



More on Entrepreneurship/Creators

Sarah Bird
3 years ago
Memes Help This YouTube Channel Earn Over $12k Per Month
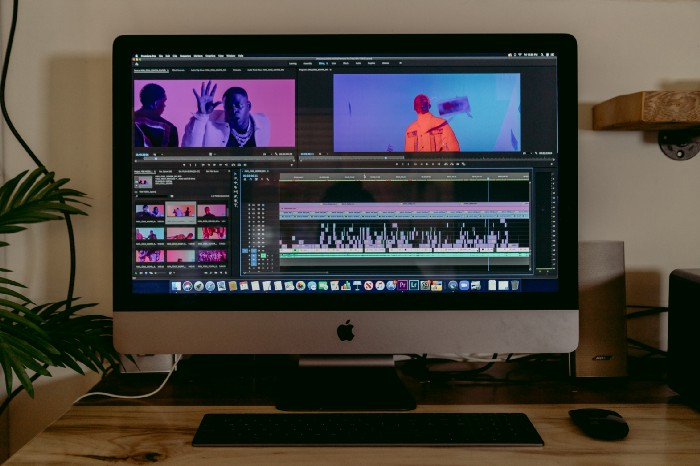
Take a look at a YouTube channel making anything up to over $12k a month from making very simple videos.
And the best part? Its replicable by anyone. Basic videos can be generated for free without design abilities.
Join me as I deconstruct the channel to estimate how much they make, how they do it, and how you can too.
What Do They Do Exactly?
Happy Land posts memes with a simple caption they wrote. So, it's new. The videos are a slideshow of meme photos with stock music.
The site posts 12 times a day.
8-10-minute videos show 10 second images. Thus, each video needs 48-60 memes.
Memes are video titles (e.g. times a boyfriend was hilarious, back to school fails, funny restaurant signs).
Some stats about the channel:
Founded on October 30, 2020
873 videos were added.
81.8k subscribers
67,244,196 views of the video
What Value Are They Adding?
Everyone can find free memes online. This channel collects similar memes into a single video so you don't have to scroll or click for more. It’s right there, you just keep watching and more will come.
By theming it, the audience is prepared for the video's content.
If you want hilarious animal memes or restaurant signs, choose the video and you'll get up to 60 memes without having to look for them. Genius!
How much money do they make?
According to www.socialblade.com, the channel earns $800-12.8k (image shown in my home currency of GBP).
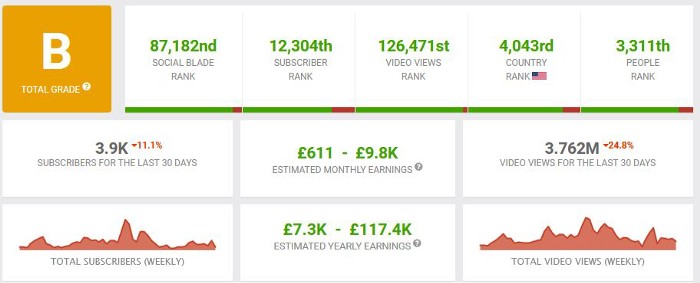
That's a crazy estimate, but it highlights the unbelievable potential of a channel that presents memes.
This channel thrives on quantity, thus putting out videos is necessary to keep the flow continuing and capture its audience's attention.
How Are the Videos Made?
Straightforward. Memes are added to a presentation without editing (so you could make this in PowerPoint or Keynote).
Each slide should include a unique image and caption. Set 10 seconds per slide.
Add music and post the video.
Finding enough memes for the material and theming is difficult, but if you enjoy memes, this is a fun job.
This case study should have shown you that you don't need expensive software or design expertise to make entertaining videos. Why not try fresh, easy-to-do ideas and see where they lead?

Emils Uztics
3 years ago
This billionaire created a side business that brings around $90,000 per month.

Dharmesh Shah co-founded HubSpot. WordPlay reached $90,000 per month in revenue without utilizing any of his wealth.
His method:
Take Advantage Of An Established Trend
Remember Wordle? Dharmesh was instantly hooked. As was the tech world.

HubSpot's co-founder noted inefficiencies in a recent My First Million episode. He wanted to play daily. Dharmesh, a tinkerer and software engineer, decided to design a word game.
He's a billionaire. How could he?
Wordle had limitations in his opinion;
Dharmesh is fundamentally a developer. He desired to start something new and increase his programming knowledge;
This project may serve as an excellent illustration for his son, who had begun learning about software development.
Better It Up
Building a new Wordle wasn't successful.
WordPlay lets you play with friends and family. You could challenge them and compare the results. It is a built-in growth tool.
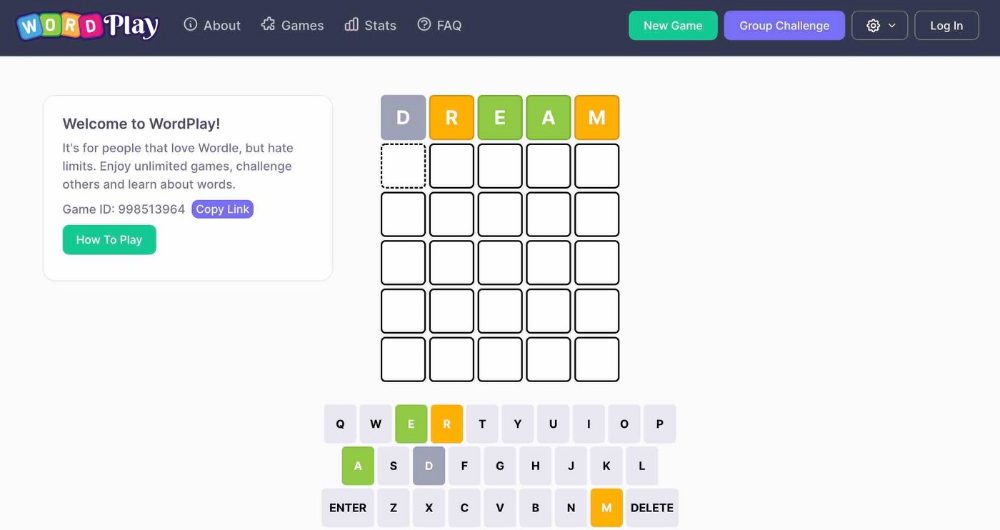
WordPlay features:
the capacity to follow sophisticated statistics after creating an account;
continuous feedback on your performance;
Outstanding domain name (wordplay.com).
Project Development
WordPlay has 9.5 million visitors and 45 million games played since February.
HubSpot co-founder credits tremendous growth to flywheel marketing, pushing the game through his own following.
Choosing an exploding specialty and making sharing easy also helped.
Shah enabled Google Ads on the website to test earning potential. Monthly revenue was $90,000.
That's just Google Ads. If monetization was the goal, a specialized ad network like Ezoic could double or triple the amount.
Wordle was a great buy for The New York Times at $1 million.

Sanjay Priyadarshi
3 years ago
Using Ruby code, a programmer created a $48,000,000,000 product that Elon Musk admired.
Unexpected Success

Shopify CEO and co-founder Tobias Lutke. Shopify is worth $48 billion.
World-renowned entrepreneur Tobi
Tobi never expected his first online snowboard business to become a multimillion-dollar software corporation.
Tobi founded Shopify to establish a 20-person company.
The publicly traded corporation employs over 10,000 people.
Here's Tobi Lutke's incredible story.
Elon Musk tweeted his admiration for the Shopify creator.
30-October-2019.
Musk praised Shopify founder Tobi Lutke on Twitter.
Happened:
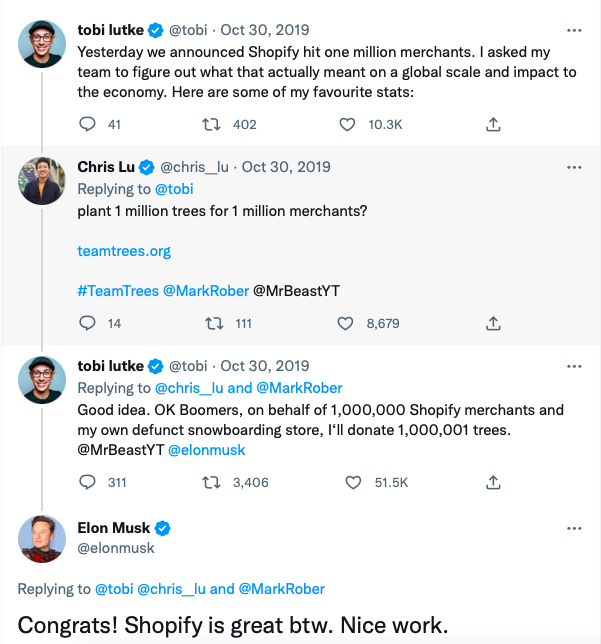
Explore this programmer's journey.
What difficulties did Tobi experience as a young child?
Germany raised Tobi.
Tobi's parents realized he was smart but had trouble learning as a toddler.
Tobi was learning disabled.
Tobi struggled with school tests.
Tobi's learning impairments were undiagnosed.
Tobi struggled to read as a dyslexic.
Tobi also found school boring.
Germany's curriculum didn't inspire Tobi's curiosity.
“The curriculum in Germany was taught like here are all the solutions you might find useful later in life, spending very little time talking about the problem…If I don’t understand the problem I’m trying to solve, it’s very hard for me to learn about a solution to a problem.”
Studying computer programming
After tenth grade, Tobi decided school wasn't for him and joined a German apprenticeship program.
This curriculum taught Tobi software engineering.
He was an apprentice in a small Siemens subsidiary team.
Tobi worked with rebellious Siemens employees.
Team members impressed Tobi.
Tobi joined the team for this reason.
Tobi was pleased to get paid to write programming all day.
His life could not have been better.
Devoted to snowboarding
Tobi loved snowboarding.
He drove 5 hours to ski at his folks' house.
His friends traveled to the US to snowboard when he was older.
However, the cheap dollar conversion rate led them to Canada.
2000.
Tobi originally decided to snowboard instead than ski.
Snowboarding captivated him in Canada.
On the trip to Canada, Tobi encounters his wife.
Tobi meets his wife Fiona McKean on his first Canadian ski trip.
They maintained in touch after the trip.
Fiona moved to Germany after graduating.
Tobi was a startup coder.
Fiona found work in Germany.
Her work included editing, writing, and academics.
“We lived together for 10 months and then she told me that she need to go back for the master's program.”
With Fiona, Tobi immigrated to Canada.
Fiona invites Tobi.
Tobi agreed to move to Canada.
Programming helped Tobi move in with his girlfriend.
Tobi was an excellent programmer, therefore what he did in Germany could be done anywhere.
He worked remotely for his German employer in Canada.
Tobi struggled with remote work.
Due to poor communication.
No slack, so he used email.
Programmers had trouble emailing.
Tobi's startup was developing a browser.
After the dot-com crash, individuals left that startup.
It ended.
Tobi didn't intend to work for any major corporations.
Tobi left his startup.
He believed he had important skills for any huge corporation.
He refused to join a huge corporation.
Because of Siemens.
Tobi learned to write professional code and about himself while working at Siemens in Germany.
Siemens culture was odd.
Employees were distrustful.
Siemens' rigorous dress code implies that the corporation doesn't trust employees' attire.
It wasn't Tobi's place.
“There was so much bad with it that it just felt wrong…20-year-old Tobi would not have a career there.”
Focused only on snowboarding
Tobi lived in Ottawa with his girlfriend.
Canada is frigid in winter.
Ottawa's winters last.
Almost half a year.
Tobi wanted to do something worthwhile now.
So he snowboarded.
Tobi began snowboarding seriously.
He sought every snowboarding knowledge.
He researched the greatest snowboarding gear first.
He created big spreadsheets for snowboard-making technologies.
Tobi grew interested in selling snowboards while researching.
He intended to sell snowboards online.
He had no choice but to start his own company.
A small local company offered Tobi a job.
Interested.
He must sign papers to join the local company.
He needed a work permit when he signed the documents.
Tobi had no work permit.
He was allowed to stay in Canada while applying for permanent residency.
“I wasn’t illegal in the country, but my state didn’t give me a work permit. I talked to a lawyer and he told me it’s going to take a while until I get a permanent residency.”
Tobi's lawyer told him he cannot get a work visa without permanent residence.
His lawyer said something else intriguing.
Tobis lawyer advised him to start a business.
Tobi declined this local company's job offer because of this.
Tobi considered opening an internet store with his technical skills.
He sold snowboards online.
“I was thinking of setting up an online store software because I figured that would exist and use it as a way to sell snowboards…make money while snowboarding and hopefully have a good life.”
What brought Tobi and his co-founder together, and how did he support Tobi?
Tobi lived with his girlfriend's parents.
In Ottawa, Tobi encounters Scott Lake.
Scott was Tobis girlfriend's family friend and worked for Tobi's future employer.
Scott and Tobi snowboarded.
Tobi pitched Scott his snowboard sales software idea.
Scott liked the idea.
They planned a business together.
“I was looking after the technology and Scott was dealing with the business side…It was Scott who ended up developing relationships with vendors and doing all the business set-up.”
Issues they ran into when attempting to launch their business online
Neither could afford a long-term lease.
That prompted their online business idea.
They would open a store.
Tobi anticipated opening an internet store in a week.
Tobi seeks open-source software.
Most existing software was pricey.
Tobi and Scott couldn't afford pricey software.
“In 2004, I was sitting in front of my computer absolutely stunned realising that we hadn’t figured out how to create software for online stores.”
They required software to:
to upload snowboard images to the website.
people to look up the types of snowboards that were offered on the website. There must be a search feature in the software.
Online users transmit payments, and the merchant must receive them.
notifying vendors of the recently received order.
No online selling software existed at the time.
Online credit card payments were difficult.
How did they advance the software while keeping expenses down?
Tobi and Scott needed money to start selling snowboards.
Tobi and Scott funded their firm with savings.
“We both put money into the company…I think the capital we had was around CAD 20,000(Canadian Dollars).”
Despite investing their savings.
They minimized costs.
They tried to conserve.
No office rental.
They worked in several coffee shops.
Tobi lived rent-free at his girlfriend's parents.
He installed software in coffee cafes.
How were the software issues handled?
Tobi found no online snowboard sales software.
Two choices remained:
Change your mind and try something else.
Use his programming expertise to produce something that will aid in the expansion of this company.
Tobi knew he was the sole programmer working on such a project from the start.
“I had this realisation that I’m going to be the only programmer who has ever worked on this, so I don’t have to choose something that lots of people know. I can choose just the best tool for the job…There is been this programming language called Ruby which I just absolutely loved ”
Ruby was open-source and only had Japanese documentation.
Latin is the source code.
Tobi used Ruby twice.
He assumed he could pick the tool this time.
Why not build with Ruby?
How did they find their first time operating a business?
Tobi writes applications in Ruby.
He wrote the initial software version in 2.5 months.
Tobi and Scott founded Snowdevil to sell snowboards.
Tobi coded for 16 hours a day.
His lifestyle was unhealthy.
He enjoyed pizza and coke.
“I would never recommend this to anyone, but at the time there was nothing more interesting to me in the world.”
Their initial purchase and encounter with it
Tobi worked in cafes then.
“I was working in a coffee shop at this time and I remember everything about that day…At some time, while I was writing the software, I had to type the email that the software would send to tell me about the order.”
Tobi recalls everything.
He checked the order on his laptop at the coffee shop.
Pennsylvanian ordered snowboard.
Tobi walked home and called Scott. Tobi told Scott their first order.
They loved the order.
How were people made aware about Snowdevil?
2004 was very different.
Tobi and Scott attempted simple website advertising.
Google AdWords was new.
Ad clicks cost 20 cents.
Online snowboard stores were scarce at the time.
Google ads propelled the snowdevil brand.
Snowdevil prospered.
They swiftly recouped their original investment in the snowboard business because to its high profit margin.
Tobi and Scott struggled with inventories.
“Snowboards had really good profit margins…Our biggest problem was keeping inventory and getting it back…We were out of stock all the time.”
Selling snowboards returned their investment and saved them money.
They did not appoint a business manager.
They accomplished everything alone.
Sales dipped in the spring, but something magical happened.
Spring sales plummeted.
They considered stocking different boards.
They naturally wanted to add boards and grow the business.
However, magic occurred.
Tobi coded and improved software while running Snowdevil.
He modified software constantly. He wanted speedier software.
He experimented to make the software more resilient.
Tobi received emails requesting the Snowdevil license.
They intended to create something similar.
“I didn’t stop programming, I was just like Ok now let me try things, let me make it faster and try different approaches…Increasingly I got people sending me emails and asking me If I would like to licence snowdevil to them. People wanted to start something similar.”
Software or skateboards, your choice
Scott and Tobi had to choose a hobby in 2005.
They might sell alternative boards or use software.
The software was a no-brainer from demand.
Daniel Weinand is invited to join Tobi's business.
Tobis German best friend is Daniel.
Tobi and Scott chose to use the software.
Tobi and Scott kept the software service.
Tobi called Daniel to invite him to Canada to collaborate.
Scott and Tobi had quit snowboarding until then.
How was Shopify launched, and whence did the name come from?
The three chose Shopify.
Named from two words.
First:
Shop
Final part:
Simplify
Shopify
Shopify's crew has always had one goal:
creating software that would make it simple and easy for people to launch online storefronts.
Launched Shopify after raising money for the first time.
Shopify began fundraising in 2005.
First, they borrowed from family and friends.
They needed roughly $200k to run the company efficiently.
$200k was a lot then.
When questioned why they require so much money. Tobi told them to trust him with their goals. The team raised seed money from family and friends.
Shopify.com has a landing page. A demo of their goal was on the landing page.
In 2006, Shopify had about 4,000 emails.
Shopify rented an Ottawa office.
“We sent a blast of emails…Some people signed up just to try it out, which was exciting.”
How things developed after Scott left the company
Shopify co-founder Scott Lake left in 2008.
Scott was CEO.
“He(Scott) realized at some point that where the software industry was going, most of the people who were the CEOs were actually the highly technical person on the founding team.”
Scott leaving the company worried Tobi.
Tobis worried about finding a new CEO.
To Tobi:
A great VC will have the network to identify the perfect CEO for your firm.
Tobi started visiting Silicon Valley to meet with venture capitalists to recruit a CEO.
Initially visiting Silicon Valley
Tobi came to Silicon Valley to start a 20-person company.
This company creates eCommerce store software.
Tobi never wanted a big corporation. He desired a fulfilling existence.
“I stayed in a hostel in the Bay Area. I had one roommate who was also a computer programmer. I bought a bicycle on Craiglist. I was there for a week, but ended up staying two and a half weeks.”
Tobi arrived unprepared.
When venture capitalists asked him business questions.
He answered few queries.
Tobi didn't comprehend VC meetings' terminology.
He wrote the terms down and looked them up.
Some were fascinated after he couldn't answer all these queries.
“I ended up getting the kind of term sheets people dream about…All the offers were conditional on moving our company to Silicon Valley.”
Canada received Tobi.
He wanted to consult his team before deciding. Shopify had five employees at the time.
2008.
A global recession greeted Tobi in Canada. The recession hurt the market.
His term sheets were useless.
The economic downturn in the world provided Shopify with a fantastic opportunity.
The global recession caused significant job losses.
Fired employees had several ideas.
They wanted online stores.
Entrepreneurship was desired. They wanted to quit work.
People took risks and tried new things during the global slump.
Shopify subscribers skyrocketed during the recession.
“In 2009, the company reached neutral cash flow for the first time…We were in a position to think about long-term investments, such as infrastructure projects.”
Then, Tobi Lutke became CEO.
How did Tobi perform as the company's CEO?
“I wasn’t good. My team was very patient with me, but I had a lot to learn…It’s a very subtle job.”
2009–2010.
Tobi limited the company's potential.
He deliberately restrained company growth.
Tobi had one costly problem:
Whether Shopify is a venture or a lifestyle business.
The company's annual revenue approached $1 million.
Tobi battled with the firm and himself despite good revenue.
His wife was supportive, but the responsibility was crushing him.
“It’s a crushing responsibility…People had families and kids…I just couldn’t believe what was going on…My father-in-law gave me money to cover the payroll and it was his life-saving.”
Throughout this trip, everyone supported Tobi.
They believed it.
$7 million in donations received
Tobi couldn't decide if this was a lifestyle or a business.
Shopify struggled with marketing then.
Later, Tobi tried 5 marketing methods.
He told himself that if any marketing method greatly increased their growth, he would call it a venture, otherwise a lifestyle.
The Shopify crew brainstormed and voted on marketing concepts.
Tested.
“Every single idea worked…We did Adwords, published a book on the concept, sponsored a podcast and all the ones we tracked worked.”
To Silicon Valley once more
Shopify marketing concepts worked once.
Tobi returned to Silicon Valley to pitch investors.
He raised $7 million, valuing Shopify at $25 million.
All investors had board seats.
“I find it very helpful…I always had a fantastic relationship with everyone who’s invested in my company…I told them straight that I am not going to pretend I know things, I want you to help me.”
Tobi developed skills via running Shopify.
Shopify had 20 employees.
Leaving his wife's parents' home
Tobi left his wife's parents in 2014.
Tobi had a child.
Shopify has 80,000 customers and 300 staff in 2013.
Public offering in 2015
Shopify investors went public in 2015.
Shopify powers 4.1 million e-Commerce sites.
Shopify stores are 65% US-based.
It is currently valued at $48 billion.
You might also like

Taher Batterywala
3 years ago
Do You Have Focus Issues? Use These 5 Simple Habits

Many can't concentrate. The first 20% of the day isn't optimized.
Elon Musk, Tony Robbins, and Bill Gates share something:
Morning Routines.
A repeatable morning ritual saves time.
The result?
Time for hobbies.
I'll discuss 5 easy morning routines you can use.
1. Stop pressing snooze
Waking up starts the day. You disrupt your routine by hitting snooze.
One sleep becomes three. Your morning routine gets derailed.
Fix it:
Hide your phone. This disables snooze and wakes you up.
Once awake, staying awake is 10x easier. Simple trick, big results.
2. Drink water
Chronic dehydration is common. Mostly urban, air-conditioned workers/residents.
2% cerebral dehydration causes short-term memory loss.
Dehydration shrinks brain cells.
Drink 3-4 liters of water daily to avoid this.
3. Improve your focus
How to focus better?
Meditation.
Improve your mood
Enhance your memory
increase mental clarity
Reduce blood pressure and stress
Headspace helps with the habit.
Here's a meditation guide.
Sit comfortably
Shut your eyes.
Concentrate on your breathing
Breathe in through your nose
Breathe out your mouth.
5 in, 5 out.
Repeat for 1 to 20 minutes.
Here's a beginner's video:
4. Workout
Exercise raises:
Mental Health
Effort levels
focus and memory
15-60 minutes of fun:
Exercise Lifting
Running
Walking
Stretching and yoga
This helps you now and later.
5. Keep a journal
You have countless thoughts daily. Many quietly steal your focus.
Here’s how to clear these:
Write for 5-10 minutes.
You'll gain 2x more mental clarity.
Recap
5 morning practices for 5x more productivity:
Say no to snoozing
Hydrate
Improve your focus
Exercise
Journaling
Conclusion
One step starts a thousand-mile journey. Try these easy yet effective behaviors if you have trouble concentrating or have too many thoughts.
Start with one of these behaviors, then add the others. Its astonishing results are instant.

DC Palter
2 years ago
Why Are There So Few Startups in Japan?
Japan's startup challenge: 7 reasons

Every day, another Silicon Valley business is bought for a billion dollars, making its founders rich while growing the economy and improving consumers' lives.
Google, Amazon, Twitter, and Medium dominate our daily lives. Tesla automobiles and Moderna Covid vaccinations.
The startup movement started in Silicon Valley, California, but the rest of the world is catching up. Global startup buzz is rising. Except Japan.
644 of CB Insights' 1170 unicorns—successful firms valued at over $1 billion—are US-based. China follows with 302 and India third with 108.
Japan? 6!
1% of US startups succeed. The third-largest economy is tied with small Switzerland for startup success.
Mexico (8), Indonesia (12), and Brazil (12) have more successful startups than Japan (16). South Korea has 16. Yikes! Problem?
Why Don't Startups Exist in Japan More?
Not about money. Japanese firms invest in startups. To invest in startups, big Japanese firms create Silicon Valley offices instead of Tokyo.
Startups aren't the issue either. Local governments are competing to be Japan's Shirikon Tani, providing entrepreneurs financing, office space, and founder visas.
Startup accelerators like Plug and Play in Tokyo, Osaka, and Kyoto, the Startup Hub in Kobe, and Google for Startups are many.
Most of the companies I've encountered in Japan are either local offices of foreign firms aiming to expand into the Japanese market or small businesses offering local services rather than disrupting a staid industry with new ideas.
There must be a reason Japan can develop world-beating giant corporations like Toyota, Nintendo, Shiseido, and Suntory but not inventive startups.
Culture, obviously. Japanese culture excels in teamwork, craftsmanship, and quality, but it hates moving fast, making mistakes, and breaking things.
If you have a brilliant idea in Silicon Valley, quit your job, get money from friends and family, and build a prototype. To fund the business, you approach angel investors and VCs.
Most non-startup folks don't aware that venture capitalists don't want good, profitable enterprises. That's wonderful if you're developing a solid small business to consult, open shops, or make a specialty product. However, you must pay for it or borrow money. Venture capitalists want moon rockets. Silicon Valley is big or bust. Almost 90% will explode and crash. The few successes are remarkable enough to make up for the failures.
Silicon Valley's high-risk, high-reward attitude contrasts with Japan's incrementalism. Japan makes the best automobiles and cleanrooms, but it fails to produce new items that grow the economy.
Changeable? Absolutely. But, what makes huge manufacturing enterprises successful and what makes Japan a safe and comfortable place to live are inextricably connected with the lack of startups.
Barriers to Startup Development in Japan
These are the 7 biggest obstacles to Japanese startup success.
Unresponsive Employment Market
While the lifelong employment system in Japan is evolving, the average employee stays at their firm for 12 years (15 years for men at large organizations) compared to 4.3 years in the US. Seniority, not experience or aptitude, determines career routes, making it tough to quit a job to join a startup and then return to corporate work if it fails.
Conservative Buyers
Even if your product is buggy and undocumented, US customers will migrate to a cheaper, superior one. Japanese corporations demand perfection from their trusted suppliers and keep with them forever. Startups need income fast, yet product evaluation takes forever.
Failure intolerance
Japanese business failures harm lives. Failed forever. It hinders risk-taking. Silicon Valley embraces failure. Build another startup if your first fails. Build a third if that fails. Every setback is viewed as a learning opportunity for success.
4. No Corporate Purchases
Silicon Valley industrial giants will buy fast-growing startups for a lot of money. Many huge firms have stopped developing new goods and instead buy startups after the product is validated.
Japanese companies prefer in-house product development over startup acquisitions. No acquisitions mean no startup investment and no investor reward.
Startup investments can also be monetized through stock market listings. Public stock listings in Japan are risky because the Nikkei was stagnant for 35 years while the S&P rose 14x.
5. Social Unity Above Wealth
In Silicon Valley, everyone wants to be rich. That creates a competitive environment where everyone wants to succeed, but it also promotes fraud and societal problems.
Japan values communal harmony above individual success. Wealthy folks and overachievers are avoided. In Japan, renegades are nearly impossible.
6. Rote Learning Education System
Japanese high school graduates outperform most Americans. Nonetheless, Japanese education is known for its rote memorization. The American system, which fails too many kids, emphasizes creativity to create new products.
Immigration.
Immigrants start 55% of successful Silicon Valley firms. Some come for university, some to escape poverty and war, and some are recruited by Silicon Valley startups and stay to start their own.
Japan is difficult for immigrants to start a business due to language barriers, visa restrictions, and social isolation.
How Japan Can Promote Innovation
Patchwork solutions to deep-rooted cultural issues will not work. If customers don't buy things, immigration visas won't aid startups. Startups must have a chance of being acquired for a huge sum to attract investors. If risky startups fail, employees won't join.
Will Japan never have a startup culture?
Once a consensus is reached, Japan changes rapidly. A dwindling population and standard of living may lead to such consensus.
Toyota and Sony were firms with renowned founders who used technology to transform the world. Repeatable.
Silicon Valley is flawed too. Many people struggle due to wealth disparities, job churn and layoffs, and the tremendous ups and downs of the economy caused by stock market fluctuations.
The founders of the 10% successful startups are heroes. The 90% that fail and return to good-paying jobs with benefits are never mentioned.
Silicon Valley startup culture and Japanese corporate culture are opposites. Each have pros and cons. Big Japanese corporations make the most reliable, dependable, high-quality products yet move too slowly. That's good for creating cars, not social networking apps.
Can innovation and success be encouraged without eroding social cohesion? That can motivate software firms to move fast and break things while recognizing the beauty and precision of expert craftsmen? A hybrid culture where Japan can make the world's best and most original items. Hopefully.

Solomon Ayanlakin
3 years ago
Metrics for product management and being a good leader
Never design a product without explicit metrics and tracking tools.
Imagine driving cross-country without a dashboard. How do you know your school zone speed? Low gas? Without a dashboard, you can't monitor your car. You can't improve what you don't measure, as Peter Drucker said. Product managers must constantly enhance their understanding of their users, how they use their product, and how to improve it for optimum value. Customers will only pay if they consistently acquire value from your product.

I’m Solomon Ayanlakin. I’m a product manager at CredPal, a financial business that offers credit cards and Buy Now Pay Later services. Before falling into product management (like most PMs lol), I self-trained as a data analyst, using Alex the Analyst's YouTube playlists and DannyMas' virtual data internship. This article aims to help product managers, owners, and CXOs understand product metrics, give a methodology for creating them, and execute product experiments to enhance them.
☝🏽Introduction
Product metrics assist companies track product performance from the user's perspective. Metrics help firms decide what to construct (feature priority), how to build it, and the outcome's success or failure. To give the best value to new and existing users, track product metrics.
Why should a product manager monitor metrics?
to assist your users in having a "aha" moment
To inform you of which features are frequently used by users and which are not
To assess the effectiveness of a product feature
To aid in enhancing client onboarding and retention
To assist you in identifying areas throughout the user journey where customers are satisfied or dissatisfied
to determine the percentage of returning users and determine the reasons for their return
📈 What Metrics Ought a Product Manager to Monitor?
What indicators should a product manager watch to monitor product health? The metrics to follow change based on the industry, business stage (early, growth, late), consumer needs, and company goals. A startup should focus more on conversion, activation, and active user engagement than revenue growth and retention. The company hasn't found product-market fit or discovered what features drive customer value.
Depending on your use case, company goals, or business stage, here are some important product metric buckets:
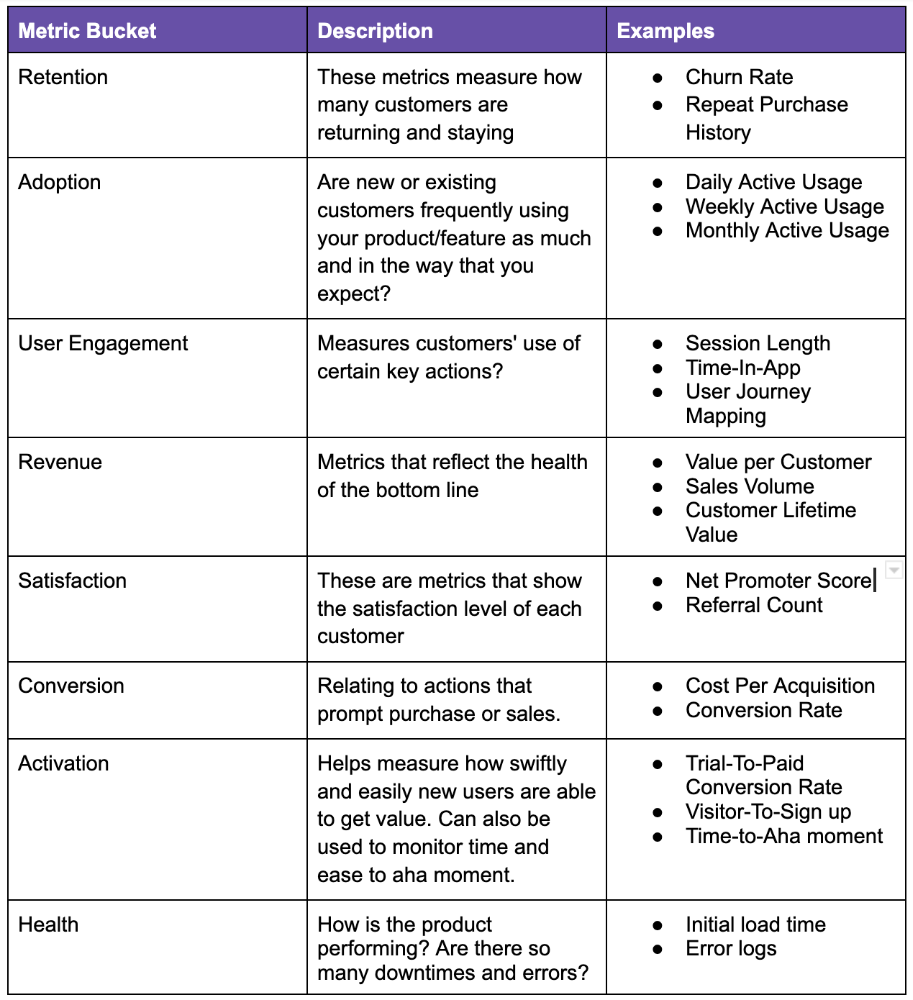
All measurements shouldn't be used simultaneously. It depends on your business goals and what value means for your users, then selecting what metrics to track to see if they get it.
Some KPIs are more beneficial to track, independent of industry or customer type. To prevent recording vanity metrics, product managers must clearly specify the types of metrics they should track. Here's how to segment metrics:
The North Star Metric, also known as the Focus Metric, is the indicator and aid in keeping track of the top value you provide to users.
Primary/Level 1 Metrics: These metrics should either add to the north star metric or be used to determine whether it is moving in the appropriate direction. They are metrics that support the north star metric.
These measures serve as leading indications for your north star and Level 2 metrics. You ought to have been aware of certain problems with your L2 measurements prior to the North star metric modifications.
North Star Metric
This is the key metric. A good north star metric measures customer value. It emphasizes your product's longevity. Many organizations fail to grow because they confuse north star measures with other indicators. A good focus metric should touch all company teams and be tracked forever. If a company gives its customers outstanding value, growth and success are inevitable. How do we measure this value?
A north star metric has these benefits:
Customer Obsession: It promotes a culture of customer value throughout the entire organization.
Consensus: Everyone can quickly understand where the business is at and can promptly make improvements, according to consensus.
Growth: It provides a tool to measure the company's long-term success. Do you think your company will last for a long time?
How can I pick a reliable North Star Metric?
Some fear a single metric. Ensure product leaders can objectively determine a north star metric. Your company's focus metric should meet certain conditions. Here are a few:
A good focus metric should reflect value and, as such, should be closely related to the point at which customers obtain the desired value from your product. For instance, the quick delivery to your home is a value proposition of UberEats. The value received from a delivery would be a suitable focal metric to use. While counting orders is alluring, the quantity of successfully completed positive review orders would make a superior north star statistic. This is due to the fact that a client who placed an order but received a defective or erratic delivery is not benefiting from Uber Eats. By tracking core value gain, which is the number of purchases that resulted in satisfied customers, we are able to track not only the total number of orders placed during a specific time period but also the core value proposition.
Focus metrics need to be quantifiable; they shouldn't only be feelings or states; they need to be actionable. A smart place to start is by counting how many times an activity has been completed.
A great focus metric is one that can be measured within predetermined time limits; otherwise, you are not measuring at all. The company can improve that measure more quickly by having time-bound focus metrics. Measuring and accounting for progress over set time periods is the only method to determine whether or not you are moving in the right path. You can then evaluate your metrics for today and yesterday. It's generally not a good idea to use a year as a time frame. Ideally, depending on the nature of your organization and the measure you are focusing on, you want to take into account on a daily, weekly, or monthly basis.
Everyone in the firm has the potential to affect it: A short glance at the well-known AAARRR funnel, also known as the Pirate Metrics, reveals that various teams inside the organization have an impact on the funnel. Ideally, the NSM should be impacted if changes are made to one portion of the funnel. Consider how the growth team in your firm is enhancing customer retention. This would have a good effect on the north star indicator because at this stage, a repeat client is probably being satisfied on a regular basis. Additionally, if the opposite were true and a client churned, it would have a negative effect on the focus metric.
It ought to be connected to the business's long-term success: The direction of sustainability would be indicated by a good north star metric. A company's lifeblood is product demand and revenue, so it's critical that your NSM points in the direction of sustainability. If UberEats can effectively increase the monthly total of happy client orders, it will remain in operation indefinitely.
Many product teams make the mistake of focusing on revenue. When the bottom line is emphasized, a company's goal moves from giving value to extracting money from customers. A happy consumer will stay and pay for your service. Customer lifetime value always exceeds initial daily, monthly, or weekly revenue.
Great North Star Metrics Examples

🥇 Basic/L1 Metrics:
The NSM is broad and focuses on providing value for users, while the primary metric is product/feature focused and utilized to drive the focus metric or signal its health. The primary statistic is team-specific, whereas the north star metric is company-wide. For UberEats' NSM, the marketing team may measure the amount of quality food vendors who sign up using email marketing. With quality vendors, more orders will be satisfied. Shorter feedback loops and unambiguous team assignments make L1 metrics more actionable and significant in the immediate term.
🥈 Supporting L2 metrics:
These are supporting metrics to the L1 and focus metrics. Location, demographics, or features are examples of L1 metrics. UberEats' supporting metrics might be the number of sales emails sent to food vendors, the number of opens, and the click-through rate. Secondary metrics are low-level and evident, and they relate into primary and north star measurements. UberEats needs a high email open rate to attract high-quality food vendors. L2 is a leading sign for L1.
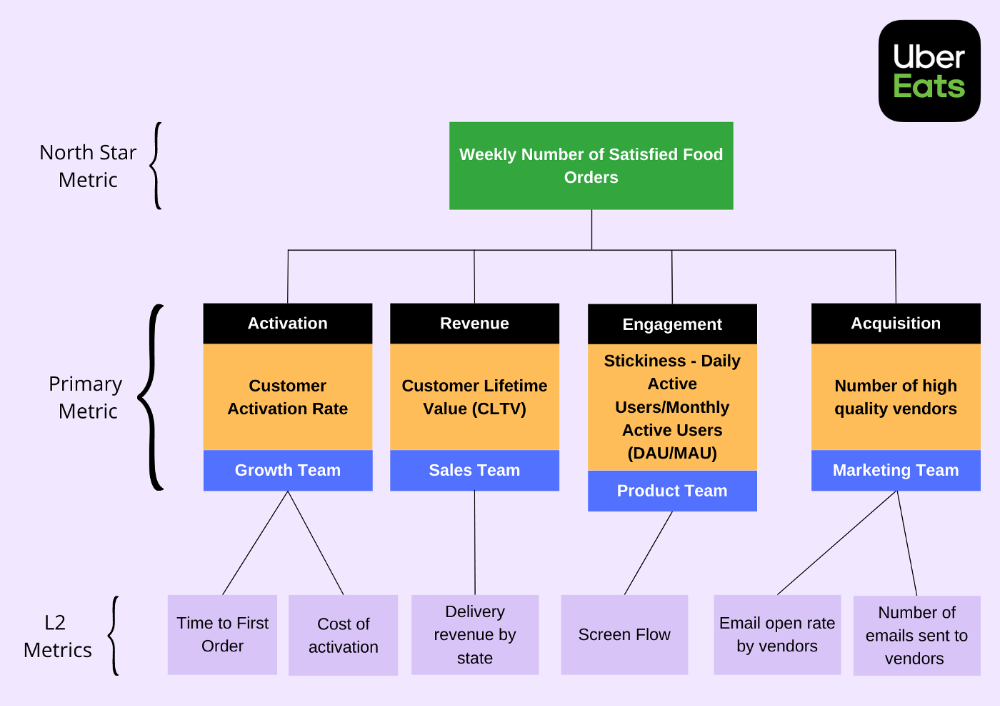
Where can I find product metrics?
How can I measure in-app usage and activity now that I know what metrics to track? Enter product analytics. Product analytics tools evaluate and improve product management parameters that indicate a product's health from a user's perspective.
Various analytics tools on the market supply product insight. From page views and user flows through A/B testing, in-app walkthroughs, and surveys. Depending on your use case and necessity, you may combine tools to see how users engage with your product. Gainsight, MixPanel, Amplitude, Google Analytics, FullStory, Heap, and Pendo are product tools.
This article isn't sponsored and doesn't market product analytics tools. When choosing an analytics tool, consider the following:
Tools for tracking your Focus, L1, and L2 measurements
Pricing
Adaptations to include external data sources and other products
Usability and the interface
Scalability
Security
An investment in the appropriate tool pays off. To choose the correct metrics to track, you must first understand your business need and what value means to your users. Metrics and analytics are crucial for any tech product's growth. It shows how your business is doing and how to best serve users.