




More on Entrepreneurship/Creators

Aure's Notes
3 years ago
I met a man who in just 18 months scaled his startup to $100 million.
A fascinating business conversation.

This week at Web Summit, I had mentor hour.
Mentor hour connects startups with experienced entrepreneurs.
The YC-selected founder who mentored me had grown his company to $100 million in 18 months.
I had 45 minutes to question him.
I've compiled this.
Context
Founder's name is Zack.
After working in private equity, Zack opted to acquire an MBA.
Surrounded by entrepreneurs at a prominent school, he decided to become one himself.
Unsure how to proceed, he bet on two horses.
On one side, he received an offer from folks who needed help running their startup owing to lack of time. On the other hand, he had an idea for a SaaS to start himself.
He just needed to validate it.
Validating
Since Zack's proposal helped companies, he contacted university entrepreneurs for comments.
He contacted university founders.
Once he knew he'd correctly identified the problem and that people were willing to pay to address it, he started developing.
He earned $100k in a university entrepreneurship competition.
His plan was evident by then.
The other startup's founders saw his potential and granted him $400k to launch his own SaaS.
Hiring
He started looking for a tech co-founder because he lacked IT skills.
He interviewed dozens and picked the finest.
As he didn't want to wait for his program to be ready, he contacted hundreds of potential clients and got 15 letters of intent promising they'd join up when it was available.
YC accepted him by then.
He had enough positive signals to raise.
Raising
He didn't say how many VCs he called, but he indicated 50 were interested.
He jammed meetings into two weeks to generate pressure and encourage them to invest.
Seed raise: $11 million.
Selling
His objective was to contact as many entrepreneurs as possible to promote his product.
He first contacted startups by scraping CrunchBase data.
Once he had more money, he started targeting companies with ZoomInfo.
His VC urged him not to hire salespeople until he closed 50 clients himself.
He closed 100 and hired a CRO through a headhunter.
Scaling
Three persons started the business.
He primarily works in sales.
Coding the product was done by his co-founder.
Another person performing operational duties.
He regretted recruiting the third co-founder, who was ineffective (could have hired an employee instead).
He wanted his company to be big, so he hired two young marketing people from a competing company.
After validating several marketing channels, he chose PR.
$100 Million and under
He developed a sales team and now employs 30 individuals.
He raised a $100 million Series A.
Additionally, he stated
He’s been rejected a lot. Like, a lot.
Two great books to read: Steve Jobs by Isaacson, and Why Startups Fail by Tom Eisenmann.
The best skill to learn for non-tech founders is “telling stories”, which means sales. A founder’s main job is to convince: co-founders, employees, investors, and customers. Learn code, or learn sales.
Conclusion
I often read about these stories but hardly take them seriously.
Zack was amazing.
Three things about him stand out:
His vision. He possessed a certain amount of fire.
His vitality. The man had a lot of enthusiasm and spoke quickly and decisively. He takes no chances and pushes the envelope in all he does.
His Rolex.
He didn't do all this in 18 months.
Not really.
He couldn't launch his company without private equity experience.
These accounts disregard entrepreneurs' original knowledge.
Hormozi will tell you how he founded Gym Launch, but he won't tell you how he had a gym first, how he worked at uni to pay for his gym, or how he went to the gym and learnt about fitness, which gave him the idea to open his own.
Nobody knows nothing. If you scale quickly, it's probable because you gained information early.
Lincoln said, "Give me six hours to chop down a tree, and I'll spend four sharpening the axe."
Sharper axes cut trees faster.

Esteban
3 years ago
The Berkus Startup Valuation Method: What Is It?
What Is That?
Berkus is a pre-revenue valuation method based exclusively on qualitative criteria, like Scorecard.
Few firms match their financial estimates, especially in the early stages, so valuation methodologies like the Berkus method are a good way to establish a valuation when the economic measures are not reliable.
How does it work?
This technique evaluates five key success factors.
Fundamental principle
Technology
Execution
Strategic alliances in its primary market
Production, followed by sales
The Berkus technique values the business idea and four success factors. As seen in the matrix below, each of these dimensions poses a danger to the startup's success.
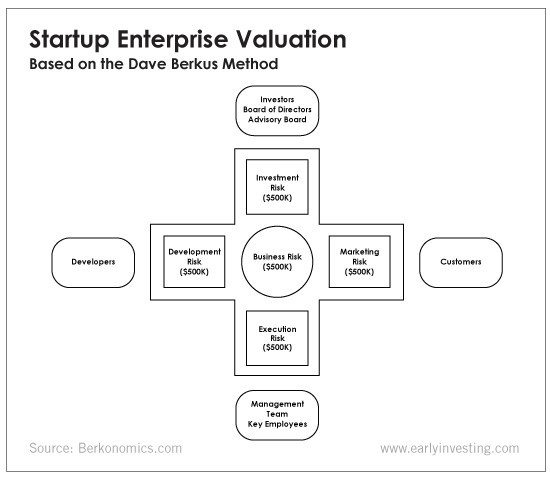
It assigns $0-$500,000 to each of these beginning regions. This approach enables a maximum $2.5M pre-money valuation.
This approach relies significantly on geography and uses the US as a baseline, as it differs in every country in Europe.
A set of standards for analyzing each dimension individually
Fundamental principle (or strength of the idea)
Ideas are worthless; execution matters. Most of us can relate to seeing a new business open in our area or a startup get funded and thinking, "I had this concept years ago!" Someone did it.
The concept remains. To assess the idea's viability, we must consider several criteria.
The concept's exclusivity It is necessary to protect a product or service's concept using patents and copyrights. Additionally, it must be capable of generating large profits.
Planned growth and growth that goes in a specific direction have a lot of potential, therefore incorporating them into a business is really advantageous.
The ability of a concept to grow A venture's ability to generate scalable revenue is a key factor in its emergence and continuation. A startup needs a scalable idea in order to compete successfully in the market.
The attraction of a business idea to a broad spectrum of people is significantly influenced by the current socio-political climate. Thus, the requirement for the assumption of conformity.
Concept Validation Ideas must go through rigorous testing with a variety of audiences in order to lower risk during the implementation phase.
Technology (Prototype)
This aspect reduces startup's technological risk. How good is the startup prototype when facing cyber threats, GDPR compliance (in Europe), tech stack replication difficulty, etc.?
Execution
Check the management team's efficacy. A potential angel investor must verify the founders' experience and track record with previous ventures. Good leadership is needed to chart a ship's course.
Strategic alliances in its primary market
Existing and new relationships will play a vital role in the development of both B2B and B2C startups. What are the startup's synergies? potential ones?
Production, followed by sales (product rollout)
Startup success depends on its manufacturing and product rollout. It depends on the overall addressable market, the startup's ability to market and sell their product, and their capacity to provide consistent, high-quality support.
Example
We're now founders of EyeCaramba, a machine vision-assisted streaming platform. My imagination always goes to poor puns when naming a startup.
Since we're first-time founders and the Berkus technique depends exclusively on qualitative methods and the evaluator's skill, we ask our angel-investor acquaintance for a pre-money appraisal of EyeCaramba.
Our friend offers us the following table:
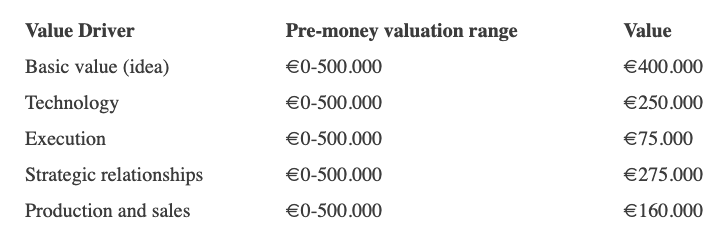
Because we're first-time founders, our pal lowered our Execution score. He knows the idea's value and that the gaming industry is red-hot, with worse startup ideas getting funded, therefore he gave the Basic value the highest value (idea).
EyeCaramba's pre-money valuation is $400,000 + $250,000 + $75,000 + $275,000 + $164,000 (1.16M). Good.
References
https://medium.com/humble-ventures/how-angel-investors-value-pre-revenue-startups-part-iii-8271405f0774#:~:text=pre%2Drevenue%20startups.-,Berkus%20Method,potential%20of%20the%20idea%20itself.%E2%80%9D
https://eqvista.com/berkus-valuation-method-for-startups/
https://www.venionaire.com/early-stage-startup-valuation-part-2-the-berkus-method/

Sanjay Priyadarshi
3 years ago
Using Ruby code, a programmer created a $48,000,000,000 product that Elon Musk admired.
Unexpected Success

Shopify CEO and co-founder Tobias Lutke. Shopify is worth $48 billion.
World-renowned entrepreneur Tobi
Tobi never expected his first online snowboard business to become a multimillion-dollar software corporation.
Tobi founded Shopify to establish a 20-person company.
The publicly traded corporation employs over 10,000 people.
Here's Tobi Lutke's incredible story.
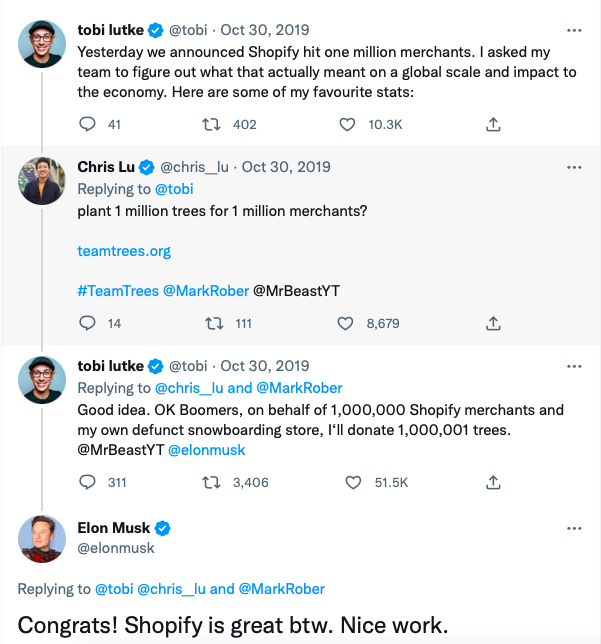
Elon Musk tweeted his admiration for the Shopify creator.
30-October-2019.
Musk praised Shopify founder Tobi Lutke on Twitter.
Happened:
Explore this programmer's journey.
What difficulties did Tobi experience as a young child?
Germany raised Tobi.
Tobi's parents realized he was smart but had trouble learning as a toddler.
Tobi was learning disabled.
Tobi struggled with school tests.
Tobi's learning impairments were undiagnosed.
Tobi struggled to read as a dyslexic.
Tobi also found school boring.
Germany's curriculum didn't inspire Tobi's curiosity.
“The curriculum in Germany was taught like here are all the solutions you might find useful later in life, spending very little time talking about the problem…If I don’t understand the problem I’m trying to solve, it’s very hard for me to learn about a solution to a problem.”
Studying computer programming
After tenth grade, Tobi decided school wasn't for him and joined a German apprenticeship program.
This curriculum taught Tobi software engineering.
He was an apprentice in a small Siemens subsidiary team.
Tobi worked with rebellious Siemens employees.
Team members impressed Tobi.
Tobi joined the team for this reason.
Tobi was pleased to get paid to write programming all day.
His life could not have been better.
Devoted to snowboarding
Tobi loved snowboarding.
He drove 5 hours to ski at his folks' house.
His friends traveled to the US to snowboard when he was older.
However, the cheap dollar conversion rate led them to Canada.
2000.
Tobi originally decided to snowboard instead than ski.
Snowboarding captivated him in Canada.
On the trip to Canada, Tobi encounters his wife.
Tobi meets his wife Fiona McKean on his first Canadian ski trip.
They maintained in touch after the trip.
Fiona moved to Germany after graduating.
Tobi was a startup coder.
Fiona found work in Germany.
Her work included editing, writing, and academics.
“We lived together for 10 months and then she told me that she need to go back for the master's program.”
With Fiona, Tobi immigrated to Canada.
Fiona invites Tobi.
Tobi agreed to move to Canada.
Programming helped Tobi move in with his girlfriend.
Tobi was an excellent programmer, therefore what he did in Germany could be done anywhere.
He worked remotely for his German employer in Canada.
Tobi struggled with remote work.
Due to poor communication.
No slack, so he used email.
Programmers had trouble emailing.
Tobi's startup was developing a browser.
After the dot-com crash, individuals left that startup.
It ended.
Tobi didn't intend to work for any major corporations.
Tobi left his startup.
He believed he had important skills for any huge corporation.
He refused to join a huge corporation.
Because of Siemens.
Tobi learned to write professional code and about himself while working at Siemens in Germany.
Siemens culture was odd.
Employees were distrustful.
Siemens' rigorous dress code implies that the corporation doesn't trust employees' attire.
It wasn't Tobi's place.
“There was so much bad with it that it just felt wrong…20-year-old Tobi would not have a career there.”
Focused only on snowboarding
Tobi lived in Ottawa with his girlfriend.
Canada is frigid in winter.
Ottawa's winters last.
Almost half a year.
Tobi wanted to do something worthwhile now.
So he snowboarded.
Tobi began snowboarding seriously.
He sought every snowboarding knowledge.
He researched the greatest snowboarding gear first.
He created big spreadsheets for snowboard-making technologies.
Tobi grew interested in selling snowboards while researching.
He intended to sell snowboards online.
He had no choice but to start his own company.
A small local company offered Tobi a job.
Interested.
He must sign papers to join the local company.
He needed a work permit when he signed the documents.
Tobi had no work permit.
He was allowed to stay in Canada while applying for permanent residency.
“I wasn’t illegal in the country, but my state didn’t give me a work permit. I talked to a lawyer and he told me it’s going to take a while until I get a permanent residency.”
Tobi's lawyer told him he cannot get a work visa without permanent residence.
His lawyer said something else intriguing.
Tobis lawyer advised him to start a business.
Tobi declined this local company's job offer because of this.
Tobi considered opening an internet store with his technical skills.
He sold snowboards online.
“I was thinking of setting up an online store software because I figured that would exist and use it as a way to sell snowboards…make money while snowboarding and hopefully have a good life.”
What brought Tobi and his co-founder together, and how did he support Tobi?
Tobi lived with his girlfriend's parents.
In Ottawa, Tobi encounters Scott Lake.
Scott was Tobis girlfriend's family friend and worked for Tobi's future employer.
Scott and Tobi snowboarded.
Tobi pitched Scott his snowboard sales software idea.
Scott liked the idea.
They planned a business together.
“I was looking after the technology and Scott was dealing with the business side…It was Scott who ended up developing relationships with vendors and doing all the business set-up.”
Issues they ran into when attempting to launch their business online
Neither could afford a long-term lease.
That prompted their online business idea.
They would open a store.
Tobi anticipated opening an internet store in a week.
Tobi seeks open-source software.
Most existing software was pricey.
Tobi and Scott couldn't afford pricey software.
“In 2004, I was sitting in front of my computer absolutely stunned realising that we hadn’t figured out how to create software for online stores.”
They required software to:
to upload snowboard images to the website.
people to look up the types of snowboards that were offered on the website. There must be a search feature in the software.
Online users transmit payments, and the merchant must receive them.
notifying vendors of the recently received order.
No online selling software existed at the time.
Online credit card payments were difficult.
How did they advance the software while keeping expenses down?
Tobi and Scott needed money to start selling snowboards.
Tobi and Scott funded their firm with savings.
“We both put money into the company…I think the capital we had was around CAD 20,000(Canadian Dollars).”
Despite investing their savings.
They minimized costs.
They tried to conserve.
No office rental.
They worked in several coffee shops.
Tobi lived rent-free at his girlfriend's parents.
He installed software in coffee cafes.
How were the software issues handled?
Tobi found no online snowboard sales software.
Two choices remained:
Change your mind and try something else.
Use his programming expertise to produce something that will aid in the expansion of this company.
Tobi knew he was the sole programmer working on such a project from the start.
“I had this realisation that I’m going to be the only programmer who has ever worked on this, so I don’t have to choose something that lots of people know. I can choose just the best tool for the job…There is been this programming language called Ruby which I just absolutely loved ”
Ruby was open-source and only had Japanese documentation.
Latin is the source code.
Tobi used Ruby twice.
He assumed he could pick the tool this time.
Why not build with Ruby?
How did they find their first time operating a business?
Tobi writes applications in Ruby.
He wrote the initial software version in 2.5 months.
Tobi and Scott founded Snowdevil to sell snowboards.
Tobi coded for 16 hours a day.
His lifestyle was unhealthy.
He enjoyed pizza and coke.
“I would never recommend this to anyone, but at the time there was nothing more interesting to me in the world.”
Their initial purchase and encounter with it
Tobi worked in cafes then.
“I was working in a coffee shop at this time and I remember everything about that day…At some time, while I was writing the software, I had to type the email that the software would send to tell me about the order.”
Tobi recalls everything.
He checked the order on his laptop at the coffee shop.
Pennsylvanian ordered snowboard.
Tobi walked home and called Scott. Tobi told Scott their first order.
They loved the order.
How were people made aware about Snowdevil?
2004 was very different.
Tobi and Scott attempted simple website advertising.
Google AdWords was new.
Ad clicks cost 20 cents.
Online snowboard stores were scarce at the time.
Google ads propelled the snowdevil brand.
Snowdevil prospered.
They swiftly recouped their original investment in the snowboard business because to its high profit margin.
Tobi and Scott struggled with inventories.
“Snowboards had really good profit margins…Our biggest problem was keeping inventory and getting it back…We were out of stock all the time.”
Selling snowboards returned their investment and saved them money.
They did not appoint a business manager.
They accomplished everything alone.
Sales dipped in the spring, but something magical happened.
Spring sales plummeted.
They considered stocking different boards.
They naturally wanted to add boards and grow the business.
However, magic occurred.
Tobi coded and improved software while running Snowdevil.
He modified software constantly. He wanted speedier software.
He experimented to make the software more resilient.
Tobi received emails requesting the Snowdevil license.
They intended to create something similar.
“I didn’t stop programming, I was just like Ok now let me try things, let me make it faster and try different approaches…Increasingly I got people sending me emails and asking me If I would like to licence snowdevil to them. People wanted to start something similar.”
Software or skateboards, your choice
Scott and Tobi had to choose a hobby in 2005.
They might sell alternative boards or use software.
The software was a no-brainer from demand.
Daniel Weinand is invited to join Tobi's business.
Tobis German best friend is Daniel.
Tobi and Scott chose to use the software.
Tobi and Scott kept the software service.
Tobi called Daniel to invite him to Canada to collaborate.
Scott and Tobi had quit snowboarding until then.
How was Shopify launched, and whence did the name come from?
The three chose Shopify.
Named from two words.
First:
Shop
Final part:
Simplify
Shopify
Shopify's crew has always had one goal:
creating software that would make it simple and easy for people to launch online storefronts.
Launched Shopify after raising money for the first time.
Shopify began fundraising in 2005.
First, they borrowed from family and friends.
They needed roughly $200k to run the company efficiently.
$200k was a lot then.
When questioned why they require so much money. Tobi told them to trust him with their goals. The team raised seed money from family and friends.
Shopify.com has a landing page. A demo of their goal was on the landing page.
In 2006, Shopify had about 4,000 emails.
Shopify rented an Ottawa office.
“We sent a blast of emails…Some people signed up just to try it out, which was exciting.”
How things developed after Scott left the company
Shopify co-founder Scott Lake left in 2008.
Scott was CEO.
“He(Scott) realized at some point that where the software industry was going, most of the people who were the CEOs were actually the highly technical person on the founding team.”
Scott leaving the company worried Tobi.
Tobis worried about finding a new CEO.
To Tobi:
A great VC will have the network to identify the perfect CEO for your firm.
Tobi started visiting Silicon Valley to meet with venture capitalists to recruit a CEO.
Initially visiting Silicon Valley
Tobi came to Silicon Valley to start a 20-person company.
This company creates eCommerce store software.
Tobi never wanted a big corporation. He desired a fulfilling existence.
“I stayed in a hostel in the Bay Area. I had one roommate who was also a computer programmer. I bought a bicycle on Craiglist. I was there for a week, but ended up staying two and a half weeks.”
Tobi arrived unprepared.
When venture capitalists asked him business questions.
He answered few queries.
Tobi didn't comprehend VC meetings' terminology.
He wrote the terms down and looked them up.
Some were fascinated after he couldn't answer all these queries.
“I ended up getting the kind of term sheets people dream about…All the offers were conditional on moving our company to Silicon Valley.”
Canada received Tobi.
He wanted to consult his team before deciding. Shopify had five employees at the time.
2008.
A global recession greeted Tobi in Canada. The recession hurt the market.
His term sheets were useless.
The economic downturn in the world provided Shopify with a fantastic opportunity.
The global recession caused significant job losses.
Fired employees had several ideas.
They wanted online stores.
Entrepreneurship was desired. They wanted to quit work.
People took risks and tried new things during the global slump.
Shopify subscribers skyrocketed during the recession.
“In 2009, the company reached neutral cash flow for the first time…We were in a position to think about long-term investments, such as infrastructure projects.”
Then, Tobi Lutke became CEO.
How did Tobi perform as the company's CEO?
“I wasn’t good. My team was very patient with me, but I had a lot to learn…It’s a very subtle job.”
2009–2010.
Tobi limited the company's potential.
He deliberately restrained company growth.
Tobi had one costly problem:
Whether Shopify is a venture or a lifestyle business.
The company's annual revenue approached $1 million.
Tobi battled with the firm and himself despite good revenue.
His wife was supportive, but the responsibility was crushing him.
“It’s a crushing responsibility…People had families and kids…I just couldn’t believe what was going on…My father-in-law gave me money to cover the payroll and it was his life-saving.”
Throughout this trip, everyone supported Tobi.
They believed it.
$7 million in donations received
Tobi couldn't decide if this was a lifestyle or a business.
Shopify struggled with marketing then.
Later, Tobi tried 5 marketing methods.
He told himself that if any marketing method greatly increased their growth, he would call it a venture, otherwise a lifestyle.
The Shopify crew brainstormed and voted on marketing concepts.
Tested.
“Every single idea worked…We did Adwords, published a book on the concept, sponsored a podcast and all the ones we tracked worked.”
To Silicon Valley once more
Shopify marketing concepts worked once.
Tobi returned to Silicon Valley to pitch investors.
He raised $7 million, valuing Shopify at $25 million.
All investors had board seats.
“I find it very helpful…I always had a fantastic relationship with everyone who’s invested in my company…I told them straight that I am not going to pretend I know things, I want you to help me.”
Tobi developed skills via running Shopify.
Shopify had 20 employees.
Leaving his wife's parents' home
Tobi left his wife's parents in 2014.
Tobi had a child.
Shopify has 80,000 customers and 300 staff in 2013.
Public offering in 2015
Shopify investors went public in 2015.
Shopify powers 4.1 million e-Commerce sites.
Shopify stores are 65% US-based.
It is currently valued at $48 billion.
You might also like
Muhammad Rahmatullah
3 years ago
The Pyramid of Coding Principles
A completely operating application requires many processes and technical challenges. Implementing coding standards can make apps right, work, and faster.
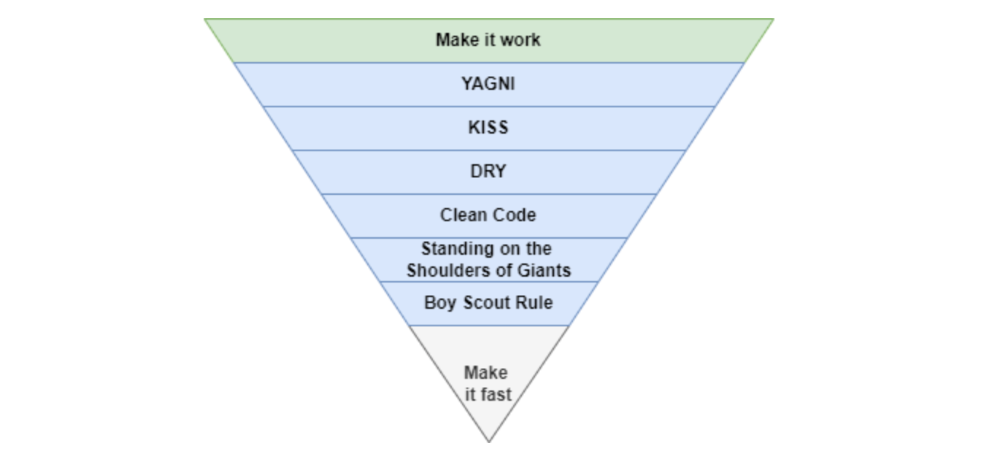
With years of experience working in software houses. Many client apps are scarcely maintained.
Why are these programs "barely maintainable"? If we're used to coding concepts, we can probably tell if an app is awful or good from its codebase.
This is how I coded much of my app.
Make It Work
Before adopting any concept, make sure the apps are completely functional. Why have a fully maintained codebase if the app can't be used?
The user doesn't care if the app is created on a super server or uses the greatest coding practices. The user just cares if the program helps them.
After the application is working, we may implement coding principles.
You Aren’t Gonna Need It
As a junior software engineer, I kept unneeded code, components, comments, etc., thinking I'd need them later.
In reality, I never use that code for weeks or months.
First, we must remove useless code from our primary codebase. If you insist on keeping it because "you'll need it later," employ version control.
If we remove code from our codebase, we can quickly roll back or copy-paste the previous code without preserving it permanently.
The larger the codebase, the more maintenance required.
Keep It Simple Stupid
Indeed. Keep things simple.
Why complicate something if we can make it simpler?
Our code improvements should lessen the server load and be manageable by others.
If our code didn't pass those benchmarks, it's too convoluted and needs restructuring. Using an open-source code critic or code smell library, we can quickly rewrite the code.
Simpler codebases and processes utilize fewer server resources.
Don't Repeat Yourself
Have you ever needed an action or process before every action, such as ensuring the user is logged in before accessing user pages?
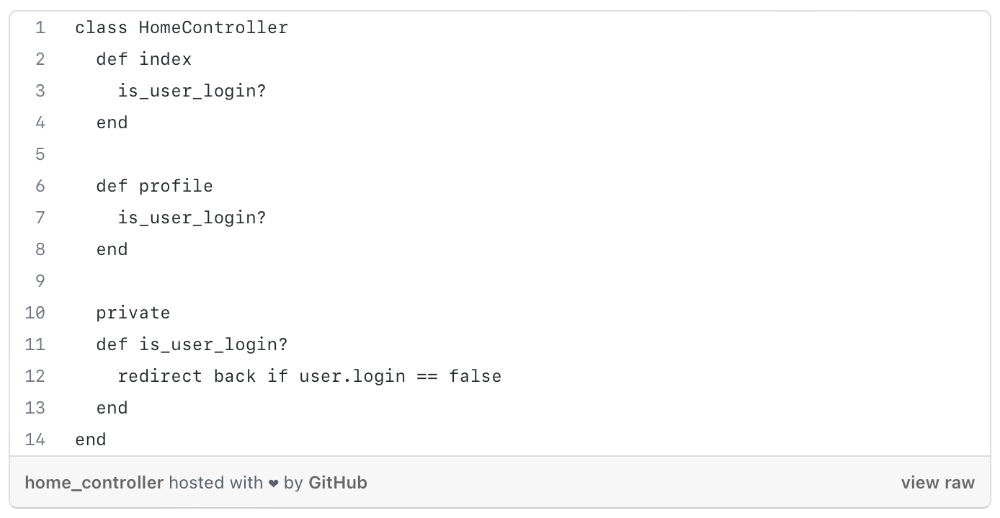
As you can see from the above code, I try to call is user login? in every controller action, and it should be optimized, because if we need to rename the method or change the logic, etc. We can improve this method's efficiency.
We can write a constructor/middleware/before action that calls is_user_login?
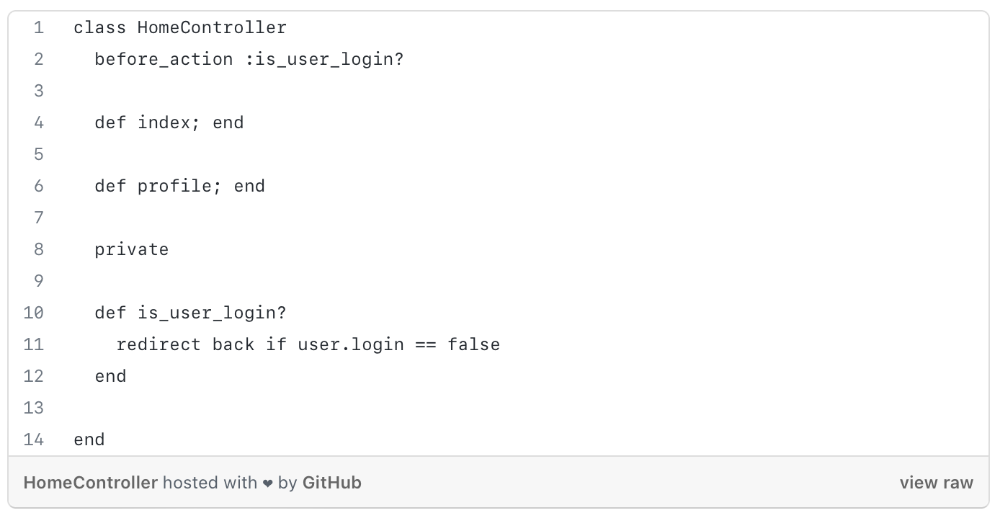
The code is more maintainable and readable after refactoring.
Each programming language or framework handles this issue differently, so be adaptable.
Clean Code
Clean code is a broad notion that you've probably heard of before.
When creating a function, method, module, or variable name, the first rule of clean code is to be precise and simple.
The name should express its value or logic as a whole, and follow code rules because every programming language is distinct.
If you want to learn more about this topic, I recommend reading https://www.amazon.com/Clean-Code-Handbook-Software-Craftsmanship/dp/0132350882.
Standing On The Shoulder of Giants
Use industry standards and mature technologies, not your own(s).
There are several resources that explain how to build boilerplate code with tools, how to code with best practices, etc.
I propose following current conventions, best practices, and standardization since we shouldn't innovate on top of them until it gives us a competitive edge.
Boy Scout Rule
What reduces programmers' productivity?
When we have to maintain or build a project with messy code, our productivity decreases.
Having to cope with sloppy code will slow us down (shame of us).
How to cope? Uncle Bob's book says, "Always leave the campground cleaner than you found it."
When developing new features or maintaining current ones, we must improve our codebase. We can fix minor issues too. Renaming variables, deleting whitespace, standardizing indentation, etc.
Make It Fast
After making our code more maintainable, efficient, and understandable, we can speed up our app.
Whether it's database indexing, architecture, caching, etc.
A smart craftsman understands that refactoring takes time and it's preferable to balance all the principles simultaneously. Don't YAGNI phase 1.
Using these ideas in each iteration/milestone, while giving the bottom items less time/care.
You can check one of my articles for further information. https://medium.com/life-at-mekari/why-does-my-website-run-very-slowly-and-how-do-i-optimize-it-for-free-b21f8a2f0162

CoinTelegraph
4 years ago
2 NFT-based blockchain games that could soar in 2022
NFTs look ready to rule 2022, and the recent pivot toward NFT utility in P2E gaming could make blockchain gaming this year’s sector darling.
After the popularity of decentralized finance (DeFi) came the rise of nonfungible tokens (NFTs), and to the surprise of many, NFTs took the spotlight and now remain front and center with the highest volume in sales occurring at the start of January 2022.
While 2021 became the year of NFTs, GameFi applications did surpass DeFi in terms of user popularity. According to data from DappRadar, Bloomberg gathered:
Nearly 50% of active cryptocurrency wallets connected to decentralized applications in November were for playing games. The percentage of wallets linked to decentralized finance, or DeFi, dapps fell to 45% during the same period, after months of being the leading dapp use case.
Blockchain play-to-earn (P2E) game Axie infinity skyrocketed and kicked off a gaming craze that is expected to continue all throughout 2022. Crypto pundits and gaming advocates have high expectations for P2E blockchain-based games and there’s bound to be a few sleeping giants that will dominate the sector.
Let’s take a look at five blockchain games that could make waves in 2022.
DeFi Kingdoms
The inspiration for DeFi Kingdoms came from simple beginnings — a passion for investing that lured the developers to blockchain technology. DeFi Kingdoms was born as a visualization of liquidity pool investing where in-game ‘gardens’ represent literal and figurative token pairings and liquidity pool mining.
As shown in the game, investors have a portion of their LP share within a plot filled with blooming plants. By attaching the concept of growth to DeFi protocols within a play-and-earn model, DeFi Kingdoms puts a twist on “playing” a game.
Built on the Harmony Network, DeFi Kingdoms became the first project on the network to ever top the DappRadar charts. This could be attributed to an influx of individuals interested in both DeFi and blockchain games or it could be attributed to its recent in-game utility token JEWEL surging.
JEWEL is a utility token that allows users to purchase NFTs in-game buffs to increase a base-level stat. It is also used for liquidity mining to grant users the opportunity to make more JEWEL through staking.
JEWEL is also a governance token that gives holders a vote in the growth and evolution of the project. In the past four months, the token price surged from $1.23 to an all-time high of $22.52. At the time of writing, JEWEL is down by nearly 16%, trading at $19.51.
Surging approximately 1,487% from its humble start of $1.23 four months ago in September, JEWEL token price has increased roughly 165% this last month alone, according to data from CoinGecko.
Guild of Guardians
Guild of Guardians is one of the more anticipated blockchain games in 2022 and it is built on ImmutableX, the first layer-two solution built on Ethereum that focuses on NFTs. Aiming to provide more access, it will operate as a free-to-play mobile role-playing game, modeling the P2E mechanics.
Similar to blockchain games like Axie Infinity, Guild of Guardians in-game assets can be exchanged. The project seems to be of interest to many gamers and investors with its NFT founder sale and token launch generating nearly $10 million in volume.
Launching its in-game token in October of 2021, the Guild of Guardians (GOG) tokens are ERC-20 tokens known as ‘gems’ inside the game. Gems are what power key features in the game such as minting in-game NFTs and interacting with the marketplace, and are available to earn while playing.
For the last month, the Guild of Guardians token has performed rather steadily after spiking to its all-time high of $2.81 after its launch. Despite the token being down over 50% from its all-time high, at the time of writing, some members of the community are looking forward to the possibility of staking and liquidity pools, which are features that tend to help stabilize token prices.

Coinbase
4 years ago
10 Predictions for Web3 and the Cryptoeconomy for 2022
By Surojit Chatterjee, Chief Product Officer
2021 proved to be a breakout year for crypto with BTC price gaining almost 70% yoy, Defi hitting $150B in value locked, and NFTs emerging as a new category. Here’s my view through the crystal ball into 2022 and what it holds for our industry:
1. Eth scalability will improve, but newer L1 chains will see substantial growth — As we welcome the next hundred million users to crypto and Web3, scalability challenges for Eth are likely to grow. I am optimistic about improvements in Eth scalability with the emergence of Eth2 and many L2 rollups. Traction of Solana, Avalanche and other L1 chains shows that we’ll live in a multi-chain world in the future. We’re also going to see newer L1 chains emerge that focus on specific use cases such as gaming or social media.
2. There will be significant usability improvements in L1-L2 bridges — As more L1 networks gain traction and L2s become bigger, our industry will desperately seek improvements in speed and usability of cross-L1 and L1-L2 bridges. We’re likely to see interesting developments in usability of bridges in the coming year.
3. Zero knowledge proof technology will get increased traction — 2021 saw protocols like ZkSync and Starknet beginning to get traction. As L1 chains get clogged with increased usage, ZK-rollup technology will attract both investor and user attention. We’ll see new privacy-centric use cases emerge, including privacy-safe applications, and gaming models that have privacy built into the core. This may also bring in more regulator attention to crypto as KYC/AML could be a real challenge in privacy centric networks.
4. Regulated Defi and emergence of on-chain KYC attestation — Many Defi protocols will embrace regulation and will create separate KYC user pools. Decentralized identity and on-chain KYC attestation services will play key roles in connecting users’ real identity with Defi wallet endpoints. We’ll see more acceptance of ENS type addresses, and new systems from cross chain name resolution will emerge.
5. Institutions will play a much bigger role in Defi participation — Institutions are increasingly interested in participating in Defi. For starters, institutions are attracted to higher than average interest-based returns compared to traditional financial products. Also, cost reduction in providing financial services using Defi opens up interesting opportunities for institutions. However, they are still hesitant to participate in Defi. Institutions want to confirm that they are only transacting with known counterparties that have completed a KYC process. Growth of regulated Defi and on-chain KYC attestation will help institutions gain confidence in Defi.
6. Defi insurance will emerge — As Defi proliferates, it also becomes the target of security hacks. According to London-based firm Elliptic, total value lost by Defi exploits in 2021 totaled over $10B. To protect users from hacks, viable insurance protocols guaranteeing users’ funds against security breaches will emerge in 2022.
7. NFT Based Communities will give material competition to Web 2.0 social networks — NFTs will continue to expand in how they are perceived. We’ll see creator tokens or fan tokens take more of a first class seat. NFTs will become the next evolution of users’ digital identity and passport to the metaverse. Users will come together in small and diverse communities based on types of NFTs they own. User created metaverses will be the future of social networks and will start threatening the advertising driven centralized versions of social networks of today.
8. Brands will start actively participating in the metaverse and NFTs — Many brands are realizing that NFTs are great vehicles for brand marketing and establishing brand loyalty. Coca-Cola, Campbell’s, Dolce & Gabbana and Charmin released NFT collectibles in 2021. Adidas recently launched a new metaverse project with Bored Ape Yacht Club. We’re likely to see more interesting brand marketing initiatives using NFTs. NFTs and the metaverse will become the new Instagram for brands. And just like on Instagram, many brands may start as NFT native. We’ll also see many more celebrities jumping in the bandwagon and using NFTs to enhance their personal brand.
9. Web2 companies will wake up and will try to get into Web3 — We’re already seeing this with Facebook trying to recast itself as a Web3 company. We’re likely to see other big Web2 companies dipping their toes into Web3 and metaverse in 2022. However, many of them are likely to create centralized and closed network versions of the metaverse.
10. Time for DAO 2.0 — We’ll see DAOs become more mature and mainstream. More people will join DAOs, prompting a change in definition of employment — never receiving a formal offer letter, accepting tokens instead of or along with fixed salaries, and working in multiple DAO projects at the same time. DAOs will also confront new challenges in terms of figuring out how to do M&A, run payroll and benefits, and coordinate activities in larger and larger organizations. We’ll see a plethora of tools emerge to help DAOs execute with efficiency. Many DAOs will also figure out how to interact with traditional Web2 companies. We’re likely to see regulators taking more interest in DAOs and make an attempt to educate themselves on how DAOs work.
Thanks to our customers and the ecosystem for an incredible 2021. Looking forward to another year of building the foundations for Web3. Wagmi.