



More on Science

Katrina Paulson
3 years ago
Dehumanization Against Anthropomorphization
We've fought for humanity's sake. We need equilibrium.

We live in a world of opposites (black/white, up/down, love/hate), thus life is a game of achieving equilibrium. We have a universe of paradoxes within ourselves, not just in physics.
Individually, you balance your intellect and heart, but as a species, we're full of polarities. They might be gentle and compassionate, then ruthless and unsympathetic.
We desire for connection so much that we personify non-human beings and objects while turning to violence and hatred toward others. These contrasts baffle me. Will we find balance?
Anthropomorphization
Assigning human-like features or bonding with objects is common throughout childhood. Cartoons often give non-humans human traits. Adults still anthropomorphize this trait. Researchers agree we start doing it as infants and continue throughout life.
Humans of all ages are good at humanizing stuff. We build emotional attachments to weather events, inanimate objects, animals, plants, and locales. Gods, goddesses, and fictitious figures are anthropomorphized.
Cast Away, starring Tom Hanks, features anthropization. Hanks is left on an island, where he builds an emotional bond with a volleyball he calls Wilson.
We became emotionally invested in Wilson, including myself.
Why do we do it, though?
Our instincts and traits helped us survive and thrive. Our brain is alert to other people's thoughts, feelings, and intentions to assist us to determine who is safe or hazardous. We can think about others and our own mental states, or about thinking. This is the Theory of Mind.
Neurologically, specialists believe the Theory of Mind has to do with our mirror neurons, which exhibit the same activity while executing or witnessing an action.
Mirror neurons may contribute to anthropization, but they're not the only ones. In 2021, Harvard Medical School researchers at MGH and MIT colleagues published a study on the brain's notion of mind.
“Our study provides evidence to support theory of mind by individual neurons. Until now, it wasn’t clear whether or how neurons were able to perform these social cognitive computations.”
Neurons have particular functions, researchers found. Others encode information that differentiates one person's beliefs from another's. Some neurons reflect tale pieces, whereas others aren't directly involved in social reasoning but may multitask contributing factors.
Combining neuronal data gives a precise portrait of another's beliefs and comprehension. The theory of mind describes how we judge and understand each other in our species, and it likely led to anthropomorphism. Neuroscience indicates identical brain regions react to human or non-human behavior, like mirror neurons.
Some academics believe we're wired for connection, which explains why we anthropomorphize. When we're alone, we may anthropomorphize non-humans.
Humanizing non-human entities may make them deserving of moral care, according to another theory. Animamorphizing something makes it responsible for its actions and deserves punishments or rewards. This mental shift is typically apparent in our connections with pets and leads to deanthropomorphization.
Dehumanization
Dehumanizing involves denying someone or anything ethical regard, the opposite of anthropomorphizing.
Dehumanization occurs throughout history. We do it to everything in nature, including ourselves. We experiment on and torture animals. We enslave, hate, and harm other groups of people.
Race, immigrant status, dress choices, sexual orientation, social class, religion, gender, politics, need I go on? Our degrading behavior is promoting fascism and division everywhere.
Dehumanizing someone or anything reduces their agency and value. Many assume they're immune to this feature, but tests disagree.
It's inevitable. Humans are wired to have knee-jerk reactions to differences. We are programmed to dehumanize others, and it's easier than we'd like to admit.
Why do we do it, though?
Dehumanizing others is simpler than humanizing things for several reasons. First, we consider everything unusual as harmful, which has helped our species survive for hundreds of millions of years. Our propensity to be distrustful of others, like our fear of the unknown, promotes an us-vs.-them mentality.
Since WWII, various studies have been done to explain how or why the holocaust happened. How did so many individuals become radicalized to commit such awful actions and feel morally justified? Researchers quickly showed how easily the mind can turn gloomy.
Stanley Milgram's 1960s electroshock experiment highlighted how quickly people bow to authority to injure others. Philip Zimbardo's 1971 Stanford Prison Experiment revealed how power may be abused.
The us-versus-them attitude is natural and even young toddlers act on it. Without a relationship, empathy is more difficult.
It's terrifying how quickly dehumanizing behavior becomes commonplace. The current pandemic is an example. Most countries no longer count deaths. Long Covid is a major issue, with predictions of a handicapped tsunami in the future years. Mostly, we shrug.
In 2020, we panicked. Remember everyone's caution? Now Long Covid is ruining more lives, threatening to disable an insane amount of our population for months or their entire lives.
There's little research. Experts can't even classify or cure it. The people should be outraged, but most have ceased caring. They're over covid.
We're encouraged to find a method to live with a terrible pandemic that will cause years of damage. People aren't worried about infection anymore. They shrug and say, "We'll all get it eventually," then hope they're not one of the 30% who develops Long Covid.
We can correct course before further damage. Because we can recognize our urges and biases, we're not captives to them. We can think critically about our thoughts and behaviors, then attempt to improve. We can recognize our deficiencies and work to attain balance.
Changing perspectives
We're currently attempting to find equilibrium between opposites. It's superficial to defend extremes by stating we're only human or wired this way because both imply we have no control.
Being human involves having self-awareness, and by being careful of our thoughts and acts, we can find balance and recognize opposites' purpose.
Extreme anthropomorphizing and dehumanizing isolate and imperil us. We anthropomorphize because we desire connection and dehumanize because we're terrified, frequently of the connection we crave. Will we find balance?
Katrina Paulson ponders humanity, unanswered questions, and discoveries. Please check out her newsletters, Curious Adventure and Curious Life.

Sam Warain
3 years ago
Sam Altman, CEO of Open AI, foresees the next trillion-dollar AI company
“I think if I had time to do something else, I would be so excited to go after this company right now.”

Sam Altman, CEO of Open AI, recently discussed AI's present and future.
Open AI is important. They're creating the cyberpunk and sci-fi worlds.
They use the most advanced algorithms and data sets.
GPT-3...sound familiar? Open AI built most copyrighting software. Peppertype, Jasper AI, Rytr. If you've used any, you'll be shocked by the quality.
Open AI isn't only GPT-3. They created DallE-2 and Whisper (a speech recognition software released last week).
What will they do next? What's the next great chance?
Sam Altman, CEO of Open AI, recently gave a lecture about the next trillion-dollar AI opportunity.
Who is the organization behind Open AI?
Open AI first. If you know, skip it.
Open AI is one of the earliest private AI startups. Elon Musk, Greg Brockman, and Rebekah Mercer established OpenAI in December 2015.
OpenAI has helped its citizens and AI since its birth.
They have scary-good algorithms.
Their GPT-3 natural language processing program is excellent.
The algorithm's exponential growth is astounding. GPT-2 came out in November 2019. May 2020 brought GPT-3.
Massive computation and datasets improved the technique in just a year. New York Times said GPT-3 could write like a human.
Same for Dall-E. Dall-E 2 was announced in April 2022. Dall-E 2 won a Colorado art contest.
Open AI's algorithms challenge jobs we thought required human innovation.
So what does Sam Altman think?
The Present Situation and AI's Limitations
During the interview, Sam states that we are still at the tip of the iceberg.
So I think so far, we’ve been in the realm where you can do an incredible copywriting business or you can do an education service or whatever. But I don’t think we’ve yet seen the people go after the trillion dollar take on Google.
He's right that AI can't generate net new human knowledge. It can train and synthesize vast amounts of knowledge, but it simply reproduces human work.
“It’s not going to cure cancer. It’s not going to add to the sum total of human scientific knowledge.”
But the key word is yet.
And that is what I think will turn out to be wrong that most surprises the current experts in the field.
Reinforcing his point that massive innovations are yet to come.
But where?
The Next $1 Trillion AI Company
Sam predicts a bio or genomic breakthrough.
There’s been some promising work in genomics, but stuff on a bench top hasn’t really impacted it. I think that’s going to change. And I think this is one of these areas where there will be these new $100 billion to $1 trillion companies started, and those areas are rare.
Avoid human trials since they take time. Bio-materials or simulators are suitable beginning points.
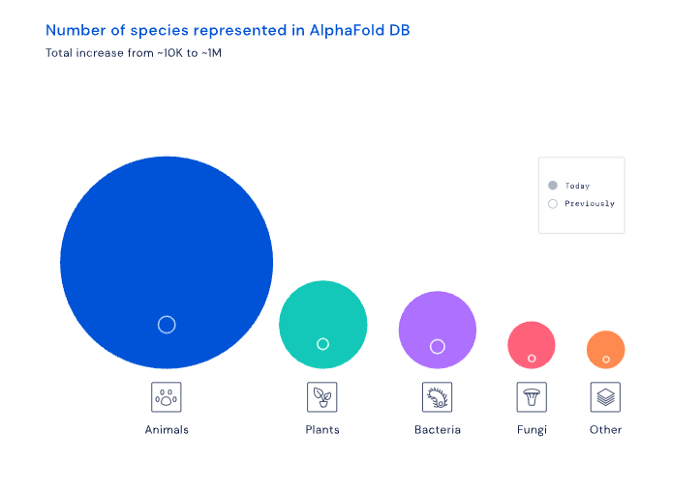
AI may have a breakthrough. DeepMind, an OpenAI competitor, has developed AlphaFold to predict protein 3D structures.
It could change how we see proteins and their function. AlphaFold could provide fresh understanding into how proteins work and diseases originate by revealing their structure. This could lead to Alzheimer's and cancer treatments. AlphaFold could speed up medication development by revealing how proteins interact with medicines.
Deep Mind offered 200 million protein structures for scientists to download (including sustainability, food insecurity, and neglected diseases).
Being in AI for 4+ years, I'm amazed at the progress. We're past the hype cycle, as evidenced by the collapse of AI startups like C3 AI, and have entered a productive phase.
We'll see innovative enterprises that could replace Google and other trillion-dollar companies.
What happens after AI adoption is scary and unpredictable. How will AGI (Artificial General Intelligence) affect us? Highly autonomous systems that exceed humans at valuable work (Open AI)
My guess is that the things that we’ll have to figure out are how we think about fairly distributing wealth, access to AGI systems, which will be the commodity of the realm, and governance, how we collectively decide what they can do, what they don’t do, things like that. And I think figuring out the answer to those questions is going to just be huge. — Sam Altman CEO

Nojus Tumenas
3 years ago
NASA: Strange Betelgeuse Explosion Just Took Place

Orion's red supergiant Betelgeuse erupted. This is astronomers' most magnificent occurrence.
Betelgeuse, a supergiant star in Orion, garnered attention in 2019 for its peculiar appearance. It continued to dim in 2020.
The star was previously thought to explode as a supernova. Studying the event has revealed what happened to Betelgeuse since it happened.
Astronomers saw that the star released a large amount of material, causing it to lose a section of its surface.
They have never seen anything like this and are unsure what caused the star to release so much material.
According to Harvard-Smithsonian Center for Astrophysics astrophysicist Andrea Dupre, astronomers' data reveals an unexplained mystery.
They say it's a new technique to examine star evolution. The James Webb telescope revealed the star's surface features.
Corona flares are stellar mass ejections. These eruptions change the Sun's outer atmosphere.
This could affect power grids and satellite communications if it hits Earth.
Betelgeuse's flare ejected four times more material than the Sun's corona flare.
Astronomers have monitored star rhythms for 50 years. They've seen its dimming and brightening cycle start, stop, and repeat.
Monitoring Betelgeuse's pulse revealed the eruption's power.
Dupre believes the star's convection cells are still amplifying the blast's effects, comparing it to an imbalanced washing machine tub.
The star's outer layer has returned to normal, Hubble data shows. The photosphere slowly rebuilds its springy surface.
Dupre noted the star's unusual behavior. For instance, it’s causing its interior to bounce.
This suggests that the mass ejections that caused the star's surface to lose mass were two separate processes.
Researchers hope to better understand star mass ejection with the James Webb Space Telescope.
You might also like

Sanjay Priyadarshi
3 years ago
Meet a Programmer Who Turned Down Microsoft's $10,000,000,000 Acquisition Offer
Failures inspire young developers

Jason citron created many products.
These products flopped.
Microsoft offered $10 billion for one of these products.
He rejected the offer since he was so confident in his success.
Let’s find out how he built a product that is currently valued at $15 billion.
Early in his youth, Jason began learning to code.
Jason's father taught him programming and IT.
His father wanted to help him earn money when he needed it.
Jason created video games and websites in high school.
Jason realized early on that his IT and programming skills could make him money.
Jason's parents misjudged his aptitude for programming.
Jason frequented online programming communities.
He looked for web developers. He created websites for those people.
His parents suspected Jason sold drugs online. When he said he used programming to make money, they were shocked.
They helped him set up a PayPal account.
Florida higher education to study video game creation
Jason never attended an expensive university.
He studied game design in Florida.
“Higher Education is an interesting part of society… When I work with people, the school they went to never comes up… only thing that matters is what can you do…At the end of the day, the beauty of silicon valley is that if you have a great idea and you can bring it to the life, you can convince a total stranger to give you money and join your project… This notion that you have to go to a great school didn’t end up being a thing for me.”
Jason's life was altered by Steve Jobs' keynote address.
After graduating, Jason joined an incubator.
Jason created a video-dating site first.
Bad idea.
Nobody wanted to use it when it was released, so they shut it down.
He made a multiplayer game.
It was released on Bebo. 10,000 people played it.
When Steve Jobs unveiled the Apple app store, he stopped playing.
The introduction of the app store resembled that of a new gaming console.
Jason's life altered after Steve Jobs' 2008 address.
“Whenever a new video game console is launched, that’s the opportunity for a new video game studio to get started, it’s because there aren’t too many games available…When a new PlayStation comes out, since it’s a new system, there’s only a handful of titles available… If you can be a launch title you can get a lot of distribution.”
Apple's app store provided a chance to start a video game company.
They released an app after 5 months of work.
Aurora Feint is the game.
Jason believed 1000 players in a week would be wonderful. A thousand players joined in the first hour.
Over time, Aurora Feints' game didn't gain traction. They don't make enough money to keep playing.
They could only make enough for one month.
Instead of buying video games, buy technology
Jason saw that they established a leaderboard, chat rooms, and multiplayer capabilities and believed other developers would want to use these.
They opted to sell the prior game's technology.
OpenFeint.
Assisting other game developers
They had no money in the bank to create everything needed to make the technology user-friendly.
Jason and Daniel designed a website saying:
“If you’re making a video game and want to have a drop in multiplayer support, you can use our system”
TechCrunch covered their website launch, and they gained a few hundred mailing list subscribers.
They raised seed funding with the mailing list.
Nearly all iPhone game developers started adopting the Open Feint logo.
“It was pretty wild… It was really like a whole social platform for people to play with their friends.”
What kind of a business model was it?
OpenFeint originally planned to make the software free for all games. As the game gained popularity, they demanded payment.
They later concluded it wasn't a good business concept.
It became free eventually.
Acquired for $104 million
Open Feint's users and employees grew tremendously.
GREE bought OpenFeint for $104 million in April 2011.
GREE initially committed to helping Jason and his team build a fantastic company.
Three or four months after the acquisition, Jason recognized they had a different vision.
He quit.
Jason's Original Vision for the iPad
Jason focused on distribution in 2012 to help businesses stand out.
The iPad market and user base were growing tremendously.
Jason said the iPad may replace mobile gadgets.
iPad gamers behaved differently than mobile gamers.
People sat longer and experienced more using an iPad.
“The idea I had was what if we built a gaming business that was more like traditional video games but played on tablets as opposed to some kind of mobile game that I’ve been doing before.”
Unexpected insight after researching the video game industry
Jason learned from studying the gaming industry that long-standing companies had advantages beyond a single release.
Previously, long-standing video game firms had their own distribution system. This distribution strategy could buffer time between successful titles.
Sony, Microsoft, and Valve all have gaming consoles and online stores.
So he built a distribution system.
He created a group chat app for gamers.
He envisioned a team-based multiplayer game with text and voice interaction.
His objective was to develop a communication network, release more games, and start a game distribution business.
Remaking the video game League of Legends
Jason and his crew reimagined a League of Legends game mode for 12-inch glass.
They adapted the game for tablets.
League of Legends was PC-only.
So they rebuilt it.
They overhauled the game and included native mobile experiences to stand out.
Hammer and Chisel was the company's name.
18 people worked on the game.
The game was funded. The game took 2.5 years to make.
Was the game a success?
July 2014 marked the game's release. The team's hopes were dashed.
Critics initially praised the game.
Initial installation was widespread.
The game failed.
As time passed, the team realized iPad gaming wouldn't increase much and mobile would win.
Jason was given a fresh idea by Stan Vishnevskiy.
Stan Vishnevskiy was a corporate engineer.
He told Jason about his plan to design a communication app without a game.
This concept seeded modern strife.
“The insight that he really had was to put a couple of dots together… we’re seeing our customers communicating around our own game with all these different apps and also ourselves when we’re playing on PC… We should solve that problem directly rather than needing to build a new game…we should start making it on PC.”
So began Discord.
Online socializing with pals was the newest trend.
Jason grew up playing video games with his friends.
He never played outside.
Jason had many great moments playing video games with his closest buddy, wife, and brother.
Discord was about providing a location for you and your group to speak and hang out.
Like a private cafe, bedroom, or living room.
Discord was developed for you and your friends on computers and phones.
You can quickly call your buddies during a game to conduct a conference call. Put the call on speaker and talk while playing.
Discord wanted to give every player a unique experience. Because coordinating across apps was a headache.
The entire team started concentrating on Discord.
Jason decided Hammer and Chisel would focus on their chat app.
Jason didn't want to make a video game.
How Discord attracted the appropriate attention
During the first five months, the entire team worked on the game and got feedback from friends.
This ensures product improvement. As a result, some teammates' buddies started utilizing Discord.
The team knew it would become something, but the result was buggy. App occasionally crashed.
Jason persuaded a gamer friend to write on Reddit about the software.
New people would find Discord. Why not?
Reddit users discovered Discord and 50 started using it frequently.
Discord was launched.
Rejecting the $10 billion acquisition proposal
Discord has increased in recent years.
It sends billions of messages.
Discord's users aren't tracked. They're privacy-focused.
Purchase offer
Covid boosted Discord's user base.
Weekly, billions of messages were transmitted.
Microsoft offered $10 billion for Discord in 2021.
Jason sold Open Feint for $104m in 2011.
This time, he believed in the product so much that he rejected Microsoft's offer.
“I was talking to some people in the team about which way we could go… The good thing was that most of the team wanted to continue building.”
Last time, Discord was valued at $15 billion.
Discord raised money on March 12, 2022.
The $15 billion corporation raised $500 million in 2021.

Tim Denning
3 years ago
I gave up climbing the corporate ladder once I realized how deeply unhappy everyone at the top was.
Restructuring and layoffs cause career reevaluation. Your career can benefit.

Once you become institutionalized, the corporate ladder is all you know.
You're bubbled. Extremists term it the corporate Matrix. I'm not so severe because the business world brainwashed me, too.
This boosted my corporate career.
Until I hit bottom.
15 months later, I view my corporate life differently. You may wish to advance professionally. Read this before you do.
Your happiness in the workplace may be deceptive.
I've been fortunate to spend time with corporate aces.
Working for 2.5 years in banking social media gave me some of these experiences. Earlier in my career, I recorded interviews with business leaders.
These people have titles like Chief General Manager and Head Of. New titles brought life-changing salaries.
They seemed happy.
I’d pass them in the hallway and they’d smile or shake my hand. I dreamt of having their life.
The ominous pattern
Unfiltered talks with some of them revealed a different world.
They acted well. They were skilled at smiling and saying the correct things. All had the same dark pattern, though.
Something felt off.
I found my conversations with them were generally for their benefit. They hoped my online antics as a writer/coach would shed light on their dilemma.
They'd tell me they wanted more. When you're one position away from CEO, it's hard not to wonder if this next move will matter.
What really displeased corporate ladder chasers
Before ascending further, consider these.
Zero autonomy
As you rise in a company, your days get busier.
Many people and initiatives need supervision. Everyone expects you to know business details. Weak when you don't. A poor leader is fired during the next restructuring and left to pursue their corporate ambition.
Full calendars leave no time for reflection. You can't have a coffee with a friend or waste a day.
You’re always on call. It’s a roll call kinda life.
Unable to express oneself freely
My 8 years of LinkedIn writing helped me meet these leaders.
I didn't think they'd care. Mistake.
Corporate leaders envied me because they wanted to talk freely again without corporate comms or a PR firm directing them what to say.
They couldn't share their flaws or inspiring experiences.
They wanted to.
Every day they were muzzled eroded by their business dream.
Limited family time
Top leaders had families.
They've climbed the corporate ladder. Nothing excellent happens overnight.
Corporate dreamers rarely saw their families.
Late meetings, customer functions, expos, training, leadership days, team days, town halls, and product demos regularly occurred after work.
Or they had to travel interstate or internationally for work events. They used bags and motel showers.
Initially, they said business class flights and hotels were nice. They'd get bored. 5-star hotels become monotonous.
No hotel beats home.
One leader said he hadn't seen his daughter much. They used to Facetime, but now that he's been gone so long, she rarely wants to talk to him.
So they iPad-parented.
You're miserable without your family.
Held captive by other job titles
Going up the business ladder seems like a battle.
Leaders compete for business gains and corporate advancement.
I saw shocking filthy tricks. Leaders would lie to seem nice.
Captives included top officials.
A different section every week. If they ran technology, the Head of Sales would argue their CRM cost millions. Or an Operations chief would battle a product team over support requests.
After one conflict, another began.
Corporate echelons are antagonistic. Huge pay and bonuses guarantee bad behavior.
Overly centered on revenue
As you rise, revenue becomes more prevalent. Most days, you'd believe revenue was everything. Here’s the problem…
Numbers drain us.
Unless you're a closet math nerd, contemplating and talking about numbers drains your creativity.
Revenue will never substitute impact.
Incapable of taking risks
Corporate success requires taking fewer risks.
Risks can cause dismissal. Risks can interrupt business. Keep things moving so you may keep getting paid your enormous salary and bonus.
Restructuring or layoffs are inevitable. All corporate climbers experience it.
On this fateful day, a small few realize the game they’ve been trapped in and escape. Most return to play for a new company, but it takes time.
Addiction keeps them trapped. You know nothing else. The rest is strange.
You start to think “I’m getting old” or “it’s nearly retirement.” So you settle yet again for the trappings of the corporate ladder game to nowhere.
Should you climb the corporate ladder?
Let me end on a surprising note.
Young people should ascend the corporate ladder. It teaches you business skills and helps support your side gig and (potential) online business.
Don't get trapped, shackled, or muzzled.
Your ideas and creativity become stifled after too much gaming play.
Corporate success won't bring happiness.
Find fulfilling employment that matters. That's it.

DC Palter
2 years ago
Why Are There So Few Startups in Japan?
Japan's startup challenge: 7 reasons

Every day, another Silicon Valley business is bought for a billion dollars, making its founders rich while growing the economy and improving consumers' lives.
Google, Amazon, Twitter, and Medium dominate our daily lives. Tesla automobiles and Moderna Covid vaccinations.
The startup movement started in Silicon Valley, California, but the rest of the world is catching up. Global startup buzz is rising. Except Japan.
644 of CB Insights' 1170 unicorns—successful firms valued at over $1 billion—are US-based. China follows with 302 and India third with 108.
Japan? 6!
1% of US startups succeed. The third-largest economy is tied with small Switzerland for startup success.
Mexico (8), Indonesia (12), and Brazil (12) have more successful startups than Japan (16). South Korea has 16. Yikes! Problem?
Why Don't Startups Exist in Japan More?
Not about money. Japanese firms invest in startups. To invest in startups, big Japanese firms create Silicon Valley offices instead of Tokyo.
Startups aren't the issue either. Local governments are competing to be Japan's Shirikon Tani, providing entrepreneurs financing, office space, and founder visas.
Startup accelerators like Plug and Play in Tokyo, Osaka, and Kyoto, the Startup Hub in Kobe, and Google for Startups are many.
Most of the companies I've encountered in Japan are either local offices of foreign firms aiming to expand into the Japanese market or small businesses offering local services rather than disrupting a staid industry with new ideas.
There must be a reason Japan can develop world-beating giant corporations like Toyota, Nintendo, Shiseido, and Suntory but not inventive startups.
Culture, obviously. Japanese culture excels in teamwork, craftsmanship, and quality, but it hates moving fast, making mistakes, and breaking things.
If you have a brilliant idea in Silicon Valley, quit your job, get money from friends and family, and build a prototype. To fund the business, you approach angel investors and VCs.
Most non-startup folks don't aware that venture capitalists don't want good, profitable enterprises. That's wonderful if you're developing a solid small business to consult, open shops, or make a specialty product. However, you must pay for it or borrow money. Venture capitalists want moon rockets. Silicon Valley is big or bust. Almost 90% will explode and crash. The few successes are remarkable enough to make up for the failures.
Silicon Valley's high-risk, high-reward attitude contrasts with Japan's incrementalism. Japan makes the best automobiles and cleanrooms, but it fails to produce new items that grow the economy.
Changeable? Absolutely. But, what makes huge manufacturing enterprises successful and what makes Japan a safe and comfortable place to live are inextricably connected with the lack of startups.
Barriers to Startup Development in Japan
These are the 7 biggest obstacles to Japanese startup success.
Unresponsive Employment Market
While the lifelong employment system in Japan is evolving, the average employee stays at their firm for 12 years (15 years for men at large organizations) compared to 4.3 years in the US. Seniority, not experience or aptitude, determines career routes, making it tough to quit a job to join a startup and then return to corporate work if it fails.
Conservative Buyers
Even if your product is buggy and undocumented, US customers will migrate to a cheaper, superior one. Japanese corporations demand perfection from their trusted suppliers and keep with them forever. Startups need income fast, yet product evaluation takes forever.
Failure intolerance
Japanese business failures harm lives. Failed forever. It hinders risk-taking. Silicon Valley embraces failure. Build another startup if your first fails. Build a third if that fails. Every setback is viewed as a learning opportunity for success.
4. No Corporate Purchases
Silicon Valley industrial giants will buy fast-growing startups for a lot of money. Many huge firms have stopped developing new goods and instead buy startups after the product is validated.
Japanese companies prefer in-house product development over startup acquisitions. No acquisitions mean no startup investment and no investor reward.
Startup investments can also be monetized through stock market listings. Public stock listings in Japan are risky because the Nikkei was stagnant for 35 years while the S&P rose 14x.
5. Social Unity Above Wealth
In Silicon Valley, everyone wants to be rich. That creates a competitive environment where everyone wants to succeed, but it also promotes fraud and societal problems.
Japan values communal harmony above individual success. Wealthy folks and overachievers are avoided. In Japan, renegades are nearly impossible.
6. Rote Learning Education System
Japanese high school graduates outperform most Americans. Nonetheless, Japanese education is known for its rote memorization. The American system, which fails too many kids, emphasizes creativity to create new products.
Immigration.
Immigrants start 55% of successful Silicon Valley firms. Some come for university, some to escape poverty and war, and some are recruited by Silicon Valley startups and stay to start their own.
Japan is difficult for immigrants to start a business due to language barriers, visa restrictions, and social isolation.
How Japan Can Promote Innovation
Patchwork solutions to deep-rooted cultural issues will not work. If customers don't buy things, immigration visas won't aid startups. Startups must have a chance of being acquired for a huge sum to attract investors. If risky startups fail, employees won't join.
Will Japan never have a startup culture?
Once a consensus is reached, Japan changes rapidly. A dwindling population and standard of living may lead to such consensus.
Toyota and Sony were firms with renowned founders who used technology to transform the world. Repeatable.
Silicon Valley is flawed too. Many people struggle due to wealth disparities, job churn and layoffs, and the tremendous ups and downs of the economy caused by stock market fluctuations.
The founders of the 10% successful startups are heroes. The 90% that fail and return to good-paying jobs with benefits are never mentioned.
Silicon Valley startup culture and Japanese corporate culture are opposites. Each have pros and cons. Big Japanese corporations make the most reliable, dependable, high-quality products yet move too slowly. That's good for creating cars, not social networking apps.
Can innovation and success be encouraged without eroding social cohesion? That can motivate software firms to move fast and break things while recognizing the beauty and precision of expert craftsmen? A hybrid culture where Japan can make the world's best and most original items. Hopefully.