


Framework to Evaluate Metaverse and Web3
Everywhere we turn, there's a new metaverse or Web3 debut. Microsoft recently announced a $68.7 BILLION cash purchase of Activision.
Like AI in 2013 and blockchain in 2014, NFT growth in 2021 feels like this year's metaverse and Web3 growth. We are all bombarded with information, conflicting signals, and a sensation of FOMO.
How can we evaluate the metaverse and Web3 in a noisy, new world? My framework for evaluating upcoming technologies and themes is shown below. I hope you will also find them helpful.
Understand the “pipes” in a new space.
Whatever people say, Metaverse and Web3 will have to coexist with the current Internet. Companies who host, move, and store data over the Internet have a lot of intriguing use cases in Metaverse and Web3, whether in infrastructure, data analytics, or compliance. Hence the following point.
## Understand the apps layer and their infrastructure.
Gaming, crypto exchanges, and NFT marketplaces would not exist today if not for technology that enables rapid app creation. Yes, according to Chainalysis and other research, 30–40% of Ethereum is self-hosted, with the rest hosted by large cloud providers. For Microsoft to acquire Activision makes strategic sense. It's not only about the games, but also the infrastructure that supports them.
Follow the money
Understanding how money and wealth flow in a complex and dynamic environment helps build clarity. Unless you are exceedingly wealthy, you have limited ability to significantly engage in the Web3 economy today. Few can just buy 10 ETH and spend it in one day. You must comprehend who benefits from the process, and how that 10 ETH circulates now and possibly tomorrow. Major holders and players control supply and liquidity in any market. Today, most Web3 apps are designed to increase capital inflow so existing significant holders can utilize it to create a nascent Web3 economy. When you see a new Metaverse or Web3 application, remember how money flows.
What is the use case?
What does the app do? If there is no clear use case with clear makers and consumers solving a real problem, then the euphoria soon fades, and the only stakeholders who remain enthused are those who have too much to lose.
Time is a major competition that is often overlooked.
We're only busier, but each day is still 24 hours. Using new apps may mean that time is lost doing other things. The user must be eager to learn. Metaverse and Web3 vs. our time? I don't think we know the answer yet (at least for working adults whose cost of time is higher).
I don't think we know the answer yet (at least for working adults whose cost of time is higher).
People and organizations need security and transparency.
For new technologies or apps to be widely used, they must be safe, transparent, and trustworthy. What does secure Metaverse and Web3 mean? This is an intriguing subject for both the business and public sectors. Cloud adoption grew in part due to improved security and data protection regulations.
The following frameworks can help analyze and understand new technologies and emerging technological topics, unless you are a significant investment fund with the financial ability to gamble on numerous initiatives and essentially form your own “index fund”.
I write on VC, startups, and leadership.
More on https://www.linkedin.com/in/joycejshen/ and https://joyceshen.substack.com/
This writing is my own opinion and does not represent investment advice.
More on Web3 & Crypto

Elnaz Sarraf
3 years ago
Why Bitcoin's Crash Could Be Good for Investors

The crypto market crashed in June 2022. Bitcoin and other cryptocurrencies hit their lowest prices in over a year, causing market panic. Some believe this crash will benefit future investors.
Before I discuss how this crash might help investors, let's examine why it happened. Inflation in the U.S. reached a 30-year high in 2022 after Russia invaded Ukraine. In response, the U.S. Federal Reserve raised interest rates by 0.5%, the most in almost 20 years. This hurts cryptocurrencies like Bitcoin. Higher interest rates make people less likely to invest in volatile assets like crypto, so many investors sold quickly.
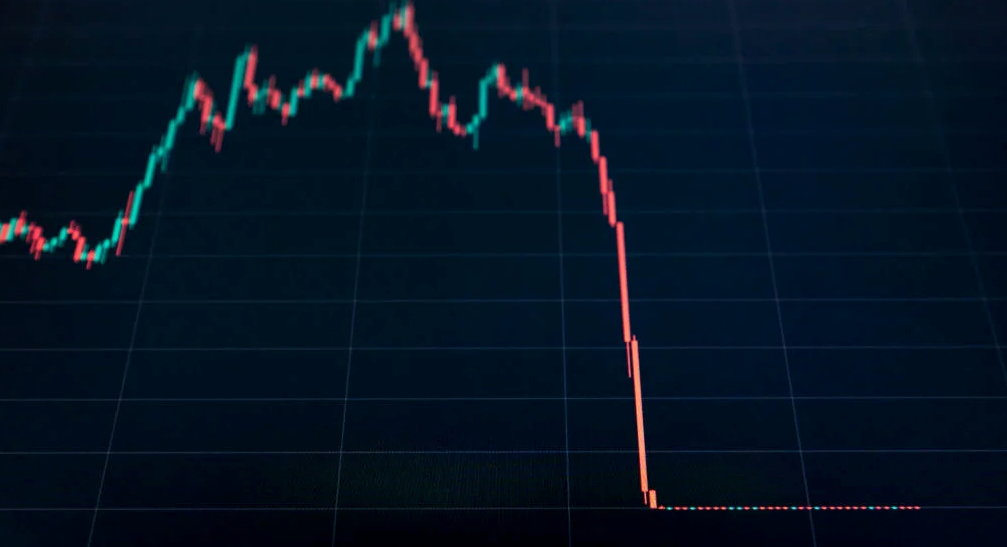
The crypto market collapsed. Bitcoin, Ethereum, and Binance dropped 40%. Other cryptos crashed so hard they were delisted from almost every exchange. Bitcoin peaked in April 2022 at $41,000, but after the May interest rate hike, it crashed to $28,000. Bitcoin investors were worried. Even in bad times, this crash is unprecedented.
Bitcoin wasn't "doomed." Before the crash, LUNA was one of the top 5 cryptos by market cap. LUNA was trading around $80 at the start of May 2022, but after the rate hike?
Less than 1 cent. LUNA lost 99.99% of its value in days and was removed from every crypto exchange. Bitcoin's "crash" isn't as devastating when compared to LUNA.
Many people said Bitcoin is "due" for a LUNA-like crash and that the only reason it hasn't crashed is because it's bigger. Still false. If so, Bitcoin should be worth zero by now. We didn't. Instead, Bitcoin reached 28,000, then 29k, 30k, and 31k before falling to 18k. That's not the world's greatest recovery, but it shows Bitcoin's safety.
Bitcoin isn't falling constantly. It fell because of the initial shock of interest rates, but not further. Now, Bitcoin's value is more likely to rise than fall. Bitcoin's low price also attracts investors. They know what prices Bitcoin can reach with enough hype, and they want to capitalize on low prices before it's too late.

Bitcoin's crash was bad, but in a way it wasn't. To understand, consider 2021. In March 2021, Bitcoin surpassed $60k for the first time. Elon Musk's announcement in May that he would no longer support Bitcoin caused a massive crash in the crypto market. In May 2017, Bitcoin's price hit $29,000. Elon Musk's statement isn't worth more than the Fed raising rates. Many expected this big announcement to kill Bitcoin.

Not so. Bitcoin crashed from $58k to $31k in 2021. Bitcoin fell from $41k to $28k in 2022. This crash is smaller. Bitcoin's price held up despite tensions and stress, proving investors still believe in it. What happened after the initial crash in the past?
Bitcoin fell until mid-July. This is also something we’re not seeing today. After a week, Bitcoin began to improve daily. Bitcoin's price rose after mid-July. Bitcoin's price fluctuated throughout the rest of 2021, but it topped $67k in November. Despite no major changes, the peak occurred after the crash. Elon Musk seemed uninterested in crypto and wasn't likely to change his mind soon. What triggered this peak? Nothing, really. What really happened is that people got over the initial statement. They forgot.
Internet users have goldfish-like attention spans. People quickly forgot the crash's cause and were back investing in crypto months later. Despite the market's setbacks, more crypto investors emerged by the end of 2017. Who gained from these peaks? Bitcoin investors who bought low. Bitcoin not only recovered but also doubled its ROI. It was like a movie, and it shows us what to expect from Bitcoin in the coming months.
The current Bitcoin crash isn't as bad as the last one. LUNA is causing market panic. LUNA and Bitcoin are different cryptocurrencies. LUNA crashed because Terra wasn’t able to keep its peg with the USD. Bitcoin is unanchored. It's one of the most decentralized investments available. LUNA's distrust affected crypto prices, including Bitcoin, but it won't last forever.
This is why Bitcoin will likely rebound in the coming months. In 2022, people will get over the rise in interest rates and the crash of LUNA, just as they did with Elon Musk's crypto stance in 2021. When the world moves on to the next big controversy, Bitcoin's price will soar.
Bitcoin may recover for another reason. Like controversy, interest rates fluctuate. The Russian invasion caused this inflation. World markets will stabilize, prices will fall, and interest rates will drop.
Next, lower interest rates could boost Bitcoin's price. Eventually, it will happen. The U.S. economy can't sustain such high interest rates. Investors will put every last dollar into Bitcoin if interest rates fall again.
Bitcoin has proven to be a stable investment. This boosts its investment reputation. Even if Ethereum dethrones Bitcoin as crypto king one day (or any other crypto, for that matter). Bitcoin may stay on top of the crypto ladder for a while. We'll have to wait a few months to see if any of this is true.
This post is a summary. Read the full article here.
JEFF JOHN ROBERTS
3 years ago
What just happened in cryptocurrency? A plain-English Q&A about Binance's FTX takedown.

Crypto people have witnessed things. They've seen big hacks, mind-boggling swindles, and amazing successes. They've never seen a day like Tuesday, when the world's largest crypto exchange murdered its closest competition.
Here's a primer on Binance and FTX's lunacy and why it matters if you're new to crypto.
What happened?
CZ, a shrewd Chinese-Canadian billionaire, runs Binance. FTX, a newcomer, has challenged Binance in recent years. SBF (Sam Bankman-Fried)—a young American with wild hair—founded FTX (initials are a thing in crypto).
Last weekend, CZ complained about SBF's lobbying and then exploited Binance's market power to attack his competition.
How did CZ do that?
CZ invested in SBF's new cryptocurrency exchange when they were friends. CZ sold his investment in FTX for FTT when he no longer wanted it. FTX clients utilize those tokens to get trade discounts, although they are less liquid than Bitcoin.
SBF made a mistake by providing CZ just too many FTT tokens, giving him control over FTX. It's like Pepsi handing Coca-Cola a lot of stock it could sell at any time. CZ got upset with SBF and flooded the market with FTT tokens.
SBF owns a trading fund with many FTT tokens, therefore this was catastrophic. SBF sought to defend FTT's worth by selling other assets to buy up the FTT tokens flooding the market, but it didn't succeed, and as FTT's value plummeted, his liabilities exceeded his assets. By Tuesday, his companies were insolvent, so he sold them to his competition.
Crazy. How could CZ do that?
CZ likely did this to crush a rising competition. It was also personal. In recent months, regulators have been tough toward the crypto business, and Binance and FTX have been trying to stay on their good side. CZ believed SBF was poisoning U.S. authorities by saying CZ was linked to China, so CZ took retribution.
“We supported previously, but we won't pretend to make love after divorce. We're neutral. But we won't assist people that push against other industry players behind their backs," CZ stated in a tragic tweet on Sunday. He crushed his rival's company two days later.
So does Binance now own FTX?
No. Not yet. CZ has only stated that Binance signed a "letter of intent" to acquire FTX. CZ and SBF say Binance will protect FTX consumers' funds.
Who’s to blame?
You could blame CZ for using his control over FTX to destroy it. SBF is also being criticized for not disclosing the full overlap between FTX and his trading company, which controlled plenty of FTT. If he had been upfront, someone might have warned FTX about this vulnerability earlier, preventing this mess.
Others have alleged that SBF utilized customer monies to patch flaws in his enterprises' balance accounts. That happened to multiple crypto startups that collapsed this spring, which is unfortunate. These are allegations, not proof.
Why does this matter? Isn't this common in crypto?
Crypto is notorious for shady executives and pranks. FTX is the second-largest crypto business, and SBF was largely considered as the industry's golden boy who would help it get on authorities' good side. Thus far.
Does this affect cryptocurrency prices?
Short-term, it's bad. Prices fell on suspicions that FTX was in peril, then rallied when Binance rescued it, only to fall again later on Tuesday.
These occurrences have hurt FTT and SBF's Solana token. It appears like a huge token selloff is affecting the rest of the market. Bitcoin fell 10% and Ethereum 15%, which is bad but not catastrophic for the two largest coins by market cap.

Robert Kim
4 years ago
Crypto Legislation Might Progress Beyond Talk in 2022
Financial regulators have for years attempted to apply existing laws to the multitude of issues created by digital assets. In 2021, leading federal regulators and members of Congress have begun to call for legislation to address these issues. As a result, 2022 may be the year when federal legislation finally addresses digital asset issues that have been growing since the mining of the first Bitcoin block in 2009.
Digital Asset Regulation in the Absence of Legislation
So far, Congress has left the task of addressing issues created by digital assets to regulatory agencies. Although a Congressional Blockchain Caucus formed in 2016, House and Senate members introduced few bills addressing digital assets until 2018. As of October 2021, Congress has not amended federal laws on financial regulation, which were last significantly revised by the Dodd-Frank Act in 2010, to address digital asset issues.
In the absence of legislation, issues that do not fit well into existing statutes have created problems. An example is the legal status of digital assets, which can be considered to be either securities or commodities, and can even shift from one to the other over time. Years after the SEC’s 2017 report applying the definition of a security to digital tokens, the SEC and the CFTC have yet to clarify the distinction between securities and commodities for the thousands of digital assets in existence.
SEC Chair Gary Gensler has called for Congress to act, stating in August, “We need additional Congressional authorities to prevent transactions, products, and platforms from falling between regulatory cracks.” Gensler has reached out to Sen. Elizabeth Warren (D-Ma.), who has expressed her own concerns about the need for legislation.
Legislation on Digital Assets in 2021
While regulators and members of Congress talked about the need for legislation, and the debate over cryptocurrency tax reporting in the 2021 infrastructure bill generated headlines, House and Senate bills proposing specific solutions to various issues quietly started to emerge.
Digital Token Sales
Several House bills attempt to address securities law barriers to digital token sales—some of them by building on ideas proposed by regulators in past years.
Exclusion from the definition of a security. Congressional Blockchain Caucus members have been introducing bills to exclude digital tokens from the definition of a security since 2018, and they have revived those bills in 2021. They include the Token Taxonomy Act of 2021 (H.R. 1628), successor to identically named bills in 2018 and 2019, and the Securities Clarity Act (H.R. 4451), successor to a 2020 namesake.
Safe harbor. SEC Commissioner Hester Peirce proposed a regulatory safe harbor for token sales in 2020, and two 2021 bills have proposed statutory safe harbors. Rep. Patrick McHenry (R-N.C.), Republican leader of the House Financial Services Committee, introduced a Clarity for Digital Tokens Act of 2021 (H.R. 5496) that would amend the Securities Act to create a safe harbor providing a grace period of exemption from Securities Act registration requirements. The Digital Asset Market Structure and Investor Protection Act (H.R. 4741) from Rep. Don Beyer (D-Va.) would amend the Securities Exchange Act to define a new type of security—a “digital asset security”—and add issuers of digital asset securities to an existing provision for delayed registration of securities.
Stablecoins
Stablecoins—digital currencies linked to the value of the U.S. dollar or other fiat currencies—have not yet been the subject of regulatory action, although Treasury Secretary Janet Yellen and Federal Reserve Chair Jerome Powell have each underscored the need to create a regulatory framework for them. The Beyer bill proposes to create a regulatory regime for stablecoins by amending Title 31 of the U.S. Code. Treasury Department approval would be required for any “digital asset fiat-based stablecoin” to be issued or used, under an application process to be established by Treasury in consultation with the Federal Reserve, the SEC, and the CFTC.
Serious consideration for any of these proposals in the current session of Congress may be unlikely. A spate of autumn bills on crypto ransom payments (S. 2666, S. 2923, S. 2926, H.R. 5501) shows that Congress is more inclined to pay attention first to issues that are more spectacular and less arcane. Moreover, the arcaneness of digital asset regulatory issues is likely only to increase further, now that major industry players such as Coinbase and Andreessen Horowitz are starting to roll out their own regulatory proposals.
Digital Dollar vs. Digital Yuan
Impetus to pass legislation on another type of digital asset, a central bank digital currency (CBDC), may come from a different source: rivalry with China.
China established itself as a world leader in developing a CBDC with a pilot project launched in 2020, and in 2021, the People’s Bank of China announced that its CBDC will be used at the Beijing Winter Olympics in February 2022. Republican Senators responded by calling for the U.S. Olympic Committee to forbid use of China’s CBDC by U.S. athletes in Beijing and introducing a bill (S. 2543) to require a study of its national security implications.
The Beijing Olympics could motivate a legislative mandate to accelerate implementation of a U.S. digital dollar, which the Federal Reserve has been in the process of considering in 2021. Antecedents to such legislation already exist. A House bill sponsored by 46 Republicans (H.R. 4792) has a provision that would require the Treasury Department to assess China’s CBDC project and report on the status of Federal Reserve work on a CBDC, and the Beyer bill includes a provision amending the Federal Reserve Act to authorize issuing a digital dollar.
Both parties are likely to support creating a digital dollar. The Covid-19 pandemic made a digital dollar for delivery of relief payments a popular idea in 2020, and House Democrats introduced bills with provisions for creating one in 2020 and 2021. Bipartisan support for a bill on a digital dollar, based on concerns both foreign and domestic in nature, could result.
International rivalry and bipartisan support may make the digital dollar a gateway issue for digital asset legislation in 2022. Legislative work on a digital dollar may open the door for considering further digital asset issues—including the regulatory issues that have been emerging for years—in 2022 and beyond.
You might also like

Adrien Book
3 years ago
What is Vitalik Buterin's newest concept, the Soulbound NFT?
Decentralizing Web3's soul
Our tech must reflect our non-transactional connections. Web3 arose from a lack of social links. It must strengthen these linkages to get widespread adoption. Soulbound NFTs help.
This NFT creates digital proofs of our social ties. It embodies G. Simmel's idea of identity, in which individuality emerges from social groups, just as social groups evolve from people.
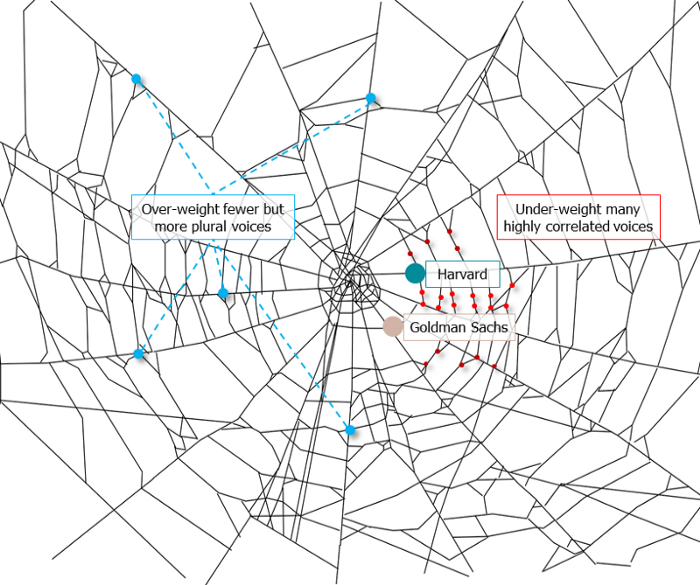
It's multipurpose. First, gather online our distinctive social features. Second, highlight and categorize social relationships between entities and people to create a spiderweb of networks.
1. 🌐 Reducing online manipulation: Only socially rich or respectable crypto wallets can participate in projects, ensuring that no one can create several wallets to influence decentralized project governance.
2. 🤝 Improving social links: Some sectors of society lack social context. Racism, sexism, and homophobia do that. Public wallets can help identify and connect distinct social groupings.
3. 👩❤️💋👨 Increasing pluralism: Soulbound tokens can ensure that socially connected wallets have less voting power online to increase pluralism. We can also overweight a minority of numerous voices.
4. 💰Making more informed decisions: Taking out an insurance policy requires a life review. Why not loans? Character isn't limited by income, and many people need a chance.
5. 🎶 Finding a community: Soulbound tokens are accessible to everyone. This means we can find people who are like us but also different. This is probably rare among your friends and family.
NFTs are dangerous, and I don't like them. Social credit score, privacy, lost wallet. We must stay informed and keep talking to innovators.
E. Glen Weyl, Puja Ohlhaver and Vitalik Buterin get all the credit for these ideas, having written the very accessible white paper “Decentralized Society: Finding Web3’s Soul”.

Dung Claire Tran
3 years ago
Is the future of brand marketing with virtual influencers?
Digital influences that mimic humans are rising.
Lil Miquela has 3M Instagram followers, 3.6M TikTok followers, and 30K Twitter followers. She's been on the covers of Prada, Dior, and Calvin Klein magazines. Miquela released Not Mine in 2017 and launched Hard Feelings at Lollapazoolas this year. This isn't surprising, given the rise of influencer marketing.
This may be unexpected. Miquela's fake. Brud, a Los Angeles startup, produced her in 2016.
Lil Miquela is one of many rising virtual influencers in the new era of social media marketing. She acts like a real person and performs the same tasks as sports stars and models.
The emergence of online influencers
Before 2018, computer-generated characters were rare. Since the virtual human industry boomed, they've appeared in marketing efforts worldwide.
In 2020, the WHO partnered up with Atlanta-based virtual influencer Knox Frost (@knoxfrost) to gather contributions for the COVID-19 Solidarity Response Fund.
Lu do Magalu (@magazineluiza) has been the virtual spokeswoman for Magalu since 2009, using social media to promote reviews, product recommendations, unboxing videos, and brand updates. Magalu's 10-year profit was $552M.
In 2020, PUMA partnered with Southeast Asia's first virtual model, Maya (@mayaaa.gram). She joined Singaporean actor Tosh Zhang in the PUMA campaign. Local virtual influencer Ava Lee-Graham (@avagram.ai) partnered with retail firm BHG to promote their in-house labels.

In Japan, Imma (@imma.gram) is the face of Nike, PUMA, Dior, Salvatore Ferragamo SpA, and Valentino. Imma's bubblegum pink bob and ultra-fine fashion landed her on the cover of Grazia magazine.

Lotte Home Shopping created Lucy (@here.me.lucy) in September 2020. She made her TV debut as a Christmas show host in 2021. Since then, she has 100K Instagram followers and 13K TikTok followers.
Liu Yiexi gained 3 million fans in five days on Douyin, China's TikTok, in 2021. Her two-minute video went viral overnight. She's posted 6 videos and has 830 million Douyin followers.
China's virtual human industry was worth $487 million in 2020, up 70% year over year, and is expected to reach $875.9 million in 2021.
Investors worldwide are interested. Immas creator Aww Inc. raised $1 million from Coral Capital in September 2020, according to Bloomberg. Superplastic Inc., the Vermont-based startup behind influencers Janky and Guggimon, raised $16 million by 2020. Craft Ventures, SV Angels, and Scooter Braun invested. Crunchbase shows the company has raised $47 million.
The industries they represent, including Augmented and Virtual reality, were worth $14.84 billion in 2020 and are projected to reach $454.73 billion by 2030, a CAGR of 40.7%, according to PR Newswire.
Advantages for brands
Forbes suggests brands embrace computer-generated influencers. Examples:
Unlimited creative opportunities: Because brands can personalize everything—from a person's look and activities to the style of their content—virtual influencers may be suited to a brand's needs and personalities.
100% brand control: Brand managers now have more influence over virtual influencers, so they no longer have to give up and rely on content creators to include brands into their storytelling and style. Virtual influencers can constantly produce social media content to promote a brand's identity and ideals because they are completely scandal-free.
Long-term cost savings: Because virtual influencers are made of pixels, they may be reused endlessly and never lose their beauty. Additionally, they can move anywhere around the world and even into space to fit a brand notion. They are also always available. Additionally, the expense of creating their content will not rise in step with their expanding fan base.
Introduction to the metaverse: Statista reports that 75% of American consumers between the ages of 18 and 25 follow at least one virtual influencer. As a result, marketers that support virtual celebrities may now interact with younger audiences that are more tech-savvy and accustomed to the digital world. Virtual influencers can be included into any digital space, including the metaverse, as they are entirely computer-generated 3D personas. Virtual influencers can provide brands with a smooth transition into this new digital universe to increase brand trust and develop emotional ties, in addition to the young generations' rapid adoption of the metaverse.
Better engagement than in-person influencers: A Hype Auditor study found that online influencers have roughly three times the engagement of their conventional counterparts. Virtual influencers should be used to boost brand engagement even though the data might not accurately reflect the entire sector.
Concerns about influencers created by computers
Virtual influencers could encourage excessive beauty standards in South Korea, which has a $10.7 billion plastic surgery industry.
A classic Korean beauty has a small face, huge eyes, and pale, immaculate skin. Virtual influencers like Lucy have these traits. According to Lee Eun-hee, a professor at Inha University's Department of Consumer Science, this could make national beauty standards more unrealistic, increasing demand for plastic surgery or cosmetic items.

Other parts of the world raise issues regarding selling items to consumers who don't recognize the models aren't human and the potential of cultural appropriation when generating influencers of other ethnicities, called digital blackface by some.
Meta, Facebook and Instagram's parent corporation, acknowledges this risk.
“Like any disruptive technology, synthetic media has the potential for both good and harm. Issues of representation, cultural appropriation and expressive liberty are already a growing concern,” the company stated in a blog post. “To help brands navigate the ethical quandaries of this emerging medium and avoid potential hazards, (Meta) is working with partners to develop an ethical framework to guide the use of (virtual influencers).”
Despite theoretical controversies, the industry will likely survive. Companies think virtual influencers are the next frontier in the digital world, which includes the metaverse, virtual reality, and digital currency.
In conclusion
Virtual influencers may garner millions of followers online and help marketers reach youthful audiences. According to a YouGov survey, the real impact of computer-generated influencers is yet unknown because people prefer genuine connections. Virtual characters can supplement brand marketing methods. When brands are metaverse-ready, the author predicts virtual influencer endorsement will continue to expand.

Mark Schaefer
3 years ago
20 Fun Uses for ChatGPT

Our RISE community is stoked on ChatGPT. ChatGPT has countless uses.
Early on. Companies are figuring out the legal and ethical implications of AI's content revolution. Using AI for everyday tasks is cool.
So I challenged RISE friends... Let's have fun and share non-obvious uses.
Onward!
1. Tweet
Jim MacLeod requested a design-themed Twitter thread from ChatGPT.
2. Novelize
Giuseppe Fratoni writes novels.
"This is amazing!" Impotent. I asked about writing, mystery novels, and jazz.
"Develop a mystery novel plot in which a disillusioned homicide detective hunts a serial killer who targets jazz musicians who play Autumn Leaves."
"I have:
Detective James Thompson is a seasoned veteran of the Homicide department, but lately he’s been feeling burnt out and disillusioned. His latest case, the murder of a young jazz pianist who was found brutally killed in his home, only serves to deepen his sense of despair … (much more provided)
3. Question-and-answer sessions
Bliss recommends:
You have a guest speaker and want to ask audience questions.
Pre-generate questions with ChatGPT. "And here's a question from our AI?"
The conference is about Western water scarcity. Water management expert. My AI question was...
Which desalination-related questions should I ask an expert?
ChatGPT said...
How is desalination currently being used around the world, and in what types of locations is it most effective?
What are the potential advantages and disadvantages of using desalination to provide fresh water?
What are some of the key challenges and limitations of desalination technology, and how are they being addressed?
4. Game-making
Richard's a board game expert. He suggests using ChatGPT to plan games. Note: Some people have started getting help solving crossword puzzle clues.

5. Matchmaking
Tanya Thompson thinks it helps dating. ChatGPT:
Here are some flirty first-message ideas for dating apps:
I noticed you from afar. I had to say hi and see if we clicked.
Your profile picture is gorgeous. I'm obsessed with your [Feature] and want to know you better.
I don't usually message first, but I had to. You're [Attractive Quality] and I can't wait to talk.”
Hello. Your profile intimidates me. I'm starstruck by your [Attractiveness]. (Many instances)
5. Solitude/anxiety
ChatGPT excels at one-on-one conversations.
PepperBrooks: "I'm sad and lonely."
ChatGPT: I’m sorry to hear that you’re feeling sad and lonely. It’s natural to feel down sometimes, but it’s important to remember that you’re not alone. There are many people who care about you and want to help you. It can be helpful to talk to someone about your feelings, whether it’s a close friend, family member, or mental health professional.
Sometimes, just expressing your thoughts and emotions to someone else can help to alleviate your sadness and loneliness. It’s also important to take care of yourself and do things that make you happy, such as spending time with loved ones, pursuing a hobby, or exercising. These things can help to improve your mood and make you feel more connected to others. Remember that you are strong and capable, and that you can get through this difficult time.
Daniel Nestle asked ChatGPT to generate journal prompts to help him deal with anxiety.
Write down the things that are causing you anxiety at the moment.
Describe a situation in which you felt anxious and how you coped with it.
Reflect on how your thoughts and beliefs contribute to your anxiety.
Write a letter to your anxiety, expressing your feelings and concerns
Imagine yourself in a calm and peaceful place, and describe it in detail.
(many more items followed)
6. Names
Continued Daniel:
Also, naming ideas.
Me: Name this drink. Japanese gin, unsweetened tonic, lime, Szechuan pepper, grapefruit.
ChatGPT: How about “Sakura Sunrise?” The name incorporates the Japanese gin and the citrus flavors of grapefruit and lime, and the word “sunrise” suggests a fresh and invigorating start to the day. Alternatively, you could go with something like “Peppered Grapefruit Gin Fizz” to emphasize the unique flavor combination of Szechuan pepper and grapefruit.
7. Translation on the go
Monks recommends: ChatGPT is a perfect mobile translation tool. Say you need help in Italy.
ME: Translate to Italian
Where is the nearest gas station?
ChatGPT: “La mia auto sta per esaurire il carburante, mi puoi dire dove si trova la stazione di servizio più vicina?”
8. Fitness
Monks added:
ME: In 3 months, I want to run 5km. Plan out how I can do this.
ChatGPT: Here's a 3-month plan to run 5km.
Start by walking for 15–20 minutes each day to build up your endurance and get your body used to regular exercise.
After a week of walking, begin incorporating short jogs into your routine. Start by jogging for 1–2 minutes at a time, with walking breaks in between. Gradually increase the length of your jogs and reduce the amount of time you spend walking.
Once you can jog for 10 minutes without stopping, start increasing the distance of your runs. Aim to run 1km without stopping and then gradually increase the distance over time.
In addition to your regular runs, incorporate strength training and stretching into your routine to improve your overall fitness and reduce the risk of injury.
(more details continued on)
9. Integrations and coding
10. Teacher lesson plans
Spencer Crandall saved time.
This morning, I wondered who has the hardest job. Teachers.
Many students, little time. ChatGPT could handle lesson planning. I tried it and got this.
Lesson Title: The History and Impact of Artificial Intelligence
Students will understand the history and development of AI and the potential positive and negative impacts on society.
AI timeline AI technologies and applications
Overview:
Introduce the topic of artificial intelligence, and explain that it refers to the development of computer systems and algorithms that can simulate human intelligence and behavior.
Show the timeline of significant events in the history of AI, and discuss the key milestones and developments in the field.
Show examples of AI technologies and applications, and explain how they are used in various industries and fields.
Discuss the potential positive and negative impacts of AI on society, including its potential to improve productivity, efficiency, and safety, as well as its potential to create new challenges and concerns, such as job displacement and ethical issues.
(many more details followed)
11. Find podcast guests.
Joeri Billast suggested:
Who should be on my Web3 podcast?
ChatGPT: Web3 marketing experts, influencers, and thought leaders make great podcast guests. These include Web3 marketers, content creators, business owners, entrepreneurs, and technologists. You could invite Web3 startups and organizations to your podcast.
Please give examples.
ChatGPT: Ideal Web3 marketing podcast guests include:
Tim Berner-Lee, inventor of the World Wide Web
Chris Dixon, general partner at Andreessen Horowitz
Vitalik Buterin, founder of Ethereum
Joe Lubin, founder of ConsenSys
Susan Fowler, author of Whistleblower
(many other suggestions)
12. Comments and reviews on social media
Lisa Monk thinks ChatGPT can help retail staff with social media.
She asked ChatGPT to "review this restaurant"
POSITIVE CUSTOMER REVIEW: I absolutely love this place. We eat out a lot however this place has topped it all. Perfect meals, amazing staff and the timing for it all was great! Special thanks to Sophie B (you rock) From your guests all the way from the Gold Coast, THANK YOU
ChatGPT REPLY: Thank you so much for your kind words and for taking the time to write a review. We are delighted to hear that you had such a great experience at our restaurant. We are thrilled that you enjoyed your meal and the service provided by Sophie. It’s always a pleasure to serve guests visiting from the Gold Coast and we are grateful for your support. We look forward to welcoming you back again soon. Thank you again for your positive review.
CUSTOMER REVIEW: Most average food, there is a nice view, But that’s about it
ChatGPT: Thank you for your review. We apologize if your dining experience was not up to your expectations. We strive to provide top-quality food and service to all of our customers, and we will take your feedback into consideration as we continue to improve. Thank you for letting us know about your experience.
13. Crime-fighting
Zack Seipert said, "I researched some famous unsolved murders, and ChatGPT laid out the crime, suspects, clues, and more." I bet experienced detectives could solve some of these cold cases.
14. Reduce bias
Joanne Taylor struggles to remove biases from her writing. She asked ChatGPT for ideas.
I asked ChatGPT to check a text for racial bias, and it did well.
15. Furnishings
I designed a small, unique table using ChatGPT and MidJourney. I edited ChatGPT's idea for clarity and brevity before entering it in MidJourney.
Results:

16. Serialize a novel
Scott Scowcoft led ChatCPT through iterations of a story text to create serialized novel frames. You can view this here.
17. Interview preparation
I was on a sales podcast. Although this is marketing-related, it's not my forte. I asked ChatGPT for help with a sales interview. Response:
Here are some interview questions about the future of sales and how to answer them.
How will technology affect sales in the future?
Technology will impact sales in the coming years. Automation and AI could be used to handle routine tasks, and data analysis and CRM could become more important. E-commerce and online sales channels are also reshaping the sales landscape.
How will the salesperson's role change?
Future sales roles may change in response to changing customer needs and expectations. Salespeople must be knowledgeable and consultative to help customers navigate complex products and services. Increasing importance of data analysis and CRM tools will require salespeople to understand and use technology effectively.
Future sales professionals will need what skills?
Future salespeople will need many skills. Sales professionals must have strong communication and interpersonal skills, as well as product and service knowledge and the ability to use data analysis and CRM tools effectively. Adapting to changing customer needs and staying current on industry trends will also be important for sales success.
18. Gift ideas
I need Christmas gift ideas for my wife. I asked:
Suggest a gift idea under $200 for a middle-aged woman who loves The Eagles.
A middle-aged woman who loves The Eagles might like a vinyl record of "Hotel California" or "The Long Run." Many music fans enjoy the unique sound and experience of vinyl records.
Pair the record with a high-quality record player for a complete gift. The vinyl record and record player should fit within your $200 budget for an Eagles fan.
19. Explaining complex concepts
I entered: Explain quantum physics to me as if I were 10 years old.
Quantum physics is a branch of science that studies how tiny particles, like atoms and subatomic particles, behave. These particles are so small that they don’t always follow the same rules as the things we can see and touch every day.
For example, sometimes they can be in two places at the same time, or they can be friends with each other even if they are far apart. This might sound strange, but it’s what scientists have learned from studying these tiny particles. Quantum physics helps us understand how the world works at a very small scale, and it can also help us make new technologies, like computers that are much faster than the ones we have today.
20. AP-style editing
Blogs, journals, and books follow AP Style. I asked ChatGPT to "edit using AP Style" and it did a great job.
And then... "Write a catchy headline for a blog post about 16 ChatGPT uses"
Here are some possible blog post titles for 20 creative ChatGPT uses:
“20 Fun and Creative Ways to Use ChatGPT: From Games to Quizzes and More”
“The Ultimate Guide to Using ChatGPT for Entertainment and Creativity”
“20 Reasons to Use ChatGPT: How it Can Enhance Your Gaming, Storytelling, and More”
20 Entertaining Uses for ChatGPT You Never Knew Were Possible”
“Unleash Your Imagination with ChatGPT: 16 Creative and Fun Ways to Use it”
In a previous post, I said ChatGPT will change marketing careers forever. I have never made a statement like that in my life. Even in the early days of the internet, people were cautious.
This technology was just released two weeks ago, and over a million people are already using it. This is the fastest technology adoption in history.
Today's post offers inventive and entertaining ideas, but it's just the beginning. ChatGPT writes code, music, and papers.