





More on Productivity

Mickey Mellen
2 years ago
Shifting from Obsidian to Tana?

I relocated my notes database from Roam Research to Obsidian earlier this year expecting to stay there for a long. Obsidian is a terrific tool, and I explained my move in that post.
Moving everything to Tana faster than intended. Tana? Why?
Tana is just another note-taking app, but it does it differently. Three note-taking apps existed before Tana:
simple note-taking programs like Apple Notes and Google Keep.
Roam Research and Obsidian are two graph-style applications that assisted connect your notes.
You can create effective tables and charts with data-focused tools like Notion and Airtable.
Tana is the first great software I've encountered that combines graph and data notes. Google Keep will certainly remain my rapid notes app of preference. This Shu Omi video gives a good overview:
Tana handles everything I did in Obsidian with books, people, and blog entries, plus more. I can find book quotes, log my workouts, and connect my thoughts more easily. It should make writing blog entries notes easier, so we'll see.
Tana is now invite-only, but if you're interested, visit their site and sign up. As Shu noted in the video above, the product hasn't been published yet but seems quite polished.
Whether I stay with Tana or not, I'm excited to see where these apps are going and how they can benefit us all.

Aldric Chen
3 years ago
Jack Dorsey's Meeting Best Practice was something I tried. It Performs Exceptionally Well in Consulting Engagements.

Yes, client meetings are difficult. Especially when I'm alone.
Clients must tell us their problems so we can help.
In-meeting challenges contribute nothing to our work. Consider this:
Clients are unprepared.
Clients are distracted.
Clients are confused.
Introducing Jack Dorsey's Google Doc approach
I endorse his approach to meetings.
Not Google Doc-related. Jack uses it for meetings.
This is what his meetings look like.
Prior to the meeting, the Chair creates the agenda, structure, and information using Google Doc.
Participants in the meeting would have 5-10 minutes to read the Google Doc.
They have 5-10 minutes to type their comments on the document.
In-depth discussion begins
There is elegance in simplicity. Here's how Jack's approach is fantastic.
Unprepared clients are given time to read.
During the meeting, they think and work on it.
They can see real-time remarks from others.
Discussion ensues.
Three months ago, I fell for this strategy. After trying it with a client, I got good results.
I conducted social control experiments in a few client workshops.
Context matters.
I am sure Jack Dorsey’s method works well in meetings. What about client workshops?
So, I tested Enterprise of the Future with a consulting client.
I sent multiple emails to client stakeholders describing the new approach.
No PowerPoints that day. I spent the night setting up the Google Doc with conversation topics, critical thinking questions, and a Before and After section.
The client was shocked. First, a Google Doc was projected. Second surprise was a verbal feedback.
“No pre-meeting materials?”
“Don’t worry. I know you are not reading it before our meeting, anyway.”
We laughed. The experiment started.
Observations throughout a 90-minute engagement workshop from beginning to end
For 10 minutes, the workshop was silent.
People read the Google Doc. For some, the silence was unnerving.
“Are you not going to present anything to us?”
I said everything's in Google Doc. I asked them to read, remark, and add relevant paragraphs.
As they unlocked their laptops, they were annoyed.
Ten client stakeholders are typing on the Google Doc. My laptop displays comment bubbles, red lines, new paragraphs, and strikethroughs.
The first 10 minutes were productive. Everyone has seen and contributed to the document.
I was silent.
The move to a classical workshop was smooth. I didn't stimulate dialogue. They did.
Stephanie asked Joe why a blended workforce hinders company productivity. She questioned his comments and additional paragraphs.
That is when a light bulb hit my head. Yes, you want to speak to the right person to resolve issues!
Not only that was discussed. Others discussed their remark bubbles with neighbors. Debate circles sprung up one after the other.
The best part? I asked everyone to add their post-discussion thoughts on a Google Doc.
After the workshop, I have:
An agreement-based working document
A post-discussion minutes that are prepared for publication
A record of the discussion points that were brought up, argued, and evaluated critically
It showed me how stakeholders viewed their Enterprise of the Future. It allowed me to align with them.
Finale Keynotes
Client meetings are a hit-or-miss. I know that.
Jack Dorsey's meeting strategy works for consulting. It promotes session alignment.
It relieves clients of preparation.
I get the necessary information to advance this consulting engagement.
It is brilliant.

Ellane W
3 years ago
The Last To-Do List Template I'll Ever Need, Years in the Making
The holy grail of plain text task management is finally within reach

Plain text task management? Are you serious?? Dedicated task managers exist for a reason, you know. Sheesh.
—Oh, I know. Believe me, I know! But hear me out.
I've managed projects and tasks in plain text for more than four years. Since reorganizing my to-do list, plain text task management is within reach.
Data completely yours? One billion percent. Beef it up with coding? Be my guest.
Enter: The List
The answer? A list. That’s it!
Write down tasks. Obsidian, Notenik, Drafts, or iA Writer are good plain text note-taking apps.
List too long? Of course, it is! A large list tells you what to do. Feel the itch and friction. Then fix it.
But I want to be able to distinguish between work and personal life! List two things.
However, I need to know what should be completed first. Put those items at the top.
However, some things keep coming up, and I need to be reminded of them! Put those in your calendar and make an alarm for them.
But since individual X hasn't completed task Y, I can't proceed with this. Create a Waiting section on your list by dividing it.
But I must know what I'm supposed to be doing right now! Read your list(s). Check your calendar. Think critically.
Before I begin a new one, I remind myself that "Listory Never Repeats."
There’s no such thing as too many lists if all are needed. There is such a thing as too many lists if you make them before they’re needed. Before they complain that their previous room was small or too crowded or needed a new light.
A list that feels too long has a voice; it’s telling you what to do next.
I use one Master List. It's a control panel that tells me what to focus on short-term. If something doesn't need semi-immediate attention, it goes on my Backlog list.
Todd Lewandowski's DWTS (Done, Waiting, Top 3, Soon) performance deserves praise. His DWTS to-do list structure has transformed my plain-text task management. I didn't realize it was upside down.
This is my take on it:
D = Done
Move finished items here. If they pile up, clear them out every week or month. I have a Done Archive folder.
W = Waiting
Things seething in the background, awaiting action. Stir them occasionally so they don't burn.
T = Top 3
Three priorities. Personal comes first, then work. There will always be a top 3 (no more than 5) in every category. Projects, not chores, usually.
S = Soon
This part is action-oriented. It's for anything you can accomplish to finish one of the Top 3. This collection includes thoughts and project lists. The sole requirement is that they should be short-term goals.
Some of you have probably concluded this isn't for you. Please read Todd's piece before throwing out the baby. Often. You shouldn't miss a newborn.
As much as Dancing With The Stars helps me recall this method, I may try switching their order. TSWD; Drilling Tunnel Seismic? Serenity After Task?
Master List Showcase
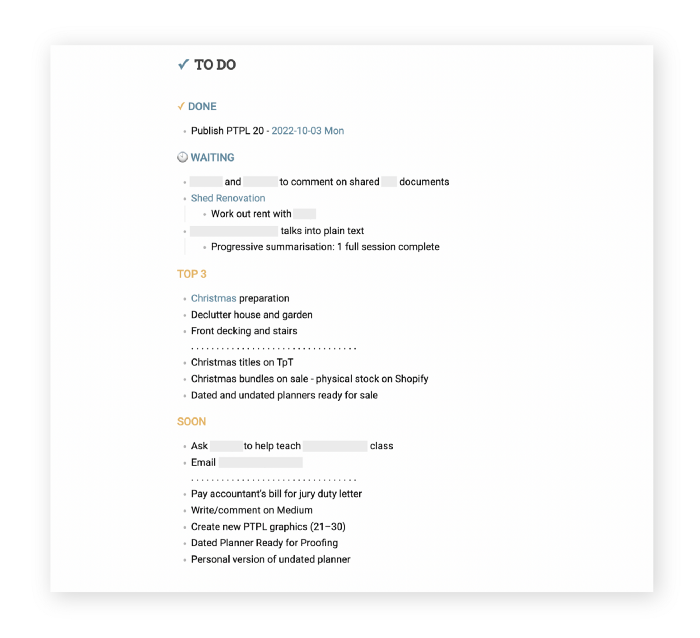
My Master List lives alone in its own file, but sometimes appears in other places. It's included in my Weekly List template. Here's a (soon-to-be-updated) demo vault of my Obsidian planning setup to download for free.
Here's the code behind my weekly screenshot:
## [[Master List - 2022|✓]] TO DO
![[Master List - 2022]]FYI, I use the Minimal Theme in Obsidian, with a few tweaks.
You may note I'm utilizing a checkmark as a link. For me, that's easier than locating the proper spot to click on the embed.
Blue headings for Done and Waiting are links. Done links to the Done Archive page and Waiting to a general waiting page.
Read my full article here.
You might also like

OnChain Wizard
3 years ago
How to make a >800 million dollars in crypto attacking the once 3rd largest stablecoin, Soros style
Everyone is talking about the $UST attack right now, including Janet Yellen. But no one is talking about how much money the attacker made (or how brilliant it was). Lets dig in.
Our story starts in late March, when the Luna Foundation Guard (or LFG) starts buying BTC to help back $UST. LFG started accumulating BTC on 3/22, and by March 26th had a $1bn+ BTC position. This is leg #1 that made this trade (or attack) brilliant.
The second leg comes in the form of the 4pool Frax announcement for $UST on April 1st. This added the second leg needed to help execute the strategy in a capital efficient way (liquidity will be lower and then the attack is on).
We don't know when the attacker borrowed 100k BTC to start the position, other than that it was sold into Kwon's buying (still speculation). LFG bought 15k BTC between March 27th and April 11th, so lets just take the average price between these dates ($42k).
So you have a ~$4.2bn short position built. Over the same time, the attacker builds a $1bn OTC position in $UST. The stage is now set to create a run on the bank and get paid on your BTC short. In anticipation of the 4pool, LFG initially removes $150mm from 3pool liquidity.
The liquidity was pulled on 5/8 and then the attacker uses $350mm of UST to drain curve liquidity (and LFG pulls another $100mm of liquidity).
But this only starts the de-pegging (down to 0.972 at the lows). LFG begins selling $BTC to defend the peg, causing downward pressure on BTC while the run on $UST was just getting started.
With the Curve liquidity drained, the attacker used the remainder of their $1b OTC $UST position ($650mm or so) to start offloading on Binance. As withdrawals from Anchor turned from concern into panic, this caused a real de-peg as people fled for the exits
So LFG is selling $BTC to restore the peg while the attacker is selling $UST on Binance. Eventually the chain gets congested and the CEXs suspend withdrawals of $UST, fueling the bank run panic. $UST de-pegs to 60c at the bottom, while $BTC bleeds out.
The crypto community panics as they wonder how much $BTC will be sold to keep the peg. There are liquidations across the board and LUNA pukes because of its redemption mechanism (the attacker very well could have shorted LUNA as well). BTC fell 25% from $42k on 4/11 to $31.3k
So how much did our attacker make? There aren't details on where they covered obviously, but if they are able to cover (or buy back) the entire position at ~$32k, that means they made $952mm on the short.
On the $350mm of $UST curve dumps I don't think they took much of a loss, lets assume 3% or just $11m. And lets assume that all the Binance dumps were done at 80c, thats another $125mm cost of doing business. For a grand total profit of $815mm (bf borrow cost).
BTC was the perfect playground for the trade, as the liquidity was there to pull it off. While having LFG involved in BTC, and foreseeing they would sell to keep the peg (and prevent LUNA from dying) was the kicker.
Lastly, the liquidity being low on 3pool in advance of 4pool allowed the attacker to drain it with only $350mm, causing the broader panic in both BTC and $UST. Any shorts on LUNA would've added a lot of P&L here as well, with it falling -65% since 5/7.
And for the reply guys, yes I know a lot of this involves some speculation & assumptions. But a lot of money was made here either way, and I thought it would be cool to dive into how they did it.

Nitin Sharma
3 years ago
Web3 Terminology You Should Know
The easiest online explanation.

Web3 is growing. Crypto companies are growing.
Instagram, Adidas, and Stripe adopted cryptocurrency.

Bitcoin and other cryptocurrencies made web3 famous.
Most don't know where to start. Cryptocurrency, DeFi, etc. are investments.
Since we don't understand web3, I'll help you today.
Let’s go.
1. Web3
It is the third generation of the web, and it is built on the decentralization idea which means no one can control it.
There are static webpages that we can only read on the first generation of the web (i.e. Web 1.0).
Web 2.0 websites are interactive. Twitter, Medium, and YouTube.
Each generation controlled the website owner. Simply put, the owner can block us. However, data breaches and selling user data to other companies are issues.
They can influence the audience's mind since they have control.
Assume Twitter's CEO endorses Donald Trump. Result? Twitter would have promoted Donald Trump with tweets and graphics, enhancing his chances of winning.
We need a decentralized, uncontrollable system.
And then there’s Web3.0 to consider. As Bitcoin and Ethereum values climb, so has its popularity. Web3.0 is uncontrolled web evolution. It's good and bad.
Dapps, DeFi, and DAOs are here. It'll all be explained afterwards.
2. Cryptocurrencies:
No need to elaborate.
Bitcoin, Ethereum, Cardano, and Dogecoin are cryptocurrencies. It's digital money used for payments and other uses.
Programs must interact with cryptocurrencies.
3. Blockchain:
Blockchain facilitates bitcoin transactions, investments, and earnings.
This technology governs Web3. It underpins the web3 environment.
Let us delve much deeper.
Blockchain is simple. However, the name expresses the meaning.
Blockchain is a chain of blocks.
Let's use an image if you don't understand.
The graphic above explains blockchain. Think Blockchain. The block stores related data.
Here's more.
4. Smart contracts
Programmers and developers must write programs. Smart contracts are these blockchain apps.
That’s reasonable.
Decentralized web3.0 requires immutable smart contracts or programs.
5. NFTs
Blockchain art is NFT. Non-Fungible Tokens.
Explaining Non-Fungible Token may help.
Two sorts of tokens:
These tokens are fungible, meaning they can be changed. Think of Bitcoin or cash. The token won't change if you sell one Bitcoin and acquire another.
Non-Fungible Token: Since these tokens cannot be exchanged, they are exclusive. For instance, music, painting, and so forth.
Right now, Companies and even individuals are currently developing worthless NFTs.
The concept of NFTs is much improved when properly handled.
6. Dapp
Decentralized apps are Dapps. Instagram, Twitter, and Medium apps in the same way that there is a lot of decentralized blockchain app.
Curve, Yearn Finance, OpenSea, Axie Infinity, etc. are dapps.
7. DAOs
DAOs are member-owned and governed.
Consider it a company with a core group of contributors.
8. DeFi
We all utilize centrally regulated financial services. We fund these banks.
If you have $10,000 in your bank account, the bank can invest it and retain the majority of the profits.
We only get a penny back. Some banks offer poor returns. To secure a loan, we must trust the bank, divulge our information, and fill out lots of paperwork.
DeFi was built for such issues.
Decentralized banks are uncontrolled. Staking, liquidity, yield farming, and more can earn you money.
Web3 beginners should start with these resources.

Caleb Naysmith
3 years ago Draft
A Myth: Decentralization
It’s simply not conceivable, or at least not credible.

One of the most touted selling points of Crypto has always been this grandiose idea of decentralization. Bitcoin first arose in 2009 after the housing crisis and subsequent crash that came with it. It aimed to solve this supposed issue of centralization. Nobody “owns” Bitcoin in theory, so the idea then goes that it won’t be subject to the same downfalls that led to the 2008 crash or similarly speculative events that led to the 2008 disaster. The issue is the banks, not the human nature associated with the greedy individuals running them.
Subsequent blockchains have attempted to fix many of the issues of Bitcoin by increasing capacity, decreasing the costs and processing times associated with Bitcoin, and expanding what can be done with their blockchains. Since nobody owns Bitcoin, it hasn’t really been able to be expanded on. You have people like Vitalk Buterin, however, that actively work on Ethereum though.
The leap from Bitcoin to Ethereum was a massive leap toward centralization, and the trend has only gotten worse. In fact, crypto has since become almost exclusively centralized in recent years.
Decentralization is only good in theory
It’s a good idea. In fact, it’s a wonderful idea. However, like other utopian societies, individuals misjudge human nature and greed. In a perfect world, decentralization would certainly be a wonderful idea because sure, people may function as their own banks, move payments immediately, remain anonymous, and so on. However, underneath this are a couple issues:
You can already send money instantaneously today.
They are not decentralized.
Decentralization is a bad idea.
Being your own bank is a stupid move.
Let’s break these down. Some are quite simple, but lets have a look.
Sending money right away
One thing with crypto is the idea that you can send payments instantly. This has pretty much been entirely solved in current times. You can transmit significant sums of money instantly for a nominal cost and it’s instantaneously cleared. Venmo was launched in 2009 and has since increased to prominence, and currently is on most people's phones. I can directly send ANY amount of money quickly from my bank to another person's Venmo account.
Comparing that with ETH and Bitcoin, Venmo wins all around. I can send money to someone for free instantly in dollars and the only fee paid is optional depending on when you want it.
Both Bitcoin and Ethereum are subject to demand. If the blockchains have a lot of people trying to process transactions fee’s go up, and the time that it takes to receive your crypto takes longer. When Ethereum gets bad, people have reported spending several thousand of dollars on just 1 transaction.
These transactions take place via “miners” bundling and confirming transactions, then recording them on the blockchain to confirm that the transaction did indeed happen. They charge fees to do this and are also paid in Bitcoin/ETH. When a transaction is confirmed, it's then sent to the other users wallet. This within itself is subject to lots of controversy because each transaction needs to be confirmed 6 times, this takes massive amounts of power, and most of the power is wasted because this is an adversarial system in which the person that mines the transaction gets paid, and everyone else is out of luck. Also, these could theoretically be subject to a “51% attack” in which anyone with over 51% of the mining hash rate could effectively control all of the transactions, and reverse transactions while keeping the BTC resulting in “double spending”.
There are tons of other issues with this, but essentially it means: They rely on these third parties to confirm the transactions. Without people confirming these transactions, Bitcoin stalls completely, and if anyone becomes too dominant they can effectively control bitcoin.
Not to mention, these transactions are in Bitcoin and ETH, not dollars. So, you need to convert them to dollars still, and that's several more transactions, and likely to take several days anyway as the centralized exchange needs to send you the money by traditional methods.
They are not distributed
That takes me to the following point. This isn’t decentralized, at all. Bitcoin is the closest it gets because Satoshi basically closed it to new upgrades, although its still subject to:
Whales
Miners
It’s vital to realize that these are often the same folks. While whales aren’t centralized entities typically, they can considerably effect the price and outcome of Bitcoin. If the largest wallets holding as much as 1 million BTC were to sell, it’d effectively collapse the price perhaps beyond repair. However, Bitcoin can and is pretty much controlled by the miners. Further, Bitcoin is more like an oligarchy than decentralized. It’s been effectively used to make the rich richer, and both the mining and price is impacted by the rich. The overwhelming minority of those actually using it are retail investors. The retail investors are basically never the ones generating money from it either.
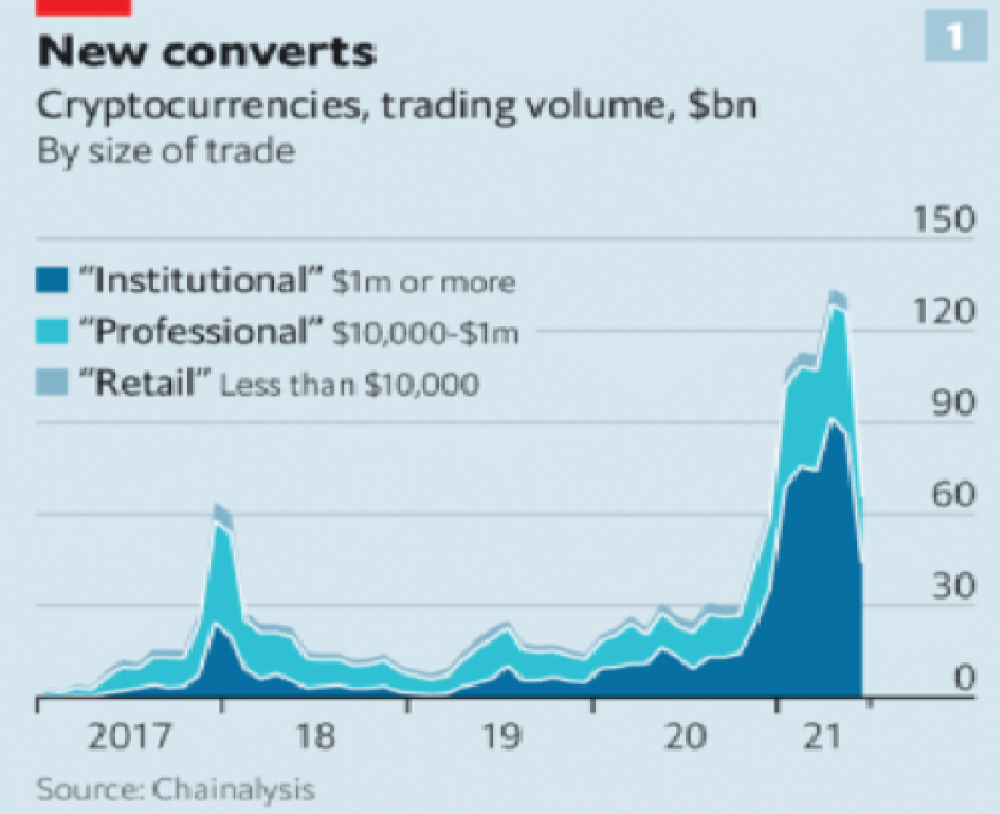
As far as ETH and other cryptos go, there is realistically 0 case for them being decentralized. Vitalik could not only kill it but even walking away from it would likely lead to a significant decline. It has tons of issues right now that Vitalik has promised to fix with the eventual Ethereum 2.0., and stepping away from it wouldn’t help.
Most tokens as well are generally tied to some promise of future developments and creators. The same is true for most NFT projects. The reason 99% of crypto and NFT projects fail is because they failed to deliver on various promises or bad dev teams, or poor innovation, or the founders just straight up stole from everyone. I could go more in-depth than this but go find any project and if there is a dev team, company, or person tied to it then it's likely, not decentralized. The success of that project is directly tied to the dev team, and if they wanted to, most hold large wallets and could sell it all off effectively killing the project. Not to mention, any crypto project that doesn’t have a locked contract can 100% be completely rugged and they can run off with all of the money.
Decentralization is undesirable
Even if they were decentralized then it would not be a good thing. The graphic above indicates this is effectively a rich person’s unregulated playground… so it’s exactly like… the very issue it tried to solve?
Not to mention, it’s supposedly meant to prevent things like 2008, but is regularly subjected to 50–90% drawdowns in value? Back when Bitcoin was only known in niche parts of the dark web and illegal markets, it would regularly drop as much as 90% and has a long history of massive drawdowns.
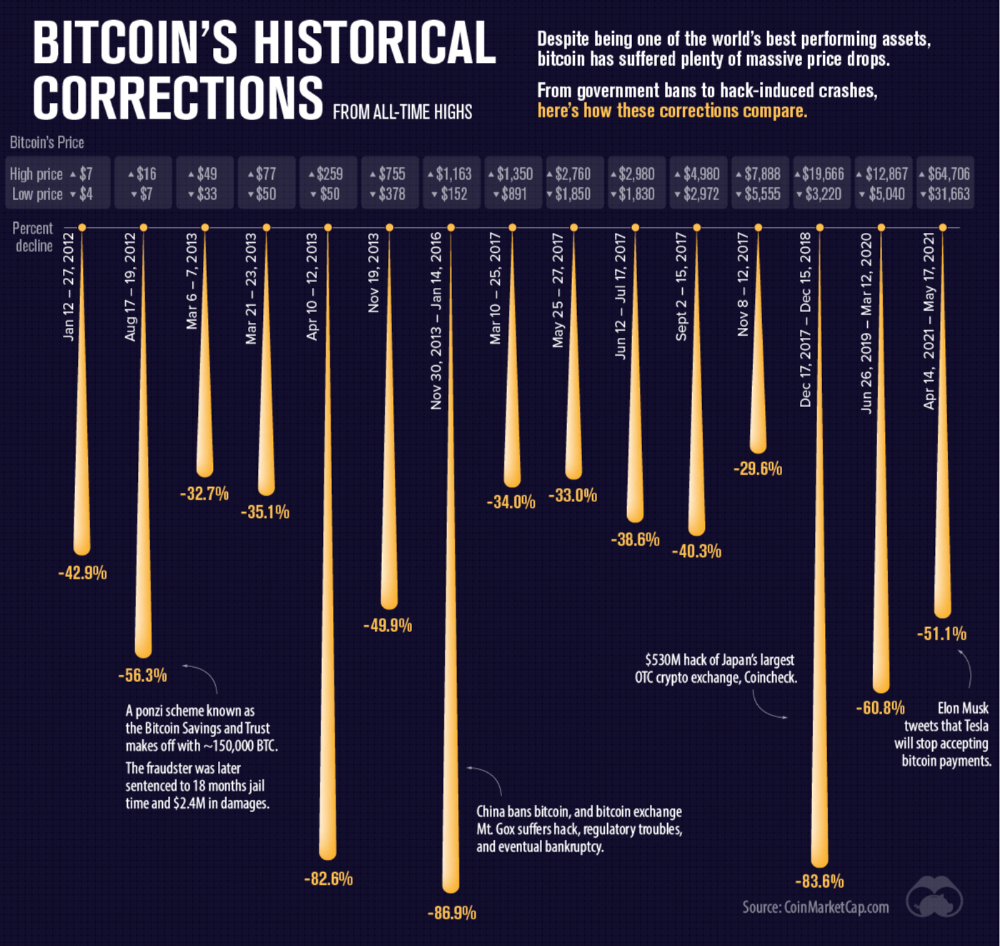
The majority of crypto is blatant scams, and ALL of crypto is a “zero” or “negative” sum game in that it relies on the next person buying for people to make money. This is not a good thing. This has yet to solve any issues around what caused the 2008 crisis. Rather, it seemingly amplified all of the bad parts of it actually. Crypto is the ultimate speculative asset and realistically has no valuation metric. People invest in Apple because it has revenue and cash on hand. People invest in crypto purely for speculation. The lack of regulation or accountability means this is amplified to the most extreme degree where anything goes: Fraud, deception, pump and dumps, scams, etc. This results in a pure speculative madhouse where, unsurprisingly, only the rich win. Not only that but the deck is massively stacked in against the everyday investor because you can’t do a pump and dump without money.
At the heart of all of this is still the same issues: greed and human nature. However, in setting out to solve the issues that allowed 2008 to happen, they made something that literally took all of the bad parts of 2008 and then amplified it. 2008, similarly, was due to greed and human nature but was allowed to happen due to lack of oversite, rich people's excessive leverage over the poor, and excessive speculation. Crypto trades SOLELY on human emotion, has 0 oversite, is pure speculation, and the power dynamic is just as bad or worse.
Why should each individual be their own bank?
This is the last one, and it's short and basic. Why do we want people functioning as their own bank? Everything we do relies on another person. Without the internet, and internet providers there is no crypto. We don’t have people functioning as their own home and car manufacturers or internet service providers. Sure, you might specialize in some of these things, but masquerading as your own bank is a horrible idea.
I am not in the banking industry so I don’t know all the issues with banking. Most people aren’t in banking or crypto, so they don’t know the ENDLESS scams associated with it, and they are bound to lose their money eventually.
If you appreciate this article and want to read more from me and authors like me, without any limits, consider buying me a coffee: buymeacoffee.com/calebnaysmith