





More on Web3 & Crypto

James Howell
3 years ago
Which Metaverse Is Better, Decentraland or Sandbox?
The metaverse is the most commonly used term in current technology discussions. While the entire tech ecosystem awaits the metaverse's full arrival, defining it is difficult. Imagine the internet in the '80s! The metaverse is a three-dimensional virtual world where users can interact with digital solutions and each other as digital avatars.
The metaverse is a three-dimensional virtual world where users can interact with digital solutions and each other as digital avatars.
Among the metaverse hype, the Decentraland vs Sandbox debate has gained traction. Both are decentralized metaverse platforms with no central authority. So, what's the difference and which is better? Let us examine the distinctions between Decentraland and Sandbox.
2 Popular Metaverse Platforms Explained
The first step in comparing sandbox and Decentraland is to outline the definitions. Anyone keeping up with the metaverse news has heard of the two current leaders. Both have many similarities, but also many differences. Let us start with defining both platforms to see if there is a winner.
Decentraland
Decentraland, a fully immersive and engaging 3D metaverse, launched in 2017. It allows players to buy land while exploring the vast virtual universe. Decentraland offers a wide range of activities for its visitors, including games, casinos, galleries, and concerts. It is currently the longest-running metaverse project.
Decentraland began with a $24 million ICO and went public in 2020. The platform's virtual real estate parcels allow users to create a variety of experiences. MANA and LAND are two distinct tokens associated with Decentraland. MANA is the platform's native ERC-20 token, and users can burn MANA to get LAND, which is ERC-721 compliant. The MANA coin can be used to buy avatars, wearables, products, and names on Decentraland.
Sandbox
Sandbox, the next major player, began as a blockchain-based virtual world in 2011 and migrated to a 3D gaming platform in 2017. The virtual world allows users to create, play, own, and monetize their virtual experiences. Sandbox aims to empower artists, creators, and players in the blockchain community to customize the platform. Sandbox gives the ideal means for unleashing creativity in the development of the modern gaming ecosystem.
The project combines NFTs and DAOs to empower a growing community of gamers. A new play-to-earn model helps users grow as gamers and creators. The platform offers a utility token, SAND, which is required for all transactions.
What are the key points from both metaverse definitions to compare Decentraland vs sandbox?
It is ideal for individuals, businesses, and creators seeking new artistic, entertainment, and business opportunities. It is one of the rapidly growing Decentralized Autonomous Organization projects. Holders of MANA tokens also control the Decentraland domain.
Sandbox, on the other hand, is a blockchain-based virtual world that runs on the native token SAND. On the platform, users can create, sell, and buy digital assets and experiences, enabling blockchain-based gaming. Sandbox focuses on user-generated content and building an ecosystem of developers.
Sandbox vs. Decentraland
If you try to find what is better Sandbox or Decentraland, then you might struggle with only the basic definitions. Both are metaverse platforms offering immersive 3D experiences. Users can freely create, buy, sell, and trade digital assets. However, both have significant differences, especially in MANA vs SAND.
For starters, MANA has a market cap of $5,736,097,349 versus $4,528,715,461, giving Decentraland an advantage.
The MANA vs SAND pricing comparison is also noteworthy. A SAND is currently worth $3664, while a MANA is worth $2452.
The value of the native tokens and the market capitalization of the two metaverse platforms are not enough to make a choice. Let us compare Sandbox vs Decentraland based on the following factors.
Workstyle
The way Decentraland and Sandbox work is one of the main comparisons. From a distance, they both appear to work the same way. But there's a lot more to learn about both platforms' workings. Decentraland has 90,601 digital parcels of land.
Individual parcels of virtual real estate or estates with multiple parcels of land are assembled. It also has districts with similar themes and plazas, which are non-tradeable parcels owned by the community. It has three token types: MANA, LAND, and WEAR.
Sandbox has 166,464 plots of virtual land that can be grouped into estates. Estates are owned by one person, while districts are owned by two or more people. The Sandbox metaverse has four token types: SAND, GAMES, LAND, and ASSETS.
Age
The maturity of metaverse projects is also a factor in the debate. Decentraland is clearly the winner in terms of maturity. It was the first solution to create a 3D blockchain metaverse. Decentraland made the first working proof of concept public. However, Sandbox has only made an Alpha version available to the public.
Backing
The MANA vs SAND comparison would also include support for both platforms. Digital Currency Group, FBG Capital, and CoinFund are all supporters of Decentraland. It has also partnered with Polygon, the South Korean government, Cyberpunk, and Samsung.
SoftBank, a Japanese multinational conglomerate focused on investment management, is another major backer. Sandbox has the backing of one of the world's largest investment firms, as well as Slack and Uber.
Compatibility
Wallet compatibility is an important factor in comparing the two metaverse platforms. Decentraland currently has a competitive advantage. How? Both projects' marketplaces accept ERC-20 wallets. However, Decentraland has recently improved by bridging with Walletconnect. So it can let Polygon users join Decentraland.
Scalability
Because Sandbox and Decentraland use the Ethereum blockchain, scalability is an issue. Both platforms' scalability is constrained by volatile tokens and high gas fees. So, scalability issues can hinder large-scale adoption of both metaverse platforms.
Buying Land
Decentraland vs Sandbox comparisons often include virtual real estate. However, the ability to buy virtual land on both platforms defines the user experience and differentiates them. In this case, Sandbox offers better options for users to buy virtual land by combining OpenSea and Sandbox. In fact, Decentraland users can only buy from the MANA marketplace.
Innovation
The rate of development distinguishes Sandbox and Decentraland. Both platforms have been developing rapidly new features. However, Sandbox wins by adopting Polygon NFT layer 2 solutions, which consume almost 100 times less energy than Ethereum.
Collaborations
The platforms' collaborations are the key to determining "which is better Sandbox or Decentraland." Adoption of metaverse platforms like the two in question can be boosted by association with reputable brands. Among the partners are Atari, Cyberpunk, and Polygon. Rather, Sandbox has partnered with well-known brands like OpenSea, CryptoKitties, The Walking Dead, Snoop Dogg, and others.
Platform Adaptivity
Another key feature that distinguishes Sandbox and Decentraland is the ease of use. Sandbox clearly wins in terms of platform access. It allows easy access via social media, email, or a Metamask wallet. However, Decentraland requires a wallet connection.
Prospects
The future development plans also play a big role in defining Sandbox vs Decentraland. Sandbox's future development plans include bringing the platform to mobile devices. This includes consoles like PlayStation and Xbox. By the end of 2023, the platform expects to have around 5000 games.
Decentraland, on the other hand, has no set plan. In fact, the team defines the decisions that appear to have value. They plan to add celebrities, creators, and brands soon, along with NFT ads and drops.
Final Words
The comparison of Decentraland vs Sandbox provides a balanced view of both platforms. You can see how difficult it is to determine which decentralized metaverse is better now. Sandbox is still in Alpha, whereas Decentraland has a working proof of concept.
Sandbox, on the other hand, has better graphics and is backed by some big names. But both have a long way to go in the larger decentralized metaverse.

Chris
2 years ago
What the World's Most Intelligent Investor Recently Said About Crypto
Cryptoshit. This thing is crazy to buy.

Charlie Munger is revered and powerful in finance.
Munger, vice chairman of Berkshire Hathaway, is noted for his wit, no-nonsense attitude to investment, and ability to spot promising firms and markets.
Munger's crypto views have upset some despite his reputation as a straight shooter.
“There’s only one correct answer for intelligent people, just totally avoid all the people that are promoting it.” — Charlie Munger
The Munger Interview on CNBC (4:48 secs)
This Monday, CNBC co-anchor Rebecca Quick interviewed Munger and brought up his 2007 statement, "I'm not allowed to have an opinion on this subject until I can present the arguments against my viewpoint better than the folks who are supporting it."
Great investing and life advice!
If you can't explain the opposing reasons, you're not informed enough to have an opinion.
In today's world, it's important to grasp both sides of a debate before supporting one.
Rebecca inquired:
Does your Wall Street Journal article on banning cryptocurrency apply? If so, would you like to present the counterarguments?
Mungers reply:
I don't see any viable counterarguments. I think my opponents are idiots, hence there is no sensible argument against my position.
Consider his words.
Do you believe Munger has studied both sides?
He said, "I assume my opponents are idiots, thus there is no sensible argument against my position."
This is worrisome, especially from a guy who once encouraged studying both sides before forming an opinion.
Munger said:
National currencies have benefitted humanity more than almost anything else.
Hang on, I think we located the perpetrator.
Munger thinks crypto will replace currencies.
False.
I doubt he studied cryptocurrencies because the name is deceptive.
He misread a headline as a Dollar destroyer.
Cryptocurrencies are speculations.
Like Tesla, Amazon, Apple, Google, Microsoft, etc.
Crypto won't replace dollars.
In the interview with CNBC, Munger continued:
“I’m not proud of my country for allowing this crap, what I call the cryptoshit. It’s worthless, it’s no good, it’s crazy, it’ll do nothing but harm, it’s anti-social to allow it.” — Charlie Munger
Not entirely inaccurate.
Daily cryptos are established solely to pump and dump regular investors.
Let's get into Munger's crypto aversion.
Rat poison is bitcoin.
Munger famously dubbed Bitcoin rat poison and a speculative bubble that would implode.
Partially.
But the bubble broke. Since 2021, the market has fallen.
Scam currencies and NFTs are being eliminated, which I like.
Whoa.
Why does Munger doubt crypto?
Mungers thinks cryptocurrencies has no intrinsic value.
He worries about crypto fraud and money laundering.
Both are valid issues.
Yet grouping crypto is intellectually dishonest.
Ethereum, Bitcoin, Solana, Chainlink, Flow, and Dogecoin have different purposes and values (not saying they’re all good investments).
Fraudsters who hurt innocents will be punished.
Therefore, complaining is useless.
Why not stop it? Repair rather than complain.
Regrettably, individuals today don't offer solutions.
Blind Areas for Mungers
As with everyone, Mungers' bitcoin views may be impacted by his biases and experiences.
OK.
But Munger has always advocated classic value investing and may be wary of investing in an asset outside his expertise.
Mungers' banking and insurance investments may influence his bitcoin views.
Could a coworker or acquaintance have told him crypto is bad and goes against traditional finance?
Right?
Takeaways
Do you respect Charlie Mungers?
Yes and no, like any investor or individual.
To understand Mungers' bitcoin beliefs, you must be critical.
Mungers is a successful investor, but his views about bitcoin should be considered alongside other viewpoints.
Munger’s success as an investor has made him an influencer in the space.
Influence gives power.
He controls people's thoughts.
Munger's ok. He will always be heard.
I'll do so cautiously.

Marco Manoppo
3 years ago
Failures of DCG and Genesis
Don't sleep with your own sister.

70% of lottery winners go broke within five years. You've heard the last one. People who got rich quickly without setbacks and hard work often lose it all. My father said, "Easy money is easily lost," and a wealthy friend who owns a family office said, "The first generation makes it, the second generation spends it, and the third generation blows it."
This is evident. Corrupt politicians in developing countries live lavishly, buying their third wives' fifth Hermès bag and celebrating New Year's at The Brando Resort. A successful businessperson from humble beginnings is more conservative with money. More so if they're atom-based, not bit-based. They value money.
Crypto can "feel" easy. I have nothing against capital market investing. The global financial system is shady, but that's another topic. The problem started when those who took advantage of easy money started affecting other businesses. VCs did minimal due diligence on FTX because they needed deal flow and returns for their LPs. Lenders did minimum diligence and underwrote ludicrous loans to 3AC because they needed revenue.
Alameda (hence FTX) and 3AC made "easy money" Genesis and DCG aren't. Their businesses are more conventional, but they underestimated how "easy money" can hurt them.
Genesis has been the victim of easy money hubris and insolvency, losing $1 billion+ to 3AC and $200M to FTX. We discuss the implications for the broader crypto market.
Here are the quick takeaways:
Genesis is one of the largest and most notable crypto lenders and prime brokerage firms.
DCG and Genesis have done related party transactions, which can be done right but is a bad practice.
Genesis owes DCG $1.5 billion+.
If DCG unwinds Grayscale's GBTC, $9-10 billion in BTC will hit the market.
DCG will survive Genesis.
What happened?
Let's recap the FTX shenanigan from two weeks ago. Shenanigans! Delphi's tweet sums up the craziness. Genesis has $175M in FTX.
Cred's timeline: I hate bad crisis management. Yes, admitting their balance sheet hole right away might've sparked more panic, and there's no easy way to convey your trouble, but no one ever learns.
By November 23, rumors circulated online that the problem could affect Genesis' parent company, DCG. To address this, Barry Silbert, Founder, and CEO of DCG released a statement to shareholders.
A few things are confirmed thanks to this statement.
DCG owes $1.5 billion+ to Genesis.
$500M is due in 6 months, and the rest is due in 2032 (yes, that’s not a typo).
Unless Barry raises new cash, his last-ditch efforts to repay the money will likely push the crypto market lower.
Half a year of GBTC fees is approximately $100M.
They can pay $500M with GBTC.
With profits, sell another port.
Genesis has hired a restructuring adviser, indicating it is in trouble.
Rehypothecation
Every crypto problem in the past year seems to be rehypothecation between related parties, excessive leverage, hubris, and the removal of the money printer. The Bankless guys provided a chart showing 2021 crypto yield.

In June 2022, @DataFinnovation published a great investigation about 3AC and DCG. Here's a summary.
3AC borrowed BTC from Genesis and pledged it to create Grayscale's GBTC shares.
3AC uses GBTC to borrow more money from Genesis.
This lets 3AC leverage their capital.
3AC's strategy made sense because GBTC had a premium, creating "free money."
GBTC's discount and LUNA's implosion caused problems.
3AC lost its loan money in LUNA.
Margin called on 3ACs' GBTC collateral.
DCG bought GBTC to avoid a systemic collapse and a larger discount.
Genesis lost too much money because 3AC can't pay back its loan. DCG "saved" Genesis, but the FTX collapse hurt Genesis further, forcing DCG and Genesis to seek external funding.
bruh…
Learning Experience
Co-borrowing. Unnecessary rehypothecation. Extra space. Governance disaster. Greed, hubris. Crypto has repeatedly shown it can recreate traditional financial system disasters quickly. Working in crypto is one of the best ways to learn crazy financial tricks people will do for a quick buck much faster than if you dabble in traditional finance.
Moving Forward
I think the crypto industry needs to consider its future. This is especially true for professionals. I'm not trying to scare you. In 2018 and 2020, I had doubts. No doubts now. Detailing the crypto industry's potential outcomes helped me gain certainty and confidence in its future. This includes VCs' benefits and talking points during the bull market, as well as what would happen if government regulations became hostile, etc. Even if that happens, I'm certain. This is permanent. I may write a post about that soon.
Sincerely,
M.
You might also like

Web3Lunch
3 years ago
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.

The space had better days. Those greenish spikes...oh wow, haven't felt that in ages. Cryptocurrencies and NFTs have lost popularity. Google agrees. Both are declining.
As seen below, crypto interest spiked in May because of the Luna fall. NFT interest is similar to early October last year.
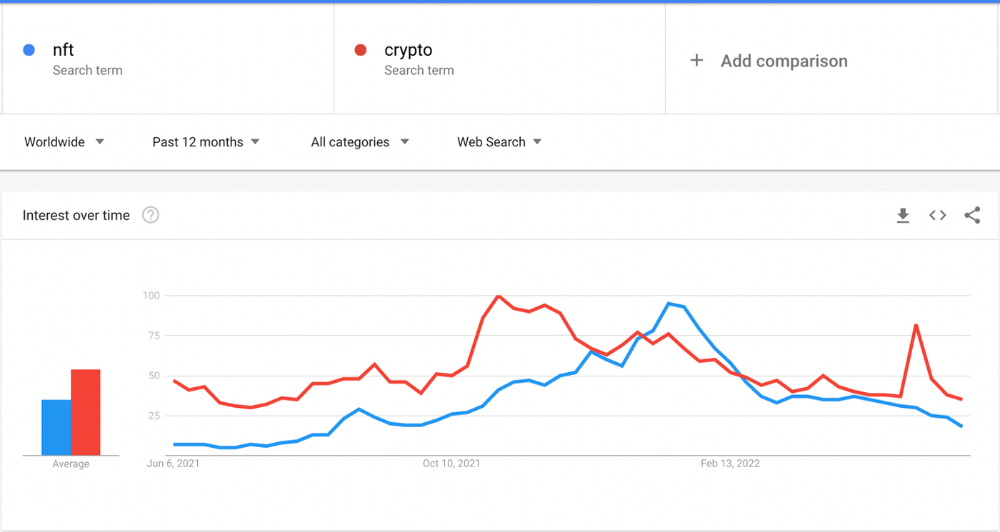
This makes me think NFTs are mostly hype and FOMO. No art or community. I've seen enough initiatives to know that communities stick around if they're profitable. Once it starts falling, they move on to the next project. The space has no long-term investments. Flip everything.
OpenSea trading volume has stayed steady for months. May's volume is 1.8 million ETH ($3.3 billion).
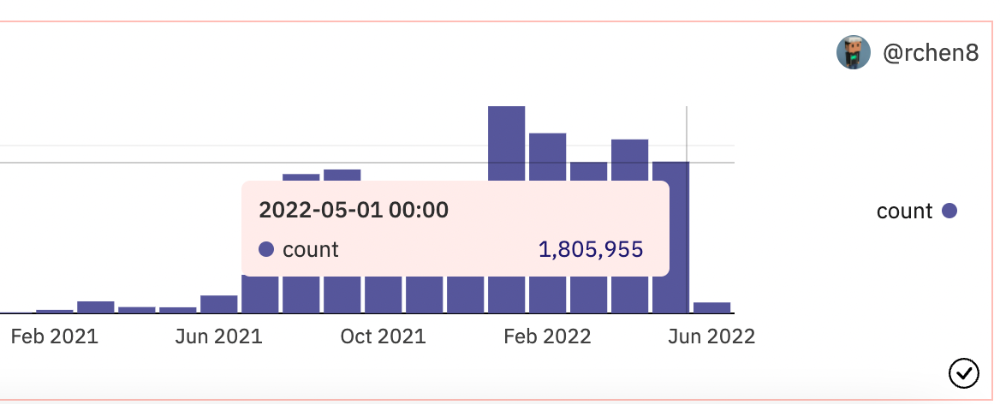
Despite this, I think NFTs and crypto will stick around. In bad markets, builders gain most.
Only 4k developers are active on Ethereum blockchain. It's low. A great chance for the space enthusiasts.
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.
Nathaniel Chastian, an OpenSea employee, traded on insider knowledge. He'll serve 40 years for that.
Here's what happened if you're unfamiliar.
OpenSea is a secondary NFT marketplace. Their homepage featured remarkable drops. Whatever gets featured there, NFT prices will rise 5x.
Chastian was at OpenSea. He chose forthcoming NFTs for OpenSeas' webpage.
Using anonymous digital currency wallets and OpenSea accounts, he would buy NFTs before promoting them on the homepage, showcase them, and then sell them for at least 25 times the price he paid.
From June through September 2021, this happened. Later caught, fired. He's charged with wire fraud and money laundering, each carrying a 20-year maximum penalty.
Although web3 space is all about decentralization, a step like this is welcomed since it restores faith in the area. We hope to see more similar examples soon.
Here's the press release.

Understanding smart contracts
@cantino.eth has a Twitter thread on smart contracts. Must-read. Also, he appears educated about the space, so follow him.


Techletters
2 years ago
Using Synthesia, DALL-E 2, and Chat GPT-3, create AI news videos
Combining AIs creates realistic AI News Videos.

Powerful AI tools like Chat GPT-3 are trending. Have you combined AIs?
The 1-minute fake news video below is startlingly realistic. Artificial Intelligence developed NASA's Mars exploration breakthrough video (AI). However, integrating the aforementioned AIs generated it.
AI-generated text for the Chat GPT-3 based on a succinct tagline
DALL-E-2 AI generates an image from a brief slogan.
Artificial intelligence-generated avatar and speech
This article shows how to use and mix the three AIs to make a realistic news video. First, watch the video (1 minute).
Talk GPT-3
Chat GPT-3 is an OpenAI NLP model. It can auto-complete text and produce conversational responses.
Try it at the playground. The AI will write a comprehensive text from a brief tagline. Let's see what the AI generates with "Breakthrough in Mars Project" as the headline.

Amazing. Our tagline matches our complete and realistic text. Fake news can start here.
DALL-E-2
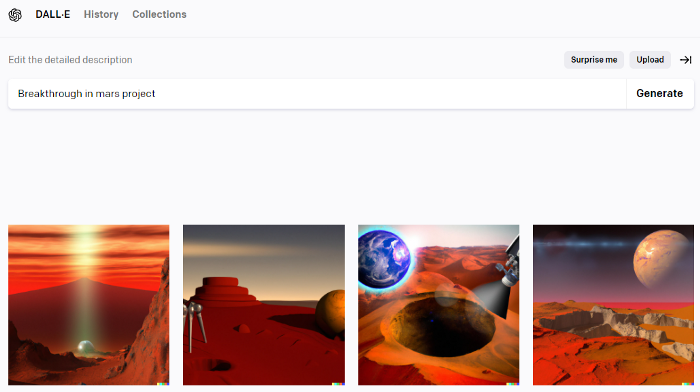
OpenAI's huge transformer-based language model DALL-E-2. Its GPT-3 basis is geared for image generation. It can generate high-quality photos from a brief phrase and create artwork and images of non-existent objects.
DALL-E-2 can create a news video background. We'll use "Breakthrough in Mars project" again. Our AI creates four striking visuals. Last.
Synthesia
Synthesia lets you quickly produce videos with AI avatars and synthetic vocals.
Avatars are first. Rosie it is.

Upload and select DALL-backdrop. E-2's
Copy the Chat GPT-3 content and choose a synthetic voice.
Voice: English (US) Professional.
Finally, we generate and watch or download our video.
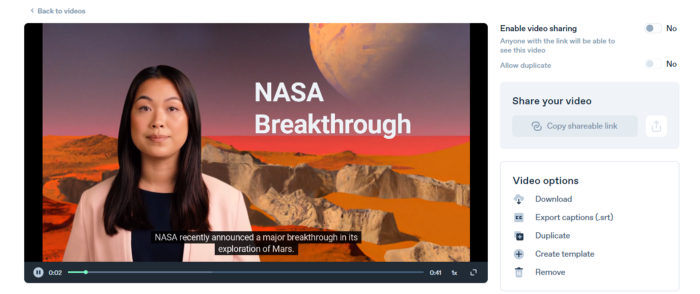
Synthesia AI completes the AI video.
Overview & Resources
We used three AIs to make surprisingly realistic NASA Mars breakthrough fake news in this post. Synthesia generates an avatar and a synthetic voice, therefore it may be four AIs.
These AIs created our fake news.
AI-generated text for the Chat GPT-3 based on a succinct tagline
DALL-E-2 AI generates an image from a brief slogan.
Artificial intelligence-generated avatar and speech

Maria Urkedal York
3 years ago
When at work, don't give up; instead, think like a designer.
How to reframe irritation and go forward

“… before you can figure out where you are going, you need to know where you are, and once you know and accept where you are, you can design your way to where you want to be.” — Bill Burnett and Dave Evans
“You’ve been here before. But there are some new ingredients this time. What can tell yourself that will make you understand that now isn’t just like last year? That there’s something new in this August.”
My coach paused. I sighed, inhaled deeply, and considered her question.
What could I say? I simply needed a plan from her so everything would fall into place and I could be the happy, successful person I want to be.
Time passed. My mind was exhausted from running all morning, all summer, or the last five years, searching for what to do next and how to get there.
Calmer, I remembered that my coach's inquiry had benefited me throughout the summer. The month before our call, I read Designing Your Work Life — How to Thrive and Change and Find Happiness at Work from Standford University’s Bill Burnett and Dave Evans.
A passage in their book felt like a lifeline: “We have something important to say to you: Wherever you are in your work life, whatever job you are doing, it’s good enough. For now. Not forever. For now.”
As I remembered this book on the coaching call, I wondered if I could embrace where I am in August and say my job life is good enough for now. Only temporarily.
I've done that since. I'm getting unstuck.
Here's how you can take the first step in any area where you feel stuck.
How to acquire the perspective of "Good enough for now" for yourself
We’ve all heard the advice to just make the best of a bad situation. That´s not bad advice, but if you only make the best of a bad situation, you are still in a bad situation. It doesn’t get to the root of the problem or offer an opportunity to change the situation. You’re more cheerfully navigating lousiness, which is an improvement, but not much of one and rather hard to sustain over time.” — Bill Burnett and Dave Evans
Reframing Burnett at Evans says good enough for now is the key to being happier at work. Because, as they write, a designer always has options.
Choosing to believe things are good enough for now is liberating. It helps us feel less victimized and less judged. Accepting our situation helps us become unstuck.
Let's break down the process, which designers call constructing your way ahead, into steps you can take today.
Writing helps get started. First, write down your challenge and why it's essential to you. If pen and paper help, try this strategy:
Make the decision to accept the circumstance as it is. Designers always begin by acknowledging the truth of the situation. You now refrain from passing judgment. Instead, you simply describe the situation as accurately as you can. This frees us from negative thought patterns that prevent us from seeing the big picture and instead keep us in a tunnel of negativity.
Look for a reframing right now. Begin with good enough for the moment. Take note of how your body feels as a result. Tell yourself repeatedly that whatever is occurring is sufficient for the time being. Not always, but just now. If you want to, you can even put it in writing and repeatedly breathe it in, almost like a mantra.
You can select a reframe that is more relevant to your situation once you've decided that you're good enough for now and have allowed yourself to believe it. Try to find another perspective that is possible, for instance, if you feel unappreciated at work and your perspective of I need to use and be recognized for all my new skills in my job is making you sad and making you want to resign. For instance, I can learn from others at work and occasionally put my new abilities to use.
After that, leave your mind and act in accordance with your new perspective. Utilize the designer's bias for action to test something out and create a prototype that you can learn from. Your beginning point for creating experiences that will support the new viewpoint derived from the aforementioned point is the new perspective itself. By doing this, you recognize a circumstance at work where you can provide value to yourself or your workplace and then take appropriate action. Send two or three coworkers from whom you wish to learn anything an email, for instance, asking them to get together for coffee or a talk.
Choose tiny, doable actions. You prioritize them at work.
Let's assume you're feeling disconnected at work, so you make a list of folks you may visit each morning or invite to lunch. If you're feeling unmotivated and tired, take a daily walk and treat yourself to a decent coffee.
This may be plenty for now. If you want to take this procedure further, use Burnett and Evans' internet tools and frameworks.
Developing the daily practice of reframing
“We’re not discontented kids in the backseat of the family minivan, but how many of us live our lives, especially our work lives, as if we are?” — Bill Burnett and Dave Evans
I choose the good enough for me perspective every day, often. No quick fix. Am a failing? Maybe a little bit, but I like to think of it more as building muscle.
This way, every time I tell myself it's ok, I hear you. For now, that muscle gets stronger.
Hopefully, reframing will become so natural for us that it will become a habit, and not a technique anymore.
If you feel like you’re stuck in your career or at work, the reframe of Good enough, for now, might be valuable, so just go ahead and try it out right now.
And while you’re playing with this, why not think of other areas of your life too, like your relationships, where you live — even your writing, and see if you can feel a shift?