





More on Web3 & Crypto

Franz Schrepf
3 years ago
What I Wish I'd Known About Web3 Before Building
Cryptoland rollercoaster

I've lost money in crypto.
Unimportant.
The real issue: I didn’t understand how.
I'm surrounded with winners. To learn more, I created my own NFTs, currency, and DAO.
Web3 is a hilltop castle. Everything is valuable, decentralized, and on-chain.
The castle is Disneyland: beautiful in images, but chaotic with lengthy lines and kids spending too much money on dressed-up animals.
When the throng and businesses are gone, Disneyland still has enchantment.

The Real Story of Web3
NFTs
Scarcity. Scarce NFTs. That's their worth.
Skull. Rare-looking!
Nonsense.
Bored Ape Yacht Club vs. my NFTs?
Marketing.
BAYC is amazing, but not for the reasons people believe. Apecoin and Otherside's art, celebrity following, and innovation? Stunning.
No other endeavor captured the zeitgeist better. Yet how long did you think it took to actually mint the NFTs?
1 hour? Maybe a week for the website?
Minting NFTs is incredibly easy. Kid-friendly. Developers are rare. Think about that next time somebody posts “DevS dO SMt!?”
NFTs will remain popular. These projects are like our Van Goghs and Monets. Still, be wary. It still uses exclusivity and wash selling like the OG art market.
Not all NFTs are art-related.
Soulbound and anonymous NFTs could offer up new use cases. Property rights, privacy-focused ID, open-source project verification. Everything.
NFTs build online trust through ownership.
We just need to evolve from the apes first.
NFTs' superpower is marketing until then.
Crypto currency
What the hell is a token?
99% of people are clueless.
So I invested in both coins and tokens. Same same. Only that they are not.
Coins have their own blockchain and developer/validator community. It's hard.
Creating a token on top of a blockchain? Five minutes.
Most consumers don’t understand the difference, creating an arbitrage opportunity: pretend you’re a serious project without having developers on your payroll.
Few market sites help. Take a look. See any tokens?
There's a hint one click deeper.

Some tokens are legitimate. Some coins are bad investments.
Tokens are utilized for DAO governance and DApp payments. Still, know who's behind a token. They might be 12 years old.
Coins take time and money. The recent LUNA meltdown indicates that currency investing requires research.
DAOs
Decentralized Autonomous Organizations (DAOs) don't work as you assume.
Yes, members can vote.
A productive organization requires more.
I've observed two types of DAOs.
Total decentralization total dysfunction
Centralized just partially. Community-driven.
A core team executes the DAO's strategy and roadmap in successful DAOs. The community owns part of the organization, votes on decisions, and holds the team accountable.
DAOs are public companies.
Amazing.
A shareholder meeting's logistics are staggering. DAOs may hold anonymous, secure voting quickly. No need for intermediaries like banks to chase up every shareholder.
Successful DAOs aren't totally decentralized. Large-scale voting and collaboration have never been easier.
And that’s all that matters.
Scale, speed.
My Web3 learnings
Disneyland is enchanting. Web3 too.
In a few cycles, NFTs may be used to build trust, not clout. Not speculating with coins. DAOs run organizations, not themselves.
Finally, some final thoughts:
NFTs will be a very helpful tool for building trust online. NFTs are successful now because of excellent marketing.
Tokens are not the same as coins. Look into any project before making a purchase. Make sure it isn't run by three 9-year-olds piled on top of one another in a trench coat, at the very least.
Not entirely decentralized, DAOs. We shall see a future where community ownership becomes the rule rather than the exception once we acknowledge this fact.
Crypto Disneyland is a rollercoaster with loops that make you sick.
Always buckle up.
Have fun!

Sam Hickmann
3 years ago
Nomad.xyz got exploited for $190M
Key Takeaways:
Another hack. This time was different. This is a doozy.
Why? Nomad got exploited for $190m. It was crypto's 5th-biggest hack. Ouch.
It wasn't hackers, but random folks. What happened:
A Nomad smart contract flaw was discovered. They couldn't drain the funds at once, so they tried numerous transactions. Rookie!
People noticed and copied the attack.
They just needed to discover a working transaction, substitute the other person's address with theirs, and run it.

In a two-and-a-half-hour attack, $190M was siphoned from Nomad Bridge.
Nomad is a novel approach to blockchain interoperability that leverages an optimistic mechanism to increase the security of cross-chain communication. — nomad.xyz
This hack was permissionless, therefore anyone could participate.
After the fatal blow, people fought over the scraps.
Cross-chain bridges remain a DeFi weakness and exploit target. When they collapse, it's typically total.
$190M...gobbled.
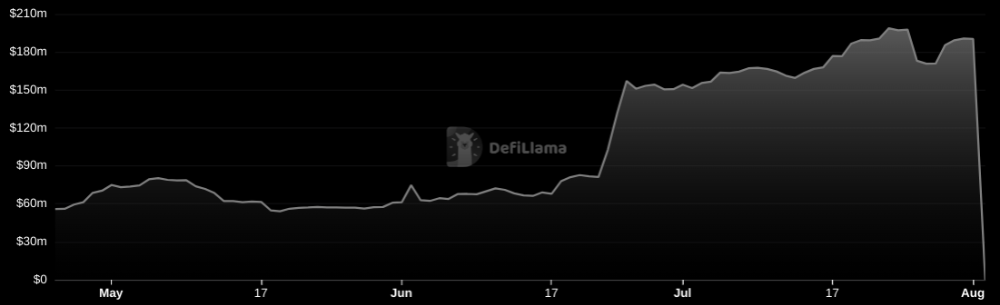
Unbacked assets are hurting Nomad-dependent chains. Moonbeam, EVMOS, and Milkomeda's TVLs dropped.
This incident is every-man-for-himself, although numerous whitehats exploited the issue...
But what triggered the feeding frenzy?
How did so many pick the bones?
After a normal upgrade in June, the bridge's Replica contract was initialized with a severe security issue. The 0x00 address was a trusted root, therefore all messages were valid by default.
After a botched first attempt (costing $350k in gas), the original attacker's exploit tx called process() without first 'proving' its validity.
The process() function executes all cross-chain messages and checks the merkle root of all messages (line 185).
The upgrade caused transactions with a'messages' value of 0 (invalid, according to old logic) to be read by default as 0x00, a trusted root, passing validation as 'proven'
Any process() calls were valid. In reality, a more sophisticated exploiter may have designed a contract to drain the whole bridge.
Copycat attackers simply copied/pasted the same process() function call using Etherscan, substituting their address.
The incident was a wild combination of crowdhacking, whitehat activities, and MEV-bot (Maximal Extractable Value) mayhem.
For example, 🍉🍉🍉. eth stole $4M from the bridge, but claims to be whitehat.

Others stood out for the wrong reasons. Repeat criminal Rari Capital (Artibrum) exploited over $3M in stablecoins, which moved to Tornado Cash.
The top three exploiters (with 95M between them) are:
$47M: 0x56D8B635A7C88Fd1104D23d632AF40c1C3Aac4e3
$40M: 0xBF293D5138a2a1BA407B43672643434C43827179
$8M: 0xB5C55f76f90Cc528B2609109Ca14d8d84593590E
Here's a list of all the exploiters:
The project conducted a Quantstamp audit in June; QSP-19 foreshadowed a similar problem.
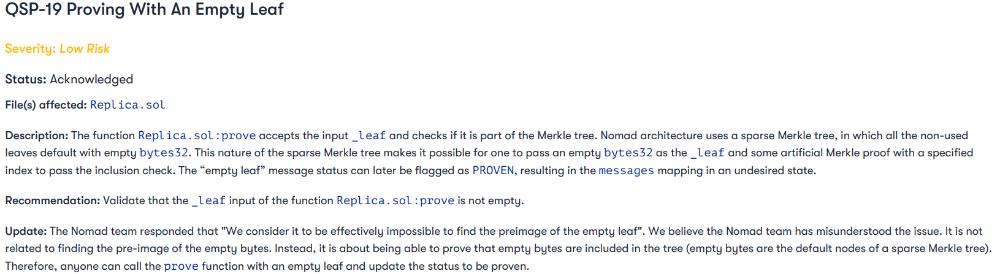
The auditor's comments that "We feel the Nomad team misinterpreted the issue" speak to a troubling attitude towards security that the project's "Long-Term Security" plan appears to confirm:
Concerns were raised about the team's response time to a live, public exploit; the team's official acknowledgement came three hours later.
"Removing the Replica contract as owner" stopped the exploit, but it was too late to preserve the cash.
Closed blockchain systems are only as strong as their weakest link.
The Harmony network is in turmoil after its bridge was attacked and lost $100M in late June.
What's next for Nomad's ecosystems?
Moonbeam's TVL is now $135M, EVMOS's is $3M, and Milkomeda's is $20M.
Loss of confidence may do more damage than $190M.
Cross-chain infrastructure is difficult to secure in a new, experimental sector. Bridge attacks can pollute an entire ecosystem or more.
Nomadic liquidity has no permanent home, so consumers will always migrate in pursuit of the "next big thing" and get stung when attentiveness wanes.
DeFi still has easy prey...
Sources: rekt.news & The Milk Road.

OnChain Wizard
3 years ago
How to make a >800 million dollars in crypto attacking the once 3rd largest stablecoin, Soros style
Everyone is talking about the $UST attack right now, including Janet Yellen. But no one is talking about how much money the attacker made (or how brilliant it was). Lets dig in.
Our story starts in late March, when the Luna Foundation Guard (or LFG) starts buying BTC to help back $UST. LFG started accumulating BTC on 3/22, and by March 26th had a $1bn+ BTC position. This is leg #1 that made this trade (or attack) brilliant.
The second leg comes in the form of the 4pool Frax announcement for $UST on April 1st. This added the second leg needed to help execute the strategy in a capital efficient way (liquidity will be lower and then the attack is on).
We don't know when the attacker borrowed 100k BTC to start the position, other than that it was sold into Kwon's buying (still speculation). LFG bought 15k BTC between March 27th and April 11th, so lets just take the average price between these dates ($42k).
So you have a ~$4.2bn short position built. Over the same time, the attacker builds a $1bn OTC position in $UST. The stage is now set to create a run on the bank and get paid on your BTC short. In anticipation of the 4pool, LFG initially removes $150mm from 3pool liquidity.
The liquidity was pulled on 5/8 and then the attacker uses $350mm of UST to drain curve liquidity (and LFG pulls another $100mm of liquidity).
But this only starts the de-pegging (down to 0.972 at the lows). LFG begins selling $BTC to defend the peg, causing downward pressure on BTC while the run on $UST was just getting started.
With the Curve liquidity drained, the attacker used the remainder of their $1b OTC $UST position ($650mm or so) to start offloading on Binance. As withdrawals from Anchor turned from concern into panic, this caused a real de-peg as people fled for the exits
So LFG is selling $BTC to restore the peg while the attacker is selling $UST on Binance. Eventually the chain gets congested and the CEXs suspend withdrawals of $UST, fueling the bank run panic. $UST de-pegs to 60c at the bottom, while $BTC bleeds out.
The crypto community panics as they wonder how much $BTC will be sold to keep the peg. There are liquidations across the board and LUNA pukes because of its redemption mechanism (the attacker very well could have shorted LUNA as well). BTC fell 25% from $42k on 4/11 to $31.3k
So how much did our attacker make? There aren't details on where they covered obviously, but if they are able to cover (or buy back) the entire position at ~$32k, that means they made $952mm on the short.
On the $350mm of $UST curve dumps I don't think they took much of a loss, lets assume 3% or just $11m. And lets assume that all the Binance dumps were done at 80c, thats another $125mm cost of doing business. For a grand total profit of $815mm (bf borrow cost).
BTC was the perfect playground for the trade, as the liquidity was there to pull it off. While having LFG involved in BTC, and foreseeing they would sell to keep the peg (and prevent LUNA from dying) was the kicker.
Lastly, the liquidity being low on 3pool in advance of 4pool allowed the attacker to drain it with only $350mm, causing the broader panic in both BTC and $UST. Any shorts on LUNA would've added a lot of P&L here as well, with it falling -65% since 5/7.
And for the reply guys, yes I know a lot of this involves some speculation & assumptions. But a lot of money was made here either way, and I thought it would be cool to dive into how they did it.
You might also like

Dr Mehmet Yildiz
3 years ago
How I train my brain daily for clarity and productivity.
I use a conceptual and practical system I developed decades ago as an example.

Since childhood, I've been interested in the brain-mind connection, so I developed a system using scientific breakthroughs, experiments, and the experiences of successful people in my circles.
This story provides a high-level overview of a custom system to inform and inspire readers. Creating a mind gym was one of my best personal and professional investments.
Such a complex system may not be possible for everyone or appear luxurious at first. However, the process and approach may help you find more accessible and viable solutions.
Visualizing the brain as a muscle, I learned to stimulate it with physical and mental exercises, applying a new mindset and behavioral changes.
My methods and practices may not work for others because we're all different. I focus on the approach's principles and highlights so you can create your own program.
Some create a conceptual and practical system intuitively, and others intellectually. Both worked. I see intellect and intuition as higher selves.
The mental tools I introduce are based on lifestyle changes and can be personalized by anyone, barring physical constraints or underlying health conditions.
Some people can't meditate despite wanting to due to mental constraints. This story lacks exceptions.
People's systems may vary. Many have used my tools successfully. All have scientific backing because their benefits attracted scientists. None are unethical or controversial.
My focus is cognition, which is the neocortex's ability. These practices and tools can affect the limbic and reptilian brain regions.
A previous article discussed brain health's biological aspects. This article focuses on psychology.
Thinking, learning, and remembering are cognitive abilities. Cognitive abilities determine our health and performance.
Cognitive health is the ability to think, concentrate, learn, and remember. Cognitive performance boosting involves various tools and processes. My system and protocols address cognitive health and performance.
As a biological organ, the brain's abilities decline with age, especially if not used regularly. Older people have more neurodegenerative disorders like dementia.
As aging is inevitable, I focus on creating cognitive reserves to remain mentally functional as we age and face mental decline or cognitive impairment.
My protocols focus on neurogenesis, or brain growth and maintenance. Neurons and connections can grow at any age.
Metacognition refers to knowing our cognitive abilities, like thinking about thinking and learning how to learn.
In the following sections, I provide an overview of my system, mental tools, and protocols.
This system summarizes my 50-year career. Some may find it too abstract, so I give examples.
First, explain the system. Section 2 introduces activities. Third, how to measure and maintain mental growth.
1 — Developed a practical mental gym.
The mental gym is a metaphor for the physical fitness gym to improve our mental muscles.
This concept covers brain and mind functionality. Integrated biological and psychological components.
I'll describe my mental gym so my other points make sense. My mental gym has physical and mental tools.
Mindfulness, meditation, visualization, self-conversations, breathing exercises, expressive writing, working in a flow state, reading, music, dance, isometric training, barefoot walking, cold/heat exposure, CBT, and social engagements are regular tools.
Dancing, walking, and thermogenesis are body-related tools. As the brain is part of the body and houses the mind, these tools can affect mental abilities such as attention, focus, memory, task switching, and problem-solving.
Different people may like different tools. I chose these tools based on my needs, goals, and lifestyle. They're just examples. You can choose tools that fit your goals and personality.
2 — Performed tasks regularly.
These tools gave me clarity. They became daily hobbies. Some I did alone, others with others.
Some examples: I meditate daily. Even though my overactive mind made daily meditation difficult at first, I now enjoy it. Meditation three times a day sharpens my mind.
Self-talk is used for self-therapy and creativity. Self-talk was initially difficult, but neurogenesis rewired my brain to make it a habit.
Cold showers, warm baths with Epsom salts, fasting, barefoot walks on the beach or grass, dancing, calisthenics, trampoline hopping, and breathing exercises increase my mental clarity, creativity, and productivity.
These exercises can increase BDNF, which promotes nervous system growth. They improve mental capacity and performance by increasing blood flow and brain oxygenation.
I use weekly and occasional activities like dry saunas, talking with others, and community activities.
These activities stimulate the brain and mind, improving performance and cognitive capacity.
3 — Measured progress, set growth goals.
Measuring progress helps us stay on track. Without data, it's hard to stay motivated. When we face inevitable setbacks, we may abandon our dreams.
I created a daily checklist for a spreadsheet with macros. I tracked how often and long I did each activity.
I measured my progress objectively and subjectively. In the progress spreadsheet, I noted my meditation hours and subjective feelings.
In another column, I used good, moderate, and excellent to get qualitative data. It took time and effort. Later, I started benefiting from this automated structure.
Creating a page for each activity, such as meditation, self-talk, cold showers, walking, expressive writing, personal interactions, etc., gave me empirical data I could analyze, modify, and graph to show progress.
Colored charts showed each area's strengths and weaknesses.
Strengths motivate me to continue them. Identifying weaknesses helped me improve them.
As the system matured, data recording became a habit and took less time. I saw the result immediately because I automated the charts when I entered daily data. Early time investment paid off later.
Mind Gym Benefits, Effective Use, and Progress Measuring
This concept helped me move from comfort to risk. I accept things as they are.
Turnarounds were made. I stopped feeling "Fight-Flight-Freeze" and maintained self-control.
I tamed my overactive amygdala by strengthening my brain. Stress and anxiety decreased. With these shifts, I accepted criticism and turned envy into admiration. Clarity improved.
When the cognitive part of the brain became stronger and the primitive part was tamed, managing thoughts and emotions became easier. My AQ increased. I learned to tolerate people, physical, mental, and emotional obstacles.
Accessing vast information sources in my subconscious mind through an improved RAS allowed me to easily tap into my higher self and recognize flaws in my lower self.
Summary
The brain loves patterns and routines, so habits help. Observing, developing, and monitoring habits mindfully can be beneficial. Mindfulness helps us achieve this goal systematically.
As body and mind are connected, we must consider both when building habits. Consistent and joyful practices can strengthen neurons and neural connections.
Habits help us accomplish more with less effort. Regularly using mental tools and processes can improve our cognitive health and performance as we age.
Creating daily habits to improve cognitive abilities can sharpen our minds and boost our well-being.
Some apps monitor our activities and behavior to help build habits. If you can't replicate my system, try these apps. Some smartwatches and fitness devices include them.
Set aside time each day for mental activities you enjoy. Regular scheduling and practice can strengthen brain regions and form habits. Once you form habits, tasks become easy.
Improving our minds is a lifelong journey. It's easier and more sustainable to increase our efforts daily, weekly, monthly, or annually.
Despite life's ups and downs, many want to remain calm and cheerful.
This valuable skill is unrelated to wealth or fame. It's about our mindset, fueled by our biological and psychological needs.
Here are some lessons I've learned about staying calm and composed despite challenges and setbacks.
1 — Tranquillity starts with observing thoughts and feelings.
2 — Clear the mental clutter and emotional entanglements with conscious breathing and gentle movements.
3 — Accept situations and events as they are with no resistance.
4 — Self-love can lead to loving others and increasing compassion.
5 — Count your blessings and cultivate gratitude.
Clear thinking can bring joy and satisfaction. It's a privilege to wake up with a healthy body and clear mind, ready to connect with others and serve them.
Thank you for reading my perspectives. I wish you a healthy and happy life.

Jess Rifkin
3 years ago
As the world watches the Russia-Ukraine border situation, This bill would bar aid to Ukraine until the Mexican border is secured.
Although Mexico and Ukraine are thousands of miles apart, this legislation would link their responses.
Context
Ukraine was a Soviet republic until 1991. A significant proportion of the population, particularly in the east, is ethnically Russian. In February, the Russian military invaded Ukraine, intent on overthrowing its democratically elected government.
This could be the biggest European land invasion since WWII. In response, President Joe Biden sent 3,000 troops to NATO countries bordering Ukraine to help with Ukrainian refugees, with more troops possible if the situation worsened.
In July 2021, the US Border Patrol reported its highest monthly encounter total since March 2000. Some Republicans compare Biden's response to the Mexican border situation to his response to the Ukrainian border situation, though the correlation is unclear.
What the bills do
Two new Republican bills seek to link the US response to Ukraine to the situation in Mexico.
The Secure America's Borders First Act would prohibit federal funding for Ukraine until the US-Mexico border is “operationally controlled,” including a wall as promised by former President Donald Trump. (The bill even mandates a 30-foot-high wall.)
The USB (Ukraine and Southern Border) Act, introduced on February 8 by Rep. Matt Rosendale (R-MT0), would allow the US to support Ukraine, but only if the number of Armed Forces deployed there is less than the number deployed to the Mexican border. Madison Cawthorne introduced H.R. 6665 on February 9th (R-NC11).
What backers say
Supporters argue that even if the US should militarily assist Ukraine, our own domestic border situation should take precedence.
After failing to secure our own border and protect our own territorial integrity, ‘America Last' politicians on both sides of the aisle now tell us that we must do so for Ukraine. “Before rushing America into another foreign conflict over an Eastern European nation's border thousands of miles from our shores, they should first secure our southern border.”
“If Joe Biden truly cared about Americans, he would prioritize national security over international affairs,” Rep. Cawthorn said in a separate press release. The least we can do to secure our own country is send the same number of troops to the US-Mexico border to assist our border patrol agents working diligently to secure America.
What opponents say
The president has defended his Ukraine and Mexico policies, stating that both seek peace and diplomacy.
Our nations [the US and Mexico] have a long and complicated history, and we haven't always been perfect neighbors, but we have seen the power and purpose of cooperation,” Biden said in 2021. “We're safer when we work together, whether it's to manage our shared border or stop the pandemic. [In both the Obama and Biden administration], we made a commitment that we look at Mexico as an equal, not as somebody who is south of our border.”
No mistake: If Russia goes ahead with its plans, it will be responsible for a catastrophic and unnecessary war of choice. To protect our collective security, the United States and our allies are ready to defend every inch of NATO territory. We won't send troops into Ukraine, but we will continue to support the Ukrainian people... But, I repeat, Russia can choose diplomacy. It is not too late to de-escalate and return to the negotiating table.”
Odds of passage
The Secure America's Borders First Act has nine Republican sponsors. Either the House Armed Services or Foreign Affairs Committees may vote on it.
Rep. Paul Gosar, a Republican, co-sponsored the USB Act (R-AZ4). The House Armed Services Committee may vote on it.
With Republicans in control, passage is unlikely.

Katharine Valentino
3 years ago
A Gun-toting Teacher Is Like a Cook With Rat Poison
Pink or blue AR-15s?
A teacher teaches; a gun kills. Killing isn't teaching. Killing is opposite of teaching.
Without 27 school shootings this year, we wouldn't be talking about arming teachers. Gun makers, distributors, and the NRA cause most school shootings. Gun makers, distributors, and the NRA wouldn't be huge business if weapons weren't profitable.
Guns, ammo, body armor, holsters, concealed carriers, bore sights, cleaner kits, spare magazines and speed loaders, gun safes, and ear protection are sold. And more guns.
And lots more profit.
Guns aren't bread. You eat a loaf of bread in a week or so and then must buy more. Bread makers will make money. Winchester 94.30–30 1899 Lever Action Rifle from 1894 still kills. (For safety, I won't link to the ad.) Gun makers don't object if you collect antique weapons, but they need you to buy the latest, in-style killing machine. The youngster who killed 19 students and 2 teachers at Robb Elementary School in Uvalde, Texas, used an AR-15. Better yet, two.
Salvador Ramos, the Robb Elementary shooter, is a "killing influencer" He pushes consumers to buy items, which benefits manufacturers and distributors. Like every previous AR-15 influencer, he profits Colt, the rifle's manufacturer, and 52,779 gun dealers in the U.S. Ramos and other AR-15 influences make us fear for our safety and our children's. Fearing for our safety, we acquire 20 million firearms a year and live in a gun culture.
So now at school, we want to arm teachers.
Consider. Which of your teachers would you have preferred in body armor with a gun drawn?
Miss Summers? Remember her bringing daisies from her yard to second grade? She handed each student a beautiful flower. Miss Summers loved everyone, even those with AR-15s. She can't shoot.
Frasier? Mr. Frasier turned a youngster over down to explain "invert." Mr. Frasier's hands shook when he wasn't flipping fifth-graders and fractions. He may have shot wrong.
Mrs. Barkley barked in high school English class when anyone started an essay with "But." Mrs. Barkley dubbed Abie a "Jewboy" and gave him terrible grades. Arming Miss Barkley is like poisoning the chef.
Think back. Do you remember a teacher with a gun? No. Arming teachers so the gun industry can make more money is the craziest idea ever.
Or maybe you agree with Ted Cruz, the gun lobby-bought senator, that more guns reduce gun violence. After the next school shooting, you'll undoubtedly talk about arming teachers and pupils. Colt will likely develop a backpack-sized, lighter version of its popular killing machine in pink and blue for kids and boys. The MAR-15? (M for mini).
This post is a summary. Read the full one here.