



More on Productivity

Cammi Pham
3 years ago
7 Scientifically Proven Things You Must Stop Doing To Be More Productive
Smarter work yields better results.

17-year-old me worked and studied 20 hours a day. During school breaks, I did coursework and ran a nonprofit at night. Long hours earned me national campaigns, A-list opportunities, and a great career. As I aged, my thoughts changed. Working harder isn't necessarily the key to success.
In some cases, doing less work might lead to better outcomes.
Consider a hard-working small business owner. He can't beat his corporate rivals by working hard. Time's limited. An entrepreneur can work 24 hours a day, 7 days a week, but a rival can invest more money, create a staff, and put in more man hours. Why have small startups done what larger companies couldn't? Facebook paid $1 billion for 13-person Instagram. Snapchat, a 30-person startup, rejected Facebook and Google bids. Luck and efficiency each contributed to their achievement.
The key to success is not working hard. It’s working smart.
Being busy and productive are different. Busy doesn't always equal productive. Productivity is less about time management and more about energy management. Life's work. It's using less energy to obtain more rewards. I cut my work week from 80 to 40 hours and got more done. I value simplicity.
Here are seven activities I gave up in order to be more productive.
1. Give up working extra hours and boost productivity instead.
When did the five-day, 40-hour work week start? Henry Ford, Ford Motor Company founder, experimented with his workers in 1926.
He decreased their daily hours from 10 to 8, and shortened the work week from 6 days to 5. As a result, he saw his workers’ productivity increase.
According to a 1980 Business Roundtable report, Scheduled Overtime Effect on Construction Projects, the more you work, the less effective and productive you become.
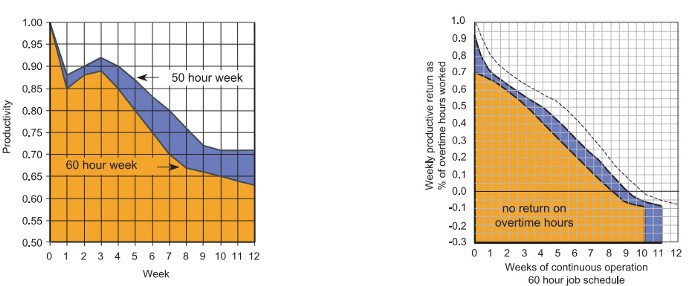
“Where a work schedule of 60 or more hours per week is continued longer than about two months, the cumulative effect of decreased productivity will cause a delay in the completion date beyond that which could have been realized with the same crew size on a 40-hour week.” Source: Calculating Loss of Productivity Due to Overtime Using Published Charts — Fact or Fiction
AlterNet editor Sara Robinson cited US military research showing that losing one hour of sleep per night for a week causes cognitive impairment equivalent to a.10 blood alcohol level. You can get fired for showing up drunk, but an all-nighter is fine.
Irrespective of how well you were able to get on with your day after that most recent night without sleep, it is unlikely that you felt especially upbeat and joyous about the world. Your more-negative-than-usual perspective will have resulted from a generalized low mood, which is a normal consequence of being overtired. More important than just the mood, this mind-set is often accompanied by decreases in willingness to think and act proactively, control impulses, feel positive about yourself, empathize with others, and generally use emotional intelligence. Source: The Secret World of Sleep: The Surprising Science of the Mind at Rest
To be productive, don't overwork and get enough sleep. If you're not productive, lack of sleep may be to blame. James Maas, a sleep researcher and expert, said 7/10 Americans don't get enough sleep.
Did you know?
Leonardo da Vinci slept little at night and frequently took naps.
Napoleon, the French emperor, had no qualms about napping. He splurged every day.
Even though Thomas Edison felt self-conscious about his napping behavior, he regularly engaged in this ritual.
President Franklin D. Roosevelt's wife Eleanor used to take naps before speeches to increase her energy.
The Singing Cowboy, Gene Autry, was known for taking regular naps in his dressing area in between shows.
Every day, President John F. Kennedy took a siesta after eating his lunch in bed.
Every afternoon, oil businessman and philanthropist John D. Rockefeller took a nap in his office.
It was unavoidable for Winston Churchill to take an afternoon snooze. He thought it enabled him to accomplish twice as much each day.
Every afternoon around 3:30, President Lyndon B. Johnson took a nap to divide his day into two segments.
Ronald Reagan, the 40th president, was well known for taking naps as well.
Source: 5 Reasons Why You Should Take a Nap Every Day — Michael Hyatt
Since I started getting 7 to 8 hours of sleep a night, I've been more productive and completed more work than when I worked 16 hours a day. Who knew marketers could use sleep?
2. Refrain from accepting too frequently
Pareto's principle states that 20% of effort produces 80% of results, but 20% of results takes 80% of effort. Instead of working harder, we should prioritize the initiatives that produce the most outcomes. So we can focus on crucial tasks. Stop accepting unproductive tasks.
“The difference between successful people and very successful people is that very successful people say “no” to almost everything.” — Warren Buffett
What should you accept? Why say no? Consider doing a split test to determine if anything is worth your attention. Track what you do, how long it takes, and the consequences. Then, evaluate your list to discover what worked (or didn't) to optimize future chores.
Most of us say yes more often than we should, out of guilt, overextension, and because it's simpler than no. Nobody likes being awful.
Researchers separated 120 students into two groups for a 2012 Journal of Consumer Research study. One group was educated to say “I can't” while discussing choices, while the other used “I don't”.
The students who told themselves “I can’t eat X” chose to eat the chocolate candy bar 61% of the time. Meanwhile, the students who told themselves “I don’t eat X” chose to eat the chocolate candy bars only 36% of the time. This simple change in terminology significantly improved the odds that each person would make a more healthy food choice.
Next time you need to say no, utilize I don't to encourage saying no to unimportant things.
The 20-second rule is another wonderful way to avoid pursuits with little value. Add a 20-second roadblock to things you shouldn't do or bad habits you want to break. Delete social media apps from your phone so it takes you 20 seconds to find your laptop to access them. You'll be less likely to engage in a draining hobby or habit if you add an inconvenience.
Lower the activation energy for habits you want to adopt and raise it for habits you want to avoid. The more we can lower or even eliminate the activation energy for our desired actions, the more we enhance our ability to jump-start positive change. Source: The Happiness Advantage: The Seven Principles of Positive Psychology That Fuel Success and Performance at Work
3. Stop doing everything yourself and start letting people help you
I once managed a large community and couldn't do it alone. The community took over once I burned out. Members did better than I could have alone. I learned about community and user-generated content.
Consumers know what they want better than marketers. Octoly says user-generated videos on YouTube are viewed 10 times more than brand-generated videos. 51% of Americans trust user-generated material more than a brand's official website (16%) or media coverage (22%). (14 percent). Marketers should seek help from the brand community.

Being a successful content marketer isn't about generating the best content, but cultivating a wonderful community.
We should seek aid when needed. We can't do everything. It's best to delegate work so you may focus on the most critical things. Instead of overworking or doing things alone, let others help.
Having friends or coworkers around can boost your productivity even if they can't help.
Just having friends nearby can push you toward productivity. “There’s a concept in ADHD treatment called the ‘body double,’ ” says David Nowell, Ph.D., a clinical neuropsychologist from Worcester, Massachusetts. “Distractable people get more done when there is someone else there, even if he isn’t coaching or assisting them.” If you’re facing a task that is dull or difficult, such as cleaning out your closets or pulling together your receipts for tax time, get a friend to be your body double. Source: Friendfluence: The Surprising Ways Friends Make Us Who We Are
4. Give up striving for perfection
Perfectionism hinders professors' research output. Dr. Simon Sherry, a psychology professor at Dalhousie University, did a study on perfectionism and productivity. Dr. Sherry established a link between perfectionism and productivity.
Perfectionism has its drawbacks.
They work on a task longer than necessary.
They delay and wait for the ideal opportunity. If the time is right in business, you are already past the point.
They pay too much attention to the details and miss the big picture.
Marketers await the right time. They miss out.
The perfect moment is NOW.
5. Automate monotonous chores instead of continuing to do them.
A team of five workers who spent 3%, 20%, 25%, 30%, and 70% of their time on repetitive tasks reduced their time spent to 3%, 10%, 15%, 15%, and 10% after two months of working to improve their productivity.
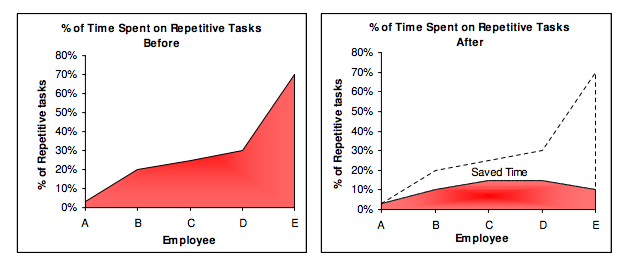
Last week, I wrote a 15-minute Python program. I wanted to generate content utilizing Twitter API data and Hootsuite to bulk schedule it. Automation has cut this task from a day to five minutes. Whenever I do something more than five times, I try to automate it.
Automate monotonous chores without coding. Skills and resources are nice, but not required. If you cannot build it, buy it.
People forget time equals money. Manual work is easy and requires little investigation. You can moderate 30 Instagram photographs for your UGC campaign. You need digital asset management software to manage 30,000 photographs and movies from five platforms. Filemobile helps individuals develop more user-generated content. You may buy software to manage rich media and address most internet difficulties.
Hire an expert if you can't find a solution. Spend money to make money, and time is your most precious asset.
Visit GitHub or Google Apps Script library, marketers. You may often find free, easy-to-use open source code.
6. Stop relying on intuition and start supporting your choices with data.
You may optimize your life by optimizing webpages for search engines.
Numerous studies might help you boost your productivity. Did you know individuals are most distracted from midday to 4 p.m.? This is what a Penn State psychology professor found. Even if you can't find data on a particular question, it's easy to run a split test and review your own results.
7. Stop working and spend some time doing absolutely nothing.
Most people don't know that being too focused can be destructive to our work or achievements. The Boston Globe's The Power of Lonely says solo time is excellent for the brain and spirit.
One ongoing Harvard study indicates that people form more lasting and accurate memories if they believe they’re experiencing something alone. Another indicates that a certain amount of solitude can make a person more capable of empathy towards others. And while no one would dispute that too much isolation early in life can be unhealthy, a certain amount of solitude has been shown to help teenagers improve their moods and earn good grades in school. Source: The Power of Lonely
Reflection is vital. We find solutions when we're not looking.
We don't become more productive overnight. It demands effort and practice. Waiting for change doesn't work. Instead, learn about your body and identify ways to optimize your energy and time for a happy existence.

Ethan Siegel
2 years ago
How you view the year will change after using this one-page calendar.

No other calendar is simpler, smaller, and reusable year after year. It works and is used here.
Most of us discard and replace our calendars annually. Each month, we move our calendar ahead another page, thus if we need to know which day of the week corresponds to a given day/month combination, we have to calculate it or flip forward/backward to the corresponding month. Questions like:
What day does this year's American Thanksgiving fall on?
Which months contain a Friday the thirteenth?
When is July 4th? What day of the week?
Alternatively, what day of the week is Christmas?
They're hard to figure out until you switch to the right month or look up all the months.
However, mathematically, the answers to these questions or any question that requires matching the day of the week with the day/month combination in a year are predictable, basic, and easy to work out. If you use this one-page calendar instead of a 12-month calendar, it lasts the whole year and is easy to alter for future years. Let me explain.
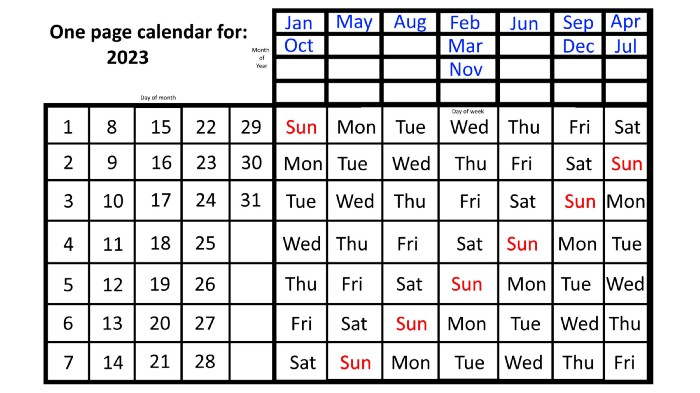
The 2023 one-page calendar is above. The days of the month are on the lower left, which works for all months if you know that:
There are 31 days in January, March, May, July, August, October, and December.
All of the months of April, June, September, and November have 30 days.
And depending on the year, February has either 28 days (in non-leap years) or 29 days (in leap years).
If you know this, this calendar makes it easy to match the day/month of the year to the weekday.
Here are some instances. American Thanksgiving is always on the fourth Thursday of November. You'll always know the month and day of the week, but the date—the day in November—changes each year.
On any other calendar, you'd have to flip to November to see when the fourth Thursday is. This one-page calendar only requires:
pick the month of November in the top-right corner to begin.
drag your finger down until Thursday appears,
then turn left and follow the monthly calendar until you reach the fourth Thursday.
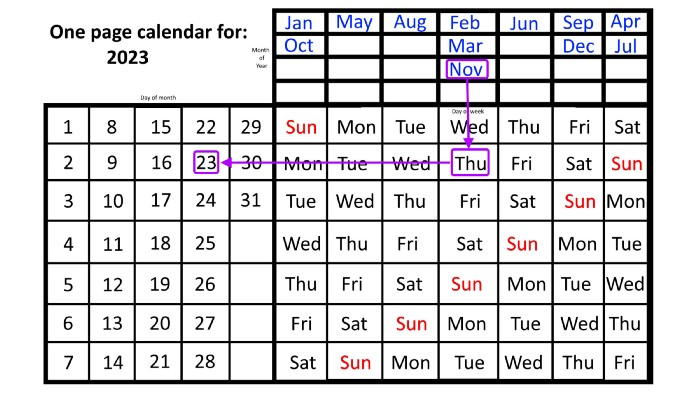
It's obvious: 2023 is the 23rd American Thanksgiving. For every month and day-of-the-week combination, start at the month, drag your finger down to the desired day, and then move to the left to see which dates match.
What if you knew the day of the week and the date of the month, but not the month(s)?
A different method using the same one-page calendar gives the answer. Which months have Friday the 13th this year? Just:
begin on the 13th of the month, the day you know you desire,
then swipe right with your finger till Friday appears.
and then work your way up until you can determine which months the specific Friday the 13th falls under.
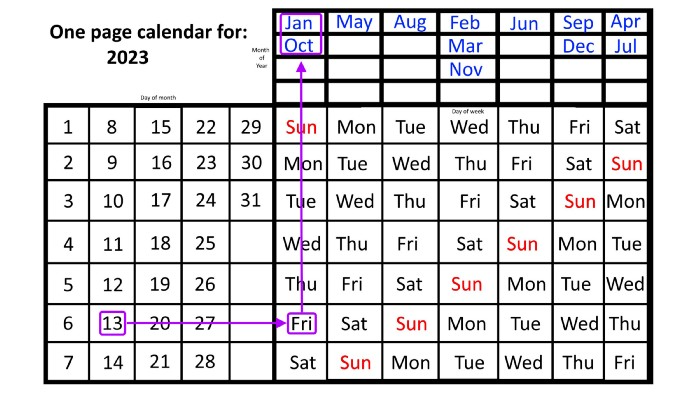
One Friday the 13th occurred in January 2023, and another will occur in October.
The most typical reason to consult a calendar is when you know the month/day combination but not the day of the week.
Compared to single-month calendars, the one-page calendar excels here. Take July 4th, for instance. Find the weekday here:
beginning on the left on the fourth of the month, as you are aware,
also begin with July, the month of the year you are most familiar with, at the upper right,
you should move your two fingers in the opposite directions till they meet: on a Tuesday in 2023.
That's how you find your selected day/month combination's weekday.
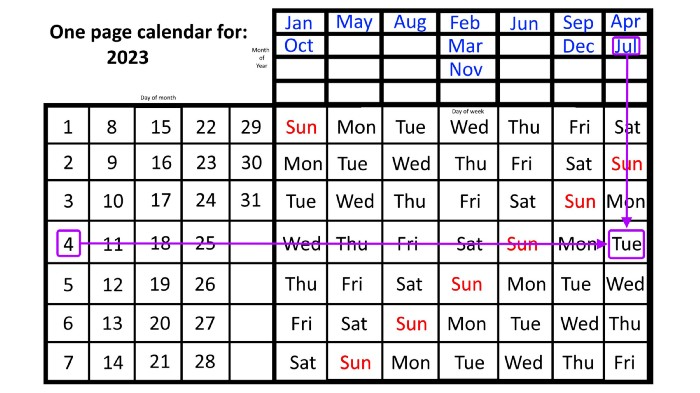
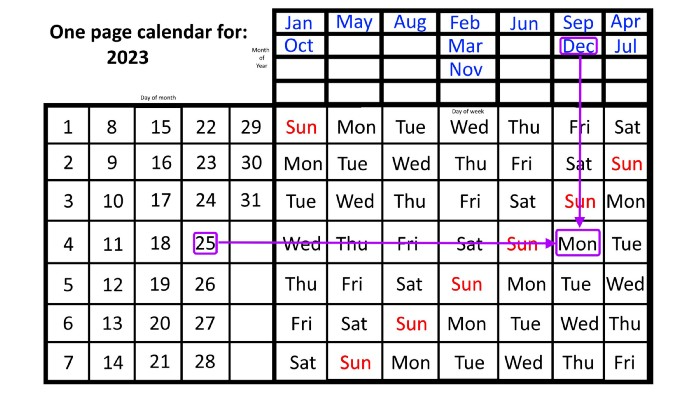
Another example: Christmas. Christmas Day is always December 25th, however unless your conventional calendar is open to December of your particular year, a question like "what day of the week is Christmas?" difficult to answer.
Unlike the one-page calendar!
Remember the left-hand day of the month. Top-right, you see the month. Put two fingers, one from each hand, on the date (25th) and the month (December). Slide the day hand to the right and the month hand downwards until they touch.
They meet on Monday—December 25, 2023.
For 2023, that's fine, but what happens in 2024? Even worse, what if we want to know the day-of-the-week/day/month combo many years from now?
I think the one-page calendar shines here.
Except for the blue months in the upper-right corner of the one-page calendar, everything is the same year after year. The months also change in a consistent fashion.
Each non-leap year has 365 days—one more than a full 52 weeks (which is 364). Since January 1, 2023 began on a Sunday and 2023 has 365 days, we immediately know that December 31, 2023 will conclude on a Sunday (which you can confirm using the one-page calendar) and that January 1, 2024 will begin on a Monday. Then, reorder the months for 2024, taking in mind that February will have 29 days in a leap year.
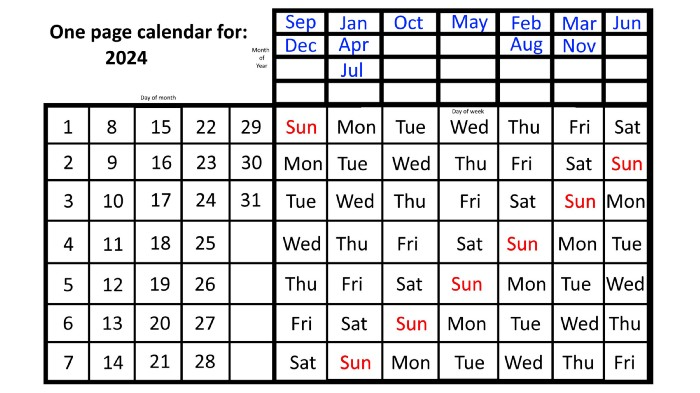
Please note the differences between 2023 and 2024 month placement. In 2023:
October and January began on the same day of the week.
On the following Monday of the week, May began.
August started on the next day,
then the next weekday marked the start of February, March, and November, respectively.
Unlike June, which starts the following weekday,
While September and December start on the following day of the week,
Lastly, April and July start one extra day later.
Since 2024 is a leap year, February has 29 days, disrupting the rhythm. Month placements change to:
The first day of the week in January, April, and July is the same.
October will begin the following day.
Possibly starting the next weekday,
February and August start on the next weekday,
beginning on the following day of the week between March and November,
beginning the following weekday in June,
and commencing one more day of the week after that, September and December.
Due to the 366-day leap year, 2025 will start two days later than 2024 on January 1st.
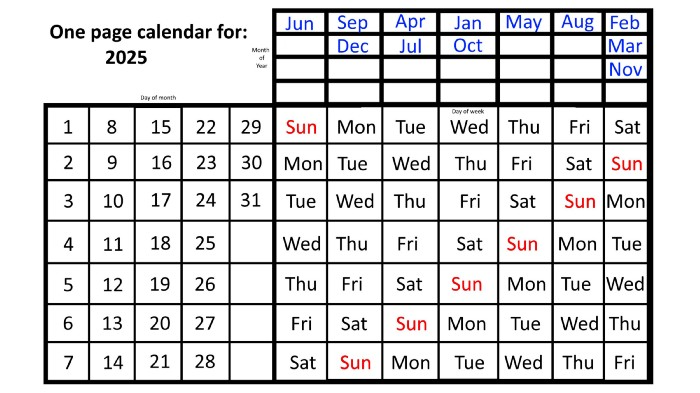
Now, looking at the 2025 calendar, you can see that the 2023 pattern of which months start on which days is repeated! The sole variation is a shift of three days-of-the-week ahead because 2023 had one more day (365) than 52 full weeks (364), and 2024 had two more days (366). Again,
On Wednesday this time, January and October begin on the same day of the week.
Although May begins on Thursday,
August begins this Friday.
March, November, and February all begin on a Saturday.
Beginning on a Sunday in June
Beginning on Monday are September and December,
and on Tuesday, April and July begin.
In 2026 and 2027, the year will commence on a Thursday and a Friday, respectively.
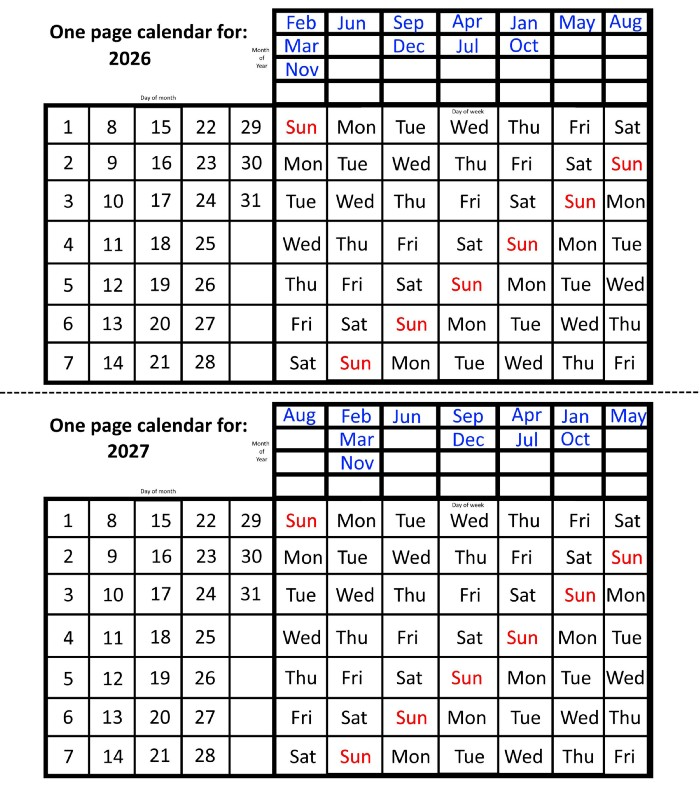
We must return to our leap year monthly arrangement in 2028. Yes, January 1, 2028 begins on a Saturday, but February, which begins on a Tuesday three days before January, will have 29 days. Thus:
Start dates for January, April, and July are all Saturdays.
Given that October began on Sunday,
Although May starts on a Monday,
beginning on a Tuesday in February and August,
Beginning on a Wednesday in March and November,
Beginning on Thursday, June
and Friday marks the start of September and December.
This is great because there are only 14 calendar configurations: one for each of the seven non-leap years where January 1st begins on each of the seven days of the week, and one for each of the seven leap years where it begins on each day of the week.
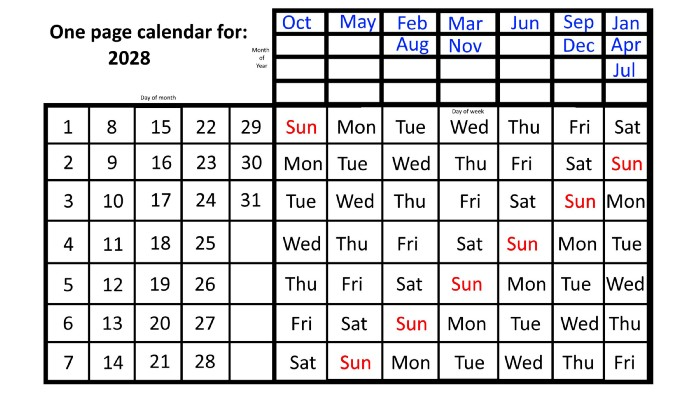
The 2023 calendar will function in 2034, 2045, 2051, 2062, 2073, 2079, 2090, 2102, 2113, and 2119. Except when passing over a non-leap year that ends in 00, like 2100, the repeat time always extends to 12 years or shortens to an extra 6 years.
The pattern is repeated in 2025's calendar in 2031, 2042, 2053, 2059, 2070, 2081, 2087, 2098, 2110, and 2121.
The extra 6-year repeat at the end of the century on the calendar for 2026 will occur in the years 2037, 2043, 2054, 2065, 2071, 2082, 2093, 2099, 2105, and 2122.
The 2027s calendar repeats in 2038, 2049, 2055, 2066, 2077, 2083, 2094, 2100, 2106, and 2117, almost exactly matching the 2026s pattern.
For leap years, the recurrence pattern is every 28 years when not passing a non-leap year ending in 00, or 12 or 40 years when we do. 2024's calendar repeats in 2052, 2080, 2120, 2148, 2176, and 2216; 2028's in 2056, 2084, 2124, 2152, 2180, and 2220.
Knowing January 1st and whether it's a leap year lets you construct a one-page calendar for any year. Try it—you might find it easier than any other alternative!

Taher Batterywala
3 years ago
Do You Have Focus Issues? Use These 5 Simple Habits

Many can't concentrate. The first 20% of the day isn't optimized.
Elon Musk, Tony Robbins, and Bill Gates share something:
Morning Routines.
A repeatable morning ritual saves time.
The result?
Time for hobbies.
I'll discuss 5 easy morning routines you can use.
1. Stop pressing snooze
Waking up starts the day. You disrupt your routine by hitting snooze.
One sleep becomes three. Your morning routine gets derailed.
Fix it:
Hide your phone. This disables snooze and wakes you up.
Once awake, staying awake is 10x easier. Simple trick, big results.
2. Drink water
Chronic dehydration is common. Mostly urban, air-conditioned workers/residents.
2% cerebral dehydration causes short-term memory loss.
Dehydration shrinks brain cells.
Drink 3-4 liters of water daily to avoid this.
3. Improve your focus
How to focus better?
Meditation.
Improve your mood
Enhance your memory
increase mental clarity
Reduce blood pressure and stress
Headspace helps with the habit.
Here's a meditation guide.
Sit comfortably
Shut your eyes.
Concentrate on your breathing
Breathe in through your nose
Breathe out your mouth.
5 in, 5 out.
Repeat for 1 to 20 minutes.
Here's a beginner's video:
4. Workout
Exercise raises:
Mental Health
Effort levels
focus and memory
15-60 minutes of fun:
Exercise Lifting
Running
Walking
Stretching and yoga
This helps you now and later.
5. Keep a journal
You have countless thoughts daily. Many quietly steal your focus.
Here’s how to clear these:
Write for 5-10 minutes.
You'll gain 2x more mental clarity.
Recap
5 morning practices for 5x more productivity:
Say no to snoozing
Hydrate
Improve your focus
Exercise
Journaling
Conclusion
One step starts a thousand-mile journey. Try these easy yet effective behaviors if you have trouble concentrating or have too many thoughts.
Start with one of these behaviors, then add the others. Its astonishing results are instant.
You might also like

Sam Hickmann
3 years ago
Donor-Advised Fund Tax Benefits (DAF)
Giving through a donor-advised fund can be tax-efficient. Using a donor-advised fund can reduce your tax liability while increasing your charitable impact.
Grow Your Donations Tax-Free.
Your DAF's charitable dollars can be invested before being distributed. Your DAF balance can grow with the market. This increases grantmaking funds. The assets of the DAF belong to the charitable sponsor, so you will not be taxed on any growth.
Avoid a Windfall Tax Year.
DAFs can help reduce tax burdens after a windfall like an inheritance, business sale, or strong market returns. Contributions to your DAF are immediately tax deductible, lowering your taxable income. With DAFs, you can effectively pre-fund years of giving with assets from a single high-income event.
Make a contribution to reduce or eliminate capital gains.
One of the most common ways to fund a DAF is by gifting publicly traded securities. Securities held for more than a year can be donated at fair market value and are not subject to capital gains tax. If a donor liquidates assets and then donates the proceeds to their DAF, capital gains tax reduces the amount available for philanthropy. Gifts of appreciated securities, mutual funds, real estate, and other assets are immediately tax deductible up to 30% of Adjusted gross income (AGI), with a five-year carry-forward for gifts that exceed AGI limits.
Using Appreciated Stock as a Gift
Donating appreciated stock directly to a DAF rather than liquidating it and donating the proceeds reduces philanthropists' tax liability by eliminating capital gains tax and lowering marginal income tax.
In the example below, a donor has $100,000 in long-term appreciated stock with a cost basis of $10,000:
Using a DAF would allow this donor to give more to charity while paying less taxes. This strategy often allows donors to give more than 20% more to their favorite causes.
For illustration purposes, this hypothetical example assumes a 35% income tax rate. All realized gains are subject to the federal long-term capital gains tax of 20% and the 3.8% Medicare surtax. No other state taxes are considered.
The information provided here is general and educational in nature. It is not intended to be, nor should it be construed as, legal or tax advice. NPT does not provide legal or tax advice. Furthermore, the content provided here is related to taxation at the federal level only. NPT strongly encourages you to consult with your tax advisor or attorney before making charitable contributions.

Joe Procopio
3 years ago
Provide a product roadmap that can withstand startup velocities
This is how to build a car while driving.

Building a high-growth startup is compared to building a car while it's speeding down the highway.
How to plan without going crazy? Or, without losing team, board, and investor buy-in?
I just delivered our company's product roadmap for the rest of the year. Complete. Thorough. Page-long. I'm optimistic about its chances of surviving as everything around us changes, from internal priorities to the global economy.
It's tricky. This isn't the first time I've created a startup roadmap. I didn't invent a document. It took time to deliver a document that will be relevant for months.
Goals matter.
Although they never change, goals are rarely understood.
This is the third in a series about a startup's unique roadmapping needs. Velocity is the intensity at which a startup must produce to survive.
A high-growth startup moves at breakneck speed, which I alluded to when I said priorities and economic factors can change daily or weekly.
At that speed, a startup's roadmap must be flexible, bend but not break, and be brief and to the point. I can't tell you how many startups and large companies develop a product roadmap every quarter and then tuck it away.
Big, wealthy companies can do this. It's suicide for a startup.
The drawer thing happens because startup product roadmaps are often valid for a short time. The roadmap is a random list of features prioritized by different company factions and unrelated to company goals.
It's not because the goals changed that a roadmap is shelved or ignored. Because the company's goals were never communicated or documented in the context of its product.
In the previous post, I discussed how to turn company goals into a product roadmap. In this post, I'll show you how to make a one-page startup roadmap.
In a future post, I'll show you how to follow this roadmap. This roadmap helps you track company goals, something a roadmap must do.
Be vague for growth, but direct for execution.
Here's my plan. The real one has more entries and more content in each.

Let's discuss smaller boxes.
Product developers and engineers know that the further out they predict, the more wrong they'll be. When developing the product roadmap, this rule is ignored. Then it bites us three, six, or nine months later when we haven't even started.
Why do we put everything in a product roadmap like a project plan?
Yes, I know. We use it when the product roadmap isn't goal-based.
A goal-based roadmap begins with a document that outlines each goal's idea, execution, growth, and refinement.
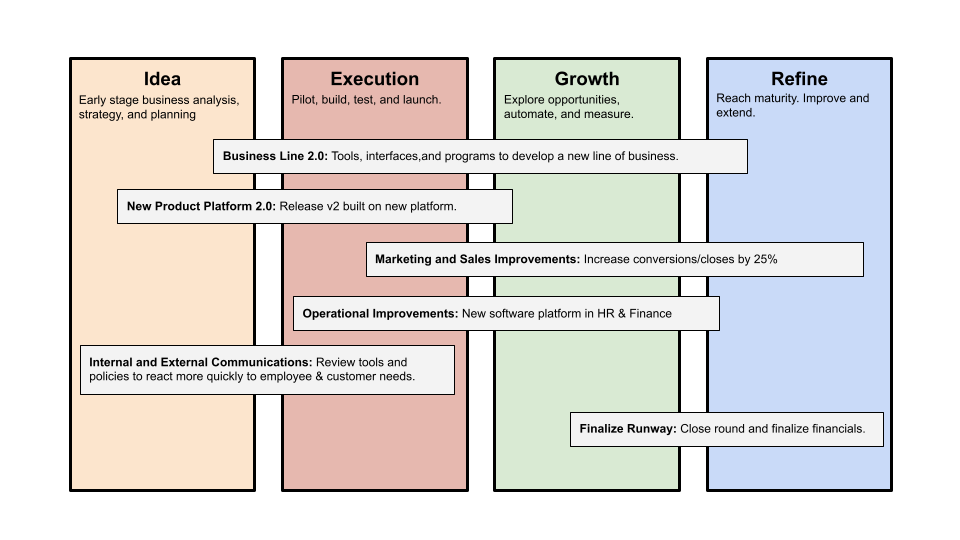
Once the goals are broken down into epics, initiatives, projects, and programs, only the idea and execution phases should be modeled. Any goal growth or refinement items should be vague and loosely mapped.
Why? First, any idea or execution-phase goal will result in growth initiatives that are unimaginable today. Second, internal priorities and external factors will change, but the goals won't. Locking items into calendar slots reduces flexibility and forces deviation from the single source of truth.
No soothsayers. Predicting the future is pointless; just prepare.
A map is useless if you don't know where you're going.
As we speed down the road, the car and the road will change. Goals define the destination.
This quarter and next quarter's roadmap should be set. After that, you should track destination milestones, not how to get there.
When you do that, even the most critical investors will understand the roadmap and buy in. When you track progress at the end of the quarter and revise your roadmap, the destination won't change.

Vishal Chawla
3 years ago
5 Bored Apes borrowed to claim $1.1 million in APE tokens
Takeaway
Unknown user took advantage of the ApeCoin airdrop to earn $1.1 million.
He used a flash loan to borrow five BAYC NFTs, claim the airdrop, and repay the NFTs.
Yuga Labs, the creators of BAYC, airdropped ApeCoin (APE) to anyone who owns one of their NFTs yesterday.
For the Bored Ape Yacht Club and Mutant Ape Yacht Club collections, the team allocated 150 million tokens, or 15% of the total ApeCoin supply, worth over $800 million. Each BAYC holder received 10,094 tokens worth $80,000 to $200,000.
But someone managed to claim the airdrop using NFTs they didn't own. They used the airdrop's specific features to carry it out. And it worked, earning them $1.1 million in ApeCoin.
The trick was that the ApeCoin airdrop wasn't based on who owned which Bored Ape at a given time. Instead, anyone with a Bored Ape at the time of the airdrop could claim it. So if you gave someone your Bored Ape and you hadn't claimed your tokens, they could claim them.
The person only needed to get hold of some Bored Apes that hadn't had their tokens claimed to claim the airdrop. They could be returned immediately.
So, what happened?
The person found a vault with five Bored Ape NFTs that hadn't been used to claim the airdrop.
A vault tokenizes an NFT or a group of NFTs. You put a bunch of NFTs in a vault and make a token. This token can then be staked for rewards or sold (representing part of the value of the collection of NFTs). Anyone with enough tokens can exchange them for NFTs.
This vault uses the NFTX protocol. In total, it contained five Bored Apes: #7594, #8214, #9915, #8167, and #4755. Nobody had claimed the airdrop because the NFTs were locked up in the vault and not controlled by anyone.
The person wanted to unlock the NFTs to claim the airdrop but didn't want to buy them outright s o they used a flash loan, a common tool for large DeFi hacks. Flash loans are a low-cost way to borrow large amounts of crypto that are repaid in the same transaction and block (meaning that the funds are never at risk of not being repaid).
With a flash loan of under $300,000 they bought a Bored Ape on NFT marketplace OpenSea. A large amount of the vault's token was then purchased, allowing them to redeem the five NFTs. The NFTs were used to claim the airdrop, before being returned, the tokens sold back, and the loan repaid.
During this process, they claimed 60,564 ApeCoin airdrops. They then sold them on Uniswap for 399 ETH ($1.1 million). Then they returned the Bored Ape NFT used as collateral to the same NFTX vault.
Attack or arbitrage?
However, security firm BlockSecTeam disagreed with many social media commentators. A flaw in the airdrop-claiming mechanism was exploited, it said.
According to BlockSecTeam's analysis, the user took advantage of a "vulnerability" in the airdrop.
"We suspect a hack due to a flaw in the airdrop mechanism. The attacker exploited this vulnerability to profit from the airdrop claim" said BlockSecTeam.
For example, the airdrop could have taken into account how long a person owned the NFT before claiming the reward.
Because Yuga Labs didn't take a snapshot, anyone could buy the NFT in real time and claim it. This is probably why BAYC sales exploded so soon after the airdrop announcement.