


More on Web3 & Crypto

William Brucee
3 years ago
This person is probably Satoshi Nakamoto.

Who founded bitcoin is the biggest mystery in technology today, not how it works.
On October 31, 2008, Satoshi Nakamoto posted a whitepaper to a cryptography email list. Still confused by the mastermind who changed monetary history.
Journalists and bloggers have tried in vain to uncover bitcoin's creator. Some candidates self-nominated. We're still looking for the mystery's perpetrator because none of them have provided proof.
One person. I'm confident he invented bitcoin. Let's assess Satoshi Nakamoto before I reveal my pick. Or what he wants us to know.
Satoshi's P2P Foundation biography says he was born in 1975. He doesn't sound or look Japanese. First, he wrote the whitepaper and subsequent articles in flawless English. His sleeping habits are unusual for a Japanese person.
Stefan Thomas, a Bitcoin Forum member, displayed Satoshi's posting timestamps. Satoshi Nakamoto didn't publish between 2 and 8 p.m., Japanese time. Satoshi's identity may not be real.
Why would he disguise himself?
There is a legitimate explanation for this
Phil Zimmermann created PGP to give dissidents an open channel of communication, like Pretty Good Privacy. US government seized this technology after realizing its potential. Police investigate PGP and Zimmermann.
This technology let only two people speak privately. Bitcoin technology makes it possible to send money for free without a bank or other intermediary, removing it from government control.
How much do we know about the person who invented bitcoin?
Here's what we know about Satoshi Nakamoto now that I've covered my doubts about his personality.
Satoshi Nakamoto first appeared with a whitepaper on metzdowd.com. On Halloween 2008, he presented a nine-page paper on a new peer-to-peer electronic monetary system.

Using the nickname satoshi, he created the bitcointalk forum. He kept developing bitcoin and created bitcoin.org. Satoshi mined the genesis block on January 3, 2009.
Satoshi Nakamoto worked with programmers in 2010 to change bitcoin's protocol. He engaged with the bitcoin community. Then he gave Gavin Andresen the keys and codes and transferred community domains. By 2010, he'd abandoned the project.
The bitcoin creator posted his goodbye on April 23, 2011. Mike Hearn asked Satoshi if he planned to rejoin the group.
“I’ve moved on to other things. It’s in good hands with Gavin and everyone.”
Nakamoto Satoshi
The man who broke the banking system vanished. Why?

Satoshi's wallets held 1,000,000 BTC. In December 2017, when the price peaked, he had over US$19 billion. Nakamoto had the 44th-highest net worth then. He's never cashed a bitcoin.
This data suggests something happened to bitcoin's creator. I think Hal Finney is Satoshi Nakamoto .
Hal Finney had ALS and died in 2014. I suppose he created the future of money, then he died, leaving us with only rumors about his identity.
Hal Finney, who was he?
Hal Finney graduated from Caltech in 1979. Student peers voted him the smartest. He took a doctoral-level gravitational field theory course as a freshman. Finney's intelligence meets the first requirement for becoming Satoshi Nakamoto.
Students remember Finney holding an Ayn Rand book. If he'd read this, he may have developed libertarian views.
His beliefs led him to a small group of freethinking programmers. In the 1990s, he joined Cypherpunks. This action promoted the use of strong cryptography and privacy-enhancing technologies for social and political change. Finney helped them achieve a crypto-anarchist perspective as self-proclaimed privacy defenders.
Zimmermann knew Finney well.
Hal replied to a Cypherpunk message about Phil Zimmermann and PGP. He contacted Phil and became PGP Corporation's first member, retiring in 2011. Satoshi Nakamoto quit bitcoin in 2011.
Finney improved the new PGP protocol, but he had to do so secretly. He knew about Phil's PGP issues. I understand why he wanted to hide his identity while creating bitcoin.
Why did he pretend to be from Japan?
His envisioned persona was spot-on. He resided near scientist Dorian Prentice Satoshi Nakamoto. Finney could've assumed Nakamoto's identity to hide his. Temple City has 36,000 people, so what are the chances they both lived there? A cryptographic genius with the same name as Bitcoin's creator: coincidence?
Things went differently, I think.
I think Hal Finney sent himself Satoshis messages. I know it's odd. If you want to conceal your involvement, do as follows. He faked messages and transferred the first bitcoins to himself to test the transaction mechanism, so he never returned their money.
Hal Finney created the first reusable proof-of-work system. The bitcoin protocol. In the 1990s, Finney was intrigued by digital money. He invented CRypto cASH in 1993.
Legacy
Hal Finney's contributions should not be forgotten. Even if I'm wrong and he's not Satoshi Nakamoto, we shouldn't forget his bitcoin contribution. He helped us achieve a better future.

Robert Kim
4 years ago
Crypto Legislation Might Progress Beyond Talk in 2022
Financial regulators have for years attempted to apply existing laws to the multitude of issues created by digital assets. In 2021, leading federal regulators and members of Congress have begun to call for legislation to address these issues. As a result, 2022 may be the year when federal legislation finally addresses digital asset issues that have been growing since the mining of the first Bitcoin block in 2009.
Digital Asset Regulation in the Absence of Legislation
So far, Congress has left the task of addressing issues created by digital assets to regulatory agencies. Although a Congressional Blockchain Caucus formed in 2016, House and Senate members introduced few bills addressing digital assets until 2018. As of October 2021, Congress has not amended federal laws on financial regulation, which were last significantly revised by the Dodd-Frank Act in 2010, to address digital asset issues.
In the absence of legislation, issues that do not fit well into existing statutes have created problems. An example is the legal status of digital assets, which can be considered to be either securities or commodities, and can even shift from one to the other over time. Years after the SEC’s 2017 report applying the definition of a security to digital tokens, the SEC and the CFTC have yet to clarify the distinction between securities and commodities for the thousands of digital assets in existence.
SEC Chair Gary Gensler has called for Congress to act, stating in August, “We need additional Congressional authorities to prevent transactions, products, and platforms from falling between regulatory cracks.” Gensler has reached out to Sen. Elizabeth Warren (D-Ma.), who has expressed her own concerns about the need for legislation.
Legislation on Digital Assets in 2021
While regulators and members of Congress talked about the need for legislation, and the debate over cryptocurrency tax reporting in the 2021 infrastructure bill generated headlines, House and Senate bills proposing specific solutions to various issues quietly started to emerge.
Digital Token Sales
Several House bills attempt to address securities law barriers to digital token sales—some of them by building on ideas proposed by regulators in past years.
Exclusion from the definition of a security. Congressional Blockchain Caucus members have been introducing bills to exclude digital tokens from the definition of a security since 2018, and they have revived those bills in 2021. They include the Token Taxonomy Act of 2021 (H.R. 1628), successor to identically named bills in 2018 and 2019, and the Securities Clarity Act (H.R. 4451), successor to a 2020 namesake.
Safe harbor. SEC Commissioner Hester Peirce proposed a regulatory safe harbor for token sales in 2020, and two 2021 bills have proposed statutory safe harbors. Rep. Patrick McHenry (R-N.C.), Republican leader of the House Financial Services Committee, introduced a Clarity for Digital Tokens Act of 2021 (H.R. 5496) that would amend the Securities Act to create a safe harbor providing a grace period of exemption from Securities Act registration requirements. The Digital Asset Market Structure and Investor Protection Act (H.R. 4741) from Rep. Don Beyer (D-Va.) would amend the Securities Exchange Act to define a new type of security—a “digital asset security”—and add issuers of digital asset securities to an existing provision for delayed registration of securities.
Stablecoins
Stablecoins—digital currencies linked to the value of the U.S. dollar or other fiat currencies—have not yet been the subject of regulatory action, although Treasury Secretary Janet Yellen and Federal Reserve Chair Jerome Powell have each underscored the need to create a regulatory framework for them. The Beyer bill proposes to create a regulatory regime for stablecoins by amending Title 31 of the U.S. Code. Treasury Department approval would be required for any “digital asset fiat-based stablecoin” to be issued or used, under an application process to be established by Treasury in consultation with the Federal Reserve, the SEC, and the CFTC.
Serious consideration for any of these proposals in the current session of Congress may be unlikely. A spate of autumn bills on crypto ransom payments (S. 2666, S. 2923, S. 2926, H.R. 5501) shows that Congress is more inclined to pay attention first to issues that are more spectacular and less arcane. Moreover, the arcaneness of digital asset regulatory issues is likely only to increase further, now that major industry players such as Coinbase and Andreessen Horowitz are starting to roll out their own regulatory proposals.
Digital Dollar vs. Digital Yuan
Impetus to pass legislation on another type of digital asset, a central bank digital currency (CBDC), may come from a different source: rivalry with China.
China established itself as a world leader in developing a CBDC with a pilot project launched in 2020, and in 2021, the People’s Bank of China announced that its CBDC will be used at the Beijing Winter Olympics in February 2022. Republican Senators responded by calling for the U.S. Olympic Committee to forbid use of China’s CBDC by U.S. athletes in Beijing and introducing a bill (S. 2543) to require a study of its national security implications.
The Beijing Olympics could motivate a legislative mandate to accelerate implementation of a U.S. digital dollar, which the Federal Reserve has been in the process of considering in 2021. Antecedents to such legislation already exist. A House bill sponsored by 46 Republicans (H.R. 4792) has a provision that would require the Treasury Department to assess China’s CBDC project and report on the status of Federal Reserve work on a CBDC, and the Beyer bill includes a provision amending the Federal Reserve Act to authorize issuing a digital dollar.
Both parties are likely to support creating a digital dollar. The Covid-19 pandemic made a digital dollar for delivery of relief payments a popular idea in 2020, and House Democrats introduced bills with provisions for creating one in 2020 and 2021. Bipartisan support for a bill on a digital dollar, based on concerns both foreign and domestic in nature, could result.
International rivalry and bipartisan support may make the digital dollar a gateway issue for digital asset legislation in 2022. Legislative work on a digital dollar may open the door for considering further digital asset issues—including the regulatory issues that have been emerging for years—in 2022 and beyond.

forkast
3 years ago
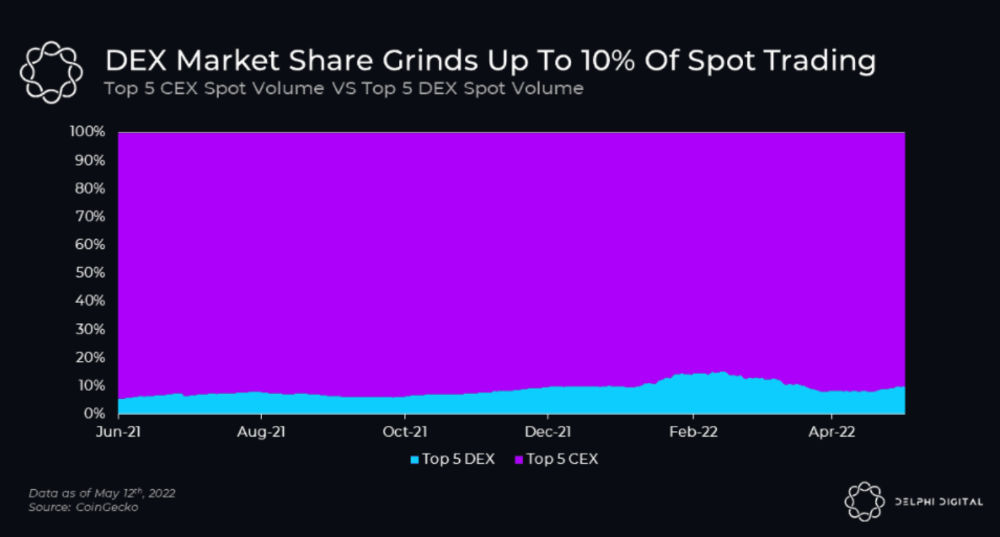
Three Arrows Capital collapse sends crypto tremors

Three Arrows Capital's Google search volume rose over 5,000%.
Three Arrows Capital, a Singapore-based cryptocurrency hedge fund, filed for Chapter 15 bankruptcy last Friday to protect its U.S. assets from creditors.
Three Arrows filed for bankruptcy on July 1 in New York.
Three Arrows was ordered liquidated by a British Virgin Islands court last week after defaulting on a $670 million loan from Voyager Digital. Three days later, the Singaporean government reprimanded Three Arrows for spreading misleading information and exceeding asset limits.
Three Arrows' troubles began with Terra's collapse in May, after it bought US$200 million worth of Terra's LUNA tokens in February, co-founder Kyle Davies told the Wall Street Journal. Three Arrows has failed to meet multiple margin calls since then, including from BlockFi and Genesis.
Three Arrows Capital, founded by Kyle Davies and Su Zhu in 2012, manages $10 billion in crypto assets.
Bitcoin's price fell from US$20,600 to below US$19,200 after Three Arrows' bankruptcy petition. According to CoinMarketCap, BTC is now above US$20,000.
What does it mean?
Every action causes an equal and opposite reaction, per Newton's third law. Newtonian physics won't comfort Three Arrows investors, but future investors will thank them for their overconfidence.
Regulators are taking notice of crypto's meteoric rise and subsequent fall. Historically, authorities labeled the industry "high risk" to warn traditional investors against entering it. That attitude is changing. Regulators are moving quickly to regulate crypto to protect investors and prevent broader asset market busts.
The EU has reached a landmark deal that will regulate crypto asset sales and crypto markets across the 27-member bloc. The U.S. is close behind with a similar ruling, and smaller markets are also looking to improve safeguards.
For many, regulation is the only way to ensure the crypto industry survives the current winter.
You might also like

Jano le Roux
3 years ago
My Top 11 Tools For Building A Modern Startup, With A Free Plan
The best free tools are probably unknown to you.
Modern startups are easy to build.
Start with free tools.
Let’s go.
Web development — Webflow
Code-free HTML, CSS, and JS.
Webflow isn't like Squarespace, Wix, or Shopify.
It's a super-fast no-code tool for professionals to construct complex, highly-responsive websites and landing pages.
Webflow can help you add animations like those on Apple's website to your own site.
I made the jump from WordPress a few years ago and it changed my life.
No damn plugins. No damn errors. No damn updates.
The best, you can get started on Webflow for free.
Data tracking — Airtable
Spreadsheet wings.
Airtable combines spreadsheet flexibility with database power without code.
Airtable is modern.
Airtable has modularity.
Scaling Airtable is simple.
Airtable, one of the most adaptable solutions on this list, is perfect for client data management.
Clients choose customized service packages. Airtable consolidates data so you can automate procedures like invoice management and focus on your strengths.
Airtable connects with so many tools that rarely creates headaches. Airtable scales when you do.
Airtable's flexibility makes it a potential backend database.
Design — Figma
Better, faster, easier user interface design.
Figma rocks!
It’s fast.
It's free.
It's adaptable
First, design in Figma.
Iterate.
Export development assets.
Figma lets you add more team members as your company grows to work on each iteration simultaneously.
Figma is web-based, so you don't need a powerful PC or Mac to start.
Task management — Trello
Unclock jobs.
Tacky and terrifying task management products abound. Trello isn’t.
Those that follow Marie Kondo will appreciate Trello.
Everything is clean.
Nothing is complicated.
Everything has a place.
Compared to other task management solutions, Trello is limited. And that’s good. Too many buttons lead to too many decisions lead to too many hours wasted.
Trello is a must for teamwork.
Domain email — Zoho
Free domain email hosting.
Professional email is essential for startups. People relied on monthly payments for too long. Nope.
Zoho offers 5 free professional emails.
It doesn't have Google's UI, but it works.
VPN — Proton VPN
Fast Swiss VPN protects your data and privacy.
Proton VPN is secure.
Proton doesn't record any data.
Proton is based in Switzerland.
Swiss privacy regulation is among the most strict in the world, therefore user data are protected. Switzerland isn't a 14 eye country.
Journalists and activists trust Proton to secure their identities while accessing and sharing information authoritarian governments don't want them to access.
Web host — Netlify
Free fast web hosting.
Netlify is a scalable platform that combines your favorite tools and APIs to develop high-performance sites, stores, and apps through GitHub.
Serverless functions and environment variables preserve API keys.
Netlify's free tier is unmissable.
100GB of free monthly bandwidth.
Free 125k serverless operations per website each month.
Database — MongoDB
Create a fast, scalable database.
MongoDB is for small and large databases. It's a fast and inexpensive database.
Free for the first million reads.
Then, for each million reads, you must pay $0.10.
MongoDB's free plan has:
Encryption from end to end
Continual authentication
field-level client-side encryption
If you have a large database, you can easily connect MongoDB to Webflow to bypass CMS limits.
Automation — Zapier
Time-saving tip: automate repetitive chores.
Zapier simplifies life.
Zapier syncs and connects your favorite apps to do impossibly awesome things.
If your online store is connected to Zapier, a customer's purchase can trigger a number of automated actions, such as:
The customer is being added to an email chain.
Put the information in your Airtable.
Send a pre-programmed postcard to the customer.
Alexa, set the color of your smart lights to purple.
Zapier scales when you do.
Email & SMS marketing — Omnisend
Email and SMS marketing campaigns.
This is an excellent Mailchimp option for magical emails. Omnisend's processes simplify email automation.
I love the interface's cleanliness.
Omnisend's free tier includes web push notifications.
Send up to:
500 emails per month
60 maximum SMSs
500 Web Push Maximum
Forms and surveys — Tally
Create flexible forms that people enjoy.
Typeform is clean but restricting. Sometimes you need to add many questions. Tally's needed sometimes.
Tally is flexible and cheaper than Typeform.
99% of Tally's features are free and unrestricted, including:
Unlimited forms
Countless submissions
Collect payments
File upload
Tally lets you examine what individuals contributed to forms before submitting them to see where they get stuck.
Airtable and Zapier connectors automate things further. If you pay, you can apply custom CSS to fit your brand.
See.
Free tools are the greatest.
Let's use them to launch a startup.

Rita McGrath
3 years ago
Flywheels and Funnels
Traditional sales organizations used the concept of a sales “funnel” to describe the process through which potential customers move, ending up with sales at the end. Winners today have abandoned that way of thinking in favor of building flywheels — business models in which every element reinforces every other.
Ah, the marketing funnel…
Prospective clients go through a predictable set of experiences, students learn in business school marketing classes. It looks like this:

Understanding the funnel helps evaluate sales success indicators. Gail Goodwin, former CEO of small business direct mail provider Constant Contact, said managing the pipeline was key to escaping the sluggish SaaS ramp of death.
Like the funnel concept. To predict how well your business will do, measure how many potential clients are aware of it (awareness) and how many take the next step. If 1,000 people heard about your offering and 10% showed interest, you'd have 100 at that point. If 50% of these people made buyer-like noises, you'd know how many were, etc. It helped model buying trends.
TV, magazine, and radio advertising are pricey for B2C enterprises. Traditional B2B marketing involved armies of sales reps, which was expensive and a barrier to entry.
Cracks in the funnel model
Digital has exposed the funnel's limitations. Hubspot was born at a time when buyers and sellers had huge knowledge asymmetries, according to co-founder Brian Halligan. Those selling a product could use the buyer's lack of information to become a trusted partner.
As the world went digital, getting information and comparing offerings became faster, easier, and cheaper. Buyers didn't need a seller to move through a funnel. Interactions replaced transactions, and the relationship didn't end with a sale.
Instead, buyers and sellers interacted in a constant flow. In many modern models, the sale is midway through the process (particularly true with subscription and software-as-a-service models). Example:
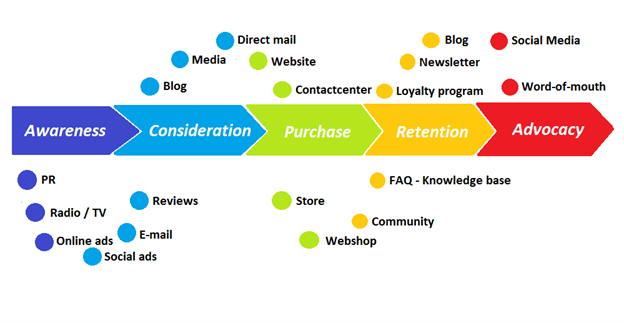
You're creating a winding journey with many touch points, not a funnel (and lots of opportunities for customers to get lost).
From winding journey to flywheel
Beyond this revised view of an interactive customer journey, a company can create what Jim Collins famously called a flywheel. Imagine rolling a heavy disc on its axis. The first few times you roll it, you put in a lot of effort for a small response. The same effort yields faster turns as it gains speed. Over time, the flywheel gains momentum and turns without your help.
Modern digital organizations have created flywheel business models, in which any additional force multiplies throughout the business. The flywheel becomes a force multiplier, according to Collins.
Amazon is a famous flywheel example. Collins explained the concept to Amazon CEO Jeff Bezos at a corporate retreat in 2001. In The Everything Store, Brad Stone describes in his book The Everything Store how he immediately understood Amazon's levers.
The result (drawn on a napkin):
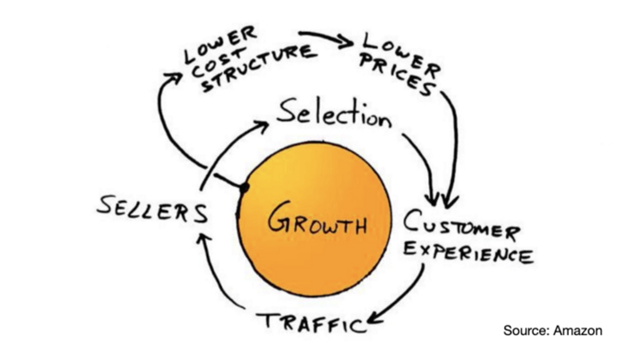
Low prices and a large selection of products attracted customers, while a focus on customer service kept them coming back, increasing traffic. Third-party sellers then increased selection. Low-cost structure supports low-price commitment. It's brilliant! Every wheel turn creates acceleration.
Where from here?
Flywheel over sales funnel! Consider these business terms.

Simone Basso
3 years ago
How I set up my teams to be successful
After 10 years of working in scale-ups, I've embraced a few concepts for scaling Tech and Product teams.
First, cross-functionalize teams. Product Managers represent the business, Product Designers the consumer, and Engineers build.
I organize teams of 5-10 individuals, following AWS's two pizza teams guidelines, with a Product Trio guiding each.
If more individuals are needed to reach a goal, I group teams under a Product Trio.
With Engineering being the biggest group, Staff/Principal Engineers often support the Trio on cross-team technical decisions.
Product Managers, Engineering Managers, or Engineers in the team may manage projects (depending on the project or aim), but the trio is collectively responsible for the team's output and outcome.
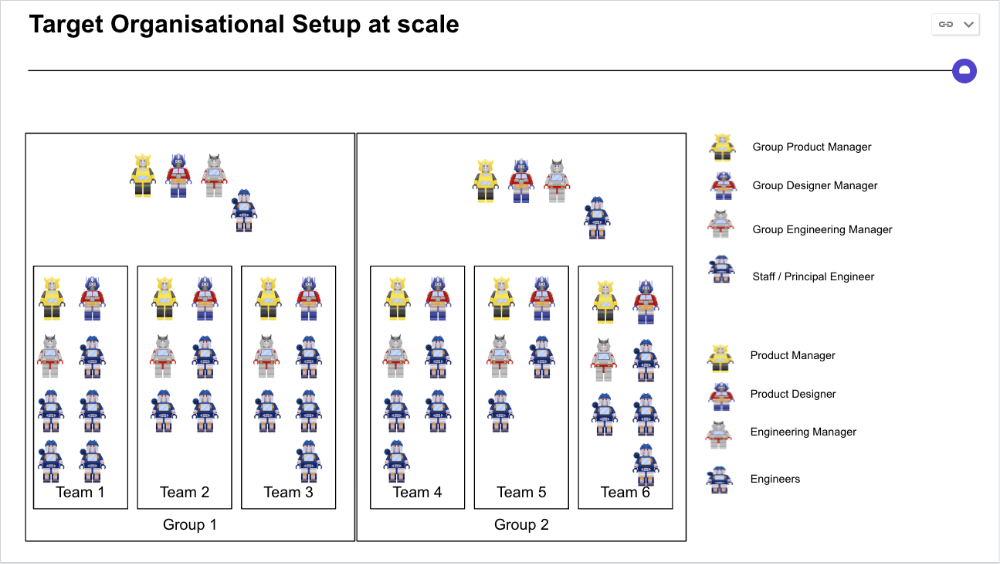
Once the Product Trio model is created, roles, duties, team ceremonies, and cooperation models must be clarified.
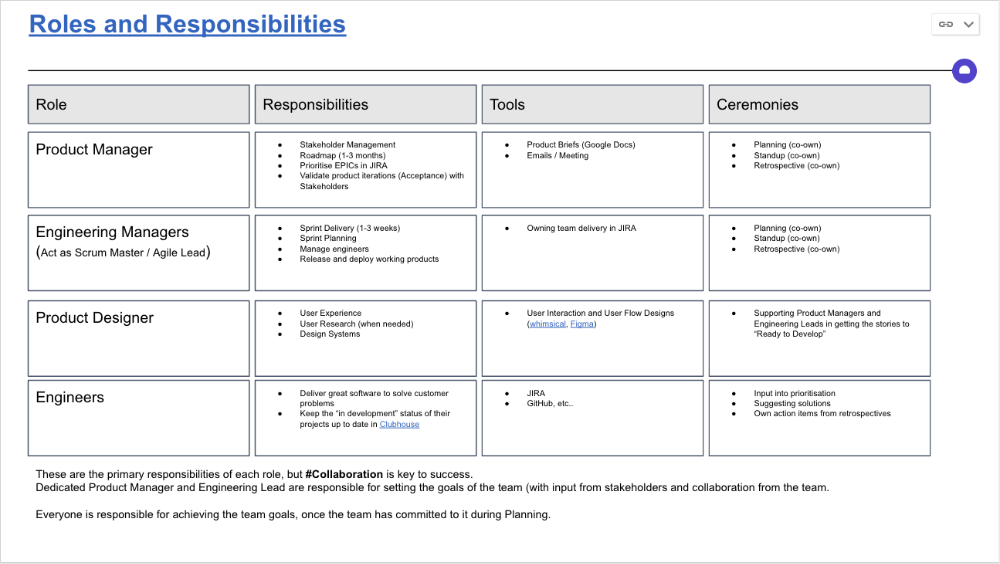
Keep reporting lines by discipline. Line managers are accountable for each individual's advancement, thus it's crucial that they know the work in detail.

Cross-team collaboration becomes more important after 3 teams (15-30 people). Teams can easily diverge in how they write code, run ceremonies, and build products.
Establishing groups of people that are cross-team, but grouped by discipline and skills, sharing and agreeing on working practices becomes critical.
The “Spotify Guild” model has been where I’ve taken a lot of my inspiration from.
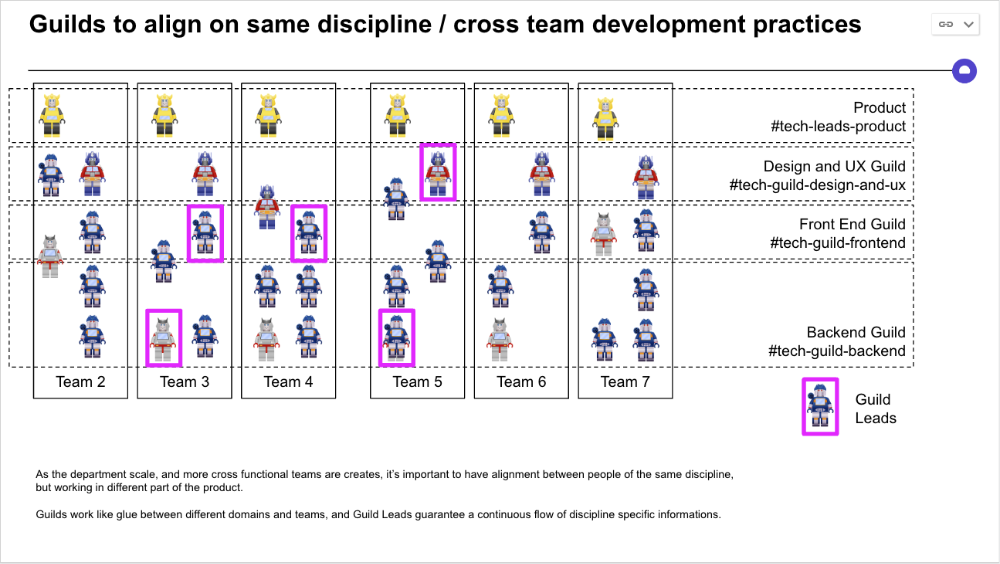
Last, establish a taxonomy for communication channels.
In Slack, I create one channel per team and one per guild (and one for me to have discussions with the team leads).
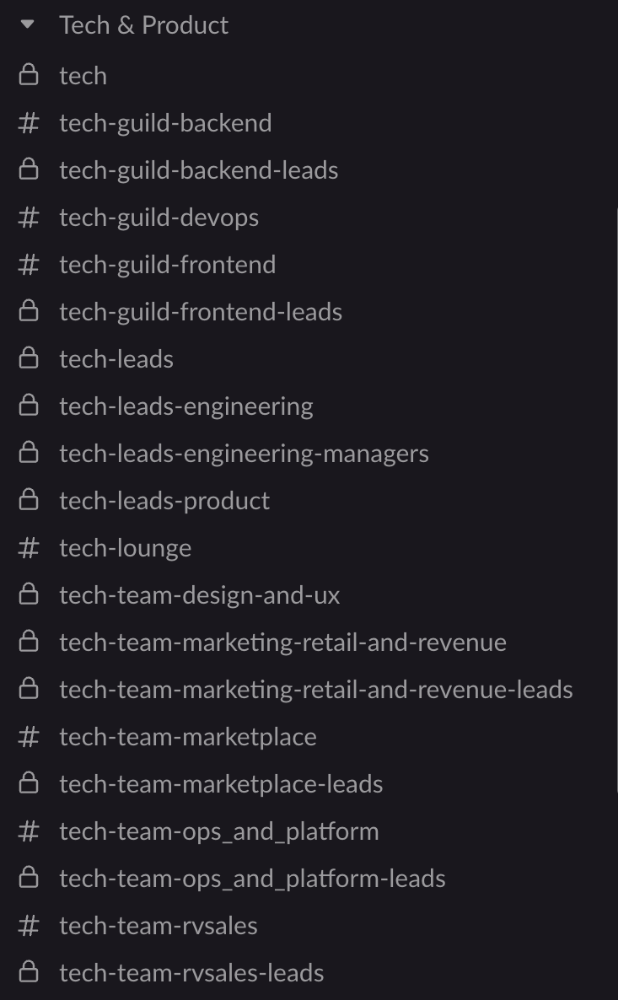
These are just some of the basic principles I follow to organize teams.
A book I particularly like about team types and how they interact with each other is https://teamtopologies.com/.