


More on Personal Growth

Alex Mathers
3 years ago
12 habits of the zenith individuals I know
Calmness is a vital life skill.
It aids communication. It boosts creativity and performance.
I've studied calm people's habits for years. Commonalities:
Have mastered the art of self-humor.
Protectors take their job seriously, draining the room's energy.
They are fixated on positive pursuits like making cool things, building a strong physique, and having fun with others rather than on depressing influences like the news and gossip.
Every day, spend at least 20 minutes moving, whether it's walking, yoga, or lifting weights.
Discover ways to take pleasure in life's challenges.
Since perspective is malleable, they change their view.
Set your own needs first.
Stressed people neglect themselves and wonder why they struggle.
Prioritize self-care.
Don't ruin your life to please others.
Make something.
Calm people create more than react.
They love creating beautiful things—paintings, children, relationships, and projects.
Don’t hold their breath.
If you're stressed or angry, you may be surprised how much time you spend holding your breath and tightening your belly.
Release, breathe, and relax to find calm.
Stopped rushing.
Rushing is disadvantageous.
Calm people handle life better.
Are aware of their own dietary requirements.
They avoid junk food and eat foods that keep them healthy, happy, and calm.
Don’t take anything personally.
Stressed people control everything.
Self-conscious.
Calm people put others and their work first.
Keep their surroundings neat.
Maintaining an uplifting and clutter-free environment daily calms the mind.
Minimise negative people.
Calm people are ruthless with their boundaries and avoid negative and drama-prone people.

Daniel Vassallo
3 years ago
Why I quit a $500K job at Amazon to work for myself
I quit my 8-year Amazon job last week. I wasn't motivated to do another year despite promotions, pay, recognition, and praise.
In AWS, I built developer tools. I could have worked in that field forever.
I became an Amazon developer. Within 3.5 years, I was promoted twice to senior engineer and would have been promoted to principal engineer if I stayed. The company said I had great potential.
Over time, I became a reputed expert and leader within the company. I was respected.
First year I made $75K, last year $511K. If I stayed another two years, I could have made $1M.
Despite Amazon's reputation, my work–life balance was good. I no longer needed to prove myself and could do everything in 40 hours a week. My team worked from home once a week, and I rarely opened my laptop nights or weekends.
My coworkers were great. I had three generous, empathetic managers. I’m very grateful to everyone I worked with.
Everything was going well and getting better. My motivation to go to work each morning was declining despite my career and income growth.
Another promotion, pay raise, or big project wouldn't have boosted my motivation. Motivation was also waning. It was my freedom.
Demotivation
My motivation was high in the beginning. I worked with someone on an internal tool with little scrutiny. I had more freedom to choose how and what to work on than in recent years. Me and another person improved it, talked to users, released updates, and tested it. Whatever we wanted, we did. We did our best and were mostly self-directed.
In recent years, things have changed. My department's most important project had many stakeholders and complex goals. What I could do depended on my ability to convince others it was the best way to achieve our goals.
Amazon was always someone else's terms. The terms started out simple (keep fixing it), but became more complex over time (maximize all goals; satisfy all stakeholders). Working in a large organization imposed restrictions on how to do the work, what to do, what goals to set, and what business to pursue. This situation forced me to do things I didn't want to do.
Finding New Motivation
What would I do forever? Not something I did until I reached a milestone (an exit), but something I'd do until I'm 80. What could I do for the next 45 years that would make me excited to wake up and pay my bills? Is that too unambitious? Nope. Because I'm motivated by two things.
One is an external carrot or stick. I'm not forced to file my taxes every April, but I do because I don't want to go to jail. Or I may not like something but do it anyway because I need to pay the bills or want a nice car. Extrinsic motivation
One is internal. When there's no carrot or stick, this motivates me. This fuels hobbies. I wanted a job that was intrinsically motivated.
Is this too low-key? Extrinsic motivation isn't sustainable. Getting promoted felt good for a week, then it was over. When I hit $100K, I admired my W2 for a few days, but then it wore off. Same thing happened at $200K, $300K, $400K, and $500K. Earning $1M or $10M wouldn't change anything. I feel the same about every material reward or possession. Getting them feels good at first, but quickly fades.
Things I've done since I was a kid, when no one forced me to, don't wear off. Coding, selling my creations, charting my own path, and being honest. Why not always use my strengths and motivation? I'm lucky to live in a time when I can work independently in my field without large investments. So that’s what I’m doing.
What’s Next?
I'm going all-in on independence and will make a living from scratch. I won't do only what I like, but on my terms. My goal is to cover my family's expenses before my savings run out while doing something I enjoy. What more could I want from my work?
You can now follow me on Twitter as I continue to document my journey.
This post is a summary. Read full article here

Neeramitra Reddy
3 years ago
The best life advice I've ever heard could very well come from 50 Cent.
He built a $40M hip-hop empire from street drug dealing.

50 Cent was nearly killed by 9mm bullets.
Before 50 Cent, Curtis Jackson sold drugs.
He sold coke to worried addicts after being orphaned at 8.
Pursuing police. Murderous hustlers and gangs. Unwitting informers.
Despite his hard life, his hip-hop career was a success.
An assassination attempt ended his career at the start.
What sane producer would want to deal with a man entrenched in crime?
Most would have drowned in self-pity and drank themselves to death.
But 50 Cent isn't most people. Life on the streets had given him fearlessness.
“Having a brush with death, or being reminded in a dramatic way of the shortness of our lives, can have a positive, therapeutic effect. So it is best to make every moment count, to have a sense of urgency about life.” ― 50 Cent, The 50th Law
50 released a series of mixtapes that caught Eminem's attention and earned him a $50 million deal!
50 Cents turned death into life.
Things happen; that is life.
We want problems solved.
Every human has problems, whether it's Jeff Bezos swimming in his billions, Obama in his comfortable retirement home, or Dan Bilzerian with his hired bikini models.
All problems.
Problems churn through life. solve one, another appears.
It's harsh. Life's unfair. We can face reality or run from it.
The latter will worsen your issues.
“The firmer your grasp on reality, the more power you will have to alter it for your purposes.” — 50 Cent, The 50th Law
In a fantasy-obsessed world, 50 Cent loves reality.
Wish for better problem-solving skills rather than problem-free living.
Don't wish, work.
We All Have the True Power of Alchemy
Humans are arrogant enough to think the universe cares about them.
That things happen as if the universe notices our nanosecond existences.
Things simply happen. Period.
By changing our perspective, we can turn good things bad.
The alchemists' search for the philosopher's stone may have symbolized the ability to turn our lead-like perceptions into gold.
Negativity bias tints our perceptions.
Normal sparring broke your elbow? Rest and rethink your training. Fired? You can improve your skills and get a better job.
Consider Curtis if he had fallen into despair.
The legend we call 50 Cent wouldn’t have existed.
The Best Lesson in Life Ever?
Neither avoid nor fear your reality.
That simple sentence contains every self-help tip and life lesson on Earth.
When reality is all there is, why fear it? avoidance?
Or worse, fleeing?
To accept reality, we must eliminate the words should be, could be, wish it were, and hope it will be.
It is. Period.
Only by accepting reality's chaos can you shape your life.
“Behind me is infinite power. Before me is endless possibility, around me is boundless opportunity. My strength is mental, physical and spiritual.” — 50 Cent
You might also like

Sam Hickmann
3 years ago
What is headline inflation?
Headline inflation is the raw Consumer price index (CPI) reported monthly by the Bureau of labour statistics (BLS). CPI measures inflation by calculating the cost of a fixed basket of goods. The CPI uses a base year to index the current year's prices.
Explaining Inflation
As it includes all aspects of an economy that experience inflation, headline inflation is not adjusted to remove volatile figures. Headline inflation is often linked to cost-of-living changes, which is useful for consumers.
The headline figure doesn't account for seasonality or volatile food and energy prices, which are removed from the core CPI. Headline inflation is usually annualized, so a monthly headline figure of 4% inflation would equal 4% inflation for the year if repeated for 12 months. Top-line inflation is compared year-over-year.
Inflation's downsides
Inflation erodes future dollar values, can stifle economic growth, and can raise interest rates. Core inflation is often considered a better metric than headline inflation. Investors and economists use headline and core results to set growth forecasts and monetary policy.
Core Inflation
Core inflation removes volatile CPI components that can distort the headline number. Food and energy costs are commonly removed. Environmental shifts that affect crop growth can affect food prices outside of the economy. Political dissent can affect energy costs, such as oil production.
From 1957 to 2018, the U.S. averaged 3.64 percent core inflation. In June 1980, the rate reached 13.60%. May 1957 had 0% inflation. The Fed's core inflation target for 2022 is 3%.
Central bank:
A central bank has privileged control over a nation's or group's money and credit. Modern central banks are responsible for monetary policy and bank regulation. Central banks are anti-competitive and non-market-based. Many central banks are not government agencies and are therefore considered politically independent. Even if a central bank isn't government-owned, its privileges are protected by law. A central bank's legal monopoly status gives it the right to issue banknotes and cash. Private commercial banks can only issue demand deposits.
What are living costs?
The cost of living is the amount needed to cover housing, food, taxes, and healthcare in a certain place and time. Cost of living is used to compare the cost of living between cities and is tied to wages. If expenses are higher in a city like New York, salaries must be higher so people can live there.
What's U.S. bureau of labor statistics?
BLS collects and distributes economic and labor market data about the U.S. Its reports include the CPI and PPI, both important inflation measures.

Gareth Willey
3 years ago
I've had these five apps on my phone for a long time.
TOP APPS
Who survives spring cleaning?

Relax. Notion is off-limits. This topic is popular.
(I wrote about it 2 years ago, before everyone else did.) So).
These apps are probably new to you. I hope you find a new phone app after reading this.
Outdooractive
ViewRanger is Google Maps for outdoor enthusiasts.
This app has been so important to me as a freedom-loving long-distance walker and hiker.
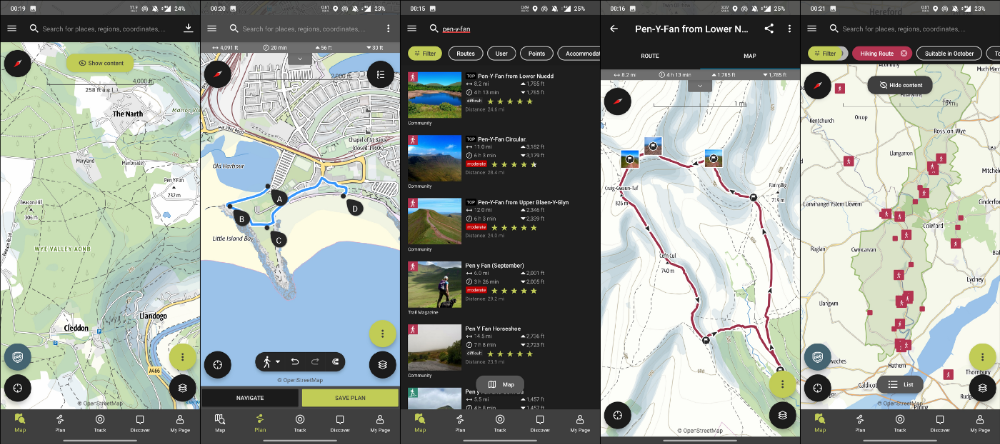
This app shows nearby trails and right-of-ways on top of an Open Street Map.
Helpful detail and data. Any route's distance,
You can download and follow tons of routes planned by app users.
This has helped me find new routes and places a fellow explorer has tried.
Free with non-intrusive ads. Years passed before I subscribed. Pro costs £2.23/month.

This app is for outdoor lovers.
Google Files
New phones come with bloatware. These rushed apps are frustrating.
We must replace these apps. 2017 was Google's year.
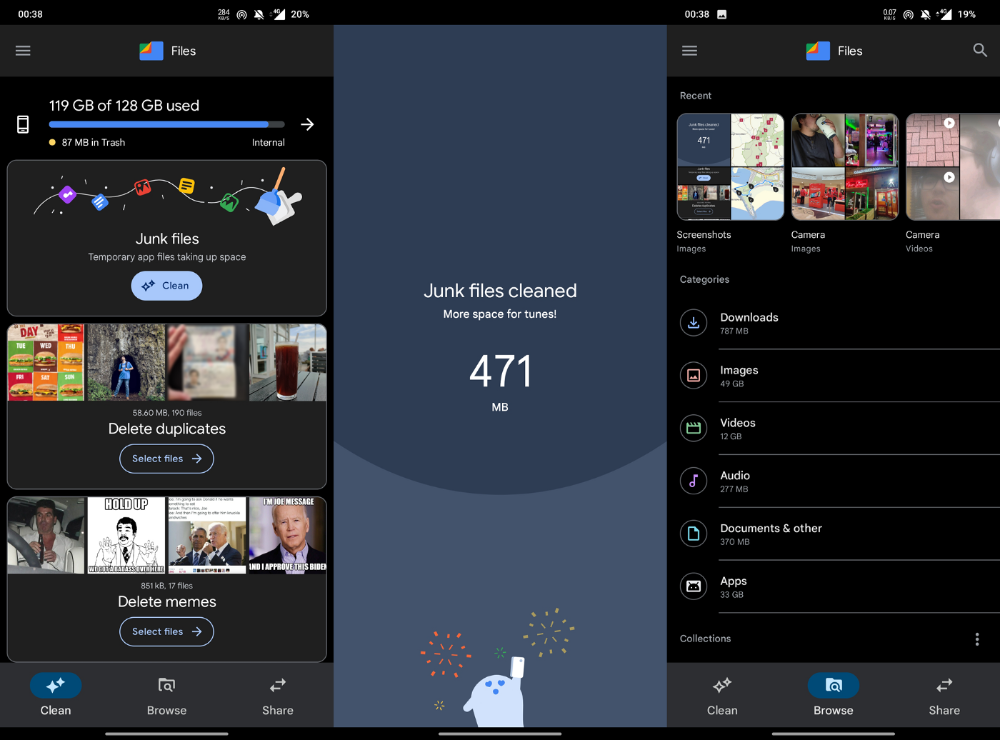
Files is a file manager. It's quick, innovative, and clean. They've given people what they want.
It's easy to organize files, clear space, and clear cache.
I recommend Gallery by Google as a gallery app alternative. It's quick and easy.
Trainline
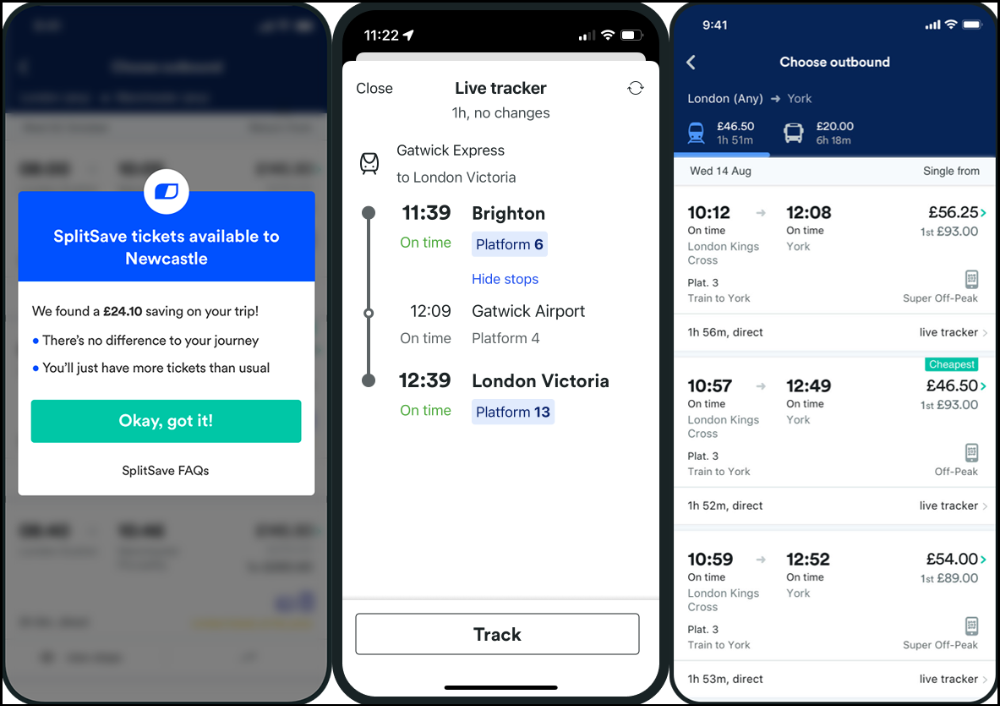
App for trains, buses, and coaches.
I've used this app for years. It did the basics well when I first used it.
Since then, it's improved. It's constantly adding features to make traveling easier and less stressful.
Split-ticketing helps me save hundreds a year on train fares. This app is only available in the UK and Europe.
This service doesn't link to a third-party site. Their app handles everything.
Not all train and coach companies use this app. All the big names are there, though.
Here's more on the app.
Battlefield: Mobile
Play Store has 478,000 games. Few can turn my phone into a console.
Call of Duty Mobile and Asphalt 8/9 are examples.
Asphalt's loot boxes and ads make it unplayable. Call of Duty opens with a few ads. Close them to play without hassle.
This game uses all your phone's features to provide a high-quality, seamless experience. If my internet connection is good, I never experience lag or glitches.
The gameplay is energizing and intense, just like on consoles. Sometimes I'm too involved. I've thrown my phone in anger. I'm totally absorbed.
Customizability is my favorite. Since phones have limited screen space, we should only have the buttons we need, placed conveniently.
Size, opacity, and position are modifiable. Adjust audio, graphics, and textures. It's customizable.
This game has been on my phone for three years. It began well and has gotten better. When I think the creators can't do more, they do.
If you play, read my tips for winning a Battle Royale.
Lightroom
As a photographer, I believe your best camera is on you. The phone.
2017 was a big year for this app. I've tried many photo-editing apps since then. This always wins.
The app is dull. I've never seen better photo editing on a phone.
Adjusting settings and sliders doesn't damage or compress photos. It's detailed.
This is important for phone photos, which are lower quality than professional ones.
Some tools are behind a £4.49/month paywall. Adobe must charge a subscription fee instead of selling licenses. (I'm still bitter about Creative Cloud's price)
Snapseed is my pick. Lightroom is where I do basic editing before moving to Snapseed. Snapseed review:

These apps are great. They cover basic and complex editing needs while traveling.
Final Reflections
I hope you downloaded one of these. Share your favorite apps. These apps are scarce.

Sammy Abdullah
3 years ago
SaaS payback period data
It's ok and even desired to be unprofitable if you're gaining revenue at a reasonable cost and have 100%+ net dollar retention, meaning you never lose customers and expand them. To estimate the acceptable cost of new SaaS revenue, we compare new revenue to operating loss and payback period. If you pay back the customer acquisition cost in 1.5 years and never lose them (100%+ NDR), you're doing well.
To evaluate payback period, we compared new revenue to net operating loss for the last 73 SaaS companies to IPO since October 2017. (55 out of 73). Here's the data. 1/(new revenue/operating loss) equals payback period. New revenue/operating loss equals cost of new revenue.
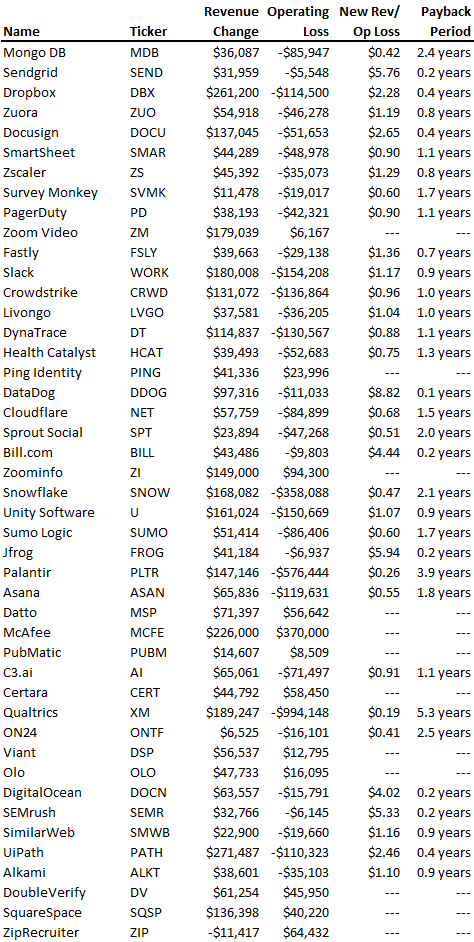
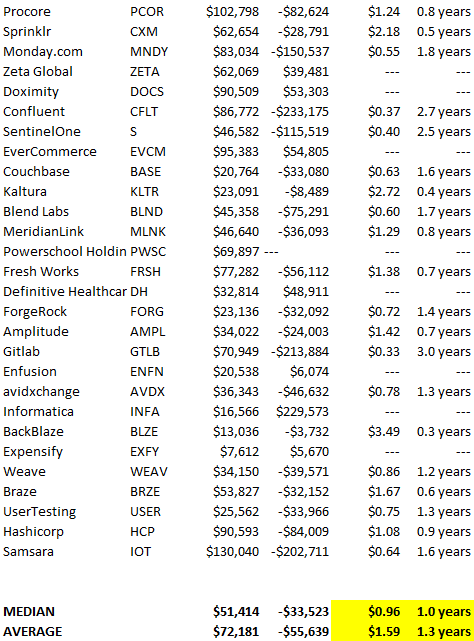
Payback averages a year. 55 SaaS companies that weren't profitable at IPO got a 1-year payback. Outstanding. If you pay for a customer in a year and never lose them (100%+ NDR), you're establishing a valuable business. The average was 1.3 years, which is within the 1.5-year range.
New revenue costs $0.96 on average. These SaaS companies lost $0.96 every $1 of new revenue last year. Again, impressive. Average new revenue per operating loss was $1.59.
Loss-in-operations definition. Operating loss revenue COGS S&M R&D G&A (technical point: be sure to use the absolute value of operating loss). It's wrong to only consider S&M costs and ignore other business costs. Operating loss and new revenue are measured over one year to eliminate seasonality.
Operating losses are desirable if you never lose a customer and have a quick payback period, especially when SaaS enterprises are valued on ARR. The payback period should be under 1.5 years, the cost of new income < $1, and net dollar retention 100%.