




More on Web3 & Crypto

Ren & Heinrich
3 years ago
200 DeFi Projects were examined. Here is what I learned.
I analyze the top 200 DeFi crypto projects in this article.
This isn't a study. The findings benefit crypto investors.
Let’s go!
A set of data
I analyzed data from defillama.com. In my analysis, I used the top 200 DeFis by TVL in October 2022.
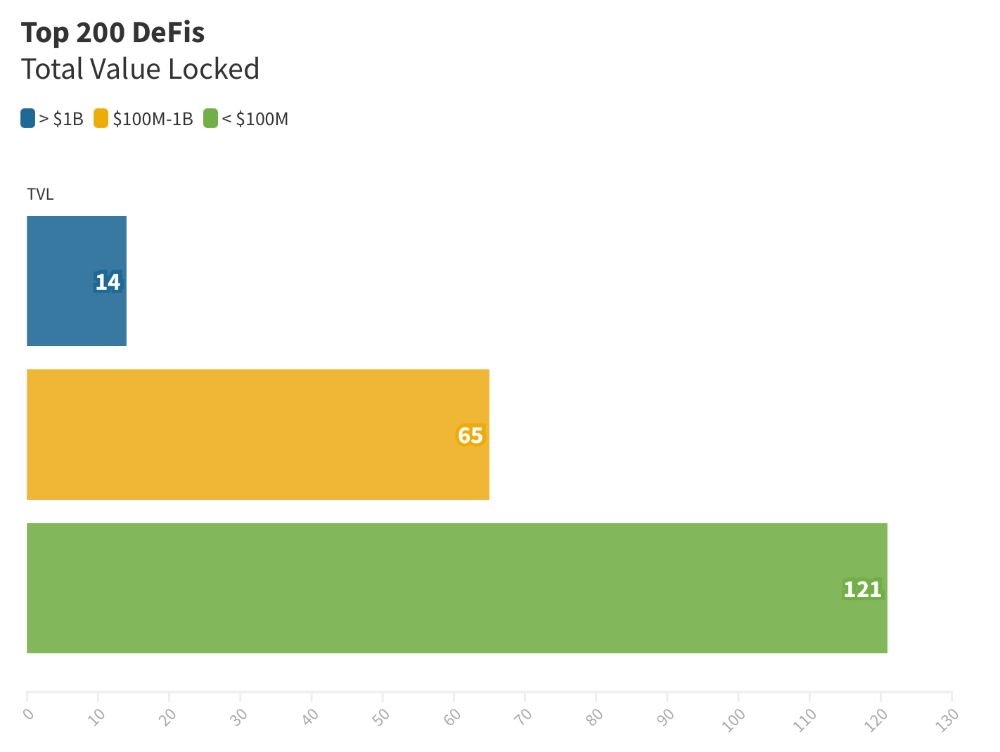
Total Locked Value
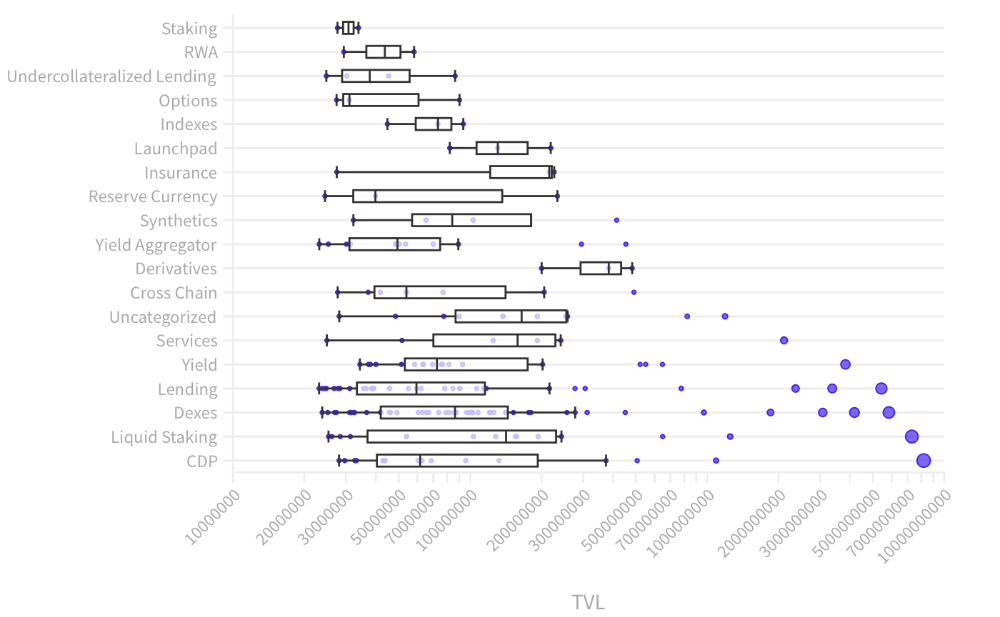
The chart below shows platform-specific locked value.
14 platforms had $1B+ TVL. 65 platforms have $100M-$1B TVL. The remaining 121 platforms had TVLs below $100 million, with the lowest being $23 million.
TVLs are distributed Pareto. Top 40% of DeFis account for 80% of TVLs.
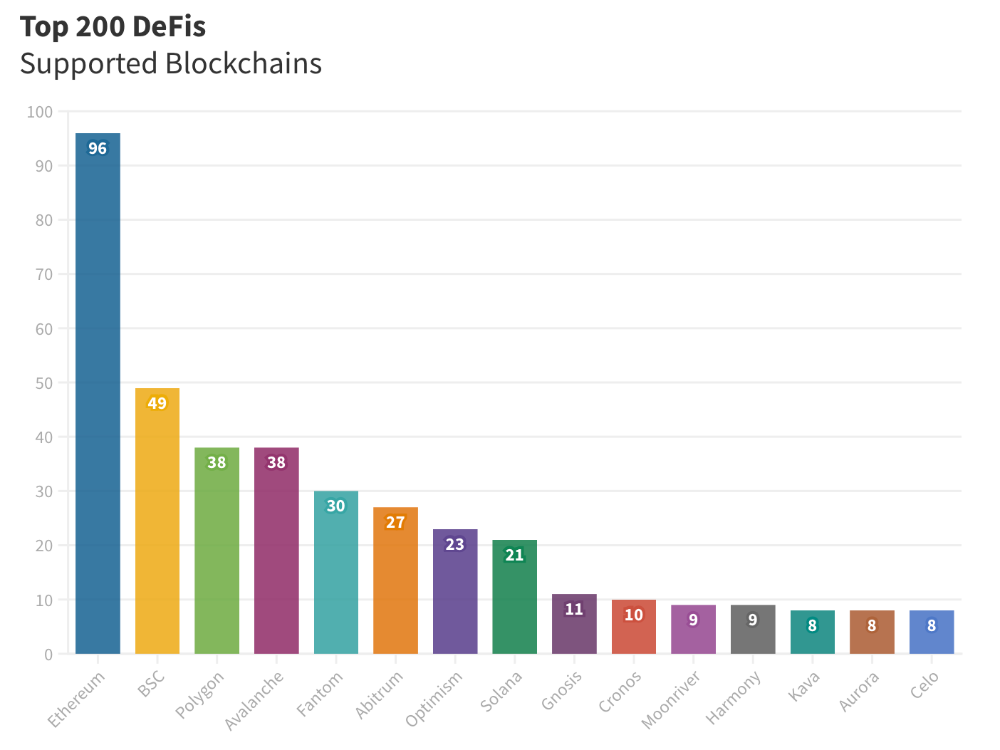
Compliant Blockchains
Ethereum's blockchain leads DeFi. 96 of the examined projects offer services on Ethereum. Behind BSC, Polygon, and Avalanche.
Five platforms used 10+ blockchains. 36 between 2-10 159 used 1 blockchain.
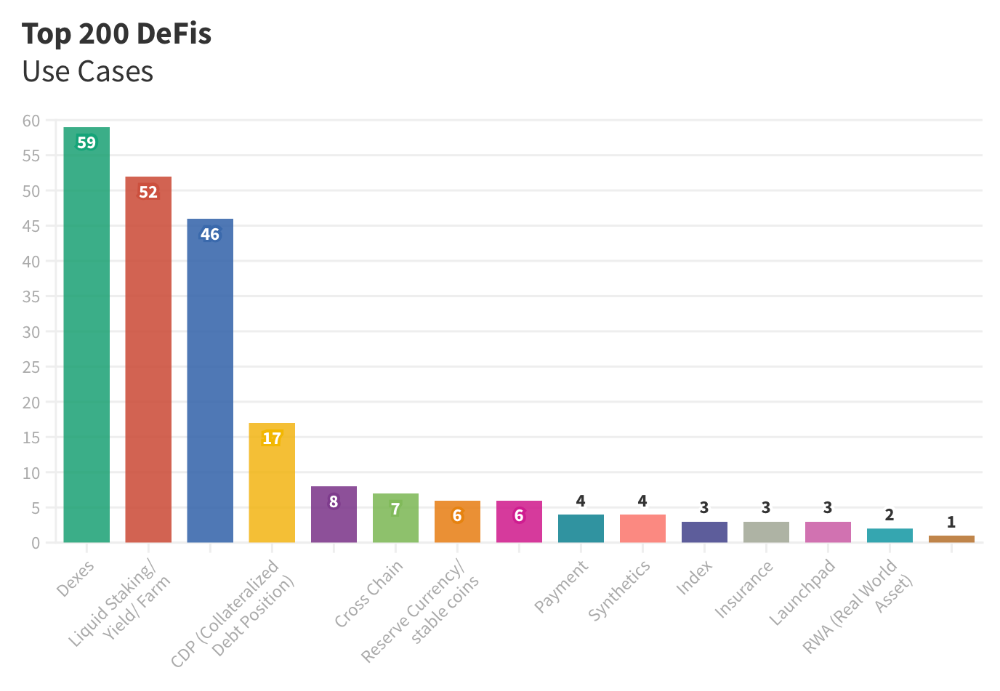
Use Cases for DeFi
The chart below shows platform use cases. Each platform has decentralized exchanges, liquid staking, yield farming, and lending.
These use cases are DefiLlama's main platform features.
Which use case costs the most? Chart explains. Collateralized debt, liquid staking, dexes, and lending have high TVLs.
The DeFi Industry
I compared three high-TVL platforms (Maker DAO, Balancer, AAVE). The columns show monthly TVL and token price changes. The graph shows monthly Bitcoin price changes.
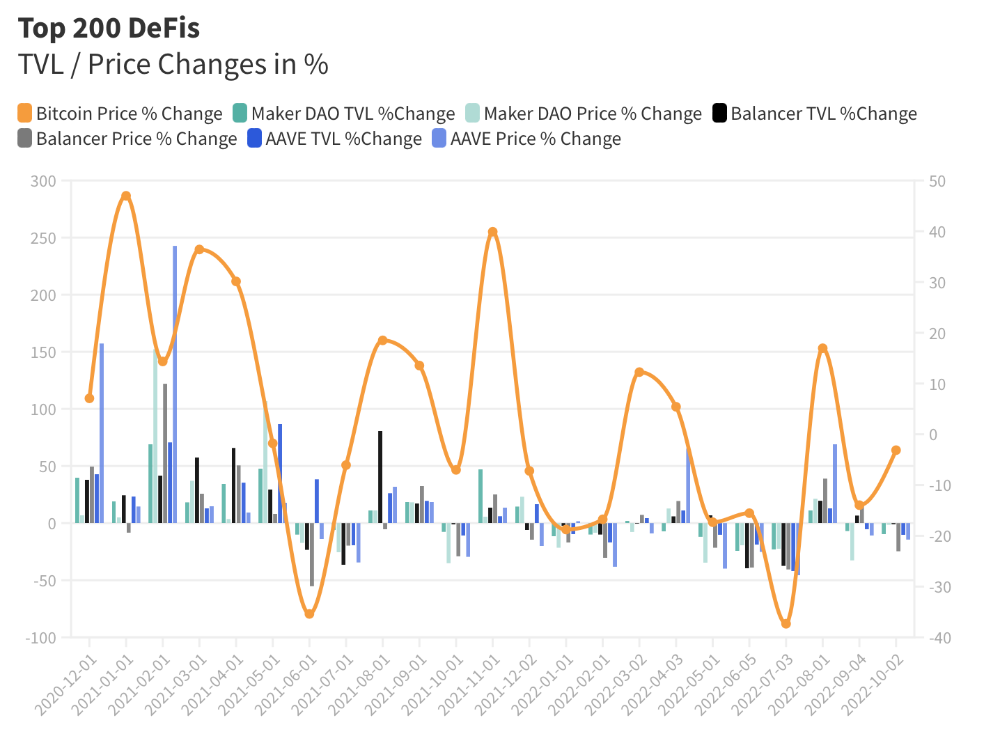
Each platform's market moves similarly.
Probably because most DeFi deposits are cryptocurrencies. Since individual currencies are highly correlated with Bitcoin, it's not surprising that they move in unison.
Takeaways
This analysis shows that the most common DeFi services (decentralized exchanges, liquid staking, yield farming, and lending) also have the highest average locked value.
Some projects run on one or two blockchains, while others use 15 or 20. Our analysis shows that a project's blockchain count has no correlation with its success.
It's hard to tell if certain use cases are rising. Bitcoin's price heavily affects the entire DeFi market.
TVL seems to be a good indicator of a DeFi platform's success and quality. Higher TVL platforms are cheaper. They're a better long-term investment because they gain or lose less value than DeFis with lower TVLs.

ANDREW SINGER
3 years ago
Crypto seen as the ‘future of money’ in inflation-mired countries
Crypto as the ‘future of money' in inflation-stricken nations
Citizens of devalued currencies “need” crypto. “Nice to have” in the developed world.
According to Gemini's 2022 Global State of Crypto report, cryptocurrencies “evolved from what many considered a niche investment into an established asset class” last year.
More than half of crypto owners in Brazil (51%), Hong Kong (51%), and India (54%), according to the report, bought cryptocurrency for the first time in 2021.
The study found that inflation and currency devaluation are powerful drivers of crypto adoption, especially in emerging market (EM) countries:
“Respondents in countries that have seen a 50% or greater devaluation of their currency against the USD over the last decade were more than 5 times as likely to plan to purchase crypto in the coming year.”
Between 2011 and 2021, the real lost 218 percent of its value against the dollar, and 45 percent of Brazilians surveyed by Gemini said they planned to buy crypto in 2019.
The rand (South Africa's currency) has fallen 103 percent in value over the last decade, second only to the Brazilian real, and 32 percent of South Africans expect to own crypto in the coming year. Mexico and India, the third and fourth highest devaluation countries, followed suit.
Compared to the US dollar, Hong Kong and the UK currencies have not devalued in the last decade. Meanwhile, only 5% and 8% of those surveyed in those countries expressed interest in buying crypto.
What can be concluded? Noah Perlman, COO of Gemini, sees various crypto use cases depending on one's location.
‘Need to have' investment in countries where the local currency has devalued against the dollar, whereas in the developed world it is still seen as a ‘nice to have'.
Crypto as money substitute
As an adjunct professor at New York University School of Law, Winston Ma distinguishes between an asset used as an inflation hedge and one used as a currency replacement.
Unlike gold, he believes Bitcoin (BTC) is not a “inflation hedge”. They acted more like growth stocks in 2022. “Bitcoin correlated more closely with the S&P 500 index — and Ether with the NASDAQ — than gold,” he told Cointelegraph. But in the developing world, things are different:
“Inflation may be a primary driver of cryptocurrency adoption in emerging markets like Brazil, India, and Mexico.”
According to Justin d'Anethan, institutional sales director at the Amber Group, a Singapore-based digital asset firm, early adoption was driven by countries where currency stability and/or access to proper banking services were issues. Simply put, he said, developing countries want alternatives to easily debased fiat currencies.
“The larger flows may still come from institutions and developed countries, but the actual users may come from places like Lebanon, Turkey, Venezuela, and Indonesia.”
“Inflation is one of the factors that has and continues to drive adoption of Bitcoin and other crypto assets globally,” said Sean Stein Smith, assistant professor of economics and business at Lehman College.
But it's only one factor, and different regions have different factors, says Stein Smith. As a “instantaneously accessible, traceable, and cost-effective transaction option,” investors and entrepreneurs increasingly recognize the benefits of crypto assets. Other places promote crypto adoption due to “potential capital gains and returns”.
According to the report, “legal uncertainty around cryptocurrency,” tax questions, and a general education deficit could hinder adoption in Asia Pacific and Latin America. In Africa, 56% of respondents said more educational resources were needed to explain cryptocurrencies.
Not only inflation, but empowering our youth to live better than their parents without fear of failure or allegiance to legacy financial markets or products, said Monica Singer, ConsenSys South Africa lead. Also, “the issue of cash and remittances is huge in Africa, as is the issue of social grants.”
Money's future?
The survey found that Brazil and Indonesia had the most cryptocurrency ownership. In each country, 41% of those polled said they owned crypto. Only 20% of Americans surveyed said they owned cryptocurrency.
These markets are more likely to see cryptocurrencies as the future of money. The survey found:
“The majority of respondents in Latin America (59%) and Africa (58%) say crypto is the future of money.”
Brazil (66%), Nigeria (63%), Indonesia (61%), and South Africa (57%). Europe and Australia had the fewest believers, with Denmark at 12%, Norway at 15%, and Australia at 17%.
Will the Ukraine conflict impact adoption?
The poll was taken before the war. Will the devastating conflict slow global crypto adoption growth?
With over $100 million in crypto donations directly requested by the Ukrainian government since the war began, Stein Smith says the war has certainly brought crypto into the mainstream conversation.
“This real-world demonstration of decentralized money's power could spur wider adoption, policy debate, and increased use of crypto as a medium of exchange.”
But the war may not affect all developing nations. “The Ukraine war has no impact on African demand for crypto,” Others loom larger. “Yes, inflation, but also a lack of trust in government in many African countries, and a young demographic very familiar with mobile phones and the internet.”
A major success story like Mpesa in Kenya has influenced the continent and may help accelerate crypto adoption. Creating a plan when everyone you trust fails you is directly related to the African spirit, she said.
On the other hand, Ma views the Ukraine conflict as a sort of crisis check for cryptocurrencies. For those in emerging markets, the Ukraine-Russia war has served as a “stress test” for the cryptocurrency payment rail, he told Cointelegraph.
“These emerging markets may see the greatest future gains in crypto adoption.”
Inflation and currency devaluation are persistent global concerns. In such places, Bitcoin and other cryptocurrencies are now seen as the “future of money.” Not in the developed world, but that could change with better regulation and education. Inflation and its impact on cash holdings are waking up even Western nations.
Read original post here.

Tim Denning
3 years ago
The Dogecoin millionaire mysteriously disappeared.
The American who bought a meme cryptocurrency.

Cryptocurrency is the financial underground.
I love it. But there’s one thing I hate: scams. Over the last few years the Dogecoin cryptocurrency saw massive gains.
Glauber Contessoto overreacted. He shared his rags-to-riches cryptocurrency with the media.
He's only wealthy on paper. No longer Dogecoin millionaire.
Here's what he's doing now. It'll make you rethink cryptocurrency investing.
Strange beginnings
Glauber once had a $36,000-a-year job.
He grew up poor and wanted to make his mother proud. Tesla was his first investment. He bought GameStop stock after Reddit boosted it.
He bought whatever was hot.
He was a young investor. Memes, not research, influenced his decisions.
Elon Musk (aka Papa Elon) began tweeting about Dogecoin.
Doge is a 2013 cryptocurrency. One founder is Australian. He insists it's funny.
He was shocked anyone bought it LOL.
Doge is a Shiba Inu-themed meme. Now whenever I see a Shiba Inu, I think of Doge.
Elon helped drive up the price of Doge by talking about it in 2020 and 2021 (don't take investment advice from Elon; he's joking and gaslighting you).
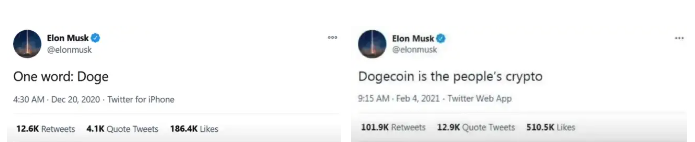
Glauber caved. He invested everything in Doge. He borrowed from family and friends. He maxed out his credit card to buy more Doge. Yuck.
Internet dubbed him a genius. Slumdog millionaire and The Dogefather were nicknames. Elon pumped Doge on social media.
Good times.
From $180,000 to $1,000,000+
TikTok skyrocketed Doge's price.
Reddit fueled up. Influencers recommended buying Doge because of its popularity. Glauber's motto:
Scared money doesn't earn.
Glauber was no broke ass anymore.
His $180,000 Dogecoin investment became $1M. He championed investing. He quit his dumb job like a rebellious millennial.
A puppy dog meme captivated the internet.
Rise and fall
Whenever I invest in anything I ask myself “what utility does this have?”
Dogecoin is useless.
You buy it for the cute puppy face and hope others will too, driving up the price. All cryptocurrencies fell in 2021's second half.
Central banks raised interest rates, and inflation became a pain.
Dogecoin fell more than others. 90% decline.
Glauber’s Dogecoin is now worth $323K. Still no sales. His dog god is unshakeable. Confidence rocks. Dogecoin millionaire recently said...
“I should have sold some.”
Yes, sir.
He now avoids speculative cryptocurrencies like Dogecoin and focuses on Bitcoin and Ethereum.
I've long said this. Starbucks is building on Ethereum.
It's useful. Useful. Developers use Ethereum daily. Investing makes you wiser over time, like the Dogecoin millionaire.
When risk b*tch slaps you, humility follows, as it did for me when I lost money.
You have to lose money to make money. Few understand.
Dogecoin's omissions
You might be thinking Dogecoin is crap.
I'll take a contrarian stance. Dogecoin does nothing, but it has a strong community. Dogecoin dominates internet memes.
It's silly.
Not quite. The message of crypto that many people forget is that it’s a change in business model.
Businesses create products and services, then advertise to find customers. Crypto Web3 works backwards. A company builds a fanbase but sells them nothing.
Once the community reaches MVC (minimum viable community), a business can be formed.
Community members are relational versus transactional. They're invested in a cause and care about it (typically ownership in the business via crypto).
In this new world, Dogecoin has the most important feature.
Summary
While Dogecoin does have a community I still dislike it.
It's all shady. Anything Elon Musk recommends is a bad investment (except SpaceX & Tesla are great companies).
Dogecoin Millionaire has wised up and isn't YOLOing into more dog memes.
Don't follow the crowd or the hype. Investing is a long-term sport based on fundamentals and research.
Since Ethereum's inception, I've spent 10,000 hours researching.
Dogecoin will be the foundation of something new, like Pets.com at the start of the dot-com revolution. But I doubt Doge will boom.
Be safe!
You might also like

Sad NoCoiner
3 years ago
Two Key Money Principles You Should Understand But Were Never Taught

Prudence is advised. Be debt-free. Be frugal. Spend less.
This advice sounds nice, but it rarely works.
Most people never learn these two money rules. Both approaches will impact how you see personal finance.
It may safeguard you from inflation or the inability to preserve money.
Let’s dive in.
#1: Making long-term debt your ally
High-interest debt hurts consumers. Many credit cards carry 25% yearly interest (or more), so always pay on time. Otherwise, you’re losing money.
Some low-interest debt is good. Especially when buying an appreciating asset with borrowed money.
Inflation helps you.
If you borrow $800,000 at 3% interest and invest it at 7%, you'll make $32,000 (4%).
As money loses value, fixed payments get cheaper. Your assets' value and cash flow rise.
The never-in-debt crowd doesn't know this. They lose money paying off mortgages and low-interest loans early when they could have bought assets instead.
#2: How To Buy Or Build Assets To Make Inflation Irrelevant
Dozens of studies demonstrate actual wage growth is static; $2.50 in 1964 was equivalent to $22.65 now.
These reports never give solutions unless they're selling gold.
But there is one.
Assets beat inflation.
$100 invested into the S&P 500 would have an inflation-adjusted return of 17,739.30%.
Likewise, you can build assets from nothing. Doing is easy and quick. The returns can boost your income by 10% or more.
The people who obsess over inflation inadvertently make the problem worse for themselves. They wait for The Big Crash to buy assets. Or they moan about debt clocks and spending bills instead of seeking a solution.
Conclusion
Being ultra-prudent is like playing golf with a putter to avoid hitting the ball into the water. Sure, you might not slice a drive into the pond. But, you aren’t going to play well either. Or have very much fun.
Money has rules.
Avoiding debt or investment risks will limit your rewards. Long-term, being too cautious hurts your finances.
Disclaimer: This article is for entertainment purposes only. It is not financial advice, always do your own research.

nft now
3 years ago
A Guide to VeeFriends and Series 2
VeeFriends is one of the most popular and unique NFT collections. VeeFriends launched around the same time as other PFP NFTs like Bored Ape Yacht Club.
Vaynerchuk (GaryVee) took a unique approach to his large-scale project, which has influenced the NFT ecosystem. GaryVee's VeeFriends is one of the most successful NFT membership use-cases, allowing him to build a community around his creative and business passions.
What is VeeFriends?
GaryVee's NFT collection, VeeFriends, was released on May 11, 2021. VeeFriends [Mini Drops], Book Games, and a forthcoming large-scale "Series 2" collection all stem from the initial drop of 10,255 tokens.
In "Series 1," there are G.O.O. tokens (Gary Originally Owned). GaryVee reserved 1,242 NFTs (over 12% of the supply) for his own collection, so only 9,013 were available at the Series 1 launch.
Each Series 1 token represents one of 268 human traits hand-drawn by Vaynerchuk. Gary Vee's NFTs offer owners incentives.
Who made VeeFriends?
Gary Vaynerchuk, AKA GaryVee, is influential in NFT. Vaynerchuk is the chairman of New York-based communications company VaynerX. Gary Vee, CEO of VaynerMedia, VaynerSports, and bestselling author, is worth $200 million.
GaryVee went from NFT collector to creator, launching VaynerNFT to help celebrities and brands.
Vaynerchuk's influence spans the NFT ecosystem as one of its most prolific voices. He's one of the most influential NFT figures, and his VeeFriends ecosystem keeps growing.
Vaynerchuk, a trend expert, thinks NFTs will be around for the rest of his life and VeeFriends will be a landmark project.
Why use VeeFriends NFTs?
The first VeeFriends collection has sold nearly $160 million via OpenSea. GaryVee insisted that the first 10,255 VeeFriends were just the beginning.
Book Games were announced to the VeeFriends community in August 2021. Mini Drops joined VeeFriends two months later.
Book Games
GaryVee's book "Twelve and a Half: Leveraging the Emotional Ingredients for Business Success" inspired Book Games. Even prior to the announcement Vaynerchuk had mapped out the utility of the book on an NFT scale. Book Games tied his book to the VeeFriends ecosystem and solidified its place in the collection.
GaryVee says Book Games is a layer 2 NFT project with 125,000 burnable tokens. Vaynerchuk's NFT fans were incentivized to buy as many copies of his new book as possible to receive NFT rewards later.
First, a bit about “layer 2.”
Layer 2 blockchain solutions help scale applications by routing transactions away from Ethereum Mainnet (layer 1). These solutions benefit from Mainnet's decentralized security model but increase transaction speed and reduce gas fees.
Polygon (integrated into OpenSea) and Immutable X are popular Ethereum layer 2 solutions. GaryVee chose Immutable X to reduce gas costs (transaction fees). Given the large supply of Book Games tokens, this decision will likely benefit the VeeFriends community, especially if the games run forever.
What's the strategy?
The VeeFriends patriarch announced on Aug. 27, 2021, that for every 12 books ordered during the Book Games promotion, customers would receive one NFT via airdrop. After nearly 100 days, GV sold over a million copies and announced that Book Games would go gamified on Jan. 10, 2022.
Immutable X's trading options make Book Games a "game." Book Games players can trade NFTs for other NFTs, sports cards, VeeCon tickets, and other prizes. Book Games can also whitelist other VeeFirends projects, which we'll cover in Series 2.
VeeFriends Mini Drops
GaryVee launched VeeFriends Mini Drops two months after Book Games, focusing on collaboration, scarcity, and the characters' "cultural longevity."
Spooky Vees, a collection of 31 1/1 Halloween-themed VeeFriends, was released on Halloween. First-come, first-served VeeFriend owners could claim these NFTs.
Mini Drops includes Gift Goat NFTs. By holding the Gift Goat VeeFriends character, collectors will receive 18 exclusive gifts curated by GaryVee and the team. Each gifting experience includes one physical gift and one NFT out of 555, to match the 555 Gift Goat tokens.
Gift Goat holders have gotten NFTs from Danny Cole (Creature World), Isaac "Drift" Wright (Where My Vans Go), Pop Wonder, and more.
GaryVee is poised to release the largest expansion of the VeeFriends and VaynerNFT ecosystem to date with VeeFriends Series 2.
VeeCon 101
By owning VeeFriends NFTs, collectors can join the VeeFriends community and attend VeeCon in 2022. The conference is only open to VeeCon NFT ticket holders (VeeFreinds + possibly more TBA) and will feature Beeple, Steve Aoki, and even Snoop Dogg.
The VeeFreinds floor in 2022 Q1 has remained at 16 ETH ($52,000), making VeeCon unattainable for most NFT enthusiasts. Why would someone spend that much crypto on a Minneapolis "superconference" ticket? Because of Gary Vaynerchuk.
Everything to know about VeeFriends Series 2
Vaynerchuk revealed in April 2022 that the VeeFriends ecosystem will grow by 55,555 NFTs after months of teasing.
With VeeFriends Series 2, each token will cost $995 USD in ETH, allowing NFT enthusiasts to join at a lower cost. The new series will be released on multiple dates in April.
Book Games NFT holders on the Friends List (whitelist) can mint Series 2 NFTs on April 12. Book Games holders have 32,000 NFTs.
VeeFriends Series 1 NFT holders can claim Series 2 NFTs on April 12. This allotment's supply is 10,255, like Series 1's.
On April 25, the public can buy 10,000 Series 2 NFTs. Unminted Friends List NFTs will be sold on this date, so this number may change.
The VeeFriends ecosystem will add 15 new characters (220 tokens each) on April 27. One character will be released per day for 15 days, and the only way to get one is to enter a daily raffle with Book Games tokens.
Series 2 NFTs won't give owners VeeCon access, but they will offer other benefits within the VaynerNFT ecosystem. Book Games and Series 2 will get new token burn mechanics in the upcoming drop.
Visit the VeeFriends blog for the latest collection info.
Where can you buy Gary Vee’s NFTs?
Need a VeeFriend NFT? Gary Vee recommends doing "50 hours of homework" before buying. OpenSea sells VeeFriends NFTs.

Darshak Rana
3 years ago
17 Google Secrets 99 Percent of People Don't Know
What can't Google do?
Seriously, nothing! Google rocks.
Google is a major player in online tools and services. We use it for everything, from research to entertainment.
Did I say entertain yourself?
Yes, with so many features and options, it can be difficult to fully utilize Google.
#1. Drive Google Mad
You can make Google's homepage dance if you want to be silly.
Just type “Google Gravity” into Google.com. Then select I'm lucky.
See the page unstick before your eyes!
#2 Play With Google Image
Google isn't just for work.
Then have fun with it!
You can play games right in your search results. When you need a break, google “Solitaire” or “Tic Tac Toe”.
#3. Do a Barrel Roll
Need a little more excitement in your life? Want to see Google dance?
Type “Do a barrel roll” into the Google search bar.
Then relax and watch your screen do a 360.
#4 No Internet? No issue!
This is a fun trick to use when you have no internet.
If your browser shows a “No Internet” page, simply press Space.
Boom!
We have dinosaurs! Now use arrow keys to save your pixelated T-Rex from extinction.
#5 Google Can Help
Play this Google coin flip game to see if you're lucky.
Enter “Flip a coin” into the search engine.
You'll see a coin flipping animation. If you get heads or tails, click it.
#6. Think with Google
My favorite Google find so far is the “Think with Google” website.
Think with Google is a website that offers marketing insights, research, and case studies.
I highly recommend it to entrepreneurs, small business owners, and anyone interested in online marketing.
#7. Google Can Read Images!
This is a cool Google trick that few know about.
You can search for images by keyword or upload your own by clicking the camera icon on Google Images.
Google will then show you all of its similar images.
Caution: You should be fine with your uploaded images being public.
#8. Modify the Google Logo!
Clicking on the “I'm Feeling Lucky” button on Google.com takes you to a random Google Doodle.
Each year, Google creates a Doodle to commemorate holidays, anniversaries, and other occasions.
#9. What is my IP?
Simply type “What is my IP” into Google to find out.
Your IP address will appear on the results page.
#10. Send a Self-Destructing Email With Gmail,
Create a new message in Gmail. Find an icon that resembles a lock and a clock near the SEND button. That's where the Confidential Mode is.
By clicking it, you can set an expiration date for your email. Expiring emails are automatically deleted from both your and the recipient's inbox.
#11. Blink, Google Blink!
This is a unique Google trick.
Type “blink HTML” into Google. The words “blink HTML” will appear and then disappear.
The text is displayed for a split second before being deleted.
To make this work, Google reads the HTML code and executes the “blink” command.
#12. The Answer To Everything
This is for all Douglas Adams fans.
The answer to life, the universe, and everything is 42, according to Google.
An allusion to Douglas Adams' Hitchhiker's Guide to the Galaxy, in which Ford Prefect seeks to understand life, the universe, and everything.
#13. Google in 1998
It's a blast!
Type “Google in 1998” into Google. "I'm feeling lucky"
You'll be taken to an old-school Google homepage.
It's a nostalgic trip for long-time Google users.
#14. Scholarships and Internships
Google can help you find college funding!
Type “scholarships” or “internships” into Google.
The number of results will surprise you.
#15. OK, Google. Dice!
To roll a die, simply type “Roll a die” into Google.
On the results page is a virtual dice that you can click to roll.
#16. Google has secret codes!
Hit the nine squares on the right side of your Google homepage to go to My Account. Then Personal Info.
You can add your favorite language to the “General preferences for the web” tab.
#17. Google Terminal
You can feel like a true hacker.
Just type “Google Terminal” into Google.com. "I'm feeling lucky"
Voila~!
You'll be taken to an old-school computer terminal-style page.
You can then type commands to see what happens.
Have you tried any of these activities? Tell me in the comments.
Read full article here