



More on Entrepreneurship/Creators

Jenn Leach
3 years ago
What TikTok Paid Me in 2021 with 100,000 Followers

I thought it would be interesting to share how much TikTok paid me in 2021.
Onward!
Oh, you get paid by TikTok?
Yes.
They compensate thousands of creators. My Tik Tok account
I launched my account in March 2020 and generally post about money, finance, and side hustles.
TikTok creators are paid in several ways.
Fund for TikTok creators
Sponsorships (aka brand deals)
Affiliate promotion
My own creations
Only one, the TikTok Creator Fund, pays me.
The TikTok Creator Fund: What Is It?
TikTok's initiative pays creators.
YouTube's Shorts Fund, Snapchat Spotlight, and other platforms have similar programs.
Creator Fund doesn't pay everyone. Some prerequisites are:
age requirement of at least 18 years
In the past 30 days, there must have been 100,000 views.
a minimum of 10,000 followers
If you qualify, you can apply using your TikTok account, and once accepted, your videos can earn money.
My earnings from the TikTok Creator Fund
Since 2020, I've made $273.65. My 2021 payment is $77.36.
Yikes!
I made between $4.91 to around $13 payout each time I got paid.
TikTok reportedly pays 3 to 5 cents per thousand views.
To live off the Creator Fund, you'd need billions of monthly views.
Top personal finance creator Sara Finance has millions (if not billions) of views and over 700,000 followers yet only received $3,000 from the TikTok Creator Fund.
Goals for 2022
TikTok pays me in different ways, as listed above.
My largest TikTok account isn't my only one.
In 2022, I'll revamp my channel.
It's been a tumultuous year on TikTok for my account, from getting shadow-banned to being banned from the Creator Fund to being accepted back (not at my wish).
What I've experienced isn't rare. I've read about other creators' experiences.
So, some quick goals for this account…
200,000 fans by the year 2023
Consistent monthly income of $5,000
two brand deals each month
For now, that's all.

Owolabi Judah
3 years ago
How much did YouTube pay for 10 million views?
Ali's $1,054,053.74 YouTube Adsense haul.

YouTuber, entrepreneur, and former doctor Ali Abdaal. He began filming productivity and financial videos in 2017. Ali Abdaal has 3 million YouTube subscribers and has crossed $1 million in AdSense revenue. Crazy, no?
Ali will share the revenue of his top 5 youtube videos, things he's learned that you can apply to your side hustle, and how many views it takes to make a livelihood off youtube.
First, "The Long Game."
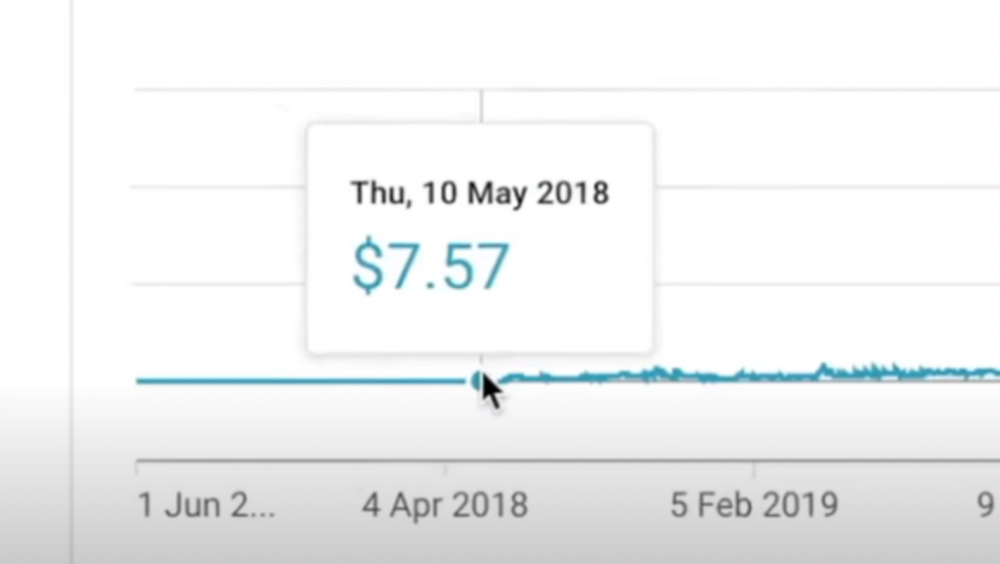
All good things take time to bear fruit. Compounding improves everything. Long-term work yields better returns. Ali made his first dollar after nine months and 85 videos.
Second, "One piece of content can transform your life, but you never know which one."
Had he abandoned YouTube at 84 videos without making any money, he wouldn't have filmed the 85th video that altered everything.
Third Lesson: Your Industry Choice Can Multiply.
The industry or niche you target as a business owner or side hustler can have a major impact on how much money you make.
Here are the top 5 videos.
1) 9.8m views: $191,258.16 for 9 passive income ideas
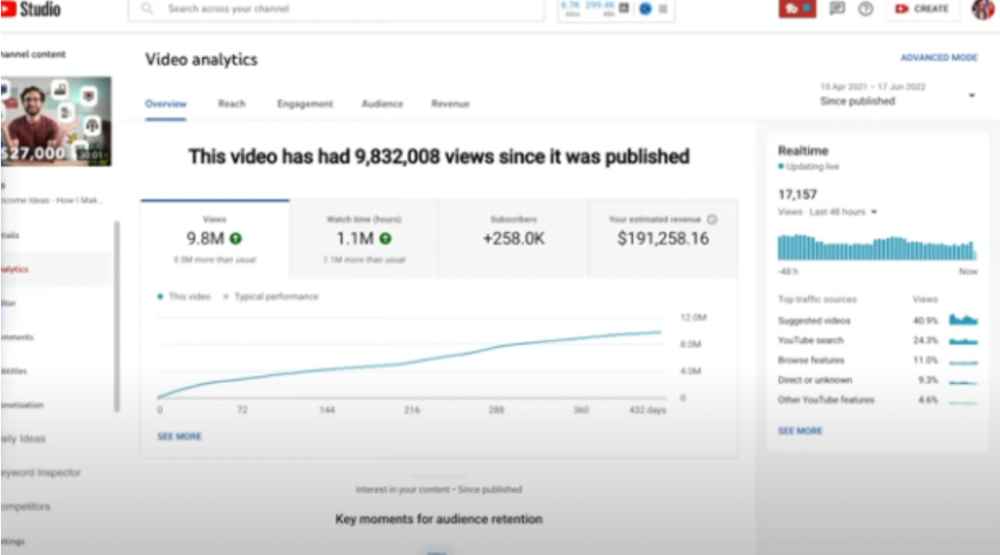
Ali made 2 points.
We should consider YouTube videos digital assets. They're investments, which make us money. His investments are yielding passive income.
Investing extra time and effort in your films can pay off.
2) How to Invest for Beginners — 5.2m Views: $87,200.08.
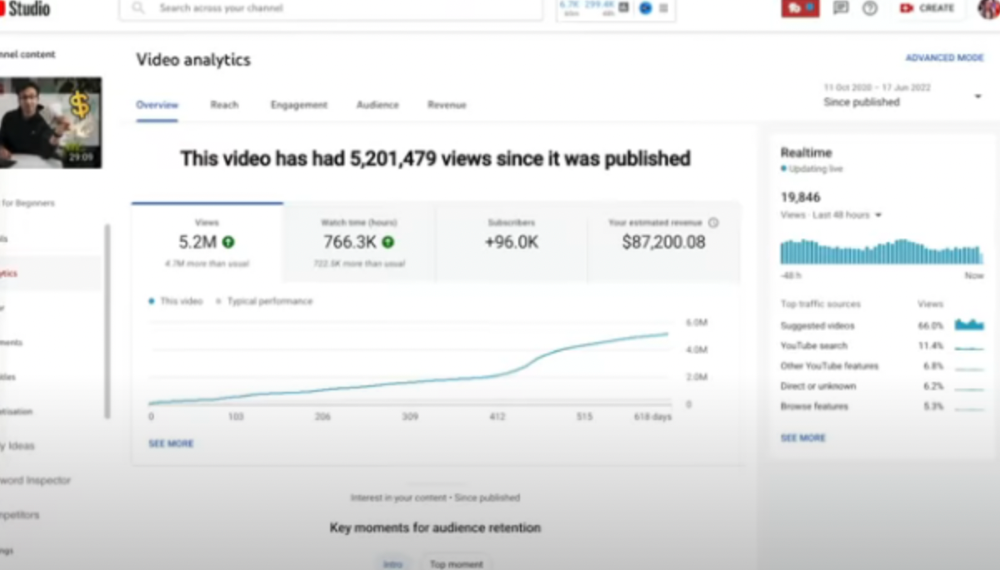
This video did poorly in the first several weeks after it was published; it was his tenth poorest performer. Don't worry about things you can't control. This applies to life, not just YouTube videos.
He stated we constantly have anxieties, fears, and concerns about things outside our control, but if we can find that line, life is easier and more pleasurable.
3) How to Build a Website in 2022— 866.3k views: $42,132.72.
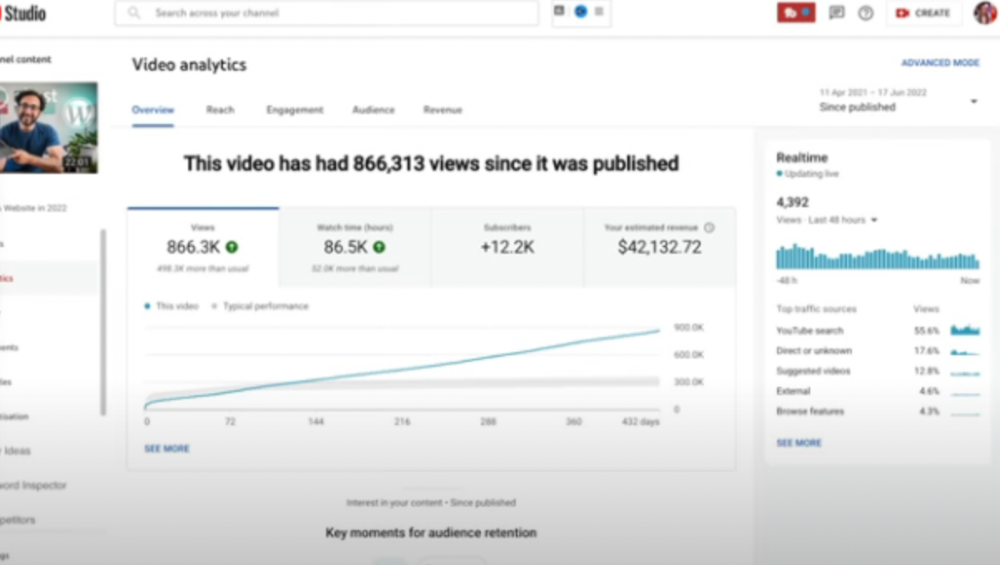
The RPM was $48.86 per thousand views, making it his highest-earning video. Squarespace, Wix, and other website builders are trying to put ads on it and competing against one other, so ad rates go up.
Because it was beyond his niche, Ali almost didn't make the video. He made the video because he wanted to help at least one person.
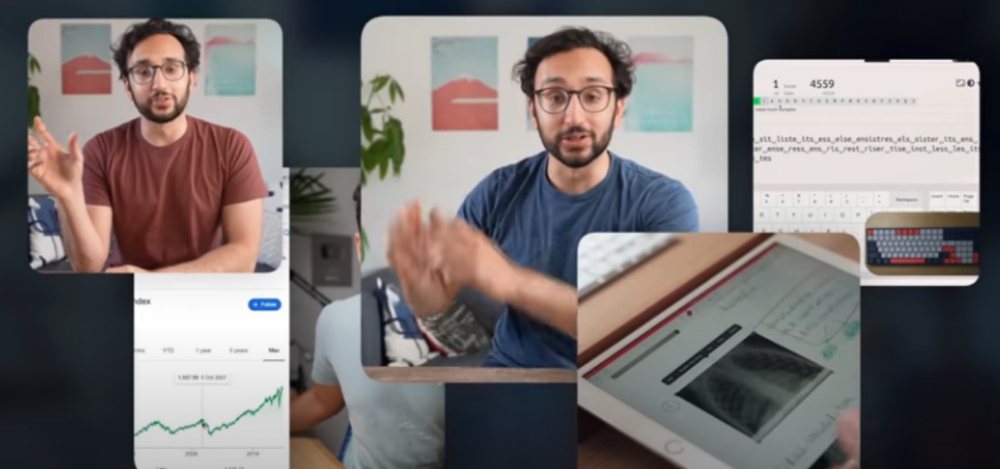
4) How I take notes on my iPad in medical school — 5.9m views: $24,479.80

85th video. It's the video that affected Ali's YouTube channel and his life the most. The video's success wasn't certain.
5) How I Type Fast 156 Words Per Minute — 8.2M views: $25,143.17
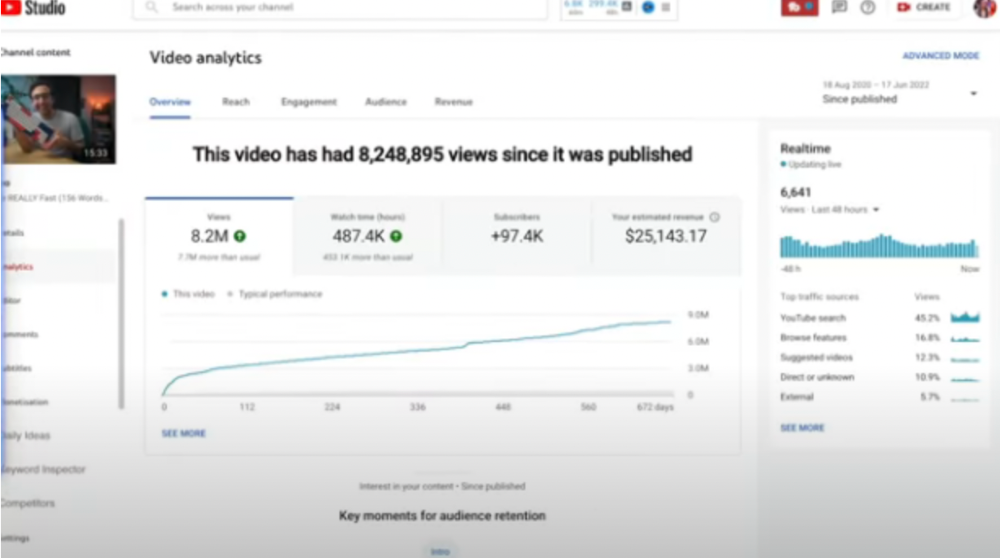
Ali didn't know this video would perform well; he made it because he can type fast and has been practicing for 10 years. So he made a video with his best advice.
How many views to different wealth levels?
It depends on geography, niche, and other monetization sources. To keep things simple, he would solely utilize AdSense.
How many views to generate money?

To generate money on Youtube, you need 1,000 subscribers and 4,000 hours of view time. How much work do you need to make pocket money?

Ali's first 1,000 subscribers took 52 videos and 6 months. The typical channel with 1,000 subscribers contains 152 videos, according to Tubebuddy. It's time-consuming.
After monetizing, you'll need 15,000 views/month to make $5-$10/day.
How many views to go part-time?

Say you make $35,000/year at your day job. If you work 5 days/week, you make $7,000/year each day. If you want to drop down from 5 days to 4 days/week, you need to make an extra $7,000/year from YouTube, or $600/month.
What's the quit-your-job budget?

Silicon Valley Girl is in a highly successful niche targeting tech-focused folks in the west. When her channel had 500k views/month, she made roughly $3,000/month or $47,000/year, enough to quit your work.
Marina has another 1.5m subscriber channel in Russia, which has a lower rpm because fewer corporations advertise there than in the west. 2.3 million views/month is $4,000/month or $50,000/year, enough to quit your employment.
Marina is an intriguing example because she has three YouTube channels with the same skills, but one is 16x more profitable due to the niche she chose.
In Ali's case, he made 100+ videos when his channel was producing enough money to quit his job, roughly $4,000/month.
How many views make you rich?

Depending on how you define rich. Ali felt prosperous with over $100,000/year and 3–5m views/month.
Conclusion
YouTubers and artists don't treat their work like a company, which is a mistake. Businesses have been attempting to figure this out for decades, if not centuries.
We can learn from the business world how to monetize YouTube, Instagram, and Tiktok and make them into sustainable enterprises where we can hire people and delegate tasks.
Bonus
Watch Ali's video explaining all this:
This post is a summary. Read the full article here

MAJESTY AliNICOLE WOW!
2 years ago
YouTube's faceless videos are growing in popularity, but this is nothing new.
I've always bucked social media norms. YouTube doesn't compare. Traditional video made me zig when everyone zagged. Audio, picture personality animation, thought movies, and slide show videos are most popular and profitable.

YouTube's business is shifting. While most video experts swear by the idea that YouTube success is all about making personal and professional Face-Share-Videos, those who use YouTube for business know things are different.
In this article, I will share concepts from my mini master class Figures to Followers: Prioritizing Purposeful Profits Over Popularity on YouTube to Create the Win-Win for You, Your Audience & More and my forthcoming publication The WOWTUBE-PRENEUR FACTOR EVOLUTION: The Basics of Powerfully & Profitably Positioning Yourself as a Video Communications Authority to Broadcast Your WOW Effect as a Video Entrepreneur.
I've researched the psychology, anthropology, and anatomy of significant social media platforms as an entrepreneur and social media marketing expert. While building my YouTube empire, I've paid particular attention to what works for short, mid, and long-term success, whether it's a niche-focused, lifestyle, or multi-interest channel.
Most new, semi-new, and seasoned YouTubers feel vlog-style or live-on-camera videos are popular. Faceless, animated, music-text-based, and slideshow videos do well for businesses.
Buyer-consumer vs. content-consumer thinking is totally different when absorbing content. Profitability and popularity are closely related, however most people become popular with traditional means but not profitable.
In my experience, Faceless videos are more profitable, although it depends on the channel's style. Several professionals are now teaching in their courses that non-traditional films are making the difference in their business success and popularity.
Face-Share-Personal-Touch videos make audiences feel like they know the personality, but they're not profitable.
Most spend hours creating articles, videos, and thumbnails to seem good. That's how most YouTubers gained their success in the past, but not anymore.
Looking the part and performing a typical role in videos doesn't convert well, especially for newbie channels.
Working with video marketers and YouTubers for years, I've noticed that most struggle to be consistent with content publishing since they exclusively use formats that need extensive development. Camera and green screen set ups, shooting/filming, and editing for post productions require their time, making it less appealing to post consistently, especially if they're doing all the work themselves.
Because they won't make simple format videos or audio videos with an overlay image, they overcomplicate the procedure (even with YouTube Shorts), and they leave their channels for weeks or months. Again, they believe YouTube only allows specific types of videos. Even though this procedure isn't working, they plan to keep at it.

A successful YouTube channel needs multiple video formats to suit viewer needs, I teach. Face-Share-Personal Touch and Faceless videos are both useful.
How people engage with YouTube content has changed over the years, and the average customer is no longer interested in an all-video channel.
Face-Share-Personal-Touch videos are great
Google Live
Online training
Giving listeners a different way to access your podcast that is being broadcast on sites like Anchor, BlogTalkRadio, Spreaker, Google, Apple Store, and others Many people enjoy using a video camera to record themselves while performing the internet radio, Facebook, or Instagram Live versions of their podcasts.
Video Blog Updates
even more
Faceless videos are popular for business and benefit both entrepreneurs and audiences.
For the business owner/entrepreneur…
Less production time results in time dollar savings.
enables the business owner to demonstrate the diversity of content development
For the Audience…
The channel offers a variety of appealing content options.
The same format is not monotonous or overly repetitive for the viewers.
Below are a couple videos from YouTube guru Make Money Matt's channel, which has over 347K subscribers.
Enjoy
24 Best Niches to Make Money on YouTube Without Showing Your Face
Make Money on YouTube Without Making Videos (Free Course)
In conclusion, you have everything it takes to build your own YouTube brand and empire. Learn the rules, then adapt them to succeed.
Please reread this and the other suggested articles for optimal benefit.
I hope this helped. How has this article helped you? Follow me for more articles like this and more multi-mission expressions.
You might also like

Guillaume Dumortier
2 years ago
Mastering the Art of Rhetoric: A Guide to Rhetorical Devices in Successful Headlines and Titles
Unleash the power of persuasion and captivate your audience with compelling headlines.
As the old adage goes, "You never get a second chance to make a first impression."
In the world of content creation and social ads, headlines and titles play a critical role in making that first impression.
A well-crafted headline can make the difference between an article being read or ignored, a video being clicked on or bypassed, or a product being purchased or passed over.
To make an impact with your headlines, mastering the art of rhetoric is essential. In this post, we'll explore various rhetorical devices and techniques that can help you create headlines that captivate your audience and drive engagement.
tl;dr : Headline Magician will help you craft the ultimate headline titles powered by rhetoric devices
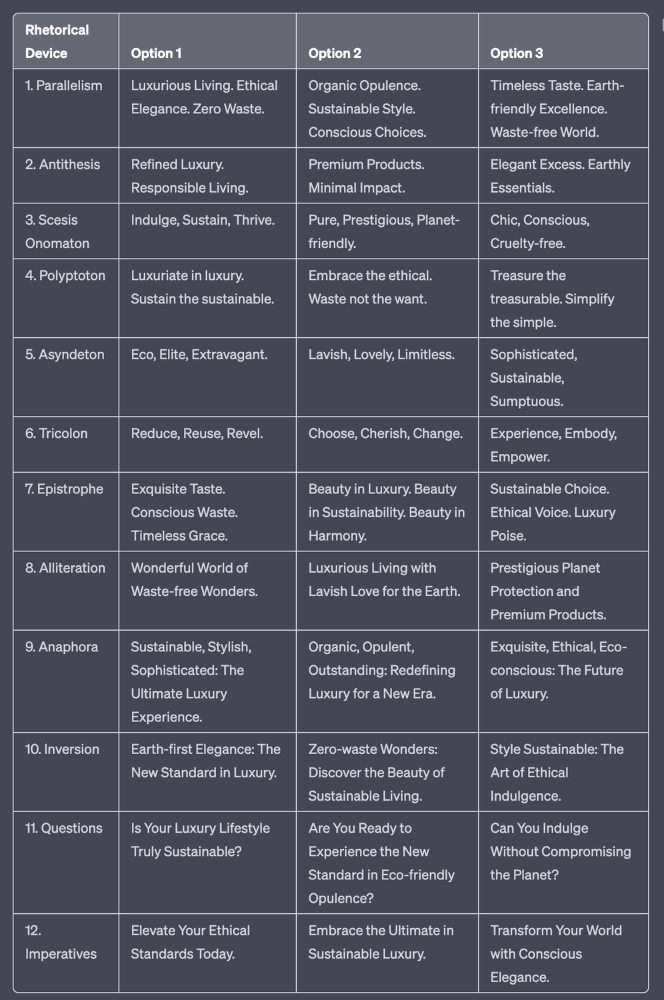
Example with a high-end luxury organic zero-waste skincare brand
✍️ The Power of Alliteration
Alliteration is the repetition of the same consonant sound at the beginning of words in close proximity. This rhetorical device lends itself well to headlines, as it creates a memorable, rhythmic quality that can catch a reader's attention.
By using alliteration, you can make your headlines more engaging and easier to remember.
Examples:
"Crafting Compelling Content: A Comprehensive Course"
"Mastering the Art of Memorable Marketing"
🔁 The Appeal of Anaphora
Anaphora is the repetition of a word or phrase at the beginning of successive clauses. This rhetorical device emphasizes a particular idea or theme, making it more memorable and persuasive.
In headlines, anaphora can be used to create a sense of unity and coherence, which can draw readers in and pique their interest.
Examples:
"Create, Curate, Captivate: Your Guide to Social Media Success"
"Innovation, Inspiration, and Insight: The Future of AI"
🔄 The Intrigue of Inversion
Inversion is a rhetorical device where the normal order of words is reversed, often to create an emphasis or achieve a specific effect.
In headlines, inversion can generate curiosity and surprise, compelling readers to explore further.
Examples:
"Beneath the Surface: A Deep Dive into Ocean Conservation"
"Beyond the Stars: The Quest for Extraterrestrial Life"
⚖️ The Persuasive Power of Parallelism
Parallelism is a rhetorical device that involves using similar grammatical structures or patterns to create a sense of balance and symmetry.
In headlines, parallelism can make your message more memorable and impactful, as it creates a pleasing rhythm and flow that can resonate with readers.
Examples:
"Eat Well, Live Well, Be Well: The Ultimate Guide to Wellness"
"Learn, Lead, and Launch: A Blueprint for Entrepreneurial Success"
⏭️ The Emphasis of Ellipsis
Ellipsis is the omission of words, typically indicated by three periods (...), which suggests that there is more to the story.
In headlines, ellipses can create a sense of mystery and intrigue, enticing readers to click and discover what lies behind the headline.
Examples:
"The Secret to Success... Revealed"
"Unlocking the Power of Your Mind... A Step-by-Step Guide"
🎭 The Drama of Hyperbole
Hyperbole is a rhetorical device that involves exaggeration for emphasis or effect.
In headlines, hyperbole can grab the reader's attention by making bold, provocative claims that stand out from the competition. Be cautious with hyperbole, however, as overuse or excessive exaggeration can damage your credibility.
Examples:
"The Ultimate Guide to Mastering Any Skill in Record Time"
"Discover the Revolutionary Technique That Will Transform Your Life"
❓The Curiosity of Questions
Posing questions in your headlines can be an effective way to pique the reader's curiosity and encourage engagement.
Questions compel the reader to seek answers, making them more likely to click on your content. Additionally, questions can create a sense of connection between the content creator and the audience, fostering a sense of dialogue and discussion.
Examples:
"Are You Making These Common Mistakes in Your Marketing Strategy?"
"What's the Secret to Unlocking Your Creative Potential?"
💥 The Impact of Imperatives
Imperatives are commands or instructions that urge the reader to take action. By using imperatives in your headlines, you can create a sense of urgency and importance, making your content more compelling and actionable.
Examples:
"Master Your Time Management Skills Today"
"Transform Your Business with These Innovative Strategies"
💢 The Emotion of Exclamations
Exclamations are powerful rhetorical devices that can evoke strong emotions and convey a sense of excitement or urgency.
Including exclamations in your headlines can make them more attention-grabbing and shareable, increasing the chances of your content being read and circulated.
Examples:
"Unlock Your True Potential: Find Your Passion and Thrive!"
"Experience the Adventure of a Lifetime: Travel the World on a Budget!"
🎀 The Effectiveness of Euphemisms
Euphemisms are polite or indirect expressions used in place of harsher, more direct language.
In headlines, euphemisms can make your message more appealing and relatable, helping to soften potentially controversial or sensitive topics.
Examples:
"Navigating the Challenges of Modern Parenting"
"Redefining Success in a Fast-Paced World"
⚡Antithesis: The Power of Opposites
Antithesis involves placing two opposite words side-by-side, emphasizing their contrasts. This device can create a sense of tension and intrigue in headlines.
Examples:
"Once a day. Every day"
"Soft on skin. Kill germs"
"Mega power. Mini size."
To utilize antithesis, identify two opposing concepts related to your content and present them in a balanced manner.
🎨 Scesis Onomaton: The Art of Verbless Copy
Scesis onomaton is a rhetorical device that involves writing verbless copy, which quickens the pace and adds emphasis.
Example:
"7 days. 7 dollars. Full access."
To use scesis onomaton, remove verbs and focus on the essential elements of your headline.
🌟 Polyptoton: The Charm of Shared Roots
Polyptoton is the repeated use of words that share the same root, bewitching words into memorable phrases.
Examples:
"Real bread isn't made in factories. It's baked in bakeries"
"Lose your knack for losing things."
To employ polyptoton, identify words with shared roots that are relevant to your content.
✨ Asyndeton: The Elegance of Omission
Asyndeton involves the intentional omission of conjunctions, adding crispness, conviction, and elegance to your headlines.
Examples:
"You, Me, Sushi?"
"All the latte art, none of the environmental impact."
To use asyndeton, eliminate conjunctions and focus on the core message of your headline.
🔮 Tricolon: The Magic of Threes
Tricolon is a rhetorical device that uses the power of three, creating memorable and impactful headlines.
Examples:
"Show it, say it, send it"
"Eat Well, Live Well, Be Well."
To use tricolon, craft a headline with three key elements that emphasize your content's main message.
🔔 Epistrophe: The Chime of Repetition
Epistrophe involves the repetition of words or phrases at the end of successive clauses, adding a chime to your headlines.
Examples:
"Catch it. Bin it. Kill it."
"Joint friendly. Climate friendly. Family friendly."
To employ epistrophe, repeat a key phrase or word at the end of each clause.

Stephen Moore
3 years ago
Web 2 + Web 3 = Web 5.
Monkey jpegs and shitcoins have tarnished Web3's reputation. Let’s move on.

Web3 was called "the internet's future."
Well, 'crypto bros' shouted about it loudly.
As quickly as it arrived to be the next internet, it appears to be dead. It's had scandals, turbulence, and crashes galore:
Web 3.0's cryptocurrencies have crashed. Bitcoin's all-time high was $66,935. This month, Ethereum fell from $2130 to $1117. Six months ago, the cryptocurrency market peaked at $3 trillion. Worst is likely ahead.
Gas fees make even the simplest Web3 blockchain transactions unsustainable.
Terra, Luna, and other dollar pegs collapsed, hurting crypto markets. Celsius, a crypto lender backed by VCs and Canada's second-largest pension fund, and Binance, a crypto marketplace, have withheld money and coins. They're near collapse.
NFT sales are falling rapidly and losing public interest.
Web3 has few real-world uses, like most crypto/blockchain technologies. Web3's image has been tarnished by monkey profile pictures and shitcoins while failing to become decentralized (the whole concept is controlled by VCs).
The damage seems irreparable, leaving Web3 in the gutter.
Step forward our new saviour — Web5
Fear not though, as hero awaits to drag us out of the Web3 hellscape. Jack Dorsey revealed his plan to save the internet quickly.
Dorsey has long criticized Web3, believing that VC capital and silicon valley insiders have created a centralized platform. In a tweet that upset believers and VCs (he was promptly blocked by Marc Andreessen), Dorsey argued, "You don't own "Web3." VCs and LPs do. Their incentives prevent it. It's a centralized organization with a new name.
Dorsey announced Web5 on June 10 in a very Elon-like manner. Block's TBD unit will work on the project (formerly Square).
Web5's pitch is that users will control their own data and identity. Bitcoin-based. Sound familiar? The presentation pack's official definition emphasizes decentralization. Web5 is a decentralized web platform that enables developers to write decentralized web apps using decentralized identifiers, verifiable credentials, and decentralized web nodes, returning ownership and control over identity and data to individuals.
Web5 would be permission-less, open, and token-less. What that means for Earth is anyone's guess. Identity. Ownership. Blockchains. Bitcoin. Different.
Web4 appears to have been skipped, forever destined to wish it could have shown the world what it could have been. (It was probably crap.) As this iteration combines Web2 and Web3, simple math and common sense add up to 5. Or something.
Dorsey and his team have had this idea simmering for a while. Daniel Buchner, a member of Block's Decentralized Identity team, said, "We're finishing up Web5's technical components."
Web5 could be the project that decentralizes the internet. It must be useful to users and convince everyone to drop the countless Web3 projects, products, services, coins, blockchains, and websites being developed as I write this.
Web5 may be too late for Dorsey and the incoming flood of creators.
Web6 is planned!
The next months and years will be hectic and less stable than the transition from Web 1.0 to Web 2.0.
Web1 was around 1991-2004.
Web2 ran from 2004 to 2021. (though the Web3 term was first used in 2014, it only really gained traction years later.)
Web3 lasted a year.
Web4 is dead.
Silicon Valley billionaires are turning it into a startup-style race, each disrupting the next iteration until they crack it. Or destroy it completely.
Web5 won't last either.

Steffan Morris Hernandez
2 years ago
10 types of cognitive bias to watch out for in UX research & design
10 biases in 10 visuals

Cognitive biases are crucial for UX research, design, and daily life. Our biases distort reality.
After learning about biases at my UX Research bootcamp, I studied Erika Hall's Just Enough Research and used the Nielsen Norman Group's wealth of information. 10 images show my findings.
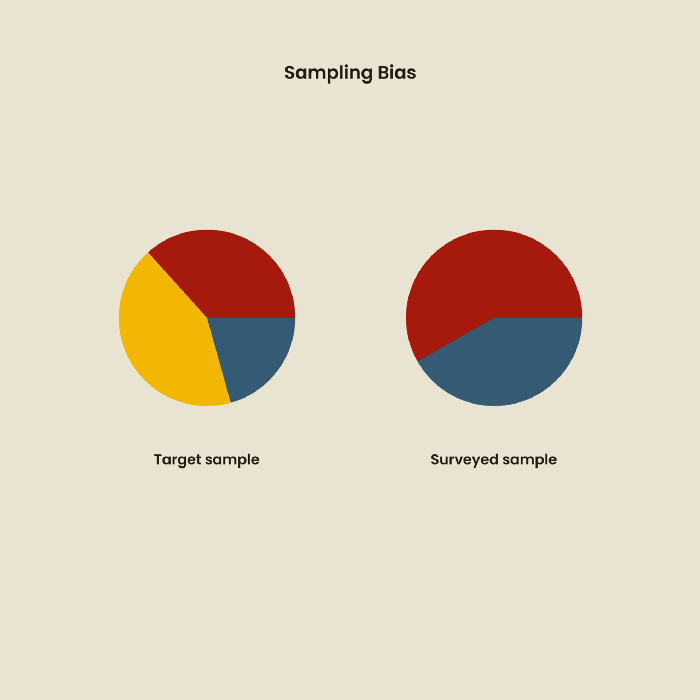
1. Bias in sampling
Misselection of target population members causes sampling bias. For example, you are building an app to help people with food intolerances log their meals and are targeting adult males (years 20-30), adult females (ages 20-30), and teenage males and females (ages 15-19) with food intolerances. However, a sample of only adult males and teenage females is biased and unrepresentative.
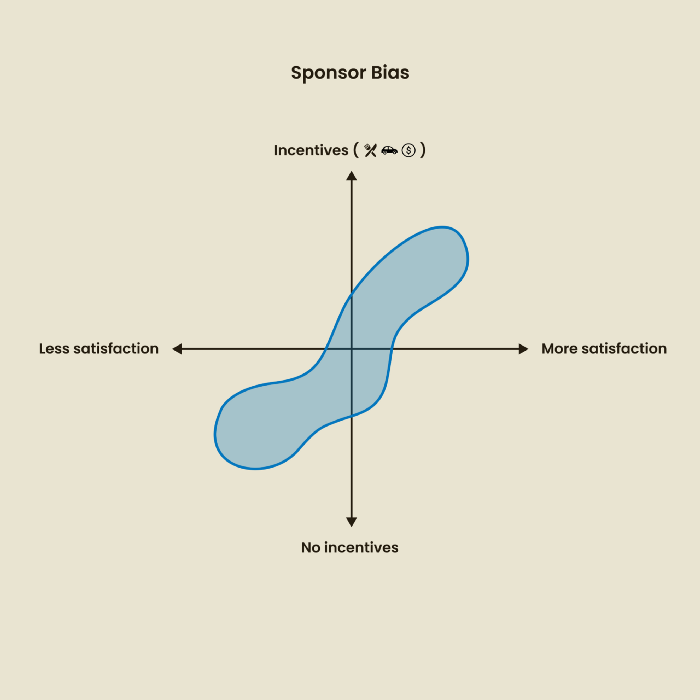
2. Sponsor Disparity
Sponsor bias occurs when a study's findings favor an organization's goals. Beware if X organization promises to drive you to their HQ, compensate you for your time, provide food, beverages, discounts, and warmth. Participants may endeavor to be neutral, but incentives and prizes may bias their evaluations and responses in favor of X organization.
In Just Enough Research, Erika Hall suggests describing the company's aims without naming it.
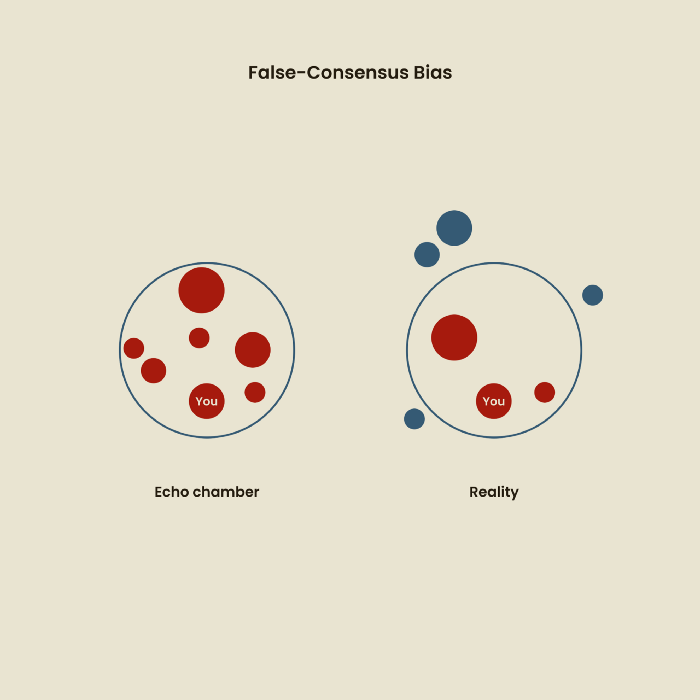
Third, False-Consensus Bias
False-consensus bias is when a person thinks others think and act the same way. For instance, if a start-up designs an app without researching end users' needs, it could fail since end users may have different wants. https://www.nngroup.com/videos/false-consensus-effect/
Working directly with the end user and employing many research methodologies to improve validity helps lessen this prejudice. When analyzing data, triangulation can boost believability.
Bias of the interviewer
I struggled with this bias during my UX research bootcamp interviews. Interviewing neutrally takes practice and patience. Avoid leading questions that structure the story since the interviewee must interpret them. Nodding or smiling throughout the interview may subconsciously influence the interviewee's responses.

The Curse of Knowledge
The curse of knowledge occurs when someone expects others understand a subject as well as they do. UX research interviews and surveys should reduce this bias because technical language might confuse participants and harm the research. Interviewing participants as though you are new to the topic may help them expand on their replies without being influenced by the researcher's knowledge.

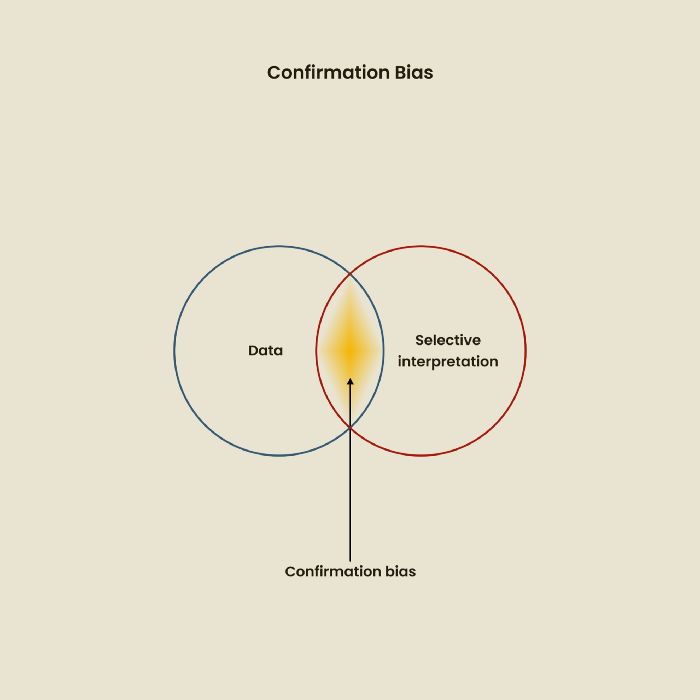
Confirmation Bias
Most prevalent bias. People highlight evidence that supports their ideas and ignore data that doesn't. The echo chamber of social media creates polarization by promoting similar perspectives.
A researcher with confirmation bias may dismiss data that contradicts their research goals. Thus, the research or product may not serve end users.
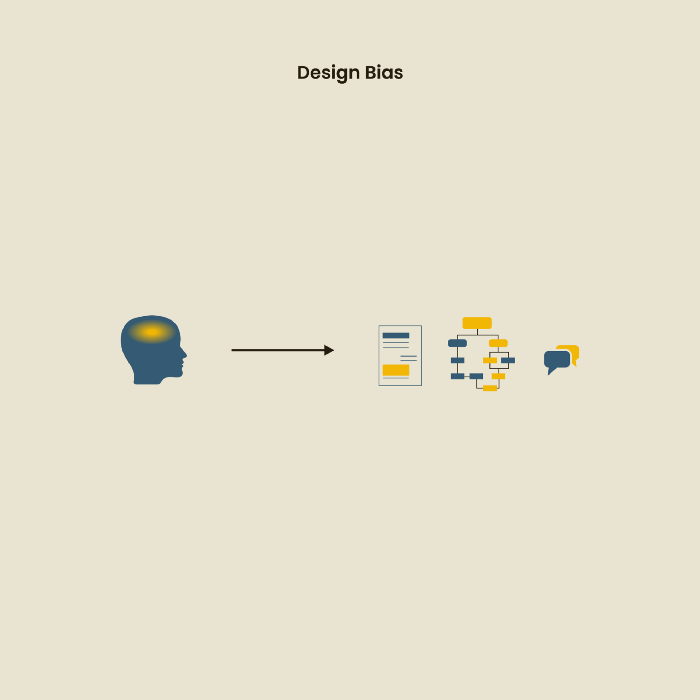
Design biases
UX Research design bias pertains to study construction and execution. Design bias occurs when data is excluded or magnified based on human aims, assumptions, and preferences.
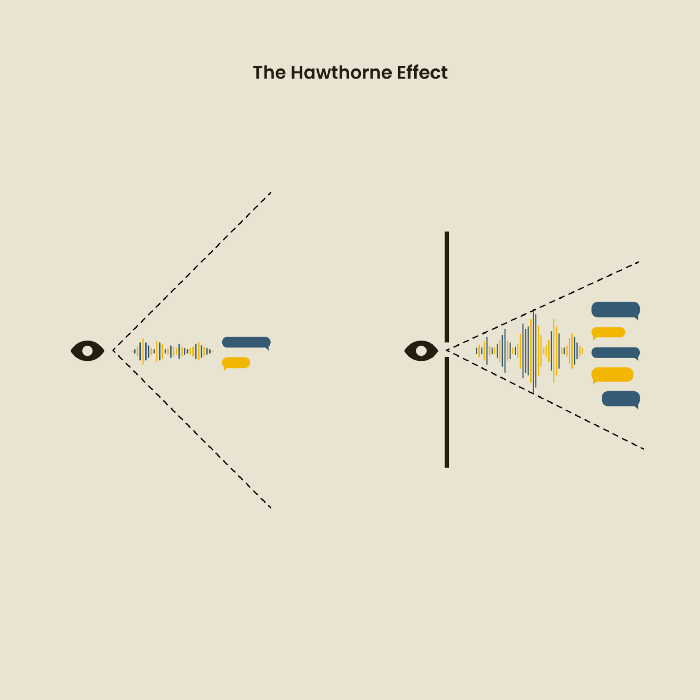
The Hawthorne Impact
Remember when you behaved differently while the teacher wasn't looking? When you behaved differently without your parents watching? A UX research study's Hawthorne Effect occurs when people modify their behavior because you're watching. To escape judgment, participants may act and speak differently.
To avoid this, researchers should blend into the background and urge subjects to act alone.
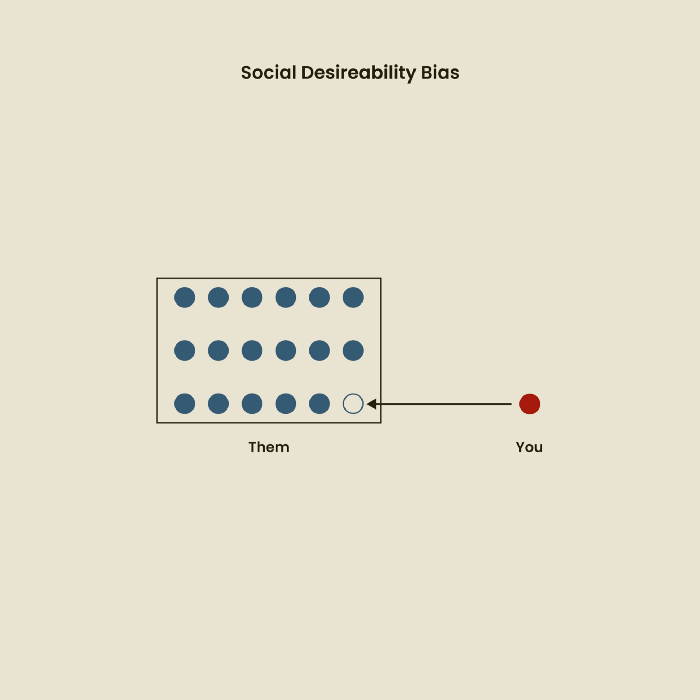
The bias against social desire
People want to belong to escape rejection and hatred. Research interviewees may mislead or slant their answers to avoid embarrassment. Researchers should encourage honesty and confidentiality in studies to address this. Observational research may reduce bias better than interviews because participants behave more organically.
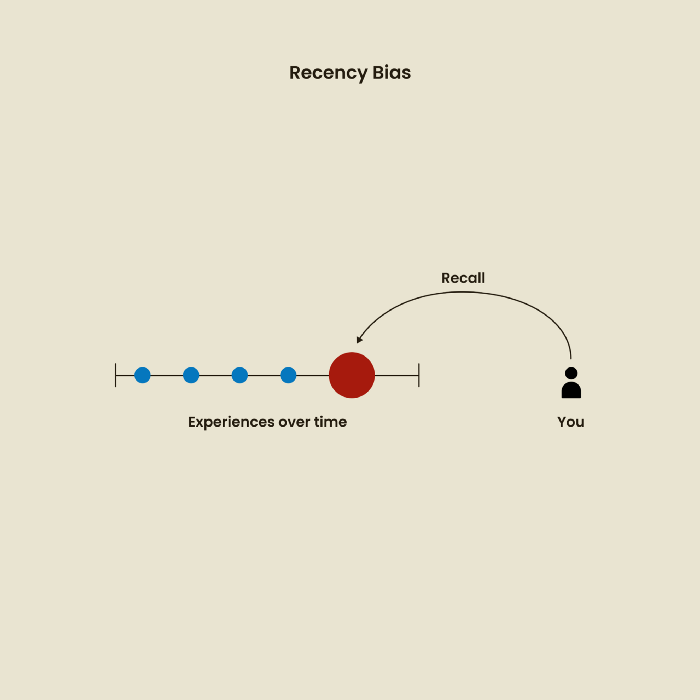
Relative Time Bias
Humans tend to appreciate recent experiences more. Consider school. Say you failed a recent exam but did well in the previous 7 exams. Instead, you may vividly recall the last terrible exam outcome.
If a UX researcher relies their conclusions on the most recent findings instead of all the data and results, recency bias might occur.
I hope you liked learning about UX design, research, and real-world biases.