



More on Entrepreneurship/Creators

Thomas Tcheudjio
3 years ago
If you don't crush these 3 metrics, skip the Series A.
I recently wrote about getting VCs excited about Marketplace start-ups. SaaS founders became envious!
Understanding how people wire tens of millions is the only Series A hack I recommend.
Few people understand the intellectual process behind investing.
VC is risk management.
Series A-focused VCs must cover two risks.
1. Market risk
You need a large market to cross a threshold beyond which you can build defensibilities. Series A VCs underwrite market risk.
They must see you have reached product-market fit (PMF) in a large total addressable market (TAM).
2. Execution risk
When evaluating your growth engine's blitzscaling ability, execution risk arises.
When investors remove operational uncertainty, they profit.
Series A VCs like businesses with derisked revenue streams. Don't raise unless you have a predictable model, pipeline, and growth.
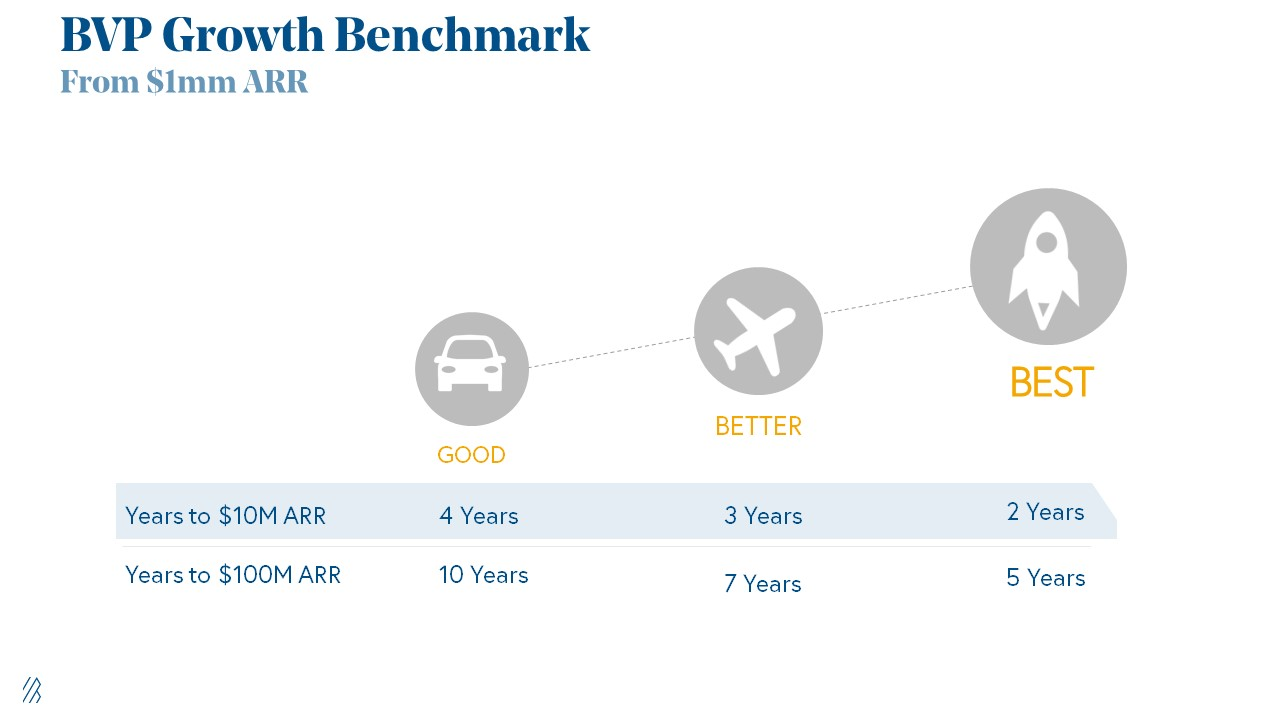
Please beat these 3 metrics before Series A:
Achieve $1.5m ARR in 12-24 months (Market risk)
Above 100% Net Dollar Retention. (Market danger)
Lead Velocity Rate supporting $10m ARR in 2–4 years (Execution risk)
Hit the 3 and you'll raise $10M in 4 months. Discussing 2/3 may take 6–7 months.
If none, don't bother raising and focus on becoming a capital-efficient business (Topics for other posts).
Let's examine these 3 metrics for the brave ones.
1. Lead Velocity Rate supporting €$10m ARR in 2 to 4 years
Last because it's the least discussed. LVR is the most reliable data when evaluating a growth engine, in my opinion.
SaaS allows you to see the future.
Monthly Sales and Sales Pipelines, two predictive KPIs, have poor data quality. Both are lagging indicators, and minor changes can cause huge modeling differences.
Analysts and Associates will trash your forecasts if they're based only on Monthly Sales and Sales Pipeline.
LVR, defined as month-over-month growth in qualified leads, is rock-solid. There's no lag. You can See The Future if you use Qualified Leads and a consistent formula and process to qualify them.
With this metric in your hand, scaling your company turns into an execution play on which VCs are able to perform calculations risk.
2. Above-100% Net Dollar Retention.
Net Dollar Retention is a better-known SaaS health metric than LVR.
Net Dollar Retention measures a SaaS company's ability to retain and upsell customers. Ask what $1 of net new customer spend will be worth in years n+1, n+2, etc.
Depending on the business model, SaaS businesses can increase their share of customers' wallets by increasing users, selling them more products in SaaS-enabled marketplaces, other add-ons, and renewing them at higher price tiers.
If a SaaS company's annualized Net Dollar Retention is less than 75%, there's a problem with the business.
Slack's ARR chart (below) shows how powerful Net Retention is. Layer chart shows how existing customer revenue grows. Slack's S1 shows 171% Net Dollar Retention for 2017–2019.

Slack S-1
3. $1.5m ARR in the last 12-24 months.
According to Point 9, $0.5m-4m in ARR is needed to raise a $5–12m Series A round.
Target at least what you raised in Pre-Seed/Seed. If you've raised $1.5m since launch, don't raise before $1.5m ARR.
Capital efficiency has returned since Covid19. After raising $2m since inception, it's harder to raise $1m in ARR.

P9's 2016-2021 SaaS Funding Napkin
In summary, less than 1% of companies VCs meet get funded. These metrics can help you win.
If there’s demand for it, I’ll do one on direct-to-consumer.
Cheers!

Raad Ahmed
3 years ago
How We Just Raised $6M At An $80M Valuation From 100+ Investors Using A Link (Without Pitching)
Lawtrades nearly failed three years ago.
We couldn't raise Series A or enthusiasm from VCs.
We raised $6M (at a $80M valuation) from 100 customers and investors using a link and no pitching.
Step-by-step:
We refocused our business first.
Lawtrades raised $3.7M while Atrium raised $75M. By comparison, we seemed unimportant.
We had to close the company or try something new.
As I've written previously, a pivot saved us. Our initial focus on SMBs attracted many unprofitable customers. SMBs needed one-off legal services, meaning low fees and high turnover.
Tech startups were different. Their General Councels (GCs) needed near-daily support, resulting in higher fees and lower churn than SMBs.
We stopped unprofitable customers and focused on power users. To avoid dilution, we borrowed against receivables. We scaled our revenue 10x, from $70k/mo to $700k/mo.
Then, we reconsidered fundraising (and do it differently)
This time was different. Lawtrades was cash flow positive for most of last year, so we could dictate our own terms. VCs were still wary of legaltech after Atrium's shutdown (though they were thinking about the space).
We neither wanted to rely on VCs nor dilute more than 10% equity. So we didn't compete for in-person pitch meetings.
AngelList Roll-Up Vehicle (RUV). Up to 250 accredited investors can invest in a single RUV. First, we emailed customers the RUV. Why? Because I wanted to help the platform's users.
Imagine if Uber or Airbnb let all drivers or Superhosts invest in an RUV. Humans make the platform, theirs and ours. Giving people a chance to invest increases their loyalty.
We expanded after initial interest.
We created a Journey link, containing everything that would normally go in an investor pitch:
- Slides
- Trailer (from me)
- Testimonials
- Product demo
- Financials
We could also link to our AngelList RUV and send the pitch to an unlimited number of people. Instead of 1:1, we had 1:10,000 pitches-to-investors.
We posted Journey's link in RUV Alliance Discord. 600 accredited investors noticed it immediately. Within days, we raised $250,000 from customers-turned-investors.
Stonks, which live-streamed our pitch to thousands of viewers, was interested in our grassroots enthusiasm. We got $1.4M from people I've never met.
These updates on Pump generated more interest. Facebook, Uber, Netflix, and Robinhood executives all wanted to invest. Sahil Lavingia, who had rejected us, gave us $100k.
We closed the round with public support.
Without a single pitch meeting, we'd raised $2.3M. It was a result of natural enthusiasm: taking care of the people who made us who we are, letting them move first, and leveraging their enthusiasm with VCs, who were interested.
We used network effects to raise $3.7M from a founder-turned-VC, bringing the total to $6M at a $80M valuation (which, by the way, I set myself).
What flipping the fundraising script allowed us to do:
We started with private investors instead of 2–3 VCs to show VCs what we were worth. This gave Lawtrades the ability to:
- Without meetings, share our vision. Many people saw our Journey link. I ended up taking meetings with people who planned to contribute $50k+, but still, the ratio of views-to-meetings was outrageously good for us.
- Leverage ourselves. Instead of us selling ourselves to VCs, they did. Some people with large checks or late arrivals were turned away.
- Maintain voting power. No board seats were lost.
- Utilize viral network effects. People-powered.
- Preemptively halt churn by turning our users into owners. People are more loyal and respectful to things they own. Our users make us who we are — no matter how good our tech is, we need human beings to use it. They deserve to be owners.
I don't blame founders for being hesitant about this approach. Pump and RUVs are new and scary. But it won’t be that way for long. Our approach redistributed some of the power that normally lies entirely with VCs, putting it into our hands and our network’s hands.
This is the future — another way power is shifting from centralized to decentralized.

Alex Mathers
3 years ago
400 articles later, nobody bothered to read them.
Writing for readers:
14 years of daily writing.
I post practically everything on social media. I authored hundreds of articles, thousands of tweets, and numerous volumes to almost no one.
Tens of thousands of readers regularly praise me.
I despised writing. I'm stuck now.
I've learned what readers like and what doesn't.
Here are some essential guidelines for writing with impact:
Readers won't understand your work if you can't.
Though obvious, this slipped me up. Share your truths.
Stories engage human brains.
Showing the journey of a person from worm to butterfly inspires the human spirit.
Overthinking hinders powerful writing.
The best ideas come from inner understanding in between thoughts.
Avoid writing to find it. Write.
Writing a masterpiece isn't motivating.
Write for five minutes to simplify. Step-by-step, entertaining, easy steps.
Good writing requires a willingness to make mistakes.
So write loads of garbage that you can edit into a good piece.
Courageous writing.
A courageous story will move readers. Personal experience is best.
Go where few dare.
Templates, outlines, and boundaries help.
Limitations enhance writing.
Excellent writing is straightforward and readable, removing all the unnecessary fat.
Use five words instead of nine.
Use ordinary words instead of uncommon ones.
Readers desire relatability.
Too much perfection will turn it off.
Write to solve an issue if you can't think of anything to write.
Instead, read to inspire. Best authors read.
Every tweet, thread, and novel must have a central idea.
What's its point?
This can make writing confusing.
️ Don't direct your reader.
Readers quit reading. Demonstrate, describe, and relate.
Even if no one responds, have fun. If you hate writing it, the reader will too.
You might also like

DC Palter
2 years ago
Why Are There So Few Startups in Japan?
Japan's startup challenge: 7 reasons

Every day, another Silicon Valley business is bought for a billion dollars, making its founders rich while growing the economy and improving consumers' lives.
Google, Amazon, Twitter, and Medium dominate our daily lives. Tesla automobiles and Moderna Covid vaccinations.
The startup movement started in Silicon Valley, California, but the rest of the world is catching up. Global startup buzz is rising. Except Japan.
644 of CB Insights' 1170 unicorns—successful firms valued at over $1 billion—are US-based. China follows with 302 and India third with 108.
Japan? 6!
1% of US startups succeed. The third-largest economy is tied with small Switzerland for startup success.
Mexico (8), Indonesia (12), and Brazil (12) have more successful startups than Japan (16). South Korea has 16. Yikes! Problem?
Why Don't Startups Exist in Japan More?
Not about money. Japanese firms invest in startups. To invest in startups, big Japanese firms create Silicon Valley offices instead of Tokyo.
Startups aren't the issue either. Local governments are competing to be Japan's Shirikon Tani, providing entrepreneurs financing, office space, and founder visas.
Startup accelerators like Plug and Play in Tokyo, Osaka, and Kyoto, the Startup Hub in Kobe, and Google for Startups are many.
Most of the companies I've encountered in Japan are either local offices of foreign firms aiming to expand into the Japanese market or small businesses offering local services rather than disrupting a staid industry with new ideas.
There must be a reason Japan can develop world-beating giant corporations like Toyota, Nintendo, Shiseido, and Suntory but not inventive startups.
Culture, obviously. Japanese culture excels in teamwork, craftsmanship, and quality, but it hates moving fast, making mistakes, and breaking things.
If you have a brilliant idea in Silicon Valley, quit your job, get money from friends and family, and build a prototype. To fund the business, you approach angel investors and VCs.
Most non-startup folks don't aware that venture capitalists don't want good, profitable enterprises. That's wonderful if you're developing a solid small business to consult, open shops, or make a specialty product. However, you must pay for it or borrow money. Venture capitalists want moon rockets. Silicon Valley is big or bust. Almost 90% will explode and crash. The few successes are remarkable enough to make up for the failures.
Silicon Valley's high-risk, high-reward attitude contrasts with Japan's incrementalism. Japan makes the best automobiles and cleanrooms, but it fails to produce new items that grow the economy.
Changeable? Absolutely. But, what makes huge manufacturing enterprises successful and what makes Japan a safe and comfortable place to live are inextricably connected with the lack of startups.
Barriers to Startup Development in Japan
These are the 7 biggest obstacles to Japanese startup success.
Unresponsive Employment Market
While the lifelong employment system in Japan is evolving, the average employee stays at their firm for 12 years (15 years for men at large organizations) compared to 4.3 years in the US. Seniority, not experience or aptitude, determines career routes, making it tough to quit a job to join a startup and then return to corporate work if it fails.
Conservative Buyers
Even if your product is buggy and undocumented, US customers will migrate to a cheaper, superior one. Japanese corporations demand perfection from their trusted suppliers and keep with them forever. Startups need income fast, yet product evaluation takes forever.
Failure intolerance
Japanese business failures harm lives. Failed forever. It hinders risk-taking. Silicon Valley embraces failure. Build another startup if your first fails. Build a third if that fails. Every setback is viewed as a learning opportunity for success.
4. No Corporate Purchases
Silicon Valley industrial giants will buy fast-growing startups for a lot of money. Many huge firms have stopped developing new goods and instead buy startups after the product is validated.
Japanese companies prefer in-house product development over startup acquisitions. No acquisitions mean no startup investment and no investor reward.
Startup investments can also be monetized through stock market listings. Public stock listings in Japan are risky because the Nikkei was stagnant for 35 years while the S&P rose 14x.
5. Social Unity Above Wealth
In Silicon Valley, everyone wants to be rich. That creates a competitive environment where everyone wants to succeed, but it also promotes fraud and societal problems.
Japan values communal harmony above individual success. Wealthy folks and overachievers are avoided. In Japan, renegades are nearly impossible.
6. Rote Learning Education System
Japanese high school graduates outperform most Americans. Nonetheless, Japanese education is known for its rote memorization. The American system, which fails too many kids, emphasizes creativity to create new products.
Immigration.
Immigrants start 55% of successful Silicon Valley firms. Some come for university, some to escape poverty and war, and some are recruited by Silicon Valley startups and stay to start their own.
Japan is difficult for immigrants to start a business due to language barriers, visa restrictions, and social isolation.
How Japan Can Promote Innovation
Patchwork solutions to deep-rooted cultural issues will not work. If customers don't buy things, immigration visas won't aid startups. Startups must have a chance of being acquired for a huge sum to attract investors. If risky startups fail, employees won't join.
Will Japan never have a startup culture?
Once a consensus is reached, Japan changes rapidly. A dwindling population and standard of living may lead to such consensus.
Toyota and Sony were firms with renowned founders who used technology to transform the world. Repeatable.
Silicon Valley is flawed too. Many people struggle due to wealth disparities, job churn and layoffs, and the tremendous ups and downs of the economy caused by stock market fluctuations.
The founders of the 10% successful startups are heroes. The 90% that fail and return to good-paying jobs with benefits are never mentioned.
Silicon Valley startup culture and Japanese corporate culture are opposites. Each have pros and cons. Big Japanese corporations make the most reliable, dependable, high-quality products yet move too slowly. That's good for creating cars, not social networking apps.
Can innovation and success be encouraged without eroding social cohesion? That can motivate software firms to move fast and break things while recognizing the beauty and precision of expert craftsmen? A hybrid culture where Japan can make the world's best and most original items. Hopefully.

Greg Satell
3 years ago
Focus: The Deadly Strategic Idea You've Never Heard Of (But Definitely Need To Know!

Steve Jobs' initial mission at Apple in 1997 was to destroy. He killed the Newton PDA and Macintosh clones. Apple stopped trying to please everyone under Jobs.
Afterward, there were few highly targeted moves. First, the pink iMac. Modest success. The iPod, iPhone, and iPad made Apple the world's most valuable firm. Each maneuver changed the company's center of gravity and won.
That's the idea behind Schwerpunkt, a German military term meaning "focus." Jobs didn't need to win everywhere, just where it mattered, so he focused Apple's resources on a few key goods. Finding your Schwerpunkt is more important than charts and analysis for excellent strategy.
Comparison of Relative Strength and Relative Weakness
The iPod, Apple's first major hit after Jobs' return, didn't damage Microsoft and the PC, but instead focused Apple's emphasis on a fledgling, fragmented market that generated "sucky" products. Apple couldn't have taken on the computer titans at this stage, yet it beat them.
The move into music players used Apple's particular capabilities, especially its ability to build simple, easy-to-use interfaces. Jobs' charisma and stature, along his understanding of intellectual property rights from Pixar, helped him build up iTunes store, which was a quagmire at the time.
In Good Strategy | Bad Strategy, management researcher Richard Rumelt argues that good strategy uses relative strength to counter relative weakness. To discover your main point, determine your abilities and where to effectively use them.
Steve Jobs did that at Apple. Microsoft and Dell, who controlled the computer sector at the time, couldn't enter the music player business. Both sought to produce iPod competitors but failed. Apple's iPod was nobody else's focus.
Finding The Center of Attention
In a military engagement, leaders decide where to focus their efforts by assessing commanders intent, the situation on the ground, the topography, and the enemy's posture on that terrain. Officers spend their careers learning about schwerpunkt.
Business executives must assess internal strengths including personnel, technology, and information, market context, competitive environment, and external partner ecosystems. Steve Jobs was a master at analyzing forces when he returned to Apple.
He believed Apple could integrate technology and design for the iPod and that the digital music player industry sucked. By analyzing competitors' products, he was convinced he could produce a smash by putting 1000 tunes in my pocket.
The only difficulty was there wasn't the necessary technology. External ecosystems were needed. On a trip to Japan to meet with suppliers, a Toshiba engineer claimed the company had produced a tiny memory drive approximately the size of a silver dollar.
Jobs knew the memory drive was his focus. He wrote a $10 million cheque and acquired exclusive technical rights. For a time, none of his competitors would be able to recreate his iPod with the 1000 songs in my pocket.
How to Enter the OODA Loop
John Boyd invented the OODA loop as a pilot to better his own decision-making. First OBSERVE your surroundings, then ORIENT that information using previous knowledge and experiences. Then you DECIDE and ACT, which changes the circumstance you must observe, orient, decide, and act on.
Steve Jobs used the OODA loop to decide to give Toshiba $10 million for a technology it had no use for. He compared the new information with earlier observations about the digital music market.
Then something much more interesting happened. The iPod was an instant hit, changing competition. Other computer businesses that competed in laptops, desktops, and servers created digital music players. Microsoft's Zune came out in 2006, Dell's Digital Jukebox in 2004. Both flopped.
By then, Apple was poised to unveil the iPhone, which would cause its competitors to Observe, Orient, Decide, and Act. Boyd named this OODA Loop infiltration. They couldn't gain the initiative by constantly reacting to Apple.
Microsoft and Dell were titans back then, but it's hard to recall. Apple went from near bankruptcy to crushing its competition via Schwerpunkt.
Rather than a destination, it is a journey
Trying to win everywhere is a strategic blunder. Win significant fights, not trivial skirmishes. Identifying a focal point to direct resources and efforts is the essence of Schwerpunkt.
When Steve Jobs returned to Apple, PC firms were competing, but he focused on digital music players, and the iPod made Apple a player. He launched the iPhone when his competitors were still reacting. When Steve Jobs said, "One more thing," at the end of a product presentation, he had a new focus.
Schwerpunkt isn't static; it's dynamic. Jobs' ability to observe, refocus, and modify the competitive backdrop allowed Apple to innovate consistently. His strategy was tailored to Apple's capabilities, customers, and ecosystem. Microsoft or Dell, better suited for the enterprise sector, couldn't succeed with a comparable approach.
There is no optimal strategy, only ones suited to a given environment, when relative strength might be used against relative weakness. Discovering the center of gravity where you can break through is more of a journey than a destination; it will become evident after you reach.

Sam Hickmann
3 years ago
What is headline inflation?
Headline inflation is the raw Consumer price index (CPI) reported monthly by the Bureau of labour statistics (BLS). CPI measures inflation by calculating the cost of a fixed basket of goods. The CPI uses a base year to index the current year's prices.
Explaining Inflation
As it includes all aspects of an economy that experience inflation, headline inflation is not adjusted to remove volatile figures. Headline inflation is often linked to cost-of-living changes, which is useful for consumers.
The headline figure doesn't account for seasonality or volatile food and energy prices, which are removed from the core CPI. Headline inflation is usually annualized, so a monthly headline figure of 4% inflation would equal 4% inflation for the year if repeated for 12 months. Top-line inflation is compared year-over-year.
Inflation's downsides
Inflation erodes future dollar values, can stifle economic growth, and can raise interest rates. Core inflation is often considered a better metric than headline inflation. Investors and economists use headline and core results to set growth forecasts and monetary policy.
Core Inflation
Core inflation removes volatile CPI components that can distort the headline number. Food and energy costs are commonly removed. Environmental shifts that affect crop growth can affect food prices outside of the economy. Political dissent can affect energy costs, such as oil production.
From 1957 to 2018, the U.S. averaged 3.64 percent core inflation. In June 1980, the rate reached 13.60%. May 1957 had 0% inflation. The Fed's core inflation target for 2022 is 3%.
Central bank:
A central bank has privileged control over a nation's or group's money and credit. Modern central banks are responsible for monetary policy and bank regulation. Central banks are anti-competitive and non-market-based. Many central banks are not government agencies and are therefore considered politically independent. Even if a central bank isn't government-owned, its privileges are protected by law. A central bank's legal monopoly status gives it the right to issue banknotes and cash. Private commercial banks can only issue demand deposits.
What are living costs?
The cost of living is the amount needed to cover housing, food, taxes, and healthcare in a certain place and time. Cost of living is used to compare the cost of living between cities and is tied to wages. If expenses are higher in a city like New York, salaries must be higher so people can live there.
What's U.S. bureau of labor statistics?
BLS collects and distributes economic and labor market data about the U.S. Its reports include the CPI and PPI, both important inflation measures.