


Elon Musk’s Rich Life Is a Nightmare
I'm sure you haven't read about Elon's other side.
Elon divorced badly.
Nobody's surprised.
Imagine you're a parent. Someone isn't home year-round. What's next?
That’s what happened to YOLO Elon.
He can do anything. He can intervene in wars, shoot his mouth off, bang anyone he wants, avoid tax, make cool tech, buy anything his ego desires, and live anywhere exotic.
Few know his billionaire backstory. I'll tell you so you don't worship his lifestyle. It’s a cult.
Only his career succeeds. His life is a nightmare otherwise.
Psychopaths' schedule
Elon has said he works 120-hour weeks.
As he told the reporter about his job, he choked up, which was unusual for him.
His crazy workload and lack of sleep forced him to scold innocent Wall Street analysts. Later, he apologized.
In the same interview, he admits he hadn't taken more than a week off since 2001, when he was bedridden with malaria. Elon stays home after a near-death experience.
He's rarely outside.
Elon says he sometimes works 3 or 4 days straight.
He admits his crazy work schedule has cost him time with his kids and friends.
Elon's a slave
Elon's birthday description made him emotional.
Elon worked his entire birthday.
"No friends, nothing," he said, stuttering.
His brother's wedding in Catalonia was 48 hours after his birthday. That meant flying there from Tesla's factory prison.
He arrived two hours before the big moment, barely enough time to eat and change, let alone see his brother.
Elon had to leave after the bouquet was tossed to a crowd of billionaire lovers. He missed his brother's first dance with his wife.
Shocking.
He went straight to Tesla's prison.
The looming health crisis
Elon was asked if overworking affected his health.
Not great. Friends are worried.
Now you know why Elon tweets dumb things. Working so hard has probably caused him mental health issues.
Mental illness removed my reality filter. You do stupid things because you're tired.
Astronauts pelted Elon
Elon's overwork isn't the first time his life has made him emotional.
When asked about Neil Armstrong and Gene Cernan criticizing his SpaceX missions, he got emotional. Elon's heroes.
They're why he started the company, and they mocked his work. In another interview, we see how Elon’s business obsession has knifed him in the heart.
Once you have a company, you must feed, nurse, and care for it, even if it destroys you.
"Yep," Elon says, tearing up.
In the same interview, he's asked how Tesla survived the 2008 recession. Elon stopped the interview because he was crying. When Tesla and SpaceX filed for bankruptcy in 2008, he nearly had a nervous breakdown. He called them his "children."
All the time, he's risking everything.
Jack Raines explains best:
Too much money makes you a slave to your net worth.
Elon's emotions are admirable. It's one of the few times he seems human, not like an alien Cyborg.
Stop idealizing Elon's lifestyle
Building a side business that becomes a billion-dollar unicorn startup is a nightmare.
"Billionaire" means financially wealthy but otherwise broke. A rich life includes more than business and money.
This post is a summary. Read full article here
More on Entrepreneurship/Creators

Greg Lim
3 years ago
How I made $160,000 from non-fiction books
I've sold over 40,000 non-fiction books on Amazon and made over $160,000 in six years while writing on the side.
I have a full-time job and three young sons; I can't spend 40 hours a week writing. This article describes my journey.
I write mainly tech books:
Thanks to my readers, many wrote positive evaluations. Several are bestsellers.
A few have been adopted by universities as textbooks:
My books' passive income allows me more time with my family.
Knowing I could quit my job and write full time gave me more confidence. And I find purpose in my work (i am in christian ministry).
I'm always eager to write. When work is a dread or something bad happens, writing gives me energy. Writing isn't scary. In fact, I can’t stop myself from writing!
Writing has also established my tech authority. Universities use my books, as I've said. Traditional publishers have asked me to write books.
These mindsets helped me become a successful nonfiction author:
1. You don’t have to be an Authority
Yes, I have computer science experience. But I'm no expert on my topics. Before authoring "Beginning Node.js, Express & MongoDB," my most profitable book, I had no experience with those topics. Node was a new server-side technology for me. Would that stop me from writing a book? It can. I liked learning a new technology. So I read the top three Node books, took the top online courses, and put them into my own book (which makes me know more than 90 percent of people already).
I didn't have to worry about using too much jargon because I was learning as I wrote. An expert forgets a beginner's hardship.
"The fellow learner can aid more than the master since he knows less," says C.S. Lewis. The problem he must explain is recent. The expert has forgotten.”
2. Solve a micro-problem (Niching down)
I didn't set out to write a definitive handbook. I found a market with several challenges and wrote one book. Ex:
- Instead of web development, what about web development using Angular?
- Instead of Blockchain, what about Blockchain using Solidity and React?
- Instead of cooking recipes, how about a recipe for a specific kind of diet?
- Instead of Learning math, what about Learning Singapore Math?
3. Piggy Backing Trends
The above topics may still be a competitive market. E.g. Angular, React. To stand out, include the latest technologies or trends in your book. Learn iOS 15 instead of iOS programming. Instead of personal finance, what about personal finance with NFTs.
Even though you're a newbie author, your topic is well-known.
4. Publish short books
My books are known for being direct. Many people like this:
Your reader will appreciate you cutting out the fluff and getting to the good stuff. A reader can finish and review your book.
Second, short books are easier to write. Instead of creating a 500-page book for $50 (which few will buy), write a 100-page book that answers a subset of the problem and sell it for less. (You make less, but that's another subject). At least it got published instead of languishing. Less time spent creating a book means less time wasted if it fails. Write a small-bets book portfolio like Daniel Vassallo!
Third, it's $2.99-$9.99 on Amazon (gets 70 percent royalties for ebooks). Anything less receives 35% royalties. $9.99 books have 20,000–30,000 words. If you write more and charge more over $9.99, you get 35% royalties. Why not make it a $9.99 book?
(This is the ebook version.) Paperbacks cost more. Higher royalties allow for higher prices.
5. Validate book idea
Amazon will tell you if your book concept, title, and related phrases are popular. See? Check its best-sellers list.
150,000 is preferable. It sells 2–3 copies daily. Consider your rivals. Profitable niches have high demand and low competition.
Don't be afraid of competitive niches. First, it shows high demand. Secondly, what are the ways you can undercut the completion? Better book? Or cheaper option? There was lots of competition in my NodeJS book's area. None received 4.5 stars or more. I wrote a NodeJS book. Today, it's a best-selling Node book.
What’s Next
So long. Part II follows. Meanwhile, I will continue to write more books!
Follow my journey on Twitter.
This post is a summary. Read full article here

Bastian Hasslinger
3 years ago
Before 2021, most startups had excessive valuations. It is currently causing issues.

Higher startup valuations are often favorable for all parties. High valuations show a business's potential. New customers and talent are attracted. They earn respect.
Everyone benefits if a company's valuation rises.
Founders and investors have always been incentivized to overestimate a company's value.
Post-money valuations were inflated by 2021 market expectations and the valuation model's mechanisms.
Founders must understand both levers to handle a normalizing market.
2021, the year of miracles
2021 must've seemed miraculous to entrepreneurs, employees, and VCs. Valuations rose, and funding resumed after the first Covid-19 epidemic caution.
In 2021, VC investments increased from $335B to $643B. 518 new worldwide unicorns vs. 134 in 2020; 951 US IPOs vs. 431.
Things can change quickly, as 2020-21 showed.
Rising interest rates, geopolitical developments, and normalizing technology conditions drive down share prices and tech company market caps in 2022. Zoom, the poster-child of early lockdown success, is down 37% since 1st Jan.
Once-inflated valuations can become a problem in a normalizing market, especially for founders, employees, and early investors.
the reason why startups are always overvalued
To see why inflated valuations are a problem, consider one of its causes.
Private company values only fluctuate following a new investment round, unlike publicly-traded corporations. The startup's new value is calculated simply:
(Latest round share price) x (total number of company shares)
This is the industry standard Post-Money Valuation model.
Let’s illustrate how it works with an example. If a VC invests $10M for 1M shares (at $10/share), and the company has 10M shares after the round, its Post-Money Valuation is $100M (10/share x 10M shares).
This approach might seem like the most natural way to assess a business, but the model often unintentionally overstates the underlying value of the company even if the share price paid by the investor is fair. All shares aren't equal.
New investors in a corporation will always try to minimize their downside risk, or the amount they lose if things go wrong. New investors will try to negotiate better terms and pay a premium.
How the value of a struggling SpaceX increased
SpaceX's 2008 Series D is an example. Despite the financial crisis and unsuccessful rocket launches, the company's Post-Money Valuation was 36% higher after the investment round. Why?
Series D SpaceX shares were protected. In case of liquidation, Series D investors were guaranteed a 2x return before other shareholders.
Due to downside protection, investors were willing to pay a higher price for this new share class.
The Post-Money Valuation model overpriced SpaceX because it viewed all the shares as equal (they weren't).
Why entrepreneurs, workers, and early investors stand to lose the most
Post-Money Valuation is an effective and sufficient method for assessing a startup's valuation, despite not taking share class disparities into consideration.
In a robust market, where the firm valuation will certainly expand with the next fundraising round or exit, the inflated value is of little significance.
Fairness endures. If a corporation leaves at a greater valuation, each stakeholder will receive a proportional distribution. (i.e., 5% of a $100M corporation yields $5M).
SpaceX's inherent overvaluation was never a problem. Had it been sold for less than its Post-Money Valuation, some shareholders, including founders, staff, and early investors, would have seen their ownership drop.
The unforgiving world of 2022
In 2022, founders, employees, and investors who benefited from inflated values will face below-valuation exits and down-rounds.
For them, 2021 will be a curse, not a blessing.
Some tech giants are worried. Klarna's valuation fell from $45B (Oct 21) to $30B (Jun 22), Canvas from $40B to $27B, and GoPuffs from $17B to $8.3B.
Shazam and Blue Apron have to exit or IPO at a cheaper price. Premium share classes are protected, while others receive less. The same goes for bankrupts.
Those who continue at lower valuations will lose reputation and talent. When their value declines by half, generous employee stock options become less enticing, and their ability to return anything is questioned.
What can we infer about the present situation?
Such techniques to enhance your company's value or stop a normalizing market are fiction.
The current situation is a painful reminder for entrepreneurs and a crucial lesson for future firms.
The devastating market fall of the previous six months has taught us one thing:
Keep in mind that any valuation is speculative. Money Post A startup's valuation is a highly simplified approximation of its true value, particularly in the early phases when it lacks significant income or a cutting-edge product. It is merely a projection of the future and a hypothetical meter. Until it is achieved by an exit, a valuation is nothing more than a number on paper.
Assume the value of your company is lower than it was in the past. Your previous valuation might not be accurate now due to substantial changes in the startup financing markets. There is little reason to think that your company's value will remain the same given the 50%+ decline in many newly listed IT companies. Recognize how the market situation is changing and use caution.
Recognize the importance of the stake you hold. Each share class has a unique value that varies. Know the sort of share class you own and how additional contractual provisions affect the market value of your security. Frameworks have been provided by Metrick and Yasuda (Yale & UC) and Gornall and Strebulaev (Stanford) for comprehending the terms that affect investors' cash-flow rights upon withdrawal. As a result, you will be able to more accurately evaluate your firm and determine the worth of each share class.
Be wary of approving excessively protective share terms.
The trade-offs should be considered while negotiating subsequent rounds. Accepting punitive contractual terms could first seem like a smart option in order to uphold your inflated worth, but you should proceed with caution. Such provisions ALWAYS result in misaligned shareholders, with common shareholders (such as you and your staff) at the bottom of the list.

Aaron Dinin, PhD
3 years ago
There Are Two Types of Entrepreneurs in the World Make sure you are aware of your type!
Know why it's important.

The entrepreneur I was meeting with said, "I should be doing crypto, or maybe AI? Aren't those the hot spots? I should look there for a startup idea.”
I shook my head. Yes, they're exciting, but that doesn't mean they're best for you and your business.
“There are different types of entrepreneurs?” he asked.
I said "obviously." Two types, actually. Knowing what type of entrepreneur you are helps you build the right startup.
The two types of businesspeople
The best way for me to describe the two types of entrepreneurs is to start by telling you exactly the kinds of entrepreneurial opportunities I never get excited about: future opportunities.
In the early 1990s, my older brother showed me the World Wide Web and urged me to use it. Unimpressed, I returned to my Super Nintendo.
My roommate tried to get me to join Facebook as a senior in college. I remember thinking, This is dumb. Who'll use it?
In 2011, my best friend tried to convince me to buy bitcoin and I laughed.
Heck, a couple of years ago I had to buy a new car, and I never even considered buying something that didn’t require fossilized dinosaur bones.
I'm no visionary. I don't anticipate the future. I focus on the present.
This tendency makes me a problem-solving entrepreneur. I identify entrepreneurial opportunities by spotting flaws and/or inefficiencies in the world and devising solutions.
There are other ways to find business opportunities. Visionary entrepreneurs also exist. I don't mean visionary in the hyperbolic sense that implies world-changing impact. I mean visionary as an entrepreneur who identifies future technological shifts that will change how people work and live and create new markets.
Problem-solving and visionary entrepreneurs are equally good. But the two approaches to building companies are very different. Knowing the type of entrepreneur you are will help you build a startup that fits your worldview.
What is the distinction?
Let's use some simple hypotheticals to compare problem-solving and visionary entrepreneurship.
Imagine a city office building without nearby restaurants. Those office workers love to eat. Sometimes they'd rather eat out than pack a lunch. As an entrepreneur, you can solve the lack of nearby restaurants. You'd open a restaurant near that office, say a pizza parlor, and get customers because you solved the lack of nearby restaurants. Problem-solving entrepreneurship.
Imagine a new office building in a developing area with no residents or workers. In this scenario, a large office building is coming. The workers will need to eat then. As a visionary entrepreneur, you're excited about the new market and decide to open a pizzeria near the construction to meet demand.
Both possibilities involve the same product. You opened a pizzeria. How you launched that pizza restaurant and what will affect its success are different.
Why is the distinction important?
Let's say you opened a pizzeria near an office. You'll probably get customers. Because people are nearby and demand isn't being met, someone from a nearby building will stop in within the first few days of your pizzeria's grand opening. This makes solving the problem relatively risk-free. You'll get customers unless you're a fool.
The market you're targeting existed before you entered it, so you're not guaranteed success. This means people in that market solved the lack of nearby restaurants. Those office workers are used to bringing their own lunches. Why should your restaurant change their habits? Even when they eat out, they're used to traveling far. They've likely developed pizza preferences.
To be successful with your problem-solving startup, you must convince consumers to change their behavior, which is difficult.
Unlike opening a pizza restaurant near a construction site. Once the building opens, workers won't have many preferences or standardized food-getting practices. Your pizza restaurant can become the incumbent quickly. You'll be the first restaurant in the area, so you'll gain a devoted following that makes your food a routine.
Great, right? It's easier than changing people's behavior. The benefit comes with a risk. Opening a pizza restaurant near a construction site increases future risk. What if builders run out of money? No one moves in? What if the building's occupants are the National Association of Pizza Haters? Then you've opened a pizza restaurant next to pizza haters.
Which kind of businessperson are you?
This isn't to say one type of entrepreneur is better than another. Each type of entrepreneurship requires different skills.
As my simple examples show, a problem-solving entrepreneur must operate in markets with established behaviors and habits. To be successful, you must be able to teach a market a new way of doing things.
Conversely, the challenge of being a visionary entrepreneur is that you have to be good at predicting the future and getting in front of that future before other people.
Both are difficult in different ways. So, smart entrepreneurs don't just chase opportunities. Smart entrepreneurs pursue opportunities that match their skill sets.
You might also like

Katrine Tjoelsen
3 years ago
8 Communication Hacks I Use as a Young Employee
Learn these subtle cues to gain influence.

Hate being ignored?
As a 24-year-old, I struggled at work. Attention-getting tips How to avoid being judged by my size, gender, and lack of wrinkles or gray hair?
I've learned seniority hacks. Influence. Within two years as a product manager, I led a team. I'm a Stanford MBA student.
These communication hacks can make you look senior and influential.
1. Slowly speak
We speak quickly because we're afraid of being interrupted.
When I doubt my ideas, I speak quickly. How can we slow down? Jamie Chapman says speaking slowly saps our energy.
Chapman suggests emphasizing certain words and pausing.
2. Interrupted? Stop the stopper
Someone interrupt your speech?
Don't wait. "May I finish?" No pause needed. Stop interrupting. I first tried this in Leadership Laboratory at Stanford. How quickly I gained influence amazed me.
Next time, try “May I finish?” If that’s not enough, try these other tips from Wendy R.S. O’Connor.
3. Context
Others don't always see what's obvious to you.
Through explanation, you help others see the big picture. If a senior knows it, you help them see where your work fits.
4. Don't ask questions in statements
“Your statement lost its effect when you ended it on a high pitch,” a group member told me. Upspeak, it’s called. I do it when I feel uncertain.
Upspeak loses influence and credibility. Unneeded. When unsure, we can say "I think." We can even ask a proper question.
Someone else's boasting is no reason to be dismissive. As leaders and colleagues, we should listen to our colleagues even if they use this speech pattern.
Give your words impact.
5. Signpost structure
Signposts improve clarity by providing structure and transitions.
Communication coach Alexander Lyon explains how to use "first," "second," and "third" He explains classic and summary transitions to help the listener switch topics.
Signs clarify. Clarity matters.

6. Eliminate email fluff
“Fine. When will the report be ready? — Jeff.”
Notice how senior leaders write short, direct emails? I often use formalities like "dear," "hope you're well," and "kind regards"
Formality is (usually) unnecessary.
7. Replace exclamation marks with periods
See how junior an exclamation-filled email looks:
Hi, all!
Hope you’re as excited as I am for tomorrow! We’re celebrating our accomplishments with cake! Join us tomorrow at 2 pm!
See you soon!
Why the exclamation points? Why not just one?
Hi, all.
Hope you’re as excited as I am for tomorrow. We’re celebrating our accomplishments with cake. Join us tomorrow at 2 pm!
See you soon.
8. Take space
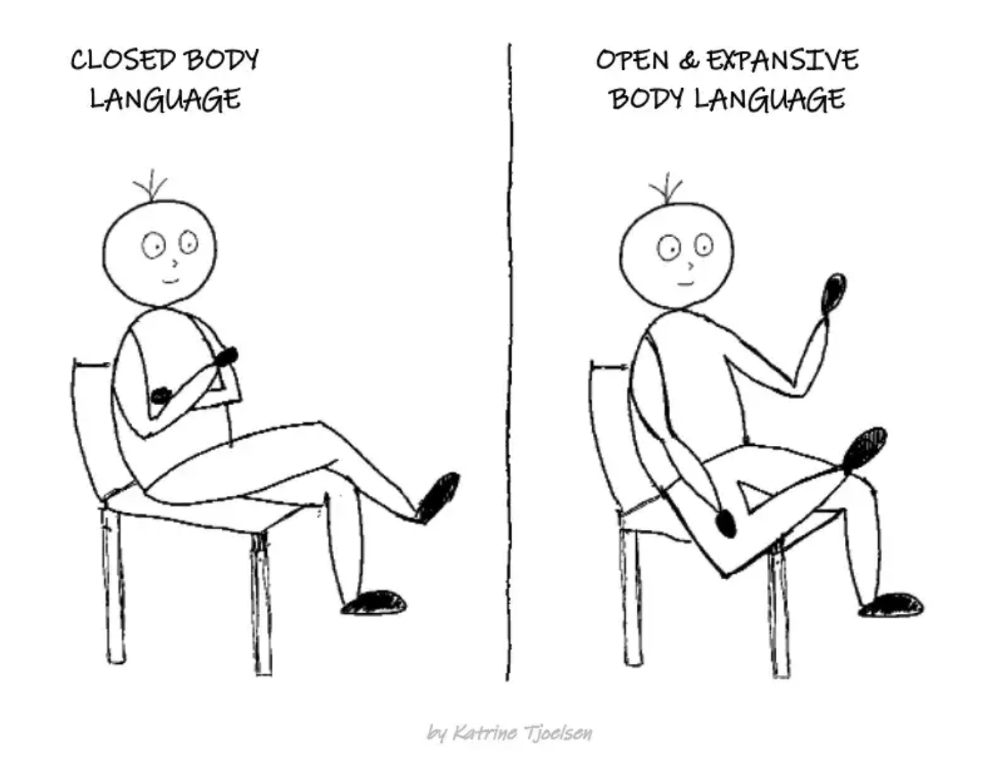
"Playing high" means having an open, relaxed body, says Stanford professor and author Deborah Gruenfield.
Crossed legs or looking small? Relax. Get bigger.

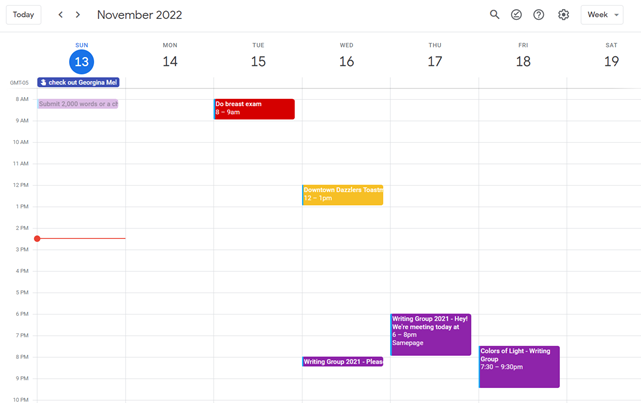
Deon Ashleigh
3 years ago
You can dominate your daily productivity with these 9 little-known Google Calendar tips.
Calendars are great unpaid employees.
After using Notion to organize my next three months' goals, my days were a mess.
I grew very chaotic afterward. I was overwhelmed, unsure of what to do, and wasting time attempting to plan the day after it had started.
Imagine if our skeletons were on the outside. Doesn’t work.
The goals were too big; I needed to break them into smaller chunks. But how?
Enters Google Calendar
RescueTime’s recommendations took me seven hours to make a daily planner. This epic narrative begins with a sheet of paper and concludes with a daily calendar that helps me focus and achieve more goals. Ain’t nobody got time for “what’s next?” all day.
Onward!
Return to the Paleolithic Era
Plan in writing.
Not on the list, but it helped me plan my day. Physical writing boosts creativity and recall.
Find My Heart
i.e. prioritize
RescueTime suggested I prioritize before planning. Personal and business goals were proposed.
My top priorities are to exercise, eat healthily, spend time in nature, and avoid stress.
Priorities include writing and publishing Medium articles, conducting more freelance editing and Medium outreach, and writing/editing sci-fi books.
These eight things will help me feel accomplished every day.
Make a baby calendar.
Create daily calendar templates.
Make family, pleasure, etc. calendars.
Google Calendar instructions:
Other calendars
Press the “+” button
Create a new calendar
Create recurring events for each day
My calendar, without the template:
Empty, so I can fill it with vital tasks.
With the template:
My daily skeleton corresponds with my priorities. I've been overwhelmed for years because I lack daily, weekly, monthly, and yearly structure.
Google Calendars helps me reach my goals and focus my energy.
Get your colored pencils ready
Time-block color-coding.
Color labeling lets me quickly see what's happening. Maybe you are too.
Google Calendar instructions:
Determine which colors correspond to each time block.
When establishing new events, select a color.
Save
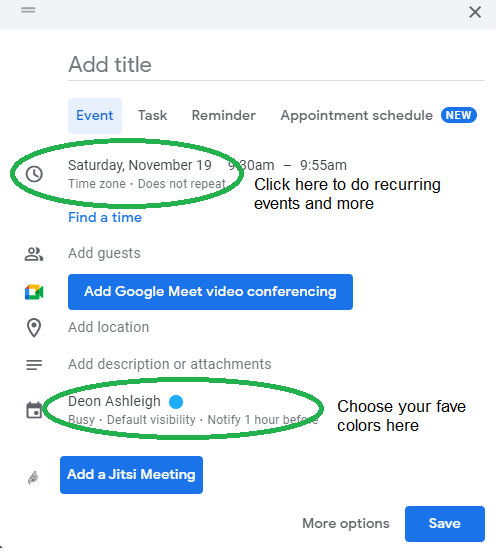
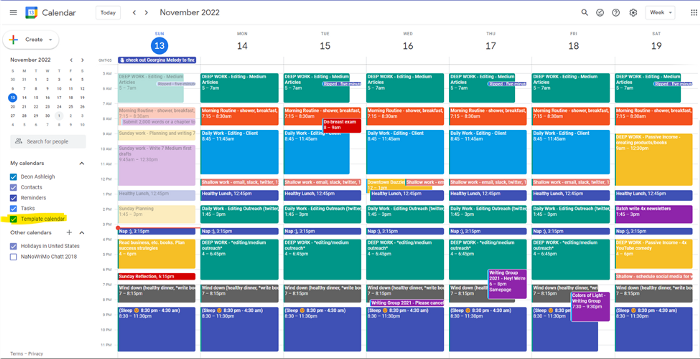
My calendar is color-coded as follows:
Yellow — passive income or other future-related activities
Red — important activities, like my monthly breast exam
Flamingo — shallow work, like emails, Twitter, etc.
Blue — all my favorite activities, like walking, watching comedy, napping, and sleeping. Oh, and eating.
Green — money-related events required for this adulting thing
Purple — writing-related stuff
Associating a time block with a color helps me stay focused. Less distractions mean faster work.
Open My Email
aka receive a daily email from Google Calendar.
Google Calendar sends a daily email feed of your calendars. I sent myself the template calendar in this email.
Google Calendar instructions:
Access settings
Select the calendar that you want to send (left side)
Go down the page to see more alerts
Under the daily agenda area, click Email.

Get in Touch With Your Red Bull Wings — Naturally
aka audit your energy levels.
My daily planner has arrows. These indicate how much energy each activity requires or how much I have.
Rightward arrow denotes medium energy.
I do my Medium and professional editing in the morning because it's energy-intensive.
Niharikaa Sodhi recommends morning Medium editing.
I’m a morning person. As long as I go to bed at a reasonable time, 5 a.m. is super wild GO-TIME. It’s like the world was just born, and I marvel at its wonderfulness.
Freelance editing lets me do what I want. An afternoon snooze will help me finish on time.
Ditch Schedule View
aka focus on the weekly view.
RescueTime advocated utilizing the weekly view of Google Calendar, so I switched.
When you launch the phone app or desktop calendar, a red line shows where you are in the day.
I'll follow the red line's instructions. My digital supervisor is easy to follow.
In the image above, it's almost 3 p.m., therefore the red line implies it's time to snooze.
I won't forget this block ;).
Reduce the Lighting
aka dim previous days.
This is another Google Calendar feature I didn't know about. Once the allotted time passes, the time block dims. This keeps me present.
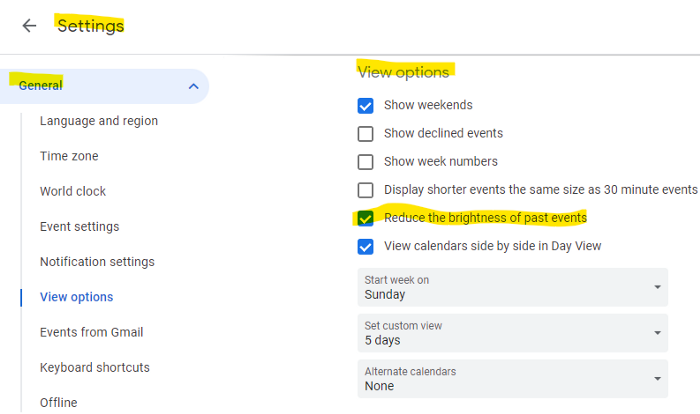
Google Calendar instructions:
Access settings
remaining general
To view choices, click.
Check Diminish the glare of the past.
Bonus
Two additional RescueTimes hacks:
Maintain a space between tasks
I left 15 minutes between each time block to transition smoothly. This relates to my goal of less stress. If I set strict start and end times, I'll be stressed.
With a buffer, I can breathe, stroll around, and start the following time block fresh.
Find a time is related to the buffer.
This option allows you conclude small meetings five minutes early and longer ones ten. Before the next meeting, relax or go wild.
Decide on a backup day.
This productivity technique is amazing.
Spend this excess day catching up on work. It helps reduce tension and clutter.
That's all I can say about Google Calendar's functionality.

Maria Stepanova
3 years ago
How Elon Musk Picks Things Up Quicker Than Anyone Else
Adopt Elon Musk's learning strategy to succeed.

Medium writers rank first and second when you Google “Elon Musk's learning approach”.
My article idea seems unoriginal. Lol
Musk is brilliant.
No doubt here.
His name connotes success and intelligence.
He knows rocket science, engineering, AI, and solar power.
Musk is a Unicorn, but his skills aren't special.
How does he manage it?
Elon Musk has two learning rules that anyone may use.
You can apply these rules and become anyone you want.
You can become a rocket scientist or a surgeon. If you want, of course.
The learning process is key.
Make sure you are creating a Tree of Knowledge according to Rule #1.
Musk told Reddit how he learns:
“It is important to view knowledge as sort of a semantic tree — make sure you understand the fundamental principles, i.e. the trunk and big branches, before you get into the leaves/details or there is nothing for them to hang onto.”
Musk understands the essential ideas and mental models of each of his business sectors.
He starts with the tree's trunk, making sure he learns the basics before going on to branches and leaves.
We often act otherwise. We memorize small details without understanding how they relate to the whole. Our minds are stuffed with useless data.
Cramming isn't learning.
Start with the basics to learn faster. Before diving into minutiae, grasp the big picture.

Rule #2: You can't connect what you can't remember.
Elon Musk transformed industries this way. As his expertise grew, he connected branches and leaves from different trees.
Musk read two books a day as a child. He didn't specialize like most people. He gained from his multidisciplinary education. It helped him stand out and develop billion-dollar firms.
He gained skills in several domains and began connecting them. World-class performances resulted.
Most of us never learn the basics and only collect knowledge. We never really comprehend information, thus it's hard to apply it.
Learn the basics initially to maximize your chances of success. Then start learning.
Learn across fields and connect them.
This method enabled Elon Musk to enter and revolutionize a century-old industry.