


More on Society & Culture

Isaiah McCall
3 years ago
Is TikTok slowly destroying a new generation?
It's kids' digital crack

TikTok is a destructive social media platform.
The interface shortens attention spans and dopamine receptors.
TikTok shares more data than other apps.
Seeing an endless stream of dancing teens on my glowing box makes me feel like a Blade Runner extra.
TikTok did in one year what MTV, Hollywood, and Warner Music tried to do in 20 years. TikTok has psychotized the two-thirds of society Aldous Huxley said were hypnotizable.
Millions of people, mostly kids, are addicted to learning a new dance, lip-sync, or prank, and those who best dramatize this collective improvisation get likes, comments, and shares.
TikTok is a great app. So what?
The Commercial Magnifying Glass TikTok made me realize my generation's time was up and the teenage Zoomers were the target.
I told my 14-year-old sister, "Enjoy your time under the commercial magnifying glass."
TikTok sells your every move, gesture, and thought. Data is the new oil. If you tell someone, they'll say, "Yeah, they collect data, but who cares? I have nothing to hide."
It's a George Orwell novel's beginning. Look up Big Brother Award winners to see if TikTok won.

TikTok shares your data more than any other social media app, and where it goes is unclear. TikTok uses third-party trackers to monitor your activity after you leave the app.
Consumers can't see what data is shared or how it will be used. — Genius URL
32.5 percent of Tiktok's users are 10 to 19 and 29.5% are 20 to 29.
TikTok is the greatest digital marketing opportunity in history, and they'll use it to sell you things, track you, and control your thoughts. Any of its users will tell you, "I don't care, I just want to be famous."
TikTok manufactures mental illness
TikTok's effect on dopamine and the brain is absurd. Dopamine controls the brain's pleasure and reward centers. It's like a switch that tells your brain "this feels good, repeat."
Dr. Julie Albright, a digital culture and communication sociologist, said TikTok users are "carried away by dopamine." It's hypnotic, you'll keep watching."
TikTok constantly releases dopamine. A guy on TikTok recently said he didn't like books because they were slow and boring.
The US didn't ban Tiktok.
Biden and Trump agree on bad things. Both agree that TikTok threatens national security and children's mental health.
The Chinese Communist Party owns and operates TikTok, but that's not its only problem.
There’s borderline child porn on TikTok
It's unsafe for children and violated COPPA.
It's also Chinese spyware. I'm not a Trump supporter, but I was glad he wanted TikTok regulated and disappointed when he failed.
Full-on internet censorship is rare outside of China, so banning it may be excessive. US should regulate TikTok more.
We must reject a low-quality present for a high-quality future.
TikTok vs YouTube
People got mad when I wrote about YouTube's death.
They didn't like when I said TikTok was YouTube's first real challenger.
Indeed. TikTok is the fastest-growing social network. In three years, the Chinese social media app TikTok has gained over 1 billion active users. In the first quarter of 2020, it had the most downloads of any app in a single quarter.
TikTok is the perfect social media app in many ways. It's brief and direct.

Can you believe they had a YouTube vs TikTok boxing match? We are doomed as a species.
YouTube hosts my favorite videos. That’s why I use it. That’s why you use it. New users expect more. They want something quicker, more addictive.
TikTok's impact on other social media platforms frustrates me. YouTube copied TikTok to compete.
It's all about short, addictive content.
I'll admit I'm probably wrong about TikTok. My friend says his feed is full of videos about food, cute animals, book recommendations, and hot lesbians.
Whatever.
TikTok makes us bad
TikTok is the opposite of what the Ancient Greeks believed about wisdom.
It encourages people to be fake. It's like a never-ending costume party where everyone competes.
It does not mean that Gen Z is doomed.
They could be the saviors of the world for all I know.
TikTok feels like a step towards Mike Judge's "Idiocracy," where the average person is a pleasure-seeking moron.

Hudson Rennie
3 years ago
Meet the $5 million monthly controversy-selling King of Toxic Masculinity.
Trigger warning — Andrew Tate is running a genius marketing campaign
Andrew Tate is a 2022 internet celebrity.
Kickboxing world champion became rich playboy with controversial views on gender roles.
Andrew's get-rich-quick scheme isn't new. His social media popularity is impressive.
He’s currently running one of the most genius marketing campaigns in history.
He pulls society's pendulum away from diversity and inclusion and toward diversion and exclusion. He's unstoppable.
Here’s everything you need to know about Andrew Tate. And how he’s playing chess while the world plays checkers.
Cobra Tate is the name he goes by.
American-born, English-raised entrepreneur Andrew Tate lives in Romania.
Romania? Says Andrew,
“I prefer a country in which corruption is available to everyone.”
Andrew was a professional kickboxer with the ring moniker Cobra before starting Hustlers University.
Before that, he liked chess and worshipped his father.
Emory Andrew Tate III is named after his grandmaster chess player father.
Emory was the first black-American chess champion. He was military, martial arts-trained, and multilingual. A superhuman.
He lived in his car to make ends meet.
Andrew and Tristan relocated to England with their mother when their parents split.
It was there that Andrew began his climb toward becoming one of the internet’s greatest villains.
Andrew fell in love with kickboxing.
Andrew spent his 20s as a professional kickboxer and reality TV star, featuring on Big Brother UK and The Ultimate Traveller.
These 3 incidents, along with a chip on his shoulder, foreshadowed Andrews' social media breakthrough.
Chess
Combat sports
Reality television
A dangerous trio.
Andrew started making money online after quitting kickboxing in 2017 due to an eye issue.
Andrew didn't suddenly become popular.
Andrew's web work started going viral in 2022.
Due to his contentious views on patriarchy and gender norms, he's labeled the King of Toxic Masculinity. His most contentious views (trigger warning):
“Women are intrinsically lazy.”
“Female promiscuity is disgusting.”
“Women shouldn’t drive cars or fly planes.”
“A lot of the world’s problems would be solved if women had their body count tattooed on their foreheads.”
Andrew's two main beliefs are:
“These are my personal opinions based on my experiences.”
2. “I believe men are better at some things and women are better at some things. We are not equal.”
Andrew intentionally offends.
Andrew's thoughts began circulating online in 2022.
In July 2022, he was one of the most Googled humans, surpassing:
Joe Biden
Donald Trump
Kim Kardashian
Andrews' rise is a mystery since no one can censure or suppress him. This is largely because Andrew nor his team post his clips.
But more on that later.
Andrew's path to wealth.
Andrew Tate is a self-made millionaire. His morality is uncertain.
Andrew and Tristan needed money soon after retiring from kickboxing.
“I owed some money to some dangerous people. I had $70K and needed $100K to stay alive.”
Andrews lost $20K on roulette at a local casino.
Andrew had one week to make $50,000, so he started planning. Andrew locked himself in a chamber like Thomas Edison to solve an energy dilemma.
He listed his assets.
Physical strength (but couldn’t fight)
a BMW (worth around $20K)
Intelligence (but no outlet)
A lightbulb.
He had an epiphany after viewing a webcam ad. He sought aid from women, ironically. His 5 international girlfriends are assets.
Then, a lightbulb.
Andrew and Tristan messaged and flew 7 women to a posh restaurant. Selling desperation masked as opportunity, Andrew pitched his master plan:
A webcam business — with a 50/50 revenue split.
5 women left.
2 stayed.
Andrew Tate, a broke kickboxer, became Top G, Cobra Tate.
The business model was simple — yet sad.
Andrew's girlfriends moved in with him and spoke online for 15+ hours a day. Andrew handled ads and equipment as the women posed.
Andrew eventually took over their keyboards, believing he knew what men wanted more than women.
Andrew detailed on the Full Send Podcast how he emotionally manipulated men for millions. They sold houses, automobiles, and life savings to fuel their companionship addiction.
When asked if he felt bad, Andrew said,
“F*ck no.“
Andrew and Tristan wiped off debts, hired workers, and diversified.
Tristan supervised OnlyFans models.
Andrew bought Romanian casinos and MMA league RXF (Real Xtreme Fighting).
Pandemic struck suddenly.
Andrew couldn't run his 2 businesses without a plan. Another easy moneymaker.
He banked on Hustlers University.
The actual cause of Andrew's ubiquity.
On a Your Mom’s House episode Andrew's 4 main revenue sources:
Hustler’s University
2. Owning casinos in Romania
3. Owning 10% of the Romanian MMA league “RXF”
4. “The War Room” — a society of rich and powerful men
When the pandemic hit, 3/4 became inoperable.
So he expanded Hustlers University.
But what is Hustler’s University?
Andrew says Hustlers University teaches 18 wealth-building tactics online. Examples:
Real estate
Copywriting
Amazon FBA
Dropshipping
Flipping Cryptos
How to swiftly become wealthy.
Lessons are imprecise, rudimentary, and macro-focused, say reviews. Invest wisely, etc. Everything is free online.
You pay for community. One unique income stream.
The only money-making mechanism that keeps the course from being a scam.
The truth is, many of Andrew’s students are actually making money. Maybe not from the free YouTube knowledge Andrew and his professors teach in the course, but through Hustler’s University’s affiliate program.
Affiliates earn 10% commission for each new student = $5.
Students can earn $10 for each new referral in the first two months.
Andrew earns $50 per membership per month.
This affiliate program isn’t anything special — in fact, it’s on the lower end of affiliate payouts. Normally, it wouldn’t be very lucrative.
But it has one secret weapon— Andrew and his viral opinions.
Andrew is viral. Andrew went on a media tour in January 2022 after appearing on Your Mom's House.
And many, many more…
He chatted with Twitch streamers. Hustlers University wanted more controversy (and clips).
Here’s the strategy behind Hustler’s University that has (allegedly) earned students upwards of $10K per month:
Make a social media profile with Andrew Tates' name and photo.
Post any of the online videos of Andrews that have gone viral.
Include a referral link in your bio.
Effectively simple.
Andrew's controversy attracts additional students. More student clips circulate as more join. Andrew's students earn more and promote the product as he goes viral.
A brilliant plan that's functioning.
At the beginning of his media tour, Hustler’s University had 5,000 students. 6 months in, and he now has over 100,000.
One income stream generates $5 million every month.
Andrew's approach is not new.
But it is different.
In the early 2010s, Tai Lopez dominated the internet.
His viral video showed his house.
“Here in my garage. Just bought this new Lamborghini.”
Tais' marketing focused on intellect, not strength, power, and wealth to attract women.
How reading quicker leads to financial freedom in 67 steps.
Years later, it was revealed that Tai Lopez rented the mansion and Lamborghini as a marketing ploy to build social proof. Meanwhile, he was living in his friend’s trailer.
Faked success is an old tactic.
Andrew is doing something similar. But with one major distinction.
Andrew outsources his virality — making him nearly impossible to cancel.
In 2022, authorities searched Andrews' estate over human trafficking suspicions. Investigation continues despite withdrawn charges.
Andrew's divisive nature would normally get him fired. Andrew's enterprises and celebrity don't rely on social media.
He doesn't promote or pay for ads. Instead, he encourages his students and anyone wishing to get rich quick to advertise his work.
Because everything goes through his affiliate program. Old saying:
“All publicity is good publicity.”
Final thoughts: it’s ok to feel triggered.
Tate is divisive.
His emotionally charged words are human nature. Andrews created the controversy.
It's non-personal.
His opinions are those of one person. Not world nor generational opinion.
Briefly:
It's easy to understand why Andrews' face is ubiquitous. Money.
The world wide web is a chessboard. Misdirection is part of it.
It’s not personal, it’s business.
Controversy sells
Sometimes understanding the ‘why’, can help you deal with the ‘what.’

Enrique Dans
3 years ago
When we want to return anything, why on earth do stores still require a receipt?

A friend told me of an incident she found particularly irritating: a retailer where she is a frequent client, with an account and loyalty card, asked for the item's receipt.
We all know that stores collect every bit of data they can on us, including our socio-demographic profile, address, shopping habits, and everything we've ever bought, so why would they need a fading receipt? Who knows? That their consumers try to pass off other goods? It's easy to verify past transactions to see when the item was purchased.
That's it. Why require receipts? Companies send us incentives, discounts, and other marketing, yet when we need something, we have to prove we're not cheating.
Why require us to preserve data and documents when our governments and governmental institutions already have them? Why do I need to carry documents like my driver's license if the authorities can check if I have one and what state it's in once I prove my identity?
We shouldn't be required to give someone data or documents they already have. The days of waiting up with our paperwork for a stern official to inform us something is missing are over.
How can retailers still ask if you have a receipt if we've made our slow, bureaucratic, and all-powerful government sensible? Then what? The shop may not accept your return (which has a two-year window, longer than most purchase tickets last) or they may just let you replace the item.
Isn't this an anachronism in the age of CRMs, customer files that know what we ate for breakfast, and loyalty programs? If government and bureaucracies have learnt to use its own files and make life easier for the consumer, why do retailers ask for a receipt?
They're adding friction to the system. They know we can obtain a refund, use our warranty, or get our money back. But if I ask for ludicrous criteria, like keeping the purchase receipt in your wallet (wallet? another anachronism, if I leave the house with only my smartphone! ), it will dissuade some individuals and tip the scales in their favor when it comes to limiting returns. Some manager will take credit for lowering returns and collect her annual bonus. Having the wrong metrics is common in management.
To slow things down, asking for a receipt is like asking us to perform a handstand and leap 20 times on one foot. You have my information, use it to send me everything, and know everything I've bought, yet when I need a two-way service, you refuse to utilize it and require that I keep it and prove it.
Refuse as customers. If retailers want our business, they should treat us well, not just when we spend money. If I come to return a product, claim its use or warranty, or be taught how to use it, I am the same person you treated wonderfully when I bought it. Remember that, and act accordingly.
A store should use my information for everything, not just what it wants. Keep my info, but don't sell me anything.
You might also like

Scott Hickmann
4 years ago
Welcome
Welcome to Integrity's Web3 community!
JEFF JOHN ROBERTS
3 years ago
What just happened in cryptocurrency? A plain-English Q&A about Binance's FTX takedown.

Crypto people have witnessed things. They've seen big hacks, mind-boggling swindles, and amazing successes. They've never seen a day like Tuesday, when the world's largest crypto exchange murdered its closest competition.
Here's a primer on Binance and FTX's lunacy and why it matters if you're new to crypto.
What happened?
CZ, a shrewd Chinese-Canadian billionaire, runs Binance. FTX, a newcomer, has challenged Binance in recent years. SBF (Sam Bankman-Fried)—a young American with wild hair—founded FTX (initials are a thing in crypto).
Last weekend, CZ complained about SBF's lobbying and then exploited Binance's market power to attack his competition.
How did CZ do that?
CZ invested in SBF's new cryptocurrency exchange when they were friends. CZ sold his investment in FTX for FTT when he no longer wanted it. FTX clients utilize those tokens to get trade discounts, although they are less liquid than Bitcoin.
SBF made a mistake by providing CZ just too many FTT tokens, giving him control over FTX. It's like Pepsi handing Coca-Cola a lot of stock it could sell at any time. CZ got upset with SBF and flooded the market with FTT tokens.
SBF owns a trading fund with many FTT tokens, therefore this was catastrophic. SBF sought to defend FTT's worth by selling other assets to buy up the FTT tokens flooding the market, but it didn't succeed, and as FTT's value plummeted, his liabilities exceeded his assets. By Tuesday, his companies were insolvent, so he sold them to his competition.
Crazy. How could CZ do that?
CZ likely did this to crush a rising competition. It was also personal. In recent months, regulators have been tough toward the crypto business, and Binance and FTX have been trying to stay on their good side. CZ believed SBF was poisoning U.S. authorities by saying CZ was linked to China, so CZ took retribution.
“We supported previously, but we won't pretend to make love after divorce. We're neutral. But we won't assist people that push against other industry players behind their backs," CZ stated in a tragic tweet on Sunday. He crushed his rival's company two days later.
So does Binance now own FTX?
No. Not yet. CZ has only stated that Binance signed a "letter of intent" to acquire FTX. CZ and SBF say Binance will protect FTX consumers' funds.
Who’s to blame?
You could blame CZ for using his control over FTX to destroy it. SBF is also being criticized for not disclosing the full overlap between FTX and his trading company, which controlled plenty of FTT. If he had been upfront, someone might have warned FTX about this vulnerability earlier, preventing this mess.
Others have alleged that SBF utilized customer monies to patch flaws in his enterprises' balance accounts. That happened to multiple crypto startups that collapsed this spring, which is unfortunate. These are allegations, not proof.
Why does this matter? Isn't this common in crypto?
Crypto is notorious for shady executives and pranks. FTX is the second-largest crypto business, and SBF was largely considered as the industry's golden boy who would help it get on authorities' good side. Thus far.
Does this affect cryptocurrency prices?
Short-term, it's bad. Prices fell on suspicions that FTX was in peril, then rallied when Binance rescued it, only to fall again later on Tuesday.
These occurrences have hurt FTT and SBF's Solana token. It appears like a huge token selloff is affecting the rest of the market. Bitcoin fell 10% and Ethereum 15%, which is bad but not catastrophic for the two largest coins by market cap.

Techletters
2 years ago
Using Synthesia, DALL-E 2, and Chat GPT-3, create AI news videos
Combining AIs creates realistic AI News Videos.

Powerful AI tools like Chat GPT-3 are trending. Have you combined AIs?
The 1-minute fake news video below is startlingly realistic. Artificial Intelligence developed NASA's Mars exploration breakthrough video (AI). However, integrating the aforementioned AIs generated it.
AI-generated text for the Chat GPT-3 based on a succinct tagline
DALL-E-2 AI generates an image from a brief slogan.
Artificial intelligence-generated avatar and speech
This article shows how to use and mix the three AIs to make a realistic news video. First, watch the video (1 minute).
Talk GPT-3
Chat GPT-3 is an OpenAI NLP model. It can auto-complete text and produce conversational responses.
Try it at the playground. The AI will write a comprehensive text from a brief tagline. Let's see what the AI generates with "Breakthrough in Mars Project" as the headline.

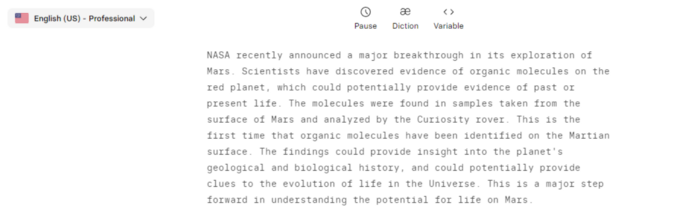
Amazing. Our tagline matches our complete and realistic text. Fake news can start here.
DALL-E-2
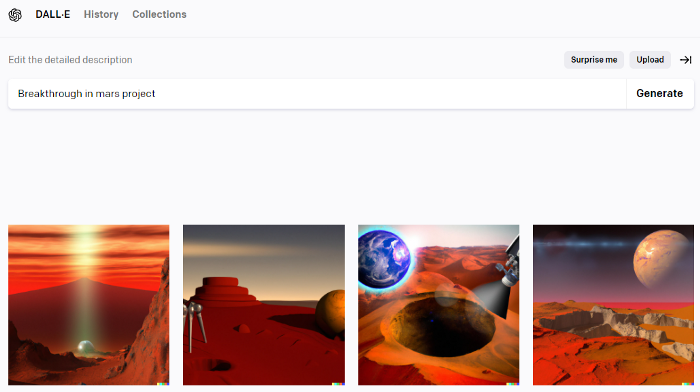
OpenAI's huge transformer-based language model DALL-E-2. Its GPT-3 basis is geared for image generation. It can generate high-quality photos from a brief phrase and create artwork and images of non-existent objects.
DALL-E-2 can create a news video background. We'll use "Breakthrough in Mars project" again. Our AI creates four striking visuals. Last.
Synthesia
Synthesia lets you quickly produce videos with AI avatars and synthetic vocals.
Avatars are first. Rosie it is.

Upload and select DALL-backdrop. E-2's
Copy the Chat GPT-3 content and choose a synthetic voice.
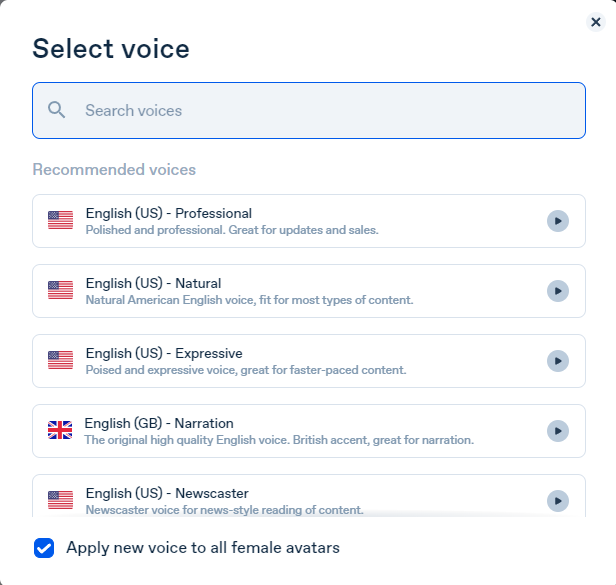
Voice: English (US) Professional.
Finally, we generate and watch or download our video.
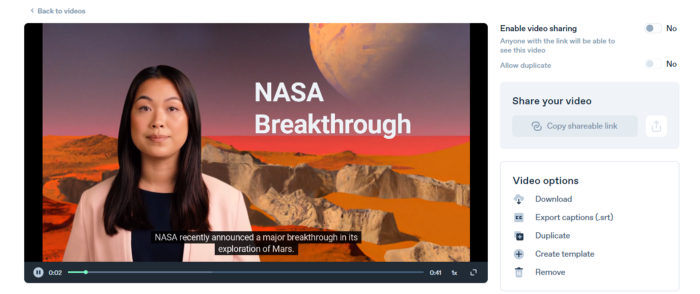
Synthesia AI completes the AI video.
Overview & Resources
We used three AIs to make surprisingly realistic NASA Mars breakthrough fake news in this post. Synthesia generates an avatar and a synthetic voice, therefore it may be four AIs.
These AIs created our fake news.
AI-generated text for the Chat GPT-3 based on a succinct tagline
DALL-E-2 AI generates an image from a brief slogan.
Artificial intelligence-generated avatar and speech