


More on Entrepreneurship/Creators

Owolabi Judah
3 years ago
How much did YouTube pay for 10 million views?
Ali's $1,054,053.74 YouTube Adsense haul.

YouTuber, entrepreneur, and former doctor Ali Abdaal. He began filming productivity and financial videos in 2017. Ali Abdaal has 3 million YouTube subscribers and has crossed $1 million in AdSense revenue. Crazy, no?
Ali will share the revenue of his top 5 youtube videos, things he's learned that you can apply to your side hustle, and how many views it takes to make a livelihood off youtube.
First, "The Long Game."
All good things take time to bear fruit. Compounding improves everything. Long-term work yields better returns. Ali made his first dollar after nine months and 85 videos.
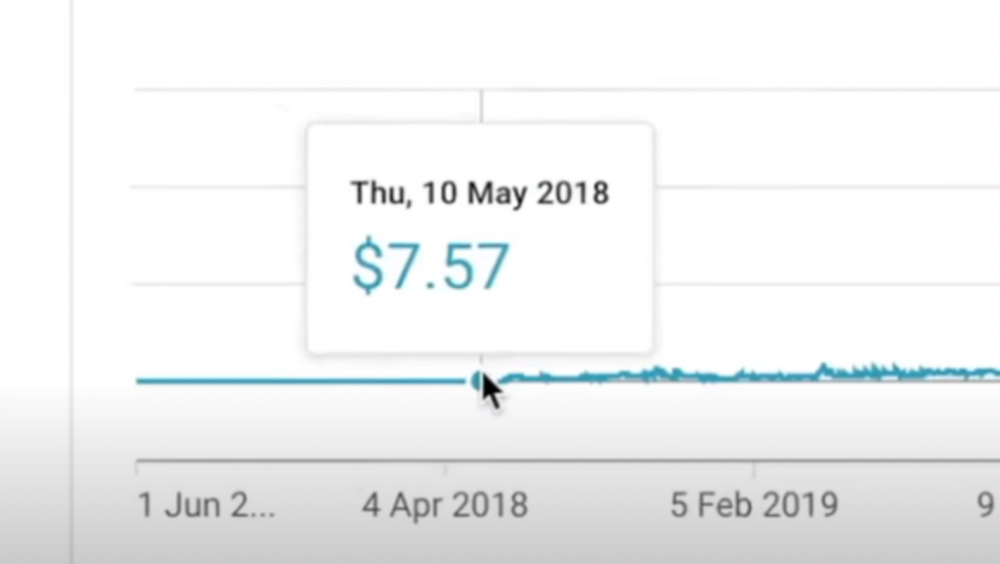
Second, "One piece of content can transform your life, but you never know which one."
Had he abandoned YouTube at 84 videos without making any money, he wouldn't have filmed the 85th video that altered everything.
Third Lesson: Your Industry Choice Can Multiply.
The industry or niche you target as a business owner or side hustler can have a major impact on how much money you make.
Here are the top 5 videos.
1) 9.8m views: $191,258.16 for 9 passive income ideas
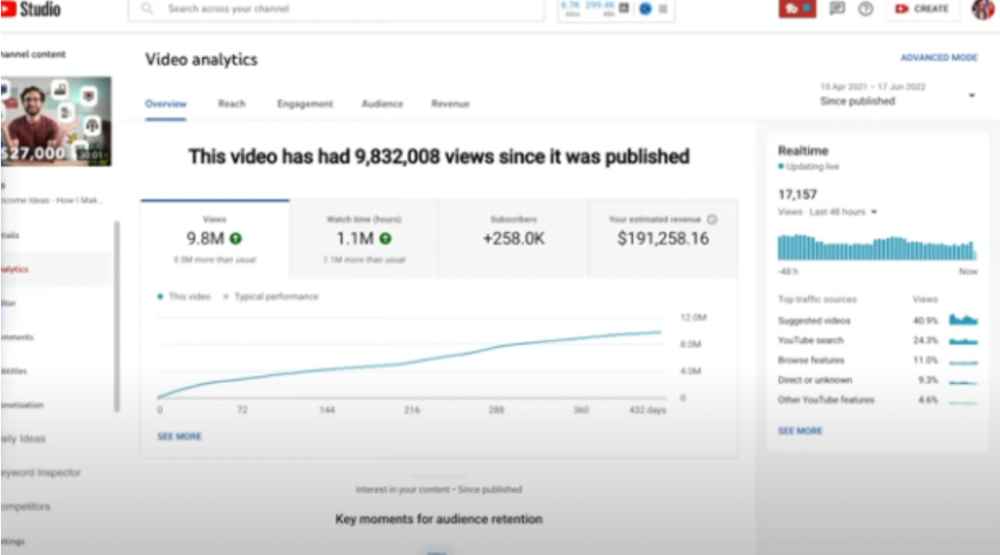
Ali made 2 points.
We should consider YouTube videos digital assets. They're investments, which make us money. His investments are yielding passive income.
Investing extra time and effort in your films can pay off.
2) How to Invest for Beginners — 5.2m Views: $87,200.08.
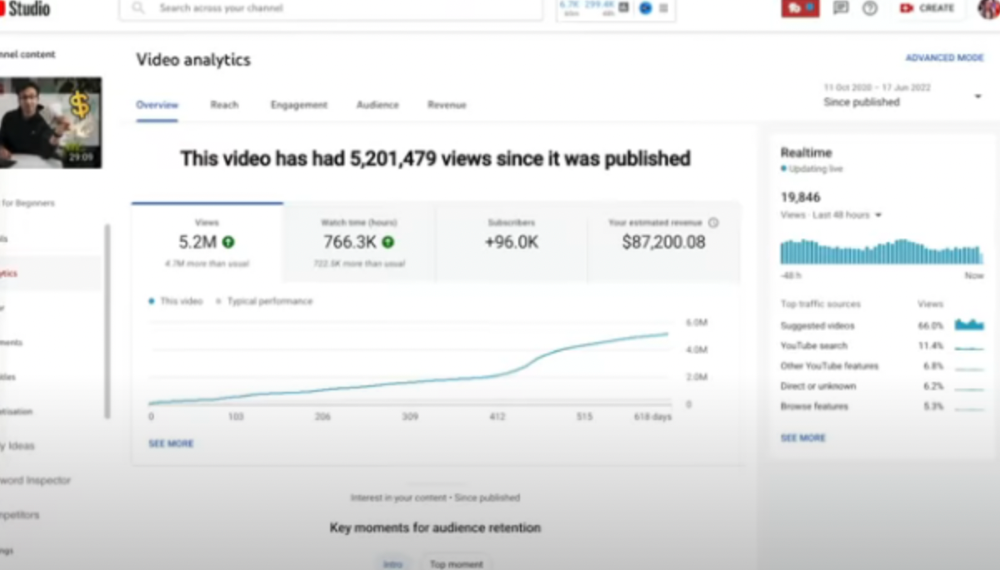
This video did poorly in the first several weeks after it was published; it was his tenth poorest performer. Don't worry about things you can't control. This applies to life, not just YouTube videos.
He stated we constantly have anxieties, fears, and concerns about things outside our control, but if we can find that line, life is easier and more pleasurable.
3) How to Build a Website in 2022— 866.3k views: $42,132.72.
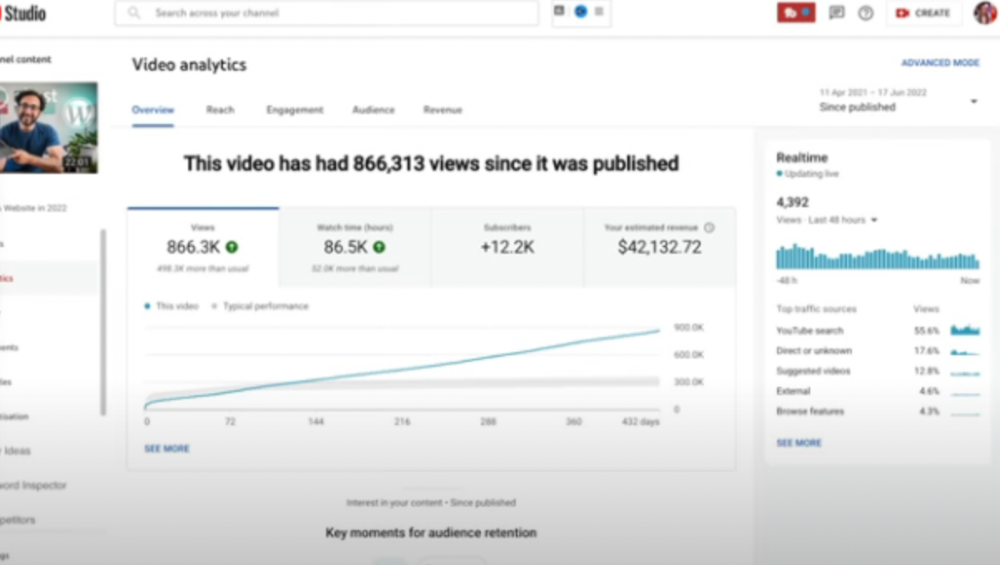
The RPM was $48.86 per thousand views, making it his highest-earning video. Squarespace, Wix, and other website builders are trying to put ads on it and competing against one other, so ad rates go up.
Because it was beyond his niche, Ali almost didn't make the video. He made the video because he wanted to help at least one person.
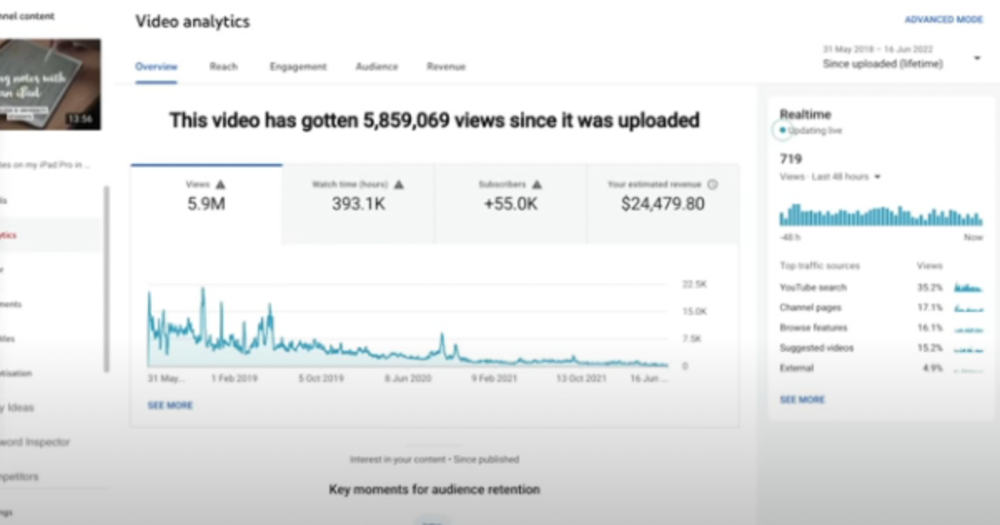
4) How I take notes on my iPad in medical school — 5.9m views: $24,479.80

85th video. It's the video that affected Ali's YouTube channel and his life the most. The video's success wasn't certain.
5) How I Type Fast 156 Words Per Minute — 8.2M views: $25,143.17
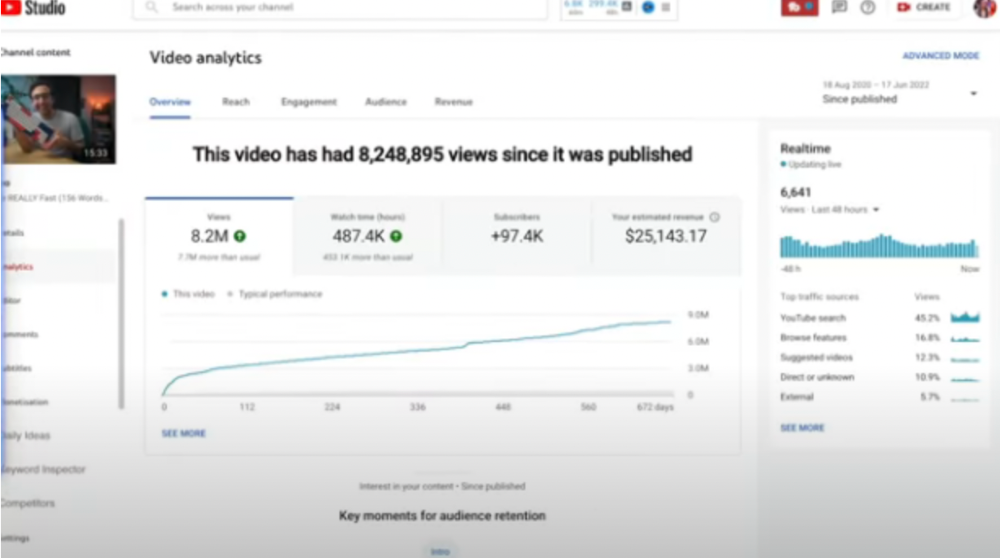
Ali didn't know this video would perform well; he made it because he can type fast and has been practicing for 10 years. So he made a video with his best advice.
How many views to different wealth levels?
It depends on geography, niche, and other monetization sources. To keep things simple, he would solely utilize AdSense.
How many views to generate money?

To generate money on Youtube, you need 1,000 subscribers and 4,000 hours of view time. How much work do you need to make pocket money?

Ali's first 1,000 subscribers took 52 videos and 6 months. The typical channel with 1,000 subscribers contains 152 videos, according to Tubebuddy. It's time-consuming.
After monetizing, you'll need 15,000 views/month to make $5-$10/day.
How many views to go part-time?

Say you make $35,000/year at your day job. If you work 5 days/week, you make $7,000/year each day. If you want to drop down from 5 days to 4 days/week, you need to make an extra $7,000/year from YouTube, or $600/month.
What's the quit-your-job budget?

Silicon Valley Girl is in a highly successful niche targeting tech-focused folks in the west. When her channel had 500k views/month, she made roughly $3,000/month or $47,000/year, enough to quit your work.
Marina has another 1.5m subscriber channel in Russia, which has a lower rpm because fewer corporations advertise there than in the west. 2.3 million views/month is $4,000/month or $50,000/year, enough to quit your employment.
Marina is an intriguing example because she has three YouTube channels with the same skills, but one is 16x more profitable due to the niche she chose.
In Ali's case, he made 100+ videos when his channel was producing enough money to quit his job, roughly $4,000/month.
How many views make you rich?

Depending on how you define rich. Ali felt prosperous with over $100,000/year and 3–5m views/month.
Conclusion
YouTubers and artists don't treat their work like a company, which is a mistake. Businesses have been attempting to figure this out for decades, if not centuries.
We can learn from the business world how to monetize YouTube, Instagram, and Tiktok and make them into sustainable enterprises where we can hire people and delegate tasks.
Bonus
Watch Ali's video explaining all this:
This post is a summary. Read the full article here

Jenn Leach
3 years ago
In November, I made an effort to pitch 10 brands per day. Here's what I discovered.

I pitched 10 brands per workday for a total of 200.
How did I do?
It was difficult.
I've never pitched so much.
What did this challenge teach me?
the superiority of quality over quantity
When you need help, outsource
Don't disregard burnout in order to complete a challenge because it exists.
First, pitching brands for brand deals requires quality. Find firms that align with your brand to expose to your audience.
If you associate with any company, you'll lose audience loyalty. I didn't lose sight of that, but I couldn't resist finishing the task.
Outsourcing.
Delegating work to teammates is effective.
I wish I'd done it.
Three people can pitch 200 companies a month significantly faster than one.
One person does research, one to two do outreach, and one to two do follow-up and negotiating.
Simple.
In 2022, I'll outsource everything.
Burnout.
I felt this, so I slowed down at the end of the month.
Thanksgiving week in November was slow.
I was buying and decorating for Christmas. First time putting up outdoor holiday lights was fun.
Much was happening.
I'm not perfect.
I'm being honest.
The Outcomes
Less than 50 brands pitched.
Result: A deal with 3 brands.
I hoped for 4 brands with reaching out to 200 companies, so three with under 50 is wonderful.
That’s a 6% conversion rate!
Whoo-hoo!
I needed 2%.
Here's a screenshot from one of the deals I booked.
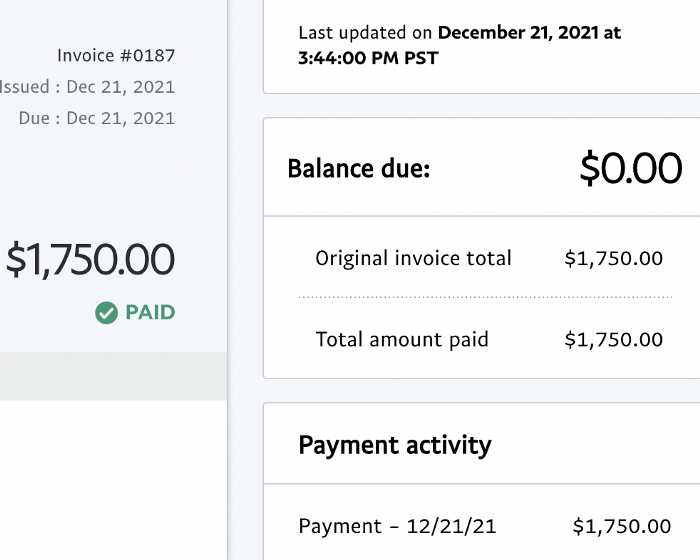
These companies fit my company well. Each campaign is different, but I've booked $2,450 in brand work with a couple of pending transactions for December and January.
$2,450 in brand work booked!
How did I do? You tell me.
Is this something you’d try yourself?

Aaron Dinin, PhD
3 years ago
I'll Never Forget the Day a Venture Capitalist Made Me Feel Like a Dunce
Are you an idiot at fundraising?

Humans undervalue what they don't grasp. Consider NASCAR. How is that a sport? ask uneducated observers. Circular traffic. Driving near a car's physical limits is different from daily driving. When driving at 200 mph, seemingly simple things like changing gas weight or asphalt temperature might be life-or-death.
Venture investors do something similar in entrepreneurship. Most entrepreneurs don't realize how complex venture finance is.
In my early startup days, I didn't comprehend venture capital's intricacy. I thought VCs were rich folks looking for the next Mark Zuckerberg. I was meant to be a sleek, enthusiastic young entrepreneur who could razzle-dazzle investors.
Finally, one of the VCs I was trying to woo set me straight. He insulted me.
How I learned that I was approaching the wrong investor
I was constructing a consumer-facing, pre-revenue marketplace firm. I looked for investors in my old university's alumni database. My city had one. After some research, I learned he was a partner at a growth-stage, energy-focused VC company with billions under management.
Billions? I thought. Surely he can write a million-dollar cheque. He'd hardly notice.
I emailed the VC about our shared alumni status, explaining that I was building a startup in the area and wanted advice. When he agreed to meet the next week, I prepared my pitch deck.
First error.
The meeting seemed like a funding request. Imagine the awkwardness.
His assistant walked me to the firm's conference room and told me her boss was running late. While waiting, I prepared my pitch. I connected my computer to the projector, queued up my PowerPoint slides, and waited for the VC.
He didn't say hello or apologize when he entered a few minutes later. What are you doing?
Hi! I said, Confused but confident. Dinin Aaron. My startup's pitch.
Who? Suspicious, he replied. Your email says otherwise. You wanted help.
I said, "Isn't that a euphemism for contacting investors?" Fundraising I figured I should pitch you.
As he sat down, he smiled and said, "Put away your computer." You need to study venture capital.
Recognizing the business aspects of venture capital
The VC taught me venture capital in an hour. Young entrepreneur me needed this lesson. I assume you need it, so I'm sharing it.
Most people view venture money from an entrepreneur's perspective, he said. They envision a world where venture capital serves entrepreneurs and startups.
As my VC indicated, VCs perceive their work differently. Venture investors don't serve entrepreneurs. Instead, they run businesses. Their product doesn't look like most products. Instead, the VCs you're proposing have recognized an undervalued market segment. By investing in undervalued companies, they hope to profit. It's their investment thesis.
Your company doesn't fit my investment thesis, the venture capitalist told me. Your pitch won't beat my investing theory. I invest in multimillion-dollar clean energy companies. Asking me to invest in you is like ordering a breakfast burrito at a fancy steakhouse. They could, but why? They don't do that.
Yeah, I’m not a fine steak yet, I laughed, feeling like a fool for pitching a growth-stage VC used to looking at energy businesses with millions in revenues on my pre-revenue, consumer startup.
He stressed that it's not necessary. There are investors targeting your company. Not me. Find investors and pitch them.
Remember this when fundraising. Your investors aren't philanthropists who want to help entrepreneurs realize their company goals. Venture capital is a sophisticated investment strategy, and VC firm managers are industry experts. They're looking for companies that meet their investment criteria. As a young entrepreneur, I didn't grasp this, which is why I struggled to raise money. In retrospect, I probably seemed like an idiot. Hopefully, you won't after reading this.
You might also like

Sofien Kaabar, CFA
3 years ago
How to Make a Trading Heatmap
Python Heatmap Technical Indicator

Heatmaps provide an instant overview. They can be used with correlations or to predict reactions or confirm the trend in trading. This article covers RSI heatmap creation.
The Market System
Market regime:
Bullish trend: The market tends to make higher highs, which indicates that the overall trend is upward.
Sideways: The market tends to fluctuate while staying within predetermined zones.
Bearish trend: The market has the propensity to make lower lows, indicating that the overall trend is downward.
Most tools detect the trend, but we cannot predict the next state. The best way to solve this problem is to assume the current state will continue and trade any reactions, preferably in the trend.
If the EURUSD is above its moving average and making higher highs, a trend-following strategy would be to wait for dips before buying and assuming the bullish trend will continue.
Indicator of Relative Strength
J. Welles Wilder Jr. introduced the RSI, a popular and versatile technical indicator. Used as a contrarian indicator to exploit extreme reactions. Calculating the default RSI usually involves these steps:
Determine the difference between the closing prices from the prior ones.
Distinguish between the positive and negative net changes.
Create a smoothed moving average for both the absolute values of the positive net changes and the negative net changes.
Take the difference between the smoothed positive and negative changes. The Relative Strength RS will be the name we use to describe this calculation.
To obtain the RSI, use the normalization formula shown below for each time step.
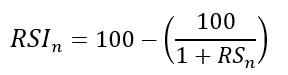
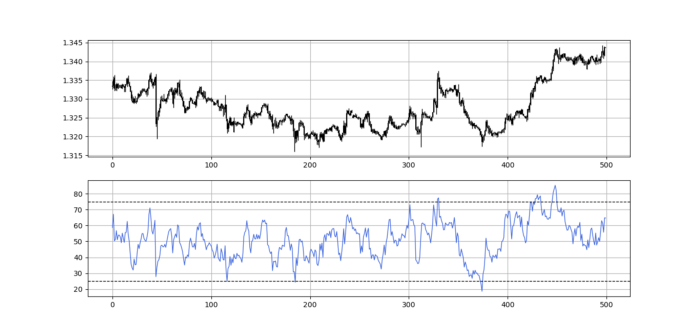
The 13-period RSI and black GBPUSD hourly values are shown above. RSI bounces near 25 and pauses around 75. Python requires a four-column OHLC array for RSI coding.
import numpy as np
def add_column(data, times):
for i in range(1, times + 1):
new = np.zeros((len(data), 1), dtype = float)
data = np.append(data, new, axis = 1)
return data
def delete_column(data, index, times):
for i in range(1, times + 1):
data = np.delete(data, index, axis = 1)
return data
def delete_row(data, number):
data = data[number:, ]
return data
def ma(data, lookback, close, position):
data = add_column(data, 1)
for i in range(len(data)):
try:
data[i, position] = (data[i - lookback + 1:i + 1, close].mean())
except IndexError:
pass
data = delete_row(data, lookback)
return data
def smoothed_ma(data, alpha, lookback, close, position):
lookback = (2 * lookback) - 1
alpha = alpha / (lookback + 1.0)
beta = 1 - alpha
data = ma(data, lookback, close, position)
data[lookback + 1, position] = (data[lookback + 1, close] * alpha) + (data[lookback, position] * beta)
for i in range(lookback + 2, len(data)):
try:
data[i, position] = (data[i, close] * alpha) + (data[i - 1, position] * beta)
except IndexError:
pass
return data
def rsi(data, lookback, close, position):
data = add_column(data, 5)
for i in range(len(data)):
data[i, position] = data[i, close] - data[i - 1, close]
for i in range(len(data)):
if data[i, position] > 0:
data[i, position + 1] = data[i, position]
elif data[i, position] < 0:
data[i, position + 2] = abs(data[i, position])
data = smoothed_ma(data, 2, lookback, position + 1, position + 3)
data = smoothed_ma(data, 2, lookback, position + 2, position + 4)
data[:, position + 5] = data[:, position + 3] / data[:, position + 4]
data[:, position + 6] = (100 - (100 / (1 + data[:, position + 5])))
data = delete_column(data, position, 6)
data = delete_row(data, lookback)
return dataMake sure to focus on the concepts and not the code. You can find the codes of most of my strategies in my books. The most important thing is to comprehend the techniques and strategies.
My weekly market sentiment report uses complex and simple models to understand the current positioning and predict the future direction of several major markets. Check out the report here:
Using the Heatmap to Find the Trend
RSI trend detection is easy but useless. Bullish and bearish regimes are in effect when the RSI is above or below 50, respectively. Tracing a vertical colored line creates the conditions below. How:
When the RSI is higher than 50, a green vertical line is drawn.
When the RSI is lower than 50, a red vertical line is drawn.
Zooming out yields a basic heatmap, as shown below.
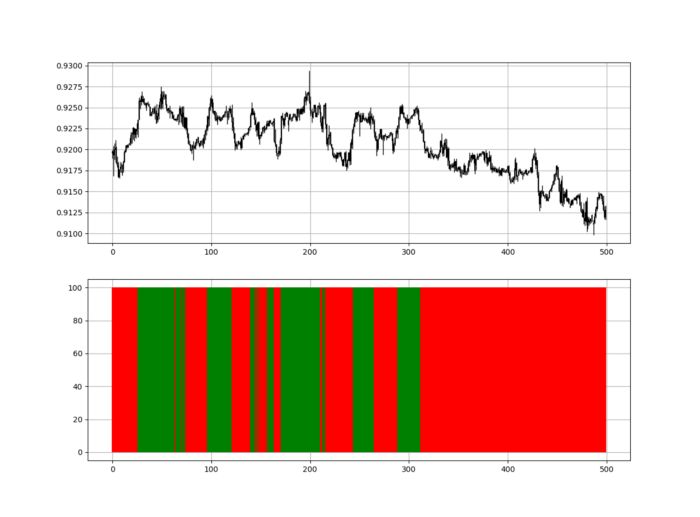
Plot code:
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
if sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)
Call RSI on your OHLC array's fifth column. 4. Adjusting lookback parameters reduces lag and false signals. Other indicators and conditions are possible.
Another suggestion is to develop an RSI Heatmap for Extreme Conditions.
Contrarian indicator RSI. The following rules apply:
Whenever the RSI is approaching the upper values, the color approaches red.
The color tends toward green whenever the RSI is getting close to the lower values.
Zooming out yields a basic heatmap, as shown below.
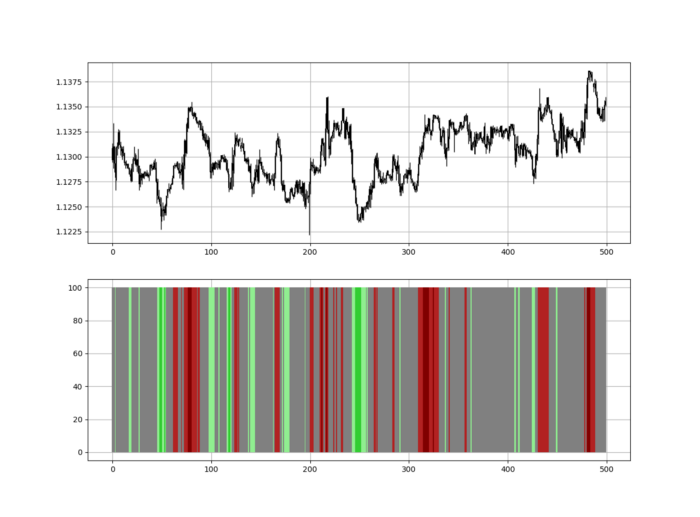
Plot code:
import matplotlib.pyplot as plt
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
if sample[i, second_panel] > 80 and sample[i, second_panel] < 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'darkred', linewidth = 1.5)
if sample[i, second_panel] > 70 and sample[i, second_panel] < 80:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'maroon', linewidth = 1.5)
if sample[i, second_panel] > 60 and sample[i, second_panel] < 70:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'firebrick', linewidth = 1.5)
if sample[i, second_panel] > 50 and sample[i, second_panel] < 60:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 40 and sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 30 and sample[i, second_panel] < 40:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'lightgreen', linewidth = 1.5)
if sample[i, second_panel] > 20 and sample[i, second_panel] < 30:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'limegreen', linewidth = 1.5)
if sample[i, second_panel] > 10 and sample[i, second_panel] < 20:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'seagreen', linewidth = 1.5)
if sample[i, second_panel] > 0 and sample[i, second_panel] < 10:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)
Dark green and red areas indicate imminent bullish and bearish reactions, respectively. RSI around 50 is grey.
Summary
To conclude, my goal is to contribute to objective technical analysis, which promotes more transparent methods and strategies that must be back-tested before implementation.
Technical analysis will lose its reputation as subjective and unscientific.
When you find a trading strategy or technique, follow these steps:
Put emotions aside and adopt a critical mindset.
Test it in the past under conditions and simulations taken from real life.
Try optimizing it and performing a forward test if you find any potential.
Transaction costs and any slippage simulation should always be included in your tests.
Risk management and position sizing should always be considered in your tests.
After checking the above, monitor the strategy because market dynamics may change and make it unprofitable.

Caspar Mahoney
3 years ago
Changing Your Mindset From a Project to a Product
Product game mindsets? How do these vary from Project mindset?
1950s spawned the Iron Triangle. Project people everywhere know and live by it. In stakeholder meetings, it is used to stretch the timeframe, request additional money, or reduce scope.
Quality was added to this triangle as things matured.
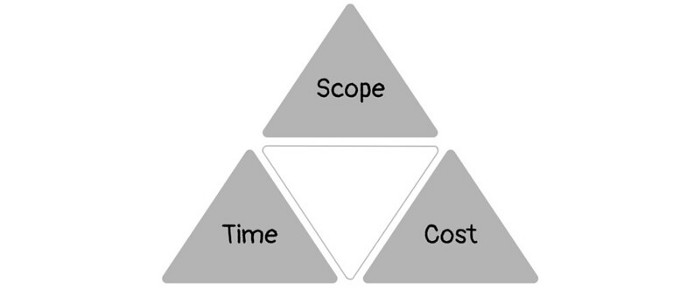
Quality was intended to be transformative, but none of these principles addressed why we conduct projects.
Value and benefits are key.
Product value is quantified by ROI, revenue, profit, savings, or other metrics. For me, every project or product delivery is about value.
Most project managers, especially those schooled 5-10 years or more ago (thousands working in huge corporations worldwide), understand the world in terms of the iron triangle. What does that imply? They worry about:
a) enough time to get the thing done.
b) have enough resources (budget) to get the thing done.
c) have enough scope to fit within (a) and (b) >> note, they never have too little scope, not that I have ever seen! although, theoretically, this could happen.
Boom—iron triangle.
To make the triangle function, project managers will utilize formal governance (Steering) to move those things. Increase money, scope, or both if time is short. Lacking funds? Increase time, scope, or both.
In current product development, shifting each item considerably may not yield value/benefit.
Even terrible. This approach will fail because it deprioritizes Value/Benefit by focusing the major stakeholders (Steering participants) and delivery team(s) on Time, Scope, and Budget restrictions.
Pre-agile, this problem was terrible. IT projects failed wildly. History is here.
Value, or benefit, is central to the product method. Product managers spend most of their time planning value-delivery paths.
Product people consider risk, schedules, scope, and budget, but value comes first. Let me illustrate.
Imagine managing internal products in an enterprise. Your core customer team needs a rapid text record of a chat to fix a problem. The consumer wants a feature/features added to a product you're producing because they think it's the greatest spot.
Project-minded, I may say;
Ok, I have budget as this is an existing project, due to run for a year. This is a new requirement to add to the features we’re already building. I think I can keep the deadline, and include this scope, as it sounds related to the feature set we’re building to give the desired result”.
This attitude repeats Scope, Time, and Budget.
Since it meets those standards, a project manager will likely approve it. If they have a backlog, they may add it and start specking it out assuming it will be built.
Instead, think like a product;
What problem does this feature idea solve? Is that problem relevant to the product I am building? Can that problem be solved quicker/better via another route ? Is it the most valuable problem to solve now? Is the problem space aligned to our current or future strategy? or do I need to alter/update the strategy?
A product mindset allows you to focus on timing, resource/cost, feasibility, feature detail, and so on after answering the aforementioned questions.
The above oversimplifies because
Leadership in discovery

Project managers are facilitators of ideas. This is as far as they normally go in the ‘idea’ space.
Business Requirements collection in classic project delivery requires extensive upfront documentation.
Agile project delivery analyzes requirements iteratively.
However, the project manager is a facilitator/planner first and foremost, therefore topic knowledge is not expected.
I mean business domain, not technical domain (to confuse matters, it is true that in some instances, it can be both technical and business domains that are important for a single individual to master).
Product managers are domain experts. They will become one if they are training/new.
They lead discovery.
Product Manager-led discovery is much more than requirements gathering.
Requirements gathering involves a Business Analyst interviewing people and documenting their requests.
The project manager calculates what fits and what doesn't using their Iron Triangle (presumably in their head) and reports back to Steering.
If this requirements-gathering exercise failed to identify requirements, what would a project manager do? or bewildered by project requirements and scope?
They would tell Steering they need a Business SME or Business Lead assigning or more of their time.
Product discovery requires the Product Manager's subject knowledge and a new mindset.
How should a Product Manager handle confusing requirements?
Product Managers handle these challenges with their talents and tools. They use their own knowledge to fill in ambiguity, but they have the discipline to validate those assumptions.
To define the problem, they may perform qualitative or quantitative primary research.
They might discuss with UX and Engineering on a whiteboard and test assumptions or hypotheses.
Do Product Managers escalate confusing requirements to Steering/Senior leaders? They would fix that themselves.
Product managers raise unclear strategy and outcomes to senior stakeholders. Open talks, soft skills, and data help them do this. They rarely raise requirements since they have their own means of handling them without top stakeholder participation.
Discovery is greenfield, exploratory, research-based, and needs higher-order stakeholder management, user research, and UX expertise.
Product Managers also aid discovery. They lead discovery. They will not leave customer/user engagement to a Business Analyst. Administratively, a business analyst could aid. In fact, many product organizations discourage business analysts (rely on PM, UX, and engineer involvement with end-users instead).
The Product Manager must drive user interaction, research, ideation, and problem analysis, therefore a Product professional must be skilled and confident.
Creating vs. receiving and having an entrepreneurial attitude

Product novices and project managers focus on details rather than the big picture. Project managers prefer spreadsheets to strategy whiteboards and vision statements.
These folks ask their manager or senior stakeholders, "What should we do?"
They then elaborate (in Jira, in XLS, in Confluence or whatever).
They want that plan populated fast because it reduces uncertainty about what's going on and who's supposed to do what.
Skilled Product Managers don't only ask folks Should we?
They're suggesting this, or worse, Senior stakeholders, here are some options. After asking and researching, they determine what value this product adds, what problems it solves, and what behavior it changes.
Therefore, to move into Product, you need to broaden your view and have courage in your ability to discover ideas, find insightful pieces of information, and collate them to form a valuable plan of action. You are constantly defining RoI and building Business Cases, so much so that you no longer create documents called Business Cases, it is simply ingrained in your work through metrics, intelligence, and insights.
Product Management is not a free lunch.
Plateless.
Plates and food must be prepared.
In conclusion, Product Managers must make at least three mentality shifts:
You put value first in all things. Time, money, and scope are not as important as knowing what is valuable.
You have faith in the field and have the ability to direct the search. YYou facilitate, but you don’t just facilitate. You wouldn't want to limit your domain expertise in that manner.
You develop concepts, strategies, and vision. You are not a waiter or an inbox where other people can post suggestions; you don't merely ask folks for opinion and record it. However, you excel at giving things that aren't clearly spoken or written down physical form.

Faisal Khan
2 years ago
4 typical methods of crypto market manipulation

Market fraud
Due to its decentralized and fragmented character, the crypto market has integrity difficulties.
Cryptocurrencies are an immature sector, therefore market manipulation becomes a bigger issue. Many research have attempted to uncover these abuses. CryptoCompare's newest one highlights some of the industry's most typical scams.
Why are these concerns so common in the crypto market? First, even the largest centralized exchanges remain unregulated due to industry immaturity. A low-liquidity market segment makes an attack more harmful. Finally, market surveillance solutions not implemented reduce transparency.
In CryptoCompare's latest exchange benchmark, 62.4% of assessed exchanges had a market surveillance system, although only 18.1% utilised an external solution. To address market integrity, this measure must improve dramatically. Before discussing the report's malpractices, note that this is not a full list of attacks and hacks.
Clean Trading
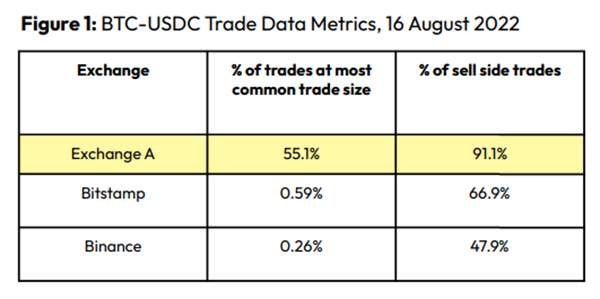
An investor buys and sells concurrently to increase the asset's price. Centralized and decentralized exchanges show this misconduct. 23 exchanges have a volume-volatility correlation < 0.1 during the previous 100 days, according to CryptoCompares. In August 2022, Exchange A reported $2.5 trillion in artificial and/or erroneous volume, up from $33.8 billion the month before.
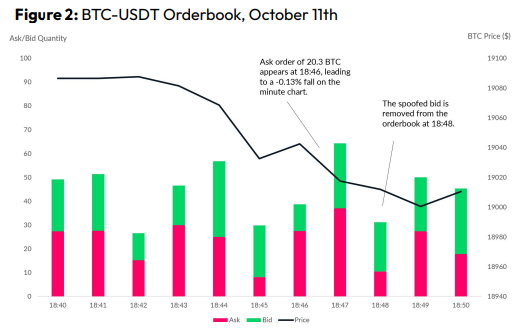
Spoofing
Criminals create and cancel fake orders before they can be filled. Since manipulators can hide in larger trading volumes, larger exchanges have more spoofing. A trader placed a 20.8 BTC ask order at $19,036 when BTC was trading at $19,043. BTC declined 0.13% to $19,018 in a minute. At 18:48, the trader canceled the ask order without filling it.
Front-Running
Most cryptocurrency front-running involves inside trading. Traditional stock markets forbid this. Since most digital asset information is public, this is harder. Retailers could utilize bots to front-run.
CryptoCompare found digital wallets of people who traded like insiders on exchange listings. The figure below shows excess cumulative anomalous returns (CAR) before a coin listing on an exchange.
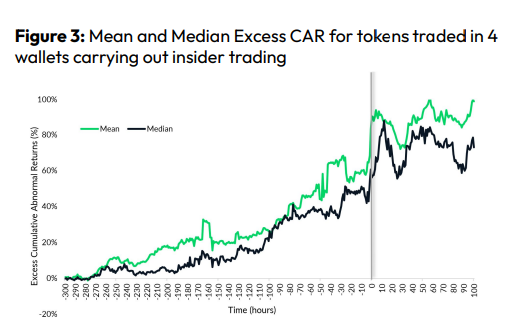
Finally, LAYERING is a sequence of spoofs in which successive orders are put along a ladder of greater (layering offers) or lower (layering bids) values. The paper concludes with recommendations to mitigate market manipulation. Exchange data transparency, market surveillance, and regulatory oversight could reduce manipulative tactics.