



More on Productivity

David G Chen
3 years ago
If you want to earn money, stop writing for entertainment.
When you stop blogging for a few weeks, your views and profits plummet.
Because you're writing fascinating posts for others. Everyone's done ithat…
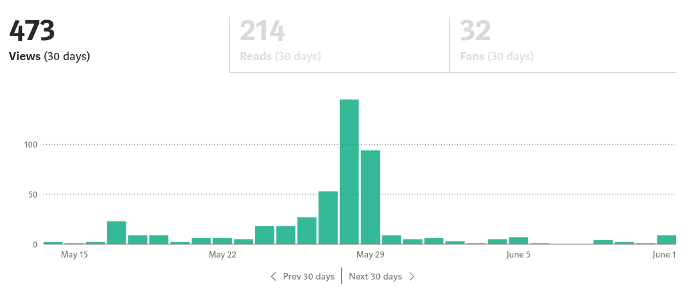
If I keep writing, the graph should maintain velocity, you could say. If I wrote more, it could rise.
However, entertaining pieces still tend to roller coaster and jump.
this type of writing is like a candle. They burn out and must be replaced. You must continuously light new ones to maintain the illumination.
When you quit writing, your income stops.
A substitute
Instead of producing amusing articles, try solving people's issues. You should answer their search questions.
Here's what happens when you answer their searches.
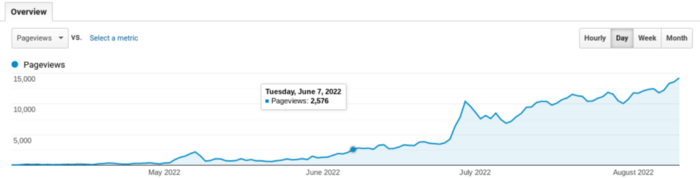
My website's Google analytics. As a dentist, I answer oral health questions.
This chart vs. Medium is pretty glaring, right?
As of yesterday, it was averaging 15k page views each day.
How much would you make on Medium with 15k daily views?
Evergreen materials
In SEO, this is called evergreen content.
Your content is like a lush, evergreen forest, and by green I mean Benjamins.

Do you have knowledge that you can leverage? Why not help your neighbors and the world?
Answer search inquiries and help others. You'll be well rewarded.
This is better than crafting candle-like content that fizzles out quickly.
Is beauty really ephemeral like how flowers bloom? Nah, I prefer watching forests grow instead (:

Jumanne Rajabu Mtambalike
3 years ago
10 Years of Trying to Manage Time and Improve My Productivity.
I've spent the last 10 years of my career mastering time management. I've tried different approaches and followed multiple people and sources. My knowledge is summarized.
Great people, including entrepreneurs, master time management. I learned time management in college. I was studying Computer Science and Finance and leading Tanzanian students in Bangalore, India. I had 24 hours per day to do this and enjoy campus. I graduated and received several awards. I've learned to maximize my time. These tips and tools help me finish quickly.
Eisenhower-Box
I don't remember when I read the article. James Clear, one of my favorite bloggers, introduced me to the Eisenhower Box, which I've used for years. Eliminate waste to master time management. By grouping your activities by importance and urgency, the tool helps you prioritize what matters and drop what doesn't. If it's urgent, do it. Delegate if it's urgent but not necessary. If it's important but not urgent, reschedule it; otherwise, drop it. I integrated the tool with Trello to manage my daily tasks. Since 2007, I've done this.

James Clear's article mentions Eisenhower Box.
Essentialism rules
Greg McKeown's book Essentialism introduced me to disciplined pursuit of less. I once wrote about this. I wasn't sure what my career's real opportunities and distractions were. A non-essentialist thinks everything is essential; you want to be everything to everyone, and your life lacks satisfaction. Poor time management starts it all. Reading and applying this book will change your life.

Essential vs non-essential
Life Calendar
Most of us make corporate calendars. Peter Njonjo, founder of Twiga Foods, said he manages time by putting life activities in his core calendars. It includes family retreats, weddings, and other events. He joked that his wife always complained to him to avoid becoming a calendar item. It's key. "Time Masters" manages life's four burners, not just work and corporate life. There's no "work-life balance"; it's life.

Health, Family, Work, and Friends.
The Brutal No
In a culture where people want to look good, saying "NO" to a favor request seems rude. In reality, the crime is breaking a promise. "Time Masters" have mastered "NO". More "YES" means less time, and more "NO" means more time for tasks and priorities. Brutal No doesn't mean being mean to your coworkers; it means explaining kindly and professionally that you have other priorities.
To-Do vs. MITs
Most people are productive with a routine to-do list. You can't be effective by just checking boxes on a To-do list. When was the last time you completed all of your daily tasks? Never. You must replace the to-do list with Most Important Tasks (MITs). MITs allow you to focus on the most important tasks on your list. You feel progress and accomplishment when you finish these tasks. MITs don't include ad-hoc emails, meetings, etc.
Journal Mapped
Most people don't journal or plan their day in the developing South. I've learned to plan my day in my journal over time. I have multiple sections on one page: MITs (things I want to accomplish that day), Other Activities (stuff I can postpone), Life (health, faith, and family issues), and Pop-Ups (things that just pop up). I leave the next page blank for notes. I reflected on the blocks to identify areas to improve the next day. You will have bad days, but at least you'll realize it was due to poor time management.
Buy time/delegate
Time or money? When you make enough money, you lose time to make more. The smart buy "Time." I resisted buying other people's time for years. I regret not hiring an assistant sooner. Learn to buy time from others and pay for time-consuming tasks. Sometimes you think you're saving money by doing things yourself, but you're actually losing money.
This post is a summary. See the full post here.

Cammi Pham
3 years ago
7 Scientifically Proven Things You Must Stop Doing To Be More Productive
Smarter work yields better results.

17-year-old me worked and studied 20 hours a day. During school breaks, I did coursework and ran a nonprofit at night. Long hours earned me national campaigns, A-list opportunities, and a great career. As I aged, my thoughts changed. Working harder isn't necessarily the key to success.
In some cases, doing less work might lead to better outcomes.
Consider a hard-working small business owner. He can't beat his corporate rivals by working hard. Time's limited. An entrepreneur can work 24 hours a day, 7 days a week, but a rival can invest more money, create a staff, and put in more man hours. Why have small startups done what larger companies couldn't? Facebook paid $1 billion for 13-person Instagram. Snapchat, a 30-person startup, rejected Facebook and Google bids. Luck and efficiency each contributed to their achievement.
The key to success is not working hard. It’s working smart.
Being busy and productive are different. Busy doesn't always equal productive. Productivity is less about time management and more about energy management. Life's work. It's using less energy to obtain more rewards. I cut my work week from 80 to 40 hours and got more done. I value simplicity.
Here are seven activities I gave up in order to be more productive.
1. Give up working extra hours and boost productivity instead.
When did the five-day, 40-hour work week start? Henry Ford, Ford Motor Company founder, experimented with his workers in 1926.
He decreased their daily hours from 10 to 8, and shortened the work week from 6 days to 5. As a result, he saw his workers’ productivity increase.
According to a 1980 Business Roundtable report, Scheduled Overtime Effect on Construction Projects, the more you work, the less effective and productive you become.
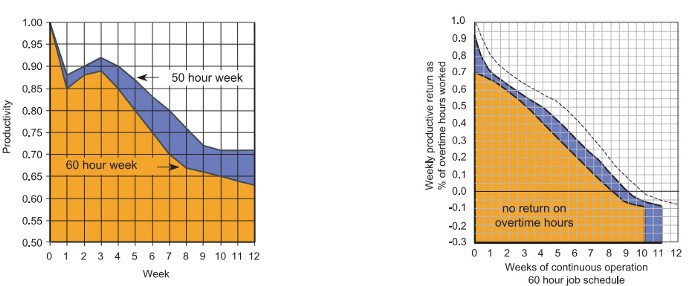
“Where a work schedule of 60 or more hours per week is continued longer than about two months, the cumulative effect of decreased productivity will cause a delay in the completion date beyond that which could have been realized with the same crew size on a 40-hour week.” Source: Calculating Loss of Productivity Due to Overtime Using Published Charts — Fact or Fiction
AlterNet editor Sara Robinson cited US military research showing that losing one hour of sleep per night for a week causes cognitive impairment equivalent to a.10 blood alcohol level. You can get fired for showing up drunk, but an all-nighter is fine.
Irrespective of how well you were able to get on with your day after that most recent night without sleep, it is unlikely that you felt especially upbeat and joyous about the world. Your more-negative-than-usual perspective will have resulted from a generalized low mood, which is a normal consequence of being overtired. More important than just the mood, this mind-set is often accompanied by decreases in willingness to think and act proactively, control impulses, feel positive about yourself, empathize with others, and generally use emotional intelligence. Source: The Secret World of Sleep: The Surprising Science of the Mind at Rest
To be productive, don't overwork and get enough sleep. If you're not productive, lack of sleep may be to blame. James Maas, a sleep researcher and expert, said 7/10 Americans don't get enough sleep.
Did you know?
Leonardo da Vinci slept little at night and frequently took naps.
Napoleon, the French emperor, had no qualms about napping. He splurged every day.
Even though Thomas Edison felt self-conscious about his napping behavior, he regularly engaged in this ritual.
President Franklin D. Roosevelt's wife Eleanor used to take naps before speeches to increase her energy.
The Singing Cowboy, Gene Autry, was known for taking regular naps in his dressing area in between shows.
Every day, President John F. Kennedy took a siesta after eating his lunch in bed.
Every afternoon, oil businessman and philanthropist John D. Rockefeller took a nap in his office.
It was unavoidable for Winston Churchill to take an afternoon snooze. He thought it enabled him to accomplish twice as much each day.
Every afternoon around 3:30, President Lyndon B. Johnson took a nap to divide his day into two segments.
Ronald Reagan, the 40th president, was well known for taking naps as well.
Source: 5 Reasons Why You Should Take a Nap Every Day — Michael Hyatt
Since I started getting 7 to 8 hours of sleep a night, I've been more productive and completed more work than when I worked 16 hours a day. Who knew marketers could use sleep?
2. Refrain from accepting too frequently
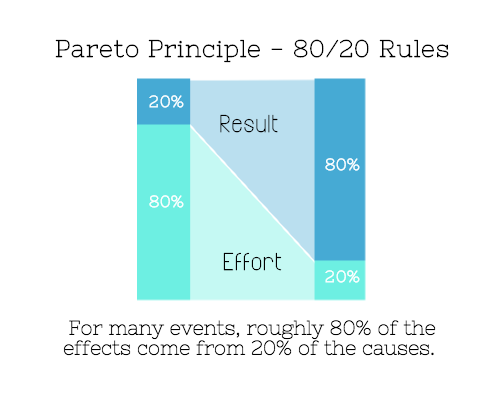
Pareto's principle states that 20% of effort produces 80% of results, but 20% of results takes 80% of effort. Instead of working harder, we should prioritize the initiatives that produce the most outcomes. So we can focus on crucial tasks. Stop accepting unproductive tasks.
“The difference between successful people and very successful people is that very successful people say “no” to almost everything.” — Warren Buffett
What should you accept? Why say no? Consider doing a split test to determine if anything is worth your attention. Track what you do, how long it takes, and the consequences. Then, evaluate your list to discover what worked (or didn't) to optimize future chores.
Most of us say yes more often than we should, out of guilt, overextension, and because it's simpler than no. Nobody likes being awful.
Researchers separated 120 students into two groups for a 2012 Journal of Consumer Research study. One group was educated to say “I can't” while discussing choices, while the other used “I don't”.
The students who told themselves “I can’t eat X” chose to eat the chocolate candy bar 61% of the time. Meanwhile, the students who told themselves “I don’t eat X” chose to eat the chocolate candy bars only 36% of the time. This simple change in terminology significantly improved the odds that each person would make a more healthy food choice.
Next time you need to say no, utilize I don't to encourage saying no to unimportant things.
The 20-second rule is another wonderful way to avoid pursuits with little value. Add a 20-second roadblock to things you shouldn't do or bad habits you want to break. Delete social media apps from your phone so it takes you 20 seconds to find your laptop to access them. You'll be less likely to engage in a draining hobby or habit if you add an inconvenience.
Lower the activation energy for habits you want to adopt and raise it for habits you want to avoid. The more we can lower or even eliminate the activation energy for our desired actions, the more we enhance our ability to jump-start positive change. Source: The Happiness Advantage: The Seven Principles of Positive Psychology That Fuel Success and Performance at Work
3. Stop doing everything yourself and start letting people help you
I once managed a large community and couldn't do it alone. The community took over once I burned out. Members did better than I could have alone. I learned about community and user-generated content.
Consumers know what they want better than marketers. Octoly says user-generated videos on YouTube are viewed 10 times more than brand-generated videos. 51% of Americans trust user-generated material more than a brand's official website (16%) or media coverage (22%). (14 percent). Marketers should seek help from the brand community.

Being a successful content marketer isn't about generating the best content, but cultivating a wonderful community.
We should seek aid when needed. We can't do everything. It's best to delegate work so you may focus on the most critical things. Instead of overworking or doing things alone, let others help.
Having friends or coworkers around can boost your productivity even if they can't help.
Just having friends nearby can push you toward productivity. “There’s a concept in ADHD treatment called the ‘body double,’ ” says David Nowell, Ph.D., a clinical neuropsychologist from Worcester, Massachusetts. “Distractable people get more done when there is someone else there, even if he isn’t coaching or assisting them.” If you’re facing a task that is dull or difficult, such as cleaning out your closets or pulling together your receipts for tax time, get a friend to be your body double. Source: Friendfluence: The Surprising Ways Friends Make Us Who We Are
4. Give up striving for perfection
Perfectionism hinders professors' research output. Dr. Simon Sherry, a psychology professor at Dalhousie University, did a study on perfectionism and productivity. Dr. Sherry established a link between perfectionism and productivity.
Perfectionism has its drawbacks.
They work on a task longer than necessary.
They delay and wait for the ideal opportunity. If the time is right in business, you are already past the point.
They pay too much attention to the details and miss the big picture.
Marketers await the right time. They miss out.
The perfect moment is NOW.
5. Automate monotonous chores instead of continuing to do them.
A team of five workers who spent 3%, 20%, 25%, 30%, and 70% of their time on repetitive tasks reduced their time spent to 3%, 10%, 15%, 15%, and 10% after two months of working to improve their productivity.
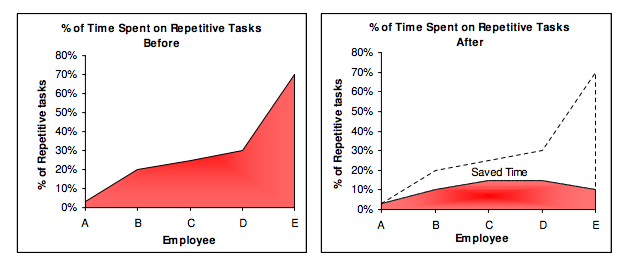
Last week, I wrote a 15-minute Python program. I wanted to generate content utilizing Twitter API data and Hootsuite to bulk schedule it. Automation has cut this task from a day to five minutes. Whenever I do something more than five times, I try to automate it.
Automate monotonous chores without coding. Skills and resources are nice, but not required. If you cannot build it, buy it.
People forget time equals money. Manual work is easy and requires little investigation. You can moderate 30 Instagram photographs for your UGC campaign. You need digital asset management software to manage 30,000 photographs and movies from five platforms. Filemobile helps individuals develop more user-generated content. You may buy software to manage rich media and address most internet difficulties.
Hire an expert if you can't find a solution. Spend money to make money, and time is your most precious asset.
Visit GitHub or Google Apps Script library, marketers. You may often find free, easy-to-use open source code.
6. Stop relying on intuition and start supporting your choices with data.
You may optimize your life by optimizing webpages for search engines.
Numerous studies might help you boost your productivity. Did you know individuals are most distracted from midday to 4 p.m.? This is what a Penn State psychology professor found. Even if you can't find data on a particular question, it's easy to run a split test and review your own results.
7. Stop working and spend some time doing absolutely nothing.
Most people don't know that being too focused can be destructive to our work or achievements. The Boston Globe's The Power of Lonely says solo time is excellent for the brain and spirit.
One ongoing Harvard study indicates that people form more lasting and accurate memories if they believe they’re experiencing something alone. Another indicates that a certain amount of solitude can make a person more capable of empathy towards others. And while no one would dispute that too much isolation early in life can be unhealthy, a certain amount of solitude has been shown to help teenagers improve their moods and earn good grades in school. Source: The Power of Lonely
Reflection is vital. We find solutions when we're not looking.
We don't become more productive overnight. It demands effort and practice. Waiting for change doesn't work. Instead, learn about your body and identify ways to optimize your energy and time for a happy existence.
You might also like

Sam Hickmann
3 years ago
Donor-Advised Fund Tax Benefits (DAF)
Giving through a donor-advised fund can be tax-efficient. Using a donor-advised fund can reduce your tax liability while increasing your charitable impact.
Grow Your Donations Tax-Free.
Your DAF's charitable dollars can be invested before being distributed. Your DAF balance can grow with the market. This increases grantmaking funds. The assets of the DAF belong to the charitable sponsor, so you will not be taxed on any growth.
Avoid a Windfall Tax Year.
DAFs can help reduce tax burdens after a windfall like an inheritance, business sale, or strong market returns. Contributions to your DAF are immediately tax deductible, lowering your taxable income. With DAFs, you can effectively pre-fund years of giving with assets from a single high-income event.
Make a contribution to reduce or eliminate capital gains.
One of the most common ways to fund a DAF is by gifting publicly traded securities. Securities held for more than a year can be donated at fair market value and are not subject to capital gains tax. If a donor liquidates assets and then donates the proceeds to their DAF, capital gains tax reduces the amount available for philanthropy. Gifts of appreciated securities, mutual funds, real estate, and other assets are immediately tax deductible up to 30% of Adjusted gross income (AGI), with a five-year carry-forward for gifts that exceed AGI limits.
Using Appreciated Stock as a Gift
Donating appreciated stock directly to a DAF rather than liquidating it and donating the proceeds reduces philanthropists' tax liability by eliminating capital gains tax and lowering marginal income tax.
In the example below, a donor has $100,000 in long-term appreciated stock with a cost basis of $10,000:
Using a DAF would allow this donor to give more to charity while paying less taxes. This strategy often allows donors to give more than 20% more to their favorite causes.
For illustration purposes, this hypothetical example assumes a 35% income tax rate. All realized gains are subject to the federal long-term capital gains tax of 20% and the 3.8% Medicare surtax. No other state taxes are considered.
The information provided here is general and educational in nature. It is not intended to be, nor should it be construed as, legal or tax advice. NPT does not provide legal or tax advice. Furthermore, the content provided here is related to taxation at the federal level only. NPT strongly encourages you to consult with your tax advisor or attorney before making charitable contributions.

Enrique Dans
3 years ago
You may not know about The Merge, yet it could change society

Ethereum is the second-largest cryptocurrency. The Merge, a mid-September event that will convert Ethereum's consensus process from proof-of-work to proof-of-stake if all goes according to plan, will be a game changer.
Why is Ethereum ditching proof-of-work? Because it can. We're talking about a fully functioning, open-source ecosystem with a capacity for evolution that other cryptocurrencies lack, a change that would allow it to scale up its performance from 15 transactions per second to 100,000 as its blockchain is used for more and more things. It would reduce its energy consumption by 99.95%. Vitalik Buterin, the system's founder, would play a less active role due to decentralization, and miners, who validated transactions through proof of work, would be far less important.
Why has this conversion taken so long and been so cautious? Because it involves modifying a core process while it's running to boost its performance. It requires running the new mechanism in test chains on an ever-increasing scale, assessing participant reactions, and checking for issues or restrictions. The last big test was in early June and was successful. All that's left is to converge the mechanism with the Ethereum blockchain to conclude the switch.
What's stopping Bitcoin, the leader in market capitalization and the cryptocurrency that began blockchain's appeal, from doing the same? Satoshi Nakamoto, whoever he or she is, departed from public life long ago, therefore there's no community leadership. Changing it takes a level of consensus that is impossible to achieve without strong leadership, which is why Bitcoin's evolution has been sluggish and conservative, with few modifications.
Secondly, The Merge will balance the consensus mechanism (proof-of-work or proof-of-stake) and the system decentralization or centralization. Proof-of-work prevents double-spending, thus validators must buy hardware. The system works, but it requires a lot of electricity and, as it scales up, tends to re-centralize as validators acquire more hardware and the entire network activity gets focused in a few nodes. Larger operations save more money, which increases profitability and market share. This evolution runs opposed to the concept of decentralization, and some anticipate that any system that uses proof of work as a consensus mechanism will evolve towards centralization, with fewer large firms able to invest in efficient network nodes.
Yet radical bitcoin enthusiasts share an opposite argument. In proof-of-stake, transaction validators put their funds at stake to attest that transactions are valid. The algorithm chooses who validates each transaction, giving more possibilities to nodes that put more coins at stake, which could open the door to centralization and government control.
In both cases, we're talking about long-term changes, but Bitcoin's proof-of-work has been evolving longer and seems to confirm those fears, while proof-of-stake is only employed in coins with a minuscule volume compared to Ethereum and has no predictive value.
As of mid-September, we will have two significant cryptocurrencies, each with a different consensus mechanisms and equally different characteristics: one is intrinsically conservative and used only for economic transactions, while the other has been evolving in open source mode, and can be used for other types of assets, smart contracts, or decentralized finance systems. Some even see it as the foundation of Web3.
Many things could change before September 15, but The Merge is likely to be a turning point. We'll have to follow this closely.

Bastian Hasslinger
3 years ago
Before 2021, most startups had excessive valuations. It is currently causing issues.

Higher startup valuations are often favorable for all parties. High valuations show a business's potential. New customers and talent are attracted. They earn respect.
Everyone benefits if a company's valuation rises.
Founders and investors have always been incentivized to overestimate a company's value.
Post-money valuations were inflated by 2021 market expectations and the valuation model's mechanisms.
Founders must understand both levers to handle a normalizing market.
2021, the year of miracles
2021 must've seemed miraculous to entrepreneurs, employees, and VCs. Valuations rose, and funding resumed after the first Covid-19 epidemic caution.
In 2021, VC investments increased from $335B to $643B. 518 new worldwide unicorns vs. 134 in 2020; 951 US IPOs vs. 431.
Things can change quickly, as 2020-21 showed.
Rising interest rates, geopolitical developments, and normalizing technology conditions drive down share prices and tech company market caps in 2022. Zoom, the poster-child of early lockdown success, is down 37% since 1st Jan.
Once-inflated valuations can become a problem in a normalizing market, especially for founders, employees, and early investors.
the reason why startups are always overvalued
To see why inflated valuations are a problem, consider one of its causes.
Private company values only fluctuate following a new investment round, unlike publicly-traded corporations. The startup's new value is calculated simply:
(Latest round share price) x (total number of company shares)
This is the industry standard Post-Money Valuation model.
Let’s illustrate how it works with an example. If a VC invests $10M for 1M shares (at $10/share), and the company has 10M shares after the round, its Post-Money Valuation is $100M (10/share x 10M shares).
This approach might seem like the most natural way to assess a business, but the model often unintentionally overstates the underlying value of the company even if the share price paid by the investor is fair. All shares aren't equal.
New investors in a corporation will always try to minimize their downside risk, or the amount they lose if things go wrong. New investors will try to negotiate better terms and pay a premium.
How the value of a struggling SpaceX increased
SpaceX's 2008 Series D is an example. Despite the financial crisis and unsuccessful rocket launches, the company's Post-Money Valuation was 36% higher after the investment round. Why?
Series D SpaceX shares were protected. In case of liquidation, Series D investors were guaranteed a 2x return before other shareholders.
Due to downside protection, investors were willing to pay a higher price for this new share class.
The Post-Money Valuation model overpriced SpaceX because it viewed all the shares as equal (they weren't).
Why entrepreneurs, workers, and early investors stand to lose the most
Post-Money Valuation is an effective and sufficient method for assessing a startup's valuation, despite not taking share class disparities into consideration.
In a robust market, where the firm valuation will certainly expand with the next fundraising round or exit, the inflated value is of little significance.
Fairness endures. If a corporation leaves at a greater valuation, each stakeholder will receive a proportional distribution. (i.e., 5% of a $100M corporation yields $5M).
SpaceX's inherent overvaluation was never a problem. Had it been sold for less than its Post-Money Valuation, some shareholders, including founders, staff, and early investors, would have seen their ownership drop.
The unforgiving world of 2022
In 2022, founders, employees, and investors who benefited from inflated values will face below-valuation exits and down-rounds.
For them, 2021 will be a curse, not a blessing.
Some tech giants are worried. Klarna's valuation fell from $45B (Oct 21) to $30B (Jun 22), Canvas from $40B to $27B, and GoPuffs from $17B to $8.3B.
Shazam and Blue Apron have to exit or IPO at a cheaper price. Premium share classes are protected, while others receive less. The same goes for bankrupts.
Those who continue at lower valuations will lose reputation and talent. When their value declines by half, generous employee stock options become less enticing, and their ability to return anything is questioned.
What can we infer about the present situation?
Such techniques to enhance your company's value or stop a normalizing market are fiction.
The current situation is a painful reminder for entrepreneurs and a crucial lesson for future firms.
The devastating market fall of the previous six months has taught us one thing:
Keep in mind that any valuation is speculative. Money Post A startup's valuation is a highly simplified approximation of its true value, particularly in the early phases when it lacks significant income or a cutting-edge product. It is merely a projection of the future and a hypothetical meter. Until it is achieved by an exit, a valuation is nothing more than a number on paper.
Assume the value of your company is lower than it was in the past. Your previous valuation might not be accurate now due to substantial changes in the startup financing markets. There is little reason to think that your company's value will remain the same given the 50%+ decline in many newly listed IT companies. Recognize how the market situation is changing and use caution.
Recognize the importance of the stake you hold. Each share class has a unique value that varies. Know the sort of share class you own and how additional contractual provisions affect the market value of your security. Frameworks have been provided by Metrick and Yasuda (Yale & UC) and Gornall and Strebulaev (Stanford) for comprehending the terms that affect investors' cash-flow rights upon withdrawal. As a result, you will be able to more accurately evaluate your firm and determine the worth of each share class.
Be wary of approving excessively protective share terms.
The trade-offs should be considered while negotiating subsequent rounds. Accepting punitive contractual terms could first seem like a smart option in order to uphold your inflated worth, but you should proceed with caution. Such provisions ALWAYS result in misaligned shareholders, with common shareholders (such as you and your staff) at the bottom of the list.