



More on Entrepreneurship/Creators

Jenn Leach
3 years ago
In November, I made an effort to pitch 10 brands per day. Here's what I discovered.

I pitched 10 brands per workday for a total of 200.
How did I do?
It was difficult.
I've never pitched so much.
What did this challenge teach me?
the superiority of quality over quantity
When you need help, outsource
Don't disregard burnout in order to complete a challenge because it exists.
First, pitching brands for brand deals requires quality. Find firms that align with your brand to expose to your audience.
If you associate with any company, you'll lose audience loyalty. I didn't lose sight of that, but I couldn't resist finishing the task.
Outsourcing.
Delegating work to teammates is effective.
I wish I'd done it.
Three people can pitch 200 companies a month significantly faster than one.
One person does research, one to two do outreach, and one to two do follow-up and negotiating.
Simple.
In 2022, I'll outsource everything.
Burnout.
I felt this, so I slowed down at the end of the month.
Thanksgiving week in November was slow.
I was buying and decorating for Christmas. First time putting up outdoor holiday lights was fun.
Much was happening.
I'm not perfect.
I'm being honest.
The Outcomes
Less than 50 brands pitched.
Result: A deal with 3 brands.
I hoped for 4 brands with reaching out to 200 companies, so three with under 50 is wonderful.
That’s a 6% conversion rate!
Whoo-hoo!
I needed 2%.
Here's a screenshot from one of the deals I booked.
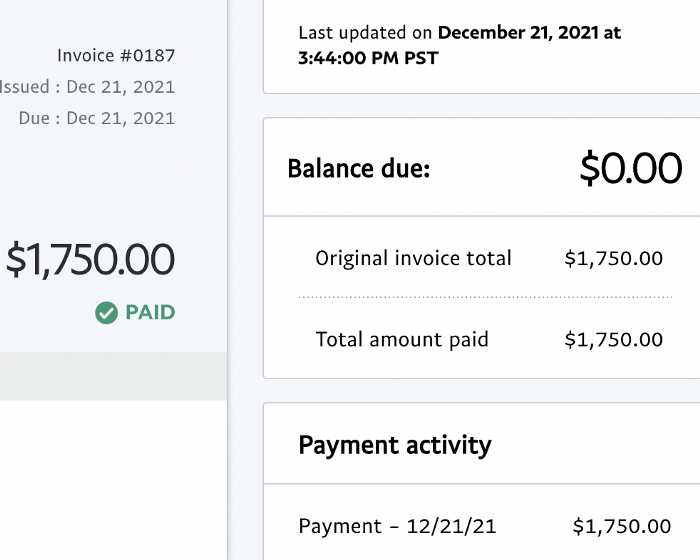
These companies fit my company well. Each campaign is different, but I've booked $2,450 in brand work with a couple of pending transactions for December and January.
$2,450 in brand work booked!
How did I do? You tell me.
Is this something you’d try yourself?

Victoria Kurichenko
3 years ago
Here's what happened after I launched my second product on Gumroad.
One-hour ebook sales, affiliate relationships, and more.

If you follow me, you may know I started a new ebook in August 2022.
Despite publishing on this platform, my website, and Quora, I'm not a writer.
My writing speed is slow, 2,000 words a day, and I struggle to communicate cohesively.
In April 2022, I wrote a successful guide on How to Write Google-Friendly Blog Posts.
I had no email list or social media presence. I've made $1,600+ selling ebooks.
Evidence:
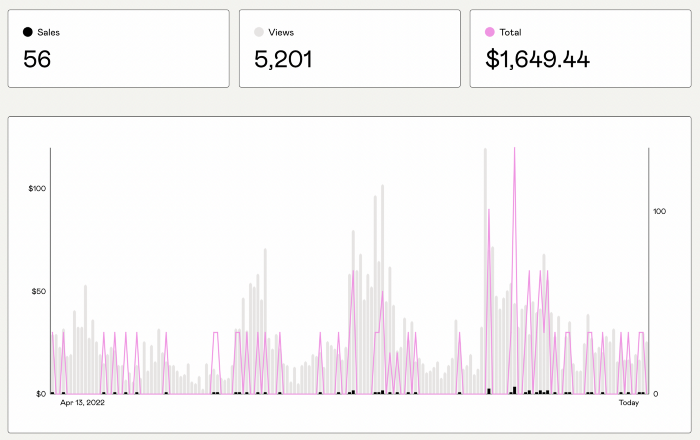
My first digital offering isn't a book.
It's an actionable guide with my tried-and-true process for writing Google-friendly content.
I'm not bragging.
Established authors like Tim Denning make more from my ebook sales with one newsletter.
This experience taught me writing isn't a privilege.
Writing a book and making money online doesn't require expertise.
Many don't consult experts. They want someone approachable.
Two years passed before I realized my own limits.
I have a brain, two hands, and Internet to spread my message.
I wrote and published a second ebook after the first's success.
On Gumroad, I released my second digital product.
Here's my complete Gumroad evaluation.
Gumroad is a marketplace for content providers to develop and sell sales pages.
Gumroad handles payments and client requests. It's helpful when someone sends a bogus payment receipt requesting an ebook (actual story!).
You'll forget administrative concerns after your first ebook sale.
After my first ebook sale, I did this: I made additional cash!
After every sale, I tell myself, "I built a new semi-passive revenue source."
This thinking shift helps me become less busy while increasing my income and quality of life.
Besides helping others, folks sell evergreen digital things to earn passive money.
It's in my second ebook.
I explain how I built and sold 50+ copies of my SEO writing ebook without being an influencer.
I show how anyone can sell ebooks on Gumroad and automate their sales process.
This is my ebook.

After publicizing the ebook release, I sold three copies within an hour.
Wow, or meh?
I don’t know.
The answer is different for everyone.
These three sales came from a small email list of 40 motivated fans waiting for my ebook release.
I had bigger plans.
I'll market my ebook on Medium, my website, Quora, and email.
I'm testing affiliate partnerships this time.
One of my ebook buyers is now promoting it for 40% commission.
Become my affiliate if you think your readers would like my ebook.
My ebook is a few days old, but I'm interested to see where it goes.
My SEO writing book started without an email list, affiliates, or 4,000 website visitors. I've made four figures.
I'm slowly expanding my communication avenues to have more impact.
Even a small project can open doors you never knew existed.
So began my writing career.
In summary
If you dare, every concept can become a profitable trip.
Before, I couldn't conceive of creating an ebook.
How to Sell eBooks on Gumroad is my second digital product.
Marketing and writing taught me that anything can be sold online.

Nick Nolan
3 years ago
How to Make $1,037,100 in 4 Months with This Weird Website
One great idea might make you rich.

Imagine having a million-dollar concept in college that made a million.
2005 precisely.
Alex Tew, 21, from Wiltshire, England, created The Million Dollar Homepage in August 2005. The idea is basic but beyond the ordinary, which is why it worked.
Alex built a 1,000,000-pixel webpage.
Each website pixel would cost $1. Since pixels are hard to discern, he sold 10x10 squares for $100.
He'd make a million if all the spots sold.
He may have thought about NFTs and the Metaverse decades ago.
MillionDollarHomepage.com launched in 2005.
Businesses and individuals could buy a website spot and add their logo, website link, and tagline. You bought an ad, but nobody visited the website.
If a few thousand people visited the website, it could drive traffic to your business's site.
Alex promised buyers the website would be up for 5 years, so it was a safe bet.
Alex's friend with a music website was the first to buy real estate on the site. Within two weeks, 4,700 pixels sold, and a tracker showed how many were sold and available.

Word-of-mouth marketing got the press's attention quickly. Everyone loves reading about new ways to make money, so it was a good news story.
By September, over 250,000 pixels had been sold, according to a BBC press release.
Alex and the website gained more media and public attention, so traffic skyrocketed. Two months after the site launched, 1,400 customers bought more than 500,000 pixels.
Businesses bought online real estate. They heard thousands visited the site, so they could get attention cheaply.
Unless you bought a few squares, I'm not sure how many people would notice your ad or click your link.
A sponge website owner emailed Alex:
“We tried Million Dollar Homepage because we were impressed at the level of ingenuity and the sheer simplicity of it. If we’re honest, we didn’t expect too much from it. Now, as a direct result, we are pitching for £18,000 GBP worth of new clients and have seen our site traffic increase over a hundred-fold. We’re even going to have to upgrade our hosting facility! It’s been exceptional.”
Web.archive.org screenshots show how the website changed.
“The idea is to create something of an internet time capsule: a homepage that is unique and permanent. Everything on the internet keeps changing so fast, it will be nice to have something that stays solid and permanent for many years. You can be a part of that!” Alex Tew, 2005
The last 1,000 pixels were sold on January 1, 2006.
By then, the homepage had hundreds of thousands of monthly visitors. Alex put the last space on eBay due to high demand.
MillionDollarWeightLoss.com won the last pixels for $38,100, bringing revenue to $1,037,100 in 4 months.

Many have tried to replicate this website's success. They've all failed.
This idea only worked because no one had seen this website before.
This winner won't be repeated, but it should inspire you to try something new and creative.
Still popular, you could buy one of the linked domains. You can't buy pixels, but you can buy an expired domain.
One link I clicked costs $59,888.

You'd own a piece of internet history if you spent that much on a domain.
Someone bought stablesgallery.co.uk after the domain expired and restored it.
Many of the linked websites have expired or been redirected, but some still link to the original. I couldn't find sponge's website. Can you?
This is a great example of how a simple creative idea can go viral.
Comment on this amazing success story.
You might also like

Shalitha Suranga
3 years ago
The Top 5 Mathematical Concepts Every Programmer Needs to Know
Using math to write efficient code in any language

Programmers design, build, test, and maintain software. Employ cases and personal preferences determine the programming languages we use throughout development. Mobile app developers use JavaScript or Dart. Some programmers design performance-first software in C/C++.
A generic source code includes language-specific grammar, pre-implemented function calls, mathematical operators, and control statements. Some mathematical principles assist us enhance our programming and problem-solving skills.
We all use basic mathematical concepts like formulas and relational operators (aka comparison operators) in programming in our daily lives. Beyond these mathematical syntaxes, we'll see discrete math topics. This narrative explains key math topics programmers must know. Master these ideas to produce clean and efficient software code.
Expressions in mathematics and built-in mathematical functions
A source code can only contain a mathematical algorithm or prebuilt API functions. We develop source code between these two ends. If you create code to fetch JSON data from a RESTful service, you'll invoke an HTTP client and won't conduct any math. If you write a function to compute the circle's area, you conduct the math there.
When your source code gets more mathematical, you'll need to use mathematical functions. Every programming language has a math module and syntactical operators. Good programmers always consider code readability, so we should learn to write readable mathematical expressions.
Linux utilizes clear math expressions.
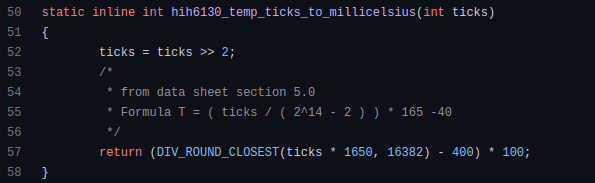
Inbuilt max and min functions can minimize verbose if statements.
How can we compute the number of pages needed to display known data? In such instances, the ceil function is often utilized.
import math as m
results = 102
items_per_page = 10
pages = m.ceil(results / items_per_page)
print(pages)Learn to write clear, concise math expressions.
Combinatorics in Algorithm Design
Combinatorics theory counts, selects, and arranges numbers or objects. First, consider these programming-related questions. Four-digit PIN security? what options exist? What if the PIN has a prefix? How to locate all decimal number pairs?
Combinatorics questions. Software engineering jobs often require counting items. Combinatorics counts elements without counting them one by one or through other verbose approaches, therefore it enables us to offer minimum and efficient solutions to real-world situations. Combinatorics helps us make reliable decision tests without missing edge cases. Write a program to see if three inputs form a triangle. This is a question I commonly ask in software engineering interviews.
Graph theory is a subfield of combinatorics. Graph theory is used in computerized road maps and social media apps.
Logarithms and Geometry Understanding
Geometry studies shapes, angles, and sizes. Cartesian geometry involves representing geometric objects in multidimensional planes. Geometry is useful for programming. Cartesian geometry is useful for vector graphics, game development, and low-level computer graphics. We can simply work with 2D and 3D arrays as plane axes.
GetWindowRect is a Windows GUI SDK geometric object.
High-level GUI SDKs and libraries use geometric notions like coordinates, dimensions, and forms, therefore knowing geometry speeds up work with computer graphics APIs.
How does exponentiation's inverse function work? Logarithm is exponentiation's inverse function. Logarithm helps programmers find efficient algorithms and solve calculations. Writing efficient code involves finding algorithms with logarithmic temporal complexity. Programmers prefer binary search (O(log n)) over linear search (O(n)). Git source specifies O(log n):
Logarithms aid with programming math. Metas Watchman uses a logarithmic utility function to find the next power of two.
Employing Mathematical Data Structures
Programmers must know data structures to develop clean, efficient code. Stack, queue, and hashmap are computer science basics. Sets and graphs are discrete arithmetic data structures. Most computer languages include a set structure to hold distinct data entries. In most computer languages, graphs can be represented using neighboring lists or objects.
Using sets as deduped lists is powerful because set implementations allow iterators. Instead of a list (or array), store WebSocket connections in a set.
Most interviewers ask graph theory questions, yet current software engineers don't practice algorithms. Graph theory challenges become obligatory in IT firm interviews.
Recognizing Applications of Recursion
A function in programming isolates input(s) and output(s) (s). Programming functions may have originated from mathematical function theories. Programming and math functions are different but similar. Both function types accept input and return value.
Recursion involves calling the same function inside another function. In its implementation, you'll call the Fibonacci sequence. Recursion solves divide-and-conquer software engineering difficulties and avoids code repetition. I recently built the following recursive Dart code to render a Flutter multi-depth expanding list UI:
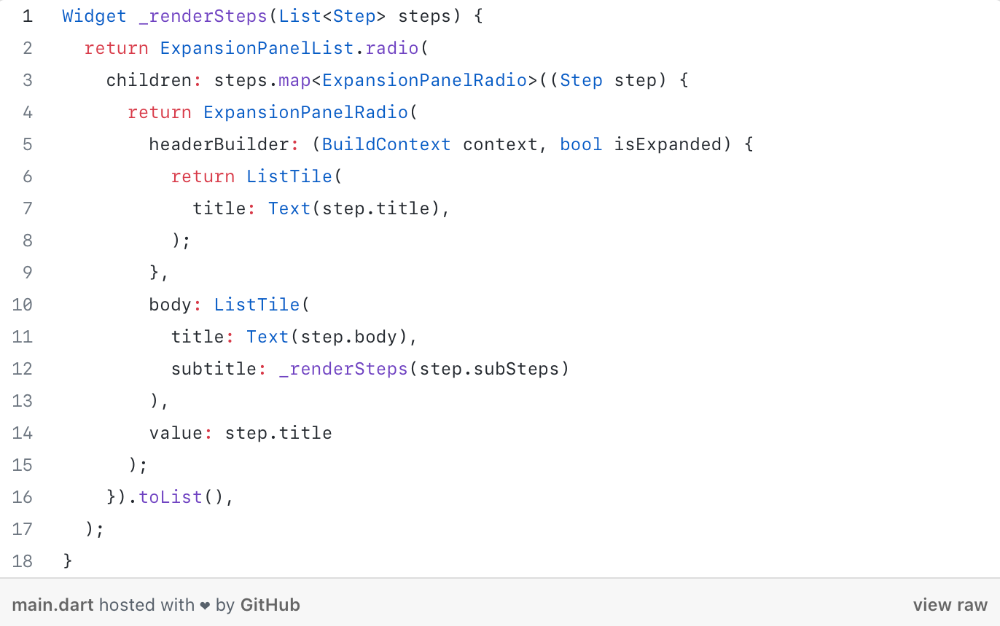
Recursion is not the natural linear way to solve problems, hence thinking recursively is difficult. Everything becomes clear when a mathematical function definition includes a base case and recursive call.
Conclusion
Every codebase uses arithmetic operators, relational operators, and expressions. To build mathematical expressions, we typically employ log, ceil, floor, min, max, etc. Combinatorics, geometry, data structures, and recursion help implement algorithms. Unless you operate in a pure mathematical domain, you may not use calculus, limits, and other complex math in daily programming (i.e., a game engine). These principles are fundamental for daily programming activities.
Master the above math fundamentals to build clean, efficient code.

Charlie Brown
3 years ago
What Happens When You Sell Your House, Never Buying It Again, Reverse the American Dream
Homeownership isn't the only life pattern.

Want to irritate people?
My party trick is to say I used to own a house but no longer do.
I no longer wish to own a home, not because I lost it or because I'm moving.
It was a long-term plan. It was more deliberate than buying a home. Many people are committed for this reason.
Poppycock.
Anyone who told me that owning a house (or striving to do so) is a must is wrong.
Because, URGH.
One pattern for life is to own a home, but there are millions of others.
You can afford to buy a home? Go, buddy.
You think you need 1,000 square feet (or more)? You think it's non-negotiable in life?
Nope.
It's insane that society forces everyone to own real estate, regardless of income, wants, requirements, or situation. As if this trade brings happiness, stability, and contentment.
Take it from someone who thought this for years: drywall isn't happy. Living your way brings contentment.
That's in real estate. It may also be renting a small apartment in a city that makes your soul sing, but you can't afford the downpayment or mortgage payments.
Living or traveling abroad is difficult when your life savings are connected to something that eats your money the moment you sign.
#vanlife, which seems like torment to me, makes some people feel alive.
I've seen co-living, vacation rental after holiday rental, living with family, and more work.
Insisting that home ownership is the only path in life is foolish and reduces alternative options.
How little we question homeownership is a disgrace.
No one challenges a homebuyer's motives. We congratulate them, then that's it.
When you offload one, you must answer every question, even if you have a loose screw.
Why do you want to sell?
Do you have any concerns about leaving the market?
Why would you want to renounce what everyone strives for?
Why would you want to abandon a beautiful place like that?
Why would you mismanage your cash in such a way?
But surely it's only temporary? RIGHT??
Incorrect questions. Buying a property requires several inquiries.
The typical American has $4500 saved up. When something goes wrong with the house (not if, it’s never if), can you actually afford the repairs?
Are you certain that you can examine a home in less than 15 minutes before committing to buying it outright and promising to pay more than twice the asking price on a 30-year 7% mortgage?
Are you certain you're ready to leave behind friends, family, and the services you depend on in order to acquire something?
Have you thought about the connotation that moving to a suburb, which more than half of Americans do, means you will be dependent on a car for the rest of your life?
Plus:
Are you sure you want to prioritize home ownership over debt, employment, travel, raising kids, and daily routines?
Homeownership entails that. This ex-homeowner says it will rule your life from the time you put the key in the door.
This isn't questioned. We don't question enough. The holy home-ownership grail was set long ago, and we don't challenge it.
Many people question after signing the deeds. 70% of homeowners had at least one regret about buying a property, including the expense.
Exactly. Tragic.
Homes are different from houses
We've been fooled into thinking home ownership will make us happy.
Some may agree. No one.
Bricks and brick hindered me from living the version of my life that made me most comfortable, happy, and steady.
I'm spending the next month in a modest apartment in southern Spain. Even though it's late November, today will be 68 degrees. My spouse and I will soon meet his visiting parents. We'll visit a Sherry store. We'll eat, nap, walk, and drink Sherry. Writing. Jerez means flamenco.
That's my home. This is such a privilege. Living a fulfilling life brings me the contentment that buying a home never did.
I'm happy and comfortable knowing I can make almost all of my days good. Rejecting home ownership is partly to blame.
I'm broke like most folks. I had to choose between home ownership and comfort. I said, I didn't find them together.
Feeling at home trumps owning brick-and-mortar every day.
The following is the reality of what it's like to turn the American Dream around.
Leaving the housing market.
Sometimes I wish I owned a home.
I miss having my own yard and bed. My kitchen, cookbooks, and pizza oven are missed.
But I rarely do.
Someone else's life plan pushed home ownership on me. I'm grateful I figured it out at 35. Many take much longer, and some never understand homeownership stinks (for them).
It's confusing. People will think you're dumb or suicidal.
If you read what I write, you'll know. You'll realize that all you've done is choose to live intentionally. Find a home beyond four walls and a picket fence.
Miss? As I said, they're not home. If it were, a pizza oven, a good mattress, and a well-stocked kitchen would bring happiness.
No.
If you can afford a house and desire one, more power to you.
There are other ways to discover home. Find calm and happiness. For fun.
For it, look deeper than your home's foundation.

Will Lockett
3 years ago
Thanks to a recent development, solar energy may prove to be the best energy source.

Perovskite solar cells will revolutionize everything.
Humanity is in a climatic Armageddon. Our widespread ecological crimes of the previous century are catching up with us, and planet-scale karma threatens everyone. We must adjust to new technologies and lifestyles to avoid this fate. Even solar power, a renewable energy source, has climate problems. A recent discovery could boost solar power's eco-friendliness and affordability. Perovskite solar cells are amazing.
Perovskite is a silicon-like semiconductor. Semiconductors are used to make computer chips, LEDs, camera sensors, and solar cells. Silicon makes sturdy and long-lasting solar cells, thus it's used in most modern solar panels.
Perovskite solar cells are far better. First, they're easy to make at room temperature, unlike silicon cells, which require long, intricate baking processes. This makes perovskite cells cheaper to make and reduces their carbon footprint. Perovskite cells are efficient. Most silicon panel solar farms are 18% efficient, meaning 18% of solar radiation energy is transformed into electricity. Perovskite cells are 25% efficient, making them 38% more efficient than silicon.
However, perovskite cells are nowhere near as durable. A normal silicon panel will lose efficiency after 20 years. The first perovskite cells were ineffective since they lasted barely minutes.
Recent research from Princeton shows that perovskite cells can endure 30 years. The cells kept their efficiency, therefore no sacrifices were made.
No electrical or chemical engineer here, thus I can't explain how they did it. But strangely, the team said longevity isn't the big deal. In the next years, perovskite panels will become longer-lasting. How do you test a panel if you only have a month or two? This breakthrough technique needs a uniform method to estimate perovskite life expectancy fast. The study's key milestone was establishing a standard procedure.
Lab-based advanced aging tests are their solution. Perovskite cells decay faster at higher temperatures, so scientists can extrapolate from that. The test heated the panel to 110 degrees and waited for its output to reduce by 20%. Their panel lasted 2,100 hours (87.5 days) before a 20% decline.
They did some math to extrapolate this data and figure out how long the panel would have lasted in different climates, and were shocked to find it would last 30 years in Princeton. This made perovskite panels as durable as silicon panels. This panel could theoretically be sold today.
This technology will soon allow these brilliant panels to be released into the wild. This technology could be commercially viable in ten, maybe five years.
Solar power will be the best once it does. Solar power is cheap and low-carbon. Perovskite is the cheapest renewable energy source if we switch to it. Solar panel manufacturing's carbon footprint will also drop.
Perovskites' impact goes beyond cost and carbon. Silicon panels require harmful mining and contain toxic elements (cadmium). Perovskite panels don't require intense mining or horrible materials, making their production and expiration more eco-friendly.
Solar power destroys habitat. Massive solar farms could reduce biodiversity and disrupt local ecology by destroying vital habitats. Perovskite cells are more efficient, so they can shrink a solar farm while maintaining energy output. This reduces land requirements, making perovskite solar power cheaper, and could reduce solar's environmental impact.
Perovskite solar power is scalable and environmentally friendly. Princeton scientists will speed up the development and rollout of this energy.
Why bother with fusion, fast reactors, SMRs, or traditional nuclear power? We're close to developing a nearly perfect environmentally friendly power source, and we have the tools and systems to do so quickly. It's also affordable, so we can adopt it quickly and let the developing world use it to grow. Even I struggle to justify spending billions on fusion when a great, cheap technology outperforms it. Perovskite's eco-credentials and cost advantages could save the world and power humanity's future.