


How to Launch an NFT Project by Yourself
Creating 10,000 auto-generated artworks, deploying a smart contract to the Ethereum / Polygon blockchain, setting up some tools, etc.
There is so much to do from launching to running an NFT project. Creating parts for artworks, generating 10,000 unique artworks and metadata, creating a smart contract and deploying it to a blockchain network, creating a website, creating a Twitter account, setting up a Discord server, setting up an OpenSea collection. In addition, you need to have MetaMask installed in your browser and have some ETH / MATIC. Did you get tired of doing all this? Don’t worry, once you know what you need to do, all you have to do is do it one by one.
To be honest, it’s best to run an NFT project in a team of three or more, including artists, developers, and marketers. However, depending on your motivation, you can do it by yourself. Some people might come later to offer help with your project. The most important thing is to take a step as soon as possible.
Creating Parts for Artworks
There are lots of free/paid software for drawing, but after all, I think Adobe Illustrator or Photoshop is the best. The images of Skulls In Love are a composite of 48x48 pixel parts created using Photoshop.
The most important thing in creating parts for generative art is to repeatedly test what your artworks will look like after each layer has been combined. The generated artworks should not be too unnatural.
How Many Parts Should You Create?
Are you wondering how many parts you should create to avoid duplication as much as possible when generating your artworks? My friend Stephane, a developer, has created a great tool to help with that.
Generating 10,000 Unique Artworks and Metadata
I highly recommend using the HashLips Art Engine to generate your artworks and metadata. Perhaps there is no better artworks generation tool at the moment.
GitHub: https://github.com/HashLips/hashlips_art_engine
YouTube:
Storing Artworks and Metadata
Ideally, the generated artworks and metadata should be stored on-chain, but if you want to store them off-chain, you should use IPFS. Do not store in centralized storage. This is because data will be lost if the server goes down or if the company goes down. On the other hand, IPFS is a more secure way to find data because it utilizes a distributed, decentralized system.
Storing to IPFS is easy with Pinata, NFT.Storage, and so on. The Skulls In Love uses Pinata. It’s very easy to use, just upload the folder containing your artworks.
Creating and Deploying a Smart Contract
You don’t have to create a smart contract from scratch. There are many great NFT projects, many of which publish their contract source code on Etherscan / PolygonScan. You can choose the contract you like and reuse it. Of course, that requires some knowledge of Solidity, but it depends on your efforts. If you don’t know which contract to choose, use the HashLips smart contract. It’s very simple, but it has almost all the functions you need.
GitHub: https://github.com/HashLips/hashlips_nft_contract
Note: Later on, you may want to change the cost value. You can change it on Remix or Etherscan / PolygonScan. But in this case, enter the Wei value instead of the Ether value. For example, if you want to sell for 1 MATIC, you have to enter “1000000000000000000”. If you set this value to “1”, you will have a nightmare. I recommend using Simple Unit Converter as a tool to calculate the Wei value.
Creating a Website
The website here is not just a static site to showcase your project, it’s a so-called dApp that allows you to access your smart contract and mint NFTs. In fact, this level of dApp is not too difficult for anyone who has ever created a website. Because the ethers.js / web3.js libraries make it easy to interact with your smart contract. There’s also no problem connecting wallets, as MetaMask has great documentation.
The Skulls In Love uses a simple, fast, and modern dApp that I built from scratch using Next.js. It is published on GitHub, so feel free to use it.
Why do people mint NFTs on a website?
Ethereum’s gas fees are high, so if you mint all your NFTs, there will be a huge initial cost. So it makes sense to get the buyers to help with the gas fees for minting.
What about Polygon? Polygon’s gas fees are super cheap, so even if you mint 10,000 NFTs, it’s not a big deal. But we don’t do that. Since NFT projects are a kind of game, it involves the fun of not knowing what will come out after minting.
Creating a Twitter Account
I highly recommend creating a Twitter account. Twitter is an indispensable tool for announcing giveaways and reaching more people. It’s better to announce your project and your artworks little by little, 1–2 weeks before launching your project.
Creating and Setting Up a Discord Server
I highly recommend creating a Discord server as well as a Twitter account. The Discord server is a community and its home. Fans of your NFT project will want to join your community and interact with many other members. So, carefully create each channel on your Discord server to make it a cozy place for your community members.
If you are unfamiliar with Discord, you may be particularly confused by the following:
What bots should I use?
How should I set roles and permissions?
But don’t worry. There are lots of great YouTube videos and blog posts about these.
It’s also a good idea to join the Discord servers of some NFT projects and see how they’re made. Our Discord server is so simple that even beginners will find it easy to understand. Please join us and see it!
Note: First, create a test account and a test server to make sure your bots and permissions work properly. It is better to verify the behavior on the test server before setting up your production server.
UPDATED: As your Discord server grows, you cannot manage it on your own. In this case, you will be hiring several moderators, but choose carefully before hiring. And don’t give them important role permissions right after hiring. Initially, the same permissions as other members are sufficient. After a while, you can add permissions as needed, such as kicking/banning, using the “@every” tag, and adding roles. Again, don’t immediately give significant permissions to your Mod role. Your server can be messed up by fake moderators.
Setting Up Your OpenSea Collection
Before you start selling your NFTs, you need to reserve some for airdrops, giveaways, staff, and more. It’s up to you whether it’s 100, 500, or how many.
After minting some of your NFTs, your account and collection should have been created in OpenSea. Go to OpenSea, connect to your wallet, and set up your collection. Just set your logo, banner image, description, links, royalties, and more. It’s not that difficult.
Promoting Your Project
After all, promotion is the most important thing. In fact, almost every successful NFT project spends a lot of time and effort on it.
In addition to Twitter and Discord, it’s even better to use Instagram, Reddit, and Medium. Also, register your project in NFTCalendar and DISBOARD
DISBOARD is the public Discord server listing community.
About Promoters
You’ll probably get lots of contacts from promoters on your Discord, Twitter, Instagram, and more. But most of them are scams, so don’t pay right away. If you have a promoter that looks attractive to you, be sure to check the promoter’s social media accounts or website to see who he/she is. They basically charge in dollars. The amount they charge isn’t cheap, but promoters with lots of followers may have some temporary effect on your project. Some promoters accept 50% prepaid and 50% postpaid. If you can afford it, it might be worth a try. I never ask them, though.
When Should the Promotion Activities Start?
You may be worried that if you promote your project before it starts, someone will copy your project (artworks). It is true that some projects have actually suffered such damage. I don’t have a clear answer to this question right now, but:
- Do not publish all the information about your project too early
- The information should be released little by little
- Creating artworks that no one can easily copy
I think these are important.
If anyone has a good idea, please share it!
About Giveaways
When hosting giveaways, you’ll probably use multiple social media platforms. You may want to grow your Discord server faster. But if joining the Discord server is included in the giveaway requirements, some people hate it. I recommend holding giveaways for each platform. On Twitter and Reddit, you should just add the words “Discord members-only giveaway is being held now! Please join us if you like!”.
If you want to easily pick a giveaway winner in your browser, I recommend Twitter Picker.
Precautions for Distributing Free NFTs
If you want to increase your Twitter followers and Discord members, you can actually get a lot of people by holding events such as giveaways and invite contests. However, distributing many free NFTs at once can be dangerous. Some people who want free NFTs, as soon as they get a free one, sell it at a very low price on marketplaces such as OpenSea. They don’t care about your project and are only thinking about replacing their own “free” NFTs with Ethereum. The lower the floor price of your NFTs, the lower the value of your NFTs (project). Try to think of ways to get people to “buy” your NFTs as much as possible.
Ethereum vs. Polygon
Even though Ethereum has high gas fees, NFT projects on the Ethereum network are still mainstream and popular. On the other hand, Polygon has very low gas fees and fast transaction processing, but NFT projects on the Polygon network are not very popular.
Why? There are several reasons, but the biggest one is that it’s a lot of work to get MATIC (on Polygon blockchain, use MATIC instead of ETH) ready to use. Simply put, you need to bridge your tokens to the Polygon chain. So people need to do this first before minting your NFTs on your website. It may not be a big deal for those who are familiar with crypto and blockchain, but it may be complicated for those who are not. I hope that the tedious work will be simplified in the near future.
If you are confident that your NFTs will be purchased even if they are expensive, or if the total supply of your NFTs is low, you may choose Ethereum. If you just want to save money, you should choose Polygon. Keep in mind that gas fees are incurred not only when minting, but also when performing some of your smart contract functions and when transferring your NFTs.
If I were to launch a new NFT project, I would probably choose Ethereum or Solana.
Conclusion
Some people may want to start an NFT project to make money, but don’t forget to enjoy your own project. Several months ago, I was playing with creating generative art by imitating the CryptoPunks. I found out that auto-generated artworks would be more interesting than I had imagined, and since then I’ve been completely absorbed in generative art.
This is one of the Skulls In Love artworks:
This character wears a cowboy hat, black slim sunglasses, and a kimono. If anyone looks like this, I can’t help laughing!
The Skulls In Love NFTs can be minted for a small amount of MATIC on the official website. Please give it a try to see what kind of unique characters will appear 💀💖
Thank you for reading to the end. I hope this article will be helpful to those who want to launch an NFT project in the future ✨
(Edited)
More on Web3 & Crypto

Dylan Smyth
4 years ago
10 Ways to Make Money Online in 2022
As a tech-savvy person (and software engineer) or just a casual technology user, I'm sure you've had this same question countless times: How do I make money online? and how do I make money with my PC/Mac?
You're in luck! Today, I will list the top 5 easiest ways to make money online. Maybe a top ten in the future? Top 5 tips for 2022.
1. Using the gig economy
There are many websites on the internet that allow you to earn extra money using skills and equipment that you already own.
I'm referring to the gig economy. It's a great way to earn a steady passive income from the comfort of your own home. For some sites, premium subscriptions are available to increase sales and access features like bidding on more proposals.
Some of these are:
- Freelancer
- Upwork
- Fiverr (⭐ my personal favorite)
- TaskRabbit
2. Mineprize
MINEPRIZE is a great way to make money online. What's more, You need not do anything! You earn money by lending your idle CPU power to MINEPRIZE.
To register with MINEPRIZE, all you need is an email address and a password. Let MINEPRIZE use your resources, and watch the money roll in! You can earn up to $100 per month by letting your computer calculate. That's insane.
3. Writing
“O Romeo, Romeo, why art thou Romeo?” Okay, I admit that not all writing is Shakespearean. To be a copywriter, you'll need to be fluent in English. Thankfully, we don't have to use typewriters anymore.
Writing is a skill that can earn you a lot of money (claps for the rhyme).
Here are a few ways you can make money typing on your fancy keyboard:
Self-publish a book
Write scripts for video creators
Write for social media
Book-checking
Content marketing help
What a list within a list!
4. Coding
Yes, kids. You've probably coded before if you understand
You've probably coded before if you understand
print("hello world");
Computational thinking (or coding) is one of the most lucrative ways to earn extra money, or even as a main source of income.
Of course, there are hardcode coders (like me) who write everything line by line, binary di — okay, that last part is a bit exaggerated.
But you can also make money by writing websites or apps or creating low code or no code platforms.
But you can also make money by writing websites or apps or creating low code or no code platforms.
Some low-code platforms
Sheet : spreadsheets to apps :
Loading... We'll install your new app... No-Code Your team can create apps and automate tasks. Agile…
www.appsheet.com
Low-code platform | Business app creator - Zoho Creator
Work is going digital, and businesses of all sizes must adapt quickly. Zoho Creator is a...
www.zoho.com
Sell your data with TrueSource. NO CODE NEEDED
Upload data, configure your product, and earn in minutes.
www.truesource.io
Cool, huh?
5. Created Content
If we use the internet correctly, we can gain unfathomable wealth and extra money. But this one is a bit more difficult. Unlike some of the other items on this list, it takes a lot of time up front.
I'm referring to sites like YouTube and Medium. It's a great way to earn money both passively and actively. With the likes of Jake- and Logan Paul, PewDiePie (a.k.a. Felix Kjellberg) and others, it's never too late to become a millionaire on YouTube. YouTubers are always rising to the top with great content.
6. NFTs and Cryptocurrency
It is now possible to amass large sums of money by buying and selling digital assets on NFTs and cryptocurrency exchanges. Binance's Initial Game Offer rewards early investors who produce the best results.
One awesome game sold a piece of its plot for US$7.2 million! It's Axie Infinity. It's free and available on Google Play and Apple Store.
7. Affiliate Marketing
Affiliate marketing is a form of advertising where businesses pay others (like bloggers) to promote their goods and services. Here's an example. I write a blog (like this one) and post an affiliate link to an item I recommend buying — say, a camera — and if you buy the camera, I get a commission!
These programs pay well:
- Elementor
- AWeber
- Sendinblue
- ConvertKit\sLeadpages
- GetResponse
- SEMRush\sFiverr
- Pabbly
8. Start a blog
Now, if you're a writer or just really passionate about something or a niche, blogging could potentially monetize that passion!
Create a blog about anything you can think of. It's okay to start right here on Medium, as I did.
9. Dropshipping
And I mean that in the best possible way — drop shopping is ridiculously easy to set up, but difficult to maintain for some.
Luckily, Shopify has made setting up an online store a breeze. Drop-shipping from Alibaba and DHGate is quite common. You've got a winner if you can find a local distributor willing to let you drop ship their product!
10. Set up an Online Course
If you have a skill and can articulate it, online education is for you.
Skillshare, Pluralsight, and Coursera have all made inroads in recent years, upskilling people with courses that YOU can create and earn from.
That's it for today! Please share if you liked this post. If not, well —

Miguel Saldana
3 years ago
Crypto Inheritance's Catch-22
Security, privacy, and a strategy!

How to manage digital assets in worst-case scenarios is a perennial crypto concern. Since blockchain and bitcoin technology is very new, this hasn't been a major issue. Many early developers are still around, and many groups created around this technology are young and feel they have a lot of life remaining. This is why inheritance and estate planning in crypto should be handled promptly. As cryptocurrency's intrinsic worth rises, many people in the ecosystem are holding on to assets that might represent generational riches. With that much value, it's crucial to have a plan. Creating a solid plan entails several challenges.
the initial hesitation in coming up with a plan
The technical obstacles to ensuring the assets' security and privacy
the passing of assets from a deceased or incompetent person
Legal experts' lack of comprehension and/or understanding of how to handle and treat cryptocurrency.
This article highlights several challenges, a possible web3-native solution, and how to learn more.

The Challenge of Inheritance:
One of the biggest hurdles to inheritance planning is starting the conversation. As humans, we don't like to think about dying. Early adopters will experience crazy gains as cryptocurrencies become more popular. Creating a plan is crucial if you wish to pass on your riches to loved ones. Without a plan, the technical and legal issues I barely mentioned above would erode value by requiring costly legal fees and/or taxes, and you could lose everything if wallets and assets are not distributed appropriately (associated with the private keys). Raising awareness of the consequences of not having a plan should motivate people to make one.

Controlling Change:
Having an inheritance plan for your digital assets is crucial, but managing the guts and bolts poses a new set of difficulties. Privacy and security provided by maintaining your own wallet provide different issues than traditional finances and assets. Traditional finance is centralized (say a stock brokerage firm). You can assign another person to handle the transfer of your assets. In crypto, asset transfer is reimagined. One may suppose future transaction management is doable, but the user must consent, creating an impossible loop.
I passed away and must send a transaction to the person I intended to deliver it to.
I have to confirm or authorize the transaction, but I'm dead.
In crypto, scheduling a future transaction wouldn't function. To transfer the wallet and its contents, we'd need the private keys and/or seed phrase. Minimizing private key exposure is crucial to protecting your crypto from hackers, social engineering, and phishing. People have lost private keys after utilizing Life Hack-type tactics to secure them. People that break and hide their keys, lose them, or make them unreadable won't help with managing and/or transferring. This will require a derived solution.

Legal Challenges and Implications
Unlike routine cryptocurrency transfers and transactions, local laws may require special considerations. Even in the traditional world, estate/inheritance taxes, how assets will be split, and who executes the will must be considered. Many lawyers aren't crypto-savvy, which complicates the matter. There will be many hoops to jump through to safeguard your crypto and traditional assets and give them to loved ones.
Knowing RUFADAA/UFADAA, depending on your state, is vital for Americans. UFADAA offers executors and trustees access to online accounts (which crypto wallets would fall into). RUFADAA was changed to limit access to the executor to protect assets. RUFADAA outlines how digital assets are administered following death and incapacity in the US.
A Succession Solution
Having a will and talking about who would get what is the first step to having a solution, but using a Dad Mans Switch is a perfect tool for such unforeseen circumstances. As long as the switch's controller has control, nothing happens. Losing control of the switch initiates a state transition.
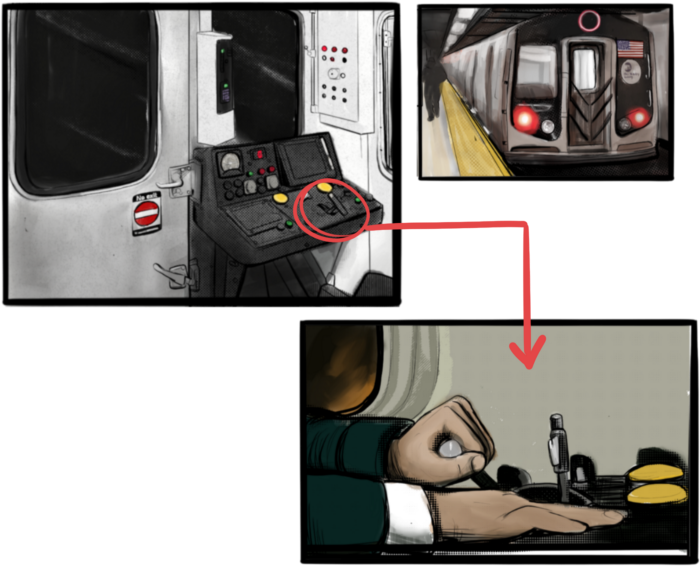
Subway or railway operations are examples. Modern control systems need the conductor to hold a switch to keep the train going. If they can't, the train stops.

Enter Sarcophagus
Sarcophagus is a decentralized dead man's switch built on Ethereum and Arweave. Sarcophagus allows actors to maintain control of their possessions even while physically unable to do so. Using a programmable dead man's switch and dual encryption, anything can be kept and passed on. This covers assets, secrets, seed phrases, and other use cases to provide authority and control back to the user and release trustworthy services from this work. Sarcophagus is built on a decentralized, transparent open source codebase. Sarcophagus is there if you're unprepared.


Modern Eremite
3 years ago
The complete, easy-to-understand guide to bitcoin

Introduction
Markets rely on knowledge.
The internet provided practically endless knowledge and wisdom. Humanity has never seen such leverage. Technology's progress drives us to adapt to a changing world, changing our routines and behaviors.
In a digital age, people may struggle to live in the analogue world of their upbringing. Can those who can't adapt change their lives? I won't answer. We should teach those who are willing to learn, nevertheless. Unravel the modern world's riddles and give them wisdom.
Adapt or die . Accept the future or remain behind.
This essay will help you comprehend Bitcoin better than most market participants and the general public. Let's dig into Bitcoin.
Join me.

Ascension
Bitcoin.org was registered in August 2008. Bitcoin whitepaper was published on 31 October 2008. The document intrigued and motivated people around the world, including technical engineers and sovereignty seekers. Since then, Bitcoin's whitepaper has been read and researched to comprehend its essential concept.
I recommend reading the whitepaper yourself. You'll be able to say you read the Bitcoin whitepaper instead of simply Googling "what is Bitcoin" and reading the fundamental definition without knowing the revolution's scope. The article links to Bitcoin's whitepaper. To avoid being overwhelmed by the whitepaper, read the following article first.
Bitcoin isn't the first peer-to-peer digital currency. Hashcash or Bit Gold were once popular cryptocurrencies. These two Bitcoin precursors failed to gain traction and produce the network effect needed for general adoption. After many struggles, Bitcoin emerged as the most successful cryptocurrency, leading the way for others.
Satoshi Nakamoto, an active bitcointalk.org user, created Bitcoin. Satoshi's identity remains unknown. Satoshi's last bitcointalk.org login was 12 December 2010. Since then, he's officially disappeared. Thus, conspiracies and riddles surround Bitcoin's creators. I've heard many various theories, some insane and others well-thought-out.
It's not about who created it; it's about knowing its potential. Since its start, Satoshi's legacy has changed the world and will continue to.
Block-by-block blockchain
Bitcoin is a distributed ledger. What's the meaning?
Everyone can view all blockchain transactions, but no one can undo or delete them.
Imagine you and your friends routinely eat out, but only one pays. You're careful with money and what others owe you. How can everyone access the info without it being changed?

You'll keep a notebook of your evening's transactions. Everyone will take a page home. If one of you changed the page's data, the group would notice and reject it. The majority will establish consensus and offer official facts.
Miners add a new Bitcoin block to the main blockchain every 10 minutes. The appended block contains miner-verified transactions. Now that the next block has been added, the network will receive the next set of user transactions.
Bitcoin Proof of Work—prove you earned it
Any firm needs hardworking personnel to expand and serve clients. Bitcoin isn't that different.
Bitcoin's Proof of Work consensus system needs individuals to validate and create new blocks and check for malicious actors. I'll discuss Bitcoin's blockchain consensus method.
Proof of Work helps Bitcoin reach network consensus. The network is checked and safeguarded by CPU, GPU, or ASIC Bitcoin-mining machines (Application-Specific Integrated Circuit).
Every 10 minutes, miners are rewarded in Bitcoin for securing and verifying the network. It's unlikely you'll finish the block. Miners build pools to increase their chances of winning by combining their processing power.
In the early days of Bitcoin, individual mining systems were more popular due to high maintenance costs and larger earnings prospects. Over time, people created larger and larger Bitcoin mining facilities that required a lot of space and sophisticated cooling systems to keep machines from overheating.
Proof of Work is a vital part of the Bitcoin network, as network security requires the processing power of devices purchased with fiat currency. Miners must invest in mining facilities, which creates a new business branch, mining facilities ownership. Bitcoin mining is a topic for a future article.
More mining, less reward
Bitcoin is usually scarce.
Why is it rare? It all comes down to 21,000,000 Bitcoins.
Were all Bitcoins mined? Nope. Bitcoin's supply grows until it hits 21 million coins. Initially, 50BTC each block was mined, and each block took 10 minutes. Around 2140, the last Bitcoin will be mined.
But 50BTC every 10 minutes does not give me the year 2140. Indeed careful reader. So important is Bitcoin's halving process.
What is halving?
The block reward is halved every 210,000 blocks, which takes around 4 years. The initial payout was 50BTC per block and has been decreased to 25BTC after 210,000 blocks. First halving occurred on November 28, 2012, when 10,500,000 BTC (50%) had been mined. As of April 2022, the block reward is 6.25BTC and will be lowered to 3.125BTC by 19 March 2024.
The halving method is tied to Bitcoin's hashrate. Here's what "hashrate" means.
What if we increased the number of miners and hashrate they provide to produce a block every 10 minutes? Wouldn't we manufacture blocks faster?

Every 10 minutes, blocks are generated with little asymmetry. Due to the built-in adaptive difficulty algorithm, the overall hashrate does not affect block production time. With increased hashrate, it's harder to construct a block. We can estimate when the next halving will occur because 10 minutes per block is fixed.
Building with nodes and blocks
For someone new to crypto, the unusual terms and words may be overwhelming. You'll also find everyday words that are easy to guess or have a vague idea of what they mean, how they work, and what they do. Consider blockchain technology.
Nodes and blocks: Think about that for a moment. What is your first idea?
The blockchain is a chain of validated blocks added to the main chain. What's a "block"? What's inside?
The block is another page in the blockchain book that has been filled with transaction information and accepted by the majority.
We won't go into detail about what each block includes and how it's built, as long as you understand its purpose.
What about nodes?
Nodes, along with miners, verify the blockchain's state independently. But why?
To create a full blockchain node, you must download the whole Bitcoin blockchain and check every transaction against Bitcoin's consensus criteria.
What's Bitcoin's size?
In April 2022, the Bitcoin blockchain was 389.72GB.
Bitcoin's blockchain has miners and node runners.
Let's revisit the US gold rush. Miners mine gold with their own power (physical and monetary resources) and are rewarded with gold (Bitcoin). All become richer with more gold, and so does the country.
Nodes are like sheriffs, ensuring everything is done according to consensus rules and that there are no rogue miners or network users.
Lost and held bitcoin
Does the Bitcoin exchange price match each coin's price? How many coins remain after 21,000,000? 21 million or less?
Common reason suggests a 21 million-coin supply.
What if I lost 1BTC from a cold wallet?
What if I saved 1000BTC on paper in 2010 and it was damaged?
What if I mined Bitcoin in 2010 and lost the keys?
Satoshi Nakamoto's coins? Since then, those coins haven't moved.
How many BTC are truly in circulation?
Many people are trying to answer this question, and you may discover a variety of studies and individual research on the topic. Be cautious of the findings because they can't be evaluated and the statistics are hazy guesses.
On the other hand, we have long-term investors who won't sell their Bitcoin or will sell little amounts to cover mining or living needs.
The price of Bitcoin is determined by supply and demand on exchanges using liquid BTC. How many BTC are left after subtracting lost and non-custodial BTC?
We have significantly less Bitcoin in circulation than you think, thus the price may not reflect demand if we knew the exact quantity of coins available.
True HODLers and diamond-hand investors won't sell you their coins, no matter the market.
What's UTXO?
Unspent (U) Transaction (TX) Output (O)

Imagine taking a $100 bill to a store. After choosing a drink and munchies, you walk to the checkout to pay. The cashier takes your $100 bill and gives you $25.50 in change. It's in your wallet.
Is it simply 100$? No way.
The $25.50 in your wallet is unrelated to the $100 bill you used. Your wallet's $25.50 is just bills and coins. Your wallet may contain these coins and bills:
2x 10$ 1x 10$
1x 5$ or 3x 5$
1x 0.50$ 2x 0.25$
Any combination of coins and bills can equal $25.50. You don't care, and I'd wager you've never ever considered it.
That is UTXO. Now, I'll detail the Bitcoin blockchain and how UTXO works, as it's crucial to know what coins you have in your (hopefully) cold wallet.
You purchased 1BTC. Is it all? No. UTXOs equal 1BTC. Then send BTC to a cold wallet. Say you pay 0.001BTC and send 0.999BTC to your cold wallet. Is it the 1BTC you got before? Well, yes and no. The UTXOs are the same or comparable as before, but the blockchain address has changed. It's like if you handed someone a wallet, they removed the coins needed for a network charge, then returned the rest of the coins and notes.
UTXO is a simple concept, but it's crucial to grasp how it works to comprehend dangers like dust attacks and how coins may be tracked.
Lightning Network: fast cash
You've probably heard of "Layer 2 blockchain" projects.
What does it mean?
Layer 2 on a blockchain is an additional layer that increases the speed and quantity of transactions per minute and reduces transaction fees.
Imagine going to an obsolete bank to transfer money to another account and having to pay a charge and wait. You can transfer funds via your bank account or a mobile app without paying a fee, or the fee is low, and the cash appear nearly quickly. Layer 1 and 2 payment systems are different.
Layer 1 is not obsolete; it merely has more essential things to focus on, including providing the blockchain with new, validated blocks, whereas Layer 2 solutions strive to offer Layer 1 with previously processed and verified transactions. The primary blockchain, Bitcoin, will only receive the wallets' final state. All channel transactions until shutting and balancing are irrelevant to the main chain.
Layer 2 and the Lightning Network's goal are now clear. Most Layer 2 solutions on multiple blockchains are created as blockchains, however Lightning Network is not. Remember the following remark, as it best describes Lightning.

Lightning Network connects public and private Bitcoin wallets.
Opening a private channel with another wallet notifies just two parties. The creation and opening of a public channel tells the network that anyone can use it.
Why create a public Lightning Network channel?
Every transaction through your channel generates fees.
Money, if you don't know.
See who benefits when in doubt.
Anonymity, huh?
Bitcoin anonymity? Bitcoin's anonymity was utilized to launder money.
Well… You've heard similar stories. When you ask why or how it permits people to remain anonymous, the conversation ends as if it were just a story someone heard.
Bitcoin isn't private. Pseudonymous.
What if someone tracks your transactions and discovers your wallet address? Where is your anonymity then?

Bitcoin is like bulletproof glass storage; you can't take or change the money. If you dig and analyze the data, you can see what's inside.
Every online action leaves a trace, and traces may be tracked. People often forget this guideline.
A tool like that can help you observe what the major players, or whales, are doing with their coins when the market is uncertain. Many people spend time analyzing on-chain data. Worth it?
Ask yourself a question. What are the big players' options? Do you think they're letting you see their wallets for a small on-chain data fee?
Instead of short-term behaviors, focus on long-term trends.
More wallet transactions leave traces. Having nothing to conceal isn't a defect. Can it lead to regulating Bitcoin so every transaction is tracked like in banks today?
But wait. How can criminals pay out Bitcoin? They're doing it, aren't they?
Mixers can anonymize your coins, letting you to utilize them freely. This is not a guide on how to make your coins anonymous; it could do more harm than good if you don't know what you're doing.
Remember, being anonymous attracts greater attention.
Bitcoin isn't the only cryptocurrency we can use to buy things. Using cryptocurrency appropriately can provide usability and anonymity. Monero (XMR), Zcash (ZEC), and Litecoin (LTC) following the Mimblewimble upgrade are examples.
Summary
Congratulations! You've reached the conclusion of the article and learned about Bitcoin and cryptocurrency. You've entered the future.
You know what Bitcoin is, how its blockchain works, and why it's not anonymous. I bet you can explain Lightning Network and UTXO to your buddies.
Markets rely on knowledge. Prepare yourself for success before taking the first step. Let your expertise be your edge.
This article is a summary of this one.
You might also like

Abhimanyu Bhargava
3 years ago
VeeFriends Series 2: The Biggest NFT Opportunity Ever
VeeFriends is one NFT project I'm sure will last.

I believe in blockchain technology and JPEGs, aka NFTs. NFTs aren't JPEGs. It's not as it seems.
Gary Vaynerchuk is leading the pack with his new NFT project VeeFriends, I wrote a year ago. I was spot-on. It's the most innovative project I've seen.
Since its minting in May 2021, it has given its holders enormous value, most notably the first edition of VeeCon, a multi-day superconference featuring iconic and emerging leaders in NFTs and Popular Culture. First-of-its-kind NFT-ticketed Web3 conference to build friendships, share ideas, and learn together.
VeeFriends holders got free VeeCon NFT tickets. Attendees heard iconic keynote speeches, innovative talks, panels, and Q&A sessions.
It was a unique conference that most of us, including me, are looking forward to in 2023. The lineup was epic, and it allowed many to network in new ways. Really memorable learning. Here are a couple of gratitude posts from the attendees.
VeeFriends Series 2
This article explains VeeFriends if you're still confused.
GaryVee's hand-drawn doodles have evolved into wonderful characters. The characters' poses and backgrounds bring the VeeFriends IP to life.

Yes, this is the second edition of VeeFriends, and at current prices, it's one of the best NFT opportunities in years. If you have the funds and risk appetite to invest in NFTs, VeeFriends Series 2 is worth every penny. Even if you can't invest, learn from their journey.
1. Art Is the Start
Many critics say VeeFriends artwork is below average and not by GaryVee. Art is often the key to future success.
Let's look at one of the first Mickey Mouse drawings. No one would have guessed that this would become one of the most beloved animated short film characters. In Walt Before Mickey, Walt Disney's original mouse Mortimer was less refined.
First came a mouse...

These sketches evolved into Steamboat Willie, Disney's first animated short film.

Fred Moore redesigned the character artwork into what we saw in cartoons as kids. Mickey Mouse's history is here.

Looking at how different cartoon characters have evolved and gained popularity over decades, I believe Series 2 characters like Self-Aware Hare, Kind Kudu, and Patient Pig can do the same.

GaryVee captures this journey on the blockchain and lets early supporters become part of history. Time will tell if it rivals Disney, Pokemon, or Star Wars. Gary has been vocal about this vision.
2. VeeFriends is Intellectual Property for the Coming Generations
Most of us grew up watching cartoons, playing with toys, cards, and video games. Our interactions with fictional characters and the stories we hear shape us.
GaryVee is slowly curating an experience for the next generation with animated videos, card games, merchandise, toys, and more.
VeeFriends UNO, a collaboration with Mattel Creations, features 17 VeeFriends characters.
VeeFriends and Zerocool recently released Trading Cards featuring all 268 Series 1 characters and 15 new ones. Another way to build VeeFriends' collectibles brand.

At Veecon, all the characters were collectible toys. Something will soon emerge.
Kids and adults alike enjoy the YouTube channel's animated shorts and VeeFriends Tunes. Here's a song by the holder's Optimistic Otter-loving daughter.
This VeeFriends story is only the beginning. I'm looking forward to animated short film series, coloring books, streetwear, candy, toys, physical collectibles, and other forms of VeeFriends IP.
3. Veefriends will always provide utilities
Smart contracts can be updated at any time and authenticated on a ledger.
VeeFriends Series 2 gives no promise of any utility whatsoever. GaryVee released no project roadmap. In the first few months after launch, many owners of specific characters or scenes received utilities.
Every benefit or perk you receive helps promote the VeeFriends brand.
Recent partnerships are listed below.
MaryRuth's Multivitamin Gummies
Productive Puffin holders from VeeFriends x Primitive
Pickleball Scene & Clown Holders Only

Pickleball & Competitive Clown Exclusive experience, anteater multivitamin gummies, and Puffin x Primitive merch
Considering the price of NFTs, it may not seem like much. It's just the beginning; you never know what the future holds. No other NFT project offers such diverse, ongoing benefits.
4. Garyvee's team is ready
Gary Vaynerchuk's team and record are undisputed. He's a serial entrepreneur and the Chairman & CEO of VaynerX, which includes VaynerMedia, VaynerCommerce, One37pm, and The Sasha Group.
Gary founded VaynerSports, Resy, and Empathy Wines. He's a Candy Digital Board Member, VCR Group Co-Founder, ArtOfficial Co-Founder, and VeeFriends Creator & CEO. Gary was recently named one of Fortune's Top 50 NFT Influencers.

Gary Vayenerchuk aka GaryVee
Gary documents his daily life as a CEO on social media, which has 34 million followers and 272 million monthly views. GaryVee Audio Experience is a top podcast. He's a five-time New York Times best-seller and sought-after speaker.
Gary can observe consumer behavior to predict trends. He understood these trends early and pioneered them.
1997 — Realized e-potential commerce's and started winelibrary.com. In five years, he grew his father's wine business from $3M to $60M.
2006 — Realized content marketing's potential and started Wine Library on YouTube. TV
2009 — Estimated social media's potential (Web2) and invested in Facebook, Twitter, and Tumblr.
2014: Ethereum and Bitcoin investments
2021 — Believed in NFTs and Web3 enough to launch VeeFriends
GaryVee isn't all of VeeFriends. Andy Krainak, Dave DeRosa, Adam Ripps, Tyler Dowdle, and others work tirelessly to make VeeFriends a success.
GaryVee has said he'll let other businesses fail but not VeeFriends. We're just beginning his 40-year vision.
I have more confidence than ever in a company with a strong foundation and team.
5. Humans die, but characters live forever
What if GaryVee dies or can't work?
A writer's books can immortalize them. As long as their books exist, their words are immortal. Socrates, Hemingway, Aristotle, Twain, Fitzgerald, and others have become immortal.
Everyone knows Vincent Van Gogh's The Starry Night.
We all love reading and watching Peter Parker, Thor, or Jessica Jones. Their behavior inspires us. Stan Lee's message and stories live on despite his death.
GaryVee represents VeeFriends. Creating characters to communicate ensures that the message reaches even those who don't listen.
Gary wants his values and messages to be omnipresent in 268 characters. Messengers die, but their messages live on.
Gary envisions VeeFriends creating timeless stories and experiences. Ten years from now, maybe every kid will sing Patient Pig.
6. I love the intent.
Gary planned to create Workplace Warriors three years ago when he began designing Patient Panda, Accountable Ant, and Empathy elephant. The project stalled. When NFTs came along, he knew.
Gary wanted to create characters with traits he values, such as accountability, empathy, patience, kindness, and self-awareness. He wants future generations to find these traits cool. He hopes one or more of his characters will become pop culture icons.
These emotional skills aren't taught in schools or colleges, but they're crucial for business and life success. I love that someone is teaching this at scale.
In the end, intent matters.
Humans Are Collectors
Buy and collect things to communicate. Since the 1700s. Medieval people formed communities around hidden metals and stones. Many people still collect stamps and coins, and luxury and fashion are multi-trillion dollar industries. We're collectors.
The early 2020s NFTs will be remembered in the future. VeeFriends will define a cultural and technological shift in this era. VeeFriends Series 1 is the original hand-drawn art, but it's expensive. VeeFriends Series 2 is a once-in-a-lifetime opportunity at $1,000.
If you are new to NFTs, check out How to Buy a Non Fungible Token (NFT) For Beginners
This is a non-commercial article. Not financial or legal advice. Information isn't always accurate. Before making important financial decisions, consult a pro or do your own research.
This post is a summary. Read the full article here

Alexandra Walker-Jones
3 years ago
These are the 15 foods you should eat daily and why.
Research on preventing disease, extending life, and caring for your body from the inside out

Grapefruit and pomegranates aren't on the list, so ignore that. Mostly, I enjoyed the visual, but those fruits are healthful, too.
15 (or 17 if you consider the photo) different foods a day sounds like a lot. If you're not used to it — it is.
These lists don't aim for perfection. Instead, use this article and the science below to eat more of these foods. If you can eat 5 foods one day and 5 the next, you're doing well. This list should be customized to your requirements and preferences.
“Every time you eat or drink, you are either feeding disease or fighting it” -Heather Morgan.
The 15 Foods That You Should Consume Daily and Why:
1. Dark/Red Berries
(blueberries, blackberries, acai, goji, cherries, strawberries, raspberries)
The 2010 Global Burden of Disease Study is the greatest definitive analysis of death and disease risk factors in history. They found the primary cause of both death, disability, and disease inside the United States was diet.
Not eating enough fruit, and specifically berries, was one of the best predictors of disease (1).
What's special about berries? It's their color! Berries have the most antioxidants of any fruit, second only to spices. The American Cancer Society found that those who ate the most berries were less likely to die of cardiovascular disease.
2. Beans
Soybeans, black beans, kidney beans, lentils, split peas, chickpeas.
Beans are one of the most important predictors of survival in older people, according to global research (2).
For every 20 grams (2 tablespoons) of beans consumed daily, the risk of death is reduced by 8%.
Soybeans and soy foods are high in phytoestrogen, which reduces breast and prostate cancer risks. Phytoestrogen blocks the receptors' access to true estrogen, mitigating the effects of weight gain, dairy (high in estrogen), and hormonal fluctuations (3).
3. Nuts
(almonds, walnuts, pecans, pistachios, Brazil nuts, cashews, hazelnuts, macadamia nuts)
Eating a handful of nuts every day reduces the risk of chronic diseases like heart disease and diabetes. Nuts also reduce oxidation, blood sugar, and LDL (bad) cholesterol, improving arterial function (4).
Despite their high-fat content, studies have linked daily nut consumption to a slimmer waistline and a lower risk of obesity (5).
4. Flaxseed
(milled flaxseed)
2013 research found that ground flaxseed had one of the strongest anti-hypertensive effects of any food. A few tablespoons (added to a smoothie or baked goods) lowered blood pressure and stroke risk 23 times more than daily aerobic exercise (6).
Flax shouldn't replace exercise, but its nutritional punch is worth adding to your diet.
5. Other seeds
(chia seeds, hemp seeds, pumpkin seeds, sesame seeds, fennel seeds)
Seeds are high in fiber and omega-3 fats and can be added to most dishes without being noticed.
When eaten with or after a meal, chia seeds moderate blood sugar and reduce inflammatory chemicals in the blood (7). Overall, a great daily addition.
6. Dates
Dates are one of the world's highest sugar foods, with 80% sugar by weight. Pure cake frosting is 60%, maple syrup is 66%, and cotton-candy jelly beans are 70%.
Despite their high sugar content, dates have a low glycemic index, meaning they don't affect blood sugar levels dramatically. They also improve triglyceride and antioxidant stress levels (8).
Dates are a great source of energy and contain high levels of dietary fiber and polyphenols, making 3-10 dates a great way to fight disease, support gut health with prebiotics, and satisfy a sweet tooth (9).
7. Cruciferous Veggies
(broccoli, Brussel sprouts, horseradish, kale, cauliflower, cabbage, boy choy, arugula, radishes, turnip greens)
Cruciferous vegetables contain an active ingredient that makes them disease-fighting powerhouses. Sulforaphane protects our brain, eyesight, against free radicals and environmental hazards, and treats and prevents cancer (10).
Unless you eat raw cruciferous vegetables daily, you won't get enough sulforaphane (and thus, its protective nutritional benefits). Cooking destroys the enzyme needed to create this super-compound.
If you chop broccoli, cauliflower, or turnip greens and let them sit for 45 minutes before cooking them, the enzyme will have had enough time to work its sulforaphane magic, allowing the vegetables to retain the same nutritional value as if eaten raw. Crazy, right? For more on this, see What Chopping Your Vegetables Has to Do with Fighting Cancer.
8. Whole grains
(barley, brown rice, quinoa, oats, millet, popcorn, whole-wheat pasta, wild rice)
Whole-grains are one of the healthiest ways to consume your daily carbs and help maintain healthy gut flora.
This happens when fibre is broken down in the colon and starts a chain reaction, releasing beneficial substances into the bloodstream and reducing the risk of Type 2 Diabetes and inflammation (11).
9. Spices
(turmeric, cumin, cinnamon, ginger, saffron, cloves, cardamom, chili powder, nutmeg, coriander)
7% of a person's cells will have DNA damage. This damage is caused by tiny breaks in our DNA caused by factors like free-radical exposure.
Free radicals cause mutations that damage lipids, proteins, and DNA, increasing the risk of disease and cancer. Free radicals are unavoidable because they result from cellular metabolism, but they can be avoided by consuming anti-oxidant and detoxifying foods.
Including spices and herbs like rosemary or ginger in our diet may cut DNA damage by 25%. Yes, this damage can be improved through diet. Turmeric worked better at a lower dose (just a pinch, daily). For maximum free-radical fighting (and anti-inflammatory) effectiveness, use 1.5 tablespoons of similar spices (12).
10. Leafy greens
(spinach, collard greens, lettuce, other salad greens, swiss chard)
Studies show that people who eat more leafy greens perform better on cognitive tests and slow brain aging by a year or two (13).
As we age, blood flow to the brain drops due to a decrease in nitric oxide, which prevents blood vessels from dilatation. Daily consumption of nitrate-rich vegetables like spinach and swiss chard may prevent dementia and Alzheimer's.
11. Fermented foods
(sauerkraut, tempeh, kombucha, plant-based kefir)
Miso, kimchi, and sauerkraut contain probiotics that support gut microbiome.
Probiotics balance the good and bad bacteria in our bodies and offer other benefits. Fermenting fruits and vegetables increases their antioxidant and vitamin content, preventing disease in multiple ways (14).
12. Sea vegetables
(seaweed, nori, dulse flakes)
A population study found that eating one sheet of nori seaweed per day may cut breast cancer risk by more than half (15).
Seaweed and sea vegetables may help moderate estrogen levels in the metabolism, reducing cancer and disease risk.
Sea vegetables make up 30% of the world's edible plants and contain unique phytonutrients. A teaspoon of these super sea-foods on your dinner will help fight disease from the inside out.
13. Water
I'm less concerned about whether you consider water food than whether you drink enough. If this list were ranked by what single item led to the best health outcomes, water would be first.
Research shows that people who drink 5 or more glasses of water per day have a 50% lower risk of dying from heart disease than those who drink 2 or less (16).
Drinking enough water boosts energy, improves skin, mental health, and digestion, and reduces the risk of various health issues, including obesity.
14. Tea
All tea consumption is linked to a lower risk of stroke, heart disease, and early death, with green tea leading for antioxidant content and immediate health benefits.
Green tea leaves may also be able to interfere with each stage of cancer formation, from the growth of the first mutated cell to the spread and progression of cancer in the body. Green tea is a quick and easy way to support your long-term and short-term health (17).
15. Supplemental B12 vitamin
B12, or cobalamin, is a vitamin responsible for cell metabolism. Not getting enough B12 can have serious consequences.
Historically, eating vegetables from untreated soil helped humans maintain their vitamin B12 levels. Due to modern sanitization, our farming soil lacks B12.
B12 is often cited as a problem only for vegetarians and vegans (as animals we eat are given B12 supplements before slaughter), but recent studies have found that plant-based eaters have lower B12 deficiency rates than any other diet (18).
Article Sources:

Quant Galore
3 years ago
I created BAW-IV Trading because I was short on money.
More retail traders means faster, more sophisticated, and more successful methods.
Tech specifications
Only requires a laptop and an internet connection.
We'll use OpenBB's research platform for data/analysis.
Pricing and execution on Options-Quant

Background
You don't need to know the arithmetic details to use this method.
Black-Scholes is a popular option pricing model. It's best for pricing European options. European options are only exercisable at expiration, unlike American options. American options are always exercisable.
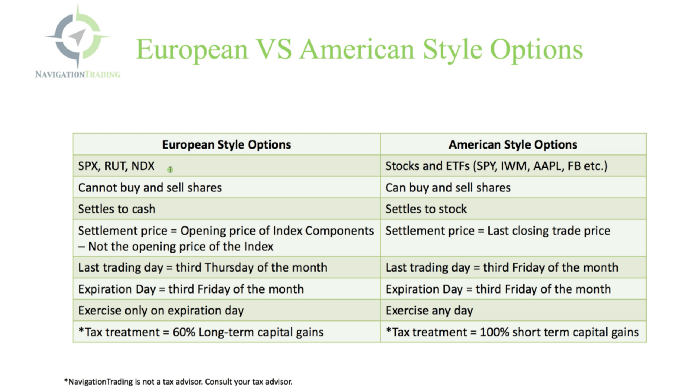
American options carry a premium to cover for the risk of early exercise. The Black-Scholes model doesn't account for this premium, hence it can't price genuine, traded American options.
Barone-Adesi-Whaley (BAW) model. BAW modifies Black-Scholes. It accounts for exercise risk premium and stock dividends. It adds the option's early exercise value to the Black-Scholes value.
The trader need not know the formulaic derivations of this model.
https://ir.nctu.edu.tw/bitstream/11536/14182/1/000264318900005.pdf
Strategy
This strategy targets implied volatility. First, we'll locate liquid options that expire within 30 days and have minimal implied volatility.
After selecting the option that meets the requirements, we price it to get the BAW implied volatility (we choose BAW because it's a more accurate Black-Scholes model). If estimated implied volatility is larger than market volatility, we'll capture the spread.
(Calculated IV — Market IV) = (Profit)
Some approaches to target implied volatility are pricey and inaccessible to individual investors. The best and most cost-effective alternative is to acquire a straddle and delta hedge. This may sound terrifying and pricey, but as shown below, it's much less so.
The Trade
First, we want to find our ideal option, so we use OpenBB terminal to screen for options that:
Have an IV at least 5% lower than the 20-day historical IV
Are no more than 5% out-of-the-money
Expire in less than 30 days
We query:
stocks/options/screen/set low_IV/scr --export Output.csv
This uses the screener function to screen for options that satisfy the above criteria, which we specify in the low IV preset (more on custom presets here). It then saves the matching results to a csv(Excel) file for viewing and analysis.
Stick to liquid names like SPY, AAPL, and QQQ since getting out of a position is just as crucial as getting in. Smaller, illiquid names have higher inefficiencies, which could restrict total profits.

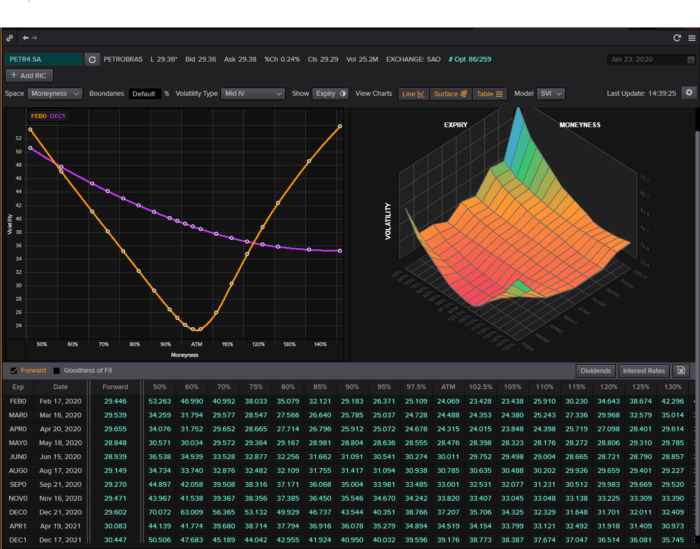
We calculate IV using the BAWbisection model (the bisection is a method of calculating IV, more can be found here.) We price the IV first.

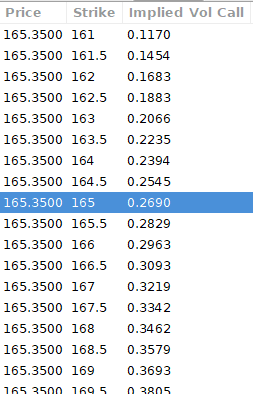
According to the BAW model, implied volatility at this level should be priced at 26.90%. When re-pricing the put, IV is 24.34%, up 3%.
Now it's evident. We must purchase the straddle (long the call and long the put) assuming the computed implied volatility is more appropriate and efficient than the market's. We just want to speculate on volatility, not price fluctuations, thus we delta hedge.
The Fun Starts
We buy both options for $7.65. (x100 multiplier). Initial delta is 2. For every dollar the stock price swings up or down, our position value moves $2.

We want delta to be 0 to avoid price vulnerability. A delta of 0 suggests our position's value won't change from underlying price changes. Being delta-hedged allows us to profit/lose from implied volatility. Shorting 2 shares makes us delta-neutral.

That's delta hedging. (Share price * shares traded) = $330.7 to become delta-neutral. You may have noted that delta is not truly 0.00. This is common since delta-hedging means getting as near to 0 as feasible, since it is rare for deltas to align at 0.00.
Now we're vulnerable to changes in Vega (and Gamma, but given we're dynamically hedging, it's not a big risk), or implied volatility. We wanted to gamble that the position's IV would climb by at least 2%, so we'll maintain it delta-hedged and watch IV.
Because the underlying moves continually, the option's delta moves continuously. A trader can short/long 5 AAPL shares at most. Paper trading lets you practice delta-hedging. Being quick-footed will help with this tactic.
Profit-Closing
As expected, implied volatility rose. By 10 minutes before market closure, the call's implied vol rose to 27% and the put's to 24%. This allowed us to sell the call for $4.95 and the put for $4.35, creating a profit of $165.

You may pull historical data to see how this trade performed. Note the implied volatility and pricing in the final options chain for August 5, 2022 (the position date).

Final Thoughts
Congratulations, that was a doozy. To reiterate, we identified tickers prone to increased implied volatility by screening OpenBB's low IV setting. We double-checked the IV by plugging the price into Options-BAW Quant's model. When volatility was off, we bought a straddle and delta-hedged it. Finally, implied volatility returned to a normal level, and we profited on the spread.
The retail trading space is very quickly catching up to that of institutions. Commissions and fees used to kill this method, but now they cost less than $5. Watching momentum, technical analysis, and now quantitative strategies evolve is intriguing.
I'm not linked with these sites and receive no financial benefit from my writing.
Tell me how your experience goes and how I helped; I love success tales.