




More on Entrepreneurship/Creators

Carter Kilmann
3 years ago
I finally achieved a $100K freelance income. Here's what I wish I knew.

We love round numbers, don't we? $100,000 is a frequent freelancing milestone. You feel like six figures means you're doing something properly.
You've most likely already conquered initial freelancing challenges like finding clients, setting fair pricing, coping with criticism, getting through dry spells, managing funds, etc.
You think I must be doing well. Last month, my freelance income topped $100,000.
That may not sound impressive considering I've been freelancing for 2.75 years, but I made 30% of that in the previous four months, which is crazy.
Here are the things I wish I'd known during the early days of self-employment that would have helped me hit $100,000 faster.
1. The Volatility of Freelancing Will Stabilize.
Freelancing is risky. No surprise.
Here's an example.
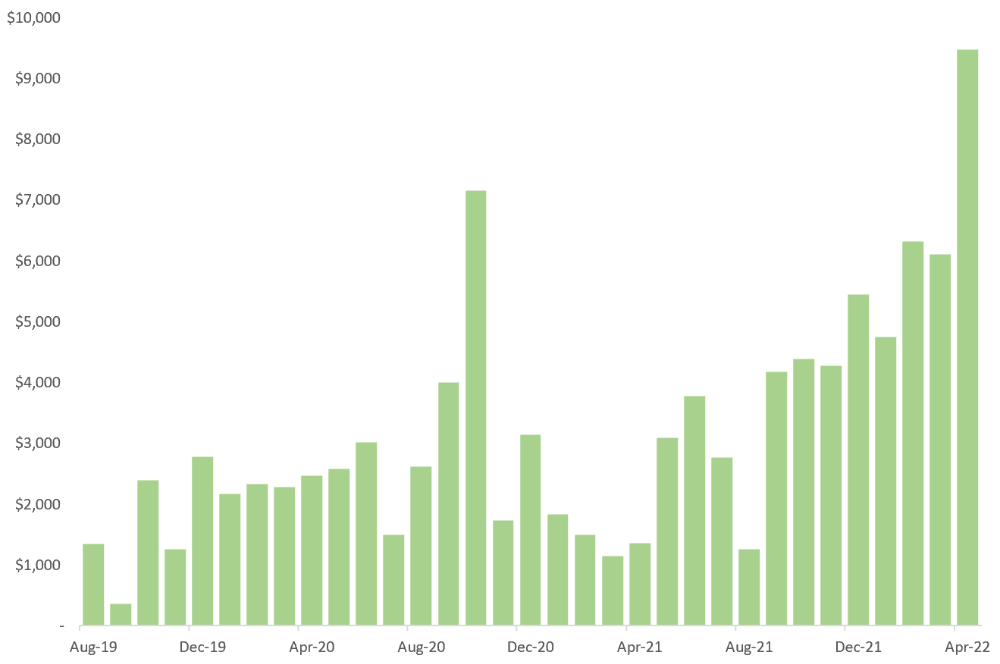
October 2020 was my best month, earning $7,150. Between $4,004 in September and $1,730 in November. Unsteady.
Freelancing is regrettably like that. Moving clients. Content requirements change. Allocating so much time to personal pursuits wasn't smart, but yet.
Stabilizing income takes time. Consider my rolling three-month average income since I started freelancing. My three-month average monthly income. In February, this metric topped $5,000. Now, it's in the mid-$7,000s, but it took a while to get there.
Finding freelance gigs that provide high pay, high volume, and recurring revenue is difficult. But it's not impossible.
TLDR: Don't expect a steady income increase at first. Be patient.
2. You Have More Value Than You Realize.
Writing is difficult. Assembling words, communicating a message, and provoking action are a puzzle.
People are willing to pay you for it because they can't do what you do or don't have enough time.
Keeping that in mind can have huge commercial repercussions.
When talking to clients, don't tiptoe. You can ignore ridiculous deadlines. You don't have to take unmanageable work.
You solve an issue, so make sure you get rightly paid.
TLDR: Frame services as problem-solutions. This will let you charge more and set boundaries.
3. Increase Your Prices.
I studied hard before freelancing. I read articles and watched videos about writing businesses.
I didn't want to work for pennies. Despite this clarity, I had no real strategy to raise my rates.
I then luckily stumbled into higher-paying work. We discussed fees and hours with a friend who launched a consulting business. It's subjective and speculative because value isn't standardized. One company may laugh at your charges. If your solution helps them create a solid ROI, another client may pay $200 per hour.
When he told me he charged his first client $125 per hour, I thought, Why not?
A new-ish client wanted to discuss a huge forthcoming project, so I raised my rates. They knew my worth, so they didn't blink when I handed them my new number.
TLDR: Increase rates periodically (e.g., every 6 or 12 months). Writing skill develops with practice. You'll gain value over time.
4. Remember Your Limits.
If you can squeeze additional time into a day, let me know. I can't manipulate time yet.
We all have time and economic limits. You could theoretically keep boosting rates, but your prospect pool diminishes. Outsourcing and establishing extra revenue sources might boost monthly revenues.
I've devoted a lot of time to side projects (hopefully extra cash sources), but I've only just started outsourcing. I wish I'd tried this earlier.
If you can discover good freelancers, you can grow your firm without sacrificing time.
TLDR: Expand your writing network immediately. You'll meet freelancers who understand your daily grind and locate reference sources.
5. Every Action You Take Involves an Investment. Be Certain to Select Correctly.
Investing in stocks or crypto requires paying money, right?
In business, time is your currency (and maybe money too). Your daily habits define your future. If you spend time collecting software customers and compiling content in the space, you'll end up with both. So be sure.
I only spend around 50% of my time on client work, therefore it's taken me nearly three years to earn $100,000. I spend the remainder of my time on personal projects including a freelance book, an investment newsletter, and this blog.
Why? I don't want to rely on client work forever. So, I'm working on projects that could pay off later and help me live a more fulfilling life.
TLDR: Consider the long-term impact of your time commitments, and don't overextend. You can only make so many "investments" in a given time.
6. LinkedIn Is an Endless Mine of Gold. Use It.
Why didn't I use LinkedIn earlier?
I designed a LinkedIn inbound lead strategy that generates 12 leads a month and a few high-quality offers. As a result, I've turned down good gigs. Wish I'd begun earlier.
If you want to create a freelance business, prioritize LinkedIn. Too many freelancers ignore this site, missing out on high-paying clients. Build your profile, post often, and interact.
TLDR: Study LinkedIn's top creators. Once you understand their audiences, start posting and participating daily.
For 99% of People, Freelancing is Not a Get-Rich-Quick Scheme.
Here's a list of things I wish I'd known when I started freelancing.
Although it is erratic, freelancing eventually becomes stable.
You deserve respect and discretion over how you conduct business because you have solved an issue.
Increase your charges rather than undervaluing yourself. If necessary, add a reminder to your calendar. Your worth grows with time.
In order to grow your firm, outsource jobs. After that, you can work on the things that are most important to you.
Take into account how your present time commitments may affect the future. It will assist in putting things into perspective and determining whether what you are doing is indeed worthwhile.
Participate on LinkedIn. You'll get better jobs as a result.
If I could give my old self (and other freelancers) one bit of advice, it's this:
Despite appearances, you're making progress.
Each job. Tweets. Newsletters. Progress. It's simpler to see retroactively than in the moment.
Consistent, intentional work pays off. No good comes from doing nothing. You must set goals, divide them into time-based targets, and then optimize your calendar.
Then you'll understand you're doing well.
Want to learn more? I’ll teach you.

Emils Uztics
3 years ago
This billionaire created a side business that brings around $90,000 per month.

Dharmesh Shah co-founded HubSpot. WordPlay reached $90,000 per month in revenue without utilizing any of his wealth.
His method:
Take Advantage Of An Established Trend
Remember Wordle? Dharmesh was instantly hooked. As was the tech world.

HubSpot's co-founder noted inefficiencies in a recent My First Million episode. He wanted to play daily. Dharmesh, a tinkerer and software engineer, decided to design a word game.
He's a billionaire. How could he?
Wordle had limitations in his opinion;
Dharmesh is fundamentally a developer. He desired to start something new and increase his programming knowledge;
This project may serve as an excellent illustration for his son, who had begun learning about software development.
Better It Up
Building a new Wordle wasn't successful.
WordPlay lets you play with friends and family. You could challenge them and compare the results. It is a built-in growth tool.
WordPlay features:
the capacity to follow sophisticated statistics after creating an account;
continuous feedback on your performance;
Outstanding domain name (wordplay.com).
Project Development
WordPlay has 9.5 million visitors and 45 million games played since February.
HubSpot co-founder credits tremendous growth to flywheel marketing, pushing the game through his own following.
Choosing an exploding specialty and making sharing easy also helped.
Shah enabled Google Ads on the website to test earning potential. Monthly revenue was $90,000.
That's just Google Ads. If monetization was the goal, a specialized ad network like Ezoic could double or triple the amount.
Wordle was a great buy for The New York Times at $1 million.

Aaron Dinin, PhD
2 years ago
Are You Unintentionally Creating the Second Difficult Startup Type?
Most don't understand the issue until it's too late.

My first startup was what entrepreneurs call the hardest. A two-sided marketplace.
Two-sided marketplaces are the hardest startups because founders must solve the chicken or the egg conundrum.
A two-sided marketplace needs suppliers and buyers. Without suppliers, buyers won't come. Without buyers, suppliers won't come. An empty marketplace and a founder striving to gain momentum result.
My first venture made me a struggling founder seeking to achieve traction for a two-sided marketplace. The company failed, and I vowed never to start another like it.
I didn’t. Unfortunately, my second venture was almost as hard. It failed like the second-hardest startup.
What kind of startup is the second-hardest?
The second-hardest startup, which is almost as hard to develop, is rarely discussed in the startup community. Because of this, I predict more founders fail each year trying to develop the second-toughest startup than the hardest.
Fairly, I have no proof. I see many startups, so I have enough of firsthand experience. From what I've seen, for every entrepreneur developing a two-sided marketplace, I'll meet at least 10 building this other challenging startup.
I'll describe a startup I just met with its two co-founders to explain the second hardest sort of startup and why it's so hard. They created a financial literacy software for parents of high schoolers.
The issue appears plausible. Children struggle with money. Parents must teach financial responsibility. Problems?
It's possible.
Buyers and users are different.
Buyer-user mismatch.
The financial literacy app I described above targets parents. The parent doesn't utilize the app. Child is end-user. That may not seem like much, but it makes customer and user acquisition and onboarding difficult for founders.
The difficulty of a buyer-user imbalance
The company developing a product faces a substantial operational burden when the buyer and end customer are different. Consider classic firms where the buyer is the end user to appreciate that responsibility.
Entrepreneurs selling directly to end users must educate them about the product's benefits and use. Each demands a lot of time, effort, and resources.
Imagine selling a financial literacy app where the buyer and user are different. To make the first sale, the entrepreneur must establish all the items I mentioned above. After selling, the entrepreneur must supply a fresh set of resources to teach, educate, or train end-users.
Thus, a startup with a buyer-user mismatch must market, sell, and train two organizations at once, requiring twice the work with the same resources.
The second hardest startup is hard for reasons other than the chicken-or-the-egg conundrum. It takes a lot of creativity and luck to solve the chicken-or-egg conundrum.
The buyer-user mismatch problem cannot be overcome by innovation or luck. Buyer-user mismatches must be solved by force. Simply said, when a product buyer is different from an end-user, founders have a lot more work. If they can't work extra, their companies fail.
You might also like

Jayden Levitt
3 years ago
How to Explain NFTs to Your Grandmother, in Simple Terms

In simple terms, you probably don’t.
But try. Grandma didn't grow up with Facebook, but she eventually joined.
Perhaps the fear of being isolated outweighed the discomfort of learning the technology.
Grandmas are Facebook likers, sharers, and commenters.
There’s no stopping her.
Not even NFTs. Web3 is currently very complex.
It's difficult to explain what NFTs are, how they work, and why we might use them.
Three explanations.
1. Everything will be ours to own, both physically and digitally.
Why own something you can't touch? What's the point?
Blockchain technology proves digital ownership.
Untouchables need ownership proof. What?
Digital assets reduce friction, save time, and are better for the environment than physical goods.
Many valuable things are intangible. Feeling like your favorite brands. You'll pay obscene prices for clothing that costs pennies.
Secondly, NFTs Are Contracts. Agreements Have Value.
Blockchain technology will replace all contracts and intermediaries.
Every insurance contract, deed, marriage certificate, work contract, plane ticket, concert ticket, or sports event is likely an NFT.
We all have public wallets, like Grandma's Facebook page.
3. Your NFT Purchases Will Be Visible To Everyone.
Everyone can see your public wallet. What you buy says more about you than what you post online.
NFTs issued double as marketing collateral when seen on social media.
While I doubt Grandma knows who Snoop Dog is, imagine him or another famous person holding your NFT in his public wallet and the attention that could bring to you, your company, or brand.
This Technical Section Is For You
The NFT is a contract; its founders can add value through access, events, tuition, and possibly royalties.
Imagine Elon Musk releasing an NFT to his network. Or yearly business consultations for three years.
Christ-alive.
It's worth millions.
These determine their value.
No unsuspecting schmuck willing to buy your hot potato at zero. That's the trend, though.
Overpriced NFTs for low-effort projects created a bubble that has burst.
During a market bubble, you can make money by buying overvalued assets and selling them later for a profit, according to the Greater Fool Theory.
People are struggling. Some are ruined by collateralized loans and the gold rush.
Finances are ruined.
It's uncomfortable.
The same happened in 2018, during the ICO crash or in 1999/2000 when the dot com bubble burst. But the underlying technology hasn’t gone away.
Chritiaan Hetzner
3 years ago
Mystery of the $1 billion'meme stock' that went to $400 billion in days
Who is AMTD Digital?
An unknown Hong Kong corporation joined the global megacaps worth over $500 billion on Tuesday.

The American Depository Share (ADS) with the ticker code HKD gapped at the open, soaring 25% over the previous closing price as trading began, before hitting an intraday high of $2,555.
At its peak, its market cap was almost $450 billion, more than Facebook parent Meta or Alibaba.
Yahoo Finance reported a daily volume of 350,500 shares, the lowest since the ADS began trading and much below the average of 1.2 million.
Despite losing a fifth of its value on Wednesday, it's still worth more than Toyota, Nike, McDonald's, or Walt Disney.
The company sold 16 million shares at $7.80 each in mid-July, giving it a $1 billion market valuation.
Why the boom?
That market cap seems unjustified.
According to SEC reports, its income-generating assets barely topped $400 million in March. Fortune's emails and calls went unanswered.
Website discloses little about company model. Its one-minute business presentation film uses a Star Wars–like design to sell the company as a "one-stop digital solutions platform in Asia"
The SEC prospectus explains.
AMTD Digital sells a "SpiderNet Ecosystems Solutions" kind of club membership that connects enterprises. This is the bulk of its $25 million annual revenue in April 2021.
Pretax profits have been higher than top line over the past three years due to fair value accounting gains on Appier, DayDayCook, WeDoctor, and five Asian fintechs.
AMTD Group, the company's parent, specializes in investment banking, hotel services, luxury education, and media and entertainment. AMTD IDEA, a $14 billion subsidiary, is also traded on the NYSE.
“Significant volatility”
Why AMTD Digital listed in the U.S. is unknown, as it informed investors in its share offering prospectus that could delist under SEC guidelines.
Beijing's red tape prevents the Sarbanes-Oxley Board from inspecting its Chinese auditor.
This frustrates Chinese stock investors. If the U.S. and China can't achieve a deal, 261 Chinese companies worth $1.3 trillion might be delisted.
Calvin Choi left UBS to become AMTD Group's CEO.
His capitalist background and status as a Young Global Leader with the World Economic Forum don't stop him from praising China's Communist party or celebrating the "glory and dream of the Great Rejuvenation of the Chinese nation" a century after its creation.
Despite having an executive vice chairman with a record of battling corruption and ties to Carrie Lam, Beijing's previous proconsul in Hong Kong, Choi is apparently being targeted for a two-year industry ban by the city's securities regulator after an investor accused Choi of malfeasance.
Some CMIG-funded initiatives produced money, but he didn't give us the proceeds, a corporate official told China's Caixin in October 2020. We don't know if he misappropriated or lost some money.
A seismic anomaly
In fundamental analysis, where companies are valued based on future cash flows, AMTD Digital's mind-boggling market cap is a statistical aberration that should occur once every hundred years.
AMTD Digital doesn't know why it's so valuable. In a thank-you letter to new shareholders, it said it was confused by the stock's performance.
Since its IPO, the company has seen significant ADS price volatility and active trading volume, it said Tuesday. "To our knowledge, there have been no important circumstances, events, or other matters since the IPO date."
Permabears awoke after the jump. Jim Chanos asked if "we're all going to ignore the $400 billion meme stock in the room," while Nate Anderson called AMTD Group "sketchy."
It happened the same day SEC Chair Gary Gensler praised the 20th anniversary of the Sarbanes-Oxley Act, aimed to restore trust in America's financial markets after the Enron and WorldCom accounting fraud scandals.
The run-up revived unpleasant memories of Robinhood's decision to limit retail investors' ability to buy GameStop, regarded as a measure to protect hedge funds invested in the meme company.
Why wasn't HKD's buy button removed? Because retail wasn't behind it?" tweeted Gensler on Tuesday. "Real stock fraud. "You're worthless."

Camilla Dudley
3 years ago
How to gain Twitter followers: A 101 Guide

No wonder brands use Twitter to reach their audience. 53% of Twitter users buy new products first.
Twitter growth does more than make your brand look popular. It helps clients trust your business. It boosts your industry standing. It shows clients, prospects, and even competitors you mean business.
How can you naturally gain Twitter followers?
Share useful information
Post visual content
Tweet consistently
Socialize
Spread your @name everywhere.
Use existing customers
Promote followers
Share useful information
Twitter users join conversations and consume material. To build your followers, make sure your material appeals to them and gives value, whether it's sales, product lessons, or current events.
Use Twitter Analytics to learn what your audience likes.
Explore popular topics by utilizing relevant keywords and hashtags. Check out this post on how to use Twitter trends.
Post visual content
97% of Twitter users focus on images, so incorporating media can help your Tweets stand out. Visuals and videos make content more engaging and memorable.
Tweet often
Your audience should expect regular content updates. Plan your ideas and tweet during crucial seasons and events with a content calendar.
Socialize
Twitter connects people. Do more than tweet. Follow industry leaders. Retweet influencers, engage with thought leaders, and reply to mentions and customers to boost engagement.
Micro-influencers can promote your brand or items. They can help you gain new audiences' trust.
Spread your @name everywhere.
Maximize brand exposure. Add a follow button on your website, link to it in your email signature and newsletters, and promote it on business cards or menus.
Use existing customers
Emails can be used to find existing Twitter clients. Upload your email contacts and follow your customers on Twitter to start a dialogue.
Promote followers
Run a followers campaign to boost your organic growth. Followers campaigns promote your account to a particular demographic, and you only pay when someone follows you.
Consider short campaigns to enhance momentum or an always-on campaign to gain new followers.
Increasing your brand's Twitter followers takes effort and experimentation, but the payback is huge.
👋 Follow me on twitter