


Why Is Blockchain So Popular?
What is Bitcoin?
The blockchain is a shared, immutable ledger that helps businesses record transactions and track assets. The blockchain can track tangible assets like cars, houses, and land. Tangible assets like intellectual property can also be tracked on the blockchain.
Imagine a blockchain as a distributed database split among computer nodes. A blockchain stores data in blocks. When a block is full, it is closed and linked to the next. As a result, all subsequent information is compiled into a new block that will be added to the chain once it is filled.
The blockchain is designed so that adding a transaction requires consensus. That means a majority of network nodes must approve a transaction. No single authority can control transactions on the blockchain. The network nodes use cryptographic keys and passwords to validate each other's transactions.
Blockchain History
The blockchain was not as popular in 1991 when Stuart Haber and W. Scott Stornetta worked on it. The blocks were designed to prevent tampering with document timestamps. Stuart Haber and W. Scott Stornetta improved their work in 1992 by using Merkle trees to increase efficiency and collect more documents on a single block.
In 2004, he developed Reusable Proof of Work. This system allows users to verify token transfers in real time. Satoshi Nakamoto invented distributed blockchains in 2008. He improved the blockchain design so that new blocks could be added to the chain without being signed by trusted parties.
Satoshi Nakomoto mined the first Bitcoin block in 2009, earning 50 Bitcoins. Then, in 2013, Vitalik Buterin stated that Bitcoin needed a scripting language for building decentralized applications. He then created Ethereum, a new blockchain-based platform for decentralized apps. Since the Ethereum launch in 2015, different blockchain platforms have been launched: from Hyperledger by Linux Foundation, EOS.IO by block.one, IOTA, NEO and Monero dash blockchain. The block chain industry is still growing, and so are the businesses built on them.
Blockchain Components
The Blockchain is made up of many parts:
1. Node: The node is split into two parts: full and partial. The full node has the authority to validate, accept, or reject any transaction. Partial nodes or lightweight nodes only keep the transaction's hash value. It doesn't keep a full copy of the blockchain, so it has limited storage and processing power.
2. Ledger: A public database of information. A ledger can be public, decentralized, or distributed. Anyone on the blockchain can access the public ledger and add data to it. It allows each node to participate in every transaction. The distributed ledger copies the database to all nodes. A group of nodes can verify transactions or add data blocks to the blockchain.
3. Wallet: A blockchain wallet allows users to send, receive, store, and exchange digital assets, as well as monitor and manage their value. Wallets come in two flavors: hardware and software. Online or offline wallets exist. Online or hot wallets are used when online. Without an internet connection, offline wallets like paper and hardware wallets can store private keys and sign transactions. Wallets generally secure transactions with a private key and wallet address.
4. Nonce: A nonce is a short term for a "number used once''. It describes a unique random number. Nonces are frequently generated to modify cryptographic results. A nonce is a number that changes over time and is used to prevent value reuse. To prevent document reproduction, it can be a timestamp. A cryptographic hash function can also use it to vary input. Nonces can be used for authentication, hashing, or even electronic signatures.
5. Hash: A hash is a mathematical function that converts inputs of arbitrary length to outputs of fixed length. That is, regardless of file size, the hash will remain unique. A hash cannot generate input from hashed output, but it can identify a file. Hashes can be used to verify message integrity and authenticate data. Cryptographic hash functions add security to standard hash functions, making it difficult to decipher message contents or track senders.
Blockchain: Pros and Cons
The blockchain provides a trustworthy, secure, and trackable platform for business transactions quickly and affordably. The blockchain reduces paperwork, documentation errors, and the need for third parties to verify transactions.
Blockchain security relies on a system of unaltered transaction records with end-to-end encryption, reducing fraud and unauthorized activity. The blockchain also helps verify the authenticity of items like farm food, medicines, and even employee certification. The ability to control data gives users a level of privacy that no other platform can match.
In the case of Bitcoin, the blockchain can only handle seven transactions per second. Unlike Hyperledger and Visa, which can handle ten thousand transactions per second. Also, each participant node must verify and approve transactions, slowing down exchanges and limiting scalability.
The blockchain requires a lot of energy to run. In addition, the blockchain is not a hugely distributable system and it is destructible. The security of the block chain can be compromised by hackers; it is not completely foolproof. Also, since blockchain entries are immutable, data cannot be removed. The blockchain's high energy consumption and limited scalability reduce its efficiency.
Why Is Blockchain So Popular?
The blockchain is a technology giant. In 2018, 90% of US and European banks began exploring blockchain's potential. In 2021, 24% of companies are expected to invest $5 million to $10 million in blockchain. By the end of 2024, it is expected that corporations will spend $20 billion annually on blockchain technical services.
Blockchain is used in cryptocurrency, medical records storage, identity verification, election voting, security, agriculture, business, and many other fields. The blockchain offers a more secure, decentralized, and less corrupt system of making global payments, which cryptocurrency enthusiasts love. Users who want to save time and energy prefer it because it is faster and less bureaucratic than banking and healthcare systems.
Most organizations have jumped on the blockchain bandwagon, and for good reason: the blockchain industry has never had more potential. The launch of IBM's Blockchain Wire, Paystack, Aza Finance and Bloom are visible proof of the wonders that the blockchain has done. The blockchain's cryptocurrency segment may not be as popular in the future as the blockchain's other segments, as evidenced by the various industries where it is used. The blockchain is here to stay, and it will be discussed for a long time, not just in tech, but in many industries.
Read original post here
More on Web3 & Crypto

Sam Bourgi
3 years ago
DAOs are legal entities in Marshall Islands.
The Pacific island state recognizes decentralized autonomous organizations.
The Republic of the Marshall Islands has recognized decentralized autonomous organizations (DAOs) as legal entities, giving collectively owned and managed blockchain projects global recognition.
The Marshall Islands' amended the Non-Profit Entities Act 2021 that now recognizes DAOs, which are blockchain-based entities governed by self-organizing communities. Incorporating Admiralty LLC, the island country's first DAO, was made possible thanks to the amendement. MIDAO Directory Services Inc., a domestic organization established to assist DAOs in the Marshall Islands, assisted in the incorporation.
The new law currently allows any DAO to register and operate in the Marshall Islands.
“This is a unique moment to lead,” said Bobby Muller, former Marshall Islands chief secretary and co-founder of MIDAO. He believes DAOs will help create “more efficient and less hierarchical” organizations.
A global hub for DAOs, the Marshall Islands hopes to become a global hub for DAO registration, domicile, use cases, and mass adoption. He added:
"This includes low-cost incorporation, a supportive government with internationally recognized courts, and a technologically open environment."
According to the World Bank, the Marshall Islands is an independent island state in the Pacific Ocean near the Equator. To create a blockchain-based cryptocurrency that would be legal tender alongside the US dollar, the island state has been actively exploring use cases for digital assets since at least 2018.
In February 2018, the Marshall Islands approved the creation of a new cryptocurrency, Sovereign (SOV). As expected, the IMF has criticized the plan, citing concerns that a digital sovereign currency would jeopardize the state's financial stability. They have also criticized El Salvador, the first country to recognize Bitcoin (BTC) as legal tender.
Marshall Islands senator David Paul said the DAO legislation does not pose the same issues as a government-backed cryptocurrency. “A sovereign digital currency is financial and raises concerns about money laundering,” . This is more about giving DAOs legal recognition to make their case to regulators, investors, and consumers.

CyberPunkMetalHead
3 years ago
I talked to ChatGPT about the adoption of cryptocurrencies.

OpenAI's ChatGPT is an amazing AI-powered chatbot. It can write poetry, fiction, and marketing ideas. I was impressed how well ChatGPT followed the interview, albeit there were a few classics “I’m afraid I can’t do that”.
Full interview below.
Me: I'm your interviewer. We'll discuss crypto. Thanks for being interviewed. What do you think about cryptocurrency?
CGPT: Cryptocurrency is an innovative technology that could transform money and financial activities. It might boost the efficiency and security of financial institutions and let consumers deal directly without banks. Cryptocurrency is still a new and untested technology with many unknowns and hurdles before it can be broadly accepted.
Me: Over 22,000 cryptocurrencies exist, and many have little use. We need how much cryptocurrencies?
CGPT: The appropriate quantity will rely on a multitude of factors, including each cryptocurrency's use cases, adoption rate, and market rivalry. Only a few cryptocurrencies will likely receive widespread adoption and be successful. Many existing cryptocurrencies may not survive since they can't deliver new or valued solutions or compete with more established cryptocurrencies.
Me: Will cryptocurrencies grow? What's next for worldwide adoption?
CGPT: It's hard to forecast the future of cryptocurrencies because the acceptance of new technologies is unpredictable. I believe cryptocurrencies will expand and acquire popularity in the future years. Regulatory ambiguity, security concerns, and scalability issues must be overcome for this to happen. Cryptocurrency companies and organizations must engage together with governments and authorities to address these obstacles and establish a growth-friendly climate. Continued innovation and improvement of the technology, including public education and awareness, will drive acceptance.
Me: Do bear markets affect bitcoin adoption?
CGPT: On the one hand, a bear market might induce uncertainty and hesitation among potential consumers. Bear markets can present opportunities for long-term investors who can acquire cryptocurrencies at cheaper prices and are more likely to hang onto their assets. A bear market can also test the tenacity and power of the underlying technology and community, which can boost long-term confidence and adoption. A bear market might have profound and nuanced effects on bitcoin adoption.
Me: What are some likely outcomes if Bitcoin reaches $100,000 by next year?
CGPT: If Bitcoin saw rapid growth, it would undoubtedly have repercussions for the cryptocurrency market and economy. Possible scenarios include increased public interest and awareness of cryptocurrency, a surge in demand for Bitcoin and other cryptocurrencies, and a growth in the cryptocurrency industry's market value. By shifting their focus and cash to the cryptocurrency market, investors and traders may also affect other asset classes, such as traditional equities and commodities. Governments and financial organizations may focus more on the cryptocurrency sector as they try to grasp Bitcoin's rapid rise.
Me: Will other countries accept crypto as currency?
CGPT: It's hard to say if additional governments will adopt cryptocurrencies as legal tender. Some countries have recognized the promise of bitcoin and are exploring its use, while others are cautious. Adoption of bitcoin as legal cash may vary by country, based on financial infrastructure, rules, and political atmosphere. As cryptocurrency technology evolves and becomes more accepted, more governments may embrace it as legal tender.
Me: Final question: will the recent cryptocurrency hacks affect long term adoption?
CGPT: Hacks might tarnish cryptocurrency's reputation and public faith in its security, the technology underpinning it is continually improving. Many cryptocurrency projects have developed strong security mechanisms to prevent hacks and other dangers, and these safeguards will undoubtedly improve over time. The decentralized nature of cryptocurrency makes it more resistant to attacks. Hacks and other security breaches are a concern, but they may not affect cryptocurrency adoption.

Alex Bentley
3 years ago
Why Bill Gates thinks Bitcoin, crypto, and NFTs are foolish
Microsoft co-founder Bill Gates assesses digital assets while the bull is caged.

Bill Gates is well-respected.
Reasonably. He co-founded and led Microsoft during its 1980s and 1990s revolution.
After leaving Microsoft, Bill Gates pursued other interests. He and his wife founded one of the world's largest philanthropic organizations, Bill & Melinda Gates Foundation. He also supports immunizations, population control, and other global health programs.
When Gates criticized Bitcoin, cryptocurrencies, and NFTs, it made news.
Bill Gates said at the 58th Munich Security Conference...
“You have an asset class that’s 100% based on some sort of greater fool theory that somebody’s going to pay more for it than I do.”
Gates means digital assets. Like many bitcoin critics, he says digital coins and tokens are speculative.
And he's not alone. Financial experts have dubbed Bitcoin and other digital assets a "bubble" for a decade.
Gates also made fun of Bored Ape Yacht Club and NFTs, saying, "Obviously pricey digital photographs of monkeys will help the world."
Why does Bill Gates dislike digital assets?
According to Gates' latest comments, Bitcoin, cryptos, and NFTs aren't good ways to hold value.
Bill Gates is a better investor than Elon Musk.
“I’m used to asset classes, like a farm where they have output, or like a company where they make products,” Gates said.
The Guardian claimed in April 2021 that Bill and Melinda Gates owned the most U.S. farms. Over 242,000 acres of farmland.
The Gates couple has enough farmland to cover Hong Kong.

Bill Gates is a classic investor. He wants companies with an excellent track record, strong fundamentals, and good management. Or tangible assets like land and property.
Gates prefers the "old economy" over the "new economy"
Gates' criticism of Bitcoin and cryptocurrency ventures isn't surprising. These digital assets lack all of Gates's investing criteria.
Volatile digital assets include Bitcoin. Their costs might change dramatically in a day. Volatility scares risk-averse investors like Gates.
Gates has a stake in the old financial system. As Microsoft's co-founder, Gates helped develop a dominant tech company.
Because of his business, he's one of the world's richest men.
Bill Gates is invested in protecting the current paradigm.
He won't invest in anything that could destroy the global economy.
When Gates criticizes Bitcoin, cryptocurrencies, and NFTs, he's suggesting they're a hoax. These soapbox speeches are one way he protects his interests.
Digital assets aren't a bad investment, though. Many think they're the future.
Changpeng Zhao and Brian Armstrong are two digital asset billionaires. Two crypto exchange CEOs. Binance/Coinbase.
Digital asset revolution won't end soon.
If you disagree with Bill Gates and plan to invest in Bitcoin, cryptocurrencies, or NFTs, do your own research and understand the risks.
But don’t take Bill Gates’ word for it.
He’s just an old rich guy with a lot of farmland.
He has a lot to lose if Bitcoin and other digital assets gain global popularity.
This post is a summary. Read the full article here.
You might also like

Bastian Hasslinger
3 years ago
Before 2021, most startups had excessive valuations. It is currently causing issues.

Higher startup valuations are often favorable for all parties. High valuations show a business's potential. New customers and talent are attracted. They earn respect.
Everyone benefits if a company's valuation rises.
Founders and investors have always been incentivized to overestimate a company's value.
Post-money valuations were inflated by 2021 market expectations and the valuation model's mechanisms.
Founders must understand both levers to handle a normalizing market.
2021, the year of miracles
2021 must've seemed miraculous to entrepreneurs, employees, and VCs. Valuations rose, and funding resumed after the first Covid-19 epidemic caution.
In 2021, VC investments increased from $335B to $643B. 518 new worldwide unicorns vs. 134 in 2020; 951 US IPOs vs. 431.
Things can change quickly, as 2020-21 showed.
Rising interest rates, geopolitical developments, and normalizing technology conditions drive down share prices and tech company market caps in 2022. Zoom, the poster-child of early lockdown success, is down 37% since 1st Jan.
Once-inflated valuations can become a problem in a normalizing market, especially for founders, employees, and early investors.
the reason why startups are always overvalued
To see why inflated valuations are a problem, consider one of its causes.
Private company values only fluctuate following a new investment round, unlike publicly-traded corporations. The startup's new value is calculated simply:
(Latest round share price) x (total number of company shares)
This is the industry standard Post-Money Valuation model.
Let’s illustrate how it works with an example. If a VC invests $10M for 1M shares (at $10/share), and the company has 10M shares after the round, its Post-Money Valuation is $100M (10/share x 10M shares).
This approach might seem like the most natural way to assess a business, but the model often unintentionally overstates the underlying value of the company even if the share price paid by the investor is fair. All shares aren't equal.
New investors in a corporation will always try to minimize their downside risk, or the amount they lose if things go wrong. New investors will try to negotiate better terms and pay a premium.
How the value of a struggling SpaceX increased
SpaceX's 2008 Series D is an example. Despite the financial crisis and unsuccessful rocket launches, the company's Post-Money Valuation was 36% higher after the investment round. Why?
Series D SpaceX shares were protected. In case of liquidation, Series D investors were guaranteed a 2x return before other shareholders.
Due to downside protection, investors were willing to pay a higher price for this new share class.
The Post-Money Valuation model overpriced SpaceX because it viewed all the shares as equal (they weren't).
Why entrepreneurs, workers, and early investors stand to lose the most
Post-Money Valuation is an effective and sufficient method for assessing a startup's valuation, despite not taking share class disparities into consideration.
In a robust market, where the firm valuation will certainly expand with the next fundraising round or exit, the inflated value is of little significance.
Fairness endures. If a corporation leaves at a greater valuation, each stakeholder will receive a proportional distribution. (i.e., 5% of a $100M corporation yields $5M).
SpaceX's inherent overvaluation was never a problem. Had it been sold for less than its Post-Money Valuation, some shareholders, including founders, staff, and early investors, would have seen their ownership drop.
The unforgiving world of 2022
In 2022, founders, employees, and investors who benefited from inflated values will face below-valuation exits and down-rounds.
For them, 2021 will be a curse, not a blessing.
Some tech giants are worried. Klarna's valuation fell from $45B (Oct 21) to $30B (Jun 22), Canvas from $40B to $27B, and GoPuffs from $17B to $8.3B.
Shazam and Blue Apron have to exit or IPO at a cheaper price. Premium share classes are protected, while others receive less. The same goes for bankrupts.
Those who continue at lower valuations will lose reputation and talent. When their value declines by half, generous employee stock options become less enticing, and their ability to return anything is questioned.
What can we infer about the present situation?
Such techniques to enhance your company's value or stop a normalizing market are fiction.
The current situation is a painful reminder for entrepreneurs and a crucial lesson for future firms.
The devastating market fall of the previous six months has taught us one thing:
Keep in mind that any valuation is speculative. Money Post A startup's valuation is a highly simplified approximation of its true value, particularly in the early phases when it lacks significant income or a cutting-edge product. It is merely a projection of the future and a hypothetical meter. Until it is achieved by an exit, a valuation is nothing more than a number on paper.
Assume the value of your company is lower than it was in the past. Your previous valuation might not be accurate now due to substantial changes in the startup financing markets. There is little reason to think that your company's value will remain the same given the 50%+ decline in many newly listed IT companies. Recognize how the market situation is changing and use caution.
Recognize the importance of the stake you hold. Each share class has a unique value that varies. Know the sort of share class you own and how additional contractual provisions affect the market value of your security. Frameworks have been provided by Metrick and Yasuda (Yale & UC) and Gornall and Strebulaev (Stanford) for comprehending the terms that affect investors' cash-flow rights upon withdrawal. As a result, you will be able to more accurately evaluate your firm and determine the worth of each share class.
Be wary of approving excessively protective share terms.
The trade-offs should be considered while negotiating subsequent rounds. Accepting punitive contractual terms could first seem like a smart option in order to uphold your inflated worth, but you should proceed with caution. Such provisions ALWAYS result in misaligned shareholders, with common shareholders (such as you and your staff) at the bottom of the list.

Jon Brosio
3 years ago
Every time I use this 6-part email sequence, I almost always make four figures.
(And you can have it for free)

Master email to sell anything.
Most novice creators don't know how to begin.
Many use online templates. These are usually fluff-filled and niche-specific.
They're robotic and "salesy."
I've attended 3 courses, read 10 books, and sent 600,000 emails in the past five years.
Outcome?
This *proven* email sequence assures me a month's salary every time I send it.
What you will discover in this article is that:
A full 6-part email sales cycle
The essential elements you must incorporate
placeholders and text-filled images
(Applies to any niche)
This can be a product introduction, holiday, or welcome sequence. This works for email-saleable products.
Let's start
Email 1: Describe your issue
This email is crucial.
How to? We introduce a subscriber or prospect's problem. Later, we'll frame our offer as the solution.
Label the:
Problem
Why it still hasn't been fixed
Resulting implications for the customer
This puts our new subscriber in solve mode and queues our offer:
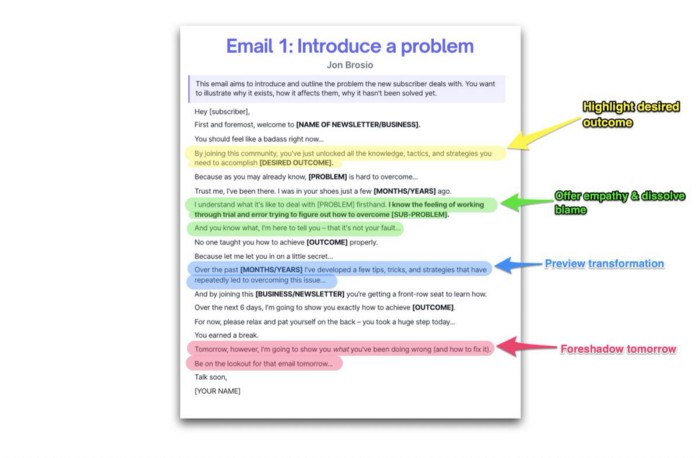
Email 2: Amplify the consequences
We're still causing problems.
We've created the problem, but now we must employ emotion and storytelling to make it real. We also want to forecast life if nothing changes.
Let's feel:
What occurs if it is not resolved?
Why is it crucial to fix it immediately?
Tell a tale of a person who was in their position. To emphasize the effects, use a true account of another person (or of yourself):

Email 3: Share a transformation story
Selling stories.
Whether in an email, landing page, article, or video. Humanize stories. They give information meaning.
This is where "issue" becomes "solution."
Let's reveal:
A tale of success
A new existence and result
tools and tactics employed
Start by transforming yourself.

Email 4: Prove with testimonials
No one buys what you say.
Emotionally stirred people buy and act. They believe in the product. They feel that if they buy, it will work.
Social proof shows prospects that your solution will help them.
Add:
Earlier and Later
Testimonials
Reviews
Proof this deal works:

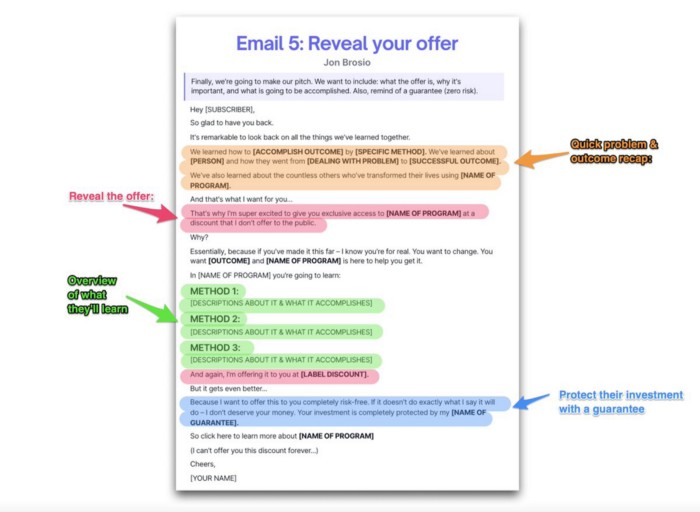
Email 5: Reveal your offer
It's showtime.
This is it. Until now, describing the offer and offering links to a landing page have been sparse in the email pictures.
We've been tense. Gaining steam. Building suspense. Email 5 reveals all.
In this email:
a description of the deal
A word about a promise
recapitulation of the transformation
and make a reference to the urgency Everything should be spelled out clearly:
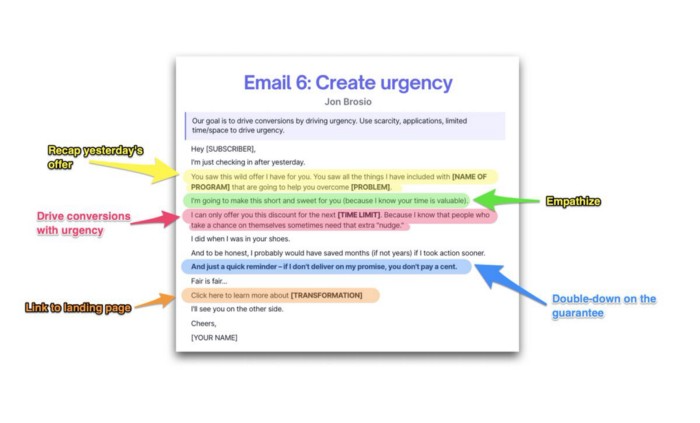
Email no. 6: Instill urgency
When there are stakes, humans act.
Creating and marketing with haste raises the stakes. Urgency makes a prospect act because they'll miss out or gain immensely.
Urgency converts. Use:
short time
Screening
Scarcity
Urgency and conversions. Limited-time offers are easy.
TL;DR
Use this proven 6-part email sequence (that turns subscribers into profit):
Introduce a problem
Amplify it with emotions
Share transformation story
Prove it works with testimonials
Value-stack and present your offer
Drive urgency and entice the purchase
Blake Montgomery
3 years ago
Explaining Twitter Files
Elon Musk, Matt Taibbi, the 'Twitter Files,' and Hunter Biden's laptop: what gives?
Explaining Twitter Files
Matt Taibbi released "The Twitter Files," a batch of emails sent by Twitter executives discussing the company's decision to stop an October 2020 New York Post story online.
What's on Twitter? New York Post and Fox News call them "bombshell" documents. Or, as a Post columnist admitted, are they "not the smoking gun"? Onward!
What started this?
The New York Post published an exclusive, potentially explosive story in October 2020: Biden's Secret Emails: Ukrainian executive thanks Hunter Biden for'meeting' veep dad. The story purported to report the contents of a laptop brought to the tabloid by a Delaware computer repair shop owner who said it belonged to President Biden's second son, Hunter Biden. Emails and files on the laptop allegedly showed how Hunter peddled influence with Ukranian businessmen and included a "raunchy 12-minute video" of Hunter smoking crack and having sex.
Twitter banned links to the Post story after it was published, calling it "hacked material." The Post's Twitter account was suspended for multiple days.
Why? Yoel Roth, Twitter's former head of trust and safety, said the company couldn't verify the story, implying they didn't trust the Post.
Twitter's stated purpose rarely includes verifying news stories. This seemed like intentional political interference. This story was hard to verify because the people who claimed to have found the laptop wouldn't give it to other newspapers. (Much of the story, including Hunter's business dealings in Ukraine and China, was later confirmed.)
Roth: "It looked like a hack and leak."
So what are the “Twitter Files?”
Twitter's decision to bury the story became a political scandal, and new CEO Elon Musk promised an explanation. The Twitter Files, named after Facebook leaks.
Musk promised exclusive details of "what really happened" with Hunter Biden late Friday afternoon. The tweet was punctuated with a popcorn emoji.
Explaining Twitter Files
Three hours later, journalist Matt Taibbi tweeted more than three dozen tweets based on internal Twitter documents that revealed "a Frankensteinian tale of a human-built mechanism grown out of its designer's control."
Musk sees this release as a way to shape Twitter's public perception and internal culture in his image. We don't know if the CEO gave Taibbi the documents. Musk hyped the document dump before and during publication, but Taibbi cited "internal sources."
Taibbi shares email screenshots showing Twitter execs discussing the Post story and blocking its distribution. Taibbi says the emails show Twitter's "extraordinary steps" to bury the story.
Twitter communications chief Brandon Borrman has the most damning quote in the Files. Can we say this is policy? The story seemed unbelievable. It seemed like a hack... or not? Could Twitter, which ex-CEO Dick Costolo called "the free speech wing of the free speech party," censor a news story?
Many on the right say the Twitter Files prove the company acted at the behest of Democrats. Both parties had these tools, writes Taibbi. In 2020, both the Trump White House and Biden campaign made requests. He says the system for reporting tweets for deletion is unbalanced because Twitter employees' political donations favor Democrats. Perhaps. These donations may have helped Democrats connect with Twitter staff, but it's also possible they didn't. No emails in Taibbi's cache show these alleged illicit relations or any actions Twitter employees took as a result.
Even Musk's supporters were surprised by the drop. Miranda Devine of the New York Post told Tucker Carlson the documents weren't "the smoking gun we'd hoped for." Sebastian Gorka said on Truth Social, "So far, I'm deeply underwhelmed." DC Democrats collude with Palo Alto Democrats. Whoop!” The Washington Free Beacon's Joe Simonson said the Twitter files are "underwhelming." Twitter was staffed by Democrats who did their bidding. (Why?)
If "The Twitter Files" matter, why?
These emails led Twitter to suppress the Hunter Biden laptop story has real news value. It's rare for a large and valuable company like Twitter to address wrongdoing so thoroughly. Emails resemble FOIA documents. They describe internal drama at a company with government-level power. Katie Notopoulos tweeted, "Any news outlet would've loved this scoop!" It's not a'scandal' as teased."
Twitter's new owner calls it "the de facto public town square," implying public accountability. Like a government agency. Though it's exciting to receive once-hidden documents in response to a FOIA, they may be boring and tell you nothing new. Like Twitter files. We learned how Twitter blocked the Post's story, but not why. Before these documents were released, we knew Twitter had suppressed the story and who was involved.
These people were disciplined and left Twitter. Musk fired Vijaya Gadde, the former CLO who reportedly played a "key role" in the decision. Roth quit over Musk's "dictatorship." Musk arrived after Borrman left. Jack Dorsey, then-CEO, has left. Did those who digitally quarantined the Post's story favor Joe Biden and the Democrats? Republican Party opposition and Trump hatred? New York Post distaste? According to our documents, no. Was there political and press interference? True. We knew.
Taibbi interviewed anonymous ex-Twitter employees about the decision; all expressed shock and outrage. One source said, "Everyone knew this was fucked." Since Taibbi doesn't quote that expletive, we can assume the leaked emails contained few or no sensational quotes. These executives said little to support nefarious claims.
Outlets more invested in the Hunter Biden story than Gizmodo seem vexed by the release and muted headlines. The New York Post, which has never shied away from a blaring headline in its 221-year history, owns the story of Hunter Biden's laptop. Two Friday-night Post alerts about Musk's actions were restrained. Elon Musk will drop Twitter files on NY Post-Hunter Biden laptop censorship today. Elon Musk's Twitter dropped Post censorship details from Biden's laptop. Fox News' Apple News push alert read, "Elon Musk drops Twitter censorship documents."
Bombshell, bombshell, bombshell… what, exactly, is the bombshell? Maybe we've heard this story too much and are missing the big picture. Maybe these documents detail a well-documented decision.
The Post explains why on its website. "Hunter Biden laptop bombshell: Twitter invented reason to censor Post's reporting," its headline says.
Twitter's ad hoc decision to moderate a tabloid's content is not surprising. The social network had done this for years as it battled toxic users—violent white nationalists, virulent transphobes, harassers and bullies of all political stripes, etc. No matter how much Musk crows, the company never had content moderation under control. Buzzfeed's 2016 investigation showed how Twitter has struggled with abusive posters since 2006. Jack Dorsey and his executives improvised, like Musk.
Did the US government interfere with the ex-social VP's media company? That's shocking, a bombshell. Musk said Friday, "Twitter suppressing free speech by itself is not a 1st amendment violation, but acting under government orders with no judicial review is." Indeed! Taibbi believed this. August 2022: "The laptop is secondary." Zeynep Tufecki, a Columbia professor and New York Times columnist, says the FBI is cutting true story distribution. Taibbi retracted the claim Friday night: "I've seen no evidence of government involvement in the laptop story."
What’s the bottom line?
I'm still not sure what's at stake in the Hunter Biden scandal after dozens of New York Post articles, hundreds of hours of Fox News airtime, and thousands of tweets. Briefly: Joe Biden's son left his laptop with a questionable repairman. FBI confiscated it? The repairman made a copy and gave it to Rudy Giuliani's lawyer. The Post got it from Steve Bannon. On that laptop were videos of Hunter Biden smoking crack, cavorting with prostitutes, and emails about introducing his father to a Ukrainian businessman for $50,000 a month. Joe Biden urged Ukraine to fire a prosecutor investigating the company. What? The story seems to be about Biden family business dealings, right?
The discussion has moved past that point anyway. Now, the story is the censorship of it. Adrienne Rich wrote in "Diving Into the Wreck" that she came for "the wreck and not the story of the wreck" No matter how far we go, Hunter Biden's laptop is done. Now, the crash's story matters.
I'm dizzy. Katherine Miller of BuzzFeed wrote, "I know who I believe, and you probably do, too. To believe one is to disbelieve the other, which implicates us in the decision; we're stuck." I'm stuck. Hunter Biden's laptop is a political fabrication. You choose. I've decided.
This could change. Twitter Files drama continues. Taibbi said, "Much more to come." I'm dizzy.