



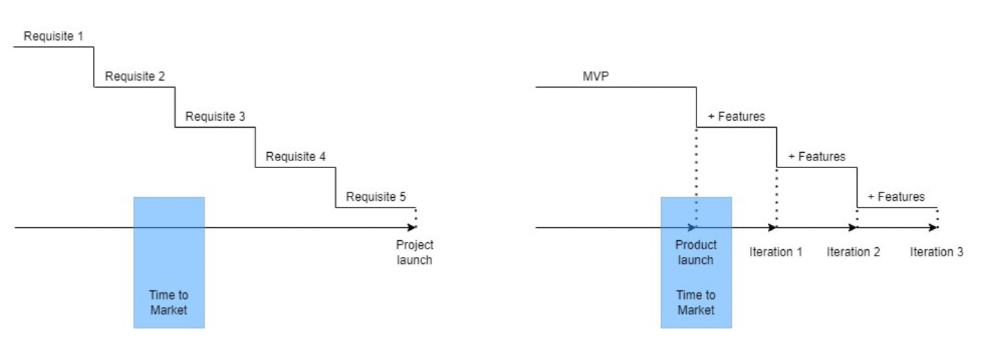
More on Entrepreneurship/Creators

Alex Mathers
3 years ago
400 articles later, nobody bothered to read them.
Writing for readers:
14 years of daily writing.
I post practically everything on social media. I authored hundreds of articles, thousands of tweets, and numerous volumes to almost no one.
Tens of thousands of readers regularly praise me.
I despised writing. I'm stuck now.
I've learned what readers like and what doesn't.
Here are some essential guidelines for writing with impact:
Readers won't understand your work if you can't.
Though obvious, this slipped me up. Share your truths.
Stories engage human brains.
Showing the journey of a person from worm to butterfly inspires the human spirit.
Overthinking hinders powerful writing.
The best ideas come from inner understanding in between thoughts.
Avoid writing to find it. Write.
Writing a masterpiece isn't motivating.
Write for five minutes to simplify. Step-by-step, entertaining, easy steps.
Good writing requires a willingness to make mistakes.
So write loads of garbage that you can edit into a good piece.
Courageous writing.
A courageous story will move readers. Personal experience is best.
Go where few dare.
Templates, outlines, and boundaries help.
Limitations enhance writing.
Excellent writing is straightforward and readable, removing all the unnecessary fat.
Use five words instead of nine.
Use ordinary words instead of uncommon ones.
Readers desire relatability.
Too much perfection will turn it off.
Write to solve an issue if you can't think of anything to write.
Instead, read to inspire. Best authors read.
Every tweet, thread, and novel must have a central idea.
What's its point?
This can make writing confusing.
️ Don't direct your reader.
Readers quit reading. Demonstrate, describe, and relate.
Even if no one responds, have fun. If you hate writing it, the reader will too.

Davlin Knight
3 years ago
2 pitfalls to stay away from when launching a YouTube channel
You do not want to miss these

Stop! Stop it! Two things to avoid when starting a YouTube channel. Critical. Possible channel-killers Its future revenue.
I'll tell you now, so don't say "I wish I knew."
The Notorious Copyright Allegation
My YouTube channel received a copyright claim before I sold it. This claim was on a one-minute video I thought I'd changed enough to make mine, but the original owner disagreed.
It cost me thousands in ad revenue. Original owner got the profits.
Well, it wasn't your video, you say.
Touché.
I've learned. Sorta
I couldn't stop looking at the video's views. The video got 1,000,000 views without any revenue. I made 4 more similar videos.
If they didn't get copyrighted, I'd be rolling in dough.
You've spent a week editing and are uploading to YouTube. You're thrilled as you stand and stretch your back. You see the video just before publishing.
No way!
The red exclamation point on checks.
Copyright claim!
YouTube lets you publish, but you won't make money.
Sounds fair? Well, it is.
Copyright claims mean you stole someone's work. Song, image, or video clip.
We wouldn't want our content used for money.
The only problem with this is that almost everything belongs to someone else. I doubt some of the biggest creators are sitting down and making their music for their videos. That just seems really excessive when you could make a quick search on YouTube and download a song (I definitely don’t do this because that would be stealing).
So how do you defeat a copyright defense?
Even copyright-free songs on YouTube aren't guaranteed. Some copyrighted songs claim to be free.
Use YouTube's free music library or pay for a subscription to adobe stock, epidemic sound, or artlist.io.
Most of my videos have Nintendo music. Almost all game soundtracks are copyright-free and offer a variety of songs.
Restriction on age
Age restrictions are a must-avoid. A channel dies.
YouTube never suggests age-restricted videos.
Shadow banning means YouTube hides your content from subscribers and non-subscribers.
Keeping your channel family-friendly can help.
I hear you complaining that your channel isn't for kids. I agree. Not everyone has a clean mouth or creates content for minors.
YouTube has changed rapidly in recent years. Focusing on kids. Fewer big creators are using profanity or explicit content in videos. Not YouTube-worthy.
Youtube wants to be family-friendly. A family-friendly movie. It won't promote illegal content. Yes, it allows profanity.

Do I recommend avoiding no-no words in videos? Never. Okay. YouTube's policies are shaky. YouTube uses video content to determine ad suitability.
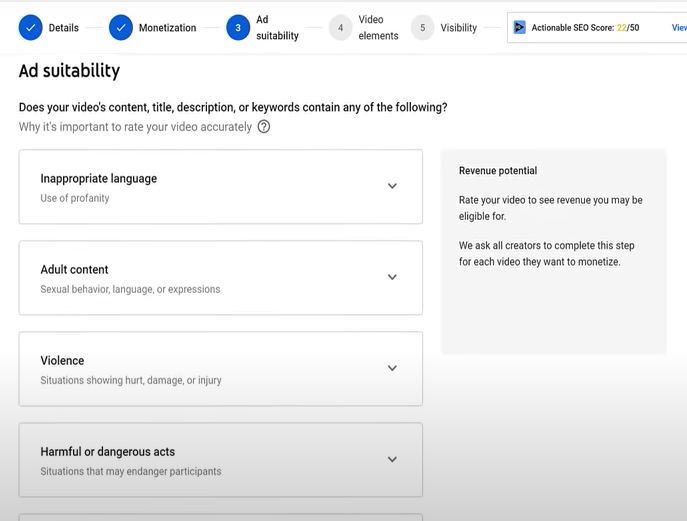
No joke. If you're serious about becoming a content creator, avoid profanity and inappropriate topics.
If your channel covers 18+ topics, like crime or commentary, censor as much as possible.
YouTube can be like walking on eggshells. You never know what is gonna upset the boss. So play it safe and try to avoid getting on their bad side.
Mr. Beast, Dream, Markplier, Faze Rug, and PewDewPie are popular creators. They maintain it family-friendly while entertaining fans.
You got this.

Scrum Ventures
3 years ago
Trends from the Winter 2022 Demo Day at Y Combinators

Y Combinators Winter 2022 Demo Day continues the trend of more startups engaging in accelerator Demo Days. Our team evaluated almost 400 projects in Y Combinator's ninth year.
After Winter 2021 Demo Day, we noticed a hurry pushing shorter rounds, inflated valuations, and larger batches.
Despite the batch size, this event's behavior showed a return to normalcy. Our observations show that investors evaluate and fund businesses more carefully. Unlike previous years, more YC businesses gave investors with data rooms and thorough pitch decks in addition to valuation data before Demo Day.
Demo Day pitches were virtual and fast-paced, limiting unplanned meetings. Investors had more time and information to do their due research before meeting founders. Our staff has more time to study diverse areas and engage with interesting entrepreneurs and founders.
This was one of the most regionally diversified YC cohorts to date. This year's Winter Demo Day startups showed some interesting tendencies.
Trends and Industries to Watch Before Demo Day
Demo day events at any accelerator show how investment competition is influencing startups. As startups swiftly become scale-ups and big success stories in fintech, e-commerce, healthcare, and other competitive industries, entrepreneurs and early-stage investors feel pressure to scale quickly and turn a notion into actual innovation.
Too much eagerness can lead founders to focus on market growth and team experience instead of solid concepts, technical expertise, and market validation. Last year, YC Winter Demo Day funding cycles ended too quickly and valuations were unrealistically high.
Scrum Ventures observed a longer funding cycle this year compared to last year's Demo Day. While that seems promising, many factors could be contributing to change, including:
Market patterns are changing and the economy is becoming worse.
the industries that investors are thinking about.
Individual differences between each event batch and the particular businesses and entrepreneurs taking part
The Winter 2022 Batch's Trends
Each year, we also wish to examine trends among early-stage firms and YC event participants. More international startups than ever were anticipated to present at Demo Day.
Less than 50% of demo day startups were from the U.S. For the S21 batch, firms from outside the US were most likely in Latin America or Europe, however this year's batch saw a large surge in startups situated in Asia and Africa.
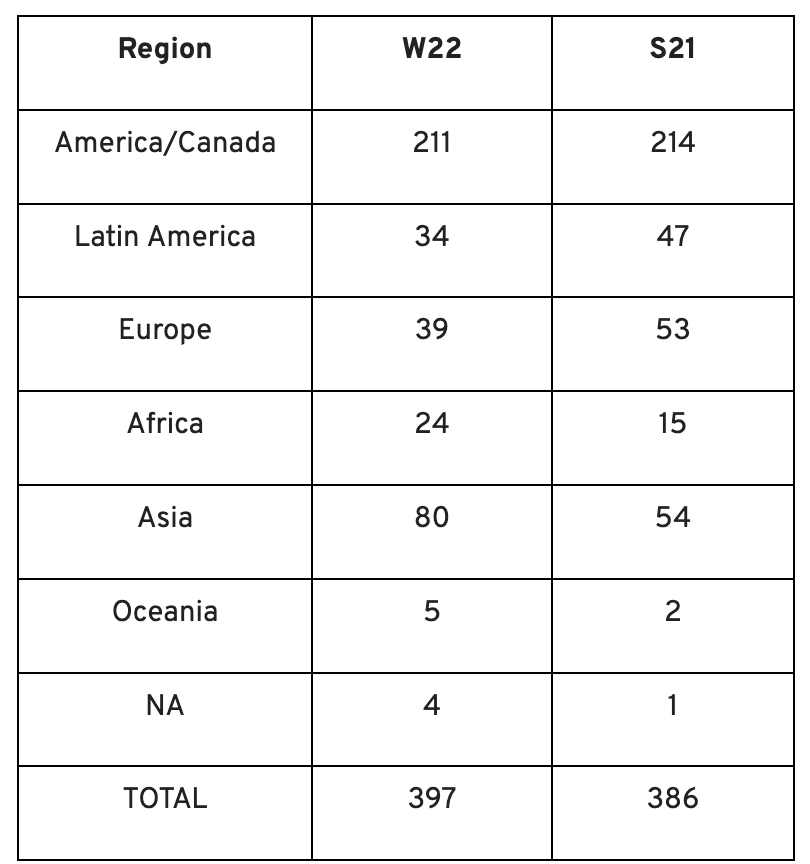
YC Startup Directory
163 out of 399 startups were B2B software and services companies. Financial, healthcare, and consumer startups were common.
Our team doesn't plan to attend every pitch or speak with every startup's founders or team members. Let's look at cleantech, Web3, and health and wellness startup trends.
Our Opinions Following Conversations with 87 Startups at Demo Day
In the lead-up to Demo Day, we spoke with 87 of the 125 startups going. Compared to B2C enterprises, B2B startups had higher average valuations. A few outliers with high valuations pushed B2B and B2C means above the YC-wide mean and median.
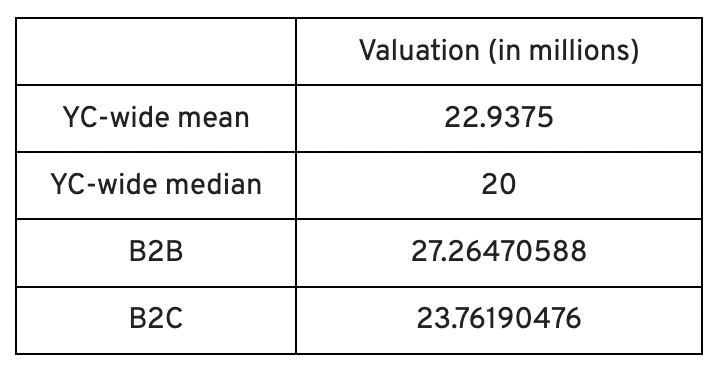
Many of these startups develop business and technology solutions we've previously covered. We've seen API, EdTech, creative platforms, and cybersecurity remain strong and increase each year.
While these persistent tendencies influenced the startups Scrum Ventures looked at and the founders we interacted with on Demo Day, new trends required more research and preparation. Let's examine cleantech, Web3, and health and wellness startups.
Hardware and software that is green
Cleantech enterprises demand varying amounts of funding for hardware and software. Although the same overarching trend is fueling the growth of firms in this category, each subgroup has its own strategy and technique for investigation and identifying successful investments.
Many cleantech startups we spoke to during the YC event are focused on helping industrial operations decrease or recycle carbon emissions.
Carbon Crusher: Creating carbon negative roads
Phase Biolabs: Turning carbon emissions into carbon negative products and carbon neutral e-fuels
Seabound: Capturing carbon dioxide emissions from ships
Fleetzero: Creating electric cargo ships
Impossible Mining: Sustainable seabed mining
Beyond Aero: Creating zero-emission private aircraft
Verdn: Helping businesses automatically embed environmental pledges for product and service offerings, boost customer engagement
AeonCharge: Allowing electric vehicle (EV) drivers to more easily locate and pay for EV charging stations
Phoenix Hydrogen: Offering a hydrogen marketplace and a connected hydrogen hub platform to connect supply and demand for hydrogen fuel and simplify hub planning and partner program expansion
Aklimate: Allowing businesses to measure and reduce their supply chain’s environmental impact
Pina Earth: Certifying and tracking the progress of businesses’ forestry projects
AirMyne: Developing machines that can reverse emissions by removing carbon dioxide from the air
Unravel Carbon: Software for enterprises to track and reduce their carbon emissions
Web3: NFTs, the metaverse, and cryptocurrency
Web3 technologies handle a wide range of business issues. This category includes companies employing blockchain technology to disrupt entertainment, finance, cybersecurity, and software development.
Many of these startups overlap with YC's FinTech trend. Despite this, B2C and B2B enterprises were evenly represented in Web3. We examined:
Stablegains: Offering consistent interest on cash balance from the decentralized finance (DeFi) market
LiquiFi: Simplifying token management with automated vesting contracts, tax reporting, and scheduling. For companies, investors, and finance & accounting
NFTScoring: An NFT trading platform
CypherD Wallet: A multichain wallet for crypto and NFTs with a non-custodial crypto debit card that instantly converts coins to USD
Remi Labs: Allowing businesses to more easily create NFT collections that serve as access to products, memberships, events, and more
Cashmere: A crypto wallet for Web3 startups to collaboratively manage funds
Chaingrep: An API that makes blockchain data human-readable and tokens searchable
Courtyard: A platform for securely storing physical assets and creating 3D representations as NFTs
Arda: “Banking as a Service for DeFi,” an API that FinTech companies can use to embed DeFi products into their platforms
earnJARVIS: A premium cryptocurrency management platform, allowing users to create long-term portfolios
Mysterious: Creating community-specific experiences for Web3 Discords
Winter: An embeddable widget that allows businesses to sell NFTs to users purchasing with a credit card or bank transaction
SimpleHash: An API for NFT data that provides compatibility across blockchains, standardized metadata, accurate transaction info, and simple integration
Lifecast: Tools that address motion sickness issues for 3D VR video
Gym Class: Virtual reality (VR) multiplayer basketball video game
WorldQL: An asset API that allows NFT creators to specify multiple in-game interpretations of their assets, increasing their value
Bonsai Desk: A software development kit (SDK) for 3D analytics
Campfire: Supporting virtual social experiences for remote teams
Unai: A virtual headset and Visual World experience
Vimmerse: Allowing creators to more easily create immersive 3D experiences
Fitness and health
Scrum Ventures encountered fewer health and wellness startup founders than Web3 and Cleantech. The types of challenges these organizations solve are still diverse. Several of these companies are part of a push toward customization in healthcare, an area of biotech set for growth for companies with strong portfolios and experienced leadership.
Here are several startups we considered:
Syrona Health: Personalized healthcare for women in the workplace
Anja Health: Personalized umbilical cord blood banking and stem cell preservation
Alfie: A weight loss program focused on men’s health that coordinates medical care, coaching, and “community-based competition” to help users lose an average of 15% body weight
Ankr Health: An artificial intelligence (AI)-enabled telehealth platform that provides personalized side effect education for cancer patients and data collection for their care teams
Koko — A personalized sleep program to improve at-home sleep analysis and training
Condition-specific telehealth platforms and programs:
Reviving Mind: Chronic care management covered by insurance and supporting holistic, community-oriented health care
Equipt Health: At-home delivery of prescription medical equipment to help manage chronic conditions like obstructive sleep apnea
LunaJoy: Holistic women’s healthcare management for mental health therapy, counseling, and medication
12 Startups from YC's Winter 2022 Demo Day to Watch
Bobidi: 10x faster AI model improvement
Artificial intelligence (AI) models have become a significant tool for firms to improve how well and rapidly they process data. Bobidi helps AI-reliant firms evaluate their models, boosting data insights in less time and reducing data analysis expenditures. The business has created a gamified community that offers a bug bounty for AI, incentivizing community members to test and find weaknesses in clients' AI models.
Magna: DeFi investment management and token vesting
Magna delivers rapid, secure token vesting so consumers may turn DeFi investments into primitives. Carta for Web3 allows enterprises to effortlessly distribute tokens to staff or investors. The Magna team hopes to allow corporations use locked tokens as collateral for loans, facilitate secondary liquidity so investors can sell shares on a public exchange, and power additional DeFi applications.
Perl Street: Funding for infrastructure
This Fintech firm intends to help hardware entrepreneurs get financing by [democratizing] structured finance, unleashing billions for sustainable infrastructure and next-generation hardware solutions. This network has helped hardware entrepreneurs achieve more than $140 million in finance, helping companies working on energy storage devices, EVs, and creating power infrastructure.
CypherD: Multichain cryptocurrency wallet
CypherD seeks to provide a multichain crypto wallet so general customers can explore Web3 products without knowledge hurdles. The startup's beta app lets consumers access crypto from EVM blockchains. The founders have crypto, financial, and startup experience.
Unravel Carbon: Enterprise carbon tracking and offsetting
Unravel Carbon's AI-powered decarbonization technology tracks companies' carbon emissions. Singapore-based startup focuses on Asia. The software can use any company's financial data to trace the supply chain and calculate carbon tracking, which is used to make regulatory disclosures and suggest carbon offsets.
LunaJoy: Precision mental health for women
LunaJoy helped women obtain mental health support throughout life. The platform combines data science to create a tailored experience, allowing women to access psychotherapy, medication management, genetic testing, and health coaching.
Posh: Automated EV battery recycling
Posh attempts to solve one of the EV industry's largest logistical difficulties. Millions of EV batteries will need to be decommissioned in the next decade, and their precious metals and residual capacity will go unused for some time. Posh offers automated, scalable lithium battery disassembly, making EV battery recycling more viable.
Unai: VR headset with 5x higher resolution
Unai stands apart from metaverse companies. Its VR headgear has five times the resolution of existing options and emphasizes human expression and interaction in a remote world. Maxim Perumal's method of latency reduction powers current VR headsets.
Palitronica: Physical infrastructure cybersecurity
Palitronica blends cutting-edge hardware and software to produce networked electronic systems that support crucial physical and supply chain infrastructure. The startup's objective is to build solutions that defend national security and key infrastructure from cybersecurity threats.
Reality Defender: Deepfake detection
Reality Defender alerts firms to bogus users and changed audio, video, and image files. Reality Deference's API and web app score material in real time to prevent fraud, improve content moderation, and detect deception.
Micro Meat: Infrastructure for the manufacture of cell-cultured meat
MicroMeat promotes sustainable meat production. The company has created technologies to scale up bioreactor-grown meat muscle tissue from animal cells. Their goal is to scale up cultured meat manufacturing so cultivated meat products can be brought to market feasibly and swiftly, boosting worldwide meat consumption.
Fleetzero: Electric cargo ships
This startup's battery technology will make cargo ships more sustainable and profitable. Fleetzero's electric cargo ships have five times larger profit margins than fossil fuel ships. Fleetzeros' founder has marine engineering, ship operations, and enterprise sales and business experience.
You might also like

Ashraful Islam
4 years ago
Clean API Call With React Hooks
| Photo by Juanjo Jaramillo on Unsplash |
Calling APIs is the most common thing to do in any modern web application. When it comes to talking with an API then most of the time we need to do a lot of repetitive things like getting data from an API call, handling the success or error case, and so on.
When calling tens of hundreds of API calls we always have to do those tedious tasks. We can handle those things efficiently by putting a higher level of abstraction over those barebone API calls, whereas in some small applications, sometimes we don’t even care.
The problem comes when we start adding new features on top of the existing features without handling the API calls in an efficient and reusable manner. In that case for all of those API calls related repetitions, we end up with a lot of repetitive code across the whole application.
In React, we have different approaches for calling an API. Nowadays mostly we use React hooks. With React hooks, it’s possible to handle API calls in a very clean and consistent way throughout the application in spite of whatever the application size is. So let’s see how we can make a clean and reusable API calling layer using React hooks for a simple web application.
I’m using a code sandbox for this blog which you can get here.
import "./styles.css";
import React, { useEffect, useState } from "react";
import axios from "axios";
export default function App() {
const [posts, setPosts] = useState(null);
const [error, setError] = useState("");
const [loading, setLoading] = useState(false);
useEffect(() => {
handlePosts();
}, []);
const handlePosts = async () => {
setLoading(true);
try {
const result = await axios.get(
"https://jsonplaceholder.typicode.com/posts"
);
setPosts(result.data);
} catch (err) {
setError(err.message || "Unexpected Error!");
} finally {
setLoading(false);
}
};
return (
<div className="App">
<div>
<h1>Posts</h1>
{loading && <p>Posts are loading!</p>}
{error && <p>{error}</p>}
<ul>
{posts?.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
</div>
</div>
);
}
I know the example above isn’t the best code but at least it’s working and it’s valid code. I will try to improve that later. For now, we can just focus on the bare minimum things for calling an API.
Here, you can try to get posts data from JsonPlaceholer. Those are the most common steps we follow for calling an API like requesting data, handling loading, success, and error cases.
If we try to call another API from the same component then how that would gonna look? Let’s see.
500: Internal Server Error
Now it’s going insane! For calling two simple APIs we’ve done a lot of duplication. On a top-level view, the component is doing nothing but just making two GET requests and handling the success and error cases. For each request, it’s maintaining three states which will periodically increase later if we’ve more calls.
Let’s refactor to make the code more reusable with fewer repetitions.
Step 1: Create a Hook for the Redundant API Request Codes
Most of the repetitions we have done so far are about requesting data, handing the async things, handling errors, success, and loading states. How about encapsulating those things inside a hook?
The only unique things we are doing inside handleComments and handlePosts are calling different endpoints. The rest of the things are pretty much the same. So we can create a hook that will handle the redundant works for us and from outside we’ll let it know which API to call.
500: Internal Server Error
Here, this request function is identical to what we were doing on the handlePosts and handleComments. The only difference is, it’s calling an async function apiFunc which we will provide as a parameter with this hook. This apiFunc is the only independent thing among any of the API calls we need.
With hooks in action, let’s change our old codes in App component, like this:
500: Internal Server Error
How about the current code? Isn’t it beautiful without any repetitions and duplicate API call handling things?
Let’s continue our journey from the current code. We can make App component more elegant. Now it knows a lot of details about the underlying library for the API call. It shouldn’t know that. So, here’s the next step…
Step 2: One Component Should Take Just One Responsibility
Our App component knows too much about the API calling mechanism. Its responsibility should just request the data. How the data will be requested under the hood, it shouldn’t care about that.
We will extract the API client-related codes from the App component. Also, we will group all the API request-related codes based on the API resource. Now, this is our API client:
import axios from "axios";
const apiClient = axios.create({
// Later read this URL from an environment variable
baseURL: "https://jsonplaceholder.typicode.com"
});
export default apiClient;
All API calls for comments resource will be in the following file:
import client from "./client";
const getComments = () => client.get("/comments");
export default {
getComments
};
All API calls for posts resource are placed in the following file:
import client from "./client";
const getPosts = () => client.get("/posts");
export default {
getPosts
};
Finally, the App component looks like the following:
import "./styles.css";
import React, { useEffect } from "react";
import commentsApi from "./api/comments";
import postsApi from "./api/posts";
import useApi from "./hooks/useApi";
export default function App() {
const getPostsApi = useApi(postsApi.getPosts);
const getCommentsApi = useApi(commentsApi.getComments);
useEffect(() => {
getPostsApi.request();
getCommentsApi.request();
}, []);
return (
<div className="App">
{/* Post List */}
<div>
<h1>Posts</h1>
{getPostsApi.loading && <p>Posts are loading!</p>}
{getPostsApi.error && <p>{getPostsApi.error}</p>}
<ul>
{getPostsApi.data?.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
</div>
{/* Comment List */}
<div>
<h1>Comments</h1>
{getCommentsApi.loading && <p>Comments are loading!</p>}
{getCommentsApi.error && <p>{getCommentsApi.error}</p>}
<ul>
{getCommentsApi.data?.map((comment) => (
<li key={comment.id}>{comment.name}</li>
))}
</ul>
</div>
</div>
);
}
Now it doesn’t know anything about how the APIs get called. Tomorrow if we want to change the API calling library from axios to fetch or anything else, our App component code will not get affected. We can just change the codes form client.js This is the beauty of abstraction.
Apart from the abstraction of API calls, Appcomponent isn’t right the place to show the list of the posts and comments. It’s a high-level component. It shouldn’t handle such low-level data interpolation things.
So we should move this data display-related things to another low-level component. Here I placed those directly in the App component just for the demonstration purpose and not to distract with component composition-related things.
Final Thoughts
The React library gives the flexibility for using any kind of third-party library based on the application’s needs. As it doesn’t have any predefined architecture so different teams/developers adopted different approaches to developing applications with React. There’s nothing good or bad. We choose the development practice based on our needs/choices. One thing that is there beyond any choices is writing clean and maintainable codes.

Shan Vernekar
3 years ago
How the Ethereum blockchain's transactions are carried out
Overview
Ethereum blockchain is a network of nodes that validate transactions. Any network node can be queried for blockchain data for free. To write data as a transition requires processing and writing to each network node's storage. Fee is paid in ether and is also called as gas.
We'll examine how user-initiated transactions flow across the network and into the blockchain.
Flow of transactions
A user wishes to move some ether from one external account to another. He utilizes a cryptocurrency wallet for this (like Metamask), which is a browser extension.
The user enters the desired transfer amount and the external account's address. He has the option to choose the transaction cost he is ready to pay.
Wallet makes use of this data, signs it with the user's private key, and writes it to an Ethereum node. Services such as Infura offer APIs that enable writing data to nodes. One of these services is used by Metamask. An example transaction is shown below. Notice the “to” address and value fields.
var rawTxn = {
nonce: web3.toHex(txnCount),
gasPrice: web3.toHex(100000000000),
gasLimit: web3.toHex(140000),
to: '0x633296baebc20f33ac2e1c1b105d7cd1f6a0718b',
value: web3.toHex(0),
data: '0xcc9ab24952616d6100000000000000000000000000000000000000000000000000000000'
};The transaction is written to the target Ethereum node's local TRANSACTION POOL. It informed surrounding nodes of the new transaction, and those nodes reciprocated. Eventually, this transaction is received by and written to each node's local TRANSACTION pool.
The miner who finds the following block first adds pending transactions (with a higher gas cost) from the nearby TRANSACTION POOL to the block.
The transactions written to the new block are verified by other network nodes.
A block is added to the main blockchain after there is consensus and it is determined to be genuine. The local blockchain is updated with the new node by additional nodes as well.
Block mining begins again next.
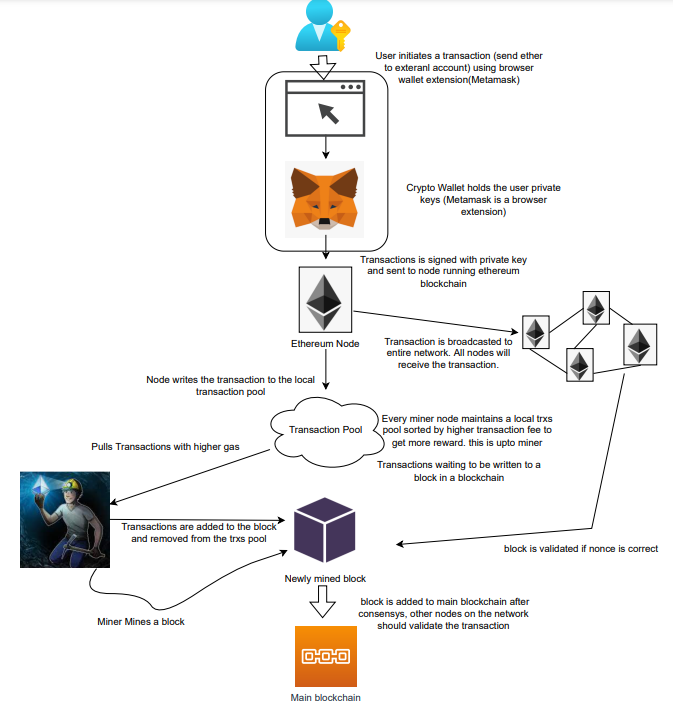
The image above shows how transactions go via the network and what's needed to submit them to the main block chain.
References
ethereum.org/transactions How Ethereum transactions function, their data structure, and how to send them via app. ethereum.org

Ivona Hirschi
3 years ago
7 LinkedIn Tips That Will Help in Audience Growth
In 8 months, I doubled my audience with them.

LinkedIn's buzz isn't over.
People dream of social proof every day. They want clients, interesting jobs, and field recognition.
LinkedIn coaches will benefit greatly. Sell learning? Probably. Can you use it?
Consistency has been key in my eight-month study of LinkedIn. However, I'll share seven of my tips. 700 to 4500 people followed me.
1. Communication, communication, communication
LinkedIn is a social network. I like to think of it as a cafe. Here, you can share your thoughts, meet friends, and discuss life and work.
Do not treat LinkedIn as if it were a board for your post-its.
More socializing improves relationships. It's about people, like any network.
Consider interactions. Three main areas:
Respond to criticism left on your posts.
Comment on other people's posts
Start and maintain conversations through direct messages.
Engage people. You spend too much time on Facebook if you only read your wall. Keeping in touch and having meaningful conversations helps build your network.
Every day, start a new conversation to make new friends.
2. Stick with those you admire
Interact thoughtfully.
Choose your contacts. Build your tribe is a term. Respectful networking.
I only had past colleagues, family, and friends in my network at the start of this year. Not business-friendly. Since then, I've sought out people I admire or can learn from.
Finding a few will help you. As they connect you to their networks. Friendships can lead to clients.
Don't underestimate network power. Cafe-style. Meet people at each table. But avoid people who sell SEO, web redesign, VAs, mysterious job opportunities, etc.
3. Share eye-catching infographics
Daily infographics flood LinkedIn. Visuals are popular. Use Canva's free templates if you can't draw them.
Last week's:

It's a fun way to visualize your topic.
You can repost and comment on infographics. Involve your network. I prefer making my own because I build my brand around certain designs.
My friend posted infographics consistently for four months and grew his network to 30,000.
If you start, credit the authors. As you steal someone's work.
4. Invite some friends over.
LinkedIn alone can be lonely. Having a few friends who support your work daily will boost your growth.
I was lucky to be invited to a group of networkers. We share knowledge and advice.
Having a few regulars who can discuss your posts is helpful. It's artificial, but it works and engages others.
Consider who you'd support if they were in your shoes.
You can pay for an engagement group, but you risk supporting unrelated people with rubbish posts.
Help each other out.
5. Don't let your feed or algorithm divert you.
LinkedIn's algorithm is magical.
Which time is best? How fast do you need to comment? Which days are best?
Overemphasize algorithms. Consider the user. No need to worry about the best time.
Remember to spend time on LinkedIn actively. Not passively. That is what Facebook is for.
Surely someone would find a LinkedIn recipe. Don't beat the algorithm yet. Consider your audience.
6. The more personal, the better
Personalization isn't limited to selfies. Share your successes and failures.
The more personality you show, the better.
People relate to others, not theories or quotes. Why should they follow you? Everyone posts the same content?
Consider your friends. What's their appeal?
Because they show their work and identity. It's simple. Medium and Linkedin are your platforms. Find out what works.
You can copy others' hooks and structures. You decide how simple to make it, though.
7. Have fun with those who have various post structures.
I like writing, infographics, videos, and carousels. Because you can:
Repurpose your content!
Out of one blog post I make:
Newsletter
Infographics (positive and negative points of view)
Carousel
Personal stories
Listicle
Create less but more variety. Since LinkedIn posts last 24 hours, you can rotate the same topics for weeks without anyone noticing.
Effective!
The final LI snippet to think about
LinkedIn is about consistency. Some say 15 minutes. If you're serious about networking, spend more time there.
The good news is that it is worth it. The bad news is that it takes time.