



More on Personal Growth

Scott Stockdale
3 years ago
A Day in the Life of Lex Fridman Can Help You Hit 6-Month Goals

The Lex Fridman podcast host has interviewed Elon Musk.
Lex is a minimalist YouTuber. His videos are sloppy. Suits are his trademark.
In a video, he shares a typical day. I've smashed my 6-month goals using its ideas.
Here's his schedule.
Morning Mantra
Not woo-woo. Lex's mantra reflects his practicality.
Four parts.
Rulebook
"I remember the game's rules," he says.
Among them:
Sleeping 6–8 hours nightly
1–3 times a day, he checks social media.
Every day, despite pain, he exercises. "I exercise uninjured body parts."
Visualize
He imagines his day. "Like Sims..."
He says three things he's grateful for and contemplates death.
"Today may be my last"
Objectives
Then he visualizes his goals. He starts big. Five-year goals.
Short-term goals follow. Lex says they're year-end goals.
Near but out of reach.
Principles
He lists his principles. Assertions. His goals.
He acknowledges his cliche beliefs. Compassion, empathy, and strength are key.
Here's my mantra routine:

Four-Hour Deep Work
Lex begins a four-hour deep work session after his mantra routine. Today's toughest.
AI is Lex's specialty. His video doesn't explain what he does.
Clearly, he works hard.
Before starting, he has water, coffee, and a bathroom break.
"During deep work sessions, I minimize breaks."
He's distraction-free. Phoneless. Silence. Nothing. Any loose ideas are typed into a Google doc for later. He wants to work.
"Just get the job done. Don’t think about it too much and feel good once it’s complete." — Lex Fridman
30-Minute Social Media & Music
After his first deep work session, Lex rewards himself.
10 minutes on social media, 20 on music. Upload content and respond to comments in 10 minutes. 20 minutes for guitar or piano.
"In the real world, I’m currently single, but in the music world, I’m in an open relationship with this beautiful guitar. Open relationship because sometimes I cheat on her with the acoustic." — Lex Fridman
Two-hour exercise
Then exercise for two hours.
Daily runs six miles. Then he chooses how far to go. Run time is an hour.
He does bodyweight exercises. Every minute for 15 minutes, do five pull-ups and ten push-ups. It's David Goggins-inspired. He aims for an hour a day.
He's hungry. Before running, he takes a salt pill for electrolytes.
He'll then take a one-minute cold shower while listening to cheesy songs. Afterward, he might eat.
Four-Hour Deep Work
Lex's second work session.
He works 8 hours a day.
Again, zero distractions.
Eating
The video's meal doesn't look appetizing, but it's healthy.
It's ground beef with vegetables. Cauliflower is his "ground-floor" veggie. "Carrots are my go-to party food."
Lex's keto diet includes 1800–2000 calories.
He drinks a "nutrient-packed" Atheltic Greens shake and takes tablets. It's:
One daily tablet of sodium.
Magnesium glycinate tablets stopped his keto headaches.
Potassium — "For electrolytes"
Fish oil: healthy joints
“So much of nutrition science is barely a science… I like to listen to my own body and do a one-person, one-subject scientific experiment to feel good.” — Lex Fridman
Four-hour shallow session
This work isn't as mentally taxing.
Lex planned to:
Finish last session's deep work (about an hour)
Adobe Premiere podcasting (about two hours).
Email-check (about an hour). Three times a day max. First, check for emergencies.
If he's sick, he may watch Netflix or YouTube documentaries or visit friends.
“The possibilities of chaos are wide open, so I can do whatever the hell I want.” — Lex Fridman
Two-hour evening reading
Nonstop work.
Lex ends the day reading academic papers for an hour. "Today I'm skimming two machine learning and neuroscience papers"
This helps him "think beyond the paper."
He reads for an hour.
“When I have a lot of energy, I just chill on the bed and read… When I’m feeling tired, I jump to the desk…” — Lex Fridman
Takeaways
Lex's day-in-the-life video is inspiring.
He has positive energy and works hard every day.
Schedule:
Mantra Routine includes rules, visualizing, goals, and principles.
Deep Work Session #1: Four hours of focus.
10 minutes social media, 20 minutes guitar or piano. "Music brings me joy"
Six-mile run, then bodyweight workout. Two hours total.
Deep Work #2: Four hours with no distractions. Google Docs stores random thoughts.
Lex supplements his keto diet.
This four-hour session is "open to chaos."
Evening reading: academic papers followed by fiction.
"I value some things in life. Work is one. The other is loving others. With those two things, life is great." — Lex Fridman

Leon Ho
3 years ago
Digital Brainbuilding (Your Second Brain)

The human brain is amazing. As more scientists examine the brain, we learn how much it can store.
The human brain has 1 billion neurons, according to Scientific American. Each neuron creates 1,000 connections, totaling over a trillion. If each neuron could store one memory, we'd run out of room. [1]
What if you could store and access more info, freeing up brain space for problem-solving and creativity?
Build a second brain to keep up with rising knowledge (what I refer to as a Digital Brain). Effectively managing information entails realizing you can't recall everything.
Every action requires information. You need the correct information to learn a new skill, complete a project at work, or establish a business. You must manage information properly to advance your profession and improve your life.
How to construct a second brain to organize information and achieve goals.
What Is a Second Brain?
How often do you forget an article or book's key point? Have you ever wasted hours looking for a saved file?
If so, you're not alone. Information overload affects millions of individuals worldwide. Information overload drains mental resources and causes anxiety.
This is when the second brain comes in.
Building a second brain doesn't involve duplicating the human brain. Building a system that captures, organizes, retrieves, and archives ideas and thoughts. The second brain improves memory, organization, and recall.
Digital tools are preferable to analog for building a second brain.
Digital tools are portable and accessible. Due to these benefits, we'll focus on digital second-brain building.
Brainware
Digital Brains are external hard drives. It stores, organizes, and retrieves. This means improving your memory won't be difficult.
Memory has three components in computing:
Recording — storing the information
Organization — archiving it in a logical manner
Recall — retrieving it again when you need it
For example:
Due to rigorous security settings, many websites need you to create complicated passwords with special characters.
You must now memorize (Record), organize (Organize), and input this new password the next time you check in (Recall).
Even in this simple example, there are many pieces to remember. We can't recognize this new password with our usual patterns. If we don't use the password every day, we'll forget it. You'll type the wrong password when you try to remember it.
It's common. Is it because the information is complicated? Nope. Passwords are basically letters, numbers, and symbols.
It happens because our brains aren't meant to memorize these. Digital Brains can do heavy lifting.
Why You Need a Digital Brain
Dual minds are best. Birth brain is limited.
The cerebral cortex has 125 trillion synapses, according to a Stanford Study. The human brain can hold 2.5 million terabytes of digital data. [2]
Building a second brain improves learning and memory.
Learn and store information effectively
Faster information recall
Organize information to see connections and patterns
Build a Digital Brain to learn more and reach your goals faster. Building a second brain requires time and work, but you'll have more time for vital undertakings.
Why you need a Digital Brain:
1. Use Brainpower Effectively
Your brain has boundaries, like any organ. This is true while solving a complex question or activity. If you can't focus on a work project, you won't finish it on time.
Second brain reduces distractions. A robust structure helps you handle complicated challenges quickly and stay on track. Without distractions, it's easy to focus on vital activities.
2. Staying Organized
Professional and personal duties must be balanced. With so much to do, it's easy to neglect crucial duties. This is especially true for skill-building. Digital Brain will keep you organized and stress-free.
Life success requires action. Organized people get things done. Organizing your information will give you time for crucial tasks.
You'll finish projects faster with good materials and methods. As you succeed, you'll gain creative confidence. You can then tackle greater jobs.
3. Creativity Process
Creativity drives today's world. Creativity is mysterious and surprising for millions worldwide. Immersing yourself in others' associations, triggers, thoughts, and ideas can generate inspiration and creativity.
Building a second brain is crucial to establishing your creative process and building habits that will help you reach your goals. Creativity doesn't require perfection or overthinking.
4. Transforming Your Knowledge Into Opportunities
This is the age of entrepreneurship. Today, you can publish online, build an audience, and make money.
Whether it's a business or hobby, you'll have several job alternatives. Knowledge can boost your economy with ideas and insights.
5. Improving Thinking and Uncovering Connections
Modern career success depends on how you think. Instead of overthinking or perfecting, collect the best images, stories, metaphors, anecdotes, and observations.
This will increase your creativity and reveal connections. Increasing your imagination can help you achieve your goals, according to research. [3]
Your ability to recognize trends will help you stay ahead of the pack.
6. Credibility for a New Job or Business
Your main asset is experience-based expertise. Others won't be able to learn without your help. Technology makes knowledge tangible.
This lets you use your time as you choose while helping others. Changing professions or establishing a new business become learning opportunities when you have a Digital Brain.
7. Using Learning Resources
Millions of people use internet learning materials to improve their lives. Online resources abound. These include books, forums, podcasts, articles, and webinars.
These resources are mostly free or inexpensive. Organizing your knowledge can save you time and money. Building a Digital Brain helps you learn faster. You'll make rapid progress by enjoying learning.
How does a second brain feel?
Digital Brain has helped me arrange my job and family life for years.
No need to remember 1001 passwords. I never forget anything on my wife's grocery lists. Never miss a meeting. I can access essential information and papers anytime, anywhere.
Delegating memory to a second brain reduces tension and anxiety because you'll know what to do with every piece of information.
No information will be forgotten, boosting your confidence. Better manage your fears and concerns by writing them down and establishing a strategy. You'll understand the plethora of daily information and have a clear head.
How to Develop Your Digital Brain (Your Second Brain)
It's cheap but requires work.
Digital Brain development requires:
Recording — storing the information
Organization — archiving it in a logical manner
Recall — retrieving it again when you need it
1. Decide what information matters before recording.
To succeed in today's environment, you must manage massive amounts of data. Articles, books, webinars, podcasts, emails, and texts provide value. Remembering everything is impossible and overwhelming.
What information do you need to achieve your goals?
You must consolidate ideas and create a strategy to reach your aims. Your biological brain can imagine and create with a Digital Brain.
2. Use the Right Tool
We usually record information without any preparation - we brainstorm in a word processor, email ourselves a message, or take notes while reading.
This information isn't used. You must store information in a central location.
Different information needs different instruments.
Evernote is a top note-taking program. Audio clips, Slack chats, PDFs, text notes, photos, scanned handwritten pages, emails, and webpages can be added.
Pocket is a great software for saving and organizing content. Images, videos, and text can be sorted. Web-optimized design
Calendar apps help you manage your time and enhance your productivity by reminding you of your most important tasks. Calendar apps flourish. The best calendar apps are easy to use, have many features, and work across devices. These calendars include Google, Apple, and Outlook.
To-do list/checklist apps are useful for managing tasks. Easy-to-use, versatility, budget, and cross-platform compatibility are important when picking to-do list apps. Google Keep, Google Tasks, and Apple Notes are good to-do apps.
3. Organize data for easy retrieval
How should you organize collected data?
When you collect and organize data, you'll see connections. An article about networking can assist you comprehend web marketing. Saved business cards can help you find new clients.
Choosing the correct tools helps organize data. Here are some tools selection criteria:
Can the tool sync across devices?
Personal or team?
Has a search function for easy information retrieval?
Does it provide easy data categorization?
Can users create lists or collections?
Does it offer easy idea-information connections?
Does it mind map and visually organize thoughts?
Conclusion
Building a Digital Brain (second brain) helps us save information, think creatively, and implement ideas. Your second brain is a biological extension. It prevents amnesia, allowing you to tackle bigger creative difficulties.
People who love learning often consume information without using it. Every day, they postpone life-improving experiences until they're forgotten. Useful information becomes strength.
Reference
[1] ^ Scientific American: What Is the Memory Capacity of the Human Brain?
[2] ^ Clinical Neurology Specialists: What is the Memory Capacity of a Human Brain?
[3] ^ National Library of Medicine: Imagining Success: Multiple Achievement Goals and the Effectiveness of Imagery

NonConformist
3 years ago
Before 6 AM, read these 6 quotations.
These quotes will change your perspective.

I try to reflect on these quotes daily. Reading it in the morning can affect your day, decisions, and priorities. Let's start.
1. Friedrich Nietzsche once said, "He who has a why to live for can bear almost any how."
What's your life goal?
80% of people don't know why they live or what they want to accomplish in life if you ask them randomly.
Even those with answers may not pursue their why. Without a purpose, life can be dull.
Your why can guide you through difficult times.
Create a life goal. Growing may change your goal. Having a purpose in life prevents feeling lost.

2. Seneca said, "He who fears death will never do anything fit for a man in life."
FAILURE STINKS Yes.
This quote is great if you're afraid to try because of failure. What if I'm not made for it? What will they think if I fail?
This wastes most of our lives. Many people prefer not failing over trying something with a better chance of success, according to studies.
Failure stinks in the short term, but it can transform our lives over time.

3. Two men peered through the bars of their cell windows; one saw mud, the other saw stars. — Dale Carnegie
It’s not what you look at that matters; it’s what you see.
The glass-full-or-empty meme is everywhere. It's hard to be positive when facing adversity.
This is a skill. Positive thinking can change our future.
We should stop complaining about our life and how easy success is for others.
Seductive pessimism. Realize this and start from first principles.

4. “Smart people learn from everything and everyone, average people from their experiences, and stupid people already have all the answers.” — Socrates.
Knowing we're ignorant can be helpful.
Every person and situation teaches you something. You can learn from others' experiences so you don't have to. Analyzing your and others' actions and applying what you learn can be beneficial.
Reading (especially non-fiction or biographies) is a good use of time. Walter Issacson wrote Benjamin Franklin's biography. Ben Franklin's early mistakes and successes helped me in some ways.
Knowing everything leads to disaster. Every incident offers lessons.

5. “We must all suffer one of two things: the pain of discipline or the pain of regret or disappointment.“ — James Rohn
My favorite Jim Rohn quote.
Exercise hurts. Healthy eating can be painful. But they're needed to get in shape. Avoiding pain can ruin our lives.
Always choose progress over hopelessness. Myth: overnight success Everyone who has mastered a craft knows that mastery comes from overcoming laziness.
Turn off your inner critic and start working. Try Can't Hurt Me by David Goggins.

6. “A champion is defined not by their wins, but by how they can recover when they fail.“ — Serena Williams
Have you heard of Traf-o-Data?
Gates and Allen founded Traf-O-Data. After some success, it failed. Traf-o-Data's failure led to Microsoft.
Allen said Traf-O-Data's setback was important for Microsoft's first product a few years later. Traf-O-Data was a business failure, but it helped them understand microprocessors, he wrote in 2017.
“The obstacle in the path becomes the path. Never forget, within every obstacle is an opportunity to improve our condition.” — Ryan Holiday.
Bonus Quotes
More helpful quotes:
“Those who cannot change their minds cannot change anything.” — George Bernard Shaw.
“Do something every day that you don’t want to do; this is the golden rule for acquiring the habit of doing your duty without pain.” — Mark Twain.
“Never give up on a dream just because of the time it will take to accomplish it. The time will pass anyway.” — Earl Nightingale.
“A life spent making mistakes is not only more honorable, but more useful than a life spent doing nothing.” — George Bernard Shaw.
“We don’t stop playing because we grow old; we grow old because we stop playing.” — George Bernard Shaw.
Conclusion
Words are powerful. Utilize it. Reading these inspirational quotes will help you.
You might also like

Scrum Ventures
3 years ago
Trends from the Winter 2022 Demo Day at Y Combinators

Y Combinators Winter 2022 Demo Day continues the trend of more startups engaging in accelerator Demo Days. Our team evaluated almost 400 projects in Y Combinator's ninth year.
After Winter 2021 Demo Day, we noticed a hurry pushing shorter rounds, inflated valuations, and larger batches.
Despite the batch size, this event's behavior showed a return to normalcy. Our observations show that investors evaluate and fund businesses more carefully. Unlike previous years, more YC businesses gave investors with data rooms and thorough pitch decks in addition to valuation data before Demo Day.
Demo Day pitches were virtual and fast-paced, limiting unplanned meetings. Investors had more time and information to do their due research before meeting founders. Our staff has more time to study diverse areas and engage with interesting entrepreneurs and founders.
This was one of the most regionally diversified YC cohorts to date. This year's Winter Demo Day startups showed some interesting tendencies.
Trends and Industries to Watch Before Demo Day
Demo day events at any accelerator show how investment competition is influencing startups. As startups swiftly become scale-ups and big success stories in fintech, e-commerce, healthcare, and other competitive industries, entrepreneurs and early-stage investors feel pressure to scale quickly and turn a notion into actual innovation.
Too much eagerness can lead founders to focus on market growth and team experience instead of solid concepts, technical expertise, and market validation. Last year, YC Winter Demo Day funding cycles ended too quickly and valuations were unrealistically high.
Scrum Ventures observed a longer funding cycle this year compared to last year's Demo Day. While that seems promising, many factors could be contributing to change, including:
Market patterns are changing and the economy is becoming worse.
the industries that investors are thinking about.
Individual differences between each event batch and the particular businesses and entrepreneurs taking part
The Winter 2022 Batch's Trends
Each year, we also wish to examine trends among early-stage firms and YC event participants. More international startups than ever were anticipated to present at Demo Day.
Less than 50% of demo day startups were from the U.S. For the S21 batch, firms from outside the US were most likely in Latin America or Europe, however this year's batch saw a large surge in startups situated in Asia and Africa.
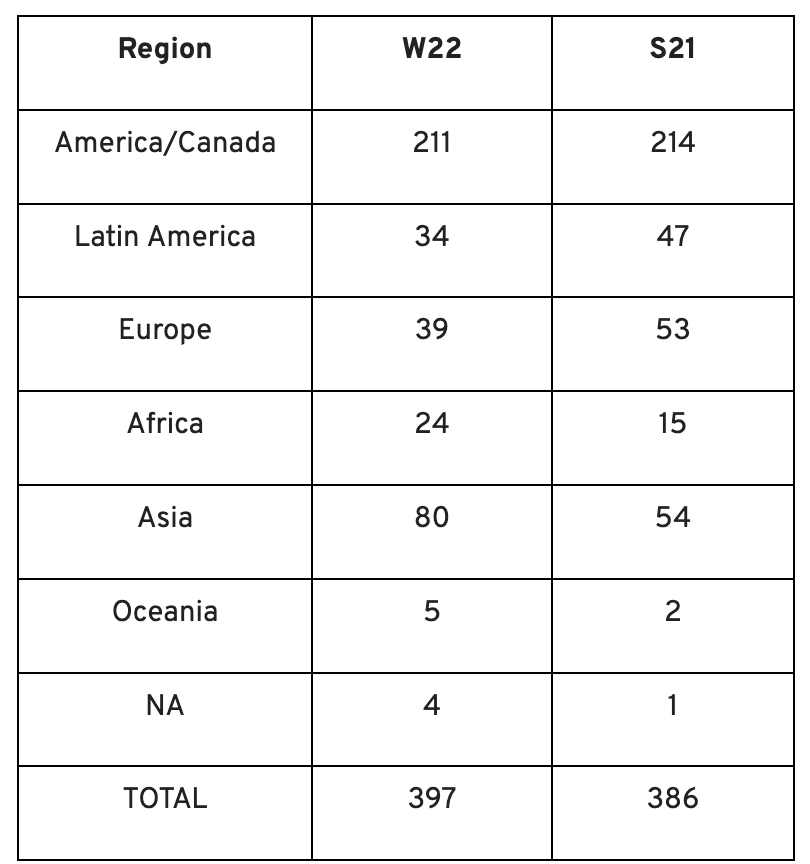
YC Startup Directory
163 out of 399 startups were B2B software and services companies. Financial, healthcare, and consumer startups were common.
Our team doesn't plan to attend every pitch or speak with every startup's founders or team members. Let's look at cleantech, Web3, and health and wellness startup trends.
Our Opinions Following Conversations with 87 Startups at Demo Day
In the lead-up to Demo Day, we spoke with 87 of the 125 startups going. Compared to B2C enterprises, B2B startups had higher average valuations. A few outliers with high valuations pushed B2B and B2C means above the YC-wide mean and median.
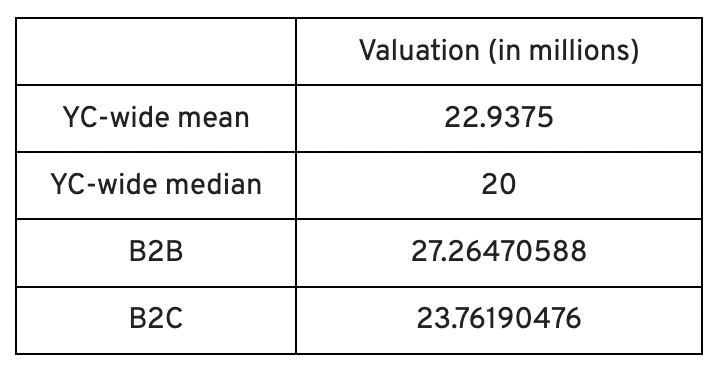
Many of these startups develop business and technology solutions we've previously covered. We've seen API, EdTech, creative platforms, and cybersecurity remain strong and increase each year.
While these persistent tendencies influenced the startups Scrum Ventures looked at and the founders we interacted with on Demo Day, new trends required more research and preparation. Let's examine cleantech, Web3, and health and wellness startups.
Hardware and software that is green
Cleantech enterprises demand varying amounts of funding for hardware and software. Although the same overarching trend is fueling the growth of firms in this category, each subgroup has its own strategy and technique for investigation and identifying successful investments.
Many cleantech startups we spoke to during the YC event are focused on helping industrial operations decrease or recycle carbon emissions.
Carbon Crusher: Creating carbon negative roads
Phase Biolabs: Turning carbon emissions into carbon negative products and carbon neutral e-fuels
Seabound: Capturing carbon dioxide emissions from ships
Fleetzero: Creating electric cargo ships
Impossible Mining: Sustainable seabed mining
Beyond Aero: Creating zero-emission private aircraft
Verdn: Helping businesses automatically embed environmental pledges for product and service offerings, boost customer engagement
AeonCharge: Allowing electric vehicle (EV) drivers to more easily locate and pay for EV charging stations
Phoenix Hydrogen: Offering a hydrogen marketplace and a connected hydrogen hub platform to connect supply and demand for hydrogen fuel and simplify hub planning and partner program expansion
Aklimate: Allowing businesses to measure and reduce their supply chain’s environmental impact
Pina Earth: Certifying and tracking the progress of businesses’ forestry projects
AirMyne: Developing machines that can reverse emissions by removing carbon dioxide from the air
Unravel Carbon: Software for enterprises to track and reduce their carbon emissions
Web3: NFTs, the metaverse, and cryptocurrency
Web3 technologies handle a wide range of business issues. This category includes companies employing blockchain technology to disrupt entertainment, finance, cybersecurity, and software development.
Many of these startups overlap with YC's FinTech trend. Despite this, B2C and B2B enterprises were evenly represented in Web3. We examined:
Stablegains: Offering consistent interest on cash balance from the decentralized finance (DeFi) market
LiquiFi: Simplifying token management with automated vesting contracts, tax reporting, and scheduling. For companies, investors, and finance & accounting
NFTScoring: An NFT trading platform
CypherD Wallet: A multichain wallet for crypto and NFTs with a non-custodial crypto debit card that instantly converts coins to USD
Remi Labs: Allowing businesses to more easily create NFT collections that serve as access to products, memberships, events, and more
Cashmere: A crypto wallet for Web3 startups to collaboratively manage funds
Chaingrep: An API that makes blockchain data human-readable and tokens searchable
Courtyard: A platform for securely storing physical assets and creating 3D representations as NFTs
Arda: “Banking as a Service for DeFi,” an API that FinTech companies can use to embed DeFi products into their platforms
earnJARVIS: A premium cryptocurrency management platform, allowing users to create long-term portfolios
Mysterious: Creating community-specific experiences for Web3 Discords
Winter: An embeddable widget that allows businesses to sell NFTs to users purchasing with a credit card or bank transaction
SimpleHash: An API for NFT data that provides compatibility across blockchains, standardized metadata, accurate transaction info, and simple integration
Lifecast: Tools that address motion sickness issues for 3D VR video
Gym Class: Virtual reality (VR) multiplayer basketball video game
WorldQL: An asset API that allows NFT creators to specify multiple in-game interpretations of their assets, increasing their value
Bonsai Desk: A software development kit (SDK) for 3D analytics
Campfire: Supporting virtual social experiences for remote teams
Unai: A virtual headset and Visual World experience
Vimmerse: Allowing creators to more easily create immersive 3D experiences
Fitness and health
Scrum Ventures encountered fewer health and wellness startup founders than Web3 and Cleantech. The types of challenges these organizations solve are still diverse. Several of these companies are part of a push toward customization in healthcare, an area of biotech set for growth for companies with strong portfolios and experienced leadership.
Here are several startups we considered:
Syrona Health: Personalized healthcare for women in the workplace
Anja Health: Personalized umbilical cord blood banking and stem cell preservation
Alfie: A weight loss program focused on men’s health that coordinates medical care, coaching, and “community-based competition” to help users lose an average of 15% body weight
Ankr Health: An artificial intelligence (AI)-enabled telehealth platform that provides personalized side effect education for cancer patients and data collection for their care teams
Koko — A personalized sleep program to improve at-home sleep analysis and training
Condition-specific telehealth platforms and programs:
Reviving Mind: Chronic care management covered by insurance and supporting holistic, community-oriented health care
Equipt Health: At-home delivery of prescription medical equipment to help manage chronic conditions like obstructive sleep apnea
LunaJoy: Holistic women’s healthcare management for mental health therapy, counseling, and medication
12 Startups from YC's Winter 2022 Demo Day to Watch
Bobidi: 10x faster AI model improvement
Artificial intelligence (AI) models have become a significant tool for firms to improve how well and rapidly they process data. Bobidi helps AI-reliant firms evaluate their models, boosting data insights in less time and reducing data analysis expenditures. The business has created a gamified community that offers a bug bounty for AI, incentivizing community members to test and find weaknesses in clients' AI models.
Magna: DeFi investment management and token vesting
Magna delivers rapid, secure token vesting so consumers may turn DeFi investments into primitives. Carta for Web3 allows enterprises to effortlessly distribute tokens to staff or investors. The Magna team hopes to allow corporations use locked tokens as collateral for loans, facilitate secondary liquidity so investors can sell shares on a public exchange, and power additional DeFi applications.
Perl Street: Funding for infrastructure
This Fintech firm intends to help hardware entrepreneurs get financing by [democratizing] structured finance, unleashing billions for sustainable infrastructure and next-generation hardware solutions. This network has helped hardware entrepreneurs achieve more than $140 million in finance, helping companies working on energy storage devices, EVs, and creating power infrastructure.
CypherD: Multichain cryptocurrency wallet
CypherD seeks to provide a multichain crypto wallet so general customers can explore Web3 products without knowledge hurdles. The startup's beta app lets consumers access crypto from EVM blockchains. The founders have crypto, financial, and startup experience.
Unravel Carbon: Enterprise carbon tracking and offsetting
Unravel Carbon's AI-powered decarbonization technology tracks companies' carbon emissions. Singapore-based startup focuses on Asia. The software can use any company's financial data to trace the supply chain and calculate carbon tracking, which is used to make regulatory disclosures and suggest carbon offsets.
LunaJoy: Precision mental health for women
LunaJoy helped women obtain mental health support throughout life. The platform combines data science to create a tailored experience, allowing women to access psychotherapy, medication management, genetic testing, and health coaching.
Posh: Automated EV battery recycling
Posh attempts to solve one of the EV industry's largest logistical difficulties. Millions of EV batteries will need to be decommissioned in the next decade, and their precious metals and residual capacity will go unused for some time. Posh offers automated, scalable lithium battery disassembly, making EV battery recycling more viable.
Unai: VR headset with 5x higher resolution
Unai stands apart from metaverse companies. Its VR headgear has five times the resolution of existing options and emphasizes human expression and interaction in a remote world. Maxim Perumal's method of latency reduction powers current VR headsets.
Palitronica: Physical infrastructure cybersecurity
Palitronica blends cutting-edge hardware and software to produce networked electronic systems that support crucial physical and supply chain infrastructure. The startup's objective is to build solutions that defend national security and key infrastructure from cybersecurity threats.
Reality Defender: Deepfake detection
Reality Defender alerts firms to bogus users and changed audio, video, and image files. Reality Deference's API and web app score material in real time to prevent fraud, improve content moderation, and detect deception.
Micro Meat: Infrastructure for the manufacture of cell-cultured meat
MicroMeat promotes sustainable meat production. The company has created technologies to scale up bioreactor-grown meat muscle tissue from animal cells. Their goal is to scale up cultured meat manufacturing so cultivated meat products can be brought to market feasibly and swiftly, boosting worldwide meat consumption.
Fleetzero: Electric cargo ships
This startup's battery technology will make cargo ships more sustainable and profitable. Fleetzero's electric cargo ships have five times larger profit margins than fossil fuel ships. Fleetzeros' founder has marine engineering, ship operations, and enterprise sales and business experience.
Colin Faife
3 years ago
The brand-new USB Rubber Ducky is much riskier than before.
The brand-new USB Rubber Ducky is much riskier than before.

With its own programming language, the well-liked hacking tool may now pwn you.
With a vengeance, the USB Rubber Ducky is back.
This year's Def Con hacking conference saw the release of a new version of the well-liked hacking tool, and its author, Darren Kitchen, was on hand to explain it. We put a few of the new features to the test and discovered that the most recent version is riskier than ever.
WHAT IS IT?
The USB Rubber Ducky seems to the untrained eye to be an ordinary USB flash drive. However, when you connect it to a computer, the computer recognizes it as a USB keyboard and will accept keystroke commands from the device exactly like a person would type them in.
Kitchen explained to me, "It takes use of the trust model built in, where computers have been taught to trust a human, in that anything it types is trusted to the same degree as the user is trusted. And a computer is aware that clicks and keystrokes are how people generally connect with it.

Over ten years ago, the first Rubber Ducky was published, quickly becoming a hacker favorite (it was even featured in a Mr. Robot scene). Since then, there have been a number of small upgrades, but the most recent Rubber Ducky takes a giant step ahead with a number of new features that significantly increase its flexibility and capability.
WHERE IS ITS USE?
The options are nearly unlimited with the proper strategy.
The Rubber Ducky has already been used to launch attacks including making a phony Windows pop-up window to collect a user's login information or tricking Chrome into sending all saved passwords to an attacker's web server. However, these attacks lacked the adaptability to operate across platforms and had to be specifically designed for particular operating systems and software versions.

The nuances of DuckyScript 3.0 are described in a new manual.
The most recent Rubber Ducky seeks to get around these restrictions. The DuckyScript programming language, which is used to construct the commands that the Rubber Ducky will enter into a target machine, receives a significant improvement with it. DuckyScript 3.0 is a feature-rich language that allows users to write functions, store variables, and apply logic flow controls, in contrast to earlier versions that were primarily limited to scripting keystroke sequences (i.e., if this... then that).
This implies that, for instance, the new Ducky can check to see if it is hooked into a Windows or Mac computer and then conditionally run code specific to each one, or it can disable itself if it has been attached to the incorrect target. In order to provide a more human effect, it can also generate pseudorandom numbers and utilize them to add a configurable delay between keystrokes.
The ability to steal data from a target computer by encoding it in binary code and transferring it through the signals intended to instruct a keyboard when the CapsLock or NumLock LEDs should light up is perhaps its most astounding feature. By using this technique, a hacker may plug it in for a brief period of time, excuse themselves by saying, "Sorry, I think that USB drive is faulty," and then take it away with all the credentials stored on it.
HOW SERIOUS IS THE RISK?
In other words, it may be a significant one, but because physical device access is required, the majority of people aren't at risk of being a target.
The 500 or so new Rubber Duckies that Hak5 brought to Def Con, according to Kitchen, were his company's most popular item at the convention, and they were all gone on the first day. It's safe to suppose that hundreds of hackers already possess one, and demand is likely to persist for some time.
Additionally, it has an online development toolkit that can be used to create attack payloads, compile them, and then load them onto the target device. A "payload hub" part of the website makes it simple for hackers to share what they've generated, and the Hak5 Discord is also busy with conversation and helpful advice. This makes it simple for users of the product to connect with a larger community.
It's too expensive for most individuals to distribute in volume, so unless your favorite cafe is renowned for being a hangout among vulnerable targets, it's doubtful that someone will leave a few of them there. To that end, if you intend to plug in a USB device that you discovered outside in a public area, pause to consider your decision.
WOULD IT WORK FOR ME?
Although the device is quite straightforward to use, there are a few things that could cause you trouble if you have no prior expertise writing or debugging code. For a while, during testing on a Mac, I was unable to get the Ducky to press the F4 key to activate the launchpad, but after forcing it to identify itself using an alternative Apple keyboard device ID, the problem was resolved.
From there, I was able to create a script that, when the Ducky was plugged in, would instantly run Chrome, open a new browser tab, and then immediately close it once more without requiring any action from the laptop user. Not bad for only a few hours of testing, and something that could be readily changed to perform duties other than reading technology news.
:max_bytes(150000):strip_icc():gifv():format(webp)/reiff_headshot-5bfc2a60c9e77c00519a70bd.jpg)
Nathan Reiff
3 years ago
Howey Test and Cryptocurrencies: 'Every ICO Is a Security'
What Is the Howey Test?
To determine whether a transaction qualifies as a "investment contract" and thus qualifies as a security, the Howey Test refers to the U.S. Supreme Court cass: the Securities Act of 1933 and the Securities Exchange Act of 1934. According to the Howey Test, an investment contract exists when "money is invested in a common enterprise with a reasonable expectation of profits from others' efforts."
The test applies to any contract, scheme, or transaction. The Howey Test helps investors and project backers understand blockchain and digital currency projects. ICOs and certain cryptocurrencies may be found to be "investment contracts" under the test.
Understanding the Howey Test
The Howey Test comes from the 1946 Supreme Court case SEC v. W.J. Howey Co. The Howey Company sold citrus groves to Florida buyers who leased them back to Howey. The company would maintain the groves and sell the fruit for the owners. Both parties benefited. Most buyers had no farming experience and were not required to farm the land.
The SEC intervened because Howey failed to register the transactions. The court ruled that the leaseback agreements were investment contracts.
This established four criteria for determining an investment contract. Investing contract:
- An investment of money
- n a common enterprise
- With the expectation of profit
- To be derived from the efforts of others
In the case of Howey, the buyers saw the transactions as valuable because others provided the labor and expertise. An income stream was obtained by only investing capital. As a result of the Howey Test, the transaction had to be registered with the SEC.
Howey Test and Cryptocurrencies
Bitcoin is notoriously difficult to categorize. Decentralized, they evade regulation in many ways. Regardless, the SEC is looking into digital assets and determining when their sale qualifies as an investment contract.
The SEC claims that selling digital assets meets the "investment of money" test because fiat money or other digital assets are being exchanged. Like the "common enterprise" test.
Whether a digital asset qualifies as an investment contract depends on whether there is a "expectation of profit from others' efforts."
For example, buyers of digital assets may be relying on others' efforts if they expect the project's backers to build and maintain the digital network, rather than a dispersed community of unaffiliated users. Also, if the project's backers create scarcity by burning tokens, the test is met. Another way the "efforts of others" test is met is if the project's backers continue to act in a managerial role.
These are just a few examples given by the SEC. If a project's success is dependent on ongoing support from backers, the buyer of the digital asset is likely relying on "others' efforts."
Special Considerations
If the SEC determines a cryptocurrency token is a security, many issues arise. It means the SEC can decide whether a token can be sold to US investors and forces the project to register.
In 2017, the SEC ruled that selling DAO tokens for Ether violated federal securities laws. Instead of enforcing securities laws, the SEC issued a warning to the cryptocurrency industry.
Due to the Howey Test, most ICOs today are likely inaccessible to US investors. After a year of ICOs, then-SEC Chair Jay Clayton declared them all securities.
SEC Chairman Gensler Agrees With Predecessor: 'Every ICO Is a Security'
Howey Test FAQs
How Do You Determine If Something Is a Security?
The Howey Test determines whether certain transactions are "investment contracts." Securities are transactions that qualify as "investment contracts" under the Securities Act of 1933 and the Securities Exchange Act of 1934.
The Howey Test looks for a "investment of money in a common enterprise with a reasonable expectation of profits from others' efforts." If so, the Securities Act of 1933 and the Securities Exchange Act of 1934 require disclosure and registration.
Why Is Bitcoin Not a Security?
Former SEC Chair Jay Clayton clarified in June 2018 that bitcoin is not a security: "Cryptocurrencies: Replace the dollar, euro, and yen with bitcoin. That type of currency is not a security," said Clayton.
Bitcoin, which has never sought public funding to develop its technology, fails the SEC's Howey Test. However, according to Clayton, ICO tokens are securities.
A Security Defined by the SEC
In the public and private markets, securities are fungible and tradeable financial instruments. The SEC regulates public securities sales.
The Supreme Court defined a security offering in SEC v. W.J. Howey Co. In its judgment, the court defines a security using four criteria:
- An investment contract's existence
- The formation of a common enterprise
- The issuer's profit promise
- Third-party promotion of the offering
Read original post.