



More on Productivity

Mickey Mellen
2 years ago
Shifting from Obsidian to Tana?

I relocated my notes database from Roam Research to Obsidian earlier this year expecting to stay there for a long. Obsidian is a terrific tool, and I explained my move in that post.
Moving everything to Tana faster than intended. Tana? Why?
Tana is just another note-taking app, but it does it differently. Three note-taking apps existed before Tana:
simple note-taking programs like Apple Notes and Google Keep.
Roam Research and Obsidian are two graph-style applications that assisted connect your notes.
You can create effective tables and charts with data-focused tools like Notion and Airtable.
Tana is the first great software I've encountered that combines graph and data notes. Google Keep will certainly remain my rapid notes app of preference. This Shu Omi video gives a good overview:
Tana handles everything I did in Obsidian with books, people, and blog entries, plus more. I can find book quotes, log my workouts, and connect my thoughts more easily. It should make writing blog entries notes easier, so we'll see.
Tana is now invite-only, but if you're interested, visit their site and sign up. As Shu noted in the video above, the product hasn't been published yet but seems quite polished.
Whether I stay with Tana or not, I'm excited to see where these apps are going and how they can benefit us all.

Leonardo Castorina
3 years ago
How to Use Obsidian to Boost Research Productivity
Tools for managing your PhD projects, reading lists, notes, and inspiration.
As a researcher, you have to know everything. But knowledge is useless if it cannot be accessed quickly. An easy-to-use method of archiving information makes taking notes effortless and enjoyable.
As a PhD student in Artificial Intelligence, I use Obsidian (https://obsidian.md) to manage my knowledge.
The article has three parts:
- What is a note, how to organize notes, tags, folders, and links? This section is tool-agnostic, so you can use most of these ideas with any note-taking app.
- Instructions for using Obsidian, managing notes, reading lists, and useful plugins. This section demonstrates how I use Obsidian, my preferred knowledge management tool.
- Workflows: How to use Zotero to take notes from papers, manage multiple projects' notes, create MOCs with Dataview, and more. This section explains how to use Obsidian to solve common scientific problems and manage/maintain your knowledge effectively.
This list is not perfect or complete, but it is my current solution to problems I've encountered during my PhD. Please leave additional comments or contact me if you have any feedback. I'll try to update this article.
Throughout the article, I'll refer to your digital library as your "Obsidian Vault" or "Zettelkasten".
Other useful resources are listed at the end of the article.
1. Philosophy: Taking and organizing notes
Carl Sagan: “To make an apple pie from scratch, you must first create the universe.”
Before diving into Obsidian, let's establish a Personal Knowledge Management System and a Zettelkasten. You can skip to Section 2 if you already know these terms.
Niklas Luhmann, a prolific sociologist who wrote 400 papers and 70 books, inspired this section and much of Zettelkasten. Zettelkasten means “slip box” (or library in this article). His Zettlekasten had around 90000 physical notes, which can be found here.
There are now many tools available to help with this process. Obsidian's website has a good introduction section: https://publish.obsidian.md/hub/
Notes
We'll start with "What is a note?" Although it may seem trivial, the answer depends on the topic or your note-taking style. The idea is that a note is as “atomic” (i.e. You should read the note and get the idea right away.
The resolution of your notes depends on their detail. Deep Learning, for example, could be a general description of Neural Networks, with a few notes on the various architectures (eg. Recurrent Neural Networks, Convolutional Neural Networks etc..).
Limiting length and detail is a good rule of thumb. If you need more detail in a specific section of this note, break it up into smaller notes. Deep Learning now has three notes:
- Deep Learning
- Recurrent Neural Networks
- Convolutional Neural Networks
Repeat this step as needed until you achieve the desired granularity. You might want to put these notes in a “Neural Networks” folder because they are all about the same thing. But there's a better way:
#Tags and [[Links]] over /Folders/
The main issue with folders is that they are not flexible and assume that all notes in the folder belong to a single category. This makes it difficult to make connections between topics.
Deep Learning has been used to predict protein structure (AlphaFold) and classify images (ImageNet). Imagine a folder structure like this:
- /Proteins/
- Protein Folding
- /Deep Learning/
- /Proteins/
Your notes about Protein Folding and Convolutional Neural Networks will be separate, and you won't be able to find them in the same folder.
This can be solved in several ways. The most common one is to use tags rather than folders. A note can be grouped with multiple topics this way. Obsidian tags can also be nested (have subtags).
You can also link two notes together. You can build your “Knowledge Graph” in Obsidian and other note-taking apps like Obsidian.
My Knowledge Graph. Green: Biology, Red: Machine Learning, Yellow: Autoencoders, Blue: Graphs, Brown: Tags.
My Knowledge Graph and the note “Backrpropagation” and its links.
Backpropagation note and all its links
Why use Folders?
Folders help organize your vault as it grows. The main suggestion is to have few folders that "weakly" collect groups of notes or better yet, notes from different sources.
Among my Zettelkasten folders are:
My Zettelkasten's 5 folders
They usually gather data from various sources:
MOC: Map of Contents for the Zettelkasten.
Projects: Contains one note for each side-project of my PhD where I log my progress and ideas. Notes are linked to these.
Bio and ML: These two are the main content of my Zettelkasten and could theoretically be combined.
Papers: All my scientific paper notes go here. A bibliography links the notes. Zotero .bib file
Books: I make a note for each book I read, which I then split into multiple notes.
Keeping images separate from other files can help keep your main folders clean.
I will elaborate on these in the Workflow Section.
My general recommendation is to use tags and links instead of folders.
Maps of Content (MOC)
Making Tables of Contents is a good solution (MOCs).
These are notes that "signposts" your Zettelkasten library, directing you to the right type of notes. It can link to other notes based on common tags. This is usually done with a title, then your notes related to that title. As an example:
An example of a Machine Learning MOC generated with Dataview.
As shown above, my Machine Learning MOC begins with the basics. Then it's on to Variational Auto-Encoders. Not only does this save time, but it also saves scrolling through the tag search section.
So I keep MOCs at the top of my library so I can quickly find information and see my library. These MOCs are generated automatically using an Obsidian Plugin called Dataview (https://github.com/blacksmithgu/obsidian-dataview).
Ideally, MOCs could be expanded to include more information about the notes, their status, and what's left to do. In the absence of this, Dataview does a fantastic job at creating a good structure for your notes.
In the absence of this, Dataview does a fantastic job at creating a good structure for your notes.
2. Tools: Knowing Obsidian
Obsidian is my preferred tool because it is free, all notes are stored in Markdown format, and each panel can be dragged and dropped. You can get it here: https://obsidian.md/
Obsidian interface.
Obsidian is highly customizable, so here is my preferred interface:
The theme is customized from https://github.com/colineckert/obsidian-things
Alternatively, each panel can be collapsed, moved, or removed as desired. To open a panel later, click on the vertical "..." (bottom left of the note panel).
My interface is organized as follows:
How my Obsidian Interface is organized.
Folders/Search:
This is where I keep all relevant folders. I usually use the MOC note to navigate, but sometimes I use the search button to find a note.
Tags:
I use nested tags and look into each one to find specific notes to link.
cMenu:
Easy-to-use menu plugin cMenu (https://github.com/chetachiezikeuzor/cMenu-Plugin)
Global Graph:
The global graph shows all your notes (linked and unlinked). Linked notes will appear closer together. Zoom in to read each note's title. It's a bit overwhelming at first, but as your library grows, you get used to the positions and start thinking of new connections between notes.
Local Graph:
Your current note will be shown in relation to other linked notes in your library. When needed, you can quickly jump to another link and back to the current note.
Links:
Finally, an outline panel and the plugin Obsidian Power Search (https://github.com/aviral-batra/obsidian-power-search) allow me to search my vault by highlighting text.
Start using the tool and worry about panel positioning later. I encourage you to find the best use-case for your library.
Plugins
An additional benefit of using Obsidian is the large plugin library. I use several (Calendar, Citations, Dataview, Templater, Admonition):
Obsidian Calendar Plugin: https://github.com/liamcain
It organizes your notes on a calendar. This is ideal for meeting notes or keeping a journal.
Calendar addon from hans/obsidian-citation-plugin
Obsidian Citation Plugin: https://github.com/hans/
Allows you to cite papers from a.bib file. You can also customize your notes (eg. Title, Authors, Abstract etc..)
Plugin citation from hans/obsidian-citation-plugin
Obsidian Dataview: https://github.com/blacksmithgu/
A powerful plugin that allows you to query your library as a database and generate content automatically. See the MOC section for an example.
Allows you to create notes with specific templates like dates, tags, and headings.
Templater. Obsidian Admonition: https://github.com/valentine195/obsidian-admonition
Blocks allow you to organize your notes.
Plugin warning. Obsidian Admonition (valentine195)
There are many more, but this list should get you started.
3. Workflows: Cool stuff
Here are a few of my workflows for using obsidian for scientific research. This is a list of resources I've found useful for my use-cases. I'll outline and describe them briefly so you can skim them quickly.
3.1 Using Templates to Structure Notes
3.2 Free Note Syncing (Laptop, Phone, Tablet)
3.3 Zotero/Mendeley/JabRef -> Obsidian — Managing Reading Lists
3.4 Projects and Lab Books
3.5 Private Encrypted Diary
3.1 Using Templates to Structure Notes
Plugins: Templater and Dataview (optional).
To take effective notes, you must first make adding new notes as easy as possible. Templates can save you time and give your notes a consistent structure. As an example:
An example of a note using a template.
### [[YOUR MOC]]
# Note Title of your note
**Tags**::
**Links**::
The top line links to your knowledge base's Map of Content (MOC) (see previous sections). After the title, I add tags (and a link between the note and the tag) and links to related notes.
To quickly identify all notes that need to be expanded, I add the tag “#todo”. In the “TODO:” section, I list the tasks within the note.
The rest are notes on the topic.
Templater can help you create these templates. For new books, I use the following template:
### [[Books MOC]]
# Title
**Author**::
**Date::
**Tags::
**Links::
A book template example.
Using a simple query, I can hook Dataview to it.
dataview
table author as Author, date as “Date Finished”, tags as “Tags”, grade as “Grade”
from “4. Books”
SORT grade DESCENDING
using Dataview to query templates.
3.2 Free Note Syncing (Laptop, Phone, Tablet)
No plugins used.
One of my favorite features of Obsidian is the library's self-contained and portable format. Your folder contains everything (plugins included).
Ordinary folders and documents are available as well. There is also a “.obsidian” folder. This contains all your plugins and settings, so you can use it on other devices.
So you can use Google Drive, iCloud, or Dropbox for free as long as you sync your folder (note: your folder should be in your Cloud Folder).
For my iOS and macOS work, I prefer iCloud. You can also use the paid service Obsidian Sync.
3.3 Obsidian — Managing Reading Lists and Notes in Zotero/Mendeley/JabRef
Plugins: Quotes (required).
3.3 Zotero/Mendeley/JabRef -> Obsidian — Taking Notes and Managing Reading Lists of Scientific Papers
My preferred reference manager is Zotero, but this workflow should work with any reference manager that produces a .bib file. This file is exported to my cloud folder so I can access it from any platform.
My Zotero library is tagged as follows:
My reference manager's tags
For readings, I usually search for the tags “!!!” and “To-Read” and select a paper. Annotate the paper next (either on PDF using GoodNotes or on physical paper).
Then I make a paper page using a template in the Citations plugin settings:
An example of my citations template.
Create a new note, open the command list with CMD/CTRL + P, and find the Citations “Insert literature note content in the current pane” to see this lovely view.
Citation generated by the article https://doi.org/10.1101/2022.01.24.22269144
You can then convert your notes to digital. I found that transcribing helped me retain information better.
3.4 Projects and Lab Books
Plugins: Tweaker (required).
PhD students offering advice on thesis writing are common (read as regret). I started asking them what they would have done differently or earlier.
“Deep stuff Leo,” one person said. So my main issue is basic organization, losing track of my tasks and the reasons for them.
As a result, I'd go on other experiments that didn't make sense, and have to reverse engineer my logic for thesis writing. - PhD student now wise Postdoc
Time management requires planning. Keeping track of multiple projects and lab books is difficult during a PhD. How I deal with it:
- One folder for all my projects
- One file for each project
I use a template to create each project
### [[Projects MOC]]
# <% tp.file.title %>
**Tags**::
**Links**::
**URL**::
**Project Description**::## Notes:
### <% tp.file.last_modified_date(“dddd Do MMMM YYYY”) %>
#### Done:
#### TODO:
#### Notes
You can insert a template into a new note with CMD + P and looking for the Templater option.
I then keep adding new days with another template:
### <% tp.file.last_modified_date("dddd Do MMMM YYYY") %>
#### Done:
#### TODO:
#### Notes:
This way you can keep adding days to your project and update with reasonings and things you still have to do and have done. An example below:
Example of project note with timestamped notes.
3.5 Private Encrypted Diary
This is one of my favorite Obsidian uses.
Mini Diary's interface has long frustrated me. After the author archived the project, I looked for a replacement. I had two demands:
- It had to be private, and nobody had to be able to read the entries.
- Cloud syncing was required for editing on multiple devices.
Then I learned about encrypting the Obsidian folder. Then decrypt and open the folder with Obsidian. Sync the folder as usual.
Use CryptoMator (https://cryptomator.org/). Create an encrypted folder in Cryptomator for your Obsidian vault, set a password, and let it do the rest.
If you need a step-by-step video guide, here it is:
Conclusion
So, I hope this was helpful!
In the first section of the article, we discussed notes and note-taking techniques. We discussed when to use tags and links over folders and when to break up larger notes.
Then we learned about Obsidian, its interface, and some useful plugins like Citations for citing papers and Templater for creating note templates.
Finally, we discussed workflows and how to use Zotero to take notes from scientific papers, as well as managing Lab Books and Private Encrypted Diaries.
Thanks for reading and commenting :)
Read original post here

Jari Roomer
3 years ago
Three Simple Daily Practices That Will Immediately Double Your Output
Most productive people are habitual.

Early in the day, do important tasks.
In his best-selling book Eat That Frog, Brian Tracy advised starting the day with your hardest, most important activity.
Most individuals work best in the morning. Energy and willpower peak then.
Mornings are also ideal for memory, focus, and problem-solving.
Thus, the morning is ideal for your hardest chores.
It makes sense to do these things during your peak performance hours.
Additionally, your morning sets the tone for the day. According to Brian Tracy, the first hour of the workday steers the remainder.
After doing your most critical chores, you may feel accomplished, confident, and motivated for the remainder of the day, which boosts productivity.
Develop Your Essentialism
In Essentialism, Greg McKeown claims that trying to be everything to everyone leads to mediocrity and tiredness.
You'll either burn out, be spread too thin, or compromise your ideals.
Greg McKeown advises Essentialism:
Clarify what’s truly important in your life and eliminate the rest.
Eliminating non-essential duties, activities, and commitments frees up time and energy for what matters most.
According to Greg McKeown, Essentialists live by design, not default.
You'll be happier and more productive if you follow your essentials.
Follow these three steps to live more essentialist.
Prioritize Your Tasks First
What matters most clarifies what matters less. List your most significant aims and values.
The clearer your priorities, the more you can focus on them.
On Essentialism, McKeown wrote, The ultimate form of effectiveness is the ability to deliberately invest our time and energy in the few things that matter most.
#2: Set Your Priorities in Order
Prioritize your priorities, not simply know them.
“If you don’t prioritize your life, someone else will.” — Greg McKeown
Planning each day and allocating enough time for your priorities is the best method to become more purposeful.
#3: Practice saying "no"
If a request or demand conflicts with your aims or principles, you must learn to say no.
Saying no frees up space for our priorities.
Place Sleep Above All Else
Many believe they must forego sleep to be more productive. This is false.
A productive day starts with a good night's sleep.
Matthew Walker (Why We Sleep) says:
“Getting a good night’s sleep can improve cognitive performance, creativity, and overall productivity.”
Sleep helps us learn, remember, and repair.
Unfortunately, 35% of people don't receive the recommended 79 hours of sleep per night.
Sleep deprivation can cause:
increased risk of diabetes, heart disease, stroke, and obesity
Depression, stress, and anxiety risk are all on the rise.
decrease in general contentment
decline in cognitive function
To live an ideal, productive, and healthy life, you must prioritize sleep.
Follow these six sleep optimization strategies to obtain enough sleep:
Establish a nightly ritual to relax and prepare for sleep.
Avoid using screens an hour before bed because the blue light they emit disrupts the generation of melatonin, a necessary hormone for sleep.
Maintain a regular sleep schedule to control your body's biological clock (and optimizes melatonin production)
Create a peaceful, dark, and cool sleeping environment.
Limit your intake of sweets and caffeine (especially in the hours leading up to bedtime)
Regular exercise (but not right before you go to bed, because your body temperature will be too high)
Sleep is one of the best ways to boost productivity.
Sleep is crucial, says Matthew Walker. It's the key to good health and longevity.
You might also like

Sam Warain
3 years ago
Sam Altman, CEO of Open AI, foresees the next trillion-dollar AI company
“I think if I had time to do something else, I would be so excited to go after this company right now.”

Sam Altman, CEO of Open AI, recently discussed AI's present and future.
Open AI is important. They're creating the cyberpunk and sci-fi worlds.
They use the most advanced algorithms and data sets.
GPT-3...sound familiar? Open AI built most copyrighting software. Peppertype, Jasper AI, Rytr. If you've used any, you'll be shocked by the quality.
Open AI isn't only GPT-3. They created DallE-2 and Whisper (a speech recognition software released last week).
What will they do next? What's the next great chance?
Sam Altman, CEO of Open AI, recently gave a lecture about the next trillion-dollar AI opportunity.
Who is the organization behind Open AI?
Open AI first. If you know, skip it.
Open AI is one of the earliest private AI startups. Elon Musk, Greg Brockman, and Rebekah Mercer established OpenAI in December 2015.
OpenAI has helped its citizens and AI since its birth.
They have scary-good algorithms.
Their GPT-3 natural language processing program is excellent.
The algorithm's exponential growth is astounding. GPT-2 came out in November 2019. May 2020 brought GPT-3.
Massive computation and datasets improved the technique in just a year. New York Times said GPT-3 could write like a human.
Same for Dall-E. Dall-E 2 was announced in April 2022. Dall-E 2 won a Colorado art contest.
Open AI's algorithms challenge jobs we thought required human innovation.
So what does Sam Altman think?
The Present Situation and AI's Limitations
During the interview, Sam states that we are still at the tip of the iceberg.
So I think so far, we’ve been in the realm where you can do an incredible copywriting business or you can do an education service or whatever. But I don’t think we’ve yet seen the people go after the trillion dollar take on Google.
He's right that AI can't generate net new human knowledge. It can train and synthesize vast amounts of knowledge, but it simply reproduces human work.
“It’s not going to cure cancer. It’s not going to add to the sum total of human scientific knowledge.”
But the key word is yet.
And that is what I think will turn out to be wrong that most surprises the current experts in the field.
Reinforcing his point that massive innovations are yet to come.
But where?
The Next $1 Trillion AI Company
Sam predicts a bio or genomic breakthrough.
There’s been some promising work in genomics, but stuff on a bench top hasn’t really impacted it. I think that’s going to change. And I think this is one of these areas where there will be these new $100 billion to $1 trillion companies started, and those areas are rare.
Avoid human trials since they take time. Bio-materials or simulators are suitable beginning points.
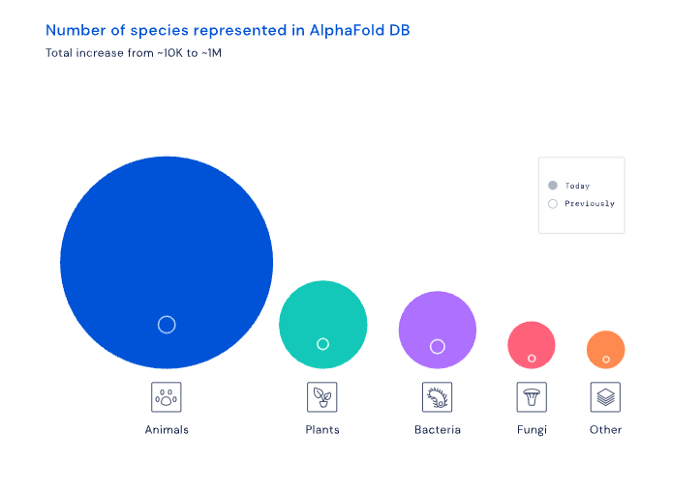
AI may have a breakthrough. DeepMind, an OpenAI competitor, has developed AlphaFold to predict protein 3D structures.
It could change how we see proteins and their function. AlphaFold could provide fresh understanding into how proteins work and diseases originate by revealing their structure. This could lead to Alzheimer's and cancer treatments. AlphaFold could speed up medication development by revealing how proteins interact with medicines.
Deep Mind offered 200 million protein structures for scientists to download (including sustainability, food insecurity, and neglected diseases).
Being in AI for 4+ years, I'm amazed at the progress. We're past the hype cycle, as evidenced by the collapse of AI startups like C3 AI, and have entered a productive phase.
We'll see innovative enterprises that could replace Google and other trillion-dollar companies.
What happens after AI adoption is scary and unpredictable. How will AGI (Artificial General Intelligence) affect us? Highly autonomous systems that exceed humans at valuable work (Open AI)
My guess is that the things that we’ll have to figure out are how we think about fairly distributing wealth, access to AGI systems, which will be the commodity of the realm, and governance, how we collectively decide what they can do, what they don’t do, things like that. And I think figuring out the answer to those questions is going to just be huge. — Sam Altman CEO

Protos
3 years ago
StableGains lost $42M in Anchor Protocol.
StableGains lost millions of dollars in customer funds in Anchor Protocol without telling its users. The Anchor Protocol offered depositors 19-20% APY before its parent ecosystem, Terra LUNA, lost tens of billions of dollars in market capitalization as LUNA fell below $0.01 and its stablecoin (UST) collapsed.
A Terra Research Forum member raised the alarm. StableGains changed its homepage and Terms and Conditions to reflect how it mitigates risk, a tacit admission that it should have done so from the start.
StableGains raised $600,000 in YCombinator's W22 batch. Moonfire, Broom Ventures, and Goodwater Capital invested $3 million more.
StableGains' 15% yield product attracted $42 million in deposits. StableGains kept most of its deposits in Anchor's UST pool earning 19-20% APY, kept one-quarter of the interest as a management fee, and then gave customers their promised 15% APY. It lost almost all customer funds when UST melted down. It changed withdrawal times, hurting customers.
- StableGains said de-pegging was unlikely. According to its website, 1 UST can be bought and sold for $1 of LUNA. LUNA became worthless, and Terra shut down its blockchain.
- It promised to diversify assets across several stablecoins to reduce the risk of one losing its $1 peg, but instead kept almost all of them in one basket.
- StableGains promised withdrawals in three business days, even if a stablecoin needed time to regain its peg. StableGains uses Coinbase for deposits and withdrawals, and customers receive the exact amount of USDC requested.
StableGains scrubs its website squeaky clean
StableGains later edited its website to say it only uses the "most trusted and tested stablecoins" and extended withdrawal times from three days to indefinite time "in extreme cases."
Previously, USDC, TerraUST (UST), and Dai were used (DAI). StableGains changed UST-related website content after the meltdown. It also removed most references to DAI.
Customers noticed a new clause in the Terms and Conditions denying StableGains liability for withdrawal losses. This new clause would have required customers to agree not to sue before withdrawing funds, avoiding a class-action lawsuit.
Customers must sign a waiver to receive a refund.
Erickson Kramer & Osborne law firm has asked StableGains to preserve all internal documents on customer accounts, marketing, and TerraUSD communications. The firm has not yet filed a lawsuit.
Thousands of StableGains customers lost an estimated $42 million.
Celsius Network customers also affected
CEL used Terra LUNA's Anchor Protocol. Celsius users lost money in the crypto market crash and UST meltdown. Many held CEL and LUNA as yielding deposits.
CEO Alex Mashinsky accused "unknown malefactors" of targeting Celsius Network without evidence. Celsius has not publicly investigated this claim as of this article's publication.
CEL fell before UST de-pegged. On June 2, 2021, it reached $8.01. May 19's close: $0.82.
When some Celsius Network users threatened to leave over token losses, Mashinsky replied, "Leave if you don't think I'm sincere and working harder than you, seven days a week."
Celsius Network withdrew $500 million from Anchor Protocol, but smaller holders had trouble.
Read original article here
Josh Chesler
3 years ago
10 Sneaker Terms Every Beginner Should Know
So you want to get into sneakers? Buying a few sneakers and figuring it out seems simple. Then you miss out on the weekend's instant-sellout releases, so you head to eBay, Twitter, or your local sneaker group to see what's available, since you're probably not ready to pay Flight Club prices just yet.
That's when you're bombarded with new nicknames, abbreviations, and general sneaker slang. It would take months to explain every word and sneaker, so here's a starter kit of ten simple terms to get you started. (Yeah, mostly Jordan. Does anyone really start with Kith or Nike SB?)
10. Colorways
Colorways are a common term in fashion, design, and other visual fields. It's just the product's color scheme. In the case of sneakers, the colorway is often as important as the actual model. Are this year's "Chicago" Air Jordan 1s more durable than last year's "Black/Gum" colorway? Because of their colorway and rarity, the Chicagos are worth roughly three pairs of the Black/Gum kicks.
Pro Tip: A colorway with a well-known nickname is almost always worth more than one without, and the same goes for collaborations.
9. Beaters
A “beater” is a well-worn, likely older model of shoe that has significant wear and tear on it. Rarely sold with the original box or extra laces, beaters rarely sell for much. Unlike most “worn” sneakers, beaters are used for rainy days and the gym. It's exactly what it sounds like, a box full of beaters, and they're a good place to start if you're looking for some cheap old kicks.
Pro Tip: Know which shoes clean up nicely. The shape of lower top sneakers with wider profiles, like SB Dunk Lows and Air Jordan 3s, tends to hold better over time than their higher and narrower cousins.
8. Retro
In the world of Jordan Brand, a “Retro” release is simply a release (or re-release) of a colorway after the shoe model's initial release. For example, the original Air Jordan 7 was released in 1992, but the Bordeaux colorway was re-released in 2011 and recently (2015). An Air Jordan model is released every year, and while half of them are unpopular and unlikely to be Retroed soon, any of them could be re-released whenever Nike and Jordan felt like it.
Pro Tip: Now that the Air Jordan line has been around for so long, the model that tends to be heavily retroed in a year is whichever shoe came out 23 (Michael Jordan’s number during the prime of his career) years ago. The Air Jordan 6 (1991) got new colorways last year, the Air Jordan 7 this year, and more Air Jordan 8s will be released later this year and early next year (1993).
7. PP/Inv
In spite of the fact that eBay takes roughly 10% of the final price, many sneaker buyers and sellers prefer to work directly with PayPal. Selling sneakers for $100 via PayPal invoice or $100 via PayPal friends/family is common on social media. Because no one wants their eBay account suspended for promoting PayPal deals, many eBay sellers will simply state “Message me for a better price.”
Pro Tip: PayPal invoices protect buyers well, but gifting or using Google Wallet does not. Unless you're certain the seller is legitimate, only use invoiced goods/services payments.
6. Yeezy
Kanye West and his sneakers are known as Yeezys. The rapper's first two Yeezys were made by Nike before switching to Adidas. Everything Yeezy-related will be significantly more expensive (and therefore have significantly more fakes made). Not only is the Nike Air Yeezy 2 “Red October” one of the most sought-after sneakers, but the Yeezy influence can be seen everywhere.
Pro Tip: If you're going to buy Yeezys, make sure you buy them from a reputable retailer or reseller. With so many fakes out there, it's not worth spending a grand on something you're not 100% sure is real.
5. GR/Limited
Regardless of how visually repulsive, uncomfortable, and/or impractical a sneaker is, if it’s rare enough, people will still want it. GR stands for General Release, which means they're usually available at retail. Reselling a “Limited Edition” release is costly. Supply and demand, but in this case, the limited supply drives up demand. If you want to get some of the colorways made for rappers, NBA players (Player Exclusive or PE models), and other celebrities, be prepared to pay a premium.
Pro Tip: Limited edition sneakers, like the annual Doernbecher Freestyle sneakers Nike creates with kids from Portland's Doernbecher Children's Hospital, will always be more expensive and limited. Or, you can use automated sneaker-buying software.
4. Grails
A “grail” is a pair of sneakers that someone desires above all others. To obtain their personal grails, people are willing to pay significantly more than the retail price. There doesn't have to be any rhyme or reason why someone chose a specific pair as their grails.
Pro Tip: For those who don't have them, the OG "Bred" or "Royal" Air Jordan 1s, the "Concord" Air Jordan 11s, etc., are all grails.
3. Bred
Anything released in “Bred” (black and red) will sell out quickly. Most resale Air Jordans (and other sneakers) come in the Bred colorway, which is a fan favorite. Bred is a good choice for a first colorway, especially on a solid sneaker silhouette.
Pro Tip: Apart from satisfying the world's hypebeasts, Bred sneakers will probably match a lot of your closet.
2. DS
DS = Deadstock = New. That's it. If something has been worn or tried on, it is no longer DS. Very Near Deadstock (VNDS) Pass As Deadstock It's a cute way of saying your sneakers have been worn but are still in good shape. In the sneaker world, “worn” means they are no longer new, but not too old or beat up.
Pro Tip: Ask for photos of any marks or defects to see what you’re getting before you buy used shoes, also find out if they come with the original box and extra laces, because that can be a sign that they’re in better shape.
1. Fake/Unauthorized
The words “Unauthorized,” “Replica,” “B-grades,” and “Super Perfect” all mean the shoes are fake. It means they aren't made by the actual company, no matter how close or how good the quality. If that's what you want, go ahead and get them. Do not wear them if you do not want the rest of the sneaker world to mock them.
Pro Tip: If you’re not sure if shoes are real or not, do a “Legit Check” on Twitter or Facebook. You'll get dozens of responses in no time.