6,600 to get included in the sale.
Many ICOs after that tried various strategies to avoid these gas price auctions; one ICO notably had a smart contract that checked the transaction's gasprice and rejected it if it exceeded 50 gwei. But that didn't solve the issue. Buyers hoping to game the system sent many transactions hoping one would get through. An auction by another name, clogging the chain even more.
ICOs have recently lost popularity, but NFTs and NFT sales have risen in popularity. But the NFT space didn't learn from 2017; they do fixed-quantity sales just like ICOs (eg. see the mint function on lines 97-108 of this contract here). So what?
That's not the worst; some NFT sales have caused gas price spikes of up to 2000 gwei.
High gas prices from users fighting to get in first by sending higher and higher transaction fees. An auction renamed, pricing out all other applications on-chain for 15 minutes.
So why do sellers sometimes sell below market price?
Selling below market value is nothing new, and many articles, papers, and podcasts have written (and sometimes bitterly complained) about the unwillingness to use auctions or set prices to market-clearing levels.
Many of the arguments are the same for both blockchain (NFTs and ICOs) and non-blockchain examples (popular restaurants and concerts). Fairness and the desire not to exclude the poor, lose fans or create tension by being perceived as greedy are major concerns. The 1986 paper by Kahneman, Knetsch, and Thaler explains how fairness and greed can influence these decisions. I recall that the desire to avoid perceptions of greed was also a major factor in discouraging the use of auction-like mechanisms in 2017.
Aside from fairness concerns, there is the argument that selling out and long lines create a sense of popularity and prestige, making the product more appealing to others. Long lines should have the same effect as high prices in a rational actor model, but this is not the case in reality. This applies to ICOs and NFTs as well as restaurants. Aside from increasing marketing value, some people find the game of grabbing a limited set of opportunities first before everyone else is quite entertaining.
But there are some blockchain-specific factors. One argument for selling ICO tokens below market value (and one that persuaded the OmiseGo team to adopt their capped sale strategy) is community dynamics. The first rule of community sentiment management is to encourage price increases. People are happy if they are "in the green." If the price drops below what the community members paid, they are unhappy and start calling you a scammer, possibly causing a social media cascade where everyone calls you a scammer.
This effect can only be avoided by pricing low enough that post-launch market prices will almost certainly be higher. But how do you do this without creating a rush for the gates that leads to an auction?
Interesting solutions
It's 2021. We have a blockchain. The blockchain is home to a powerful decentralized finance ecosystem, as well as a rapidly expanding set of non-financial tools. The blockchain also allows us to reset social norms. Where decades of economists yelling about "efficiency" failed, blockchains may be able to legitimize new uses of mechanism design. If we could use our more advanced tools to create an approach that more directly solves the problems, with fewer side effects, wouldn't that be better than fiddling with a coarse-grained one-dimensional strategy space of selling at market price versus below market price?
Begin with the goals. We'll try to cover ICOs, NFTs, and conference tickets (really a type of NFT) all at the same time.
1. Fairness: don't completely exclude low-income people from participation; give them a chance. The goal of token sales is to avoid high initial wealth concentration and have a larger and more diverse initial token holder community.
2. Don’t create races: Avoid situations where many people rush to do the same thing and only a few get in (this is the type of situation that leads to the horrible auctions-by-another-name that we saw above).
3. Don't require precise market knowledge: the mechanism should work even if the seller has no idea how much demand exists.
4. Fun: The process of participating in the sale should be fun and game-like, but not frustrating.
5. Give buyers positive expected returns: in the case of a token (or an NFT), buyers should expect price increases rather than decreases. This requires selling below market value.
Let's start with (1). From Ethereum's perspective, there is a simple solution. Use a tool designed for the job: proof of personhood protocols! Here's one quick idea:
Mechanism 1 Each participant (verified by ID) can buy up to ‘’X’’ tokens at price P, with the option to buy more at an auction.
With the per-person mechanism, buyers can get positive expected returns for the portion sold through the per-person mechanism, and the auction part does not require sellers to understand demand levels. Is it race-free? The number of participants buying through the per-person pool appears to be high. But what if the per-person pool isn't big enough to accommodate everyone?
Make the per-person allocation amount dynamic.
Mechanism 2 Each participant can deposit up to X tokens into a smart contract to declare interest. Last but not least, each buyer receives min(X, N / buyers) tokens, where N is the total sold through the per-person pool (some other amount can also be sold by auction). The buyer gets their deposit back if it exceeds the amount needed to buy their allocation.
No longer is there a race condition based on the number of buyers per person. No matter how high the demand, it's always better to join sooner rather than later.
Here's another idea if you like clever game mechanics with fancy quadratic formulas.
Mechanism 3 Each participant can buy X units at a price P X 2 up to a maximum of C tokens per buyer. C starts low and gradually increases until enough units are sold.
The quantity allocated to each buyer is theoretically optimal, though post-sale transfers will degrade this optimality over time. Mechanisms 2 and 3 appear to meet all of the above objectives. They're not perfect, but they're good starting points.
One more issue. For fixed and limited supply NFTs, the equilibrium purchased quantity per participant may be fractional (in mechanism 2, number of buyers > N, and in mechanism 3, setting C = 1 may already lead to over-subscription). With fractional sales, you can offer lottery tickets: if there are N items available, you have a chance of N/number of buyers of getting the item, otherwise you get a refund. For a conference, groups could bundle their lottery tickets to guarantee a win or a loss. The certainty of getting the item can be auctioned.
The bottom tier of "sponsorships" can be used to sell conference tickets at market rate. You may end up with a sponsor board full of people's faces, but is that okay? After all, John Lilic was on EthCC's sponsor board!
Simply put, if you want to be reliably fair to people, you need an input that explicitly measures people. Authentication protocols do this (and if desired can be combined with zero knowledge proofs to ensure privacy). So we should combine the efficiency of market and auction-based pricing with the equality of proof of personhood mechanics.
Answers to possible questions
Q: Won't people who don't care about your project buy the item and immediately resell it?
A: Not at first. Meta-games take time to appear in practice. If they do, making them untradeable for a while may help mitigate the damage. Using your face to claim that your previous account was hacked and that your identity, including everything in it, should be moved to another account works because proof-of-personhood identities are untradeable.
Q: What if I want to make my item available to a specific community?
A: Instead of ID, use proof of participation tokens linked to community events. Another option, also serving egalitarian and gamification purposes, is to encrypt items within publicly available puzzle solutions.
Q: How do we know they'll accept? Strange new mechanisms have previously been resisted.
A: Having economists write screeds about how they "should" accept a new mechanism that they find strange is difficult (or even "equity"). However, abrupt changes in context effectively reset people's expectations. So the blockchain space is the best place to try this. You could wait for the "metaverse", but it's possible that the best version will run on Ethereum anyway, so start now.
More on Web3 & Crypto

Tim Denning
3 years ago
The Dogecoin millionaire mysteriously disappeared.
The American who bought a meme cryptocurrency.

Cryptocurrency is the financial underground.
I love it. But there’s one thing I hate: scams. Over the last few years the Dogecoin cryptocurrency saw massive gains.
Glauber Contessoto overreacted. He shared his rags-to-riches cryptocurrency with the media.
He's only wealthy on paper. No longer Dogecoin millionaire.
Here's what he's doing now. It'll make you rethink cryptocurrency investing.
Strange beginnings
Glauber once had a $36,000-a-year job.
He grew up poor and wanted to make his mother proud. Tesla was his first investment. He bought GameStop stock after Reddit boosted it.
He bought whatever was hot.
He was a young investor. Memes, not research, influenced his decisions.
Elon Musk (aka Papa Elon) began tweeting about Dogecoin.
Doge is a 2013 cryptocurrency. One founder is Australian. He insists it's funny.
He was shocked anyone bought it LOL.
Doge is a Shiba Inu-themed meme. Now whenever I see a Shiba Inu, I think of Doge.
Elon helped drive up the price of Doge by talking about it in 2020 and 2021 (don't take investment advice from Elon; he's joking and gaslighting you).
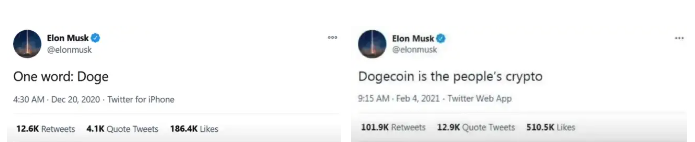
Glauber caved. He invested everything in Doge. He borrowed from family and friends. He maxed out his credit card to buy more Doge. Yuck.
Internet dubbed him a genius. Slumdog millionaire and The Dogefather were nicknames. Elon pumped Doge on social media.
Good times.
From $180,000 to $1,000,000+
TikTok skyrocketed Doge's price.
Reddit fueled up. Influencers recommended buying Doge because of its popularity. Glauber's motto:
Scared money doesn't earn.
Glauber was no broke ass anymore.
His $180,000 Dogecoin investment became $1M. He championed investing. He quit his dumb job like a rebellious millennial.
A puppy dog meme captivated the internet.
Rise and fall
Whenever I invest in anything I ask myself “what utility does this have?”
Dogecoin is useless.
You buy it for the cute puppy face and hope others will too, driving up the price. All cryptocurrencies fell in 2021's second half.
Central banks raised interest rates, and inflation became a pain.
Dogecoin fell more than others. 90% decline.
Glauber’s Dogecoin is now worth $323K. Still no sales. His dog god is unshakeable. Confidence rocks. Dogecoin millionaire recently said...
“I should have sold some.”
Yes, sir.
He now avoids speculative cryptocurrencies like Dogecoin and focuses on Bitcoin and Ethereum.
I've long said this. Starbucks is building on Ethereum.
It's useful. Useful. Developers use Ethereum daily. Investing makes you wiser over time, like the Dogecoin millionaire.
When risk b*tch slaps you, humility follows, as it did for me when I lost money.
You have to lose money to make money. Few understand.
Dogecoin's omissions
You might be thinking Dogecoin is crap.
I'll take a contrarian stance. Dogecoin does nothing, but it has a strong community. Dogecoin dominates internet memes.
It's silly.
Not quite. The message of crypto that many people forget is that it’s a change in business model.
Businesses create products and services, then advertise to find customers. Crypto Web3 works backwards. A company builds a fanbase but sells them nothing.
Once the community reaches MVC (minimum viable community), a business can be formed.
Community members are relational versus transactional. They're invested in a cause and care about it (typically ownership in the business via crypto).
In this new world, Dogecoin has the most important feature.
Summary
While Dogecoin does have a community I still dislike it.
It's all shady. Anything Elon Musk recommends is a bad investment (except SpaceX & Tesla are great companies).
Dogecoin Millionaire has wised up and isn't YOLOing into more dog memes.
Don't follow the crowd or the hype. Investing is a long-term sport based on fundamentals and research.
Since Ethereum's inception, I've spent 10,000 hours researching.
Dogecoin will be the foundation of something new, like Pets.com at the start of the dot-com revolution. But I doubt Doge will boom.
Be safe!

Koji Mochizuki
4 years ago
How to Launch an NFT Project by Yourself
Creating 10,000 auto-generated artworks, deploying a smart contract to the Ethereum / Polygon blockchain, setting up some tools, etc.
There is so much to do from launching to running an NFT project. Creating parts for artworks, generating 10,000 unique artworks and metadata, creating a smart contract and deploying it to a blockchain network, creating a website, creating a Twitter account, setting up a Discord server, setting up an OpenSea collection. In addition, you need to have MetaMask installed in your browser and have some ETH / MATIC. Did you get tired of doing all this? Don’t worry, once you know what you need to do, all you have to do is do it one by one.
To be honest, it’s best to run an NFT project in a team of three or more, including artists, developers, and marketers. However, depending on your motivation, you can do it by yourself. Some people might come later to offer help with your project. The most important thing is to take a step as soon as possible.
Creating Parts for Artworks
There are lots of free/paid software for drawing, but after all, I think Adobe Illustrator or Photoshop is the best. The images of Skulls In Love are a composite of 48x48 pixel parts created using Photoshop.
The most important thing in creating parts for generative art is to repeatedly test what your artworks will look like after each layer has been combined. The generated artworks should not be too unnatural.
How Many Parts Should You Create?
Are you wondering how many parts you should create to avoid duplication as much as possible when generating your artworks? My friend Stephane, a developer, has created a great tool to help with that.
Generating 10,000 Unique Artworks and Metadata
I highly recommend using the HashLips Art Engine to generate your artworks and metadata. Perhaps there is no better artworks generation tool at the moment.
GitHub: https://github.com/HashLips/hashlips_art_engine
YouTube:
Storing Artworks and Metadata
Ideally, the generated artworks and metadata should be stored on-chain, but if you want to store them off-chain, you should use IPFS. Do not store in centralized storage. This is because data will be lost if the server goes down or if the company goes down. On the other hand, IPFS is a more secure way to find data because it utilizes a distributed, decentralized system.
Storing to IPFS is easy with Pinata, NFT.Storage, and so on. The Skulls In Love uses Pinata. It’s very easy to use, just upload the folder containing your artworks.
Creating and Deploying a Smart Contract
You don’t have to create a smart contract from scratch. There are many great NFT projects, many of which publish their contract source code on Etherscan / PolygonScan. You can choose the contract you like and reuse it. Of course, that requires some knowledge of Solidity, but it depends on your efforts. If you don’t know which contract to choose, use the HashLips smart contract. It’s very simple, but it has almost all the functions you need.
GitHub: https://github.com/HashLips/hashlips_nft_contract
Note: Later on, you may want to change the cost value. You can change it on Remix or Etherscan / PolygonScan. But in this case, enter the Wei value instead of the Ether value. For example, if you want to sell for 1 MATIC, you have to enter “1000000000000000000”. If you set this value to “1”, you will have a nightmare. I recommend using Simple Unit Converter as a tool to calculate the Wei value.
Creating a Website
The website here is not just a static site to showcase your project, it’s a so-called dApp that allows you to access your smart contract and mint NFTs. In fact, this level of dApp is not too difficult for anyone who has ever created a website. Because the ethers.js / web3.js libraries make it easy to interact with your smart contract. There’s also no problem connecting wallets, as MetaMask has great documentation.
The Skulls In Love uses a simple, fast, and modern dApp that I built from scratch using Next.js. It is published on GitHub, so feel free to use it.
Why do people mint NFTs on a website?
Ethereum’s gas fees are high, so if you mint all your NFTs, there will be a huge initial cost. So it makes sense to get the buyers to help with the gas fees for minting.
What about Polygon? Polygon’s gas fees are super cheap, so even if you mint 10,000 NFTs, it’s not a big deal. But we don’t do that. Since NFT projects are a kind of game, it involves the fun of not knowing what will come out after minting.
Creating a Twitter Account
I highly recommend creating a Twitter account. Twitter is an indispensable tool for announcing giveaways and reaching more people. It’s better to announce your project and your artworks little by little, 1–2 weeks before launching your project.
Creating and Setting Up a Discord Server
I highly recommend creating a Discord server as well as a Twitter account. The Discord server is a community and its home. Fans of your NFT project will want to join your community and interact with many other members. So, carefully create each channel on your Discord server to make it a cozy place for your community members.
If you are unfamiliar with Discord, you may be particularly confused by the following:
What bots should I use?
How should I set roles and permissions?
But don’t worry. There are lots of great YouTube videos and blog posts about these.
It’s also a good idea to join the Discord servers of some NFT projects and see how they’re made. Our Discord server is so simple that even beginners will find it easy to understand. Please join us and see it!
Note: First, create a test account and a test server to make sure your bots and permissions work properly. It is better to verify the behavior on the test server before setting up your production server.
UPDATED: As your Discord server grows, you cannot manage it on your own. In this case, you will be hiring several moderators, but choose carefully before hiring. And don’t give them important role permissions right after hiring. Initially, the same permissions as other members are sufficient. After a while, you can add permissions as needed, such as kicking/banning, using the “@every” tag, and adding roles. Again, don’t immediately give significant permissions to your Mod role. Your server can be messed up by fake moderators.
Setting Up Your OpenSea Collection
Before you start selling your NFTs, you need to reserve some for airdrops, giveaways, staff, and more. It’s up to you whether it’s 100, 500, or how many.
After minting some of your NFTs, your account and collection should have been created in OpenSea. Go to OpenSea, connect to your wallet, and set up your collection. Just set your logo, banner image, description, links, royalties, and more. It’s not that difficult.
Promoting Your Project
After all, promotion is the most important thing. In fact, almost every successful NFT project spends a lot of time and effort on it.
In addition to Twitter and Discord, it’s even better to use Instagram, Reddit, and Medium. Also, register your project in NFTCalendar and DISBOARD
DISBOARD is the public Discord server listing community.
About Promoters
You’ll probably get lots of contacts from promoters on your Discord, Twitter, Instagram, and more. But most of them are scams, so don’t pay right away. If you have a promoter that looks attractive to you, be sure to check the promoter’s social media accounts or website to see who he/she is. They basically charge in dollars. The amount they charge isn’t cheap, but promoters with lots of followers may have some temporary effect on your project. Some promoters accept 50% prepaid and 50% postpaid. If you can afford it, it might be worth a try. I never ask them, though.
When Should the Promotion Activities Start?
You may be worried that if you promote your project before it starts, someone will copy your project (artworks). It is true that some projects have actually suffered such damage. I don’t have a clear answer to this question right now, but:
- Do not publish all the information about your project too early
- The information should be released little by little
- Creating artworks that no one can easily copy
I think these are important.
If anyone has a good idea, please share it!
About Giveaways
When hosting giveaways, you’ll probably use multiple social media platforms. You may want to grow your Discord server faster. But if joining the Discord server is included in the giveaway requirements, some people hate it. I recommend holding giveaways for each platform. On Twitter and Reddit, you should just add the words “Discord members-only giveaway is being held now! Please join us if you like!”.
If you want to easily pick a giveaway winner in your browser, I recommend Twitter Picker.
Precautions for Distributing Free NFTs
If you want to increase your Twitter followers and Discord members, you can actually get a lot of people by holding events such as giveaways and invite contests. However, distributing many free NFTs at once can be dangerous. Some people who want free NFTs, as soon as they get a free one, sell it at a very low price on marketplaces such as OpenSea. They don’t care about your project and are only thinking about replacing their own “free” NFTs with Ethereum. The lower the floor price of your NFTs, the lower the value of your NFTs (project). Try to think of ways to get people to “buy” your NFTs as much as possible.
Ethereum vs. Polygon
Even though Ethereum has high gas fees, NFT projects on the Ethereum network are still mainstream and popular. On the other hand, Polygon has very low gas fees and fast transaction processing, but NFT projects on the Polygon network are not very popular.
Why? There are several reasons, but the biggest one is that it’s a lot of work to get MATIC (on Polygon blockchain, use MATIC instead of ETH) ready to use. Simply put, you need to bridge your tokens to the Polygon chain. So people need to do this first before minting your NFTs on your website. It may not be a big deal for those who are familiar with crypto and blockchain, but it may be complicated for those who are not. I hope that the tedious work will be simplified in the near future.
If you are confident that your NFTs will be purchased even if they are expensive, or if the total supply of your NFTs is low, you may choose Ethereum. If you just want to save money, you should choose Polygon. Keep in mind that gas fees are incurred not only when minting, but also when performing some of your smart contract functions and when transferring your NFTs.
If I were to launch a new NFT project, I would probably choose Ethereum or Solana.
Conclusion
Some people may want to start an NFT project to make money, but don’t forget to enjoy your own project. Several months ago, I was playing with creating generative art by imitating the CryptoPunks. I found out that auto-generated artworks would be more interesting than I had imagined, and since then I’ve been completely absorbed in generative art.
This is one of the Skulls In Love artworks:
This character wears a cowboy hat, black slim sunglasses, and a kimono. If anyone looks like this, I can’t help laughing!
The Skulls In Love NFTs can be minted for a small amount of MATIC on the official website. Please give it a try to see what kind of unique characters will appear 💀💖
Thank you for reading to the end. I hope this article will be helpful to those who want to launch an NFT project in the future ✨

The Verge
3 years ago
Bored Ape Yacht Club creator raises $450 million at a $4 billion valuation.
Yuga Labs, owner of three of the biggest NFT brands on the market, announced today a $450 million funding round. The money will be used to create a media empire based on NFTs, starting with games and a metaverse project.
The team's Otherside metaverse project is an MMORPG meant to connect the larger NFT universe. They want to create “an interoperable world” that is “gamified” and “completely decentralized,” says Wylie Aronow, aka Gordon Goner, co-founder of Bored Ape Yacht Club. “We think the real Ready Player One experience will be player run.”
Just a few weeks ago, Yuga Labs announced the acquisition of CryptoPunks and Meebits from Larva Labs. The deal brought together three of the most valuable NFT collections, giving Yuga Labs more IP to work with when developing games and metaverses. Last week, ApeCoin was launched as a cryptocurrency that will be governed independently and used in Yuga Labs properties.
Otherside will be developed by “a few different game studios,” says Yuga Labs CEO Nicole Muniz. The company plans to create development tools that allow NFTs from other projects to work inside their world. “We're welcoming everyone into a walled garden.”
However, Yuga Labs believes that other companies are approaching metaverse projects incorrectly, allowing the startup to stand out. People won't bond spending time in a virtual space with nothing going on, says Yuga Labs co-founder Greg Solano, aka Gargamel. Instead, he says, people bond when forced to work together.
In order to avoid getting smacked, Solano advises making friends. “We don't think a Zoom chat and walking around saying ‘hi' creates a deep social experience.” Yuga Labs refused to provide a release date for Otherside. Later this year, a play-to-win game is planned.
The funding round was led by Andreessen Horowitz, a major investor in the Web3 space. It previously backed OpenSea and Coinbase. Animoca Brands, Coinbase, and MoonPay are among those who have invested. Andreessen Horowitz general partner Chris Lyons will join Yuga Labs' board. The Financial Times broke the story last month.
"META IS A DOMINANT DIGITAL EXPERIENCE PROVIDER IN A DYSTOPIAN FUTURE."
This emerging [Web3] ecosystem is important to me, as it is to companies like Meta,” Chris Dixon, head of Andreessen Horowitz's crypto arm, tells The Verge. “In a dystopian future, Meta is the dominant digital experience provider, and it controls all the money and power.” (Andreessen Horowitz co-founder Marc Andreessen sits on Meta's board and invested early in Facebook.)
Yuga Labs has been profitable so far. According to a leaked pitch deck, the company made $137 million last year, primarily from its NFT brands, with a 95% profit margin. (Yuga Labs declined to comment on deck figures.)
But the company has built little so far. According to OpenSea data, it has only released one game for a limited time. That means Yuga Labs gets hundreds of millions of dollars to build a gaming company from scratch, based on a hugely lucrative art project.
Investors fund Yuga Labs based on its success. That's what they did, says Dixon, “they created a culture phenomenon”. But ultimately, the company is betting on the same thing that so many others are: that a metaverse project will be the next big thing. Now they must construct it.
You might also like
Tim Denning
3 years ago
Read These Books on Personal Finance to Boost Your Net Worth
And retire sooner.

Books can make you filthy rich.
If you apply what you learn. In 2011, I was broke and had broken dreams.
Someone suggested I read finance books. One Up On Wall Street was his first recommendation.
Finance books were my crack.
I've read every money book since then. Some are good, but most stink.
These books will make you rich.
The Almanack of Naval Ravikant by Eric Jorgenson
This isn't a cliche book.
This book was inspired by a How to Get Rich tweet thread.
It’s one of the best tweets I’ve ever read.
Naval thinks differently. He nukes ordinary ideas. I've never heard better money advice.
Eric Jorgenson wrote a book about this tweet thread with Navals permission. A must-read, easy-to-digest book.
Best quote
Seek wealth, not money or status. Wealth is having assets that earn while you sleep. Money is how we transfer time and wealth. Status is your place in the social hierarchy — Naval
Morgan Housel's The Psychology of Money
Many finance books advise investing like a dunce.
They almost all peddle the buy an index fund BS. Different book.
It's about money-making psychology. Because any fool can get rich and drunk on their ego. Few can consistently make money.
Each chapter is short. A single-page chapter breaks all book publishing rules.
Best quote
Spending money to show people how much money you have is the fastest way to have less money — Morgan Housel
J.L. Collins' The Simple Path to Wealth
Most of the best money books were written by bloggers.
JL Collins blogs. This easy-to-read book was written for his daughter.
This book popularized the phrase F You Money. With enough money in your bank account and investment portfolio, you can say F You more.
A bad boss is an example. You can leave instead of enduring his wrath.
You can then sit at home and look for another job while financially secure. JL says its mind-freedom is powerful.
Best phrasing
You own the things you own and they in turn own you — J.L. Collins
Tony Robbins' Unshakeable
I like Tony. This book makes me sweaty.
Tony interviews the world's top financiers. He interviews people who rarely do so.
This book taught me all-weather portfolio. It's a way to invest in different asset classes in good, bad, recession, or depression times.
Look at it:
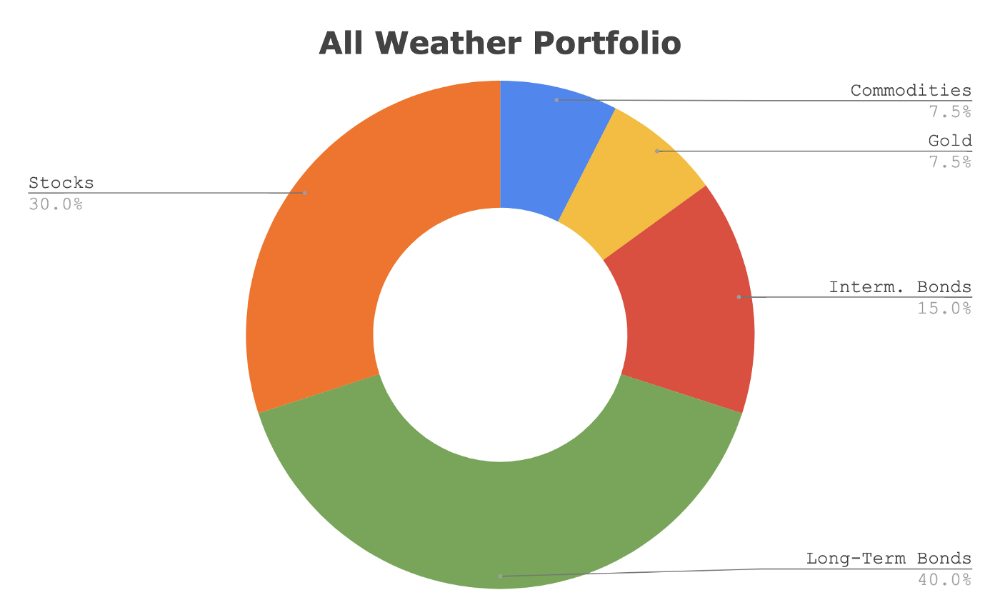
Investing isn’t about buying one big winner — that’s gambling. It’s about investing in a diversified portfolio of assets.
Best phrasing
The best opportunities come in times of maximum pessimism — Tony Robbins
Ben Graham's The Intelligent Investor
This book helped me distinguish between a spectator and an investor.
Spectators are those who shout that crypto, NFTs, or XYZ platform will die.
Tourists. They want attention and to say "I told you so." They make short-term and long-term predictions like fortunetellers. LOL. Idiots.
Benjamin Graham teaches smart investing. You'll buy a long-term asset. To be confident in recessions, use dollar-cost averaging.
Best phrasing
Those who do not remember the past are condemned to repeat it. — Benjamin Graham
The Napoleon Hill book Think and Grow Rich
This classic book introduced positive thinking to modern self-help.
Lazy pessimists can't become rich. No way.
Napoleon said, "Thoughts create reality."
No surprise that he discusses obsession and focus in this book. They are the fastest ways to make more money to invest in time and wealth-protecting assets.
Best phrasing
The starting point of all achievement is DESIRE. Keep this constantly in mind. Weak desire brings weak results, just as a small fire makes a small amount of heat — Napoleon Hill
Ramit Sethi's book I Will Teach You To Be Rich
This book is mostly good. The part about credit cards is trash.
Avoid credit card temptations. I don't care about their airline points.
This book teaches you to master money basics (that many people mess up) then automate it so your monkey brain doesn't ruin your financial future.
The book includes great negotiation tactics to help you make more money in less time.
Best quote
The 85 Percent Solution: Getting started is more important than becoming an expert — Ramit Sethi
David Bach's The Automatic Millionaire
You've probably met a six- or seven-figure earner who's broke. All their money goes to useless things like cars.
Money isn't as essential as what you do with it. David teaches how to automate your earnings for more money.
Compounding works once investing is automated. So you get rich.
His strategy eliminates luck and (almost) guarantees millionaire status.
Best phrasing
Every time you earn one dollar, make sure to pay yourself first — David Bach
Thomas J. Stanley's The Millionaire Next Door
Thomas defies the definition of rich.
He spends much of the book highlighting millionaire traits he's studied.
Rich people are quiet, so you wouldn't know they're wealthy. They don't earn much money or drive a BMW.
Thomas will give you the math to get started.
Best phrasing
I am not impressed with what people own. But I’m impressed with what they achieve. I’m proud to be a physician. Always strive to be the best in your field…. Don’t chase money. If you are the best in your field, money will find you. — Thomas J. Stanley
by Bill Perkins "Die With Zero"
Let’s end with one last book.
Bill's book angered many people. He says we spend too much time saving for retirement and die rich. That bank money is lost time.
Your grandkids could use the money. When children inherit money, they become lazy, entitled a-holes.
Bill wants us to spend our money on life-enhancing experiences. Stop saving money like monopoly monkeys.
Best phrasing
You should be focusing on maximizing your life enjoyment rather than on maximizing your wealth. Those are two very different goals. Money is just a means to an end: Having money helps you to achieve the more important goal of enjoying your life. But trying to maximize money actually gets in the way of achieving the more important goal — Bill Perkins
Wayne Duggan
3 years ago
What An Inverted Yield Curve Means For Investors
The yield spread between 10-year and 2-year US Treasury bonds has fallen below 0.2 percent, its lowest level since March 2020. A flattening or negative yield curve can be a bad sign for the economy.
What Is An Inverted Yield Curve?
In the yield curve, bonds of equal credit quality but different maturities are plotted. The most commonly used yield curve for US investors is a plot of 2-year and 10-year Treasury yields, which have yet to invert.
A typical yield curve has higher interest rates for future maturities. In a flat yield curve, short-term and long-term yields are similar. Inverted yield curves occur when short-term yields exceed long-term yields. Inversions of yield curves have historically occurred during recessions.
Inverted yield curves have preceded each of the past eight US recessions. The good news is they're far leading indicators, meaning a recession is likely not imminent.
Every US recession since 1955 has occurred between six and 24 months after an inversion of the two-year and 10-year Treasury yield curves, according to the San Francisco Fed. So, six months before COVID-19, the yield curve inverted in August 2019.
Looking Ahead
The spread between two-year and 10-year Treasury yields was 0.18 percent on Tuesday, the smallest since before the last US recession. If the graph above continues, a two-year/10-year yield curve inversion could occur within the next few months.
According to Bank of America analyst Stephen Suttmeier, the S&P 500 typically peaks six to seven months after the 2s-10s yield curve inverts, and the US economy enters recession six to seven months later.
Investors appear unconcerned about the flattening yield curve. This is in contrast to the iShares 20+ Year Treasury Bond ETF TLT +2.19% which was down 1% on Tuesday.
Inversion of the yield curve and rising interest rates have historically harmed stocks. Recessions in the US have historically coincided with or followed the end of a Federal Reserve rate hike cycle, not the start.

Jake Prins
3 years ago
What are NFTs 2.0 and what issues are they meant to address?
New standards help NFTs reach their full potential.

NFTs lack interoperability and functionality. They have great potential but are mostly speculative. To maximize NFTs, we need flexible smart contracts.
Current requirements are too restrictive.
Most NFTs are based on ERC-721, which makes exchanging them easy. CryptoKitties, a popular online game, used the 2017 standard to demonstrate NFTs' potential.
This simple standard includes a base URI and incremental IDs for tokens. Add the tokenID to the base URI to get the token's metadata.
This let creators collect NFTs. Many NFT projects store metadata on IPFS, a distributed storage network, but others use Google Drive. NFT buyers often don't realize that if the creators delete or move the files, their NFT is just a pointer.
This isn't the standard's biggest issue. There's no way to validate NFT projects.
Creators are one of the most important aspects of art, but nothing is stored on-chain.
ERC-721 contracts only have a name and symbol.
Most of the data on OpenSea's collection pages isn't from the NFT's smart contract. It was added through a platform input field, so it's in the marketplace's database. Other websites may have different NFT information.
In five years, your NFT will be just a name, symbol, and ID.
Your NFT doesn't mention its creators. Although the smart contract has a public key, it doesn't reveal who created it.
The NFT's creators and their reputation are crucial to its value. Think digital fashion and big brands working with well-known designers when more professionals use NFTs. Don't you want them in your NFT?
Would paintings be as valuable if their artists were unknown? Would you believe it's real?
Buying directly from an on-chain artist would reduce scams. Current standards don't allow this data.
Most creator profiles live on centralized marketplaces and could disappear. Current platforms have outpaced underlying standards. The industry's standards are lagging.
For NFTs to grow beyond pointers to a monkey picture file, we may need to use new Web3-based standards.
Introducing NFTs 2.0
Fabian Vogelsteller, creator of ERC-20, developed new web3 standards. He proposed LSP7 Digital Asset and LSP8 Identifiable Digital Asset, also called NFT 2.0.
NFT and token metadata inputs are extendable. Changes to on-chain metadata inputs allow NFTs to evolve. Instead of public keys, the contract can have Universal Profile addresses attached. These profiles show creators' faces and reputations. NFTs can notify asset receivers, automating smart contracts.
LSP7 and LSP8 use ERC725Y. Using a generic data key-value store gives contracts much-needed features:
The asset can be customized and made to stand out more by allowing for unlimited data attachment.
Recognizing changes to the metadata
using a hash reference for metadata rather than a URL reference
This base will allow more metadata customization and upgradeability. These guidelines are:
Genuine and Verifiable Now, the creation of an NFT by a specific Universal Profile can be confirmed by smart contracts.
Dynamic NFTs can update Flexible & Updatable Metadata, allowing certain things to evolve over time.
Protected metadata Now, secure metadata that is readable by smart contracts can be added indefinitely.
Better NFTS prevent the locking of NFTs by only being sent to Universal Profiles or a smart contract that can interact with them.
Summary
NFTS standards lack standardization and powering features, limiting the industry.
ERC-721 is the most popular NFT standard, but it only represents incremental tokenIDs without metadata or asset representation. No standard sender-receiver interaction or security measures ensure safe asset transfers.
NFT 2.0 refers to the new LSP7-DigitalAsset and LSP8-IdentifiableDigitalAsset standards.
They have new standards for flexible metadata, secure transfers, asset representation, and interactive transfer.
With NFTs 2.0 and Universal Profiles, creators could build on-chain reputations.
NFTs 2.0 could bring the industry's needed innovation if it wants to move beyond trading profile pictures for speculation.