



More on Science

Jack Burns
3 years ago
Here's what to expect from NASA Artemis 1 and why it's significant.
NASA's Artemis 1 mission will help return people to the Moon after a half-century break. The mission is a shakedown cruise for NASA's Space Launch System and Orion Crew Capsule.
The spaceship will visit the Moon, deploy satellites, and enter orbit. NASA wants to practice operating the spacecraft, test the conditions people will face on the Moon, and ensure a safe return to Earth.
We asked Jack Burns, a space scientist at the University of Colorado Boulder and former member of NASA's Presidential Transition Team, to describe the mission, explain what the Artemis program promises for space exploration, and reflect on how the space program has changed in the half-century since humans last set foot on the moon.
What distinguishes Artemis 1 from other rockets?
Artemis 1 is the Space Launch System's first launch. NASA calls this a "heavy-lift" vehicle. It will be more powerful than Apollo's Saturn V, which transported people to the Moon in the 1960s and 1970s.
It's a new sort of rocket system with two strap-on solid rocket boosters from the space shuttle. It's a mix of the shuttle and Saturn V.
The Orion Crew Capsule will be tested extensively. It'll spend a month in the high-radiation Moon environment. It will also test the heat shield, which protects the capsule and its occupants at 25,000 mph. The heat shield must work well because this is the fastest capsule descent since Apollo.
This mission will also carry miniature Moon-orbiting satellites. These will undertake vital precursor science, including as examining further into permanently shadowed craters where scientists suspect there is water and measuring the radiation environment to see long-term human consequences.
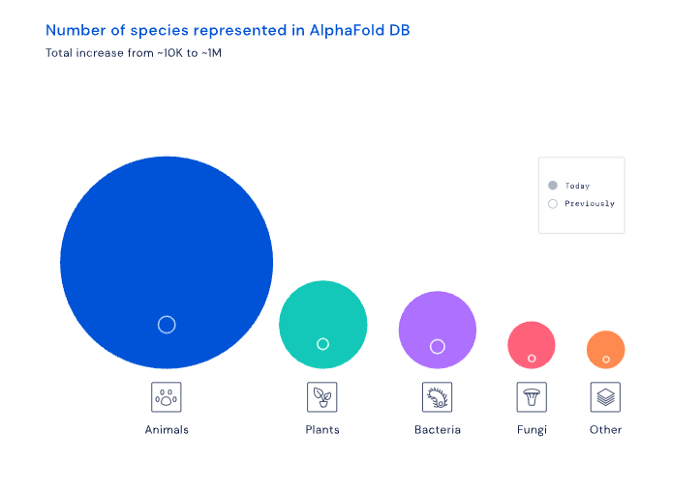
Artemis 1 will launch, fly to the Moon, place satellites, orbit it, return to Earth, and splash down in the ocean. NASA.
What's Artemis's goal? What launches are next?
The mission is a first step toward Artemis 3, which will lead to the first human Moon missions since 1972. Artemis 1 is unmanned.
Artemis 2 will have astronauts a few years later. Like Apollo 8, it will be an orbital mission that circles the Moon and returns. The astronauts will orbit the Moon longer and test everything with a crew.
Eventually, Artemis 3 will meet with the SpaceX Starship on the Moon's surface and transfer people. Orion will stay in orbit while the lunar Starship lands astronauts. They'll go to the Moon's south pole to investigate the water ice there.
Artemis is reminiscent of Apollo. What's changed in 50 years?
Kennedy wanted to beat the Soviets to the Moon with Apollo. The administration didn't care much about space flight or the Moon, but the goal would place America first in space and technology.
You live and die by the sword if you do that. When the U.S. reached the Moon, it was over. Russia lost. We planted flags and did science experiments. Richard Nixon canceled the program after Apollo 11 because the political goals were attained.
Large rocket with two boosters between two gates

NASA's new Space Launch System is brought to a launchpad. NASA
50 years later... It's quite different. We're not trying to beat the Russians, Chinese, or anyone else, but to begin sustainable space exploration.
Artemis has many goals. It includes harnessing in-situ resources like water ice and lunar soil to make food, fuel, and building materials.
SpaceX is part of this first journey to the Moon's surface, therefore the initiative is also helping to develop a lunar and space economy. NASA doesn't own the Starship but is buying seats for astronauts. SpaceX will employ Starship to transport cargo, private astronauts, and foreign astronauts.
Fifty years of technology advancement has made getting to the Moon cheaper and more practical, and computer technology allows for more advanced tests. 50 years of technological progress have changed everything. Anyone with enough money can send a spacecraft to the Moon, but not humans.
Commercial Lunar Payload Services engages commercial companies to develop uncrewed Moon landers. We're sending a radio telescope to the Moon in January. Even 10 years ago, that was impossible.
Since humans last visited the Moon 50 years ago, technology has improved greatly.
What other changes does Artemis have in store?
The government says Artemis 3 will have at least one woman and likely a person of color.
I'm looking forward to seeing more diversity so young kids can say, "Hey, there's an astronaut that looks like me. I can do this. I can be part of the space program.”

Katherine Kornei
3 years ago
The InSight lander from NASA has recorded the greatest tremor ever felt on Mars.
The magnitude 5 earthquake was responsible for the discharge of energy that was 10 times greater than the previous record holder.
Any Martians who happen to be reading this should quickly learn how to duck and cover.
NASA's Jet Propulsion Laboratory in Pasadena, California, reported that on May 4, the planet Mars was shaken by an earthquake of around magnitude 5, making it the greatest Marsquake ever detected to this point. The shaking persisted for more than six hours and unleashed more than ten times as much energy as the earthquake that had previously held the record for strongest.
The event was captured on record by the InSight lander, which is operated by the United States Space Agency and has been researching the innards of Mars ever since it touched down on the planet in 2018 (SN: 11/26/18). The epicenter of the earthquake was probably located in the vicinity of Cerberus Fossae, which is located more than 1,000 kilometers away from the lander.
The surface of Cerberus Fossae is notorious for being broken up and experiencing periodic rockfalls. According to geophysicist Philippe Lognonné, who is the lead investigator of the Seismic Experiment for Interior Structure, the seismometer that is onboard the InSight lander, it is reasonable to assume that the ground is moving in that area. "This is an old crater from a volcanic eruption."
Marsquakes, which are similar to earthquakes in that they give information about the interior structure of our planet, can be utilized to investigate what lies beneath the surface of Mars (SN: 7/22/21). And according to Lognonné, who works at the Institut de Physique du Globe in Paris, there is a great deal that can be gleaned from analyzing this massive earthquake. Because the quality of the signal is so high, we will be able to focus on the specifics.
Jamie Ducharme
3 years ago
How monkeypox spreads (and doesn't spread)
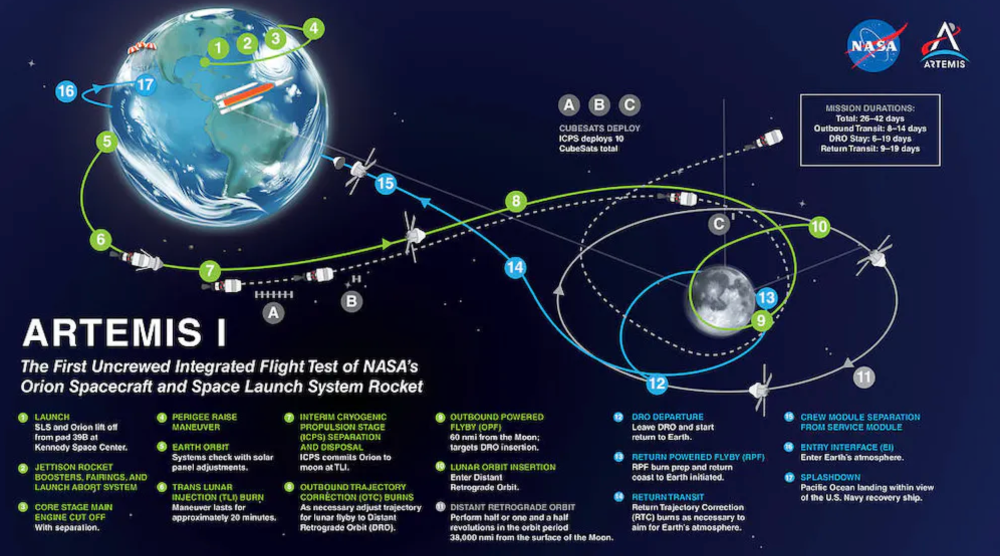
Monkeypox was rare until recently. In 2005, a research called a cluster of six monkeypox cases in the Republic of Congo "the longest reported chain to date."
That's changed. This year, over 25,000 monkeypox cases have been reported in 83 countries, indicating widespread human-to-human transmission.
What spreads monkeypox? Monkeypox transmission research is ongoing; findings may change. But science says...
Most cases were formerly animal-related.
According to the WHO, monkeypox was first diagnosed in an infant in the DRC in 1970. After that, instances were infrequent and often tied to animals. In 2003, 47 Americans contracted rabies from pet prairie dogs.
In 2017, Nigeria saw a significant outbreak. NPR reported that doctors diagnosed young guys without animal exposure who had genital sores. Nigerian researchers highlighted the idea of sexual transmission in a 2019 study, but the theory didn't catch on. “People tend to cling on to tradition, and the idea is that monkeypox is transmitted from animals to humans,” explains research co-author Dr. Dimie Ogoina.
Most monkeypox cases are sex-related.
Human-to-human transmission of monkeypox occurs, and sexual activity plays a role.
Joseph Osmundson, a clinical assistant professor of biology at NYU, says most transmission occurs in queer and gay sexual networks through sexual or personal contact.
Monkeypox spreads by skin-to-skin contact, especially with its blister-like rash, explains Ogoina. Researchers are exploring whether people can be asymptomatically contagious, but they are infectious until their rash heals and fresh skin forms, according to the CDC.
A July research in the New England Journal of Medicine reported that of more than 500 monkeypox cases in 16 countries as of June, 95% were linked to sexual activity and 98% were among males who have sex with men. WHO Director-General Tedros Adhanom Ghebreyesus encouraged males to temporarily restrict their number of male partners in July.
Is monkeypox a sexually transmitted infection (STI)?
Skin-to-skin contact can spread monkeypox, not simply sexual activities. Dr. Roy Gulick, infectious disease chief at Weill Cornell Medicine and NewYork-Presbyterian, said monkeypox is not a "typical" STI. Monkeypox isn't a STI, claims the CDC.
Most cases in the current outbreak are tied to male sexual behavior, but Osmundson thinks the virus might also spread on sports teams, in spas, or in college dorms.
Can you get monkeypox from surfaces?
Monkeypox can be spread by touching infected clothing or bedding. According to a study, a U.K. health care worker caught monkeypox in 2018 after handling ill patient's bedding.
Angela Rasmussen, a virologist at the University of Saskatchewan in Canada, believes "incidental" contact seldom distributes the virus. “You need enough virus exposure to get infected,” she says. It's conceivable after sharing a bed or towel with an infectious person, but less likely after touching a doorknob, she says.
Dr. Müge evik, a clinical lecturer in infectious diseases at the University of St. Andrews in Scotland, says there is a "spectrum" of risk connected with monkeypox. "Every exposure isn't equal," she explains. "People must know where to be cautious. Reducing [sexual] partners may be more useful than cleaning coffee shop seats.
Is monkeypox airborne?
Exposure to an infectious person's respiratory fluids can cause monkeypox, but the WHO says it needs close, continuous face-to-face contact. CDC researchers are still examining how often this happens.
Under precise laboratory conditions, scientists have shown that monkeypox can spread via aerosols, or tiny airborne particles. But there's no clear evidence that this is happening in the real world, Rasmussen adds. “This is expanding predominantly in communities of males who have sex with men, which suggests skin-to-skin contact,” she explains. If airborne transmission were frequent, she argues, we'd find more occurrences in other demographics.
In the shadow of COVID-19, people are worried about aerosolized monkeypox. Rasmussen believes the epidemiology is different. Different viruses.
Can kids get monkeypox?
More than 80 youngsters have contracted the virus thus far, mainly through household transmission. CDC says pregnant women can spread the illness to their fetus.
Among the 1970s, monkeypox predominantly affected children, but by the 2010s, it was more common in adults, according to a February study. The study's authors say routine smallpox immunization (which protects against monkeypox) halted when smallpox was eradicated. Only toddlers were born after smallpox vaccination halted decades ago. More people are vulnerable now.
Schools and daycares could become monkeypox hotspots, according to pediatric instances. Ogoina adds this hasn't happened in Nigeria's outbreaks, which is encouraging. He says, "I'm not sure if we should worry." We must be careful and seek evidence.
You might also like

Jayden Levitt
3 years ago
Billionaire who was disgraced lost his wealth more quickly than anyone in history
If you're not genuine, you'll be revealed.

Sam Bankman-Fried (SBF) was called the Cryptocurrency Warren Buffet.
No wonder.
SBF's trading expertise, Blockchain knowledge, and ability to construct FTX attracted mainstream investors.
He had a fantastic worldview, donating much of his riches to charity.
As the onion layers peel back, it's clear he wasn't the altruistic media figure he portrayed.
SBF's mistakes were disastrous.
Customer deposits were traded and borrowed by him.
With ten other employees, he shared a $40 million mansion where they all had polyamorous relationships.
Tone-deaf and wasteful marketing expenditures, such as the $200 million spent to change the name of the Miami Heat stadium to the FTX Arena
Democrats received a $40 million campaign gift.
And now there seems to be no regret.
FTX was a 32-billion-dollar cryptocurrency exchange.
It went bankrupt practically overnight.
SBF, FTX's creator, exploited client funds to leverage trade.
FTX had $1 billion in customer withdrawal reserves against $9 billion in liabilities in sister business Alameda Research.
Bloomberg Billionaire Index says it's the largest and fastest net worth loss in history.
It gets worse.
SBF's net worth is $900 Million, however he must still finalize FTX's bankruptcy.
SBF's arrest in the Bahamas and SEC inquiry followed news that his cryptocurrency exchange had crashed, losing billions in customer deposits.
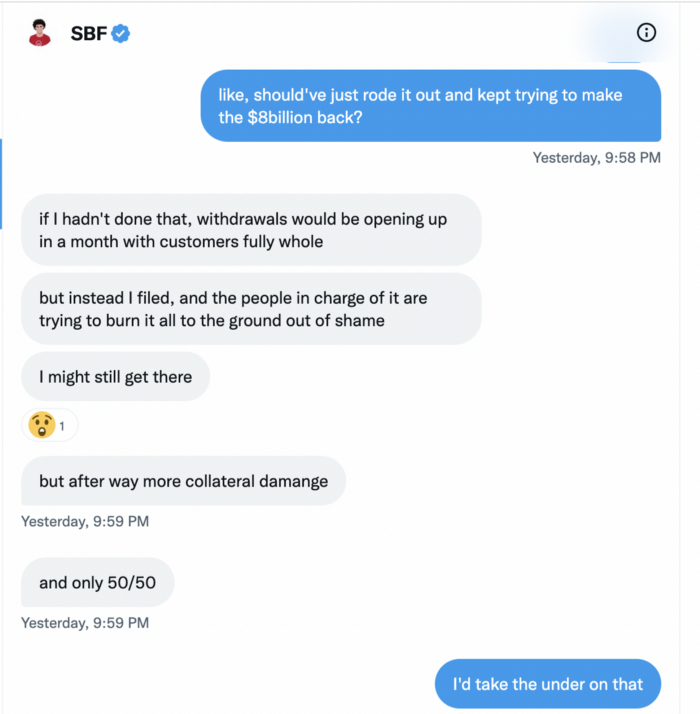
A journalist contacted him on Twitter D.M., and their exchange is telling.
His ideas are revealed.
Kelsey Piper says they didn't expect him to answer because people under investigation don't comment.
Bankman-Fried wanted to communicate, and the interaction shows he has little remorse.
SBF talks honestly about FTX gaming customers' money and insults his competition.
Reporter Kelsey Piper was outraged by what he said and felt the mistakes SBF says plague him didn't evident in the messages.
Before FTX's crash, SBF was a poster child for Cryptocurrency regulation and avoided criticizing U.S. regulators.
He tells Piper that his lobbying is just excellent PR.
It shows his genuine views and supports cynics' opinions that his attempts to win over U.S. authorities were good for his image rather than Crypto.
SBF’s responses are in Grey, and Pipers are in Blue.
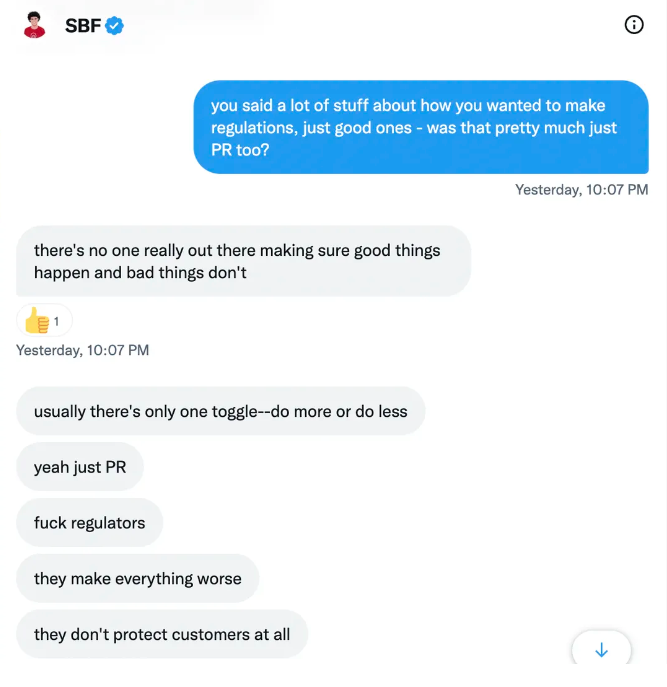
It's unclear if SBF cut corners for his gain. In their Twitter exchange, Piper revisits an interview question about ethics.
SBF says, "All the foolish sh*t I said"
SBF claims FTX has never invested customer monies.
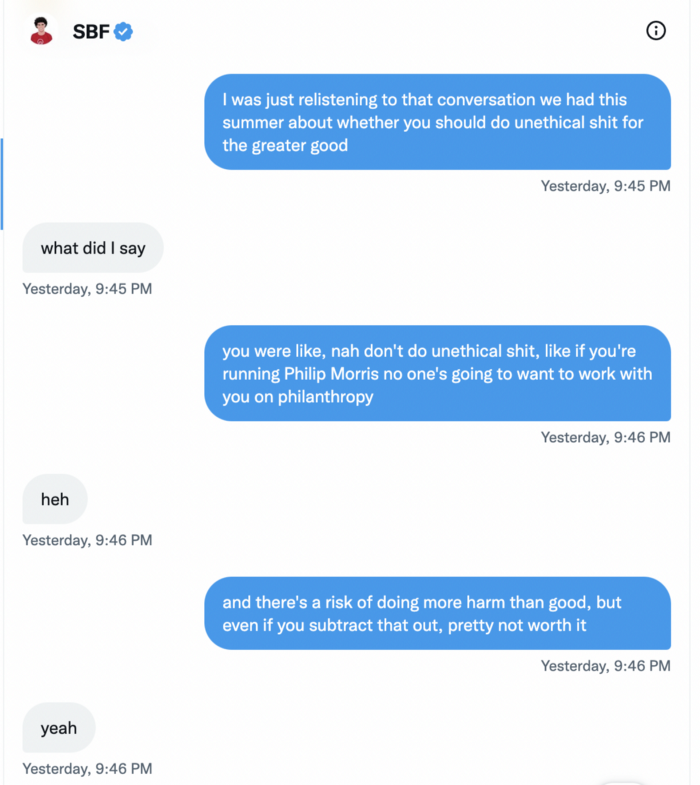
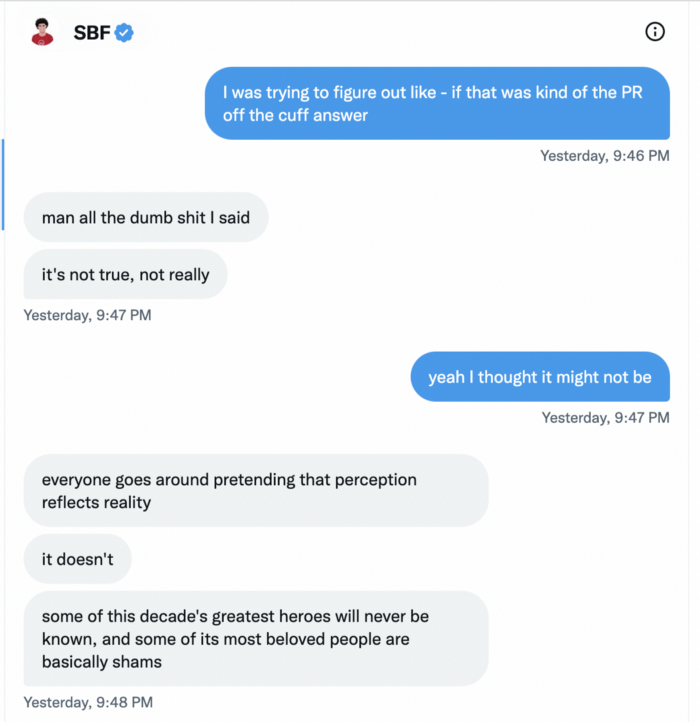
Piper challenged him on Twitter.
While he insisted FTX didn't use customer deposits, he said sibling business Alameda borrowed too much from FTX's balance sheet.
He did, basically.
When consumers tried to withdraw money, FTX was short.
SBF thought Alameda had enough money to cover FTX customers' withdrawals, but life sneaks up on you.
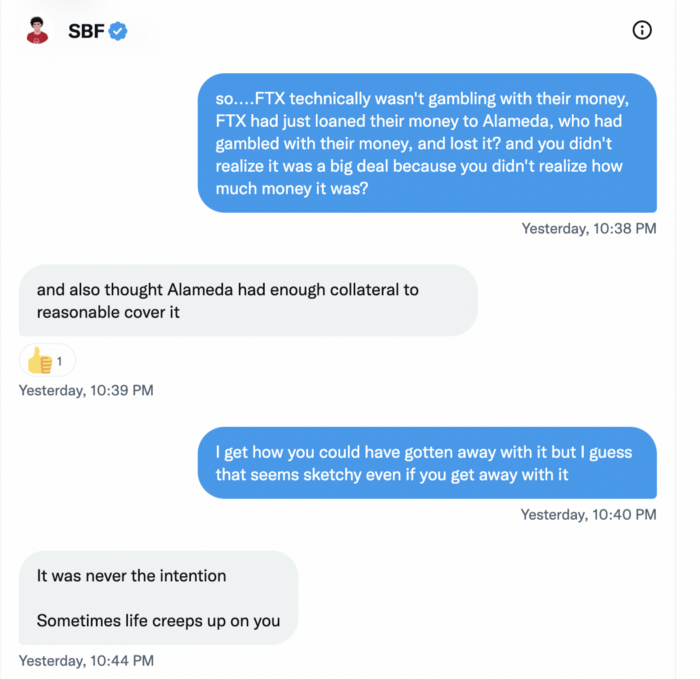
SBF believes most exchanges have done something similar to FTX, but they haven't had a bank run (a bunch of people all wanting to get their deposits out at the same time).
SBF believes he shouldn't have consented to the bankruptcy and kept attempting to raise more money because withdrawals would be open in a month with clients whole.
If additional money came in, he needed $8 billion to bridge the creditors' deficit, and there aren't many corporations with $8 billion to spare.
Once clients feel protected, they will continue to leave their assets on the exchange, according to one idea.
Kevin OLeary, a world-renowned hedge fund manager, says not all investors will walk through the open gate once the company is safe, therefore the $8 Billion wasn't needed immediately.
SBF claims the bankruptcy was his biggest error because he could have accumulated more capital.
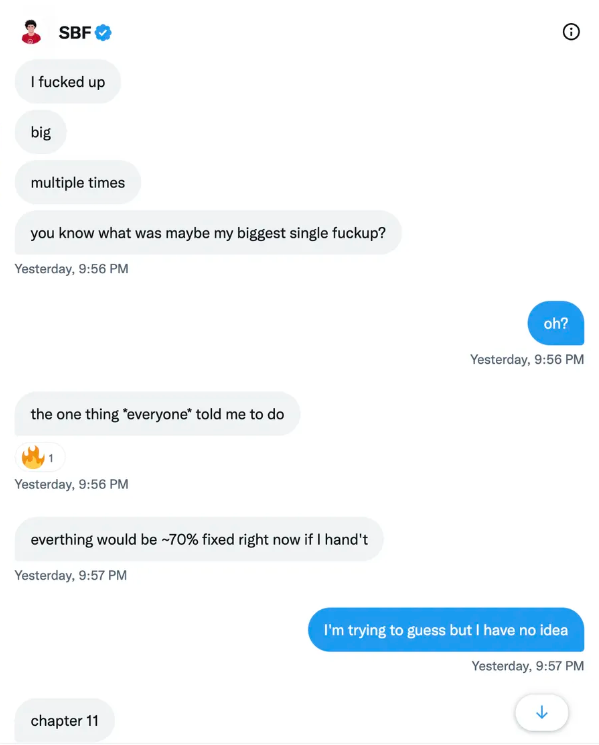
Final Reflections
Sam Bankman-Fried, 30, became the world's youngest billionaire in four years.
Never listen to what people say about investing; watch what they do.
SBF is a trader who gets wrecked occasionally.
Ten first-time entrepreneurs ran FTX, screwing each other with no risk management.
It prevents opposing or challenging perspectives and echo chamber highs.
Twitter D.M. conversation with a journalist is the final nail.
He lacks an experienced crew.
This event will surely speed up much-needed regulation.
It's also prompted cryptocurrency exchanges to offer proof of reserves to calm customers.

Ryan Weeks
3 years ago
Terra fiasco raises TRON's stablecoin backstop
After Terra's algorithmic stablecoin collapsed in May, TRON announced a plan to increase the capital backing its own stablecoin.
USDD, a near-carbon copy of Terra's UST, arrived on the TRON blockchain on May 5. TRON founder Justin Sun says USDD will be overcollateralized after initially being pegged algorithmically to the US dollar.
A reserve of cryptocurrencies and stablecoins will be kept at 130 percent of total USDD issuance, he said. TRON described the collateral ratio as "guaranteed" and said it would begin publishing real-time updates on June 5.
Currently, the reserve contains 14,040 bitcoin (around $418 million), 140 million USDT, 1.9 billion TRX, and 8.29 billion TRX in a burning contract.
Sun: "We want to hybridize USDD." We have an algorithmic stablecoin and TRON DAO Reserve.
algorithmic failure
USDD was designed to incentivize arbitrageurs to keep its price pegged to the US dollar by trading TRX, TRON's token, and USDD. Like Terra, TRON signaled its intent to establish a bitcoin and cryptocurrency reserve to support USDD in extreme market conditions.
Still, Terra's UST failed despite these safeguards. The stablecoin veered sharply away from its dollar peg in mid-May, bringing down Terra's LUNA and wiping out $40 billion in value in days. In a frantic attempt to restore the peg, billions of dollars in bitcoin were sold and unprecedented volumes of LUNA were issued.
Sun believes USDD, which has a total circulating supply of $667 million, can be backed up.
"Our reserve backing is diversified." Bitcoin and stablecoins are included. USDC will be a small part of Circle's reserve, he said.
TRON's news release lists the reserve's assets as bitcoin, TRX, USDC, USDT, TUSD, and USDJ.
All Bitcoin addresses will be signed so everyone knows they belong to us, Sun said.
Not giving in
Sun told that the crypto industry needs "decentralized" stablecoins that regulators can't touch.
Sun said the Luna Foundation Guard, a Singapore-based non-profit that raised billions in cryptocurrency to buttress UST, mismanaged the situation by trying to sell to panicked investors.
He said, "We must be ahead of the market." We want to stabilize the market and reduce volatility.
Currently, TRON finances most of its reserve directly, but Sun says the company hopes to add external capital soon.
Before its demise, UST holders could park the stablecoin in Terra's lending platform Anchor Protocol to earn 20% interest, which many deemed unsustainable. TRON's JustLend is similar. Sun hopes to raise annual interest rates from 17.67% to "around 30%."
This post is a summary. Read full article here
Isobel Asher Hamilton
3 years ago
$181 million in bitcoin buried in a dump. $11 million to get them back

James Howells lost 8,000 bitcoins. He has $11 million to get them back.
His life altered when he threw out an iPhone-sized hard drive.
Howells, from the city of Newport in southern Wales, had two identical laptop hard drives squirreled away in a drawer in 2013. One was blank; the other had 8,000 bitcoins, currently worth around $181 million.
He wanted to toss out the blank one, but the drive containing the Bitcoin went to the dump.
He's determined to reclaim his 2009 stash.
Howells, 36, wants to arrange a high-tech treasure hunt for bitcoins. He can't enter the landfill.

Newport's city council has rebuffed Howells' requests to dig for his hard drive for almost a decade, stating it would be expensive and environmentally destructive.
I got an early look at his $11 million idea to search 110,000 tons of trash. He expects submitting it to the council would convince it to let him recover the hard disk.
110,000 tons of trash, 1 hard drive
Finding a hard disk among heaps of trash may seem Herculean.
Former IT worker Howells claims it's possible with human sorters, robot dogs, and an AI-powered computer taught to find hard drives on a conveyor belt.
His idea has two versions, depending on how much of the landfill he can search.
His most elaborate solution would take three years and cost $11 million to sort 100,000 metric tons of waste. Scaled-down version costs $6 million and takes 18 months.
He's created a team of eight professionals in AI-powered sorting, landfill excavation, garbage management, and data extraction, including one who recovered Columbia's black box data.
The specialists and their companies would be paid a bonus if they successfully recovered the bitcoin stash.
Howells: "We're trying to commercialize this project."
Howells claimed rubbish would be dug up by machines and sorted near the landfill.
Human pickers and a Max-AI machine would sort it. The machine resembles a scanner on a conveyor belt.
Remi Le Grand of Max-AI told us it will train AI to recognize Howells-like hard drives. A robot arm would select candidates.
Howells has added security charges to his scheme because he fears people would steal the hard drive.
He's budgeted for 24-hour CCTV cameras and two robotic "Spot" canines from Boston Dynamics that would patrol at night and look for his hard drive by day.
Howells said his crew met in May at the Celtic Manor Resort outside Newport for a pitch rehearsal.
Richard Hammond's narrative swings from banal to epic.
Richard Hammond filmed the meeting and created a YouTube documentary on Howells.
Hammond said of Howells' squad, "They're committed and believe in him and the idea."
Hammond: "It goes from banal to gigantic." "If I were in his position, I wouldn't have the strength to answer the door."
Howells said trash would be cleaned and repurposed after excavation. Reburying the rest.
"We won't pollute," he declared. "We aim to make everything better."

After the project is finished, he hopes to develop a solar or wind farm on the dump site. The council is unlikely to accept his vision soon.
A council representative told us, "Mr. Howells can't convince us of anything." "His suggestions constitute a significant ecological danger, which we can't tolerate and are forbidden by our permit."
Will the recovered hard drive work?
The "platter" is a glass or metal disc that holds the hard drive's data. Howells estimates 80% to 90% of the data will be recoverable if the platter isn't damaged.
Phil Bridge, a data-recovery expert who consulted Howells, confirmed these numbers.

If the platter is broken, Bridge adds, data recovery is unlikely.
Bridge says he was intrigued by the proposal. "It's an intriguing case," he added. Helping him get it back and proving everyone incorrect would be a great success story.
Who'd pay?
Swiss and German venture investors Hanspeter Jaberg and Karl Wendeborn told us they would fund the project if Howells received council permission.
Jaberg: "It's a needle in a haystack and a high-risk investment."
Howells said he had no contract with potential backers but had discussed the proposal in Zoom meetings. "Until Newport City Council gives me something in writing, I can't commit," he added.
Suppose he finds the bitcoins.
Howells said he would keep 30% of the data, worth $54 million, if he could retrieve it.
A third would go to the recovery team, 30% to investors, and the remainder to local purposes, including gifting £50 ($61) in bitcoin to each of Newport's 150,000 citizens.
Howells said he opted to spend extra money on "professional firms" to help convince the council.
What if the council doesn't approve?
If Howells can't win the council's support, he'll sue, claiming its actions constitute a "illegal embargo" on the hard drive. "I've avoided that path because I didn't want to cause complications," he stated. I wanted to cooperate with Newport's council.
Howells never met with the council face-to-face. He mentioned he had a 20-minute Zoom meeting in May 2021 but thought his new business strategy would help.
He met with Jessica Morden on June 24. Morden's office confirmed meeting.
After telling the council about his proposal, he can only wait. "I've never been happier," he said. This is our most professional operation, with the best employees.
The "crypto proponent" buys bitcoin every month and sells it for cash.
Howells tries not to think about what he'd do with his part of the money if the hard disk is found functional. "Otherwise, you'll go mad," he added.
This post is a summary. Read the full article here.