



More on Entrepreneurship/Creators

Sarah Bird
3 years ago
Memes Help This YouTube Channel Earn Over $12k Per Month
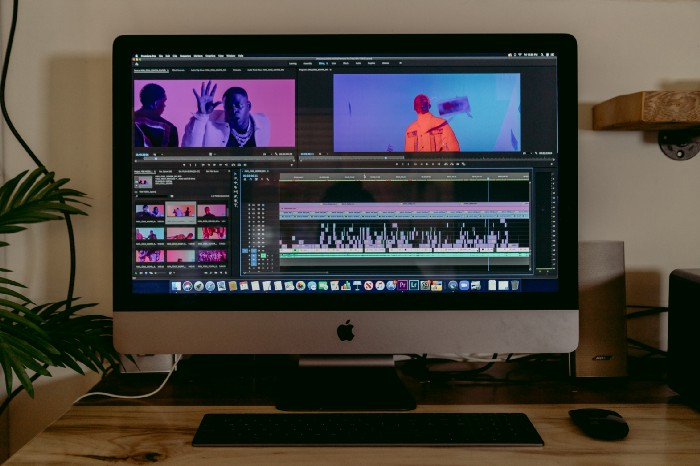
Take a look at a YouTube channel making anything up to over $12k a month from making very simple videos.
And the best part? Its replicable by anyone. Basic videos can be generated for free without design abilities.
Join me as I deconstruct the channel to estimate how much they make, how they do it, and how you can too.
What Do They Do Exactly?
Happy Land posts memes with a simple caption they wrote. So, it's new. The videos are a slideshow of meme photos with stock music.
The site posts 12 times a day.
8-10-minute videos show 10 second images. Thus, each video needs 48-60 memes.
Memes are video titles (e.g. times a boyfriend was hilarious, back to school fails, funny restaurant signs).
Some stats about the channel:
Founded on October 30, 2020
873 videos were added.
81.8k subscribers
67,244,196 views of the video
What Value Are They Adding?
Everyone can find free memes online. This channel collects similar memes into a single video so you don't have to scroll or click for more. It’s right there, you just keep watching and more will come.
By theming it, the audience is prepared for the video's content.
If you want hilarious animal memes or restaurant signs, choose the video and you'll get up to 60 memes without having to look for them. Genius!
How much money do they make?
According to www.socialblade.com, the channel earns $800-12.8k (image shown in my home currency of GBP).
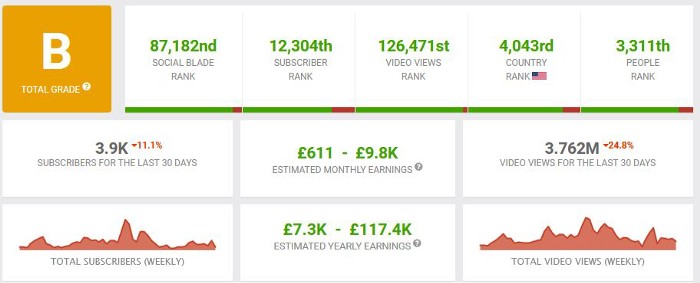
That's a crazy estimate, but it highlights the unbelievable potential of a channel that presents memes.
This channel thrives on quantity, thus putting out videos is necessary to keep the flow continuing and capture its audience's attention.
How Are the Videos Made?
Straightforward. Memes are added to a presentation without editing (so you could make this in PowerPoint or Keynote).
Each slide should include a unique image and caption. Set 10 seconds per slide.
Add music and post the video.
Finding enough memes for the material and theming is difficult, but if you enjoy memes, this is a fun job.
This case study should have shown you that you don't need expensive software or design expertise to make entertaining videos. Why not try fresh, easy-to-do ideas and see where they lead?

ANTHONY P.
3 years ago
Startups are difficult. Streamlining the procedure for creating the following unicorn.
New ventures are exciting. It's fun to imagine yourself rich, successful, and famous (if that's your thing). How you'll help others and make your family proud. This excitement can pull you forward for years, even when you intuitively realize that the path you're on may not lead to your desired success.
Know when to change course. Switching course can mean pivoting or changing direction.
In this not-so-short blog, I'll describe the journey of building your dream. And how the journey might look when you think you're building your dream, but fall short of that vision. Both can feel similar in the beginning, but there are subtle differences.
Let’s dive in.
How an exciting journey to a dead end looks and feels.
You want to help many people. You're business-minded, creative, and ambitious. You jump into entrepreneurship. You're excited, free, and in control.
I'll use tech as an example because that's what I know best, but this applies to any entrepreneurial endeavor.
So you start learning the basics of your field, say coding/software development. You read books, take courses, and may even join a bootcamp. You start practicing, and the journey begins. Once you reach a certain level of skill (which can take months, usually 12-24), you gain the confidence to speak with others in the field and find common ground. You might attract a co-founder this way with time. You and this person embark on a journey (Tip: the idea you start with is rarely the idea you end with).
Amateur mistake #1: You spend months building a product before speaking to customers.
Building something pulls you forward blindly. You make mistakes, avoid customers, and build with your co-founder or small team in the dark for months, usually 6-12 months.
You're excited when the product launches. We'll be billionaires! The market won't believe it. This excites you and the team. Launch.
….
Nothing happens.
Some people may sign up out of pity, only to never use the product or service again.
You and the team are confused, discouraged and in denial. They don't get what we've built yet. We need to market it better, we need to talk to more investors, someone will understand our vision.
This is a hopeless path, and your denial could last another 6 months. If you're lucky, while talking to consumers and investors (which you should have done from the start), someone who has been there before would pity you and give you an idea to pivot into that can create income.
Suppose you get this idea and pivot your business. Again, you've just pivoted into something limited by what you've already built. It may be a revenue-generating idea, but it's rarely new. Now you're playing catch-up, doing something others are doing but you can do better. (Tip #2: Don't be late.) Your chances of winning are slim, and you'll likely never catch up.
You're finally seeing revenue and feel successful. You can compete, but if you're not a first mover, you won't earn enough over time. You'll get by or work harder than ever to earn what a skilled trade could provide. You didn't go into business to stress out and make $100,000 or $200,000 a year. When you can make the same amount by becoming a great software developer, electrician, etc.
You become stuck. Either your firm continues this way for years until you realize there isn't enough growth to recruit a strong team and remove yourself from day-to-day operations due to competition. Or a catastrophic economic event forces you to admit that what you were building wasn't new and unique and wouldn't get you where you wanted to be.
This realization could take 6-10 years. No kidding.
The good news is, you’ve learned a lot along the way and this information can be used towards your next venture (if you have the energy).
Key Lesson: Don’t build something if you aren’t one of the first in the space building it just for the sake of building something.
-
Let's discuss what it's like to build something that can make your dream come true.
Case 2: Building something the market loves is difficult but rewarding.
It starts with a problem that hasn't been adequately solved for a long time but is now solvable due to technology. Or a new problem due to a change in how things are done.
Let's examine each example.
Example #1: Mass communication. The problem is now solvable due to some technological breakthrough.
Twitter — One of the first web 2 companies that became successful with the rise of smart mobile computing.
People can share their real-time activities via mobile device with friends, family, and strangers. Web 2 and smartphones made it easy and fun.
Example #2: A new problem has emerged due to some change in the way things are conducted.
Zoom- A web-conferencing company that reached massive success due to the movement towards “work from home”, remote/hybrid work forces.
Online web conferencing allows for face-to-face communication.
-
These two examples show how to build a unicorn-type company. It's a mix of solving the right problem at the right time, either through a technological breakthrough that opens up new opportunities or by fundamentally changing how people do things.
Let's find these opportunities.
Start by examining problems, such as how the world has changed and how we can help it adapt. It can also be both. Start team brainstorming. Research technologies, current world-trends, use common sense, and make a list. Then, choose the top 3 that you're most excited about and seem most workable based on your skillsets, values, and passion.
Once you have this list, create the simplest MVP you can and test it with customers. The prototype can be as simple as a picture or diagram of user flow and end-user value. No coding required. Market-test. Twitter's version 1 was simple. It was a web form that asked, "What are you doing?" Then publish it from your phone. A global status update, wherever you are. Currently, this company has a $50 billion market cap.
Here's their MVP screenshot.
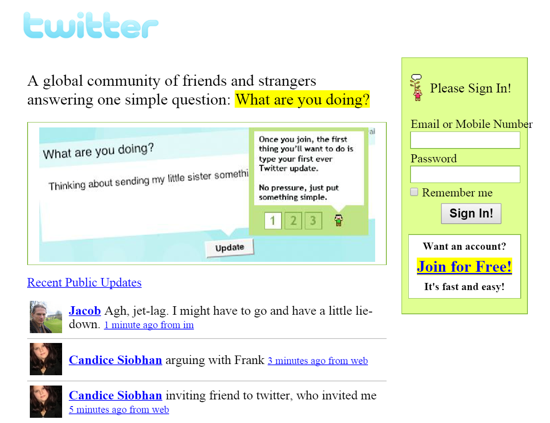
Small things grow. Tiny. Simplify.
Remember Frequency and Value when brainstorming. Your product is high frequency (Twitter, Instagram, Snapchat, TikTok) or high value (Airbnb for renting travel accommodations), or both (Gmail).
Once you've identified product ideas that meet the above criteria, they're simple, have a high frequency of use, or provide deep value. You then bring it to market in the simplest, most cost-effective way. You can sell a half-working prototype with imagination and sales skills. You need just enough of a prototype to convey your vision to a user or customer.
With this, you can approach real people. This will do one of three things: give you a green light to continue on your vision as is, show you that there is no opportunity and people won't use it, or point you in a direction that is a blend of what you've come up with and what the customer / user really wants, and you update the prototype and go back to the maze. Repeat until you have enough yeses and conviction to build an MVP.

Emils Uztics
3 years ago
This billionaire created a side business that brings around $90,000 per month.

Dharmesh Shah co-founded HubSpot. WordPlay reached $90,000 per month in revenue without utilizing any of his wealth.
His method:
Take Advantage Of An Established Trend
Remember Wordle? Dharmesh was instantly hooked. As was the tech world.

HubSpot's co-founder noted inefficiencies in a recent My First Million episode. He wanted to play daily. Dharmesh, a tinkerer and software engineer, decided to design a word game.
He's a billionaire. How could he?
Wordle had limitations in his opinion;
Dharmesh is fundamentally a developer. He desired to start something new and increase his programming knowledge;
This project may serve as an excellent illustration for his son, who had begun learning about software development.
Better It Up
Building a new Wordle wasn't successful.
WordPlay lets you play with friends and family. You could challenge them and compare the results. It is a built-in growth tool.
WordPlay features:
the capacity to follow sophisticated statistics after creating an account;
continuous feedback on your performance;
Outstanding domain name (wordplay.com).
Project Development
WordPlay has 9.5 million visitors and 45 million games played since February.
HubSpot co-founder credits tremendous growth to flywheel marketing, pushing the game through his own following.
Choosing an exploding specialty and making sharing easy also helped.
Shah enabled Google Ads on the website to test earning potential. Monthly revenue was $90,000.
That's just Google Ads. If monetization was the goal, a specialized ad network like Ezoic could double or triple the amount.
Wordle was a great buy for The New York Times at $1 million.
You might also like

Taher Batterywala
3 years ago
Do You Have Focus Issues? Use These 5 Simple Habits

Many can't concentrate. The first 20% of the day isn't optimized.
Elon Musk, Tony Robbins, and Bill Gates share something:
Morning Routines.
A repeatable morning ritual saves time.
The result?
Time for hobbies.
I'll discuss 5 easy morning routines you can use.
1. Stop pressing snooze
Waking up starts the day. You disrupt your routine by hitting snooze.
One sleep becomes three. Your morning routine gets derailed.
Fix it:
Hide your phone. This disables snooze and wakes you up.
Once awake, staying awake is 10x easier. Simple trick, big results.
2. Drink water
Chronic dehydration is common. Mostly urban, air-conditioned workers/residents.
2% cerebral dehydration causes short-term memory loss.
Dehydration shrinks brain cells.
Drink 3-4 liters of water daily to avoid this.
3. Improve your focus
How to focus better?
Meditation.
Improve your mood
Enhance your memory
increase mental clarity
Reduce blood pressure and stress
Headspace helps with the habit.
Here's a meditation guide.
Sit comfortably
Shut your eyes.
Concentrate on your breathing
Breathe in through your nose
Breathe out your mouth.
5 in, 5 out.
Repeat for 1 to 20 minutes.
Here's a beginner's video:
4. Workout
Exercise raises:
Mental Health
Effort levels
focus and memory
15-60 minutes of fun:
Exercise Lifting
Running
Walking
Stretching and yoga
This helps you now and later.
5. Keep a journal
You have countless thoughts daily. Many quietly steal your focus.
Here’s how to clear these:
Write for 5-10 minutes.
You'll gain 2x more mental clarity.
Recap
5 morning practices for 5x more productivity:
Say no to snoozing
Hydrate
Improve your focus
Exercise
Journaling
Conclusion
One step starts a thousand-mile journey. Try these easy yet effective behaviors if you have trouble concentrating or have too many thoughts.
Start with one of these behaviors, then add the others. Its astonishing results are instant.

Sukhad Anand
3 years ago
How Do Discord's Trillions Of Messages Get Indexed?
They depend heavily on open source..

Discord users send billions of messages daily. Users wish to search these messages. How do we index these to search by message keywords?
Let’s find out.
Discord utilizes Elasticsearch. Elasticsearch is a free, open search engine for textual, numerical, geographical, structured, and unstructured data. Apache Lucene powers Elasticsearch.
How does elastic search store data? It stores it as numerous key-value pairs in JSON documents.
How does elastic search index? Elastic search's index is inverted. An inverted index lists every unique word in every page and where it appears.
4. Elasticsearch indexes documents and generates an inverted index to make data searchable in near real-time. The index API adds or updates JSON documents in a given index.
Let's examine how discord uses Elastic Search. Elasticsearch prefers bulk indexing. Discord couldn't index real-time messages. You can't search posted messages. You want outdated messages.
6. Let's check what bulk indexing requires.
1. A temporary queue for incoming communications.
2. Indexer workers that index messages into elastic search.
Discord's queue is Celery. The queue is open-source. Elastic search won't run on a single server. It's clustered. Where should a message go? Where?
8. A shard allocator decides where to put the message. Nevertheless. Shattered? A shard combines elastic search and index on. So, these two form a shard which is used as a unit by discord. The elastic search itself has some shards. But this is different, so don’t get confused.
Now, the final part is service discovery — to discover the elastic search clusters and the hosts within that cluster. This, they do with the help of etcd another open source tool.
A great thing to notice here is that discord relies heavily on open source systems and their base implementations which is very different from a lot of other products.

Jano le Roux
3 years ago
Quit worrying about Twitter: Elon moves quickly before refining
Elon's rides start rough, but then...

Elon Musk has never been so hated.
They don’t get Elon.
He began using PayPal in this manner.
He began with SpaceX in a similar manner.
He began with Tesla in this manner.
Disruptive.
Elon had rocky starts. His creativity requires it. Just like writing a first draft.
His fastest way to find the way is to avoid it.
PayPal's pricey launch
PayPal was a 1999 business flop.
They were considered insane.
Elon and his co-founders had big plans for PayPal. They adopted the popular philosophy of the time, exchanging short-term profit for growth, and pulled off a miracle just before the bubble burst.
PayPal was created as a dollar alternative. Original PayPal software allowed PalmPilot money transfers. Unfortunately, there weren't enough PalmPilot users.
Since everyone had email, the company emailed payments. Costs rose faster than sales.
The startup wanted to get a million subscribers by paying $10 to sign up and $10 for each referral. Elon thought the price was fair because PayPal made money by charging transaction fees. They needed to make money quickly.
A Wall Street Journal article valuing PayPal at $500 million attracted investors. The dot-com bubble burst soon after they rushed to get financing.
Musk and his partners sold PayPal to eBay for $1.5 billion in 2002. Musk's most successful company was PayPal.
SpaceX's start-up error
Elon and his friends bought a reconditioned ICBM in Russia in 2002.
He planned to invest much of his wealth in a stunt to promote NASA and space travel.
Many called Elon crazy.
The goal was to buy a cheap Russian rocket to launch mice or plants to Mars and return them. He thought SpaceX would revive global space interest. After a bad meeting in Moscow, Elon decided to build his own rockets to undercut launch contracts.
Then SpaceX was founded.
Elon’s plan was harder than expected.
Explosions followed explosions.
Millions lost on cargo.
Millions lost on the rockets.
Investors thought Elon was crazy, but he wasn't.
NASA's biggest competitor became SpaceX. NASA hired SpaceX to handle many of its missions.
Tesla's shaky beginning
Tesla began shakily.
Clients detested their roadster.
They continued to miss deadlines.
Lotus would handle the car while Tesla focused on the EV component, easing Tesla's entry. The business experienced elegance creep. Modifying specific parts kept the car from getting worse.
Cost overruns, delays, and other factors changed the Elise-like car's appearance. Only 7% of the Tesla Roadster's parts matched its Lotus twin.
Tesla was about to die.
Elon saved the mess as CEO.
He fired 25% of the workforce to reduce costs.
Elon Musk transformed Tesla into the world's most valuable automaker by running it like a startup.
Tesla hasn't spent a dime on advertising. They let the media do the talking by investing in innovation.
Elon sheds. Elon tries. Elon learns. Elon refines.
Twitter doesn't worry me.
The media is shocked. I’m not.
This is just Elon being Elon.
Elon makes lean.
Elon tries new things.
Elon listens to feedback.
Elon refines.
Besides Twitter will always be Twitter.