


More on Personal Growth
Tom Connor
3 years ago
12 mental models that I use frequently
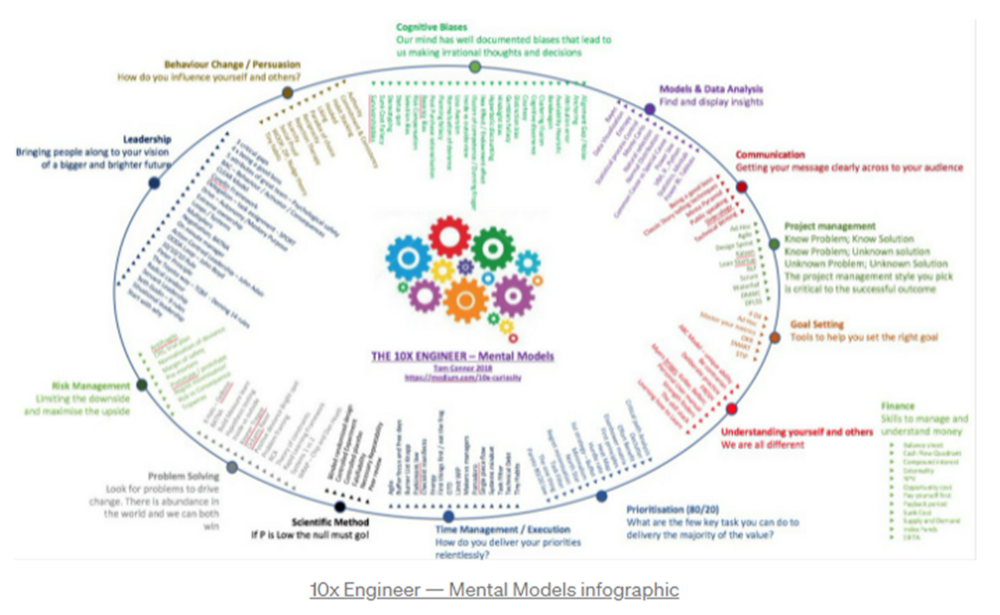
https://tomconnor.me/wp-content/uploads/2021/08/10x-Engineer-Mental-Models.pdf
I keep returning to the same mental models and tricks after writing and reading about a wide range of topics.
Top 12 mental models
12.
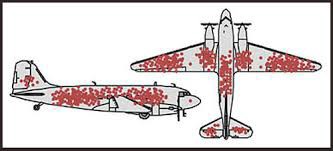
Survival bias - We perceive the surviving population as remarkable, yet they may have gotten there through sheer grit.
Survivorship bias affects us in many situations. Our retirement fund; the unicorn business; the winning team. We often study and imitate the last one standing. This can lead to genuine insights and performance improvements, but it can also lead us astray because the leader may just be lucky.
11.
The Helsinki Bus Theory - How to persevere Buss up!
Always display new work, and always be compared to others. Why? Easy. Keep riding. Stay on the fucking bus.
10.
Until it sticks… Turning up every day… — Artists teach engineers plenty. Quality work over a career comes from showing up every day and starting.
9.
WRAP decision making process (Heath Brothers)
Decision-making WRAP Model:
W — Widen your Options
R — Reality test your assumptions
A — Attain Distance
P — Prepare to be wrong or Right
8.
Systems for knowledge worker excellence - Todd Henry and Cal Newport write about techniques knowledge workers can employ to build a creative rhythm and do better work.
Todd Henry's FRESH framework:
Focus: Keep the start in mind as you wrap up.
Relationships: close a loop that's open.
Pruning is an energy.
Set aside time to be inspired by stimuli.
Hours: Spend time thinking.
7.
BBT is learning from mistakes. Science has transformed the world because it constantly updates its theories in light of failures. Complexity guarantees failure. Do we learn or self-justify?
6.
The OODA Loop - Competitive advantage
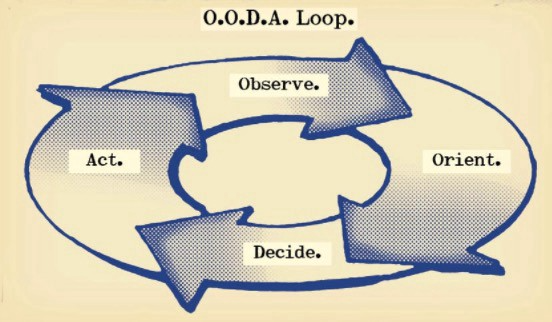
O: Observe: collect the data. Figure out exactly where you are, what’s happening.
O: Orient: analyze/synthesize the data to form an accurate picture.
D: Decide: select an action from possible options
A: Action: execute the action, and return to step (1)
Boyd's approach indicates that speed and agility are about information processing, not physical reactions. They form feedback loops. More OODA loops improve speed.
5.
Leaders who try to impose order in a complex situation fail; those who set the stage, step back, and allow patterns to develop win.
https://vimeo.com/640941172?embedded=true&source=vimeo_logo&owner=11999906
4.
Information Gap - The discrepancy between what we know and what we would like to know
Gap in Alignment - What individuals actually do as opposed to what we wish them to do
Effects Gap - the discrepancy between our expectations and the results of our actions
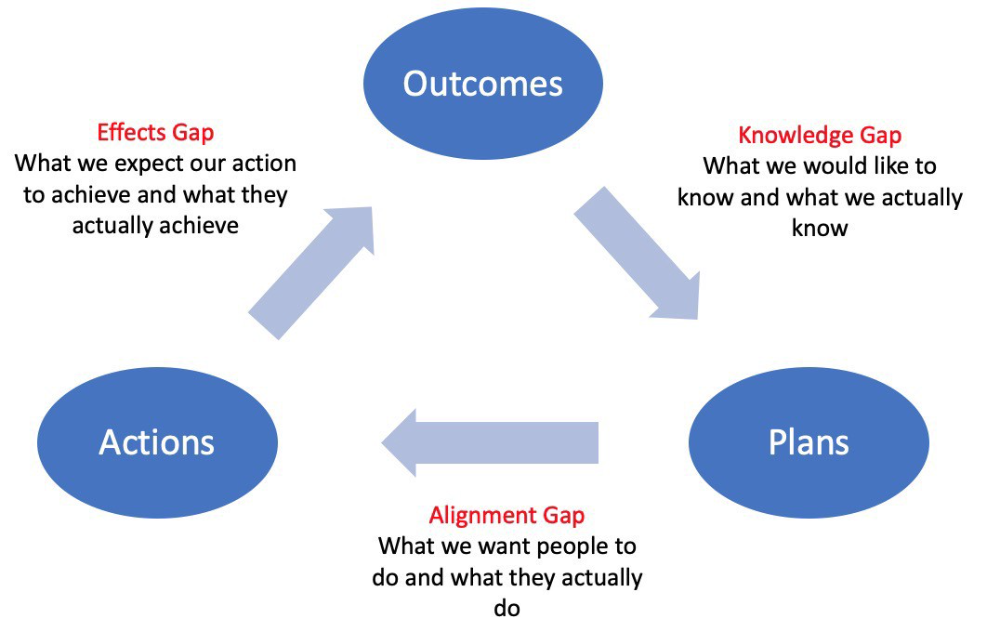
3.
Theory of Constraints — The Goal - To maximize system production, maximize bottleneck throughput.
Goldratt creates a five-step procedure:
Determine the restriction
Improve the restriction.
Everything else should be based on the limitation.
Increase the restriction
Go back to step 1 Avoid letting inertia become a limitation.
Any non-constraint improvement is an illusion.
2.
Serendipity and the Adjacent Possible - Why do several amazing ideas emerge at once? How can you foster serendipity in your work?
You need specialized abilities to reach to the edge of possibilities, where you can pursue exciting tasks that will change the world. Few people do it since it takes a lot of hard work. You'll stand out if you do.
Most people simply lack the comfort with discomfort required to tackle really hard things. At some point, in other words, there’s no way getting around the necessity to clear your calendar, shut down your phone, and spend several hard days trying to make sense of the damn proof.
1.
Boundaries of failure - Rasmussen's accident model.

Rasmussen modeled this. It has economic, workload, and performance boundaries.
The economic boundary is a company's profit zone. If the lights are on, you're within the economic boundaries, but there's pressure to cut costs and do more.
Performance limit reflects system capacity. Taking shortcuts is a human desire to minimize work. This is often necessary to survive because there's always more labor.
Both push operating points toward acceptable performance. Personal or process safety, or equipment performance.
If you exceed acceptable performance, you'll push back, typically forcefully.

Sad NoCoiner
3 years ago
Two Key Money Principles You Should Understand But Were Never Taught

Prudence is advised. Be debt-free. Be frugal. Spend less.
This advice sounds nice, but it rarely works.
Most people never learn these two money rules. Both approaches will impact how you see personal finance.
It may safeguard you from inflation or the inability to preserve money.
Let’s dive in.
#1: Making long-term debt your ally
High-interest debt hurts consumers. Many credit cards carry 25% yearly interest (or more), so always pay on time. Otherwise, you’re losing money.
Some low-interest debt is good. Especially when buying an appreciating asset with borrowed money.
Inflation helps you.
If you borrow $800,000 at 3% interest and invest it at 7%, you'll make $32,000 (4%).
As money loses value, fixed payments get cheaper. Your assets' value and cash flow rise.
The never-in-debt crowd doesn't know this. They lose money paying off mortgages and low-interest loans early when they could have bought assets instead.
#2: How To Buy Or Build Assets To Make Inflation Irrelevant
Dozens of studies demonstrate actual wage growth is static; $2.50 in 1964 was equivalent to $22.65 now.
These reports never give solutions unless they're selling gold.
But there is one.
Assets beat inflation.
$100 invested into the S&P 500 would have an inflation-adjusted return of 17,739.30%.
Likewise, you can build assets from nothing. Doing is easy and quick. The returns can boost your income by 10% or more.
The people who obsess over inflation inadvertently make the problem worse for themselves. They wait for The Big Crash to buy assets. Or they moan about debt clocks and spending bills instead of seeking a solution.
Conclusion
Being ultra-prudent is like playing golf with a putter to avoid hitting the ball into the water. Sure, you might not slice a drive into the pond. But, you aren’t going to play well either. Or have very much fun.
Money has rules.
Avoiding debt or investment risks will limit your rewards. Long-term, being too cautious hurts your finances.
Disclaimer: This article is for entertainment purposes only. It is not financial advice, always do your own research.

Alex Mathers
3 years ago
12 habits of the zenith individuals I know
Calmness is a vital life skill.
It aids communication. It boosts creativity and performance.
I've studied calm people's habits for years. Commonalities:
Have mastered the art of self-humor.
Protectors take their job seriously, draining the room's energy.
They are fixated on positive pursuits like making cool things, building a strong physique, and having fun with others rather than on depressing influences like the news and gossip.
Every day, spend at least 20 minutes moving, whether it's walking, yoga, or lifting weights.
Discover ways to take pleasure in life's challenges.
Since perspective is malleable, they change their view.
Set your own needs first.
Stressed people neglect themselves and wonder why they struggle.
Prioritize self-care.
Don't ruin your life to please others.
Make something.
Calm people create more than react.
They love creating beautiful things—paintings, children, relationships, and projects.
Don’t hold their breath.
If you're stressed or angry, you may be surprised how much time you spend holding your breath and tightening your belly.
Release, breathe, and relax to find calm.
Stopped rushing.
Rushing is disadvantageous.
Calm people handle life better.
Are aware of their own dietary requirements.
They avoid junk food and eat foods that keep them healthy, happy, and calm.
Don’t take anything personally.
Stressed people control everything.
Self-conscious.
Calm people put others and their work first.
Keep their surroundings neat.
Maintaining an uplifting and clutter-free environment daily calms the mind.
Minimise negative people.
Calm people are ruthless with their boundaries and avoid negative and drama-prone people.
You might also like

Crypto Zen Monk
2 years ago
How to DYOR in the world of cryptocurrency
RESEARCH
We must create separate ideas and handle our own risks to be better investors. DYOR is crucial.
The only thing unsustainable is your cluelessness.
DYOR: Why
On social media, there is a lot of false information and divergent viewpoints. All of these facts might be accurate, but they might not be appropriate for your portfolio and investment preferences.
You become a more knowledgeable investor thanks to DYOR.
DYOR improves your portfolio's risk management.
My DYOR resources are below.

Messari: Major Blockchains' Activities
New York-based Messari provides cryptocurrency open data libraries.
Major blockchains offer 24-hour on-chain volume. https://messari.io/screener/most-active-chains-DB01F96B
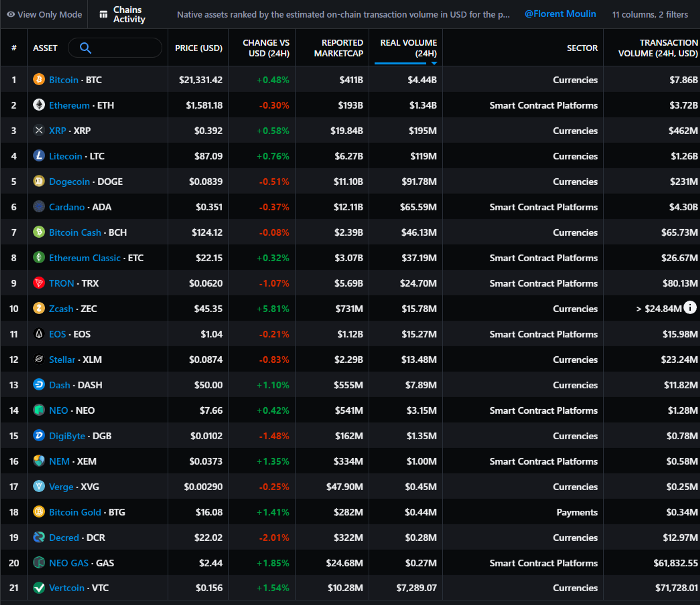
What to do
Invest in stable cryptocurrencies. Sort Messari by Real Volume (24H) or Reported Market Cap.
Coingecko: Research on Ecosystems
Top 10 Ecosystems by Coingecko are good.
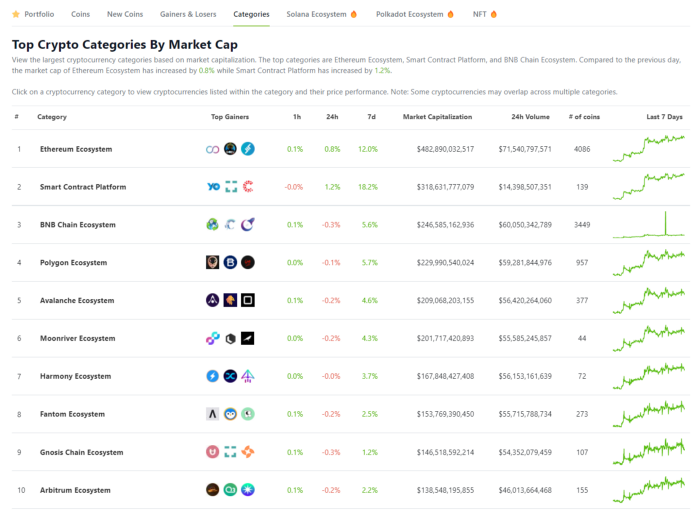
What to do
Invest in quality.
Leading ten Ecosystems by Market Cap
There are a lot of coins in the ecosystem (second last column of above chart)
CoinGecko's Market Cap Crypto Categories Market capitalization-based cryptocurrency categories. Ethereum Ecosystem www.coingecko.com
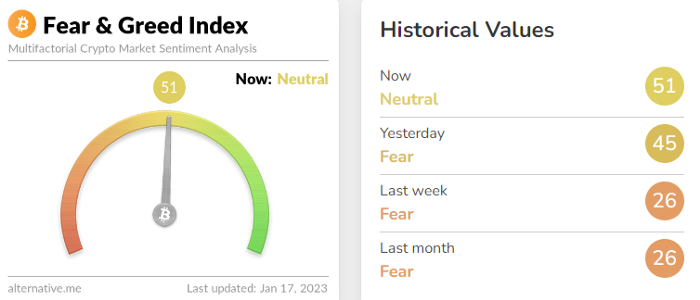
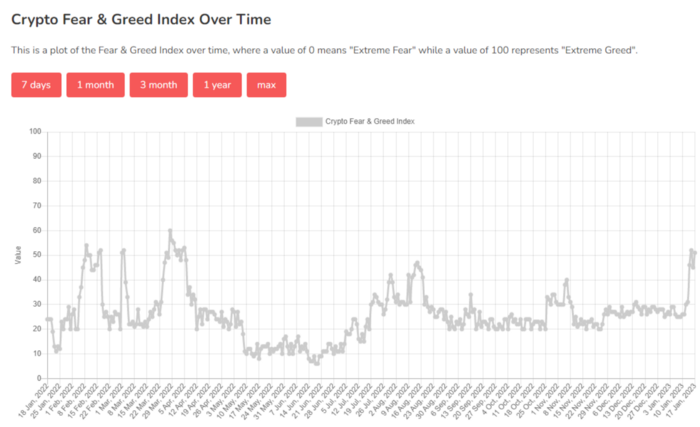
Fear & Greed Index for Bitcoin (FGI)
The Bitcoin market sentiment index ranges from 0 (extreme dread) to 100. (extreme greed).
How to Apply
See market sentiment:
Extreme fright = opportunity to buy
Extreme greed creates sales opportunity (market due for correction).
Glassnode
Glassnode gives facts, information, and confidence to make better Bitcoin, Ethereum, and cryptocurrency investments and trades.
Explore free and paid metrics.
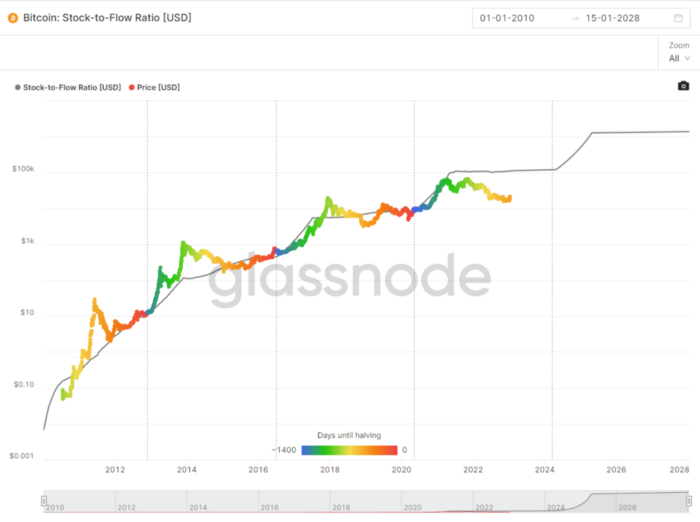
Stock to Flow Ratio: Application
The popular Stock to Flow Ratio concept believes scarcity drives value. Stock to flow is the ratio of circulating Bitcoin supply to fresh production (i.e. newly mined bitcoins). The S/F Ratio has historically predicted Bitcoin prices. PlanB invented this metric.
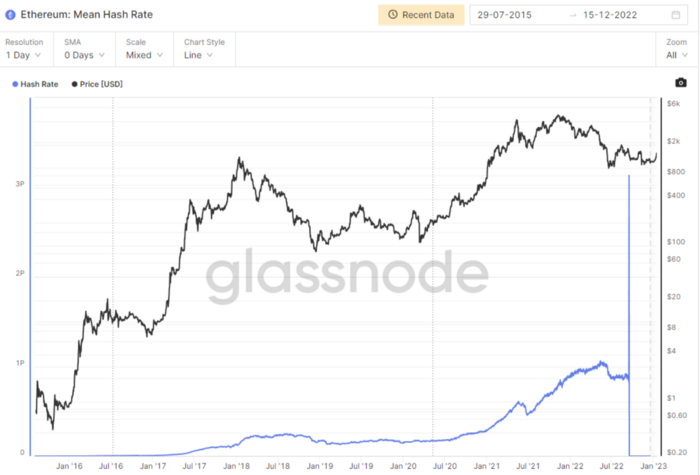
Utilization: Ethereum Hash Rate
Ethereum miners produce an estimated number of hashes per second.
ycharts: Hash rate of the Bitcoin network
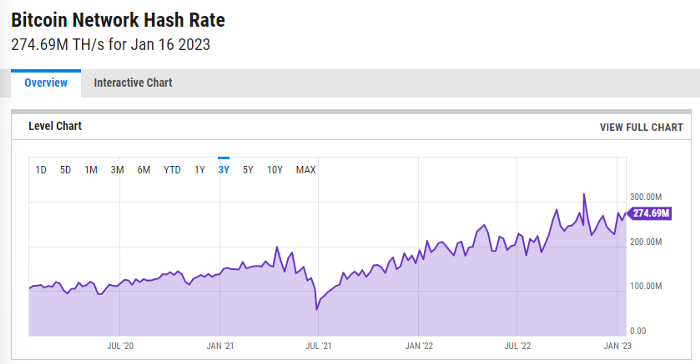
TradingView
TradingView is your go-to tool for investment analysis, watch lists, technical analysis, and recommendations from other traders/investors.
Research for a cryptocurrency project
Two key questions every successful project must ask: Q1: What is this project trying to solve? Is it a big problem or minor? Q2: How does this project make money?
Each cryptocurrency:
Check out the white paper.
check out the project's internet presence on github, twitter, and medium.
the transparency of it
Verify the team structure and founders. Verify their LinkedIn profile, academic history, and other qualifications. Search for their names with scam.
Where to purchase and use cryptocurrencies Is it traded on trustworthy exchanges?
From CoinGecko and CoinMarketCap, we may learn about market cap, circulations, and other important data.
The project must solve a problem. Solving a problem is the goal of the founders.
Avoid projects that resemble multi-level marketing or ponzi schemes.
Your use of social media
Use social media carefully or ignore it: Twitter, TradingView, and YouTube
Someone said this before and there are some truth to it. Social media bullish => short.
Your Behavior
Investigate. Spend time. You decide. Worth it!
Only you have the best interest in your financial future.

Emma Jade
3 years ago
6 hacks to create content faster
Content gurus' top time-saving hacks.

I'm a content strategist, writer, and graphic designer. Time is more valuable than money.
Money is always available. Even if you're poor. Ways exist.
Time is passing, and one day we'll run out.
Sorry to be morbid.
In today's digital age, you need to optimize how you create content for your organization. Here are six content creation hacks.
1. Use templates
Use templates to streamline your work whether generating video, images, or documents.
Setup can take hours. Using a free resource like Canva, you can create templates for any type of material.
This will save you hours each month.
2. Make a content calendar
You post without a plan? A content calendar solves 50% of these problems.
You can prepare, organize, and plan your material ahead of time so you're not scrambling when you remember, "Shit, it's Mother's Day!"
3. Content Batching
Batching content means creating a lot in one session. This is helpful for video content that requires a lot of setup time.
Batching monthly content saves hours. Time is a valuable resource.
When working on one type of task, it's easy to get into a flow state. This saves time.
4. Write Caption
On social media, we generally choose the image first and then the caption. Writing captions first sometimes work better, though.
Writing the captions first can allow you more creative flexibility and be easier if you're not excellent with language.
Say you want to tell your followers something interesting.
Writing a caption first is easier than choosing an image and then writing a caption to match.
Not everything works. You may have already-created content that needs captioning. When you don't know what to share, think of a concept, write the description, and then produce a video or graphic.
Cats can be skinned in several ways..
5. Repurpose
Reuse content when possible. You don't always require new stuff. In fact, you’re pretty stupid if you do #SorryNotSorry.
Repurpose old content. All those blog entries, videos, and unfinished content on your desk or hard drive.
This blog post can be turned into a social media infographic. Canva's motion graphic function can animate it. I can record a YouTube video regarding this issue for a podcast. I can make a post on each point in this blog post and turn it into an eBook or paid course.
And it doesn’t stop there.
My point is, to think outside the box and really dig deep into ways you can leverage the content you’ve already created.
6. Schedule Them
If you're still manually posting content, get help. When you batch your content, schedule it ahead of time.
Some scheduling apps are free or cheap. No excuses.
Don't publish and ghost.
Scheduling saves time by preventing you from doing it manually. But if you never engage with your audience, the algorithm won't reward your material.
Be online and engage your audience.
Content Machine
Use these six content creation hacks. They help you succeed and save time.

Tim Soulo
3 years ago
Here is why 90.63% of Pages Get No Traffic From Google.
The web adds millions or billions of pages per day.
How much Google traffic does this content get?
In 2017, we studied 2 million randomly-published pages to answer this question. Only 5.7% of them ranked in Google's top 10 search results within a year of being published.
94.3 percent of roughly two million pages got no Google traffic.
Two million pages is a small sample compared to the entire web. We did another study.
We analyzed over a billion pages to see how many get organic search traffic and why.
How many pages get search traffic?
90% of pages in our index get no Google traffic, and 5.2% get ten visits or less.
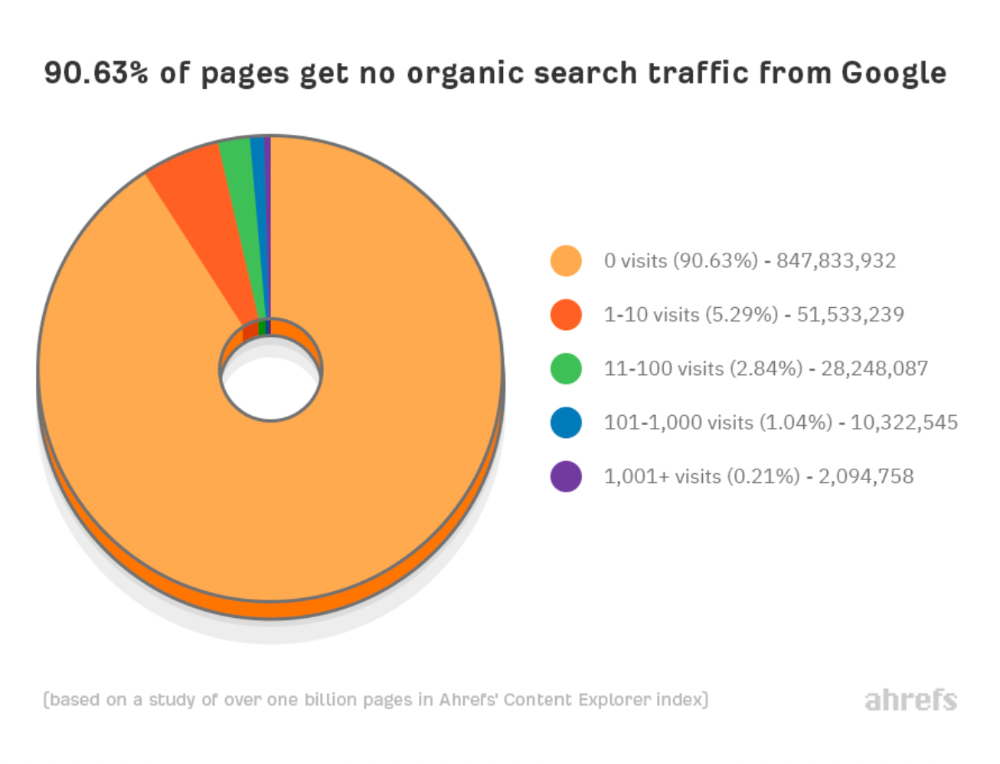
90% of google pages get no organic traffic
How can you join the minority that gets Google organic search traffic?
There are hundreds of SEO problems that can hurt your Google rankings. If we only consider common scenarios, there are only four.
Reason #1: No backlinks
I hate to repeat what most SEO articles say, but it's true:
Backlinks boost Google rankings.
Google's "top 3 ranking factors" include them.
Why don't we divide our studied pages by the number of referring domains?
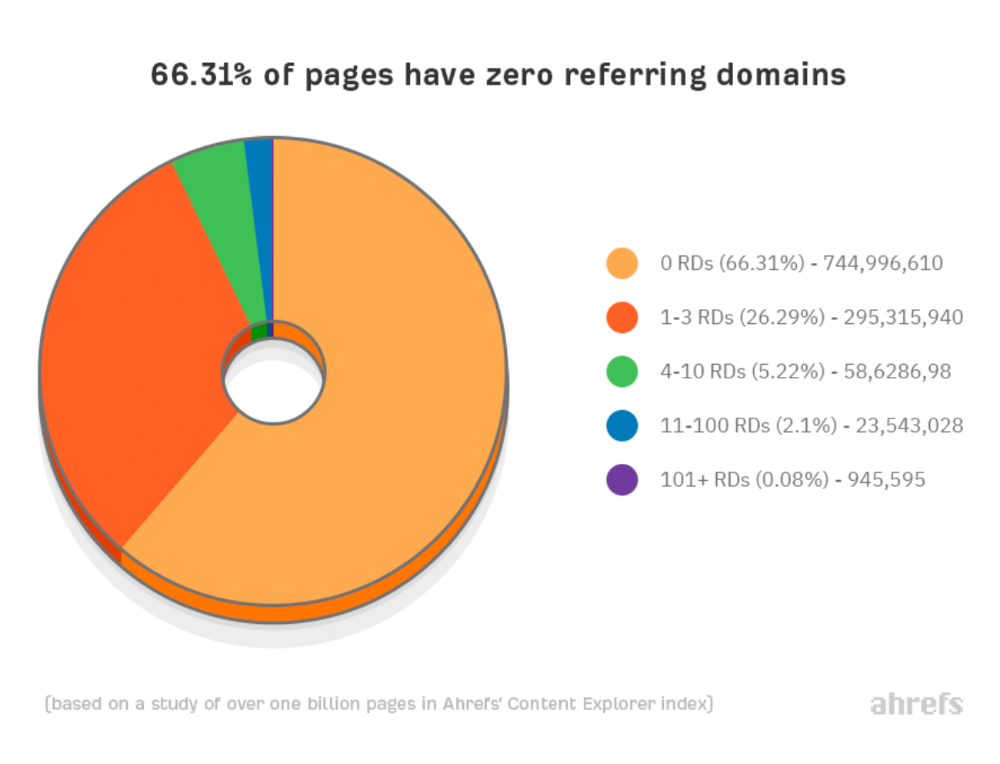
66.31 percent of pages have no backlinks, and 26.29 percent have three or fewer.
Did you notice the trend already?
Most pages lack search traffic and backlinks.
But are these the same pages?
Let's compare monthly organic search traffic to backlinks from unique websites (referring domains):
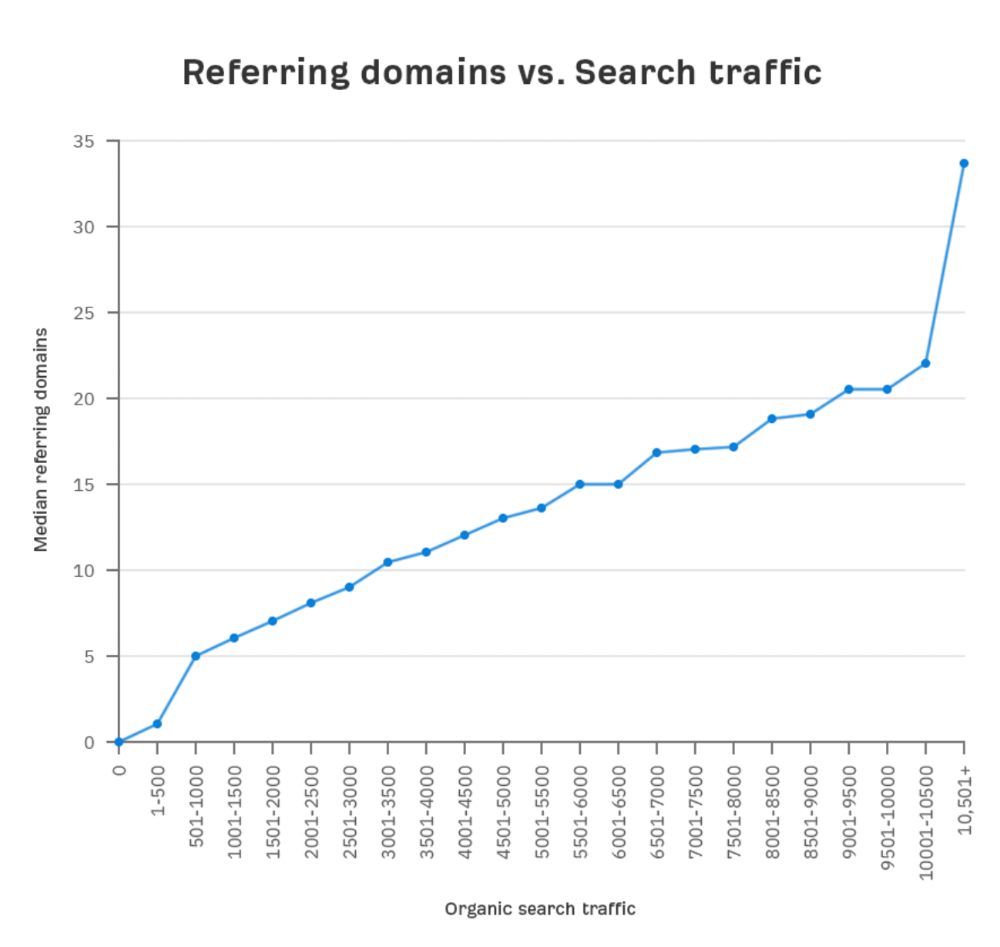
More backlinks equals more Google organic traffic.
Referring domains and keyword rankings are correlated.
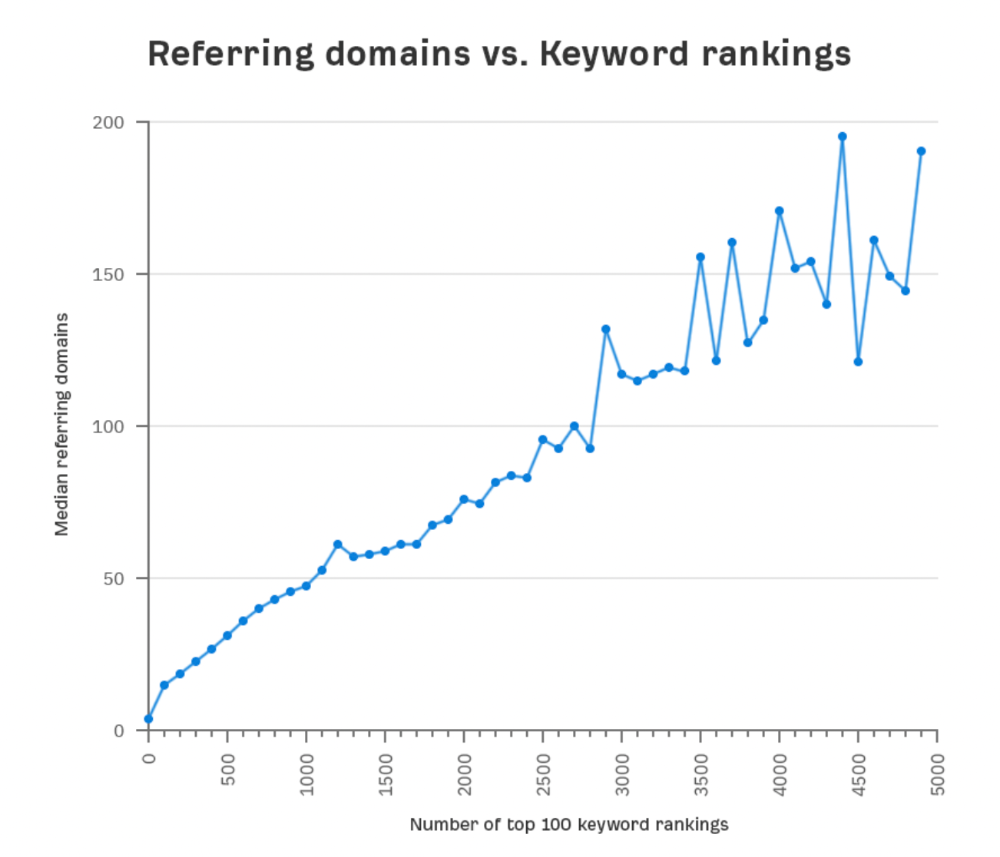
It's important to note that correlation does not imply causation, and none of these graphs prove backlinks boost Google rankings. Most SEO professionals agree that it's nearly impossible to rank on the first page without backlinks.
You'll need high-quality backlinks to rank in Google and get search traffic.
Is organic traffic possible without links?
Here are the numbers:
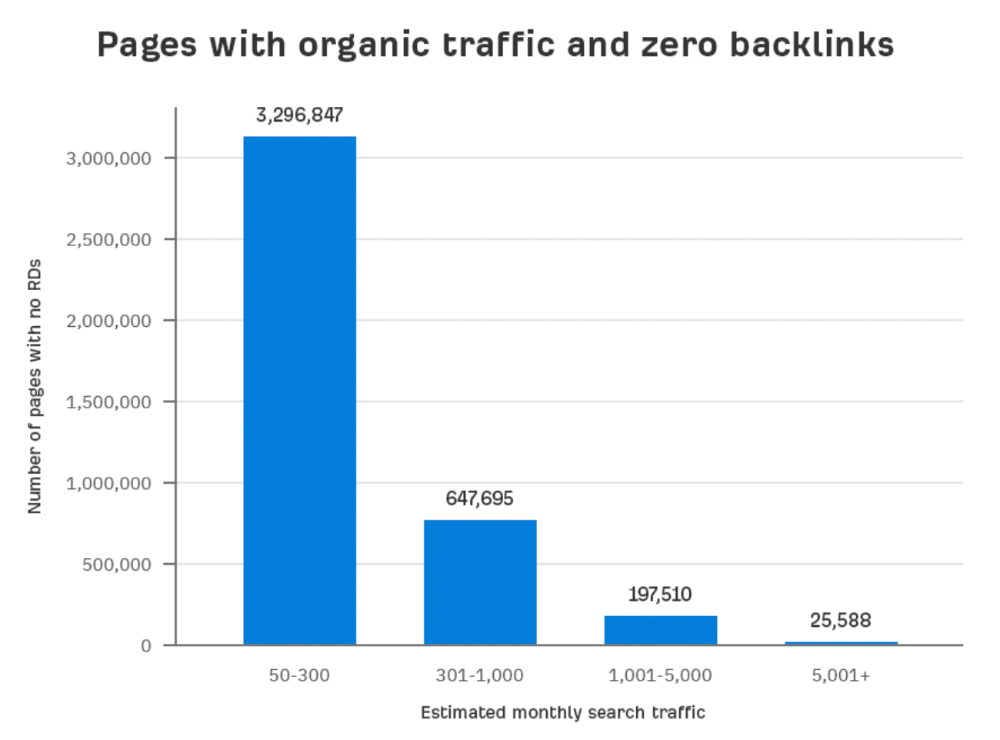
Four million pages get organic search traffic without backlinks. Only one in 20 pages without backlinks has traffic, which is 5% of our sample.
Most get 300 or fewer organic visits per month.
What happens if we exclude high-Domain-Rating pages?
The numbers worsen. Less than 4% of our sample (1.4 million pages) receive organic traffic. Only 320,000 get over 300 monthly organic visits, or 0.1% of our sample.
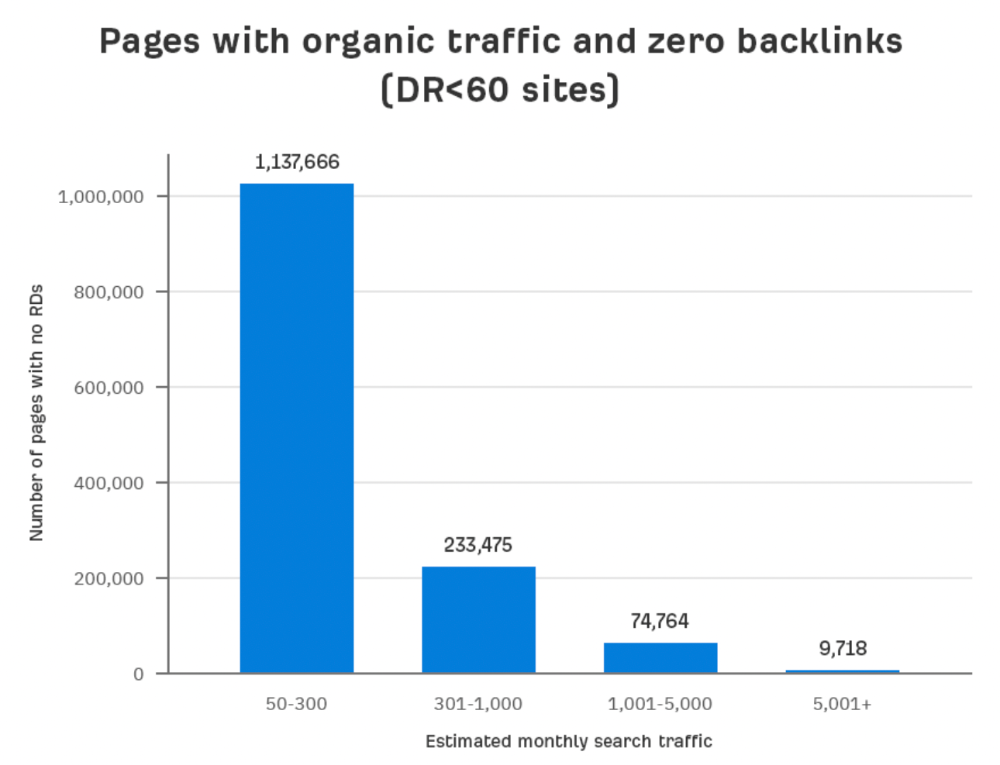
This suggests high-authority pages without backlinks are more likely to get organic traffic than low-authority pages.
Internal links likely pass PageRank to new pages.
Two other reasons:
Our crawler's blocked. Most shady SEOs block backlinks from us. This prevents competitors from seeing (and reporting) PBNs.
They choose low-competition subjects. Low-volume queries are less competitive, requiring fewer backlinks to rank.
If the idea of getting search traffic without building backlinks excites you, learn about Keyword Difficulty and how to find keywords/topics with decent traffic potential and low competition.
Reason #2: The page has no long-term traffic potential.
Some pages with many backlinks get no Google traffic.
Why? I filtered Content Explorer for pages with no organic search traffic and divided them into four buckets by linking domains.
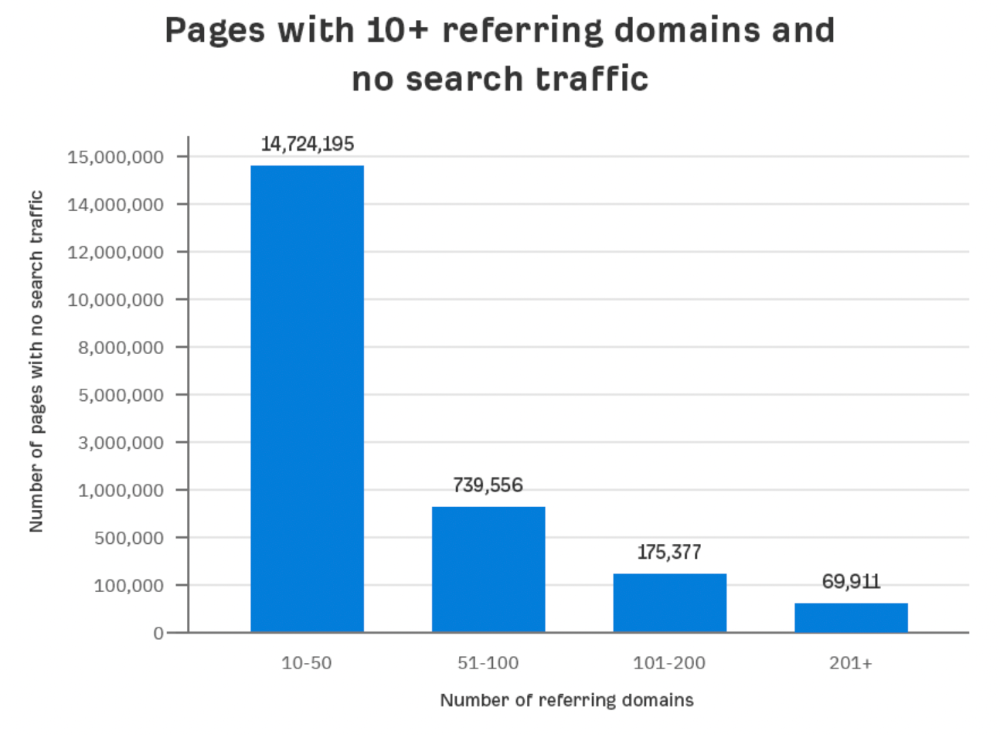
Almost 70k pages have backlinks from over 200 domains, but no search traffic.
By manually reviewing these (and other) pages, I noticed two general trends that explain why they get no traffic:
They overdid "shady link building" and got penalized by Google;
They're not targeting a Google-searched topic.
I won't elaborate on point one because I hope you don't engage in "shady link building"
#2 is self-explanatory:
If nobody searches for what you write, you won't get search traffic.
Consider one of our blog posts' metrics:

No organic traffic despite 337 backlinks from 132 sites.
The page is about "organic traffic research," which nobody searches for.
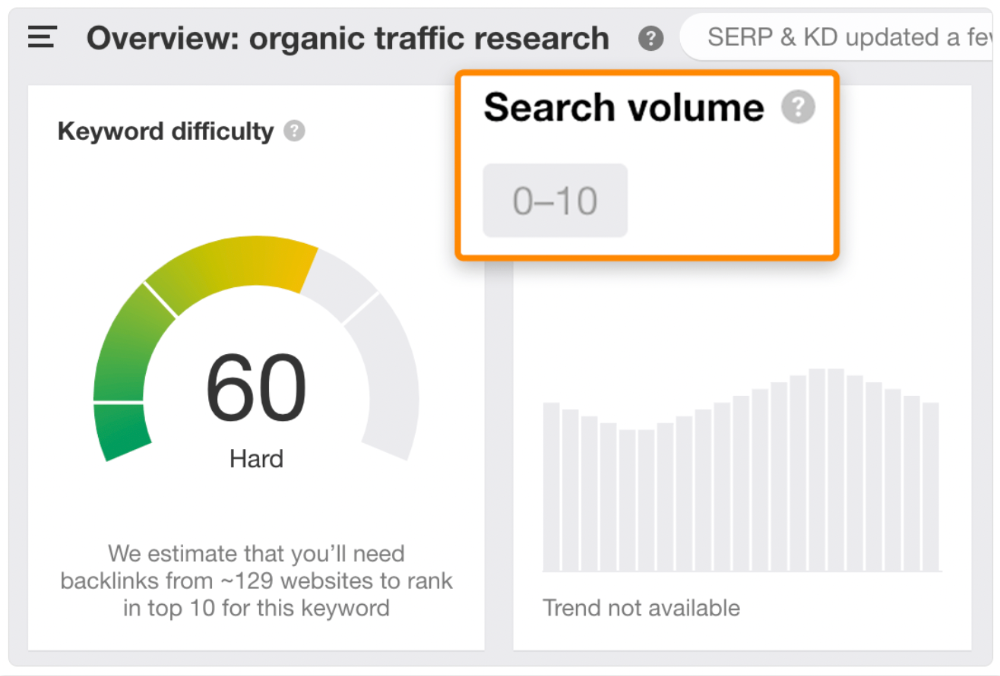
News articles often have this. They get many links from around the web but little Google traffic.
People can't search for things they don't know about, and most don't care about old events and don't search for them.
Note:
Some news articles rank in the "Top stories" block for relevant, high-volume search queries, generating short-term organic search traffic.
The Guardian's top "Donald Trump" story:
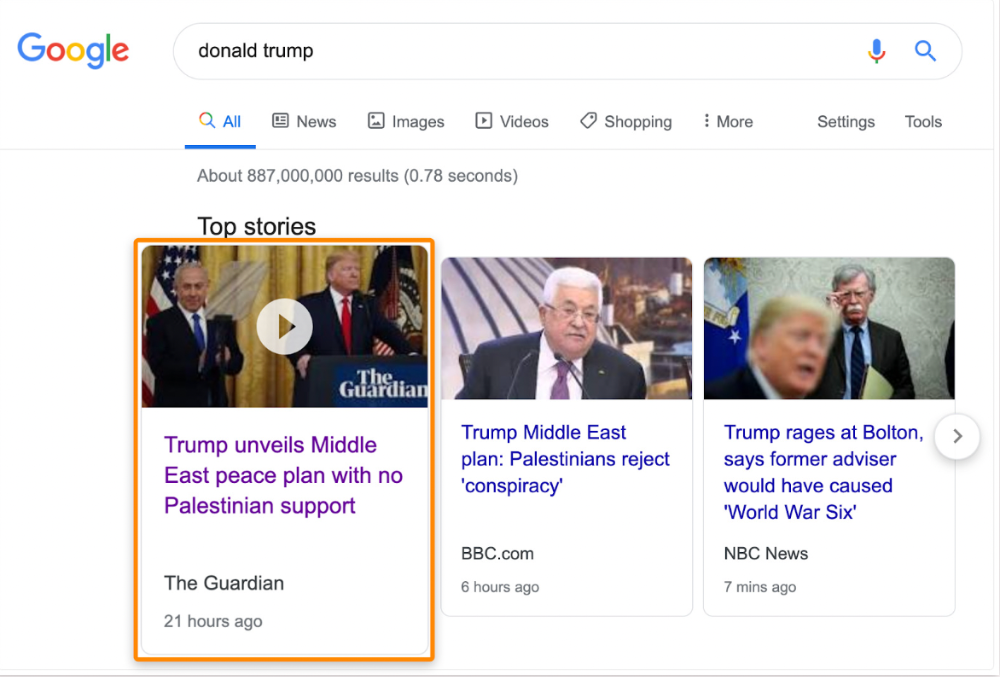
Ahrefs caught on quickly:
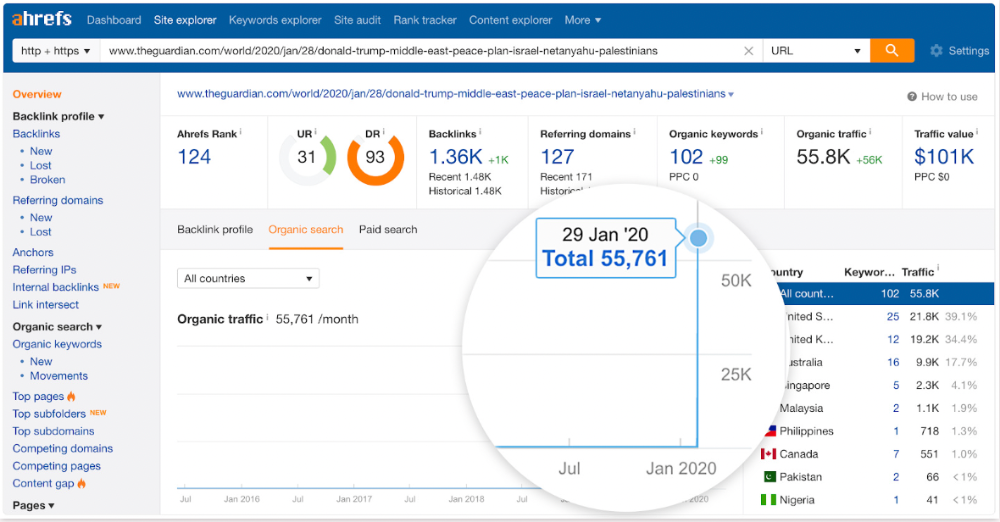
"Donald Trump" gets 5.6M monthly searches, so this page got a lot of "Top stories" traffic.
I bet traffic has dropped if you check now.
One of the quickest and most effective SEO wins is:
Find your website's pages with the most referring domains;
Do keyword research to re-optimize them for relevant topics with good search traffic potential.
Bryan Harris shared this "quick SEO win" during a course interview:
He suggested using Ahrefs' Site Explorer's "Best by links" report to find your site's most-linked pages and analyzing their search traffic. This finds pages with lots of links but little organic search traffic.
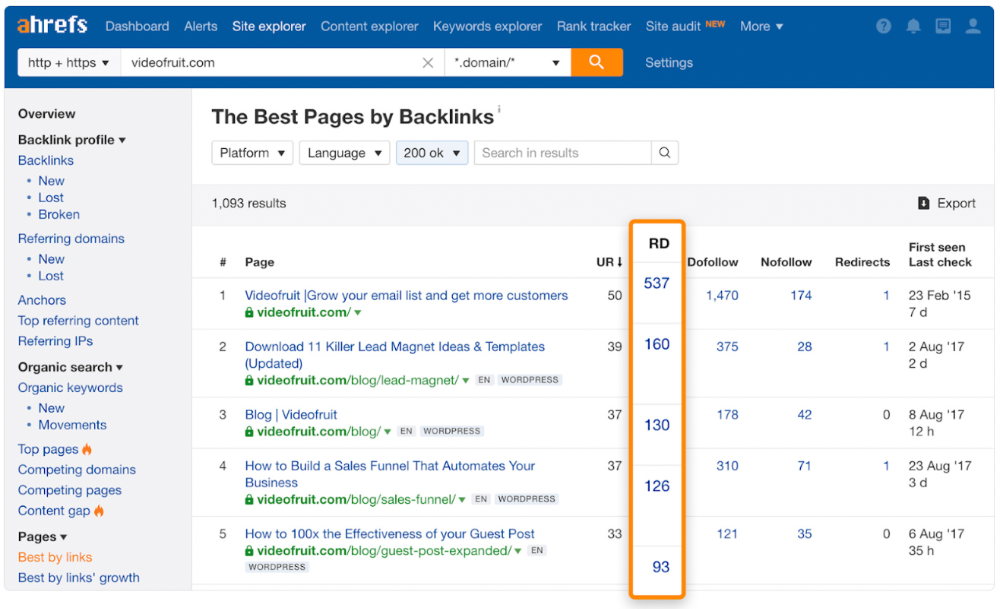
We see:
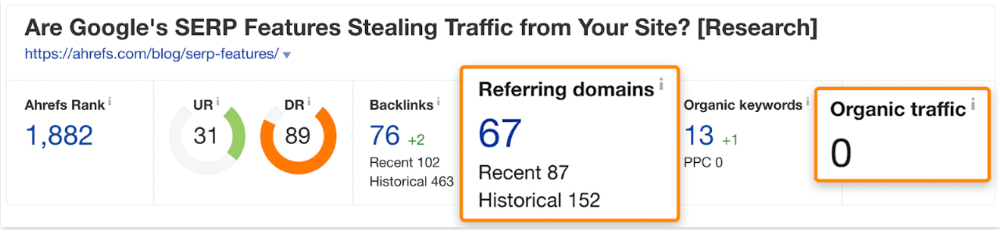
The guide has 67 backlinks but no organic traffic.
We could fix this by re-optimizing the page for "SERP"
A similar guide with 26 backlinks gets 3,400 monthly organic visits, so we should easily increase our traffic.
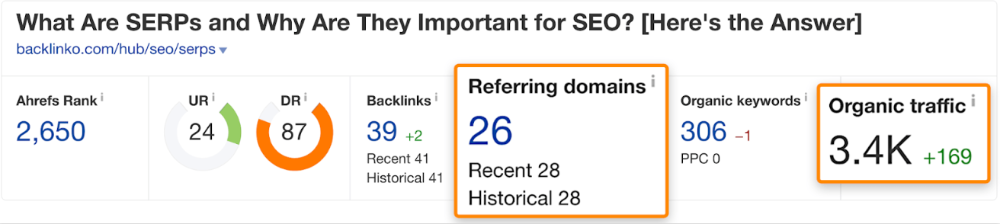
Don't do this with all low-traffic pages with backlinks. Choose your battles wisely; some pages shouldn't be ranked.
Reason #3: Search intent isn't met
Google returns the most relevant search results.
That's why blog posts with recommendations rank highest for "best yoga mat."
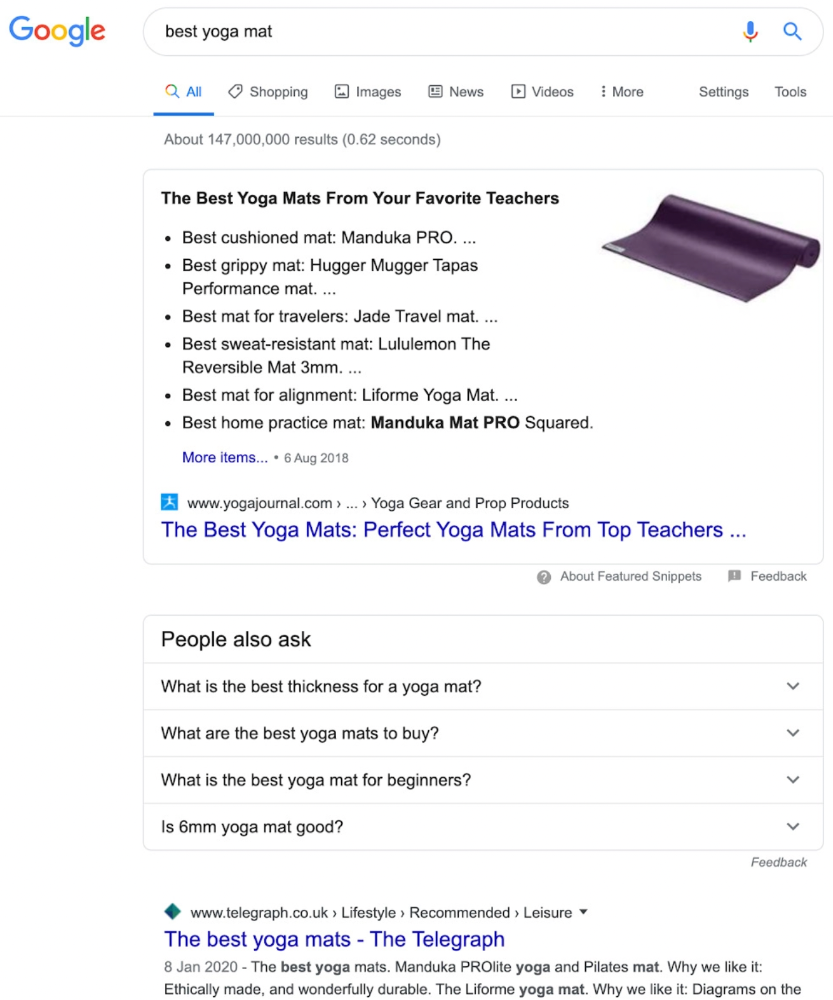
Google knows that most searchers aren't buying.
It's also why this yoga mats page doesn't rank, despite having seven times more backlinks than the top 10 pages:
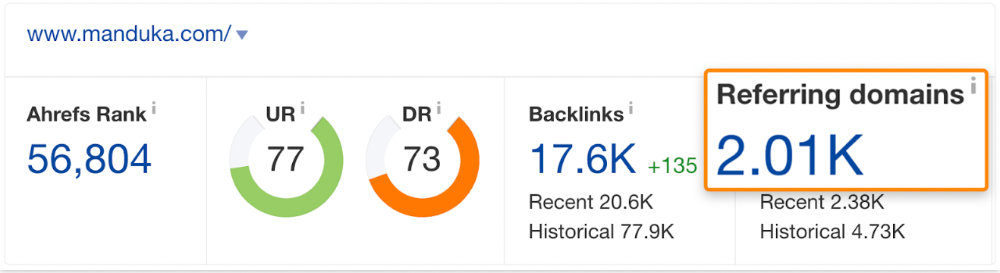
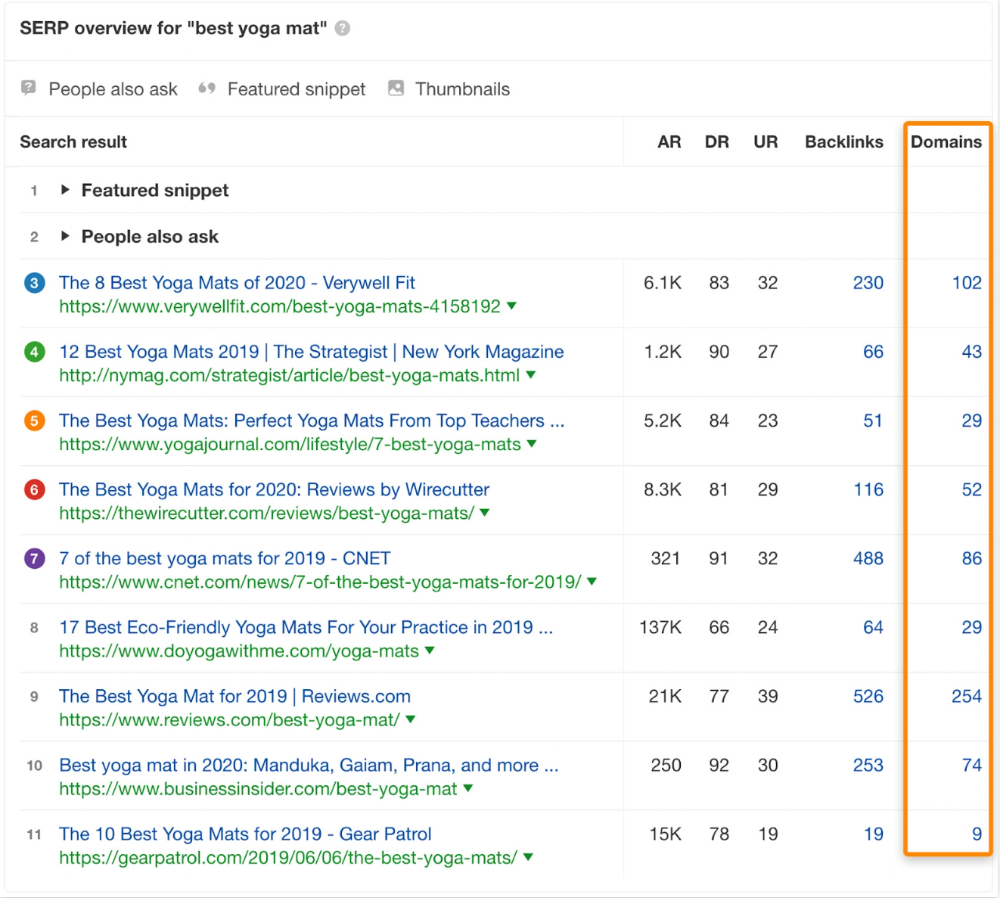
The page ranks for thousands of other keywords and gets tens of thousands of monthly organic visits. Not being the "best yoga mat" isn't a big deal.
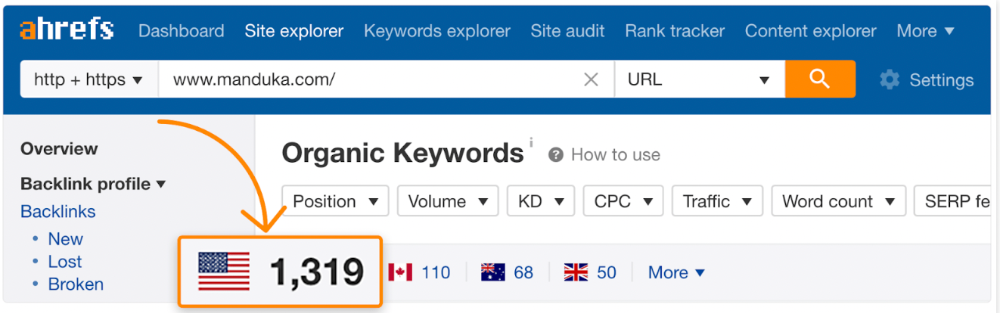
If you have pages with lots of backlinks but no organic traffic, re-optimizing them for search intent can be a quick SEO win.
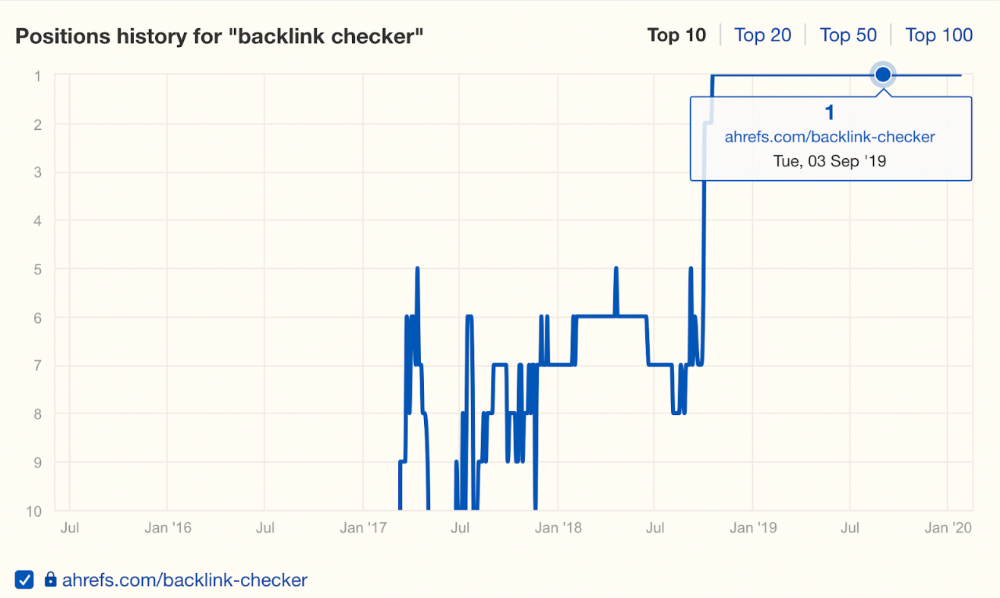
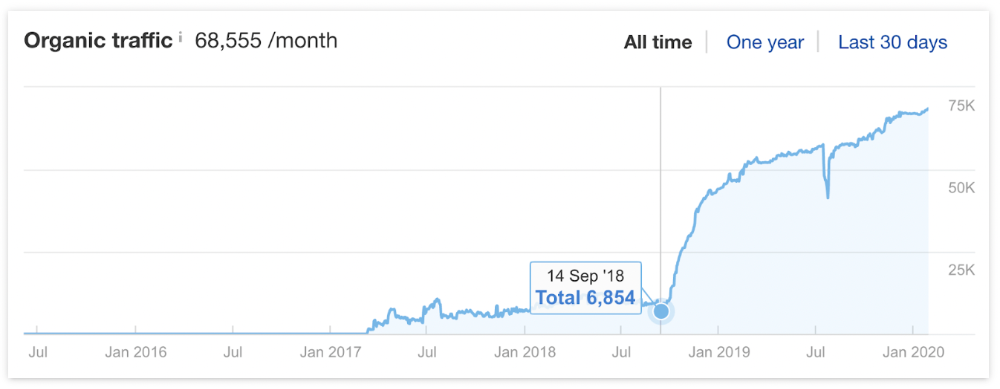
It was originally a boring landing page describing our product's benefits and offering a 7-day trial.
We realized the problem after analyzing search intent.
People wanted a free tool, not a landing page.
In September 2018, we published a free tool at the same URL. Organic traffic and rankings skyrocketed.
Reason #4: Unindexed page
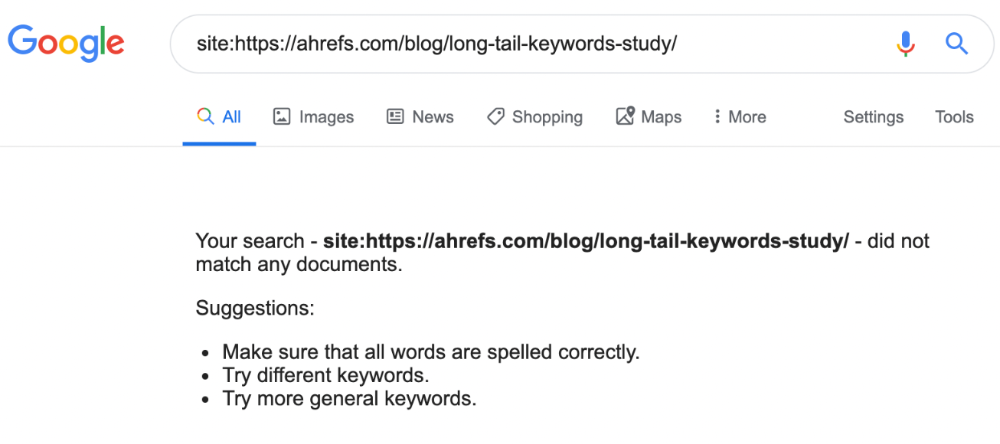
Google can’t rank pages that aren’t indexed.
If you think this is the case, search Google for site:[url]. You should see at least one result; otherwise, it’s not indexed.
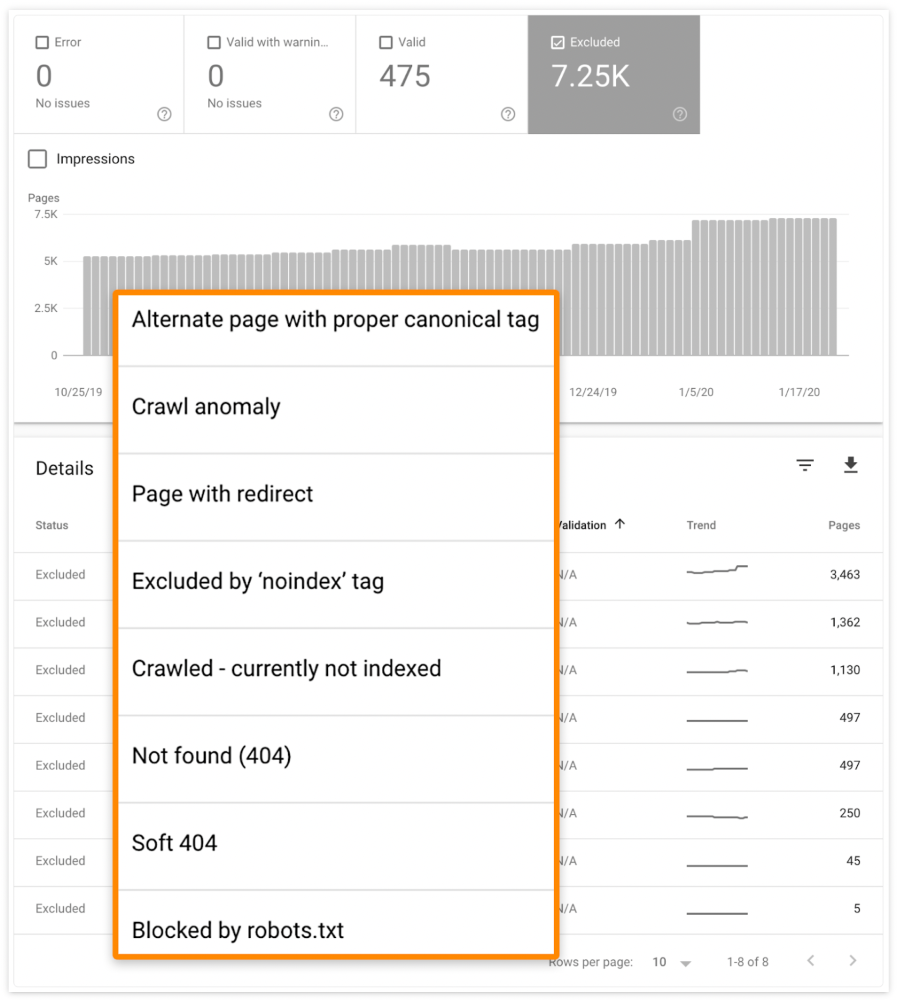
A rogue noindex meta tag is usually to blame. This tells search engines not to index a URL.
Rogue canonicals, redirects, and robots.txt blocks prevent indexing.
Check the "Excluded" tab in Google Search Console's "Coverage" report to see excluded pages.
Google doesn't index broken pages, even with backlinks.
Surprisingly common.
In Ahrefs' Site Explorer, the Best by Links report for a popular content marketing blog shows many broken pages.
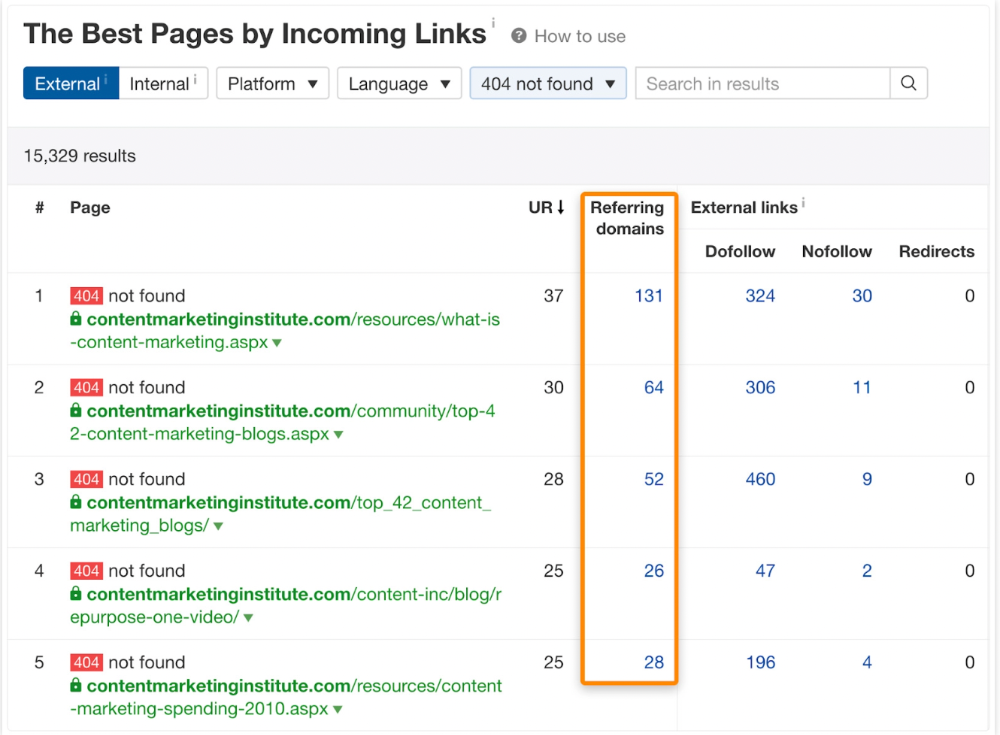
One dead page has 131 backlinks:
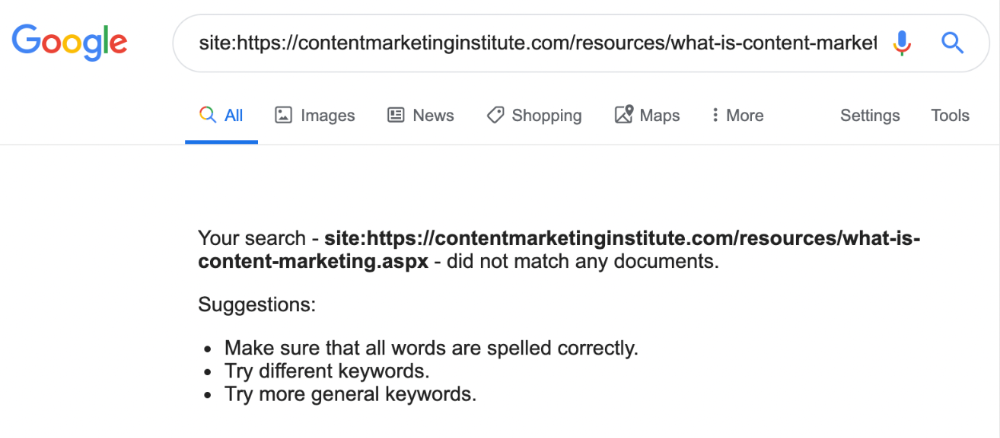
According to the URL, the page defined content marketing. —a keyword with a monthly search volume of 5,900 in the US.
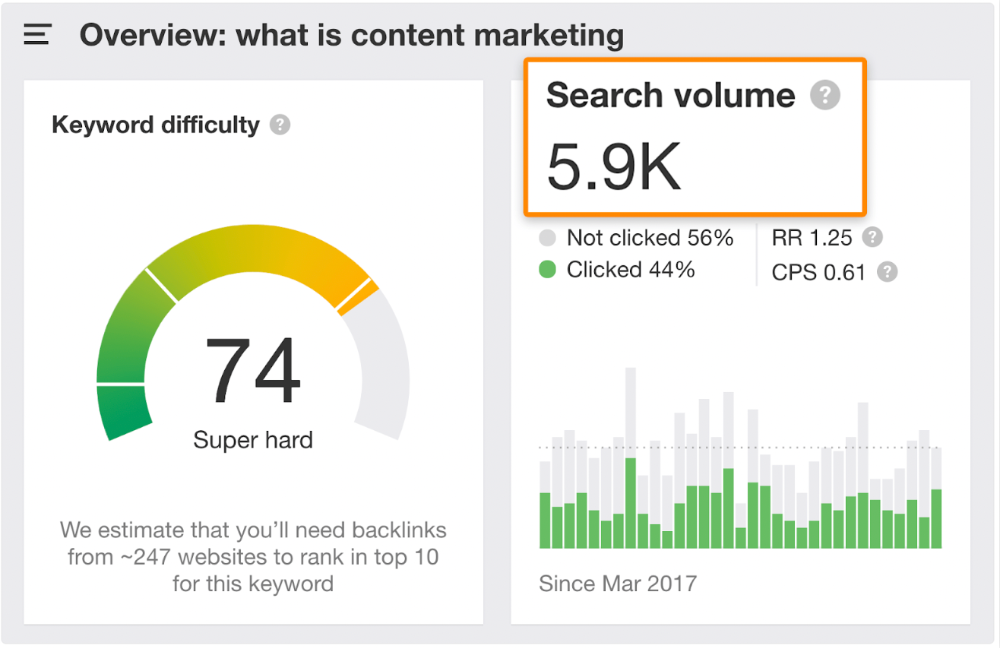
Luckily, another page ranks for this keyword. Not a huge loss.
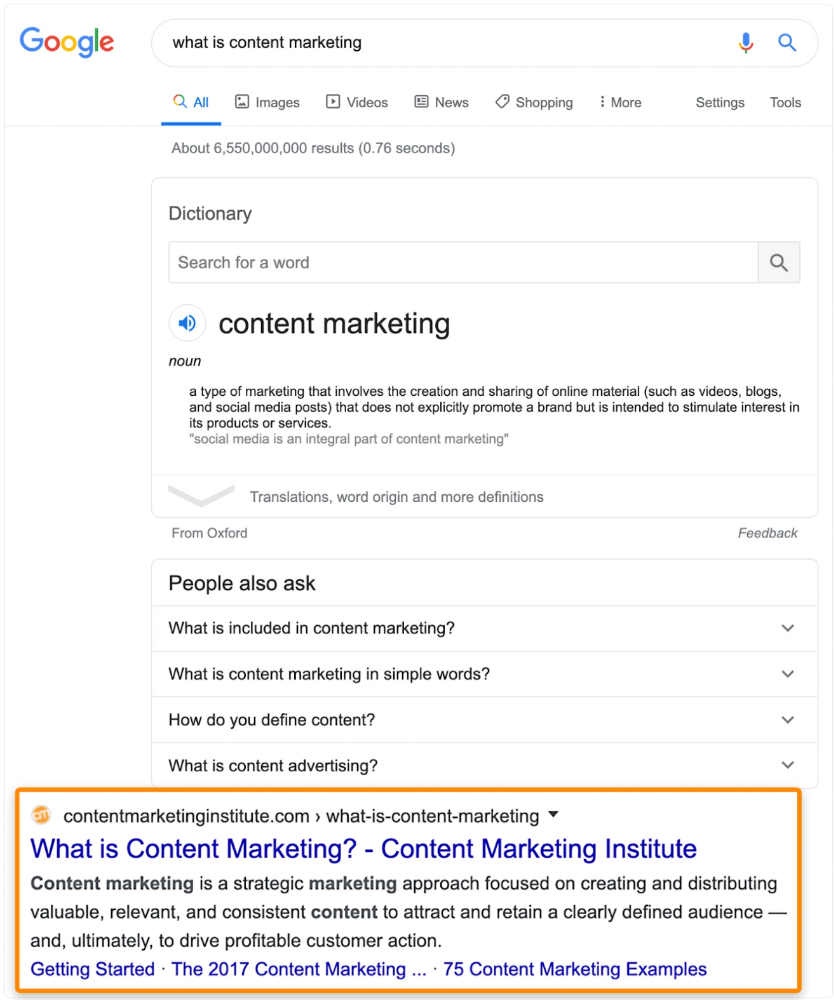
At least redirect the dead page's backlinks to a working page on the same topic. This may increase long-tail keyword traffic.
This post is a summary. See the original post here