



More on Productivity

Leonardo Castorina
3 years ago
How to Use Obsidian to Boost Research Productivity
Tools for managing your PhD projects, reading lists, notes, and inspiration.
As a researcher, you have to know everything. But knowledge is useless if it cannot be accessed quickly. An easy-to-use method of archiving information makes taking notes effortless and enjoyable.
As a PhD student in Artificial Intelligence, I use Obsidian (https://obsidian.md) to manage my knowledge.
The article has three parts:
- What is a note, how to organize notes, tags, folders, and links? This section is tool-agnostic, so you can use most of these ideas with any note-taking app.
- Instructions for using Obsidian, managing notes, reading lists, and useful plugins. This section demonstrates how I use Obsidian, my preferred knowledge management tool.
- Workflows: How to use Zotero to take notes from papers, manage multiple projects' notes, create MOCs with Dataview, and more. This section explains how to use Obsidian to solve common scientific problems and manage/maintain your knowledge effectively.
This list is not perfect or complete, but it is my current solution to problems I've encountered during my PhD. Please leave additional comments or contact me if you have any feedback. I'll try to update this article.
Throughout the article, I'll refer to your digital library as your "Obsidian Vault" or "Zettelkasten".
Other useful resources are listed at the end of the article.
1. Philosophy: Taking and organizing notes
Carl Sagan: “To make an apple pie from scratch, you must first create the universe.”
Before diving into Obsidian, let's establish a Personal Knowledge Management System and a Zettelkasten. You can skip to Section 2 if you already know these terms.
Niklas Luhmann, a prolific sociologist who wrote 400 papers and 70 books, inspired this section and much of Zettelkasten. Zettelkasten means “slip box” (or library in this article). His Zettlekasten had around 90000 physical notes, which can be found here.
There are now many tools available to help with this process. Obsidian's website has a good introduction section: https://publish.obsidian.md/hub/
Notes
We'll start with "What is a note?" Although it may seem trivial, the answer depends on the topic or your note-taking style. The idea is that a note is as “atomic” (i.e. You should read the note and get the idea right away.
The resolution of your notes depends on their detail. Deep Learning, for example, could be a general description of Neural Networks, with a few notes on the various architectures (eg. Recurrent Neural Networks, Convolutional Neural Networks etc..).
Limiting length and detail is a good rule of thumb. If you need more detail in a specific section of this note, break it up into smaller notes. Deep Learning now has three notes:
- Deep Learning
- Recurrent Neural Networks
- Convolutional Neural Networks
Repeat this step as needed until you achieve the desired granularity. You might want to put these notes in a “Neural Networks” folder because they are all about the same thing. But there's a better way:
#Tags and [[Links]] over /Folders/
The main issue with folders is that they are not flexible and assume that all notes in the folder belong to a single category. This makes it difficult to make connections between topics.
Deep Learning has been used to predict protein structure (AlphaFold) and classify images (ImageNet). Imagine a folder structure like this:
- /Proteins/
- Protein Folding
- /Deep Learning/
- /Proteins/
Your notes about Protein Folding and Convolutional Neural Networks will be separate, and you won't be able to find them in the same folder.
This can be solved in several ways. The most common one is to use tags rather than folders. A note can be grouped with multiple topics this way. Obsidian tags can also be nested (have subtags).
You can also link two notes together. You can build your “Knowledge Graph” in Obsidian and other note-taking apps like Obsidian.
My Knowledge Graph. Green: Biology, Red: Machine Learning, Yellow: Autoencoders, Blue: Graphs, Brown: Tags.
My Knowledge Graph and the note “Backrpropagation” and its links.
Backpropagation note and all its links
Why use Folders?
Folders help organize your vault as it grows. The main suggestion is to have few folders that "weakly" collect groups of notes or better yet, notes from different sources.
Among my Zettelkasten folders are:
My Zettelkasten's 5 folders
They usually gather data from various sources:
MOC: Map of Contents for the Zettelkasten.
Projects: Contains one note for each side-project of my PhD where I log my progress and ideas. Notes are linked to these.
Bio and ML: These two are the main content of my Zettelkasten and could theoretically be combined.
Papers: All my scientific paper notes go here. A bibliography links the notes. Zotero .bib file
Books: I make a note for each book I read, which I then split into multiple notes.
Keeping images separate from other files can help keep your main folders clean.
I will elaborate on these in the Workflow Section.
My general recommendation is to use tags and links instead of folders.
Maps of Content (MOC)
Making Tables of Contents is a good solution (MOCs).
These are notes that "signposts" your Zettelkasten library, directing you to the right type of notes. It can link to other notes based on common tags. This is usually done with a title, then your notes related to that title. As an example:
An example of a Machine Learning MOC generated with Dataview.
As shown above, my Machine Learning MOC begins with the basics. Then it's on to Variational Auto-Encoders. Not only does this save time, but it also saves scrolling through the tag search section.
So I keep MOCs at the top of my library so I can quickly find information and see my library. These MOCs are generated automatically using an Obsidian Plugin called Dataview (https://github.com/blacksmithgu/obsidian-dataview).
Ideally, MOCs could be expanded to include more information about the notes, their status, and what's left to do. In the absence of this, Dataview does a fantastic job at creating a good structure for your notes.
In the absence of this, Dataview does a fantastic job at creating a good structure for your notes.
2. Tools: Knowing Obsidian
Obsidian is my preferred tool because it is free, all notes are stored in Markdown format, and each panel can be dragged and dropped. You can get it here: https://obsidian.md/
Obsidian interface.
Obsidian is highly customizable, so here is my preferred interface:
The theme is customized from https://github.com/colineckert/obsidian-things
Alternatively, each panel can be collapsed, moved, or removed as desired. To open a panel later, click on the vertical "..." (bottom left of the note panel).
My interface is organized as follows:
How my Obsidian Interface is organized.
Folders/Search:
This is where I keep all relevant folders. I usually use the MOC note to navigate, but sometimes I use the search button to find a note.
Tags:
I use nested tags and look into each one to find specific notes to link.
cMenu:
Easy-to-use menu plugin cMenu (https://github.com/chetachiezikeuzor/cMenu-Plugin)
Global Graph:
The global graph shows all your notes (linked and unlinked). Linked notes will appear closer together. Zoom in to read each note's title. It's a bit overwhelming at first, but as your library grows, you get used to the positions and start thinking of new connections between notes.
Local Graph:
Your current note will be shown in relation to other linked notes in your library. When needed, you can quickly jump to another link and back to the current note.
Links:
Finally, an outline panel and the plugin Obsidian Power Search (https://github.com/aviral-batra/obsidian-power-search) allow me to search my vault by highlighting text.
Start using the tool and worry about panel positioning later. I encourage you to find the best use-case for your library.
Plugins
An additional benefit of using Obsidian is the large plugin library. I use several (Calendar, Citations, Dataview, Templater, Admonition):
Obsidian Calendar Plugin: https://github.com/liamcain
It organizes your notes on a calendar. This is ideal for meeting notes or keeping a journal.
Calendar addon from hans/obsidian-citation-plugin
Obsidian Citation Plugin: https://github.com/hans/
Allows you to cite papers from a.bib file. You can also customize your notes (eg. Title, Authors, Abstract etc..)
Plugin citation from hans/obsidian-citation-plugin
Obsidian Dataview: https://github.com/blacksmithgu/
A powerful plugin that allows you to query your library as a database and generate content automatically. See the MOC section for an example.
Allows you to create notes with specific templates like dates, tags, and headings.
Templater. Obsidian Admonition: https://github.com/valentine195/obsidian-admonition
Blocks allow you to organize your notes.
Plugin warning. Obsidian Admonition (valentine195)
There are many more, but this list should get you started.
3. Workflows: Cool stuff
Here are a few of my workflows for using obsidian for scientific research. This is a list of resources I've found useful for my use-cases. I'll outline and describe them briefly so you can skim them quickly.
3.1 Using Templates to Structure Notes
3.2 Free Note Syncing (Laptop, Phone, Tablet)
3.3 Zotero/Mendeley/JabRef -> Obsidian — Managing Reading Lists
3.4 Projects and Lab Books
3.5 Private Encrypted Diary
3.1 Using Templates to Structure Notes
Plugins: Templater and Dataview (optional).
To take effective notes, you must first make adding new notes as easy as possible. Templates can save you time and give your notes a consistent structure. As an example:
An example of a note using a template.
### [[YOUR MOC]]
# Note Title of your note
**Tags**::
**Links**::
The top line links to your knowledge base's Map of Content (MOC) (see previous sections). After the title, I add tags (and a link between the note and the tag) and links to related notes.
To quickly identify all notes that need to be expanded, I add the tag “#todo”. In the “TODO:” section, I list the tasks within the note.
The rest are notes on the topic.
Templater can help you create these templates. For new books, I use the following template:
### [[Books MOC]]
# Title
**Author**::
**Date::
**Tags::
**Links::
A book template example.
Using a simple query, I can hook Dataview to it.
dataview
table author as Author, date as “Date Finished”, tags as “Tags”, grade as “Grade”
from “4. Books”
SORT grade DESCENDING
using Dataview to query templates.
3.2 Free Note Syncing (Laptop, Phone, Tablet)
No plugins used.
One of my favorite features of Obsidian is the library's self-contained and portable format. Your folder contains everything (plugins included).
Ordinary folders and documents are available as well. There is also a “.obsidian” folder. This contains all your plugins and settings, so you can use it on other devices.
So you can use Google Drive, iCloud, or Dropbox for free as long as you sync your folder (note: your folder should be in your Cloud Folder).
For my iOS and macOS work, I prefer iCloud. You can also use the paid service Obsidian Sync.
3.3 Obsidian — Managing Reading Lists and Notes in Zotero/Mendeley/JabRef
Plugins: Quotes (required).
3.3 Zotero/Mendeley/JabRef -> Obsidian — Taking Notes and Managing Reading Lists of Scientific Papers
My preferred reference manager is Zotero, but this workflow should work with any reference manager that produces a .bib file. This file is exported to my cloud folder so I can access it from any platform.
My Zotero library is tagged as follows:
My reference manager's tags
For readings, I usually search for the tags “!!!” and “To-Read” and select a paper. Annotate the paper next (either on PDF using GoodNotes or on physical paper).
Then I make a paper page using a template in the Citations plugin settings:
An example of my citations template.
Create a new note, open the command list with CMD/CTRL + P, and find the Citations “Insert literature note content in the current pane” to see this lovely view.
Citation generated by the article https://doi.org/10.1101/2022.01.24.22269144
You can then convert your notes to digital. I found that transcribing helped me retain information better.
3.4 Projects and Lab Books
Plugins: Tweaker (required).
PhD students offering advice on thesis writing are common (read as regret). I started asking them what they would have done differently or earlier.
“Deep stuff Leo,” one person said. So my main issue is basic organization, losing track of my tasks and the reasons for them.
As a result, I'd go on other experiments that didn't make sense, and have to reverse engineer my logic for thesis writing. - PhD student now wise Postdoc
Time management requires planning. Keeping track of multiple projects and lab books is difficult during a PhD. How I deal with it:
- One folder for all my projects
- One file for each project
I use a template to create each project
### [[Projects MOC]]
# <% tp.file.title %>
**Tags**::
**Links**::
**URL**::
**Project Description**::## Notes:
### <% tp.file.last_modified_date(“dddd Do MMMM YYYY”) %>
#### Done:
#### TODO:
#### Notes
You can insert a template into a new note with CMD + P and looking for the Templater option.
I then keep adding new days with another template:
### <% tp.file.last_modified_date("dddd Do MMMM YYYY") %>
#### Done:
#### TODO:
#### Notes:
This way you can keep adding days to your project and update with reasonings and things you still have to do and have done. An example below:
Example of project note with timestamped notes.
3.5 Private Encrypted Diary
This is one of my favorite Obsidian uses.
Mini Diary's interface has long frustrated me. After the author archived the project, I looked for a replacement. I had two demands:
- It had to be private, and nobody had to be able to read the entries.
- Cloud syncing was required for editing on multiple devices.
Then I learned about encrypting the Obsidian folder. Then decrypt and open the folder with Obsidian. Sync the folder as usual.
Use CryptoMator (https://cryptomator.org/). Create an encrypted folder in Cryptomator for your Obsidian vault, set a password, and let it do the rest.
If you need a step-by-step video guide, here it is:
Conclusion
So, I hope this was helpful!
In the first section of the article, we discussed notes and note-taking techniques. We discussed when to use tags and links over folders and when to break up larger notes.
Then we learned about Obsidian, its interface, and some useful plugins like Citations for citing papers and Templater for creating note templates.
Finally, we discussed workflows and how to use Zotero to take notes from scientific papers, as well as managing Lab Books and Private Encrypted Diaries.
Thanks for reading and commenting :)
Read original post here

Asher Umerie
3 years ago
What is Bionic Reading?
Senses help us navigate a complicated world. They shape our worldview - how we hear, smell, feel, and taste. People claim a sixth sense, an intuitive capacity that extends perception.
Our brain is a half-pool of grey and white matter that stores data from our senses. Brains provide us context, so zombies' obsession makes sense.
Bionic reading uses the brain's visual information and context to simplify text comprehension.
Stay with me.
What is Bionic Reading?
Bionic reading is a software application established by Swiss typographic designer Renato Casutt. The term honors the brain (bio) and technology's collaboration to better text comprehension.
The image above shows two similar paragraphs with bionic reading.
Notice anything yet?
This Twitter user did.
I did too...
Image text describes bionic reading-
New method to aid reading by using artificial fixation points. The reader focuses on the highlighted starting letters, and the brain completes the word.
How is Bionic Reading possible?
Do you remember seeing social media posts asking you to stare at a black dot for 30 seconds (or more)? You blink and see an after-image on your wall.
Our brains are skilled at identifying patterns and'seeing' familiar objects, therefore optical illusions are conceivable.
Brain and sight collaborate well. Text comprehension proves it.
Considering evolutionary patterns, humans' understanding skills may be cosmic luck.
Scientists don't know why people can read and write, but they do know what reading does to the brain.
One portion of your brain recognizes words, while another analyzes their meaning. Fixation, saccade, and linguistic transparency/opacity aid.
Let's explain some terms.
-
Fixation is how the eyes move when reading. It's where you look. If the eyes fixate less, a reader can read quicker. [Eye fixation is a physiological process](Eye fixation is a naturally occurring physiological process) impacted by the reader's vocabulary, vision span, and text familiarity.
-
Saccade - Pause and look around. That's a saccade. Rapid eye movements that alter the place of fixation, as reading text or looking around a room. They can happen willingly (when you choose) or instinctively, even when your eyes are fixed.
-
Linguistic transparency and opacity analyze how well a composite word or phrase may be deduced from its constituents.
The Bionic reading website compares these tools.
Text highlights lead the eye. Fixation, saccade, and opacity can transfer visual stimuli to text, changing typeface.
## Final Thoughts on Bionic Reading
I'm excited about how this could influence my long-term assimilation and productivity.
This technology is still in development, with prototypes working on only a few apps. Like any new tech, it will be criticized.
I'll be watching Bionic Reading closely. Comment on it!

Alex Mathers
3 years ago
8 guidelines to help you achieve your objectives 5x fast

If you waste time every day, even though you're ambitious, you're not alone.
Many of us could use some new time-management strategies, like these:
Focus on the following three.
You're thinking about everything at once.
You're overpowered.
It's mental. We just have what's in front of us. So savor the moment's beauty.
Prioritize 1-3 things.
To be one of the most productive people you and I know, follow these steps.
Get along with boredom.
Many of us grow bored, sweat, and turn on Netflix.
We shout, "I'm rarely bored!" Look at me! I'm happy.
Shut it, Sally.
You're not making wonderful things for the world. Boredom matters.
If you can sit with it for a second, you'll get insight. Boredom? Breathe.
Go blank.
Then watch your creativity grow.
Check your MacroVision once more.
We don't know what to do with our time, which contributes to time-wasting.
Nobody does, either. Jeff Bezos won't hand-deliver that crap to you.
Daily vision checks are required.
Also:
What are 5 things you'd love to create in the next 5 years?
You're soul-searching. It's food.
Return here regularly, and you'll adore the high you get from doing valuable work.
Improve your thinking.
What's Alex's latest nonsense?
I'm talking about overcoming our own thoughts. Worrying wastes so much time.
Too many of us are assaulted by lies, myths, and insecurity.
Stop letting your worries massage you into a worried coma like a Thai woman.
Optimizing your thoughts requires accepting what you can't control.
It means letting go of unhelpful thoughts and returning to the moment.
Keep your blood sugar level.
I gave up gluten, donuts, and sweets.
This has really boosted my energy.
Blood-sugar-spiking carbs make us irritable and tired.
These day-to-day ups and downs aren't productive. It's crucial.
Know how your diet affects insulin levels. Now I have more energy and can do more without clenching my teeth.
Reduce harmful carbs to boost energy.
Create a focused setting for yourself.
When we optimize the mind, we have more energy and use our time better because we're not tense.
Changing our environment can also help us focus. Disabling alerts is one example.
Too hot makes me procrastinate and irritable.
List five items that hinder your productivity.
You may be amazed at how much you may improve by removing distractions.
Be responsible.
Accountability is a time-saver.
Creating an emotional pull to finish things.
Writing down our goals makes us accountable.
We can engage a coach or work with an accountability partner to feel horrible if we don't show up and finish on time.
‘Hey Jake, I’m going to write 1000 words every day for 30 days — you need to make sure I do.’ ‘Sure thing, Nathan, I’ll be making sure you check in daily with me.’
Tick.
You might also blog about your ambitions to show your dedication.
Now you can't hide when you promised to appear.
Acquire a liking for bravery.
Boldness changes everything.
I sometimes feel lazy and wonder why. If my food and sleep are in order, I should assess my footing.
Most of us live backward. Doubtful. Uncertain. Feelings govern us.
Backfooting isn't living. It's lame, and you'll soon melt. Live boldly now.
Be assertive.
Get disgustingly into everything. Expand.
Even if it's hard, stop being a b*tch.
Those that make Mr. Bold Bear their spirit animal benefit. Save time to maximize your effect.
You might also like

Quant Galore
3 years ago
I created BAW-IV Trading because I was short on money.
More retail traders means faster, more sophisticated, and more successful methods.
Tech specifications
Only requires a laptop and an internet connection.
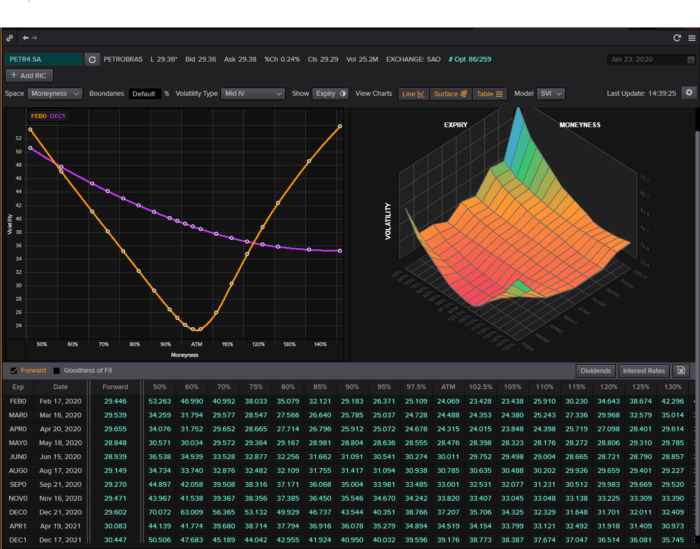
We'll use OpenBB's research platform for data/analysis.
Pricing and execution on Options-Quant

Background
You don't need to know the arithmetic details to use this method.
Black-Scholes is a popular option pricing model. It's best for pricing European options. European options are only exercisable at expiration, unlike American options. American options are always exercisable.
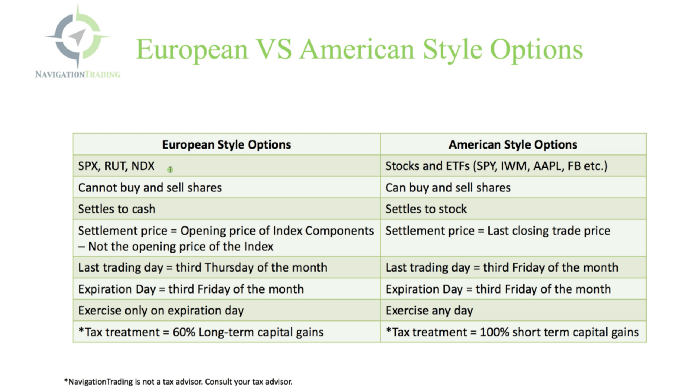
American options carry a premium to cover for the risk of early exercise. The Black-Scholes model doesn't account for this premium, hence it can't price genuine, traded American options.
Barone-Adesi-Whaley (BAW) model. BAW modifies Black-Scholes. It accounts for exercise risk premium and stock dividends. It adds the option's early exercise value to the Black-Scholes value.
The trader need not know the formulaic derivations of this model.
https://ir.nctu.edu.tw/bitstream/11536/14182/1/000264318900005.pdf
Strategy
This strategy targets implied volatility. First, we'll locate liquid options that expire within 30 days and have minimal implied volatility.
After selecting the option that meets the requirements, we price it to get the BAW implied volatility (we choose BAW because it's a more accurate Black-Scholes model). If estimated implied volatility is larger than market volatility, we'll capture the spread.
(Calculated IV — Market IV) = (Profit)
Some approaches to target implied volatility are pricey and inaccessible to individual investors. The best and most cost-effective alternative is to acquire a straddle and delta hedge. This may sound terrifying and pricey, but as shown below, it's much less so.
The Trade
First, we want to find our ideal option, so we use OpenBB terminal to screen for options that:
Have an IV at least 5% lower than the 20-day historical IV
Are no more than 5% out-of-the-money
Expire in less than 30 days
We query:
stocks/options/screen/set low_IV/scr --export Output.csv
This uses the screener function to screen for options that satisfy the above criteria, which we specify in the low IV preset (more on custom presets here). It then saves the matching results to a csv(Excel) file for viewing and analysis.
Stick to liquid names like SPY, AAPL, and QQQ since getting out of a position is just as crucial as getting in. Smaller, illiquid names have higher inefficiencies, which could restrict total profits.

We calculate IV using the BAWbisection model (the bisection is a method of calculating IV, more can be found here.) We price the IV first.

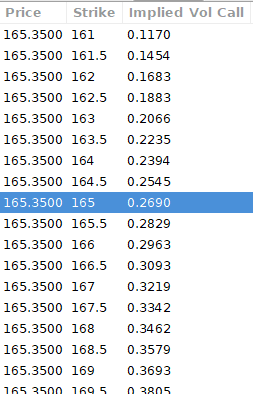
According to the BAW model, implied volatility at this level should be priced at 26.90%. When re-pricing the put, IV is 24.34%, up 3%.
Now it's evident. We must purchase the straddle (long the call and long the put) assuming the computed implied volatility is more appropriate and efficient than the market's. We just want to speculate on volatility, not price fluctuations, thus we delta hedge.
The Fun Starts
We buy both options for $7.65. (x100 multiplier). Initial delta is 2. For every dollar the stock price swings up or down, our position value moves $2.

We want delta to be 0 to avoid price vulnerability. A delta of 0 suggests our position's value won't change from underlying price changes. Being delta-hedged allows us to profit/lose from implied volatility. Shorting 2 shares makes us delta-neutral.

That's delta hedging. (Share price * shares traded) = $330.7 to become delta-neutral. You may have noted that delta is not truly 0.00. This is common since delta-hedging means getting as near to 0 as feasible, since it is rare for deltas to align at 0.00.
Now we're vulnerable to changes in Vega (and Gamma, but given we're dynamically hedging, it's not a big risk), or implied volatility. We wanted to gamble that the position's IV would climb by at least 2%, so we'll maintain it delta-hedged and watch IV.
Because the underlying moves continually, the option's delta moves continuously. A trader can short/long 5 AAPL shares at most. Paper trading lets you practice delta-hedging. Being quick-footed will help with this tactic.
Profit-Closing
As expected, implied volatility rose. By 10 minutes before market closure, the call's implied vol rose to 27% and the put's to 24%. This allowed us to sell the call for $4.95 and the put for $4.35, creating a profit of $165.

You may pull historical data to see how this trade performed. Note the implied volatility and pricing in the final options chain for August 5, 2022 (the position date).

Final Thoughts
Congratulations, that was a doozy. To reiterate, we identified tickers prone to increased implied volatility by screening OpenBB's low IV setting. We double-checked the IV by plugging the price into Options-BAW Quant's model. When volatility was off, we bought a straddle and delta-hedged it. Finally, implied volatility returned to a normal level, and we profited on the spread.
The retail trading space is very quickly catching up to that of institutions. Commissions and fees used to kill this method, but now they cost less than $5. Watching momentum, technical analysis, and now quantitative strategies evolve is intriguing.
I'm not linked with these sites and receive no financial benefit from my writing.
Tell me how your experience goes and how I helped; I love success tales.

The woman
3 years ago
The renowned and highest-paid Google software engineer
His story will inspire you.

“Google search went down for a few hours in 2002; Jeff Dean handled all the queries by hand and checked quality doubled.”- Jeff Dean Facts.
One of many Jeff Dean jokes, but you get the idea.
Google's top six engineers met in a war room in mid-2000. Google's crawling system, which indexed the Web, stopped working. Users could still enter queries, but results were five months old.
Google just signed a deal with Yahoo to power a ten-times-larger search engine. Tension rose. It was crucial. If they failed, the Yahoo agreement would likely fall through, risking bankruptcy for the firm. Their efforts could be lost.
A rangy, tall, energetic thirty-one-year-old man named Jeff dean was among those six brilliant engineers in the makeshift room. He had just left D. E. C. a couple of months ago and started his career in a relatively new firm Google, which was about to change the world. He rolled his chair over his colleague Sanjay and sat right next to him, cajoling his code like a movie director. The history started from there.
When you think of people who shaped the World Wide Web, you probably picture founders and CEOs like Larry Page and Sergey Brin, Marc Andreesen, Tim Berners-Lee, Bill Gates, and Mark Zuckerberg. They’re undoubtedly the brightest people on earth.
Under these giants, legions of anonymous coders work at keyboards to create the systems and products we use. These computer workers are irreplaceable.
Let's get to know him better.
It's possible you've never heard of Jeff Dean. He's American. Dean created many behind-the-scenes Google products. Jeff, co-founder and head of Google's deep learning research engineering team, is a popular technology, innovation, and AI keynote speaker.
While earning an MS and Ph.D. in computer science at the University of Washington, he was a teaching assistant, instructor, and research assistant. Dean joined the Compaq Computer Corporation Western Research Laboratory research team after graduating.
Jeff co-created ProfileMe and the Continuous Profiling Infrastructure for Digital at Compaq. He co-designed and implemented Swift, one of the fastest Java implementations. He was a senior technical staff member at mySimon Inc., retrieving and caching electronic commerce content.
Dean, a top young computer scientist, joined Google in mid-1999. He was always trying to maximize a computer's potential as a child.
An expert
His high school program for processing massive epidemiological data was 26 times faster than professionals'. Epi Info, in 13 languages, is used by the CDC. He worked on compilers as a computer science Ph.D. These apps make source code computer-readable.
Dean never wanted to work on compilers forever. He left Academia for Google, which had less than 20 employees. Dean helped found Google News and AdSense, which transformed the internet economy. He then addressed Google's biggest issue, scaling.
Growing Google faced a huge computing challenge. They developed PageRank in the late 1990s to return the most relevant search results. Google's popularity slowed machine deployment.
Dean solved problems, his specialty. He and fellow great programmer Sanjay Ghemawat created the Google File System, which distributed large data over thousands of cheap machines.
These two also created MapReduce, which let programmers handle massive data quantities on parallel machines. They could also add calculations to the search algorithm. A 2004 research article explained MapReduce, which became an industry sensation.
Several revolutionary inventions
Dean's other initiatives were also game-changers. BigTable, a petabyte-capable distributed data storage system, was based on Google File. The first global database, Spanner, stores data on millions of servers in dozens of data centers worldwide.
It underpins Gmail and AdWords. Google Translate co-founder Jeff Dean is surprising. He contributes heavily to Google News. Dean is Senior Fellow of Google Research and Health and leads Google AI.
Recognitions
The National Academy of Engineering elected Dean in 2009. He received the 2009 Association for Computing Machinery fellowship and the 2016 American Academy of Arts and Science fellowship. He received the 2007 ACM-SIGOPS Mark Weiser Award and the 2012 ACM-Infosys Foundation Award. Lists could continue.
A sneaky question may arrive in your mind: How much does this big brain earn? Well, most believe he is one of the highest-paid employees at Google. According to a survey, he is paid $3 million a year.
He makes espresso and chats with a small group of Googlers most mornings. Dean steams milk, another grinds, and another brews espresso. They discuss families and technology while making coffee. He thinks this little collaboration and idea-sharing keeps Google going.
“Some of us have been working together for more than 15 years,” Dean said. “We estimate that we’ve collectively made more than 20,000 cappuccinos together.”
We all know great developers and software engineers. It may inspire many.

Isaac Benson
3 years ago
What's the difference between Proof-of-Time and Proof-of-History?

Blockchain validates transactions with consensus algorithms. Bitcoin and Ethereum use Proof-of-Work, while Polkadot and Cardano use Proof-of-Stake.
Other consensus protocols are used to verify transactions besides these two. This post focuses on Proof-of-Time (PoT), used by Analog, and Proof-of-History (PoH), used by Solana as a hybrid consensus protocol.
PoT and PoH may seem similar to users, but they are actually very different protocols.
Proof-of-Time (PoT)
Analog developed Proof-of-Time (PoT) based on Delegated Proof-of-Stake (DPoS). Users select "delegates" to validate the next block in DPoS. PoT uses a ranking system, and validators stake an equal amount of tokens. Validators also "self-select" themselves via a verifiable random function."
The ranking system gives network validators a performance score, with trustworthy validators with a long history getting higher scores. System also considers validator's fixed stake. PoT's ledger is called "Timechain."
Voting on delegates borrows from DPoS, but there are changes. PoT's first voting stage has validators (or "time electors" putting forward a block to be included in the ledger).
Validators are chosen randomly based on their ranking score and fixed stake. One validator is chosen at a time using a Verifiable Delay Function (VDF).
Validators use a verifiable delay function to determine if they'll propose a Timechain block. If chosen, they validate the transaction and generate a VDF proof before submitting both to other Timechain nodes.
This leads to the second process, where the transaction is passed through 1,000 validators selected using the same method. Each validator checks the transaction to ensure it's valid.
If the transaction passes, validators accept the block, and if over 2/3 accept it, it's added to the Timechain.
Proof-of-History (PoH)
Proof-of-History is a consensus algorithm that proves when a transaction occurred. PoH uses a VDF to verify transactions, like Proof-of-Time. Similar to Proof-of-Work, VDFs use a lot of computing power to calculate but little to verify transactions, similar to (PoW).
This shows users and validators how long a transaction took to verify.
PoH uses VDFs to verify event intervals. This process uses cryptography to prevent determining output from input.
The outputs of one transaction are used as inputs for the next. Timestamps record the inputs' order. This checks if data was created before an event.
PoT vs. PoH
PoT and PoH differ in that:
PoT uses VDFs to select validators (or time electors), while PoH measures time between events.
PoH uses a VDF to validate transactions, while PoT uses a ranking system.
PoT's VDF-elected validators verify transactions proposed by a previous validator. PoH uses a VDF to validate transactions and data.
Conclusion
Both Proof-of-Time (PoT) and Proof-of-History (PoH) validate blockchain transactions differently. PoT uses a ranking system to randomly select validators to verify transactions.
PoH uses a Verifiable Delay Function to validate transactions, verify how much time has passed between two events, and allow validators to quickly verify a transaction without malicious actors knowing the input.