



More on Entrepreneurship/Creators

Caleb Naysmith
3 years ago
Ads Coming to Medium?
Could this happen?
Medium isn't like other social media giants. It wasn't a dot-com startup that became a multi-trillion-dollar social media firm. It launched in 2012 but didn't gain popularity until later. Now, it's one of the largest sites by web traffic, but it's still little compared to most. Most of Medium's traffic is external, but they don't run advertisements, so it's all about memberships.
Medium isn't profitable, but they don't disclose how terrible the problem is. Most of the $163 million they raised has been spent or used for acquisitions. If the money turns off, Medium can't stop paying its writers since the site dies. Writers must be paid, but they can't substantially slash payment without hurting the platform. The existing model needs scale to be viable and has a low ceiling. Facebook and other free social media platforms are struggling to retain users. Here, you must pay to appreciate it, and it's bad for writers AND readers. If I had the same Medium stats on YouTube, I'd make thousands of dollars a month.
Then what? Medium has tried to monetize by offering writers a cut of new members, but that's unsustainable. People-based growth is limited. Imagine recruiting non-Facebook users and getting them to pay to join. Some may, but I'd rather write.
Alternatives:
Donation buttons
Tiered subscriptions ($5, $10, $25, etc.)
Expanding content
and these may be short-term fixes, but they're not as profitable as allowing ads. Advertisements can pay several dollars per click and cents every view. If you get 40,000 views a month like me, that's several thousand instead of a few hundred. Also, Medium would have enough money to split ad revenue with writers, who would make more. I'm among the top 6% of Medium writers. Only 6% of Medium writers make more than $100, and I made $500 with 35,000 views last month. Compared to YouTube, the top 1% of Medium authors make a lot. Mr. Beast and PewDiePie make MILLIONS a month, yet top Medium writers make tens of thousands. Sure, paying 3 or 4 people a few grand, or perhaps tens of thousands, will keep them around. What if great authors leveraged their following to go huge on YouTube and abandoned Medium? If people use Medium to get successful on other platforms, Medium will be continuously cycling through authors and paying them to stay.
Ads might make writing on Medium more profitable than making videos on YouTube because they could preserve the present freemium model and pay users based on internal views. The $5 might be ad-free.
Consider: Would you accept Medium ads? A $5 ad-free version + pay-as-you-go, etc. What are your thoughts on this?
Original post available here

Dani Herrera
3 years ago
What prevents companies from disclosing salary information?

Yes, salary details ought to be mentioned in job postings. Recruiters and candidates both agree, so why doesn't it happen?
The short answer is “Unfortunately, it’s not the Recruiter’s decision”. The longer answer is well… A LOT.
Starting in November 2022, NYC employers must include salary ranges in job postings. It should have started in May, but companies balked.
I'm thrilled about salary transparency. This decision will promote fair, inclusive, and equitable hiring practices, and I'm sure other states will follow suit. Good news!
Candidates, recruiters, and ED&I practitioners have advocated for pay transparency for years. Why the opposition?
Let's quickly review why companies have trouble sharing salary bands.
💰 Pay Parity
Many companies and leaders still oppose pay parity. Yes, even in 2022.
💰 Pay Equity
Many companies believe in pay parity and have reviewed their internal processes and systems to ensure equality.
However, Pay Equity affects who gets roles/promotions/salary raises/bonuses and when. Enter the pay gap!
💰Pay Transparency and its impact on Talent Retention
Sharing salary bands with external candidates (and the world) means current employees will have access to that information, which is one of the main reasons companies don't share salary data.
If a company has Pay Parity and Pay Equity issues, they probably have a Pay Transparency policy as well.
Sharing salary information with external candidates without ensuring current employees understand their own salary bands and how promotions/raises are decided could impact talent retention strategies.
This information should help clarify recent conversations.

Jayden Levitt
3 years ago
Billionaire who was disgraced lost his wealth more quickly than anyone in history
If you're not genuine, you'll be revealed.

Sam Bankman-Fried (SBF) was called the Cryptocurrency Warren Buffet.
No wonder.
SBF's trading expertise, Blockchain knowledge, and ability to construct FTX attracted mainstream investors.
He had a fantastic worldview, donating much of his riches to charity.
As the onion layers peel back, it's clear he wasn't the altruistic media figure he portrayed.
SBF's mistakes were disastrous.
Customer deposits were traded and borrowed by him.
With ten other employees, he shared a $40 million mansion where they all had polyamorous relationships.
Tone-deaf and wasteful marketing expenditures, such as the $200 million spent to change the name of the Miami Heat stadium to the FTX Arena
Democrats received a $40 million campaign gift.
And now there seems to be no regret.
FTX was a 32-billion-dollar cryptocurrency exchange.
It went bankrupt practically overnight.
SBF, FTX's creator, exploited client funds to leverage trade.
FTX had $1 billion in customer withdrawal reserves against $9 billion in liabilities in sister business Alameda Research.
Bloomberg Billionaire Index says it's the largest and fastest net worth loss in history.
It gets worse.
SBF's net worth is $900 Million, however he must still finalize FTX's bankruptcy.
SBF's arrest in the Bahamas and SEC inquiry followed news that his cryptocurrency exchange had crashed, losing billions in customer deposits.
A journalist contacted him on Twitter D.M., and their exchange is telling.
His ideas are revealed.
Kelsey Piper says they didn't expect him to answer because people under investigation don't comment.
Bankman-Fried wanted to communicate, and the interaction shows he has little remorse.
SBF talks honestly about FTX gaming customers' money and insults his competition.
Reporter Kelsey Piper was outraged by what he said and felt the mistakes SBF says plague him didn't evident in the messages.
Before FTX's crash, SBF was a poster child for Cryptocurrency regulation and avoided criticizing U.S. regulators.
He tells Piper that his lobbying is just excellent PR.
It shows his genuine views and supports cynics' opinions that his attempts to win over U.S. authorities were good for his image rather than Crypto.
SBF’s responses are in Grey, and Pipers are in Blue.
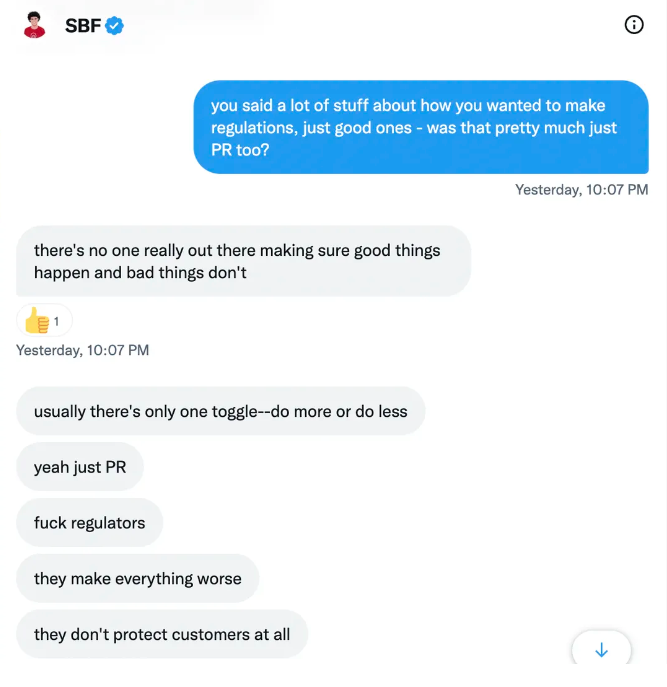
It's unclear if SBF cut corners for his gain. In their Twitter exchange, Piper revisits an interview question about ethics.
SBF says, "All the foolish sh*t I said"
SBF claims FTX has never invested customer monies.
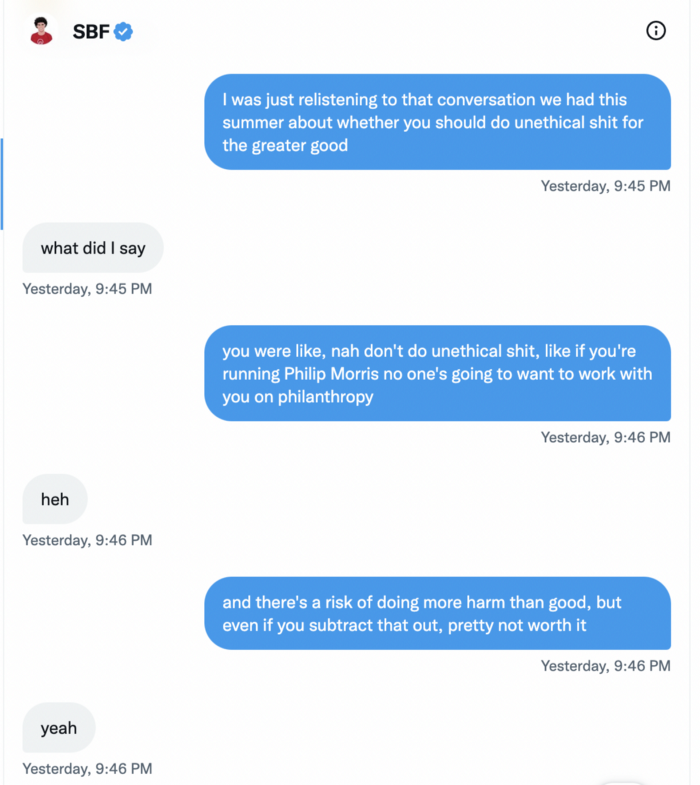
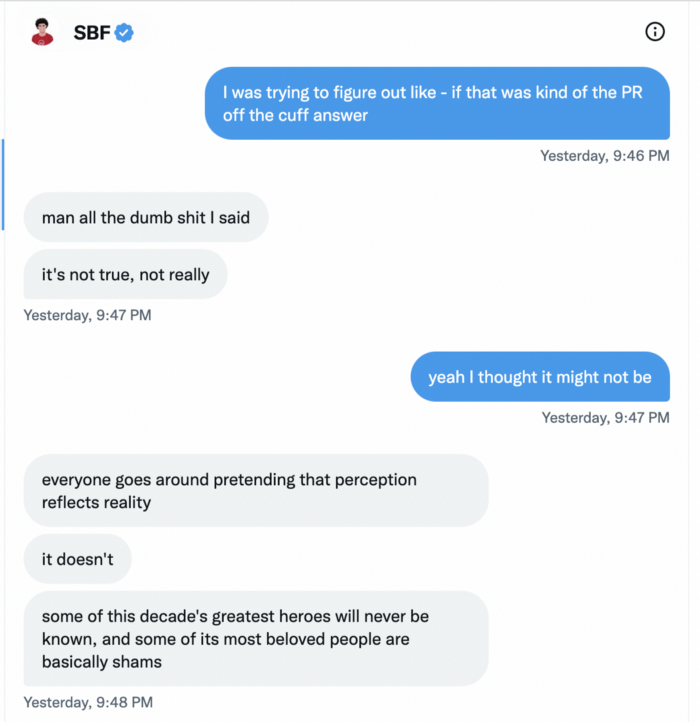
Piper challenged him on Twitter.
While he insisted FTX didn't use customer deposits, he said sibling business Alameda borrowed too much from FTX's balance sheet.
He did, basically.
When consumers tried to withdraw money, FTX was short.
SBF thought Alameda had enough money to cover FTX customers' withdrawals, but life sneaks up on you.
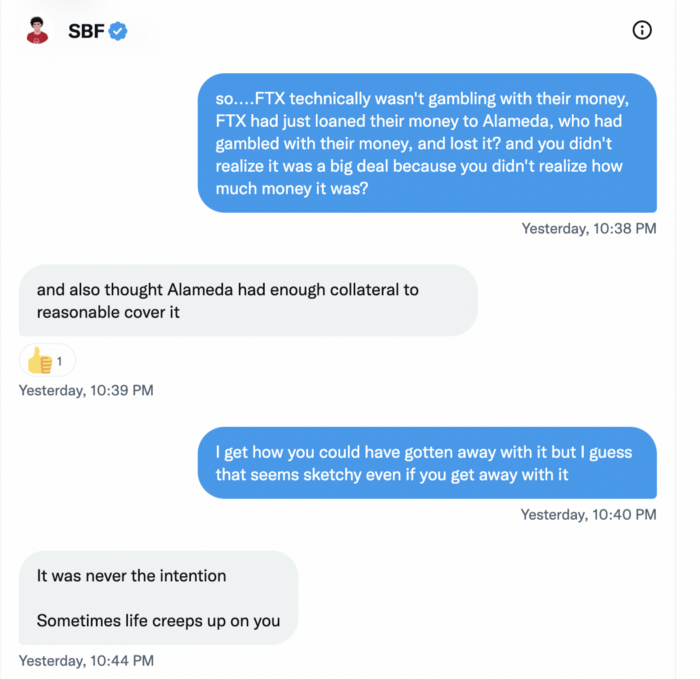
SBF believes most exchanges have done something similar to FTX, but they haven't had a bank run (a bunch of people all wanting to get their deposits out at the same time).
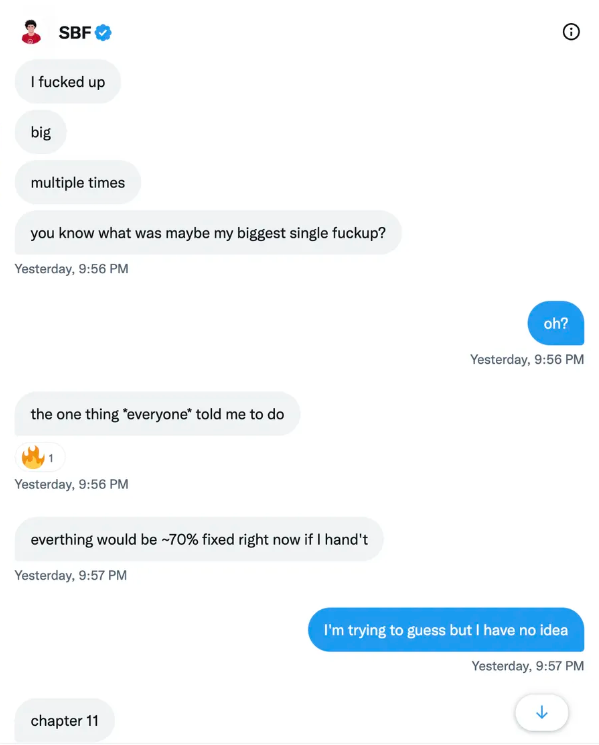
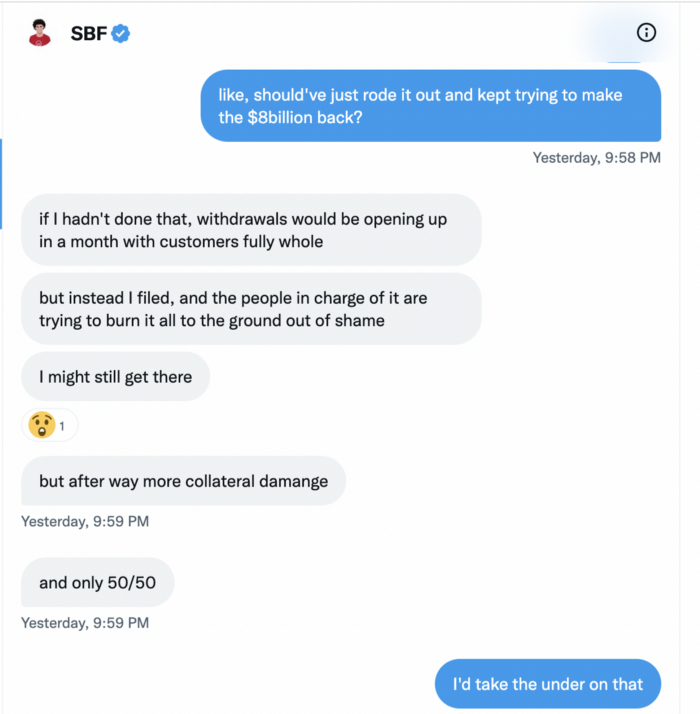
SBF believes he shouldn't have consented to the bankruptcy and kept attempting to raise more money because withdrawals would be open in a month with clients whole.
If additional money came in, he needed $8 billion to bridge the creditors' deficit, and there aren't many corporations with $8 billion to spare.
Once clients feel protected, they will continue to leave their assets on the exchange, according to one idea.
Kevin OLeary, a world-renowned hedge fund manager, says not all investors will walk through the open gate once the company is safe, therefore the $8 Billion wasn't needed immediately.
SBF claims the bankruptcy was his biggest error because he could have accumulated more capital.
Final Reflections
Sam Bankman-Fried, 30, became the world's youngest billionaire in four years.
Never listen to what people say about investing; watch what they do.
SBF is a trader who gets wrecked occasionally.
Ten first-time entrepreneurs ran FTX, screwing each other with no risk management.
It prevents opposing or challenging perspectives and echo chamber highs.
Twitter D.M. conversation with a journalist is the final nail.
He lacks an experienced crew.
This event will surely speed up much-needed regulation.
It's also prompted cryptocurrency exchanges to offer proof of reserves to calm customers.
You might also like
Caleb Naysmith
3 years ago Draft
A Myth: Decentralization
It’s simply not conceivable, or at least not credible.

One of the most touted selling points of Crypto has always been this grandiose idea of decentralization. Bitcoin first arose in 2009 after the housing crisis and subsequent crash that came with it. It aimed to solve this supposed issue of centralization. Nobody “owns” Bitcoin in theory, so the idea then goes that it won’t be subject to the same downfalls that led to the 2008 crash or similarly speculative events that led to the 2008 disaster. The issue is the banks, not the human nature associated with the greedy individuals running them.
Subsequent blockchains have attempted to fix many of the issues of Bitcoin by increasing capacity, decreasing the costs and processing times associated with Bitcoin, and expanding what can be done with their blockchains. Since nobody owns Bitcoin, it hasn’t really been able to be expanded on. You have people like Vitalk Buterin, however, that actively work on Ethereum though.
The leap from Bitcoin to Ethereum was a massive leap toward centralization, and the trend has only gotten worse. In fact, crypto has since become almost exclusively centralized in recent years.
Decentralization is only good in theory
It’s a good idea. In fact, it’s a wonderful idea. However, like other utopian societies, individuals misjudge human nature and greed. In a perfect world, decentralization would certainly be a wonderful idea because sure, people may function as their own banks, move payments immediately, remain anonymous, and so on. However, underneath this are a couple issues:
You can already send money instantaneously today.
They are not decentralized.
Decentralization is a bad idea.
Being your own bank is a stupid move.
Let’s break these down. Some are quite simple, but lets have a look.
Sending money right away
One thing with crypto is the idea that you can send payments instantly. This has pretty much been entirely solved in current times. You can transmit significant sums of money instantly for a nominal cost and it’s instantaneously cleared. Venmo was launched in 2009 and has since increased to prominence, and currently is on most people's phones. I can directly send ANY amount of money quickly from my bank to another person's Venmo account.
Comparing that with ETH and Bitcoin, Venmo wins all around. I can send money to someone for free instantly in dollars and the only fee paid is optional depending on when you want it.
Both Bitcoin and Ethereum are subject to demand. If the blockchains have a lot of people trying to process transactions fee’s go up, and the time that it takes to receive your crypto takes longer. When Ethereum gets bad, people have reported spending several thousand of dollars on just 1 transaction.
These transactions take place via “miners” bundling and confirming transactions, then recording them on the blockchain to confirm that the transaction did indeed happen. They charge fees to do this and are also paid in Bitcoin/ETH. When a transaction is confirmed, it's then sent to the other users wallet. This within itself is subject to lots of controversy because each transaction needs to be confirmed 6 times, this takes massive amounts of power, and most of the power is wasted because this is an adversarial system in which the person that mines the transaction gets paid, and everyone else is out of luck. Also, these could theoretically be subject to a “51% attack” in which anyone with over 51% of the mining hash rate could effectively control all of the transactions, and reverse transactions while keeping the BTC resulting in “double spending”.
There are tons of other issues with this, but essentially it means: They rely on these third parties to confirm the transactions. Without people confirming these transactions, Bitcoin stalls completely, and if anyone becomes too dominant they can effectively control bitcoin.
Not to mention, these transactions are in Bitcoin and ETH, not dollars. So, you need to convert them to dollars still, and that's several more transactions, and likely to take several days anyway as the centralized exchange needs to send you the money by traditional methods.
They are not distributed
That takes me to the following point. This isn’t decentralized, at all. Bitcoin is the closest it gets because Satoshi basically closed it to new upgrades, although its still subject to:
Whales
Miners
It’s vital to realize that these are often the same folks. While whales aren’t centralized entities typically, they can considerably effect the price and outcome of Bitcoin. If the largest wallets holding as much as 1 million BTC were to sell, it’d effectively collapse the price perhaps beyond repair. However, Bitcoin can and is pretty much controlled by the miners. Further, Bitcoin is more like an oligarchy than decentralized. It’s been effectively used to make the rich richer, and both the mining and price is impacted by the rich. The overwhelming minority of those actually using it are retail investors. The retail investors are basically never the ones generating money from it either.
As far as ETH and other cryptos go, there is realistically 0 case for them being decentralized. Vitalik could not only kill it but even walking away from it would likely lead to a significant decline. It has tons of issues right now that Vitalik has promised to fix with the eventual Ethereum 2.0., and stepping away from it wouldn’t help.
Most tokens as well are generally tied to some promise of future developments and creators. The same is true for most NFT projects. The reason 99% of crypto and NFT projects fail is because they failed to deliver on various promises or bad dev teams, or poor innovation, or the founders just straight up stole from everyone. I could go more in-depth than this but go find any project and if there is a dev team, company, or person tied to it then it's likely, not decentralized. The success of that project is directly tied to the dev team, and if they wanted to, most hold large wallets and could sell it all off effectively killing the project. Not to mention, any crypto project that doesn’t have a locked contract can 100% be completely rugged and they can run off with all of the money.
Decentralization is undesirable
Even if they were decentralized then it would not be a good thing. The graphic above indicates this is effectively a rich person’s unregulated playground… so it’s exactly like… the very issue it tried to solve?
Not to mention, it’s supposedly meant to prevent things like 2008, but is regularly subjected to 50–90% drawdowns in value? Back when Bitcoin was only known in niche parts of the dark web and illegal markets, it would regularly drop as much as 90% and has a long history of massive drawdowns.
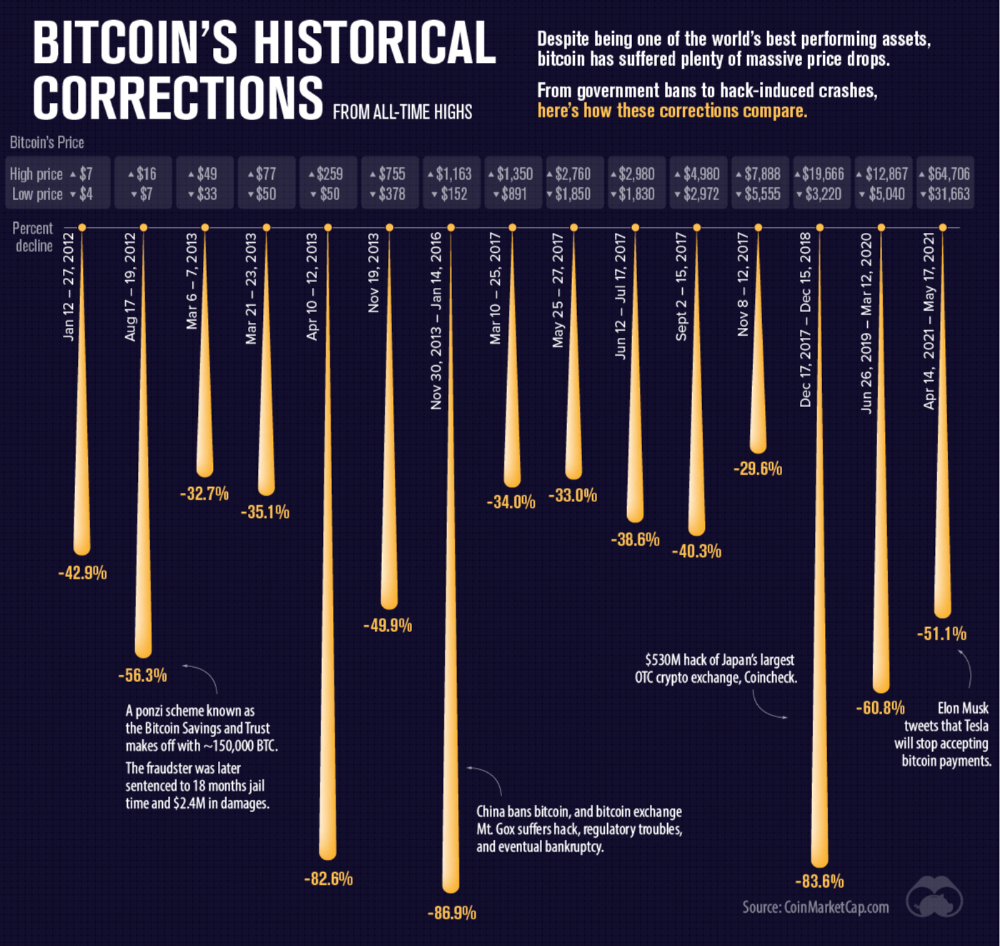
The majority of crypto is blatant scams, and ALL of crypto is a “zero” or “negative” sum game in that it relies on the next person buying for people to make money. This is not a good thing. This has yet to solve any issues around what caused the 2008 crisis. Rather, it seemingly amplified all of the bad parts of it actually. Crypto is the ultimate speculative asset and realistically has no valuation metric. People invest in Apple because it has revenue and cash on hand. People invest in crypto purely for speculation. The lack of regulation or accountability means this is amplified to the most extreme degree where anything goes: Fraud, deception, pump and dumps, scams, etc. This results in a pure speculative madhouse where, unsurprisingly, only the rich win. Not only that but the deck is massively stacked in against the everyday investor because you can’t do a pump and dump without money.
At the heart of all of this is still the same issues: greed and human nature. However, in setting out to solve the issues that allowed 2008 to happen, they made something that literally took all of the bad parts of 2008 and then amplified it. 2008, similarly, was due to greed and human nature but was allowed to happen due to lack of oversite, rich people's excessive leverage over the poor, and excessive speculation. Crypto trades SOLELY on human emotion, has 0 oversite, is pure speculation, and the power dynamic is just as bad or worse.
Why should each individual be their own bank?
This is the last one, and it's short and basic. Why do we want people functioning as their own bank? Everything we do relies on another person. Without the internet, and internet providers there is no crypto. We don’t have people functioning as their own home and car manufacturers or internet service providers. Sure, you might specialize in some of these things, but masquerading as your own bank is a horrible idea.
I am not in the banking industry so I don’t know all the issues with banking. Most people aren’t in banking or crypto, so they don’t know the ENDLESS scams associated with it, and they are bound to lose their money eventually.
If you appreciate this article and want to read more from me and authors like me, without any limits, consider buying me a coffee: buymeacoffee.com/calebnaysmith

Ryan Weeks
3 years ago
Terra fiasco raises TRON's stablecoin backstop
After Terra's algorithmic stablecoin collapsed in May, TRON announced a plan to increase the capital backing its own stablecoin.
USDD, a near-carbon copy of Terra's UST, arrived on the TRON blockchain on May 5. TRON founder Justin Sun says USDD will be overcollateralized after initially being pegged algorithmically to the US dollar.
A reserve of cryptocurrencies and stablecoins will be kept at 130 percent of total USDD issuance, he said. TRON described the collateral ratio as "guaranteed" and said it would begin publishing real-time updates on June 5.
Currently, the reserve contains 14,040 bitcoin (around $418 million), 140 million USDT, 1.9 billion TRX, and 8.29 billion TRX in a burning contract.
Sun: "We want to hybridize USDD." We have an algorithmic stablecoin and TRON DAO Reserve.
algorithmic failure
USDD was designed to incentivize arbitrageurs to keep its price pegged to the US dollar by trading TRX, TRON's token, and USDD. Like Terra, TRON signaled its intent to establish a bitcoin and cryptocurrency reserve to support USDD in extreme market conditions.
Still, Terra's UST failed despite these safeguards. The stablecoin veered sharply away from its dollar peg in mid-May, bringing down Terra's LUNA and wiping out $40 billion in value in days. In a frantic attempt to restore the peg, billions of dollars in bitcoin were sold and unprecedented volumes of LUNA were issued.
Sun believes USDD, which has a total circulating supply of $667 million, can be backed up.
"Our reserve backing is diversified." Bitcoin and stablecoins are included. USDC will be a small part of Circle's reserve, he said.
TRON's news release lists the reserve's assets as bitcoin, TRX, USDC, USDT, TUSD, and USDJ.
All Bitcoin addresses will be signed so everyone knows they belong to us, Sun said.
Not giving in
Sun told that the crypto industry needs "decentralized" stablecoins that regulators can't touch.
Sun said the Luna Foundation Guard, a Singapore-based non-profit that raised billions in cryptocurrency to buttress UST, mismanaged the situation by trying to sell to panicked investors.
He said, "We must be ahead of the market." We want to stabilize the market and reduce volatility.
Currently, TRON finances most of its reserve directly, but Sun says the company hopes to add external capital soon.
Before its demise, UST holders could park the stablecoin in Terra's lending platform Anchor Protocol to earn 20% interest, which many deemed unsustainable. TRON's JustLend is similar. Sun hopes to raise annual interest rates from 17.67% to "around 30%."
This post is a summary. Read full article here
Gill Pratt
3 years ago
War's Human Cost
War's Human Cost
I didn't start crying until I was outside a McDonald's in an Olempin, Poland rest area on highway S17.
Children pick toys at a refugee center, Olempin, Poland, March 4, 2022.
Refugee children, mostly alone with their mothers, but occasionally with a gray-haired grandfather or non-Ukrainian father, were coaxed into picking a toy from boxes provided by a kind-hearted company and volunteers.
I went to Warsaw to continue my research on my family's history during the Holocaust. In light of the ongoing Ukrainian conflict, I asked former colleagues in the US Department of Defense and Intelligence Community if it was safe to travel there. They said yes, as Poland was a NATO member.
I stayed in a hotel in the Warsaw Ghetto, where 90% of my mother's family was murdered in the Holocaust. Across the street was the first Warsaw Judenrat. It was two blocks away from the apartment building my mother's family had owned and lived in, now dilapidated and empty.
Building of my great-grandfather, December 2021.
A mass grave of thousands of rocks for those killed in the Warsaw Ghetto, I didn't cry when I touched its cold walls.
Warsaw Jewish Cemetery, 200,000–300,000 graves.
Mass grave, Warsaw Jewish Cemetery.
My mother's family had two homes, one in Warszawa and the rural one was a forest and sawmill complex in Western Ukraine. For the past half-year, a local Ukrainian historian had been helping me discover faint traces of her family’s life there — in fact, he had found some people still alive who remembered the sawmill and that it belonged to my mother’s grandfather. The historian was good at his job, and we had become close.
My historian friend, December 2021, talking to a Ukrainian.
With war raging, my second trip to Warsaw took on a different mission. To see his daughter and one-year-old grandson, I drove east instead of to Ukraine. They had crossed the border shortly after the war began, leaving men behind, and were now staying with a friend on Poland's eastern border.
I entered after walking up to the house and settling with the dog. The grandson greeted me with a huge smile and the Ukrainian word for “daddy,” “Tato!” But it was clear he was awaiting his real father's arrival, and any man he met would be so tentatively named.
After a few moments, the boy realized I was only a stranger. He had musical talent, like his mother and grandfather, both piano teachers, as he danced to YouTube videos of American children's songs dubbed in Ukrainian, picking the ones he liked and crying when he didn't.
Songs chosen by my historian friend's grandson, March 4, 2022
He had enough music and began crying regardless of the song. His mother picked him up and started nursing him, saying she was worried about him. She had no idea where she would live or how she would survive outside Ukraine. She showed me her father's family history of losses in the Holocaust, which matched my own research.
After an hour of drinking tea and trying to speak of hope, I left for the 3.5-hour drive west to Warsaw.
It was unlike my drive east. It was reminiscent of the household goods-filled carts pulled by horses and people fleeing war 80 years ago.
Jewish refugees relocating, USHMM Holocaust Encyclopaedia, 1939.
The carefully chosen trinkets by children to distract them from awareness of what is really happening and the anxiety of what lies ahead, made me cry despite all my research on the Holocaust. There is no way for them to communicate with their mothers, who are worried, absent, and without their fathers.
It's easy to see war as a contest of nations' armies, weapons, and land. The most costly aspect of war is its psychological toll. My father screamed in his sleep from nightmares of his own adolescent trauma in Warsaw 80 years ago.
Survivor father studying engineering, 1961.
In the airport, I waited to return home while Ukrainian public address systems announced refugee assistance. Like at McDonald's, many mothers were alone with their children, waiting for a flight to distant relatives.
That's when I had my worst trip experience.
A woman near me, clearly a refugee, answered her phone, cried out, and began wailing.
The human cost of war descended like a hammer, and I realized that while I was going home, she never would