


DAOs are legal entities in Marshall Islands.
The Pacific island state recognizes decentralized autonomous organizations.
The Republic of the Marshall Islands has recognized decentralized autonomous organizations (DAOs) as legal entities, giving collectively owned and managed blockchain projects global recognition.
The Marshall Islands' amended the Non-Profit Entities Act 2021 that now recognizes DAOs, which are blockchain-based entities governed by self-organizing communities. Incorporating Admiralty LLC, the island country's first DAO, was made possible thanks to the amendement. MIDAO Directory Services Inc., a domestic organization established to assist DAOs in the Marshall Islands, assisted in the incorporation.
The new law currently allows any DAO to register and operate in the Marshall Islands.
“This is a unique moment to lead,” said Bobby Muller, former Marshall Islands chief secretary and co-founder of MIDAO. He believes DAOs will help create “more efficient and less hierarchical” organizations.
A global hub for DAOs, the Marshall Islands hopes to become a global hub for DAO registration, domicile, use cases, and mass adoption. He added:
"This includes low-cost incorporation, a supportive government with internationally recognized courts, and a technologically open environment."
According to the World Bank, the Marshall Islands is an independent island state in the Pacific Ocean near the Equator. To create a blockchain-based cryptocurrency that would be legal tender alongside the US dollar, the island state has been actively exploring use cases for digital assets since at least 2018.
In February 2018, the Marshall Islands approved the creation of a new cryptocurrency, Sovereign (SOV). As expected, the IMF has criticized the plan, citing concerns that a digital sovereign currency would jeopardize the state's financial stability. They have also criticized El Salvador, the first country to recognize Bitcoin (BTC) as legal tender.
Marshall Islands senator David Paul said the DAO legislation does not pose the same issues as a government-backed cryptocurrency. “A sovereign digital currency is financial and raises concerns about money laundering,” . This is more about giving DAOs legal recognition to make their case to regulators, investors, and consumers.
More on Web3 & Crypto

joyce shen
4 years ago
Framework to Evaluate Metaverse and Web3
Everywhere we turn, there's a new metaverse or Web3 debut. Microsoft recently announced a $68.7 BILLION cash purchase of Activision.
Like AI in 2013 and blockchain in 2014, NFT growth in 2021 feels like this year's metaverse and Web3 growth. We are all bombarded with information, conflicting signals, and a sensation of FOMO.
How can we evaluate the metaverse and Web3 in a noisy, new world? My framework for evaluating upcoming technologies and themes is shown below. I hope you will also find them helpful.
Understand the “pipes” in a new space.
Whatever people say, Metaverse and Web3 will have to coexist with the current Internet. Companies who host, move, and store data over the Internet have a lot of intriguing use cases in Metaverse and Web3, whether in infrastructure, data analytics, or compliance. Hence the following point.
## Understand the apps layer and their infrastructure.
Gaming, crypto exchanges, and NFT marketplaces would not exist today if not for technology that enables rapid app creation. Yes, according to Chainalysis and other research, 30–40% of Ethereum is self-hosted, with the rest hosted by large cloud providers. For Microsoft to acquire Activision makes strategic sense. It's not only about the games, but also the infrastructure that supports them.
Follow the money
Understanding how money and wealth flow in a complex and dynamic environment helps build clarity. Unless you are exceedingly wealthy, you have limited ability to significantly engage in the Web3 economy today. Few can just buy 10 ETH and spend it in one day. You must comprehend who benefits from the process, and how that 10 ETH circulates now and possibly tomorrow. Major holders and players control supply and liquidity in any market. Today, most Web3 apps are designed to increase capital inflow so existing significant holders can utilize it to create a nascent Web3 economy. When you see a new Metaverse or Web3 application, remember how money flows.
What is the use case?
What does the app do? If there is no clear use case with clear makers and consumers solving a real problem, then the euphoria soon fades, and the only stakeholders who remain enthused are those who have too much to lose.
Time is a major competition that is often overlooked.
We're only busier, but each day is still 24 hours. Using new apps may mean that time is lost doing other things. The user must be eager to learn. Metaverse and Web3 vs. our time? I don't think we know the answer yet (at least for working adults whose cost of time is higher).
I don't think we know the answer yet (at least for working adults whose cost of time is higher).
People and organizations need security and transparency.
For new technologies or apps to be widely used, they must be safe, transparent, and trustworthy. What does secure Metaverse and Web3 mean? This is an intriguing subject for both the business and public sectors. Cloud adoption grew in part due to improved security and data protection regulations.
The following frameworks can help analyze and understand new technologies and emerging technological topics, unless you are a significant investment fund with the financial ability to gamble on numerous initiatives and essentially form your own “index fund”.
I write on VC, startups, and leadership.
More on https://www.linkedin.com/in/joycejshen/ and https://joyceshen.substack.com/
This writing is my own opinion and does not represent investment advice.

Vitalik
3 years ago
Fairness alternatives to selling below market clearing prices (or community sentiment, or fun)
When a seller has a limited supply of an item in high (or uncertain and possibly high) demand, they frequently set a price far below what "the market will bear." As a result, the item sells out quickly, with lucky buyers being those who tried to buy first. This has happened in the Ethereum ecosystem, particularly with NFT sales and token sales/ICOs. But this phenomenon is much older; concerts and restaurants frequently make similar choices, resulting in fast sell-outs or long lines.
Why do sellers do this? Economists have long wondered. A seller should sell at the market-clearing price if the amount buyers are willing to buy exactly equals the amount the seller has to sell. If the seller is unsure of the market-clearing price, they should sell at auction and let the market decide. So, if you want to sell something below market value, don't do it. It will hurt your sales and it will hurt your customers. The competitions created by non-price-based allocation mechanisms can sometimes have negative externalities that harm third parties, as we will see.
However, the prevalence of below-market-clearing pricing suggests that sellers do it for good reason. And indeed, as decades of research into this topic has shown, there often are. So, is it possible to achieve the same goals with less unfairness, inefficiency, and harm?
Selling at below market-clearing prices has large inefficiencies and negative externalities
An item that is sold at market value or at an auction allows someone who really wants it to pay the high price or bid high in the auction. So, if a seller sells an item below market value, some people will get it and others won't. But the mechanism deciding who gets the item isn't random, and it's not always well correlated with participant desire. It's not always about being the fastest at clicking buttons. Sometimes it means waking up at 2 a.m. (but 11 p.m. or even 2 p.m. elsewhere). Sometimes it's just a "auction by other means" that's more chaotic, less efficient, and has far more negative externalities.
There are many examples of this in the Ethereum ecosystem. Let's start with the 2017 ICO craze. For example, an ICO project would set the price of the token and a hard maximum for how many tokens they are willing to sell, and the sale would start automatically at some point in time. The sale ends when the cap is reached.
So what? In practice, these sales often ended in 30 seconds or less. Everyone would start sending transactions in as soon as (or just before) the sale started, offering higher and higher fees to encourage miners to include their transaction first. Instead of the token seller receiving revenue, miners receive it, and the sale prices out all other applications on-chain.
The most expensive transaction in the BAT sale set a fee of 580,000 gwei, paying a fee of $6,600 to get included in the sale.
Many ICOs after that tried various strategies to avoid these gas price auctions; one ICO notably had a smart contract that checked the transaction's gasprice and rejected it if it exceeded 50 gwei. But that didn't solve the issue. Buyers hoping to game the system sent many transactions hoping one would get through. An auction by another name, clogging the chain even more.
ICOs have recently lost popularity, but NFTs and NFT sales have risen in popularity. But the NFT space didn't learn from 2017; they do fixed-quantity sales just like ICOs (eg. see the mint function on lines 97-108 of this contract here). So what?
That's not the worst; some NFT sales have caused gas price spikes of up to 2000 gwei.
High gas prices from users fighting to get in first by sending higher and higher transaction fees. An auction renamed, pricing out all other applications on-chain for 15 minutes.
So why do sellers sometimes sell below market price?
Selling below market value is nothing new, and many articles, papers, and podcasts have written (and sometimes bitterly complained) about the unwillingness to use auctions or set prices to market-clearing levels.
Many of the arguments are the same for both blockchain (NFTs and ICOs) and non-blockchain examples (popular restaurants and concerts). Fairness and the desire not to exclude the poor, lose fans or create tension by being perceived as greedy are major concerns. The 1986 paper by Kahneman, Knetsch, and Thaler explains how fairness and greed can influence these decisions. I recall that the desire to avoid perceptions of greed was also a major factor in discouraging the use of auction-like mechanisms in 2017.
Aside from fairness concerns, there is the argument that selling out and long lines create a sense of popularity and prestige, making the product more appealing to others. Long lines should have the same effect as high prices in a rational actor model, but this is not the case in reality. This applies to ICOs and NFTs as well as restaurants. Aside from increasing marketing value, some people find the game of grabbing a limited set of opportunities first before everyone else is quite entertaining.
But there are some blockchain-specific factors. One argument for selling ICO tokens below market value (and one that persuaded the OmiseGo team to adopt their capped sale strategy) is community dynamics. The first rule of community sentiment management is to encourage price increases. People are happy if they are "in the green." If the price drops below what the community members paid, they are unhappy and start calling you a scammer, possibly causing a social media cascade where everyone calls you a scammer.
This effect can only be avoided by pricing low enough that post-launch market prices will almost certainly be higher. But how do you do this without creating a rush for the gates that leads to an auction?
Interesting solutions
It's 2021. We have a blockchain. The blockchain is home to a powerful decentralized finance ecosystem, as well as a rapidly expanding set of non-financial tools. The blockchain also allows us to reset social norms. Where decades of economists yelling about "efficiency" failed, blockchains may be able to legitimize new uses of mechanism design. If we could use our more advanced tools to create an approach that more directly solves the problems, with fewer side effects, wouldn't that be better than fiddling with a coarse-grained one-dimensional strategy space of selling at market price versus below market price?
Begin with the goals. We'll try to cover ICOs, NFTs, and conference tickets (really a type of NFT) all at the same time.
1. Fairness: don't completely exclude low-income people from participation; give them a chance. The goal of token sales is to avoid high initial wealth concentration and have a larger and more diverse initial token holder community.
2. Don’t create races: Avoid situations where many people rush to do the same thing and only a few get in (this is the type of situation that leads to the horrible auctions-by-another-name that we saw above).
3. Don't require precise market knowledge: the mechanism should work even if the seller has no idea how much demand exists.
4. Fun: The process of participating in the sale should be fun and game-like, but not frustrating.
5. Give buyers positive expected returns: in the case of a token (or an NFT), buyers should expect price increases rather than decreases. This requires selling below market value.
Let's start with (1). From Ethereum's perspective, there is a simple solution. Use a tool designed for the job: proof of personhood protocols! Here's one quick idea:
Mechanism 1 Each participant (verified by ID) can buy up to ‘’X’’ tokens at price P, with the option to buy more at an auction.
With the per-person mechanism, buyers can get positive expected returns for the portion sold through the per-person mechanism, and the auction part does not require sellers to understand demand levels. Is it race-free? The number of participants buying through the per-person pool appears to be high. But what if the per-person pool isn't big enough to accommodate everyone?
Make the per-person allocation amount dynamic.
Mechanism 2 Each participant can deposit up to X tokens into a smart contract to declare interest. Last but not least, each buyer receives min(X, N / buyers) tokens, where N is the total sold through the per-person pool (some other amount can also be sold by auction). The buyer gets their deposit back if it exceeds the amount needed to buy their allocation.
No longer is there a race condition based on the number of buyers per person. No matter how high the demand, it's always better to join sooner rather than later.
Here's another idea if you like clever game mechanics with fancy quadratic formulas.
Mechanism 3 Each participant can buy X units at a price P X 2 up to a maximum of C tokens per buyer. C starts low and gradually increases until enough units are sold.
The quantity allocated to each buyer is theoretically optimal, though post-sale transfers will degrade this optimality over time. Mechanisms 2 and 3 appear to meet all of the above objectives. They're not perfect, but they're good starting points.
One more issue. For fixed and limited supply NFTs, the equilibrium purchased quantity per participant may be fractional (in mechanism 2, number of buyers > N, and in mechanism 3, setting C = 1 may already lead to over-subscription). With fractional sales, you can offer lottery tickets: if there are N items available, you have a chance of N/number of buyers of getting the item, otherwise you get a refund. For a conference, groups could bundle their lottery tickets to guarantee a win or a loss. The certainty of getting the item can be auctioned.
The bottom tier of "sponsorships" can be used to sell conference tickets at market rate. You may end up with a sponsor board full of people's faces, but is that okay? After all, John Lilic was on EthCC's sponsor board!
Simply put, if you want to be reliably fair to people, you need an input that explicitly measures people. Authentication protocols do this (and if desired can be combined with zero knowledge proofs to ensure privacy). So we should combine the efficiency of market and auction-based pricing with the equality of proof of personhood mechanics.
Answers to possible questions
Q: Won't people who don't care about your project buy the item and immediately resell it?
A: Not at first. Meta-games take time to appear in practice. If they do, making them untradeable for a while may help mitigate the damage. Using your face to claim that your previous account was hacked and that your identity, including everything in it, should be moved to another account works because proof-of-personhood identities are untradeable.
Q: What if I want to make my item available to a specific community?
A: Instead of ID, use proof of participation tokens linked to community events. Another option, also serving egalitarian and gamification purposes, is to encrypt items within publicly available puzzle solutions.
Q: How do we know they'll accept? Strange new mechanisms have previously been resisted.
A: Having economists write screeds about how they "should" accept a new mechanism that they find strange is difficult (or even "equity"). However, abrupt changes in context effectively reset people's expectations. So the blockchain space is the best place to try this. You could wait for the "metaverse", but it's possible that the best version will run on Ethereum anyway, so start now.

Vivek Singh
4 years ago
A Warm Welcome to Web3 and the Future of the Internet
Let's take a look back at the internet's history and see where we're going — and why.
Tim Berners Lee had a problem. He was at CERN, the world's largest particle physics factory, at the time. The institute's stated goal was to study the simplest particles with the most sophisticated scientific instruments. The institute completed the LEP Tunnel in 1988, a 27 kilometer ring. This was Europe's largest civil engineering project (to study smaller particles — electrons).
The problem Tim Berners Lee found was information loss, not particle physics. CERN employed a thousand people in 1989. Due to team size and complexity, people often struggled to recall past project information. While these obstacles could be overcome, high turnover was nearly impossible. Berners Lee addressed the issue in a proposal titled ‘Information Management'.
When a typical stay is two years, data is constantly lost. The introduction of new people takes a lot of time from them and others before they understand what is going on. An emergency situation may require a detective investigation to recover technical details of past projects. Often, the data is recorded but cannot be found. — Information Management: A Proposal
He had an idea. Create an information management system that allowed users to access data in a decentralized manner using a new technology called ‘hypertext'.
To quote Berners Lee, his proposal was “vague but exciting...”. The paper eventually evolved into the internet we know today. Here are three popular W3C standards used by billions of people today:
(credit: CERN)
HTML (Hypertext Markup)
A web formatting language.
URI (Unique Resource Identifier)
Each web resource has its own “address”. Known as ‘a URL'.
HTTP (Hypertext Transfer Protocol)
Retrieves linked resources from across the web.
These technologies underpin all computer work. They were the seeds of our quest to reorganize information, a task as fruitful as particle physics.
Tim Berners-Lee would probably think the three decades from 1989 to 2018 were eventful. He'd be amazed by the billions, the inspiring, the novel. Unlocking innovation at CERN through ‘Information Management'.
The fictional character would probably need a drink, walk, and a few deep breaths to fully grasp the internet's impact. He'd be surprised to see a few big names in the mix.
Then he'd say, "Something's wrong here."
We should review the web's history before going there. Was it a success after Berners Lee made it public? Web1 and Web2: What is it about what we are doing now that so many believe we need a new one, web3?
Per Outlier Ventures' Jamie Burke:
Web 1.0 was read-only.
Web 2.0 was the writable
Web 3.0 is a direct-write web.
Let's explore.
Web1: The Read-Only Web
Web1 was the digital age. We put our books, research, and lives ‘online'. The web made information retrieval easier than any filing cabinet ever. Massive amounts of data were stored online. Encyclopedias, medical records, and entire libraries were put away into floppy disks and hard drives.
In 2015, the web had around 305,500,000,000 pages of content (280 million copies of Atlas Shrugged).
Initially, one didn't expect to contribute much to this database. Web1 was an online version of the real world, but not yet a new way of using the invention.
One gets the impression that the web has been underutilized by historians if all we can say about it is that it has become a giant global fax machine. — Daniel Cohen, The Web's Second Decade (2004)
That doesn't mean developers weren't building. The web was being advanced by great minds. Web2 was born as technology advanced.
Web2: Read-Write Web
Remember when you clicked something on a website and the whole page refreshed? Is it too early to call the mid-2000s ‘the good old days'?
Browsers improved gradually, then suddenly. AJAX calls augmented CGI scripts, and applications began sending data back and forth without disrupting the entire web page. One button to ‘digg' a post (see below). Web experiences blossomed.
In 2006, Digg was the most active ‘Web 2.0' site. (Photo: Ethereum Foundation Taylor Gerring)
Interaction was the focus of new applications. Posting, upvoting, hearting, pinning, tweeting, liking, commenting, and clapping became a lexicon of their own. It exploded in 2004. Easy ways to ‘write' on the internet grew, and continue to grow.
Facebook became a Web2 icon, where users created trillions of rows of data. Google and Amazon moved from Web1 to Web2 by better understanding users and building products and services that met their needs.
Business models based on Software-as-a-Service and then managing consumer data within them for a fee have exploded.
Web2 Emerging Issues
Unbelievably, an intriguing dilemma arose. When creating this read-write web, a non-trivial question skirted underneath the covers. Who owns it all?
You have no control over [Web 2] online SaaS. People didn't realize this because SaaS was so new. People have realized this is the real issue in recent years.
Even if these organizations have good intentions, their incentive is not on the users' side.
“You are not their customer, therefore you are their product,” they say. With Laura Shin, Vitalik Buterin, Unchained
A good plot line emerges. Many amazing, world-changing software products quietly lost users' data control.
For example: Facebook owns much of your social graph data. Even if you hate Facebook, you can't leave without giving up that data. There is no ‘export' or ‘exit'. The platform owns ownership.
While many companies can pull data on you, you cannot do so.
On the surface, this isn't an issue. These companies use my data better than I do! A complex group of stakeholders, each with their own goals. One is maximizing shareholder value for public companies. Tim Berners-Lee (and others) dislike the incentives created.
“Show me the incentive and I will show you the outcome.” — Berkshire Hathaway's CEO
It's easy to see what the read-write web has allowed in retrospect. We've been given the keys to create content instead of just consume it. On Facebook and Twitter, anyone with a laptop and internet can participate. But the engagement isn't ours. Platforms own themselves.
Web3: The ‘Unmediated’ Read-Write Web
Tim Berners Lee proposed a decade ago that ‘linked data' could solve the internet's data problem.
However, until recently, the same principles that allowed the Web of documents to thrive were not applied to data...
The Web of Data also allows for new domain-specific applications. Unlike Web 2.0 mashups, Linked Data applications work with an unbound global data space. As new data sources appear on the Web, they can provide more complete answers.
At around the same time as linked data research began, Satoshi Nakamoto created Bitcoin. After ten years, it appears that Berners Lee's ideas ‘link' spiritually with cryptocurrencies.
What should Web 3 do?
Here are some quick predictions for the web's future.
Users' data:
Users own information and provide it to corporations, businesses, or services that will benefit them.
Defying censorship:
No government, company, or institution should control your access to information (1, 2, 3)
Connect users and platforms:
Create symbiotic rather than competitive relationships between users and platform creators.
Open networks:
“First, the cryptonetwork-participant contract is enforced in open source code. Their voices and exits are used to keep them in check.” Dixon, Chris (4)
Global interactivity:
Transacting value, information, or assets with anyone with internet access, anywhere, at low cost
Self-determination:
Giving you the ability to own, see, and understand your entire digital identity.
Not pull, push:
‘Push' your data to trusted sources instead of ‘pulling' it from others.
Where Does This Leave Us?
Change incentives, change the world. Nick Babalola
People believe web3 can help build a better, fairer system. This is not the same as equal pay or outcomes, but more equal opportunity.
It should be noted that some of these advantages have been discussed previously. Will the changes work? Will they make a difference? These unanswered questions are technical, economic, political, and philosophical. Unintended consequences are likely.
We hope Web3 is a more democratic web. And we think incentives help the user. If there’s one thing that’s on our side, it’s that open has always beaten closed, given a long enough timescale.
We are at the start.
You might also like

Maria Urkedal York
3 years ago
When at work, don't give up; instead, think like a designer.
How to reframe irritation and go forward

“… before you can figure out where you are going, you need to know where you are, and once you know and accept where you are, you can design your way to where you want to be.” — Bill Burnett and Dave Evans
“You’ve been here before. But there are some new ingredients this time. What can tell yourself that will make you understand that now isn’t just like last year? That there’s something new in this August.”
My coach paused. I sighed, inhaled deeply, and considered her question.
What could I say? I simply needed a plan from her so everything would fall into place and I could be the happy, successful person I want to be.
Time passed. My mind was exhausted from running all morning, all summer, or the last five years, searching for what to do next and how to get there.
Calmer, I remembered that my coach's inquiry had benefited me throughout the summer. The month before our call, I read Designing Your Work Life — How to Thrive and Change and Find Happiness at Work from Standford University’s Bill Burnett and Dave Evans.
A passage in their book felt like a lifeline: “We have something important to say to you: Wherever you are in your work life, whatever job you are doing, it’s good enough. For now. Not forever. For now.”
As I remembered this book on the coaching call, I wondered if I could embrace where I am in August and say my job life is good enough for now. Only temporarily.
I've done that since. I'm getting unstuck.
Here's how you can take the first step in any area where you feel stuck.
How to acquire the perspective of "Good enough for now" for yourself
We’ve all heard the advice to just make the best of a bad situation. That´s not bad advice, but if you only make the best of a bad situation, you are still in a bad situation. It doesn’t get to the root of the problem or offer an opportunity to change the situation. You’re more cheerfully navigating lousiness, which is an improvement, but not much of one and rather hard to sustain over time.” — Bill Burnett and Dave Evans
Reframing Burnett at Evans says good enough for now is the key to being happier at work. Because, as they write, a designer always has options.
Choosing to believe things are good enough for now is liberating. It helps us feel less victimized and less judged. Accepting our situation helps us become unstuck.
Let's break down the process, which designers call constructing your way ahead, into steps you can take today.
Writing helps get started. First, write down your challenge and why it's essential to you. If pen and paper help, try this strategy:
Make the decision to accept the circumstance as it is. Designers always begin by acknowledging the truth of the situation. You now refrain from passing judgment. Instead, you simply describe the situation as accurately as you can. This frees us from negative thought patterns that prevent us from seeing the big picture and instead keep us in a tunnel of negativity.
Look for a reframing right now. Begin with good enough for the moment. Take note of how your body feels as a result. Tell yourself repeatedly that whatever is occurring is sufficient for the time being. Not always, but just now. If you want to, you can even put it in writing and repeatedly breathe it in, almost like a mantra.
You can select a reframe that is more relevant to your situation once you've decided that you're good enough for now and have allowed yourself to believe it. Try to find another perspective that is possible, for instance, if you feel unappreciated at work and your perspective of I need to use and be recognized for all my new skills in my job is making you sad and making you want to resign. For instance, I can learn from others at work and occasionally put my new abilities to use.
After that, leave your mind and act in accordance with your new perspective. Utilize the designer's bias for action to test something out and create a prototype that you can learn from. Your beginning point for creating experiences that will support the new viewpoint derived from the aforementioned point is the new perspective itself. By doing this, you recognize a circumstance at work where you can provide value to yourself or your workplace and then take appropriate action. Send two or three coworkers from whom you wish to learn anything an email, for instance, asking them to get together for coffee or a talk.
Choose tiny, doable actions. You prioritize them at work.
Let's assume you're feeling disconnected at work, so you make a list of folks you may visit each morning or invite to lunch. If you're feeling unmotivated and tired, take a daily walk and treat yourself to a decent coffee.
This may be plenty for now. If you want to take this procedure further, use Burnett and Evans' internet tools and frameworks.
Developing the daily practice of reframing
“We’re not discontented kids in the backseat of the family minivan, but how many of us live our lives, especially our work lives, as if we are?” — Bill Burnett and Dave Evans
I choose the good enough for me perspective every day, often. No quick fix. Am a failing? Maybe a little bit, but I like to think of it more as building muscle.
This way, every time I tell myself it's ok, I hear you. For now, that muscle gets stronger.
Hopefully, reframing will become so natural for us that it will become a habit, and not a technique anymore.
If you feel like you’re stuck in your career or at work, the reframe of Good enough, for now, might be valuable, so just go ahead and try it out right now.
And while you’re playing with this, why not think of other areas of your life too, like your relationships, where you live — even your writing, and see if you can feel a shift?

Jess Rifkin
3 years ago
As the world watches the Russia-Ukraine border situation, This bill would bar aid to Ukraine until the Mexican border is secured.
Although Mexico and Ukraine are thousands of miles apart, this legislation would link their responses.
Context
Ukraine was a Soviet republic until 1991. A significant proportion of the population, particularly in the east, is ethnically Russian. In February, the Russian military invaded Ukraine, intent on overthrowing its democratically elected government.
This could be the biggest European land invasion since WWII. In response, President Joe Biden sent 3,000 troops to NATO countries bordering Ukraine to help with Ukrainian refugees, with more troops possible if the situation worsened.
In July 2021, the US Border Patrol reported its highest monthly encounter total since March 2000. Some Republicans compare Biden's response to the Mexican border situation to his response to the Ukrainian border situation, though the correlation is unclear.
What the bills do
Two new Republican bills seek to link the US response to Ukraine to the situation in Mexico.
The Secure America's Borders First Act would prohibit federal funding for Ukraine until the US-Mexico border is “operationally controlled,” including a wall as promised by former President Donald Trump. (The bill even mandates a 30-foot-high wall.)
The USB (Ukraine and Southern Border) Act, introduced on February 8 by Rep. Matt Rosendale (R-MT0), would allow the US to support Ukraine, but only if the number of Armed Forces deployed there is less than the number deployed to the Mexican border. Madison Cawthorne introduced H.R. 6665 on February 9th (R-NC11).
What backers say
Supporters argue that even if the US should militarily assist Ukraine, our own domestic border situation should take precedence.
After failing to secure our own border and protect our own territorial integrity, ‘America Last' politicians on both sides of the aisle now tell us that we must do so for Ukraine. “Before rushing America into another foreign conflict over an Eastern European nation's border thousands of miles from our shores, they should first secure our southern border.”
“If Joe Biden truly cared about Americans, he would prioritize national security over international affairs,” Rep. Cawthorn said in a separate press release. The least we can do to secure our own country is send the same number of troops to the US-Mexico border to assist our border patrol agents working diligently to secure America.
What opponents say
The president has defended his Ukraine and Mexico policies, stating that both seek peace and diplomacy.
Our nations [the US and Mexico] have a long and complicated history, and we haven't always been perfect neighbors, but we have seen the power and purpose of cooperation,” Biden said in 2021. “We're safer when we work together, whether it's to manage our shared border or stop the pandemic. [In both the Obama and Biden administration], we made a commitment that we look at Mexico as an equal, not as somebody who is south of our border.”
No mistake: If Russia goes ahead with its plans, it will be responsible for a catastrophic and unnecessary war of choice. To protect our collective security, the United States and our allies are ready to defend every inch of NATO territory. We won't send troops into Ukraine, but we will continue to support the Ukrainian people... But, I repeat, Russia can choose diplomacy. It is not too late to de-escalate and return to the negotiating table.”
Odds of passage
The Secure America's Borders First Act has nine Republican sponsors. Either the House Armed Services or Foreign Affairs Committees may vote on it.
Rep. Paul Gosar, a Republican, co-sponsored the USB Act (R-AZ4). The House Armed Services Committee may vote on it.
With Republicans in control, passage is unlikely.

Arthur Hayes
3 years ago
Contagion
(The author's opinions should not be used to make investment decisions or as a recommendation to invest.)

The pandemic and social media pseudoscience have made us all epidemiologists, for better or worse. Flattening the curve, social distancing, lockdowns—remember? Some of you may remember R0 (R naught), the number of healthy humans the average COVID-infected person infects. Thankfully, the world has moved on from Greater China's nightmare. Politicians have refocused their talent for misdirection on getting their constituents invested in the war for Russian Reunification or Russian Aggression, depending on your side of the iron curtain.
Humanity battles two fronts. A war against an invisible virus (I know your Commander in Chief might have told you COVID is over, but viruses don't follow election cycles and their economic impacts linger long after the last rapid-test clinic has closed); and an undeclared World War between US/NATO and Eurasia/Russia/China. The fiscal and monetary authorities' current policies aim to mitigate these two conflicts' economic effects.
Since all politicians are short-sighted, they usually print money to solve most problems. Printing money is the easiest and fastest way to solve most problems because it can be done immediately without much discussion. The alternative—long-term restructuring of our global economy—would hurt stakeholders and require an honest discussion about our civilization's state. Both of those requirements are non-starters for our short-sighted political friends, so whether your government practices capitalism, communism, socialism, or fascism, they all turn to printing money-ism to solve all problems.
Free money stimulates demand, so people buy crap. Overbuying shit raises prices. Inflation. Every nation has food, energy, or goods inflation. The once-docile plebes demand action when the latter two subsets of inflation rise rapidly. They will be heard at the polls or in the streets. What would you do to feed your crying hungry child?
Global central banks During the pandemic, the Fed, PBOC, BOJ, ECB, and BOE printed money to aid their governments. They worried about inflation and promised to remove fiat liquidity and tighten monetary conditions.
Imagine Nate Diaz's round-house kick to the face. The financial markets probably felt that way when the US and a few others withdrew fiat wampum. Sovereign debt markets suffered a near-record bond market rout.
The undeclared WW3 is intensifying, with recent gas pipeline attacks. The global economy is already struggling, and credit withdrawal will worsen the situation. The next pandemic, the Yield Curve Control (YCC) virus, is spreading as major central banks backtrack on inflation promises. All central banks eventually fail.
Here's a scorecard.
In order to save its financial system, BOE recently reverted to Quantitative Easing (QE).
BOJ Continuing YCC to save their banking system and enable affordable government borrowing.
ECB printing money to buy weak EU member bonds, but will soon start Quantitative Tightening (QT).
PBOC Restarting the money printer to give banks liquidity to support the falling residential property market.
Fed raising rates and QT-shrinking balance sheet.
80% of the world's biggest central banks are printing money again. Only the Fed has remained steadfast in the face of a financial market bloodbath, determined to end the inflation for which it is at least partially responsible—the culmination of decades of bad economic policies and a world war.
YCC printing is the worst for fiat currency and society. Because it necessitates central banks fixing a multi-trillion-dollar bond market. YCC central banks promise to infinitely expand their balance sheets to keep a certain interest rate metric below an unnatural ceiling. The market always wins, crushing humanity with inflation.
BOJ's YCC policy is longest-standing. The BOE joined them, and my essay this week argues that the ECB will follow. The ECB joining YCC would make 60% of major central banks follow this terrible policy. Since the PBOC is part of the Chinese financial system, the number could be 80%. The Chinese will lend any amount to meet their economic activity goals.
The BOE committed to a 13-week, GBP 65bn bond price-fixing operation. However, BOEs YCC may return. If you lose to the market, you're stuck. Since the BOE has announced that it will buy your Gilt at inflated prices, why would you not sell them all? Market participants taking advantage of this policy will only push the bank further into the hole it dug itself, so I expect the BOE to re-up this program and count them as YCC.
In a few trading days, the BOE went from a bank determined to slay inflation by raising interest rates and QT to buying an unlimited amount of UK Gilts. I expect the ECB to be dragged kicking and screaming into a similar policy. Spoiler alert: big daddy Fed will eventually die from the YCC virus.
Threadneedle St, London EC2R 8AH, UK
Before we discuss the BOE's recent missteps, a chatroom member called the British royal family the Kardashians with Crowns, which made me laugh. I'm sad about royal attention. If the public was as interested in energy and economic policies as they are in how the late Queen treated Meghan, Duchess of Sussex, UK politicians might not have been able to get away with energy and economic fairy tales.
The BOE printed money to recover from COVID, as all good central banks do. For historical context, this chart shows the BOE's total assets as a percentage of GDP since its founding in the 18th century.
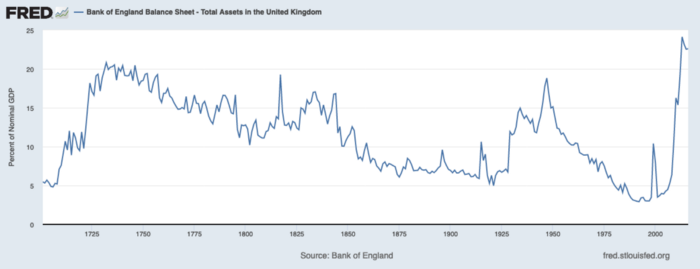
The UK has had a rough three centuries. Pandemics, empire wars, civil wars, world wars. Even so, the BOE's recent money printing was its most aggressive ever!
BOE Total Assets as % of GDP (white) vs. UK CPI
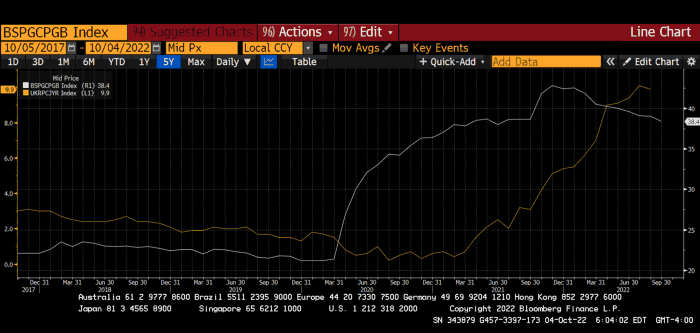
Now, inflation responded slowly to the bank's most aggressive monetary loosening. King Charles wishes the gold line above showed his popularity, but it shows his subjects' suffering.
The BOE recognized early that its money printing caused runaway inflation. In its August 2022 report, the bank predicted that inflation would reach 13% by year end before aggressively tapering in 2023 and 2024.
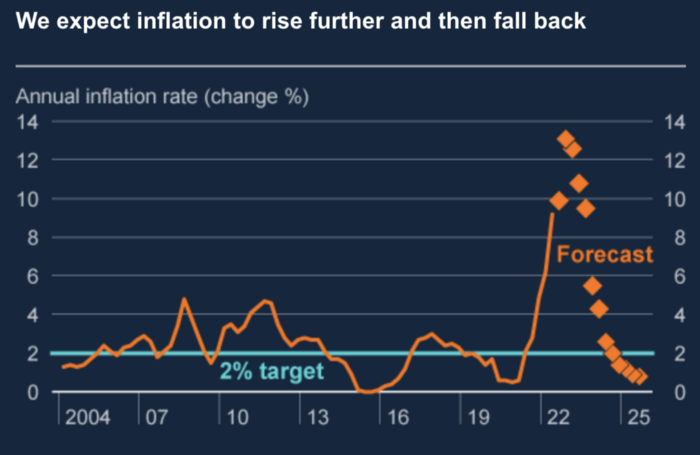
Aug 2022 BOE Monetary Policy Report
The BOE was the first major central bank to reduce its balance sheet and raise its policy rate to help.
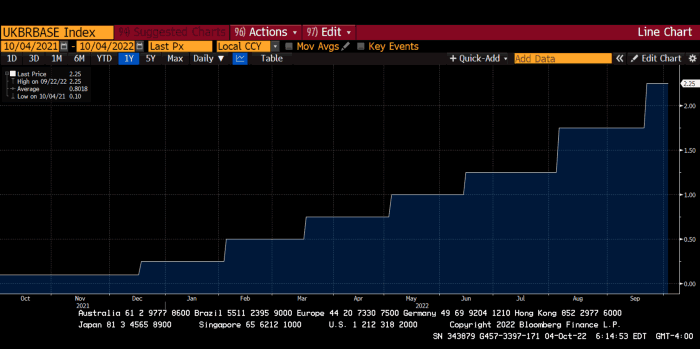
The BOE first raised rates in December 2021. Back then, JayPow wasn't even considering raising rates.
UK policymakers, like most developed nations, believe in energy fairy tales. Namely, that the developed world, which grew in lockstep with hydrocarbon use, could switch to wind and solar by 2050. The UK's energy import bill has grown while coal, North Sea oil, and possibly stranded shale oil have been ignored.
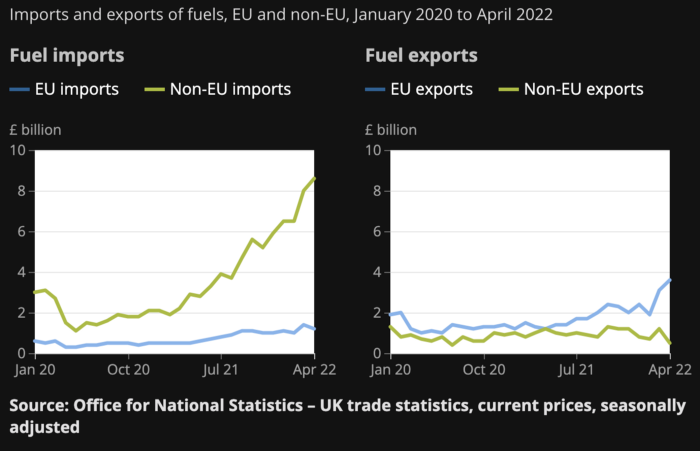
WW3 is an economic war that is balkanizing energy markets, which will continue to inflate. A nation that imports energy and has printed the most money in its history cannot avoid inflation.
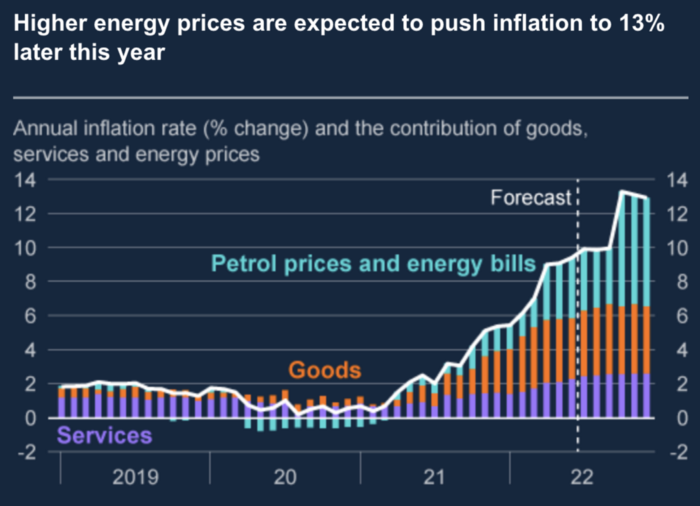
The chart above shows that energy inflation is a major cause of plebe pain.
The UK is hit by a double whammy: the BOE must remove credit to reduce demand, and energy prices must rise due to WW3 inflation. That's not economic growth.
Boris Johnson was knocked out by his country's poor economic performance, not his lockdown at 10 Downing St. Prime Minister Truss and her merry band of fools arrived with the tried-and-true government remedy: goodies for everyone.
She released a budget full of economic stimulants. She cut corporate and individual taxes for the rich. She plans to give poor people vouchers for higher energy bills. Woohoo! Margret Thatcher's new pants suit.
My buddy Jim Bianco said Truss budget's problem is that it works. It will boost activity at a time when inflation is over 10%. Truss' budget didn't include austerity measures like tax increases or spending cuts, which the bond market wanted. The bond market protested.
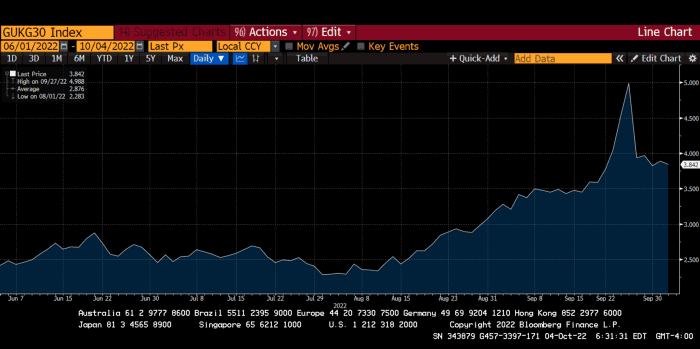
30-year Gilt yield chart. Yields spiked the most ever after Truss announced her budget, as shown. The Gilt market is the longest-running bond market in the world.
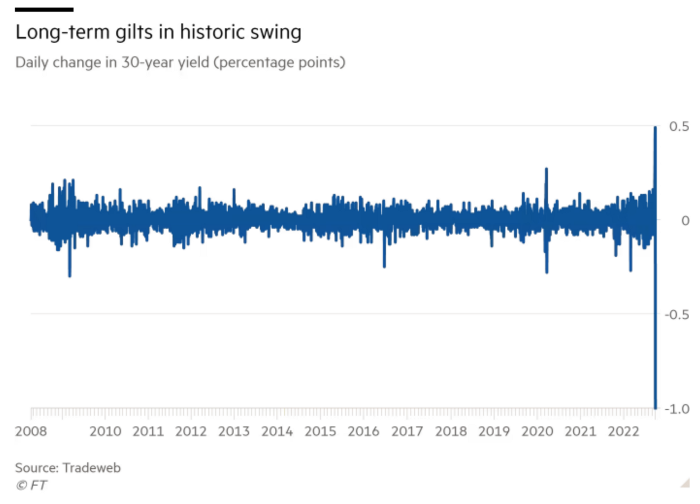
The Gilt market showed the pole who's boss with Cardi B.
Before this, the BOE was super-committed to fighting inflation. To their credit, they raised short-term rates and shrank their balance sheet. However, rapid yield rises threatened to destroy the entire highly leveraged UK financial system overnight, forcing them to change course.
Accounting gimmicks allowed by regulators for pension funds posed a systemic threat to the UK banking system. UK pension funds could use interest rate market levered derivatives to match liabilities. When rates rise, short rate derivatives require more margin. The pension funds spent all their money trying to pick stonks and whatever else their sell side banker could stuff them with, so the historic rate spike would have bankrupted them overnight. The FT describes BOE-supervised chicanery well.
To avoid a financial apocalypse, the BOE in one morning abandoned all their hard work and started buying unlimited long-dated Gilts to drive prices down.
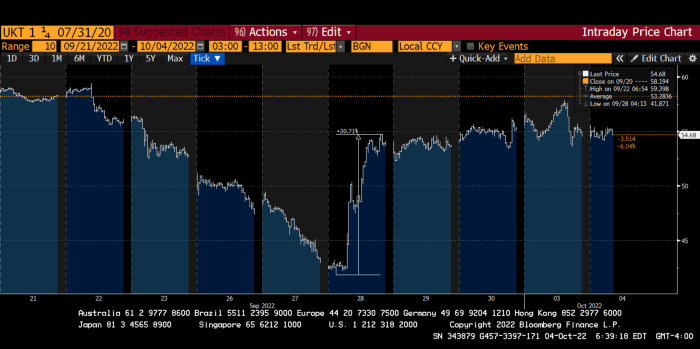
Another reminder to never fight a central bank. The 30-year Gilt is shown above. After the BOE restarted the money printer on September 28, this bond rose 30%. Thirty-fucking-percent! Developed market sovereign bonds rarely move daily. You're invested in His Majesty's government obligations, not a Chinese property developer's offshore USD bond.
The political need to give people goodies to help them fight the terrible economy ran into a financial reality. The central bank protected the UK financial system from asset-price deflation because, like all modern economies, it is debt-based and highly levered. As bad as it is, inflation is not their top priority. The BOE example demonstrated that. To save the financial system, they abandoned almost a year of prudent monetary policy in a few hours. They also started the endgame.
Let's play Central Bankers Say the Darndest Things before we go to the continent (and sorry if you live on a continent other than Europe, but you're not culturally relevant).
Pre-meltdown BOE output:
FT, October 17, 2021 On Sunday, the Bank of England governor warned that it must act to curb inflationary pressure, ignoring financial market moves that have priced in the first interest rate increase before the end of the year.
On July 19, 2022, Gov. Andrew Bailey spoke. Our 2% inflation target is unwavering. We'll do our job.
August 4th 2022 MPC monetary policy announcement According to its mandate, the MPC will sustainably return inflation to 2% in the medium term.
Catherine Mann, MPC member, September 5, 2022 speech. Fast and forceful monetary tightening, possibly followed by a hold or reversal, is better than gradualism because it promotes inflation expectations' role in bringing inflation back to 2% over the medium term.
When their financial system nearly collapsed in one trading session, they said:
The Bank of England's Financial Policy Committee warned on 28 September that gilt market dysfunction threatened UK financial stability. It advised action and supported the Bank's urgent gilt market purchases for financial stability.
It works when the price goes up but not down. Is my crypto portfolio dysfunctional enough to get a BOE bailout?
Next, the EU and ECB. The ECB is also fighting inflation, but it will also succumb to the YCC virus for the same reasons as the BOE.
Frankfurt am Main, ECB Tower, Sonnemannstraße 20, 60314
Only France and Germany matter economically in the EU. Modern European history has focused on keeping Germany and Russia apart. German manufacturing and cheap Russian goods could change geopolitics.
France created the EU to keep Germany down, and the Germans only cooperated because of WWII guilt. France's interests are shared by the US, which lurks in the shadows to prevent a Germany-Russia alliance. A weak EU benefits US politics. Avoid unification of Eurasia. (I paraphrased daddy Felix because I thought quoting a large part of his most recent missive would get me spanked.)
As with everything, understanding Germany's energy policy is the best way to understand why the German economy is fundamentally fucked and why that spells doom for the EU. Germany, the EU's main economic engine, is being crippled by high energy prices, threatening a depression. This economic downturn threatens the union. The ECB may have to abandon plans to shrink its balance sheet and switch to YCC to save the EU's unholy political union.
France did the smart thing and went all in on nuclear energy, which is rare in geopolitics. 70% of electricity is nuclear-powered. Their manufacturing base can survive Russian gas cuts. Germany cannot.
My boy Zoltan made this great graphic showing how screwed Germany is as cheap Russian gas leaves the industrial economy.
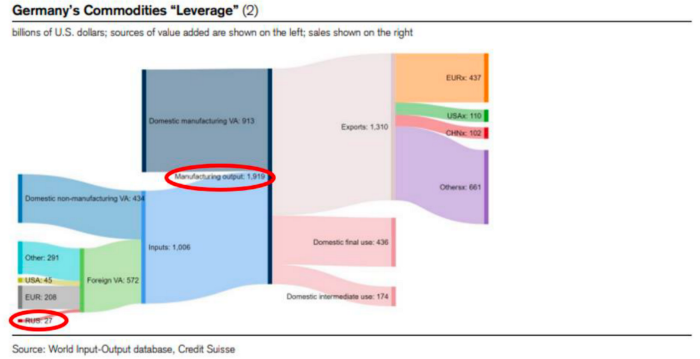
$27 billion of Russian gas powers almost $2 trillion of German economic output, a 75x energy leverage. The German public was duped into believing the same energy fairy tales as their politicians, and they overwhelmingly allowed the Green party to dismantle any efforts to build a nuclear energy ecosystem over the past several decades. Germany, unlike France, must import expensive American and Qatari LNG via supertankers due to Nordstream I and II pipeline sabotage.
American gas exports to Europe are touted by the media. Gas is cheap because America isn't the Western world's swing producer. If gas prices rise domestically in America, the plebes would demand the end of imports to avoid paying more to heat their homes.
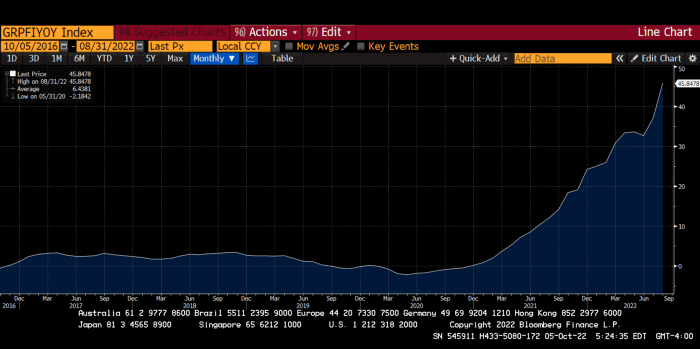
German goods would cost much more in this scenario. German producer prices rose 46% YoY in August. The German current account is rapidly approaching zero and will soon be negative.
German PPI Change YoY
German Current Account
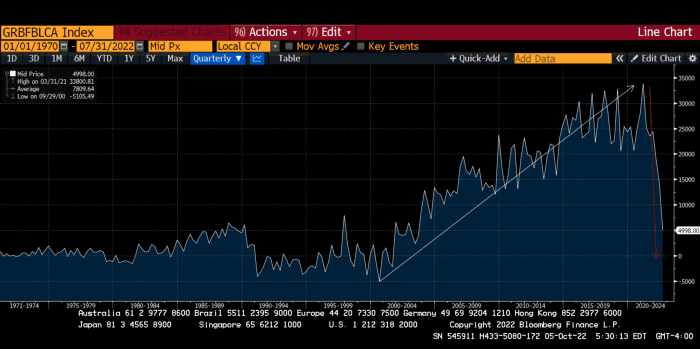
The reason this matters is a curious construction called TARGET2. Let’s hear from the horse’s mouth what exactly this beat is:
TARGET2 is the real-time gross settlement (RTGS) system owned and operated by the Eurosystem. Central banks and commercial banks can submit payment orders in euro to TARGET2, where they are processed and settled in central bank money, i.e. money held in an account with a central bank.
Source: ECB
Let me explain this in plain English for those unfamiliar with economic dogma.
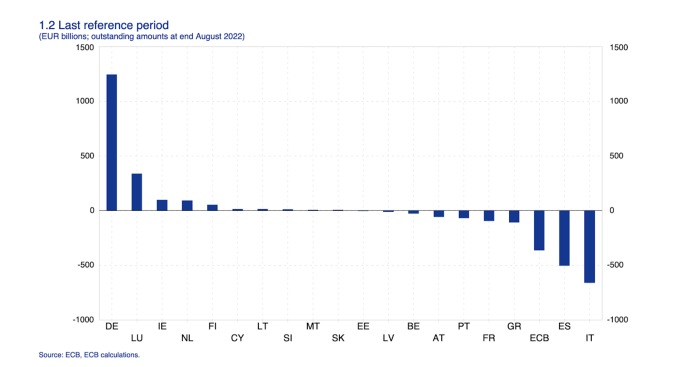
This chart shows intra-EU credits and debits. TARGET2. Germany, Europe's powerhouse, is owed money. IOU-buying Greeks buy G-wagons. The G-wagon pickup truck is badass.

If all EU countries had fiat currencies, the Deutsche Mark would be stronger than the Italian Lira, according to the chart above. If Europe had to buy goods from non-EU countries, the Euro would be much weaker. Credits and debits between smaller political units smooth out imbalances in other federal-provincial-state political systems. Financial and fiscal unions allow this. The EU is financial, so the centre cannot force the periphery to settle their imbalances.
Greece has never had to buy Fords or Kias instead of BMWs, but what if Germany had to shut down its auto manufacturing plants due to energy shortages?
Italians have done well buying ammonia from Germany rather than China, but what if BASF had to close its Ludwigshafen facility due to a lack of affordable natural gas?
I think you're seeing the issue.
Instead of Germany, EU countries would owe foreign producers like America, China, South Korea, Japan, etc. Since these countries aren't tied into an uneconomic union for politics, they'll demand hard fiat currency like USD instead of Euros, which have become toilet paper (or toilet plastic).
Keynesian economists have a simple solution for politicians who can't afford market prices. Government debt can maintain production. The debt covers the difference between what a business can afford and the international energy market price.
Germans are monetary policy conservative because of the Weimar Republic's hyperinflation. The Bundesbank is the only thing preventing ECB profligacy. Germany must print its way out without cheap energy. Like other nations, they will issue more bonds for fiscal transfers.
More Bunds mean lower prices. Without German monetary discipline, the Euro would have become a trash currency like any other emerging market that imports energy and food and has uncompetitive labor.
Bunds price all EU country bonds. The ECB's money printing is designed to keep the spread of weak EU member bonds vs. Bunds low. Everyone falls with Bunds.
Like the UK, German politicians seeking re-election will likely cause a Bunds selloff. Bond investors will understandably reject their promises of goodies for industry and individuals to offset the lack of cheap Russian gas. Long-dated Bunds will be smoked like UK Gilts. The ECB will face a wave of ultra-levered financial players who will go bankrupt if they mark to market their fixed income derivatives books at higher Bund yields.
Some treats People: Germany will spend 200B to help consumers and businesses cope with energy prices, including promoting renewable energy.
That, ladies and germs, is why the ECB will immediately abandon QT, move to a stop-gap QE program to normalize the Bund and every other EU bond market, and eventually graduate to YCC as the market vomits bonds of all stripes into Christine Lagarde's loving hands. She probably has soft hands.
The 30-year Bund market has noticed Germany's economic collapse. 2021 yields skyrocketed.
30-year Bund Yield
ECB Says the Darndest Things:
Because inflation is too high and likely to stay above our target for a long time, we took today's decision and expect to raise interest rates further.- Christine Lagarde, ECB Press Conference, Sept 8.
The Governing Council will adjust all of its instruments to stabilize inflation at 2% over the medium term. July 21 ECB Monetary Decision
Everyone struggles with high inflation. The Governing Council will ensure medium-term inflation returns to two percent. June 9th ECB Press Conference
I'm excited to read the after. Like the BOE, the ECB may abandon their plans to shrink their balance sheet and resume QE due to debt market dysfunction.
Eighty Percent
I like YCC like dark chocolate over 80%. ;).
Can 80% of the world's major central banks' QE and/or YCC overcome Sir Powell's toughness on fungible risky asset prices?
Gold and crypto are fungible global risky assets. Satoshis and gold bars are the same in New York, London, Frankfurt, Tokyo, and Shanghai.
As more Euros, Yen, Renminbi, and Pounds are printed, people will move their savings into Dollars or other stores of value. As the Fed raises rates and reduces its balance sheet, the USD will strengthen. Gold/EUR and BTC/JPY may also attract buyers.
Gold and crypto markets are much smaller than the trillions in fiat money that will be printed, so they will appreciate in non-USD currencies. These flows only matter in one instance because we trade the global or USD price. Arbitrage occurs when BTC/EUR rises faster than EUR/USD. Here is how it works:
An investor based in the USD notices that BTC is expensive in EUR terms.
Instead of buying BTC, this investor borrows USD and then sells it.
After that, they sell BTC and buy EUR.
Then they choose to sell EUR and buy USD.
The investor receives their profit after repaying the USD loan.
This triangular FX arbitrage will align the global/USD BTC price with the elevated EUR, JPY, CNY, and GBP prices.
Even if the Fed continues QT, which I doubt they can do past early 2023, small stores of value like gold and Bitcoin may rise as non-Fed central banks get serious about printing money.
“Arthur, this is just more copium,” you might retort.
Patience. This takes time. Economic and political forcing functions take time. The BOE example shows that bond markets will reject politicians' policies to appease voters. Decades of bad energy policy have no immediate fix. Money printing is the only politically viable option. Bond yields will rise as bond markets see more stimulative budgets, and the over-leveraged fiat debt-based financial system will collapse quickly, followed by a monetary bailout.
America has enough food, fuel, and people. China, Europe, Japan, and the UK suffer. America can be autonomous. Thus, the Fed can prioritize domestic political inflation concerns over supplying the world (and most of its allies) with dollars. A steady flow of dollars allows other nations to print their currencies and buy energy in USD. If the strongest player wins, everyone else loses.
I'm making a GDP-weighted index of these five central banks' money printing. When ready, I'll share its rate of change. This will show when the 80%'s money printing exceeds the Fed's tightening.