



More on Leadership

Bart Krawczyk
2 years ago
Understanding several Value Proposition kinds will help you create better goods.
Fixing problems isn't enough.
Numerous articles and how-to guides on value propositions focus on fixing consumer concerns.
Contrary to popular opinion, addressing customer pain rarely suffices. Win your market category too.

Core Value Statement
Value proposition usually means a product's main value.
Its how your product solves client problems. The product's core.
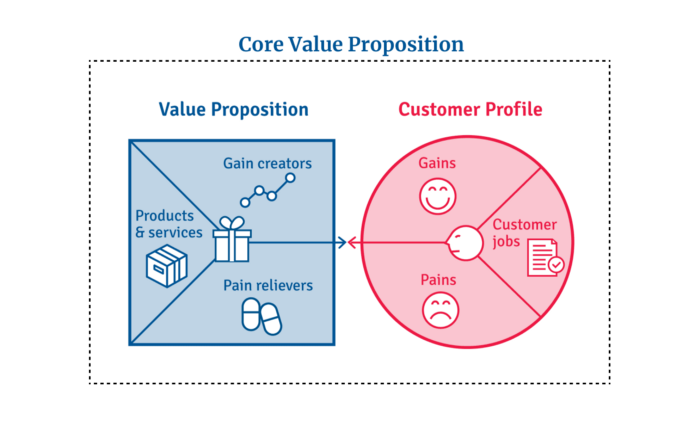
Answering these questions creates a relevant core value proposition:
What tasks is your customer trying to complete? (Jobs for clients)
How much discomfort do they feel while they perform this? (pains)
What would they like to see improved or changed? (gains)
After that, you create products and services that alleviate those pains and give value to clients.
Value Proposition by Category
Your product belongs to a market category and must follow its regulations, regardless of its value proposition.
Creating a new market category is challenging. Fitting into customers' product perceptions is usually better than trying to change them.
New product users simplify market categories. Products are labeled.
Your product will likely be associated with a collection of products people already use.
Example: IT experts will use your communication and management app.
If your target clients think it's an advanced mail software, they'll compare it to others and expect things like:
comprehensive calendar
spam detectors
adequate storage space
list of contacts
etc.
If your target users view your product as a task management app, things change. You can survive without a contact list, but not status management.
Find out what your customers compare your product to and if it fits your value offer. If so, adapt your product plan to dominate this market. If not, try different value propositions and messaging to put the product in the right context.
Finished Value Proposition
A comprehensive value proposition is when your solution addresses user problems and wins its market category.
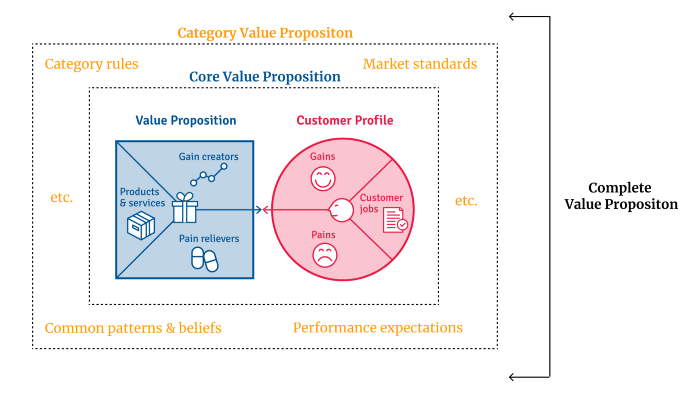
Addressing simply the primary value proposition may produce a valuable and original product, but it may struggle to cross the chasm into the mainstream market. Meeting expectations is easier than changing views.
Without a unique value proposition, you will drown in the red sea of competition.
To conclude:
Find out who your target consumer is and what their demands and problems are.
To meet these needs, develop and test a primary value proposition.
Speak with your most devoted customers. Recognize the alternatives they use to compare you against and the market segment they place you in.
Recognize the requirements and expectations of the market category.
To meet or surpass category standards, modify your goods.
Great products solve client problems and win their category.

Greg Satell
3 years ago
Focus: The Deadly Strategic Idea You've Never Heard Of (But Definitely Need To Know!

Steve Jobs' initial mission at Apple in 1997 was to destroy. He killed the Newton PDA and Macintosh clones. Apple stopped trying to please everyone under Jobs.
Afterward, there were few highly targeted moves. First, the pink iMac. Modest success. The iPod, iPhone, and iPad made Apple the world's most valuable firm. Each maneuver changed the company's center of gravity and won.
That's the idea behind Schwerpunkt, a German military term meaning "focus." Jobs didn't need to win everywhere, just where it mattered, so he focused Apple's resources on a few key goods. Finding your Schwerpunkt is more important than charts and analysis for excellent strategy.
Comparison of Relative Strength and Relative Weakness
The iPod, Apple's first major hit after Jobs' return, didn't damage Microsoft and the PC, but instead focused Apple's emphasis on a fledgling, fragmented market that generated "sucky" products. Apple couldn't have taken on the computer titans at this stage, yet it beat them.
The move into music players used Apple's particular capabilities, especially its ability to build simple, easy-to-use interfaces. Jobs' charisma and stature, along his understanding of intellectual property rights from Pixar, helped him build up iTunes store, which was a quagmire at the time.
In Good Strategy | Bad Strategy, management researcher Richard Rumelt argues that good strategy uses relative strength to counter relative weakness. To discover your main point, determine your abilities and where to effectively use them.
Steve Jobs did that at Apple. Microsoft and Dell, who controlled the computer sector at the time, couldn't enter the music player business. Both sought to produce iPod competitors but failed. Apple's iPod was nobody else's focus.
Finding The Center of Attention
In a military engagement, leaders decide where to focus their efforts by assessing commanders intent, the situation on the ground, the topography, and the enemy's posture on that terrain. Officers spend their careers learning about schwerpunkt.
Business executives must assess internal strengths including personnel, technology, and information, market context, competitive environment, and external partner ecosystems. Steve Jobs was a master at analyzing forces when he returned to Apple.
He believed Apple could integrate technology and design for the iPod and that the digital music player industry sucked. By analyzing competitors' products, he was convinced he could produce a smash by putting 1000 tunes in my pocket.
The only difficulty was there wasn't the necessary technology. External ecosystems were needed. On a trip to Japan to meet with suppliers, a Toshiba engineer claimed the company had produced a tiny memory drive approximately the size of a silver dollar.
Jobs knew the memory drive was his focus. He wrote a $10 million cheque and acquired exclusive technical rights. For a time, none of his competitors would be able to recreate his iPod with the 1000 songs in my pocket.
How to Enter the OODA Loop
John Boyd invented the OODA loop as a pilot to better his own decision-making. First OBSERVE your surroundings, then ORIENT that information using previous knowledge and experiences. Then you DECIDE and ACT, which changes the circumstance you must observe, orient, decide, and act on.
Steve Jobs used the OODA loop to decide to give Toshiba $10 million for a technology it had no use for. He compared the new information with earlier observations about the digital music market.
Then something much more interesting happened. The iPod was an instant hit, changing competition. Other computer businesses that competed in laptops, desktops, and servers created digital music players. Microsoft's Zune came out in 2006, Dell's Digital Jukebox in 2004. Both flopped.
By then, Apple was poised to unveil the iPhone, which would cause its competitors to Observe, Orient, Decide, and Act. Boyd named this OODA Loop infiltration. They couldn't gain the initiative by constantly reacting to Apple.
Microsoft and Dell were titans back then, but it's hard to recall. Apple went from near bankruptcy to crushing its competition via Schwerpunkt.
Rather than a destination, it is a journey
Trying to win everywhere is a strategic blunder. Win significant fights, not trivial skirmishes. Identifying a focal point to direct resources and efforts is the essence of Schwerpunkt.
When Steve Jobs returned to Apple, PC firms were competing, but he focused on digital music players, and the iPod made Apple a player. He launched the iPhone when his competitors were still reacting. When Steve Jobs said, "One more thing," at the end of a product presentation, he had a new focus.
Schwerpunkt isn't static; it's dynamic. Jobs' ability to observe, refocus, and modify the competitive backdrop allowed Apple to innovate consistently. His strategy was tailored to Apple's capabilities, customers, and ecosystem. Microsoft or Dell, better suited for the enterprise sector, couldn't succeed with a comparable approach.
There is no optimal strategy, only ones suited to a given environment, when relative strength might be used against relative weakness. Discovering the center of gravity where you can break through is more of a journey than a destination; it will become evident after you reach.

Sammy Abdullah
3 years ago
Payouts to founders at IPO
How much do startup founders make after an IPO? We looked at 2018's major tech IPOs. Paydays aren't what founders took home at the IPO (shares are normally locked up for 6 months), but what they were worth at the IPO price on the day the firm went public. It's not cash, but it's nice. Here's the data.
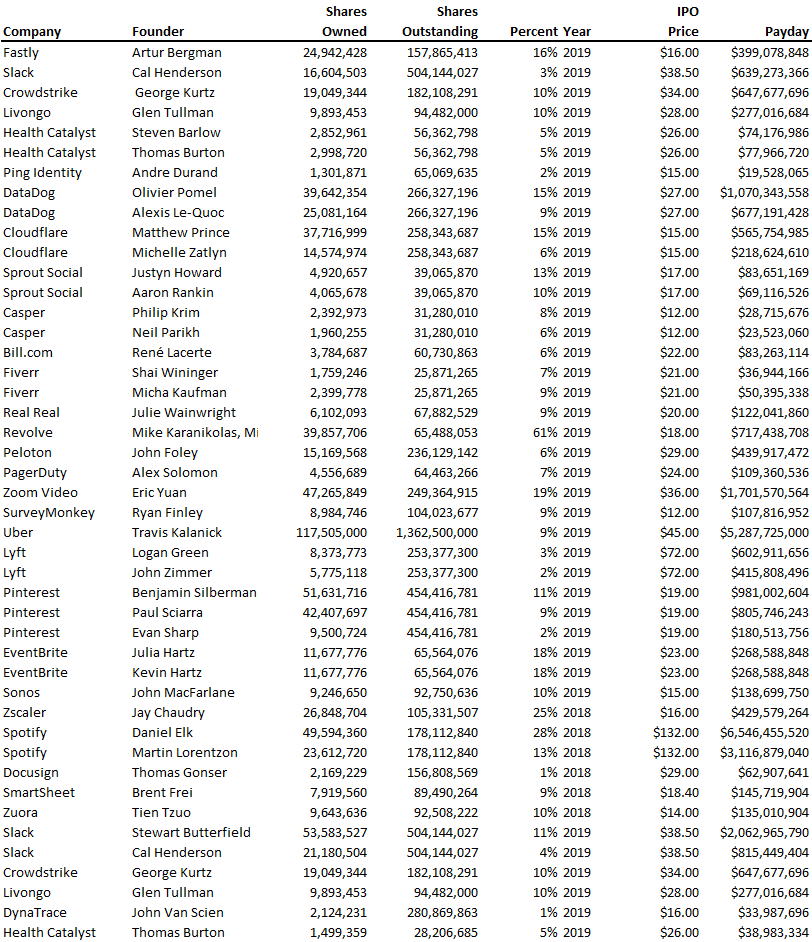
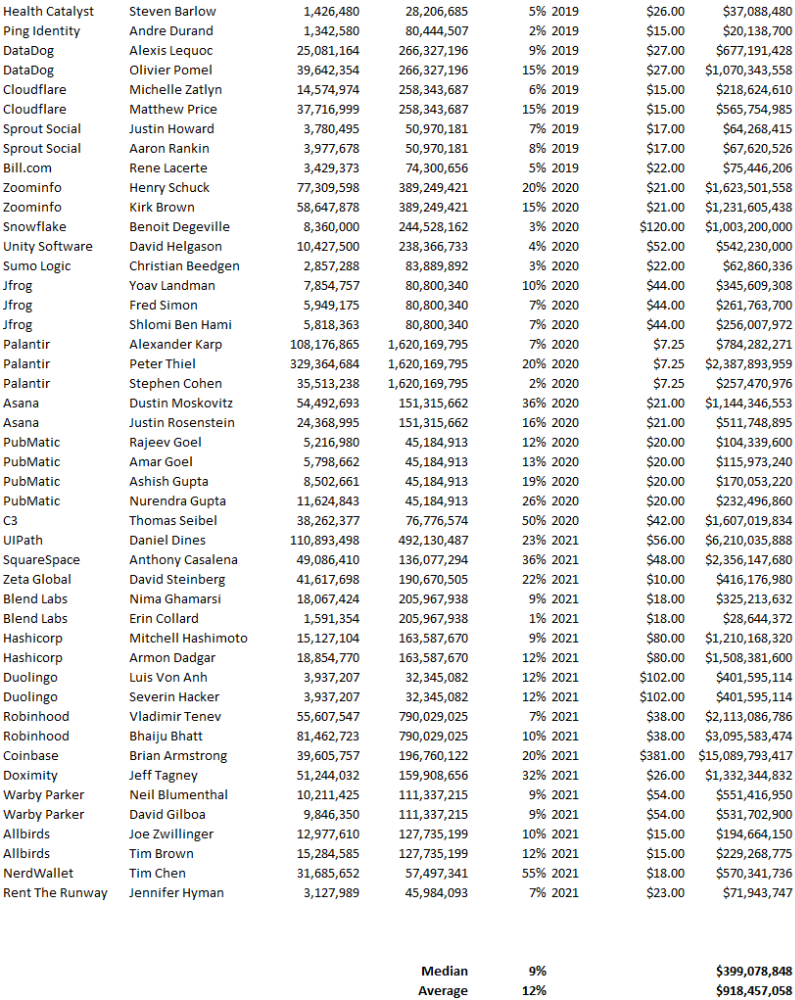
Several points are noteworthy.
Huge payoffs. Median and average pay were $399m and $918m. Average and median homeownership were 9% and 12%.
Coinbase, Uber, UI Path. Uber, Zoom, Spotify, UI Path, and Coinbase founders raised billions. Zoom's founder owned 19% and Spotify's 28% and 13%. Brian Armstrong controlled 20% of Coinbase at IPO and was worth $15bn. Preserving as much equity as possible by staying cash-efficient or raising at high valuations also helps.
The smallest was Ping. Ping's compensation was the smallest. Andre Duand owned 2% but was worth $20m at IPO. That's less than some billion-dollar paydays, but still good.
IPOs can be lucrative, as you can see. Preserving equity could be the difference between a $20mm and $15bln payday (Coinbase).
You might also like

Jayden Levitt
3 years ago
The country of El Salvador's Bitcoin-obsessed president lost $61.6 million.
It’s only a loss if you sell, right?

Nayib Bukele proclaimed himself “the world’s coolest dictator”.
His jokes aren't clear.
El Salvador's 43rd president self-proclaimed “CEO of El Salvador” couldn't be less presidential.
His thin jeans, aviator sunglasses, and baseball caps like a cartel lord.
He's popular, though.
Bukele won 53% of the vote by fighting violent crime and opposition party corruption.
El Salvador's 6.4 million inhabitants are riding the cryptocurrency volatility wave.
They were powerless.
Their autocratic leader, a former Yamaha Motors salesperson and Bitcoin believer, wants to help 70% unbanked locals.
He intended to give the citizens a way to save money and cut the country's $200 million remittance cost.
Transfer and deposit costs.
This makes logical sense when the president’s theatrics don’t blind you.
El Salvador's Bukele revealed plans to make bitcoin legal tender.
Remittances total $5.9 billion (23%) of the country's expenses.
Anything that reduces costs could boost the economy.
The country’s unbanked population is staggering. Here’s the data by % of people who either have a bank account (Blue) or a mobile money account (Black).
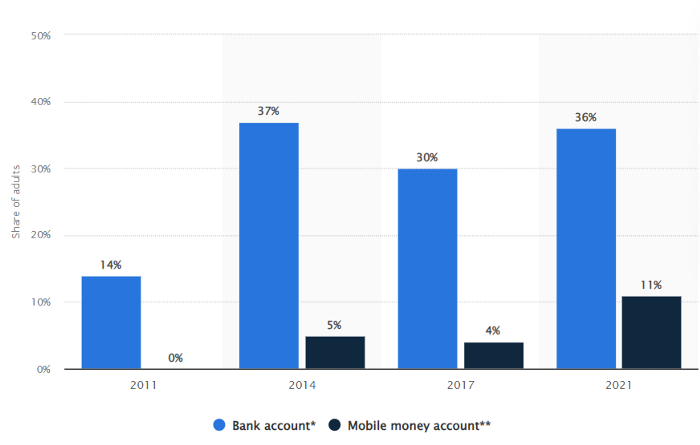
According to Bukele, 46% of the population has downloaded the Chivo Bitcoin Wallet.
In 2021, 36% of El Salvadorans had bank accounts.
Large rural countries like Kenya seem to have resolved their unbanked dilemma.
An economy surfaced where village locals would sell, trade and store network minutes and data as a store of value.
Kenyan phone networks realized unbanked people needed a safe way to accumulate wealth and have an emergency fund.
96% of Kenyans utilize M-PESA, which doesn't require a bank account.
The software involves human agents who hang out with cash and a phone.
These people are like ATMs.
You offer them cash to deposit money in your mobile money account or withdraw cash.
In a country with a faulty banking system, cash availability and a safe place to deposit it are important.
William Jack and Tavneet Suri found that M-PESA brought 194,000 Kenyan households out of poverty by making transactions cheaper and creating a safe store of value.
Mobile money, a service that allows monetary value to be stored on a mobile phone and sent to other users via text messages, has been adopted by most Kenyan households. We estimate that access to the Kenyan mobile money system M-PESA increased per capita consumption levels and lifted 194,000 households, or 2% of Kenyan households, out of poverty.
The impacts, which are more pronounced for female-headed households, appear to be driven by changes in financial behaviour — in particular, increased financial resilience and saving. Mobile money has therefore increased the efficiency of the allocation of consumption over time while allowing a more efficient allocation of labour, resulting in a meaningful reduction of poverty in Kenya.
Currently, El Salvador has 2,301 Bitcoin.
At publication, it's worth $44 million. That remains 41% of Bukele's original $105.6 million.
Unknown if the country has sold Bitcoin, but Bukeles keeps purchasing the dip.
It's still falling.

This might be a fantastic move for the impoverished country over the next five years, if they can live economically till Bitcoin's price recovers.
The evidence demonstrates that a store of value pulls individuals out of poverty, but others say Bitcoin is premature.
You may regard it as an aggressive endeavor to front run the next wave of adoption, offering El Salvador a financial upside.

Sam Hickmann
3 years ago
What is headline inflation?
Headline inflation is the raw Consumer price index (CPI) reported monthly by the Bureau of labour statistics (BLS). CPI measures inflation by calculating the cost of a fixed basket of goods. The CPI uses a base year to index the current year's prices.
Explaining Inflation
As it includes all aspects of an economy that experience inflation, headline inflation is not adjusted to remove volatile figures. Headline inflation is often linked to cost-of-living changes, which is useful for consumers.
The headline figure doesn't account for seasonality or volatile food and energy prices, which are removed from the core CPI. Headline inflation is usually annualized, so a monthly headline figure of 4% inflation would equal 4% inflation for the year if repeated for 12 months. Top-line inflation is compared year-over-year.
Inflation's downsides
Inflation erodes future dollar values, can stifle economic growth, and can raise interest rates. Core inflation is often considered a better metric than headline inflation. Investors and economists use headline and core results to set growth forecasts and monetary policy.
Core Inflation
Core inflation removes volatile CPI components that can distort the headline number. Food and energy costs are commonly removed. Environmental shifts that affect crop growth can affect food prices outside of the economy. Political dissent can affect energy costs, such as oil production.
From 1957 to 2018, the U.S. averaged 3.64 percent core inflation. In June 1980, the rate reached 13.60%. May 1957 had 0% inflation. The Fed's core inflation target for 2022 is 3%.
Central bank:
A central bank has privileged control over a nation's or group's money and credit. Modern central banks are responsible for monetary policy and bank regulation. Central banks are anti-competitive and non-market-based. Many central banks are not government agencies and are therefore considered politically independent. Even if a central bank isn't government-owned, its privileges are protected by law. A central bank's legal monopoly status gives it the right to issue banknotes and cash. Private commercial banks can only issue demand deposits.
What are living costs?
The cost of living is the amount needed to cover housing, food, taxes, and healthcare in a certain place and time. Cost of living is used to compare the cost of living between cities and is tied to wages. If expenses are higher in a city like New York, salaries must be higher so people can live there.
What's U.S. bureau of labor statistics?
BLS collects and distributes economic and labor market data about the U.S. Its reports include the CPI and PPI, both important inflation measures.

Victoria Kurichenko
3 years ago
What Happened After I Posted an AI-Generated Post on My Website
This could cost you.

Content creators may have heard about Google's "Helpful content upgrade."
This change is another Google effort to remove low-quality, repetitive, and AI-generated content.
Why should content creators care?
Because too much content manipulates search results.
My experience includes the following.
Website admins seek high-quality guest posts from me. They send me AI-generated text after I say "yes." My readers are irrelevant. Backlinks are needed.
Companies copy high-ranking content to boost their Google rankings. Unfortunately, it's common.
What does this content offer?
Nothing.
Despite Google's updates and efforts to clean search results, webmasters create manipulative content.
As a marketer, I knew about AI-powered content generation tools. However, I've never tried them.
I use old-fashioned content creation methods to grow my website from 0 to 3,000 monthly views in one year.
Last year, I launched a niche website.
I do keyword research, analyze search intent and competitors' content, write an article, proofread it, and then optimize it.
This strategy is time-consuming.
But it yields results!
Here's proof from Google Analytics:
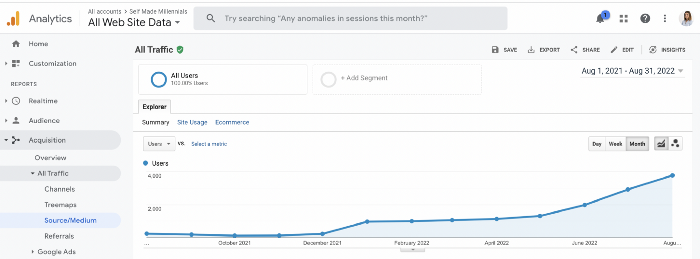
Proven strategies yield promising results.
To validate my assumptions and find new strategies, I run many experiments.
I tested an AI-powered content generator.
I used a tool to write this Google-optimized article about SEO for startups.
I wanted to analyze AI-generated content's Google performance.
Here are the outcomes of my test.
First, quality.
I dislike "meh" content. I expect articles to answer my questions. If not, I've wasted my time.
My essays usually include research, personal anecdotes, and what I accomplished and achieved.
AI-generated articles aren't as good because they lack individuality.
Read my AI-generated article about startup SEO to see what I mean.

It's dry and shallow, IMO.
It seems robotic.
I'd use quotes and personal experience to show how SEO for startups is different.
My article paraphrases top-ranked articles on a certain topic.
It's readable but useless. Similar articles abound online. Why read it?
AI-generated content is low-quality.
Let me show you how this content ranks on Google.
The Google Search Console report shows impressions, clicks, and average position.
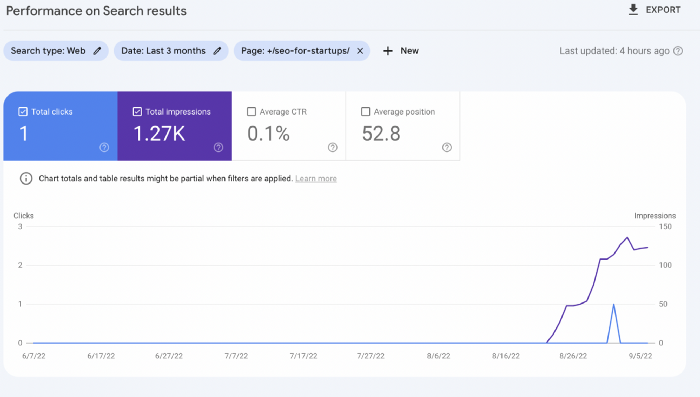
Low numbers.
No one opens the 5th Google search result page to read the article. Too far!
You may say the new article will improve.
Marketing-wise, I doubt it.
This article is shorter and less comprehensive than top-ranking pages. It's unlikely to win because of this.
AI-generated content's terrible reality.
I'll compare how this content I wrote for readers and SEO performs.
Both the AI and my article are fresh, but trends are emerging.
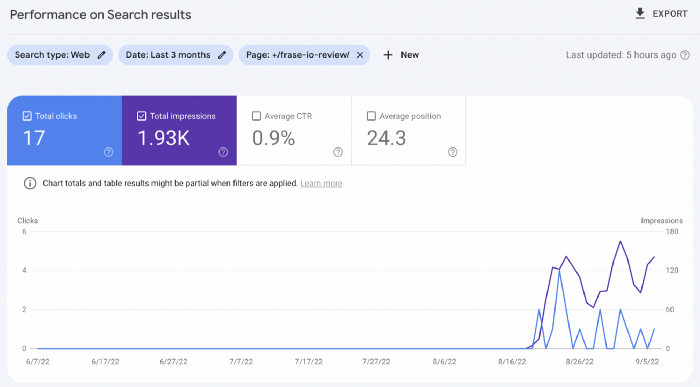
My article's CTR and average position are higher.
I spent a week researching and producing that piece, unlike AI-generated content. My expert perspective and unique consequences make it interesting to read.
Human-made.
In summary
No content generator can duplicate a human's tone, writing style, or creativity. Artificial content is always inferior.
Not "bad," but inferior.
Demand for content production tools will rise despite Google's efforts to eradicate thin content.
Most won't spend hours producing link-building articles. Costly.
As guest and sponsored posts, artificial content will thrive.
Before accepting a new arrangement, content creators and website owners should consider this.