



More on Entrepreneurship/Creators

Alex Mathers
25 years ago
400 articles later, nobody bothered to read them.
Writing for readers:
14 years of daily writing.
I post practically everything on social media. I authored hundreds of articles, thousands of tweets, and numerous volumes to almost no one.
Tens of thousands of readers regularly praise me.
I despised writing. I'm stuck now.
I've learned what readers like and what doesn't.
Here are some essential guidelines for writing with impact:
Readers won't understand your work if you can't.
Though obvious, this slipped me up. Share your truths.
Stories engage human brains.
Showing the journey of a person from worm to butterfly inspires the human spirit.
Overthinking hinders powerful writing.
The best ideas come from inner understanding in between thoughts.
Avoid writing to find it. Write.
Writing a masterpiece isn't motivating.
Write for five minutes to simplify. Step-by-step, entertaining, easy steps.
Good writing requires a willingness to make mistakes.
So write loads of garbage that you can edit into a good piece.
Courageous writing.
A courageous story will move readers. Personal experience is best.
Go where few dare.
Templates, outlines, and boundaries help.
Limitations enhance writing.
Excellent writing is straightforward and readable, removing all the unnecessary fat.
Use five words instead of nine.
Use ordinary words instead of uncommon ones.
Readers desire relatability.
Too much perfection will turn it off.
Write to solve an issue if you can't think of anything to write.
Instead, read to inspire. Best authors read.
Every tweet, thread, and novel must have a central idea.
What's its point?
This can make writing confusing.
️ Don't direct your reader.
Readers quit reading. Demonstrate, describe, and relate.
Even if no one responds, have fun. If you hate writing it, the reader will too.

Kaitlin Fritz
3 years ago
The Entrepreneurial Chicken and Egg
University entrepreneurship is like a Willy Wonka Factory of ideas. Classes, roommates, discussions, and the cafeteria all inspire new ideas. I've seen people establish a business without knowing its roots.
Chicken or egg? On my mind: I've asked university founders around the world whether the problem or solution came first.
The Problem
One African team I met started with the “instant noodles” problem in their academic ecosystem. Many of us have had money issues in college, which may have led to poor nutritional choices.
Many university students in a war-torn country ate quick noodles or pasta for dinner.

Noodles required heat, water, and preparation in the boarding house. Unreliable power from one hot plate per blue moon. What's healthier, easier, and tastier than sodium-filled instant pots?
BOOM. They were fixing that. East African kids need affordable, nutritious food.
This is a real difficulty the founders faced every day with hundreds of comrades.
This sparked their serendipitous entrepreneurial journey and became their business's cornerstone.
The Solution
I asked a UK team about their company idea. They said the solution fascinated them.
The crew was fiddling with social media algorithms. Why are some people more popular? They were studying platforms and social networks, which offered a way for them.

Solving a problem? Yes. Long nights of university research lead them to it. Is this like world hunger? Social media influencers confront this difficulty regularly.
It made me ponder something. Is there a correct response?
In my heart, yes, but in my head…maybe?
I believe you should lead with empathy and embrace the problem, not the solution. Big or small, businesses should solve problems. This should be your focus. This is especially true when building a social company with an audience in mind.
Philosophically, invention and innovation are occasionally accidental. Also not penalized. Think about bugs and the creation of Velcro, or the inception of Teflon. They tackle difficulties we overlook. The route to the problem may look different, but there is a path there.
There's no golden ticket to the Chicken-Egg debate, but I'll keep looking this summer.

Tim Denning
3 years ago
Bills are paid by your 9 to 5. 6 through 12 help you build money.
40 years pass. After 14 years of retirement, you die. Am I the only one who sees the problem?

I’m the Jedi master of escaping the rat race.
Not to impress. I know this works since I've tried it. Quitting a job to make money online is worse than Kim Kardashian's internet-burning advice.
Let me help you rethink the move from a career to online income to f*ck you money.
To understand why a job is a joke, do some life math.
Without a solid why, nothing makes sense.
The retirement age is 65. Our processed food consumption could shorten our 79-year average lifespan.
You spend 40 years working.
After 14 years of retirement, you die.
Am I alone in seeing the problem?
Life is too short to work a job forever, especially since most people hate theirs. After-hours skills are vital.
Money equals unrestricted power, f*ck you.
F*ck you money is the answer.
Jack Raines said it first. He says we can do anything with the money. Jack, a young rebel straight out of college, can travel and try new foods.
F*ck you money signifies not checking your bank account before buying.
F*ck you” money is pure, unadulterated freedom with no strings attached.
Jack claims you're rich when you rarely think about money.
Avoid confusion.
This doesn't imply you can buy a Lamborghini. It indicates your costs, income, lifestyle, and bank account are balanced.
Jack established an online portfolio while working for UPS in Atlanta, Georgia. So he gained boundless power.
The portion that many erroneously believe
Yes, you need internet abilities to make money, but they're not different from 9-5 talents.
Sahil Lavingia, Gumroad's creator, explains.
A job is a way to get paid to learn.
Mistreat your boss 9-5. Drain his skills. Defuse him. Love and leave him (eventually).
Find another employment if yours is hazardous. Pick an easy job. Make sure nothing sneaks into your 6-12 time slot.
The dumb game that makes you a sheep
A 9-5 job requires many job interviews throughout life.
You email your résumé to employers and apply for jobs through advertisements. This game makes you a sheep.
You're competing globally. Work-from-home makes the competition tougher. If you're not the cheapest, employers won't hire you.
After-hours online talents (say, 6 pm-12 pm) change the game. This graphic explains it better:
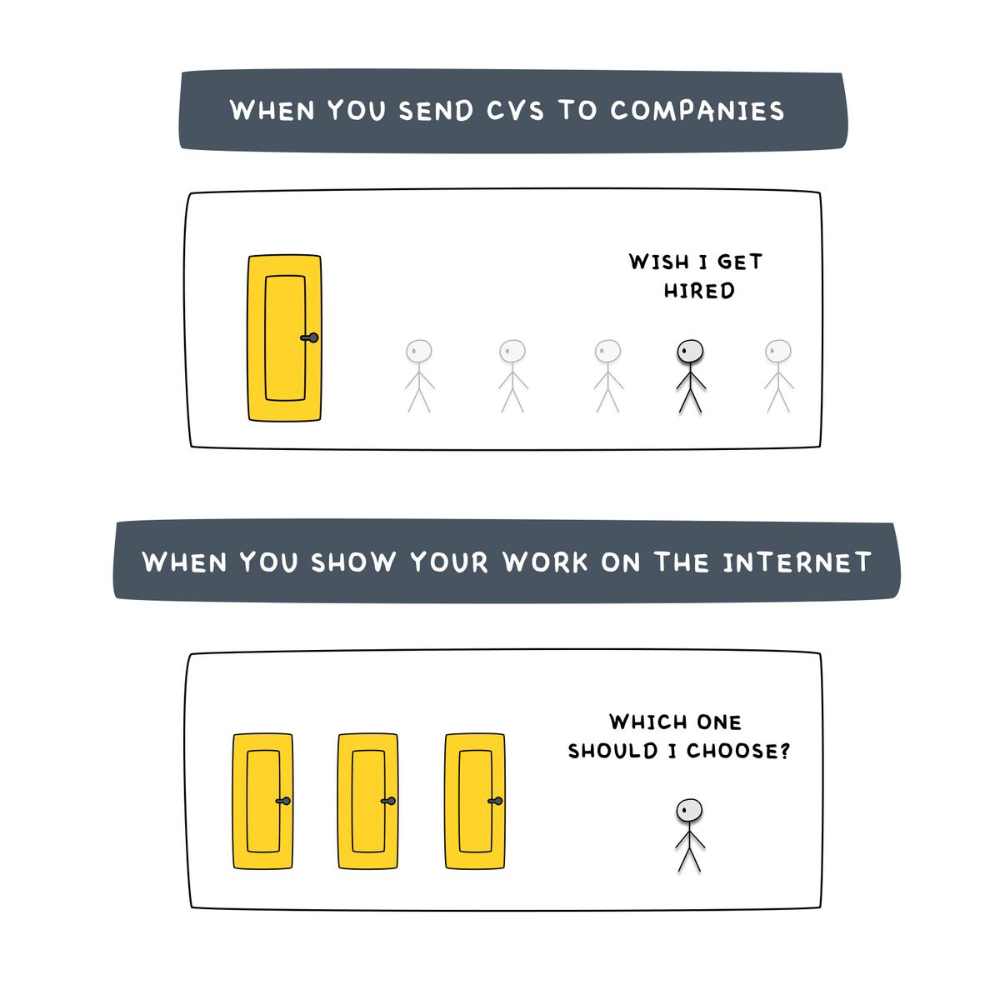
Online talents boost after-hours opportunities.
You go from wanting to be picked to picking yourself. More chances equal more money. Your f*ck you fund gets the extra cash.
A novel method of learning is essential.
College costs six figures and takes a lifetime to repay.
Informal learning is distinct. 6-12pm:
Observe the carefully controlled Twitter newsfeed.
Make use of Teachable and Gumroad's online courses.
Watch instructional YouTube videos
Look through the top Substack newsletters.
Informal learning is more effective because it's not obvious. It's fun to follow your curiosity and hobbies.

The majority of people lack one attitude. It's simple to learn.
One big impediment stands in the way of f*ck you money and time independence. So often.
Too many people plan after 6-12 hours. Dreaming. Big-thinkers. Strategically. They fill their calendar with meetings.
This is after-hours masturb*tion.
Sahil Bloom reminded me that a bias towards action will determine if this approach works for you.
The key isn't knowing what to do from 6-12 a.m. Trust yourself and develop abilities as you go. It's for building the parachute after you jump.
Sounds risky. We've eliminated the risk by finishing this process after hours while you work 9-5.
With no risk, you can have an I-don't-care attitude and still be successful.
When you choose to move forward, this occurs.
Once you try 9-5/6-12, you'll tell someone.
It's bad.
Few of us hang out with problem-solvers.
It's how much of society operates. So they make reasons so they can feel better about not giving you money.
Matthew Kobach told me chasing f*ck you money is easier with like-minded folks.
Without f*ck you money friends, loneliness will take over and you'll think you've messed up when you just need to keep going.
Steal this easy guideline
Let's act. No more fluffing and caressing.
1. Learn
If you detest your 9-5 talents or don't think they'll work online, get new ones. If you're skilled enough, continue.
Easlo recommends these skills:
Designer for Figma
Designer Canva
bubble creators
editor in Photoshop
Automation consultant for Zapier
Designer of Webflow
video editor Adobe
Ghostwriter for Twitter
Idea consultant
Artist in Blender Studio
2. Develop the ability
Every night from 6-12, apply the skill.
Practicing ghostwriting? Write someone's tweets for free. Do someone's website copy to learn copywriting. Get a website to the top of Google for a keyword to understand SEO.
Free practice is crucial. Your 9-5 pays the money, so work for free.
3. Take off stealthily like a badass
Another mistake. Sell to few. Don't be the best. Don't claim expertise.
Sell your new expertise to others behind you.
Two ways:
Using a digital good
By providing a service,
Point 1 also includes digital service examples. Digital products include eBooks, communities, courses, ad-supported podcasts, and templates. It's easy. Your 9-5 job involves one of these.
Take ideas from work.
Why? They'll steal your time for profit.
4. Iterate while feeling awful
First-time launches always fail. You'll feel terrible. Okay. Remember your 9-5?
Find improvements. Ask free and paying consumers what worked.
Multiple relaunches, each 1% better.
5. Discover more
Never stop learning. Improve your skill. Add a relevant skill. Learn copywriting if you write online.
After-hours students earn the most.
6. Continue
Repetition is key.
7. Make this one small change.
Consistently. The 6-12 momentum won't make you rich in 30 days; that's success p*rn.
Consistency helps wage slaves become f*ck you money. Most people can't switch between the two.
Putting everything together
It's easy. You're probably already doing some.
This formula explains why, how, and what to do. It's a 5th-grade-friendly blueprint. Good.
Reduce financial risk with your 9-to-5. Replace Netflix with 6-12 money-making talents.
Life is short; do whatever you want. Today.
You might also like

Adam Frank
3 years ago
Humanity is not even a Type 1 civilization. What might a Type 3 be capable of?

The Kardashev scale grades civilizations from Type 1 to Type 3 based on energy harvesting.
How do technologically proficient civilizations emerge across timescales measuring in the tens of thousands or even millions of years? This is a question that worries me as a researcher in the search for “technosignatures” from other civilizations on other worlds. Since it is already established that longer-lived civilizations are the ones we are most likely to detect, knowing something about their prospective evolutionary trajectories could be translated into improved search tactics. But even more than knowing what to seek for, what I really want to know is what happens to a society after so long time. What are they capable of? What do they become?
This was the question Russian SETI pioneer Nikolai Kardashev asked himself back in 1964. His answer was the now-famous “Kardashev Scale.” Kardashev was the first, although not the last, scientist to try and define the processes (or stages) of the evolution of civilizations. Today, I want to launch a series on this question. It is crucial to technosignature studies (of which our NASA team is hard at work), and it is also important for comprehending what might lay ahead for mankind if we manage to get through the bottlenecks we have now.
The Kardashev scale
Kardashev’s question can be expressed another way. What milestones in a civilization’s advancement up the ladder of technical complexity will be universal? The main notion here is that all (or at least most) civilizations will pass through some kind of definable stages as they progress, and some of these steps might be mirrored in how we could identify them. But, while Kardashev’s major focus was identifying signals from exo-civilizations, his scale gave us a clear way to think about their evolution.
The classification scheme Kardashev employed was not based on social systems of ethics because they are something that we can probably never predict about alien cultures. Instead, it was built on energy, which is something near and dear to the heart of everybody trained in physics. Energy use might offer the basis for universal stages of civilisation progression because you cannot do the work of establishing a civilization without consuming energy. So, Kardashev looked at what energy sources were accessible to civilizations as they evolved technologically and used those to build his scale.
From Kardashev’s perspective, there are three primary levels or “types” of advancement in terms of harvesting energy through which a civilization should progress.
Type 1: Civilizations that can capture all the energy resources of their native planet constitute the first stage. This would imply capturing all the light energy that falls on a world from its host star. This makes it reasonable, given solar energy will be the largest source available on most planets where life could form. For example, Earth absorbs hundreds of atomic bombs’ worth of energy from the Sun every second. That is a rather formidable energy source, and a Type 1 race would have all this power at their disposal for civilization construction.
Type 2: These civilizations can extract the whole energy resources of their home star. Nobel Prize-winning scientist Freeman Dyson famously anticipated Kardashev’s thinking on this when he imagined an advanced civilization erecting a large sphere around its star. This “Dyson Sphere” would be a machine the size of the complete solar system for gathering stellar photons and their energy.
Type 3: These super-civilizations could use all the energy produced by all the stars in their home galaxy. A normal galaxy has a few hundred billion stars, so that is a whole lot of energy. One way this may be done is if the civilization covered every star in their galaxy with Dyson spheres, but there could also be more inventive approaches.
Implications of the Kardashev scale
Climbing from Type 1 upward, we travel from the imaginable to the god-like. For example, it is not hard to envisage utilizing lots of big satellites in space to gather solar energy and then beaming that energy down to Earth via microwaves. That would get us to a Type 1 civilization. But creating a Dyson sphere would require chewing up whole planets. How long until we obtain that level of power? How would we have to change to get there? And once we get to Type 3 civilizations, we are virtually thinking about gods with the potential to engineer the entire cosmos.
For me, this is part of the point of the Kardashev scale. Its application for thinking about identifying technosignatures is crucial, but even more strong is its capacity to help us shape our imaginations. The mind might become blank staring across hundreds or thousands of millennia, and so we need tools and guides to focus our attention. That may be the only way to see what life might become — what we might become — once it arises to start out beyond the boundaries of space and time and potential.
This is a summary. Read the full article here.
Langston Thomas
3 years ago
A Simple Guide to NFT Blockchains
Ethereum's blockchain rules NFTs. Many consider it the one-stop shop for NFTs, and it's become the most talked-about and trafficked blockchain in existence.
Other blockchains are becoming popular in NFTs. Crypto-artists and NFT enthusiasts have sought new places to mint and trade NFTs due to Ethereum's high transaction costs and environmental impact.
When choosing a blockchain to mint on, there are several factors to consider. Size, creator costs, consumer spending habits, security, and community input are important. We've created a high-level summary of blockchains for NFTs to help clarify the fast-paced world of web3 tech.
Ethereum
Ethereum currently has the most NFTs. It's decentralized and provides financial and legal services without intermediaries. It houses popular NFT marketplaces (OpenSea), projects (CryptoPunks and the Bored Ape Yacht Club), and artists (Pak and Beeple).
It's also expensive and energy-intensive. This is because Ethereum works using a Proof-of-Work (PoW) mechanism. PoW requires computers to solve puzzles to add blocks and transactions to the blockchain. Solving these puzzles requires a lot of computer power, resulting in astronomical energy loss.
You should consider this blockchain first due to its popularity, security, decentralization, and ease of use.
Solana
Solana is a fast programmable blockchain. Its proof-of-history and proof-of-stake (PoS) consensus mechanisms eliminate complex puzzles. Reduced validation times and fees result.
PoS users stake their cryptocurrency to become a block validator. Validators get SOL. This encourages and rewards users to become stakers. PoH works with PoS to cryptographically verify time between events. Solana blockchain ensures transactions are in order and found by the correct leader (validator).
Solana's PoS and PoH mechanisms keep transaction fees and times low. Solana isn't as popular as Ethereum, so there are fewer NFT marketplaces and blockchain traders.
Tezos
Tezos is a greener blockchain. Tezos rose in 2021. Hic et Nunc was hailed as an economic alternative to Ethereum-centric marketplaces until Nov. 14, 2021.
Similar to Solana, Tezos uses a PoS consensus mechanism and only a PoS mechanism to reduce computational work. This blockchain uses two million times less energy than Ethereum. It's cheaper than Ethereum (but does cost more than Solana).
Tezos is a good place to start minting NFTs in bulk. Objkt is the largest Tezos marketplace.
Flow
Flow is a high-performance blockchain for NFTs, games, and decentralized apps (dApps). Flow is built with scalability in mind, so billions of people could interact with NFTs on the blockchain.
Flow became the NBA's blockchain partner in 2019. Flow, a product of Dapper labs (the team behind CryptoKitties), launched and hosts NBA Top Shot, making the blockchain integral to the popularity of non-fungible tokens.
Flow uses PoS to verify transactions, like Tezos. Developers are working on a model to handle 10,000 transactions per second on the blockchain. Low transaction fees.
Flow NFTs are tradeable on Blocktobay, OpenSea, Rarible, Foundation, and other platforms. NBA, NFL, UFC, and others have launched NFT marketplaces on Flow. Flow isn't as popular as Ethereum, resulting in fewer NFT marketplaces and blockchain traders.
Asset Exchange (WAX)
WAX is king of virtual collectibles. WAX is popular for digitalized versions of legacy collectibles like trading cards, figurines, memorabilia, etc.
Wax uses a PoS mechanism, but also creates carbon offset NFTs and partners with Climate Care. Like Flow, WAX transaction fees are low, and network fees are redistributed to the WAX community as an incentive to collectors.
WAX marketplaces host Topps, NASCAR, Hot Wheels, and cult classic film franchises like Godzilla, The Princess Bride, and Spiderman.
Binance Smart Chain
BSC is another good option for balancing fees and performance. High-speed transactions and low fees hurt decentralization. BSC is most centralized.
Binance Smart Chain uses Proof of Staked Authority (PoSA) to support a short block time and low fees. The 21 validators needed to run the exchange switch every 24 hours. 11 of the 21 validators are directly connected to the Binance Crypto Exchange, according to reports.
While many in the crypto and NFT ecosystems dislike centralization, the BSC NFT market picked up speed in 2021. OpenBiSea, AirNFTs, JuggerWorld, and others are gaining popularity despite not having as robust an ecosystem as Ethereum.

Ivona Hirschi
3 years ago
7 LinkedIn Tips That Will Help in Audience Growth
In 8 months, I doubled my audience with them.

LinkedIn's buzz isn't over.
People dream of social proof every day. They want clients, interesting jobs, and field recognition.
LinkedIn coaches will benefit greatly. Sell learning? Probably. Can you use it?
Consistency has been key in my eight-month study of LinkedIn. However, I'll share seven of my tips. 700 to 4500 people followed me.
1. Communication, communication, communication
LinkedIn is a social network. I like to think of it as a cafe. Here, you can share your thoughts, meet friends, and discuss life and work.
Do not treat LinkedIn as if it were a board for your post-its.
More socializing improves relationships. It's about people, like any network.
Consider interactions. Three main areas:
Respond to criticism left on your posts.
Comment on other people's posts
Start and maintain conversations through direct messages.
Engage people. You spend too much time on Facebook if you only read your wall. Keeping in touch and having meaningful conversations helps build your network.
Every day, start a new conversation to make new friends.
2. Stick with those you admire
Interact thoughtfully.
Choose your contacts. Build your tribe is a term. Respectful networking.
I only had past colleagues, family, and friends in my network at the start of this year. Not business-friendly. Since then, I've sought out people I admire or can learn from.
Finding a few will help you. As they connect you to their networks. Friendships can lead to clients.
Don't underestimate network power. Cafe-style. Meet people at each table. But avoid people who sell SEO, web redesign, VAs, mysterious job opportunities, etc.
3. Share eye-catching infographics
Daily infographics flood LinkedIn. Visuals are popular. Use Canva's free templates if you can't draw them.
Last week's:

It's a fun way to visualize your topic.
You can repost and comment on infographics. Involve your network. I prefer making my own because I build my brand around certain designs.
My friend posted infographics consistently for four months and grew his network to 30,000.
If you start, credit the authors. As you steal someone's work.
4. Invite some friends over.
LinkedIn alone can be lonely. Having a few friends who support your work daily will boost your growth.
I was lucky to be invited to a group of networkers. We share knowledge and advice.
Having a few regulars who can discuss your posts is helpful. It's artificial, but it works and engages others.
Consider who you'd support if they were in your shoes.
You can pay for an engagement group, but you risk supporting unrelated people with rubbish posts.
Help each other out.
5. Don't let your feed or algorithm divert you.
LinkedIn's algorithm is magical.
Which time is best? How fast do you need to comment? Which days are best?
Overemphasize algorithms. Consider the user. No need to worry about the best time.
Remember to spend time on LinkedIn actively. Not passively. That is what Facebook is for.
Surely someone would find a LinkedIn recipe. Don't beat the algorithm yet. Consider your audience.
6. The more personal, the better
Personalization isn't limited to selfies. Share your successes and failures.
The more personality you show, the better.
People relate to others, not theories or quotes. Why should they follow you? Everyone posts the same content?
Consider your friends. What's their appeal?
Because they show their work and identity. It's simple. Medium and Linkedin are your platforms. Find out what works.
You can copy others' hooks and structures. You decide how simple to make it, though.
7. Have fun with those who have various post structures.
I like writing, infographics, videos, and carousels. Because you can:
Repurpose your content!
Out of one blog post I make:
Newsletter
Infographics (positive and negative points of view)
Carousel
Personal stories
Listicle
Create less but more variety. Since LinkedIn posts last 24 hours, you can rotate the same topics for weeks without anyone noticing.
Effective!
The final LI snippet to think about
LinkedIn is about consistency. Some say 15 minutes. If you're serious about networking, spend more time there.
The good news is that it is worth it. The bad news is that it takes time.