



More on Technology

Paul DelSignore
2 years ago
The stunning new free AI image tool is called Leonardo AI.
Leonardo—The New Midjourney?
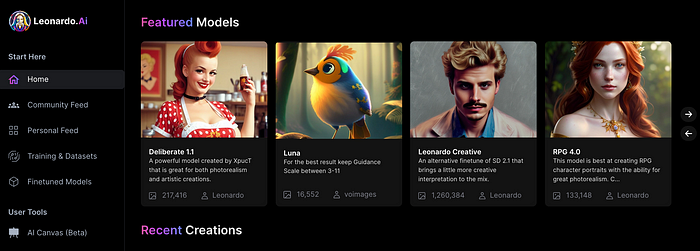
Users are comparing the new cowboy to Midjourney.
Leonardo.AI creates great photographs and has several unique capabilities I haven't seen in other AI image systems.
Midjourney's quality photographs are evident in the community feed.

Create Pictures Using Models
You can make graphics using platform models when you first enter the app (website):
Luma, Leonardo creative, Deliberate 1.1.
Clicking a model displays its description and samples:
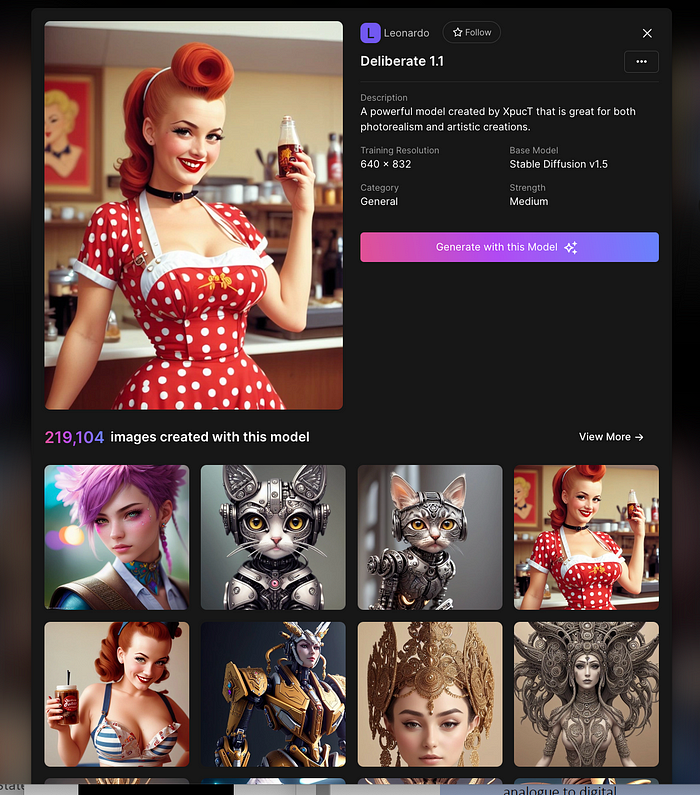
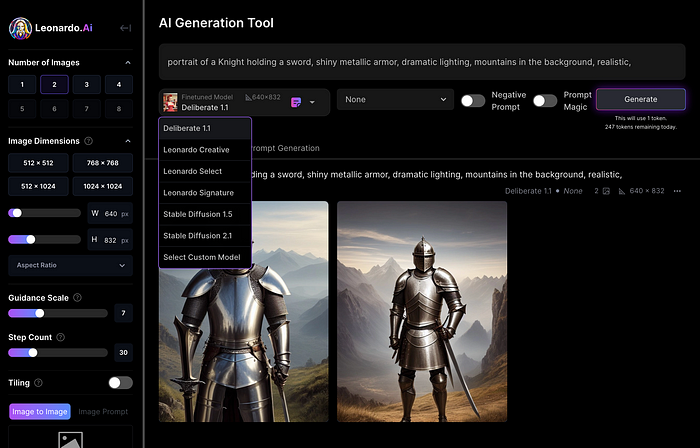
Click Generate With This Model.
Then you can add your prompt, alter models, photos, sizes, and guide scale in a sleek UI.
Changing Pictures
Leonardo's Canvas editor lets you change created images by hovering over them:

The editor opens with masking, erasing, and picture download.

Develop Your Own Models
I've never seen anything like Leonardo's model training feature.
Upload a handful of similar photographs and save them as a model for future images. Share your model with the community.
You can make photos using your own model and a community-shared set of fine-tuned models:
Obtain Leonardo access
Leonardo is currently free.
Visit Leonardo.ai and click "Get Early Access" to receive access.
Add your email to receive a link to join the discord channel. Simply describe yourself and fill out a form to join the discord channel.
Please go to 👑│introductions to make an introduction and ✨│priority-early-access will be unlocked, you must fill out a form and in 24 hours or a little more (due to demand), the invitation will be sent to you by email.
I got access in two hours, so hopefully you can too.
Last Words
I know there are many AI generative platforms, some free and some expensive, but Midjourney produces the most artistically stunning images and art.
Leonardo is the closest I've seen to Midjourney, but Midjourney is still the leader.
It's free now.
Leonardo's fine-tuned model selections, model creation, image manipulation, and output speed and quality make it a great AI image toolbox addition.

Christianlauer
3 years ago
Looker Studio Pro is now generally available, according to Google.
Great News about the new Google Business Intelligence Solution

Google has renamed Data Studio to Looker Studio and Looker Studio Pro.
Now, Google releases Looker Studio Pro. Similar to the move from Data Studio to Looker Studio, Looker Studio Pro is basically what Looker was previously, but both solutions will merge. Google says the Pro edition will acquire new enterprise management features, team collaboration capabilities, and SLAs.
![Dashboard Example in Looker Studio Pro — Image Source: Google[2]](https://storage.googleapis.com/int3grity/posts/m9yb4IqJCm7D/images/ZuJudlWT6GUeTKKNVduA5)
In addition to Google's announcements and sales methods, additional features include:
Looker Studio assets can now have organizational ownership. Customers can link Looker Studio to a Google Cloud project and migrate existing assets once. This provides:
Your users' created Looker Studio assets are all kept in a Google Cloud project.
When the users who own assets leave your organization, the assets won't be removed.
Using IAM, you may provide each Looker Studio asset in your company project-level permissions.
Other Cloud services can access Looker Studio assets that are owned by a Google Cloud project.
Looker Studio Pro clients may now manage report and data source access at scale using team workspaces.
Google announcing these features for the pro version is fascinating. Both products will likely converge, but Google may only release many features in the premium version in the future. Microsoft with Power BI and its free and premium variants already achieves this.
Sources and Further Readings
Google, Release Notes (2022)
Google, Looker (2022)

Tim Soulo
3 years ago
Here is why 90.63% of Pages Get No Traffic From Google.
The web adds millions or billions of pages per day.
How much Google traffic does this content get?
In 2017, we studied 2 million randomly-published pages to answer this question. Only 5.7% of them ranked in Google's top 10 search results within a year of being published.
94.3 percent of roughly two million pages got no Google traffic.
Two million pages is a small sample compared to the entire web. We did another study.
We analyzed over a billion pages to see how many get organic search traffic and why.
How many pages get search traffic?
90% of pages in our index get no Google traffic, and 5.2% get ten visits or less.
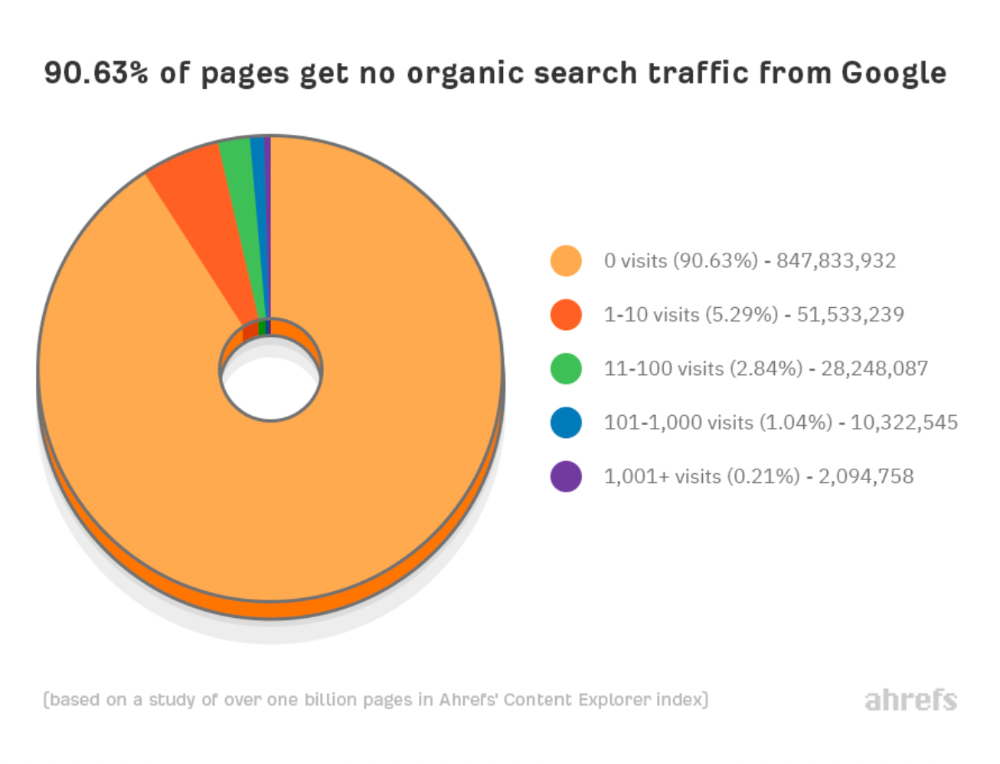
90% of google pages get no organic traffic
How can you join the minority that gets Google organic search traffic?
There are hundreds of SEO problems that can hurt your Google rankings. If we only consider common scenarios, there are only four.
Reason #1: No backlinks
I hate to repeat what most SEO articles say, but it's true:
Backlinks boost Google rankings.
Google's "top 3 ranking factors" include them.
Why don't we divide our studied pages by the number of referring domains?
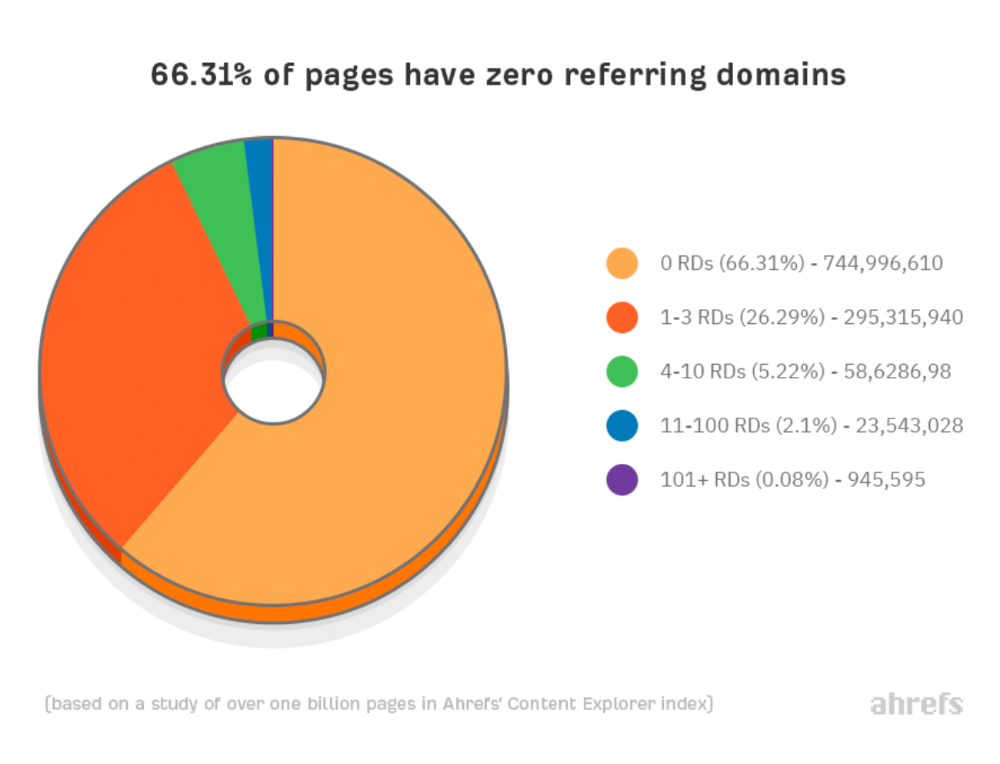
66.31 percent of pages have no backlinks, and 26.29 percent have three or fewer.
Did you notice the trend already?
Most pages lack search traffic and backlinks.
But are these the same pages?
Let's compare monthly organic search traffic to backlinks from unique websites (referring domains):
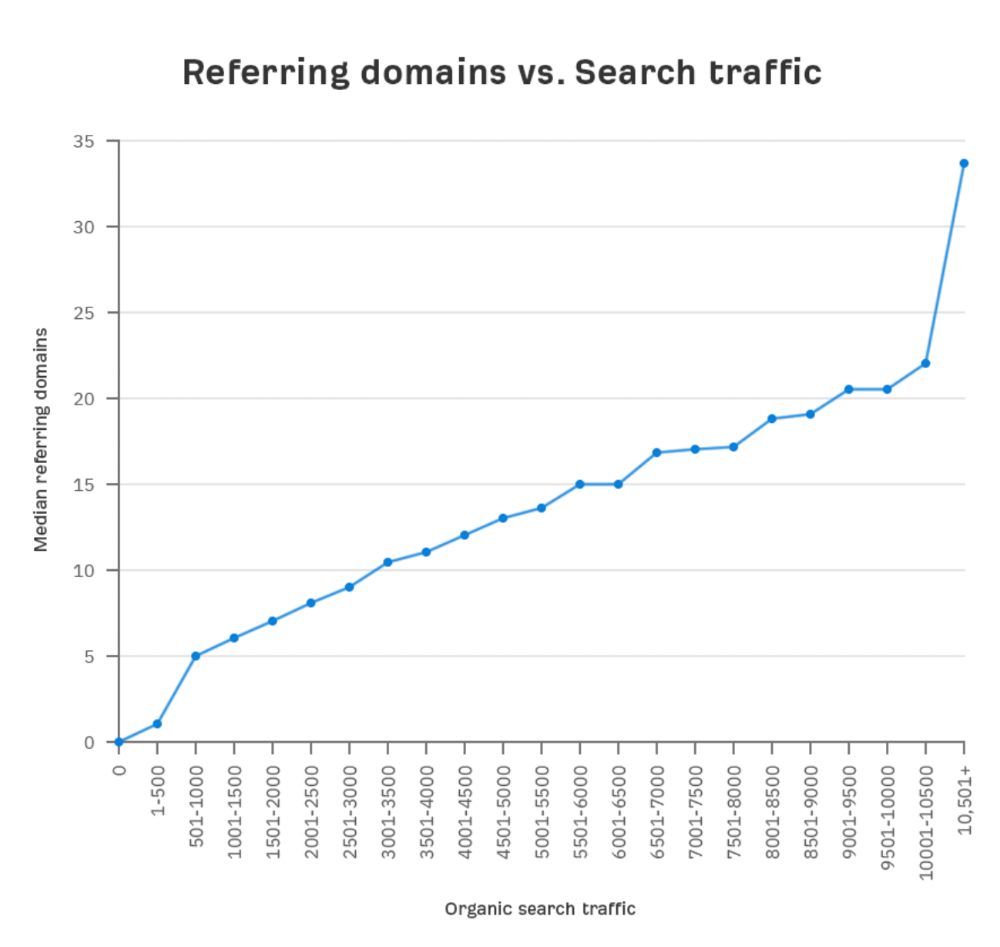
More backlinks equals more Google organic traffic.
Referring domains and keyword rankings are correlated.
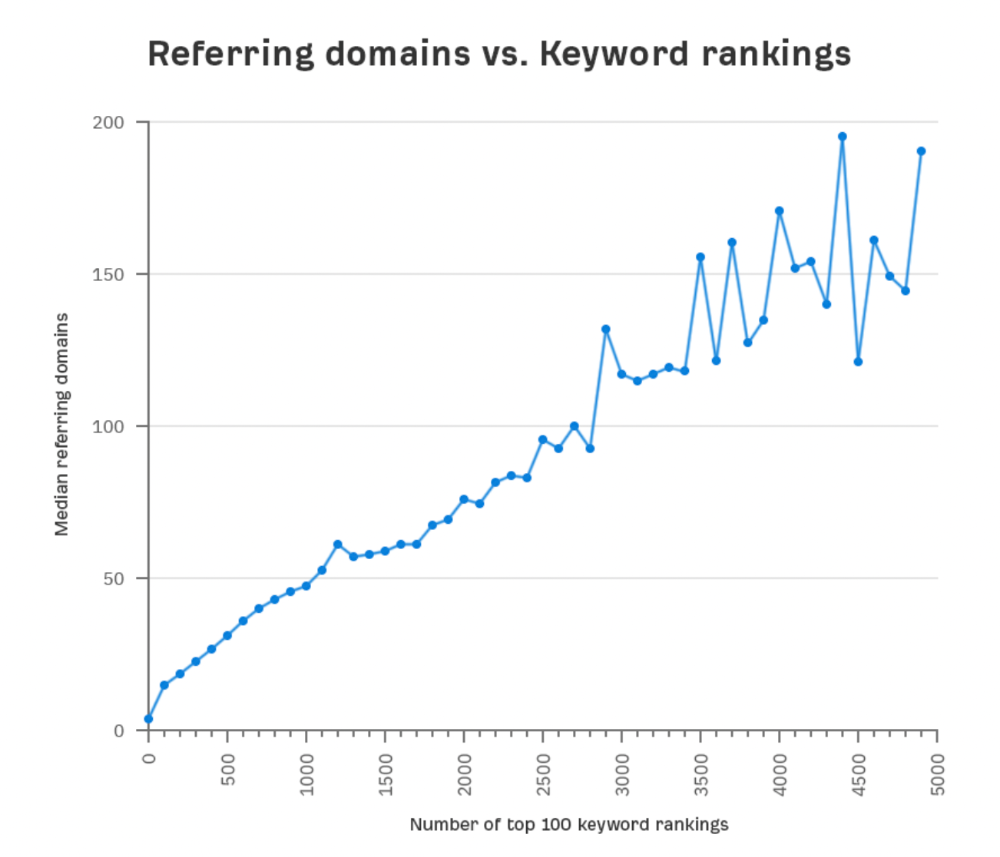
It's important to note that correlation does not imply causation, and none of these graphs prove backlinks boost Google rankings. Most SEO professionals agree that it's nearly impossible to rank on the first page without backlinks.
You'll need high-quality backlinks to rank in Google and get search traffic.
Is organic traffic possible without links?
Here are the numbers:
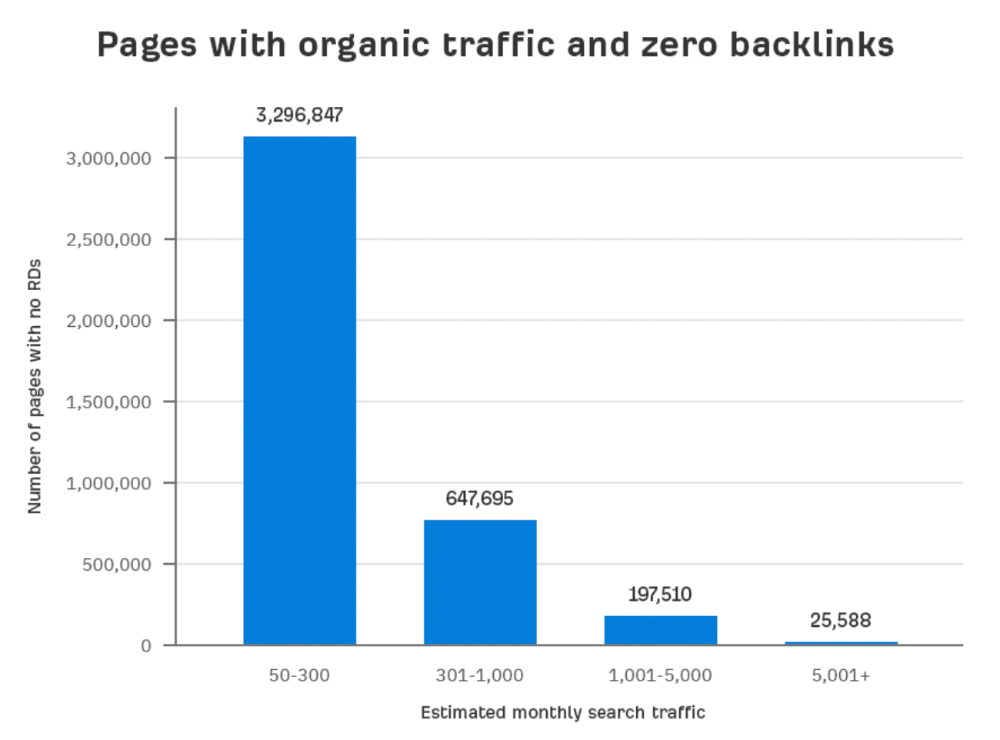
Four million pages get organic search traffic without backlinks. Only one in 20 pages without backlinks has traffic, which is 5% of our sample.
Most get 300 or fewer organic visits per month.
What happens if we exclude high-Domain-Rating pages?
The numbers worsen. Less than 4% of our sample (1.4 million pages) receive organic traffic. Only 320,000 get over 300 monthly organic visits, or 0.1% of our sample.
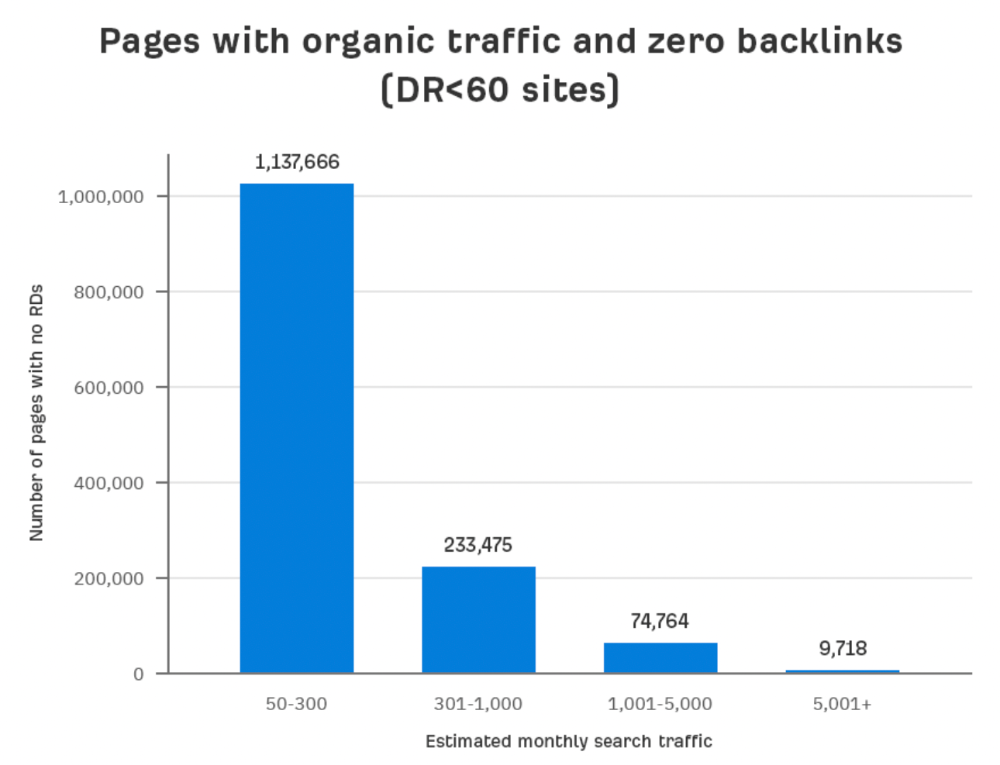
This suggests high-authority pages without backlinks are more likely to get organic traffic than low-authority pages.
Internal links likely pass PageRank to new pages.
Two other reasons:
Our crawler's blocked. Most shady SEOs block backlinks from us. This prevents competitors from seeing (and reporting) PBNs.
They choose low-competition subjects. Low-volume queries are less competitive, requiring fewer backlinks to rank.
If the idea of getting search traffic without building backlinks excites you, learn about Keyword Difficulty and how to find keywords/topics with decent traffic potential and low competition.
Reason #2: The page has no long-term traffic potential.
Some pages with many backlinks get no Google traffic.
Why? I filtered Content Explorer for pages with no organic search traffic and divided them into four buckets by linking domains.
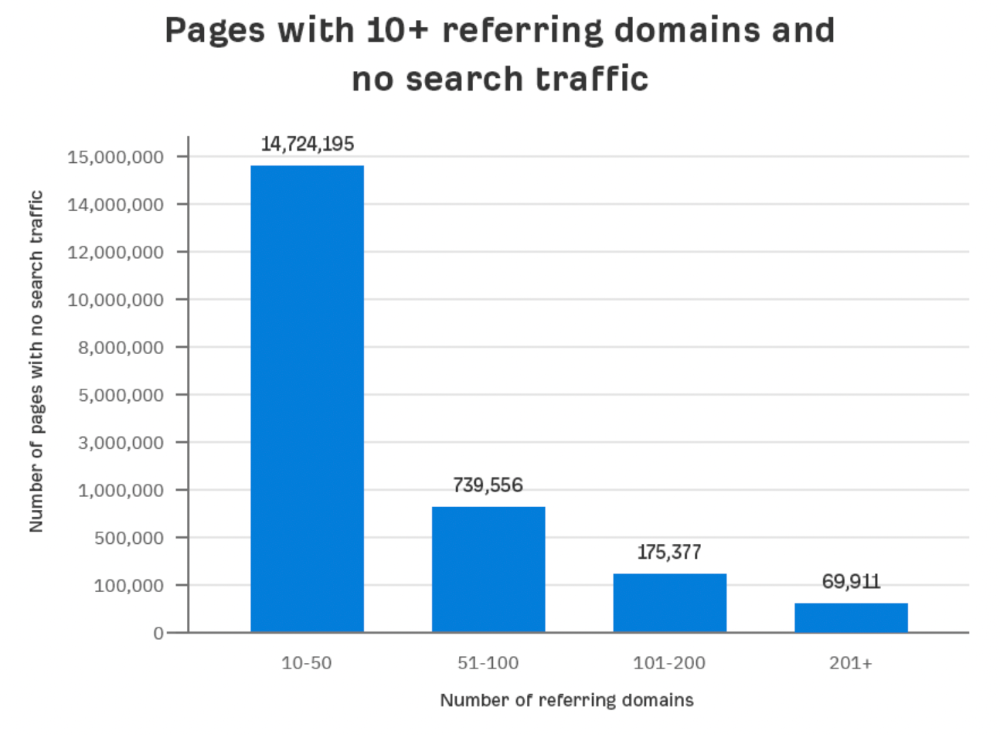
Almost 70k pages have backlinks from over 200 domains, but no search traffic.
By manually reviewing these (and other) pages, I noticed two general trends that explain why they get no traffic:
They overdid "shady link building" and got penalized by Google;
They're not targeting a Google-searched topic.
I won't elaborate on point one because I hope you don't engage in "shady link building"
#2 is self-explanatory:
If nobody searches for what you write, you won't get search traffic.
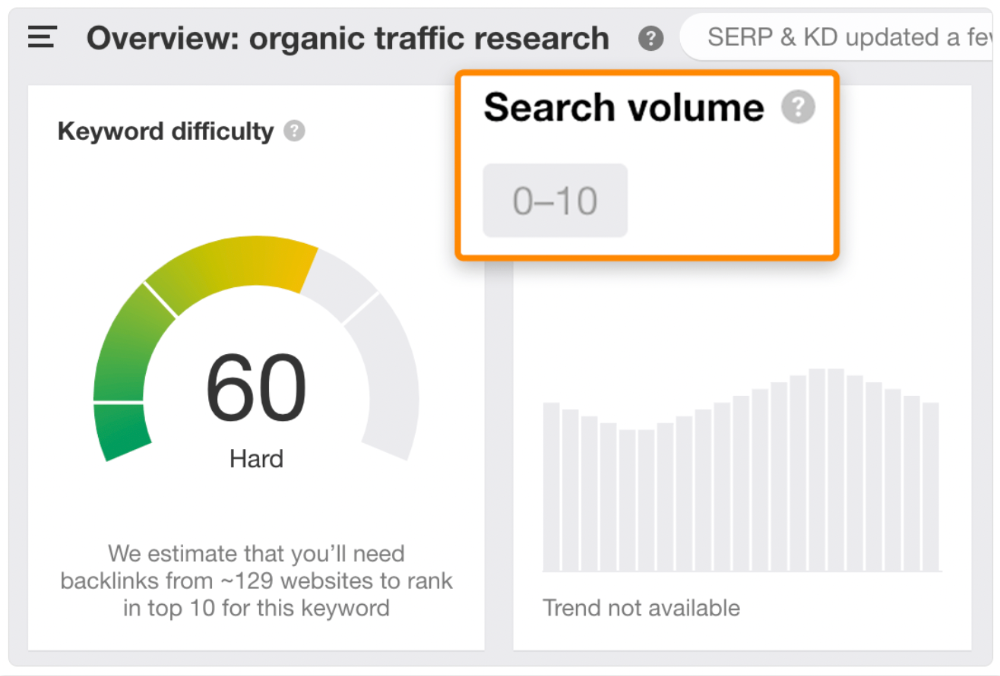
Consider one of our blog posts' metrics:

No organic traffic despite 337 backlinks from 132 sites.
The page is about "organic traffic research," which nobody searches for.
News articles often have this. They get many links from around the web but little Google traffic.
People can't search for things they don't know about, and most don't care about old events and don't search for them.
Note:
Some news articles rank in the "Top stories" block for relevant, high-volume search queries, generating short-term organic search traffic.
The Guardian's top "Donald Trump" story:
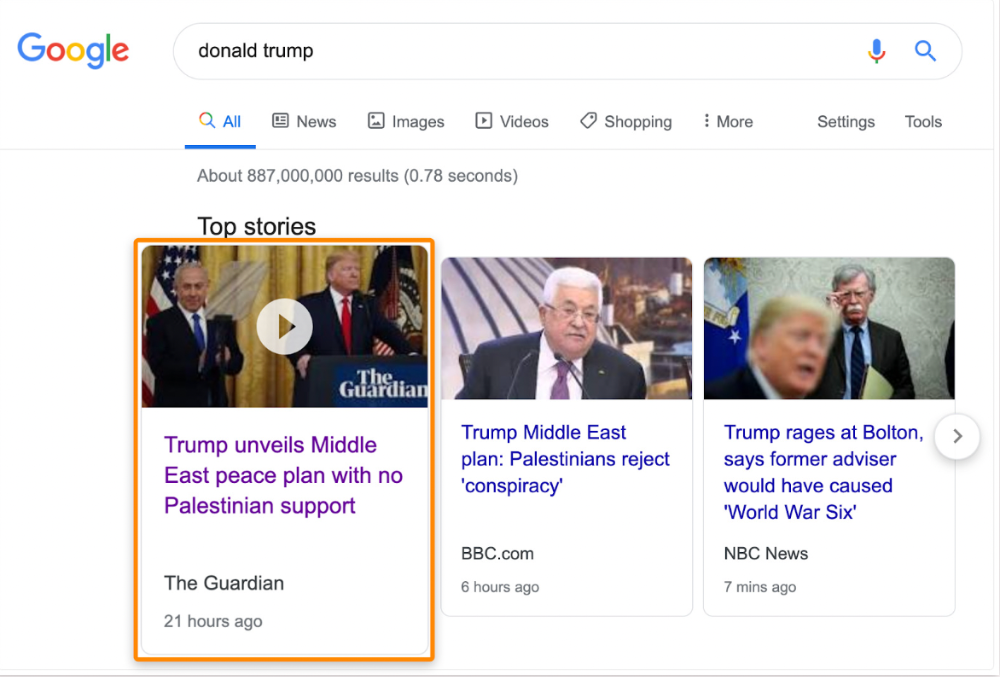
Ahrefs caught on quickly:
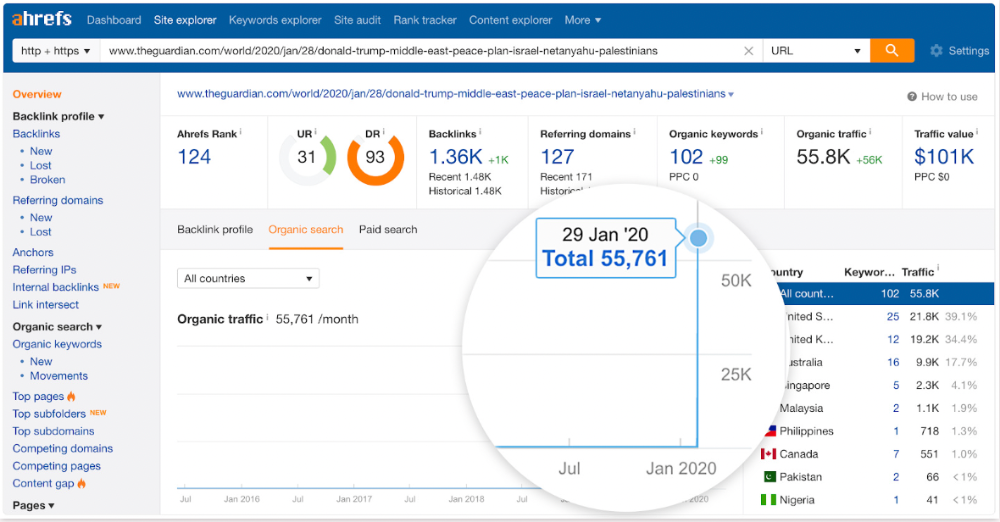
"Donald Trump" gets 5.6M monthly searches, so this page got a lot of "Top stories" traffic.
I bet traffic has dropped if you check now.
One of the quickest and most effective SEO wins is:
Find your website's pages with the most referring domains;
Do keyword research to re-optimize them for relevant topics with good search traffic potential.
Bryan Harris shared this "quick SEO win" during a course interview:
He suggested using Ahrefs' Site Explorer's "Best by links" report to find your site's most-linked pages and analyzing their search traffic. This finds pages with lots of links but little organic search traffic.
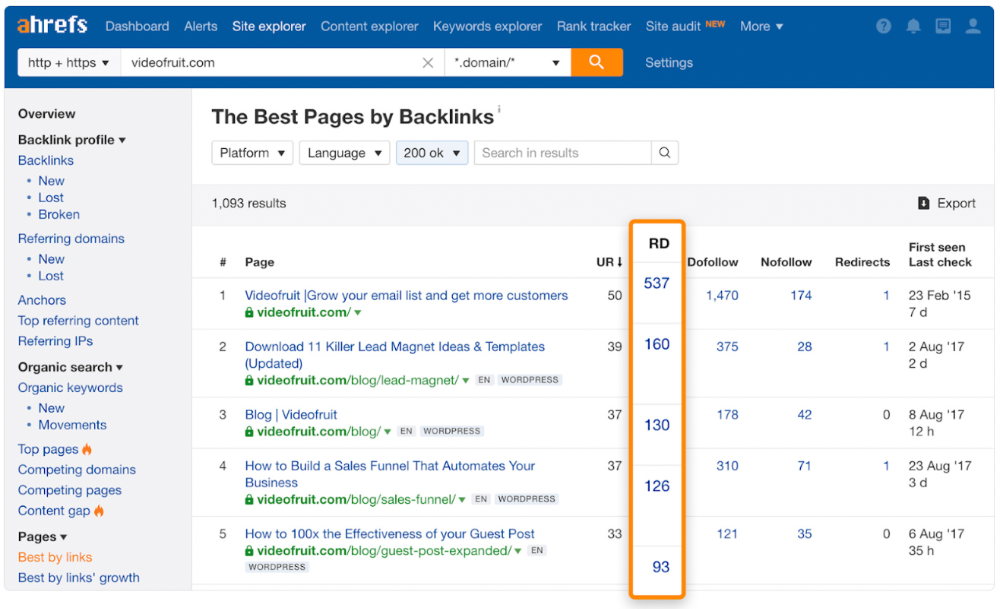
We see:
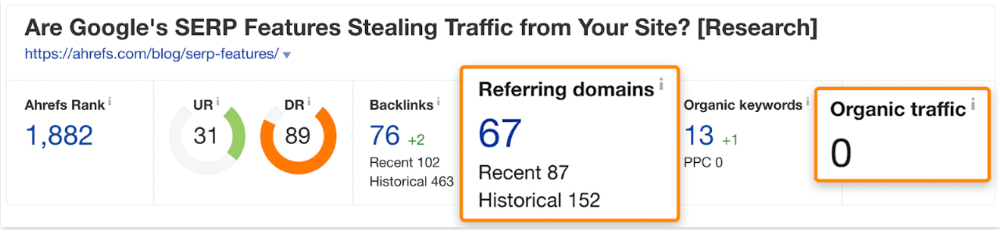
The guide has 67 backlinks but no organic traffic.
We could fix this by re-optimizing the page for "SERP"
A similar guide with 26 backlinks gets 3,400 monthly organic visits, so we should easily increase our traffic.
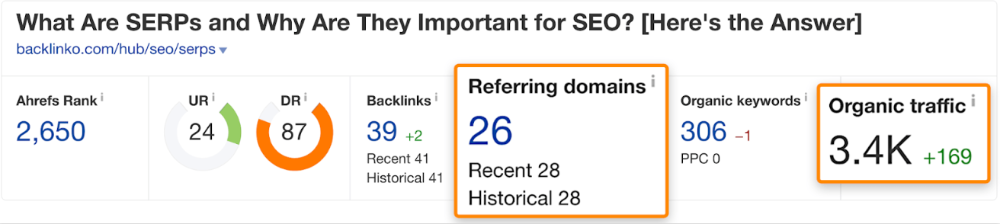
Don't do this with all low-traffic pages with backlinks. Choose your battles wisely; some pages shouldn't be ranked.
Reason #3: Search intent isn't met
Google returns the most relevant search results.
That's why blog posts with recommendations rank highest for "best yoga mat."
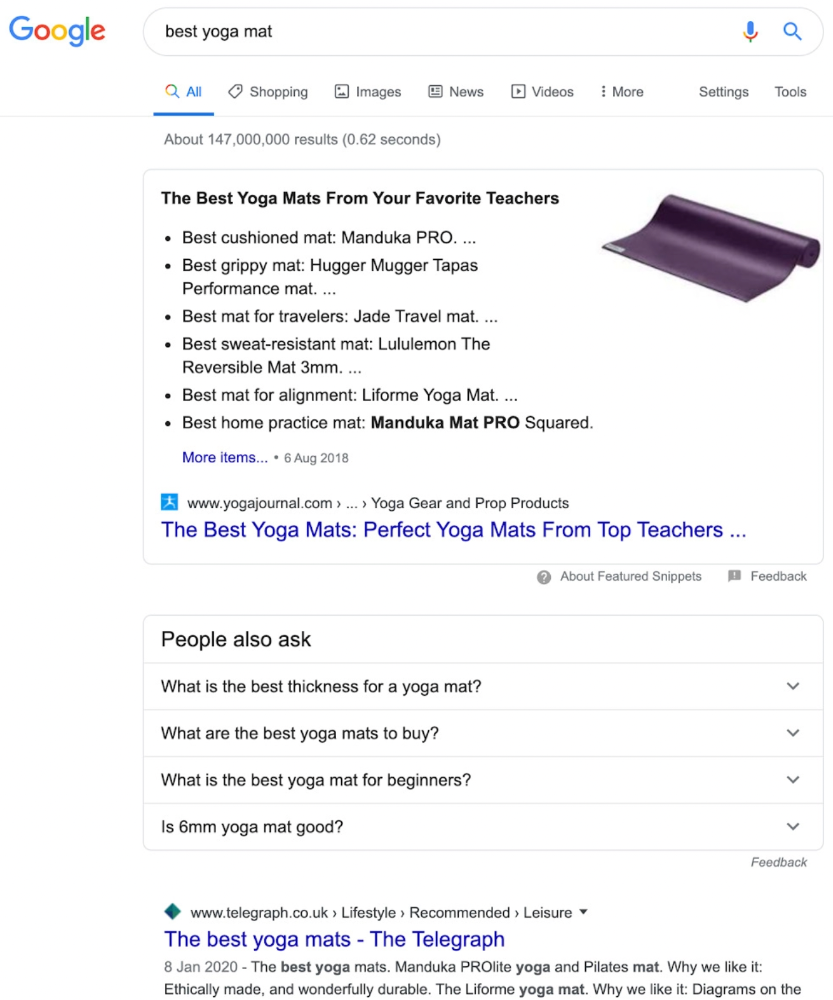
Google knows that most searchers aren't buying.
It's also why this yoga mats page doesn't rank, despite having seven times more backlinks than the top 10 pages:
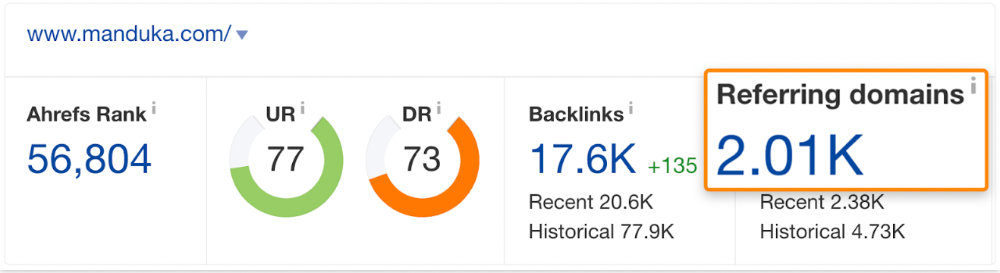
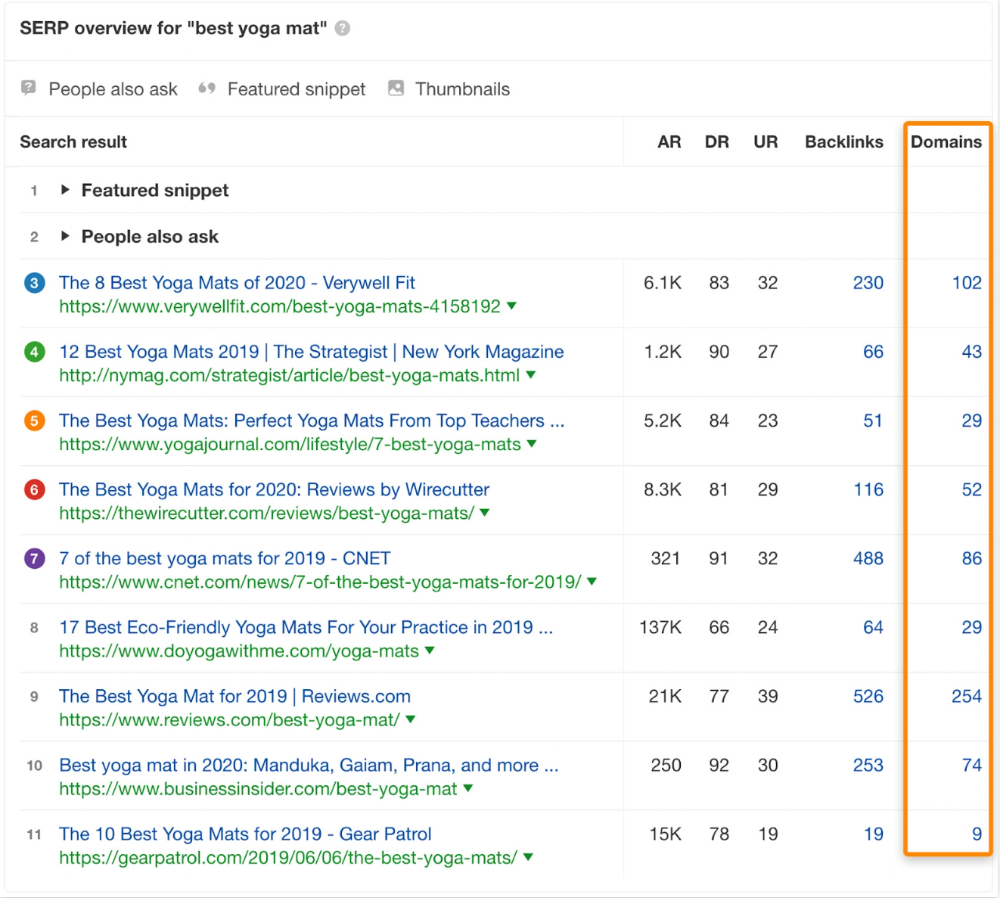
The page ranks for thousands of other keywords and gets tens of thousands of monthly organic visits. Not being the "best yoga mat" isn't a big deal.
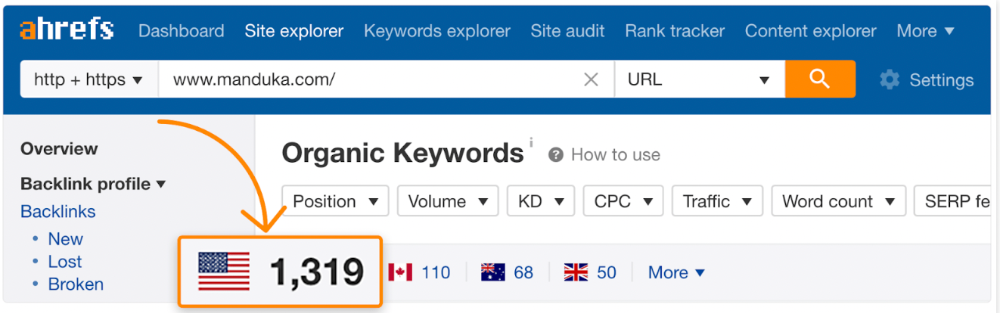
If you have pages with lots of backlinks but no organic traffic, re-optimizing them for search intent can be a quick SEO win.
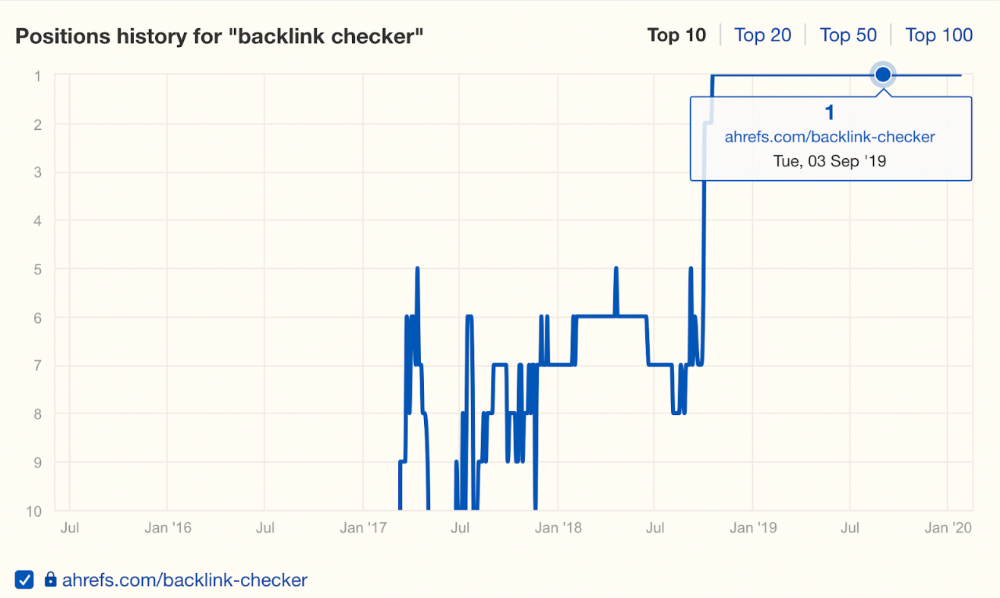
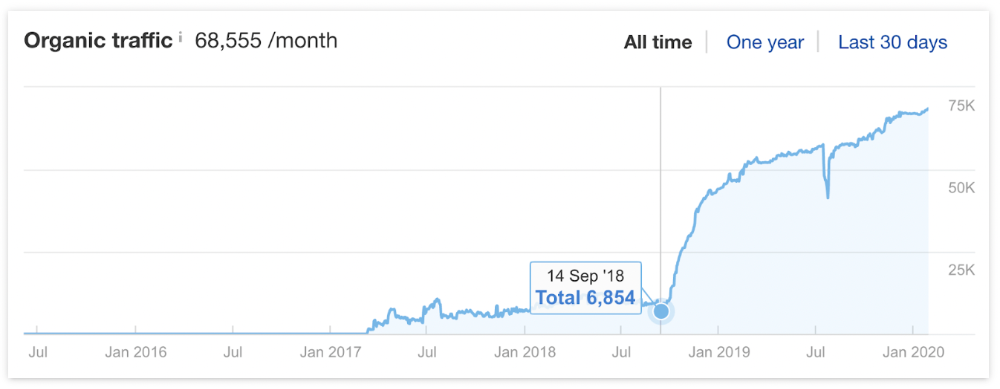
It was originally a boring landing page describing our product's benefits and offering a 7-day trial.
We realized the problem after analyzing search intent.
People wanted a free tool, not a landing page.
In September 2018, we published a free tool at the same URL. Organic traffic and rankings skyrocketed.
Reason #4: Unindexed page
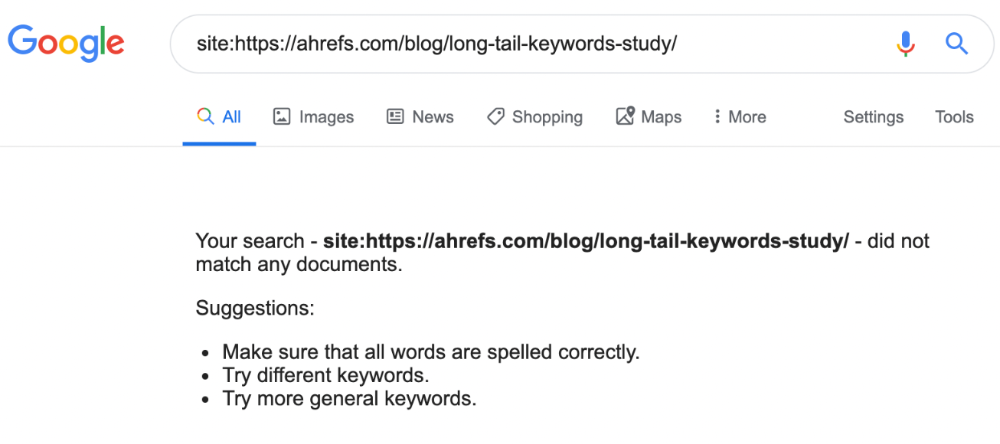
Google can’t rank pages that aren’t indexed.
If you think this is the case, search Google for site:[url]. You should see at least one result; otherwise, it’s not indexed.
A rogue noindex meta tag is usually to blame. This tells search engines not to index a URL.
Rogue canonicals, redirects, and robots.txt blocks prevent indexing.
Check the "Excluded" tab in Google Search Console's "Coverage" report to see excluded pages.
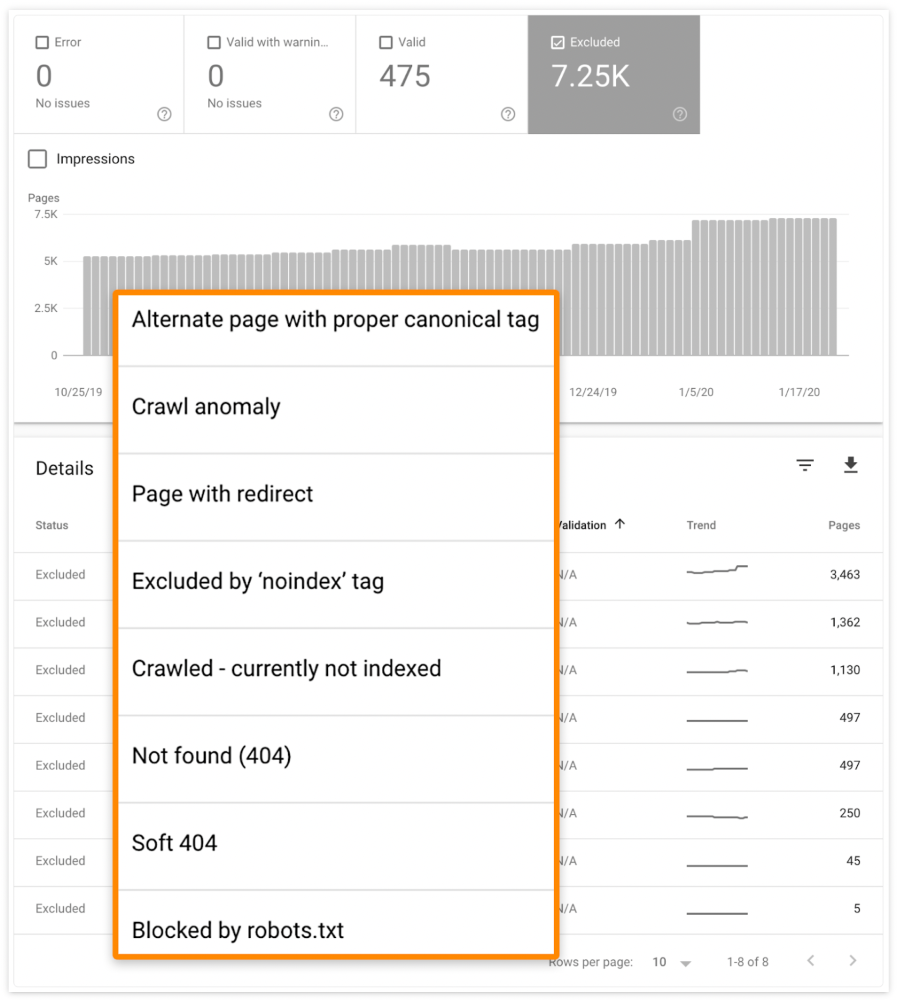
Google doesn't index broken pages, even with backlinks.
Surprisingly common.
In Ahrefs' Site Explorer, the Best by Links report for a popular content marketing blog shows many broken pages.
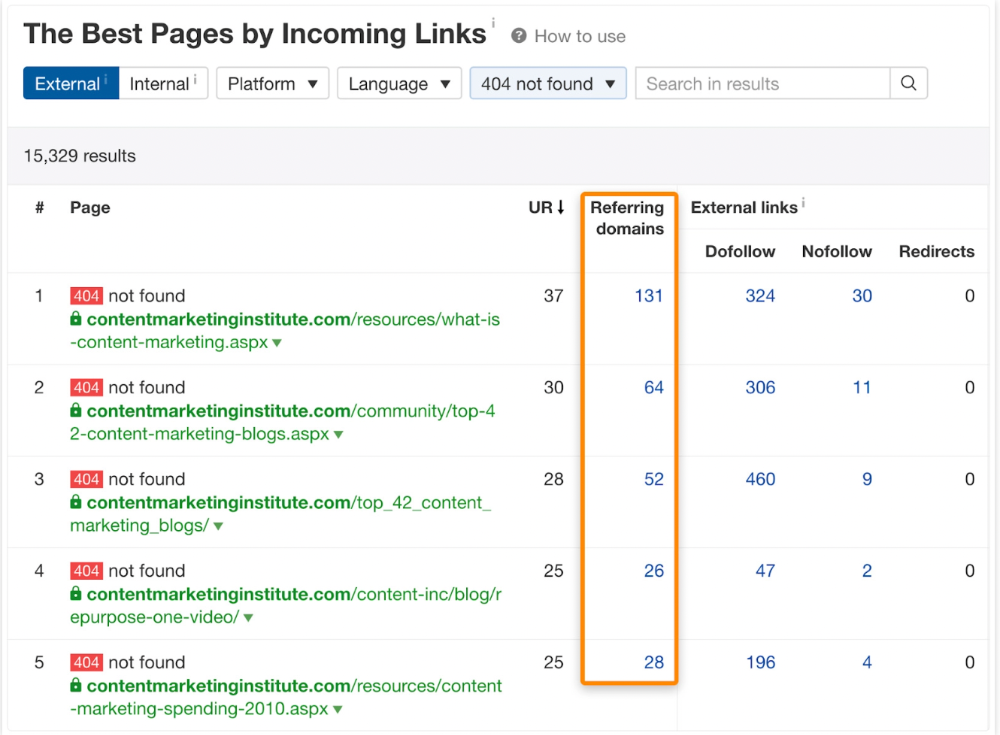
One dead page has 131 backlinks:
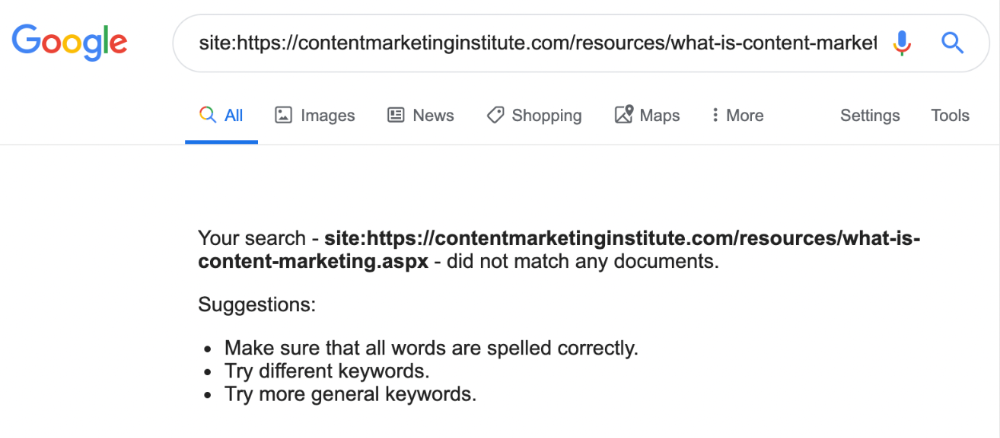
According to the URL, the page defined content marketing. —a keyword with a monthly search volume of 5,900 in the US.
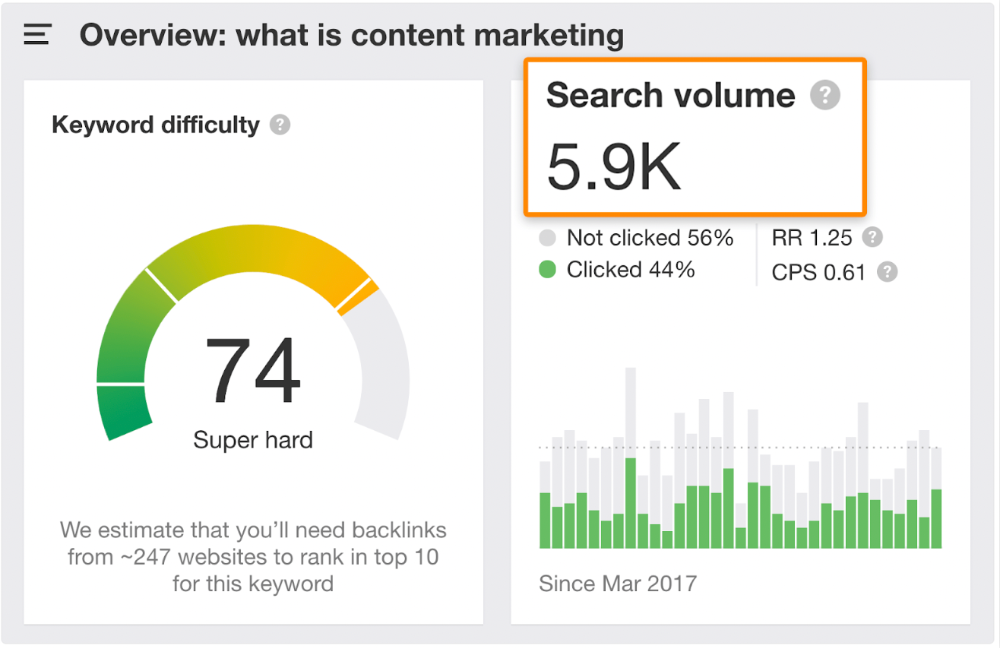
Luckily, another page ranks for this keyword. Not a huge loss.
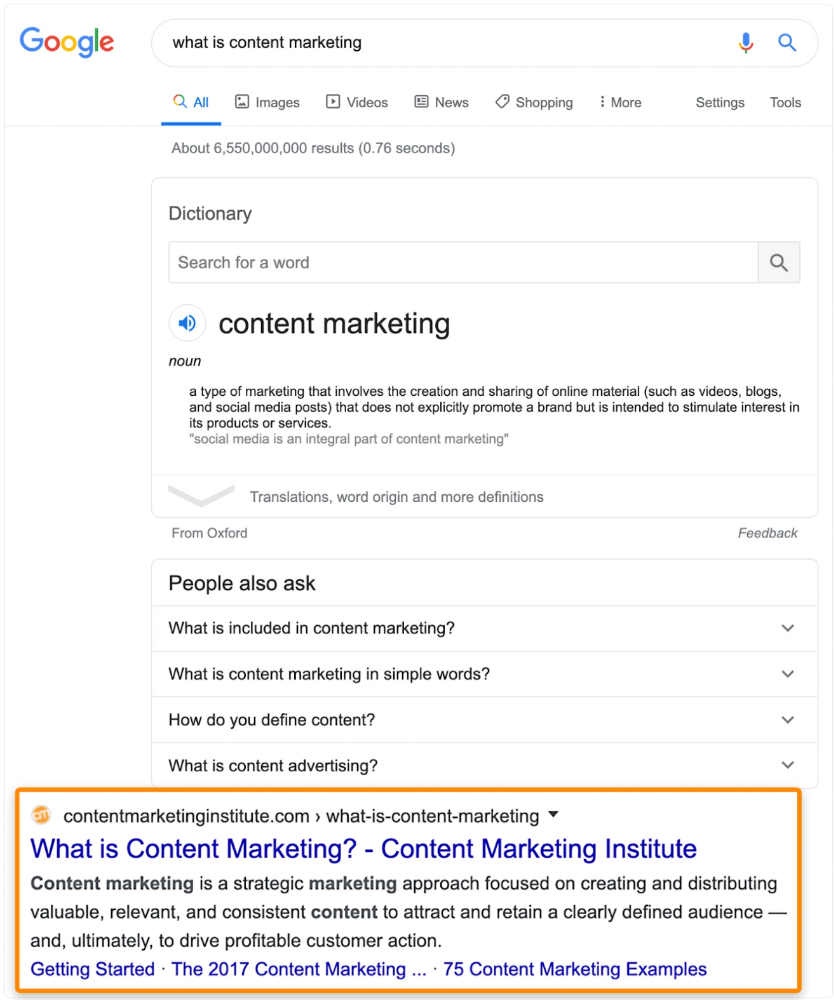
At least redirect the dead page's backlinks to a working page on the same topic. This may increase long-tail keyword traffic.
This post is a summary. See the original post here
You might also like

Jano le Roux
3 years ago
My Top 11 Tools For Building A Modern Startup, With A Free Plan
The best free tools are probably unknown to you.
Modern startups are easy to build.
Start with free tools.
Let’s go.
Web development — Webflow
Code-free HTML, CSS, and JS.
Webflow isn't like Squarespace, Wix, or Shopify.
It's a super-fast no-code tool for professionals to construct complex, highly-responsive websites and landing pages.
Webflow can help you add animations like those on Apple's website to your own site.
I made the jump from WordPress a few years ago and it changed my life.
No damn plugins. No damn errors. No damn updates.
The best, you can get started on Webflow for free.
Data tracking — Airtable
Spreadsheet wings.
Airtable combines spreadsheet flexibility with database power without code.
Airtable is modern.
Airtable has modularity.
Scaling Airtable is simple.
Airtable, one of the most adaptable solutions on this list, is perfect for client data management.
Clients choose customized service packages. Airtable consolidates data so you can automate procedures like invoice management and focus on your strengths.
Airtable connects with so many tools that rarely creates headaches. Airtable scales when you do.
Airtable's flexibility makes it a potential backend database.
Design — Figma
Better, faster, easier user interface design.
Figma rocks!
It’s fast.
It's free.
It's adaptable
First, design in Figma.
Iterate.
Export development assets.
Figma lets you add more team members as your company grows to work on each iteration simultaneously.
Figma is web-based, so you don't need a powerful PC or Mac to start.
Task management — Trello
Unclock jobs.
Tacky and terrifying task management products abound. Trello isn’t.
Those that follow Marie Kondo will appreciate Trello.
Everything is clean.
Nothing is complicated.
Everything has a place.
Compared to other task management solutions, Trello is limited. And that’s good. Too many buttons lead to too many decisions lead to too many hours wasted.
Trello is a must for teamwork.
Domain email — Zoho
Free domain email hosting.
Professional email is essential for startups. People relied on monthly payments for too long. Nope.
Zoho offers 5 free professional emails.
It doesn't have Google's UI, but it works.
VPN — Proton VPN
Fast Swiss VPN protects your data and privacy.
Proton VPN is secure.
Proton doesn't record any data.
Proton is based in Switzerland.
Swiss privacy regulation is among the most strict in the world, therefore user data are protected. Switzerland isn't a 14 eye country.
Journalists and activists trust Proton to secure their identities while accessing and sharing information authoritarian governments don't want them to access.
Web host — Netlify
Free fast web hosting.
Netlify is a scalable platform that combines your favorite tools and APIs to develop high-performance sites, stores, and apps through GitHub.
Serverless functions and environment variables preserve API keys.
Netlify's free tier is unmissable.
100GB of free monthly bandwidth.
Free 125k serverless operations per website each month.
Database — MongoDB
Create a fast, scalable database.
MongoDB is for small and large databases. It's a fast and inexpensive database.
Free for the first million reads.
Then, for each million reads, you must pay $0.10.
MongoDB's free plan has:
Encryption from end to end
Continual authentication
field-level client-side encryption
If you have a large database, you can easily connect MongoDB to Webflow to bypass CMS limits.
Automation — Zapier
Time-saving tip: automate repetitive chores.
Zapier simplifies life.
Zapier syncs and connects your favorite apps to do impossibly awesome things.
If your online store is connected to Zapier, a customer's purchase can trigger a number of automated actions, such as:
The customer is being added to an email chain.
Put the information in your Airtable.
Send a pre-programmed postcard to the customer.
Alexa, set the color of your smart lights to purple.
Zapier scales when you do.
Email & SMS marketing — Omnisend
Email and SMS marketing campaigns.
This is an excellent Mailchimp option for magical emails. Omnisend's processes simplify email automation.
I love the interface's cleanliness.
Omnisend's free tier includes web push notifications.
Send up to:
500 emails per month
60 maximum SMSs
500 Web Push Maximum
Forms and surveys — Tally
Create flexible forms that people enjoy.
Typeform is clean but restricting. Sometimes you need to add many questions. Tally's needed sometimes.
Tally is flexible and cheaper than Typeform.
99% of Tally's features are free and unrestricted, including:
Unlimited forms
Countless submissions
Collect payments
File upload
Tally lets you examine what individuals contributed to forms before submitting them to see where they get stuck.
Airtable and Zapier connectors automate things further. If you pay, you can apply custom CSS to fit your brand.
See.
Free tools are the greatest.
Let's use them to launch a startup.

Henrique Centieiro
3 years ago
DAO 101: Everything you need to know
Maybe you'll work for a DAO next! Over $1 Billion in NFTs in the Flamingo DAO Another DAO tried to buy the NFL team Denver Broncos. The UkraineDAO raised over $7 Million for Ukraine. The PleasrDAO paid $4m for a Wu-Tang Clan album that belonged to the “pharma bro.”
DAOs move billions and employ thousands. So learn what a DAO is, how it works, and how to create one!
DAO? So, what? Why is it better?
A Decentralized Autonomous Organization (DAO). Some people like to also refer to it as Digital Autonomous Organization, but I prefer the former.
They are virtual organizations. In the real world, you have organizations or companies right? These firms have shareholders and a board. Usually, anyone with authority makes decisions. It could be the CEO, the Board, or the HIPPO. If you own stock in that company, you may also be able to influence decisions. It's now possible to do something similar but much better and more equitable in the cryptocurrency world.
This article informs you:
DAOs- What are the most common DAOs, their advantages and disadvantages over traditional companies? What are they if any?
Is a DAO legally recognized?
How secure is a DAO?
I’m ready whenever you are!
A DAO is a type of company that is operated by smart contracts on the blockchain. Smart contracts are computer code that self-executes our commands. Those contracts can be any. Most second-generation blockchains support smart contracts. Examples are Ethereum, Solana, Polygon, Binance Smart Chain, EOS, etc. I think I've gone off topic. Back on track. Now let's go!
Unlike traditional corporations, DAOs are governed by smart contracts. Unlike traditional company governance, DAO governance is fully transparent and auditable. That's one of the things that sets it apart. The clarity!
A DAO, like a traditional company, has one major difference. In other words, it is decentralized. DAOs are more ‘democratic' than traditional companies because anyone can vote on decisions. Anyone! In a DAO, we (you and I) make the decisions, not the top-shots. We are the CEO and investors. A DAO gives its community members power. We get to decide.
As long as you are a stakeholder, i.e. own a portion of the DAO tokens, you can participate in the DAO. Tokens are open to all. It's just a matter of exchanging it. Ownership of DAO tokens entitles you to exclusive benefits such as governance, voting, and so on. You can vote for a move, a plan, or the DAO's next investment. You can even pitch for funding. Any ‘big' decision in a DAO requires a vote from all stakeholders. In this case, ‘token-holders'! In other words, they function like stock.
What are the 5 DAO types?
Different DAOs exist. We will categorize decentralized autonomous organizations based on their mode of operation, structure, and even technology. Here are a few. You've probably heard of them:
1. DeFi DAO
These DAOs offer DeFi (decentralized financial) services via smart contract protocols. They use tokens to vote protocol and financial changes. Uniswap, Aave, Maker DAO, and Olympus DAO are some examples. Most DAOs manage billions.
Maker DAO was one of the first protocols ever created. It is a decentralized organization on the Ethereum blockchain that allows cryptocurrency lending and borrowing without a middleman.
Maker DAO issues DAI, a stable coin. DAI is a top-rated USD-pegged stable coin.
Maker DAO has an MKR token. These token holders are in charge of adjusting the Dai stable coin policy. Simply put, MKR tokens represent DAO “shares”.
2. Investment DAO
Investors pool their funds and make investment decisions. Investing in new businesses or art is one example. Investment DAOs help DeFi operations pool capital. The Meta Cartel DAO is a community of people who want to invest in new projects built on the Ethereum blockchain. Instead of investing one by one, they want to pool their resources and share ideas on how to make better financial decisions.
Other investment DAOs include the LAO and Friends with Benefits.
3. DAO Grant/Launchpad
In a grant DAO, community members contribute funds to a grant pool and vote on how to allocate and distribute them. These DAOs fund new DeFi projects. Those in need only need to apply. The Moloch DAO is a great Grant DAO. The tokens are used to allocate capital. Also see Gitcoin and Seedify.
4. DAO Collector
I debated whether to put it under ‘Investment DAO' or leave it alone. It's a subset of investment DAOs. This group buys non-fungible tokens, artwork, and collectibles. The market for NFTs has recently exploded, and it's time to investigate. The Pleasr DAO is a collector DAO. One copy of Wu-Tang Clan's "Once Upon a Time in Shaolin" cost the Pleasr DAO $4 million. Pleasr DAO is known for buying Doge meme NFT. Collector DAOs include the Flamingo, Mutant Cats DAO, and Constitution DAOs. Don't underestimate their websites' "childish" style. They have millions.
5. Social DAO
These are social networking and interaction platforms. For example, Decentraland DAO and Friends With Benefits DAO.
What are the DAO Benefits?
Here are some of the benefits of a decentralized autonomous organization:
- They are trustless. You don’t need to trust a CEO or management team
- It can’t be shut down unless a majority of the token holders agree. The government can't shut - It down because it isn't centralized.
- It's fully democratic
- It is open-source and fully transparent.
What about DAO drawbacks?
We've been saying DAOs are the bomb? But are they really the shit? What could go wrong with DAO?
DAOs may contain bugs. If they are hacked, the results can be catastrophic.
No trade secrets exist. Because the smart contract is transparent and coded on the blockchain, it can be copied. It may be used by another organization without credit. Maybe DAOs should use Secret, Oasis, or Horizen blockchain networks.
Are DAOs legally recognized??
In most counties, DAO regulation is inexistent. It's unclear. Most DAOs don’t have a legal personality. The Howey Test and the Securities Act of 1933 determine whether DAO tokens are securities. Although most countries follow the US, this is only considered for the US. Wyoming became the first state to recognize DAOs as legal entities in July 2021 after passing a DAO bill. DAOs registered in Wyoming are thus legally recognized as business entities in the US and thus receive the same legal protections as a Limited Liability Company.
In terms of cyber-security, how secure is a DAO?
Blockchains are secure. However, smart contracts may have security flaws or bugs. This can be avoided by third-party smart contract reviews, testing, and auditing
Finally, Decentralized Autonomous Organizations are timeless. Let us examine the current situation: Ukraine's invasion. A DAO was formed to help Ukrainian troops fighting the Russians. It was named Ukraine DAO. Pleasr DAO, NFT studio Trippy Labs, and Russian art collective Pussy Riot organized this fundraiser. Coindesk reports that over $3 million has been raised in Ethereum-based tokens. AidForUkraine, a DAO aimed at supporting Ukraine's defense efforts, has launched. Accepting Solana token donations. They are fully transparent, uncensorable, and can’t be shut down or sanctioned.
DAOs are undeniably the future of blockchain. Everyone is paying attention. Personally, I believe traditional companies will soon have to choose between adapting or being left behind.
Long version of this post: https://medium.datadriveninvestor.com/dao-101-all-you-need-to-know-about-daos-275060016663

TheRedKnight
3 years ago
Say goodbye to Ponzi yields - A new era of decentralized perpetual
Decentralized perpetual may be the next crypto market boom; with tons of perpetual popping up, let's look at two protocols that offer organic, non-inflationary yields.
Decentralized derivatives exchanges' market share has increased tenfold in a year, but it's still 2% of CEXs'. DEXs have a long way to go before they can compete with centralized exchanges in speed, liquidity, user experience, and composability.
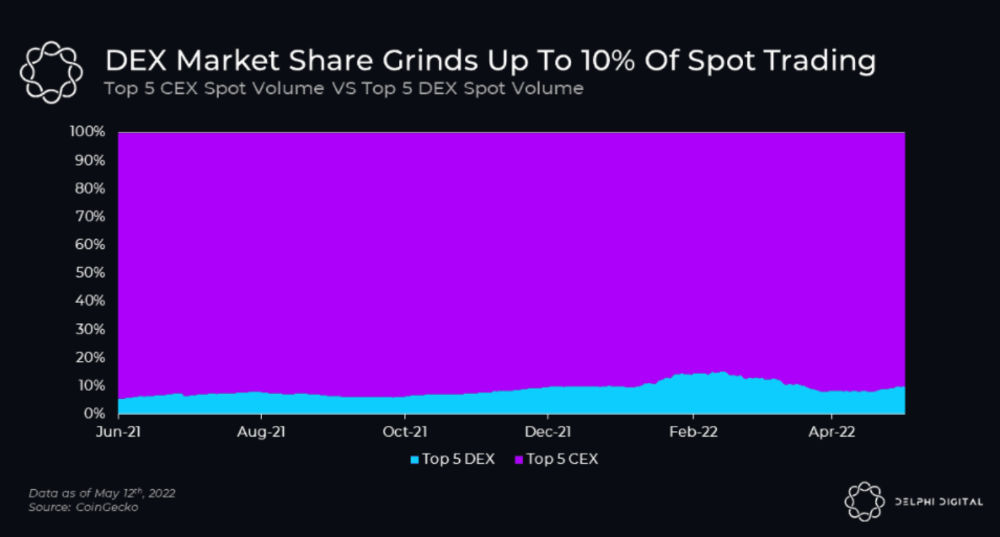
I'll cover gains.trade and GMX protocol in Polygon, Avalanche, and Arbitrum. Both protocols support leveraged perpetual crypto, stock, and Forex trading.
Why these protocols?
Decentralized GMX Gains protocol
Organic yield: path to sustainability
I've never trusted Defi's non-organic yields. Example: XYZ protocol. 20–75% of tokens may be set aside as farming rewards to provide liquidity, according to tokenomics.
Say you provide ETH-USDC liquidity. They advertise a 50% APR reward for this pair, 10% from trading fees and 40% from farming rewards. Only 10% is real, the rest is "Ponzi." The "real" reward is in protocol tokens.
Why keep this token? Governance voting or staking rewards are promoted services.
Most liquidity providers expect compensation for unused tokens. Basic psychological principles then? — Profit.
Nobody wants governance tokens. How many out of 100 care about the protocol's direction and will vote?
Staking increases your token's value. Currently, they're mostly non-liquid. If the protocol is compromised, you can't withdraw funds. Most people are sceptical of staking because of this.
"Free tokens," lack of use cases, and skepticism lead to tokens moving south. No farming reward protocols have lasted.
It may have shown strength in a bull market, but what about a bear market?
What is decentralized perpetual?
A perpetual contract is a type of futures contract that doesn't expire. So one can hold a position forever.
You can buy/sell any leveraged instruments (Long-Short) without expiration.
In centralized exchanges like Binance and coinbase, fees and revenue (liquidation) go to the exchanges, not users.
Users can provide liquidity that traders can use to leverage trade, and the revenue goes to liquidity providers.
Gains.trade and GMX protocol are perpetual trading platforms with a non-inflationary organic yield for liquidity providers.
GMX protocol
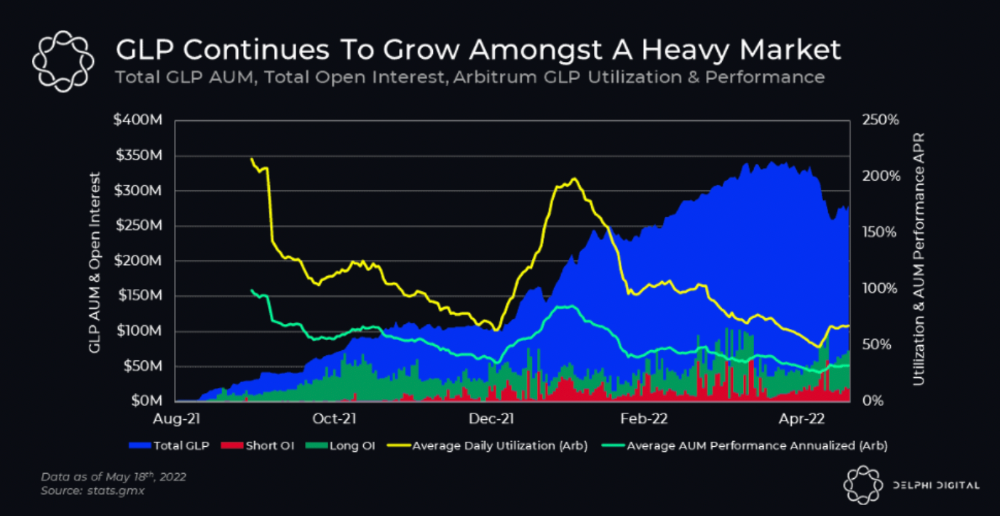
GMX is an Arbitrum and Avax protocol that rewards in ETH and Avax. GLP uses a fast oracle to borrow the "true price" from other trading venues, unlike a traditional AMM.
GLP and GMX are protocol tokens. GLP is used for leveraged trading, swapping, etc.
GLP is a basket of tokens, including ETH, BTC, AVAX, stablecoins, and UNI, LINK, and Stablecoins.
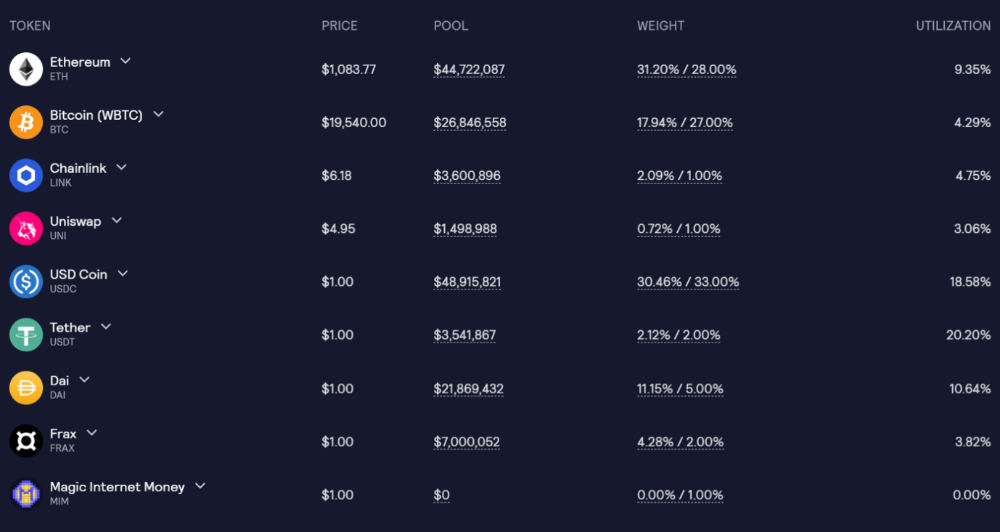
GLP composition on arbitrum
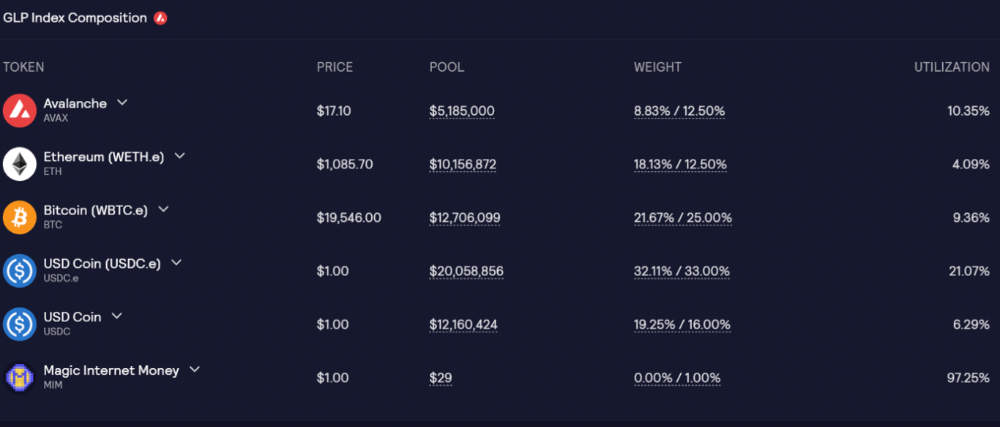
GLP composition on Avalanche
GLP token rebalances based on usage, providing liquidity without loss.
Protocol "runs" on Staking GLP. Depending on their chain, the protocol will reward users with ETH or AVAX. Current rewards are 22 percent (15.71 percent in ETH and the rest in escrowed GMX) and 21 percent (15.72 percent in AVAX and the rest in escrowed GMX). escGMX and ETH/AVAX percentages fluctuate.
Where is the yield coming from?
Swap fees, perpetual interest, and liquidations generate yield. 70% of fees go to GLP stakers, 30% to GMX. Organic yields aren't paid in inflationary farm tokens.
Escrowed GMX is vested GMX that unlocks in 365 days. To fully unlock GMX, you must farm the Escrowed GMX token for 365 days. That means less selling pressure for the GMX token.
GMX's status
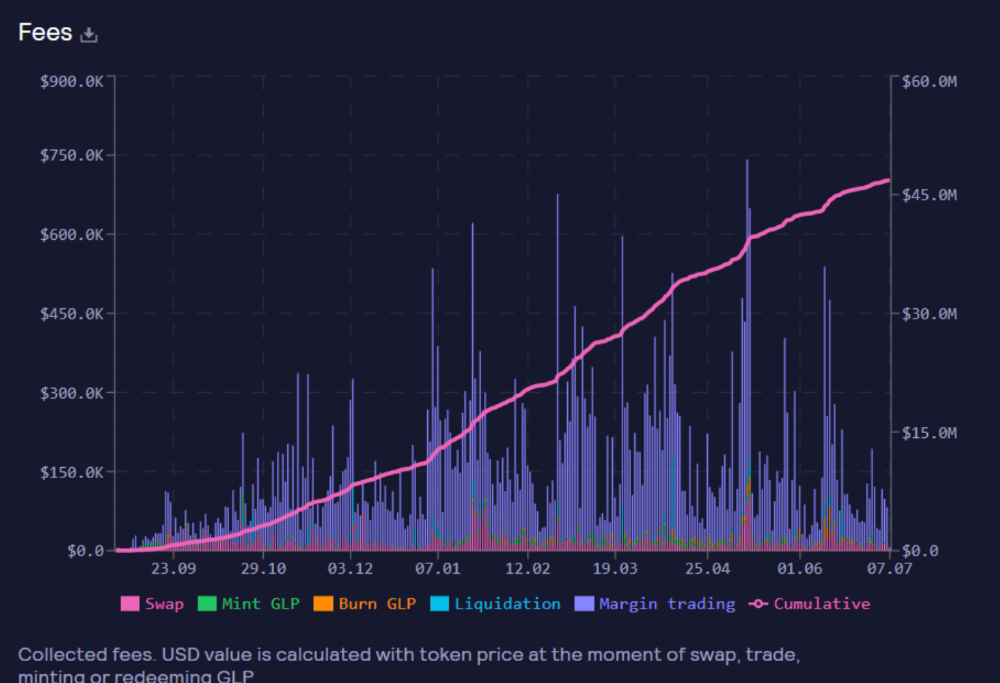
These are the fees in Arbitrum in the past 11 months by GMX.
GMX works like a casino, which increases fees. Most fees come from Margin trading, which means most traders lose money; this money goes to the casino, or GLP stakers.
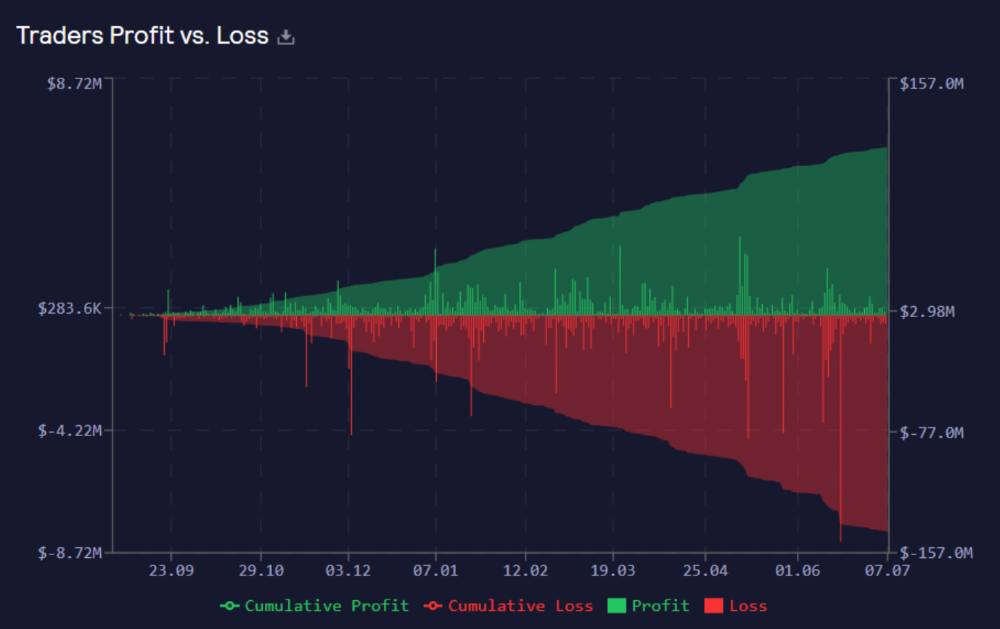
Strategies
My personal strategy is to DCA into GLP when markets hit bottom and stake it; GLP will be less volatile with extra staking rewards.
GLP YoY return vs. naked buying
Let's say I invested $10,000 in BTC, AVAX, and ETH in January.
BTC price: 47665$
ETH price: 3760$
AVAX price: $145
Current prices
BTC $21,000 (Down 56 percent )
ETH $1233 (Down 67.2 percent )
AVAX $20.36 (Down 85.95 percent )
Your $10,000 investment is now worth around $3,000.
How about GLP? My initial investment is 50% stables and 50% other assets ( Assuming the coverage ratio for stables is 50 percent at that time)
Without GLP staking yield, your value is $6500.
Let's assume the average APR for GLP staking is 23%, or $1500. So 8000$ total. It's 50% safer than holding naked assets in a bear market.
In a bull market, naked assets are preferable to GLP.
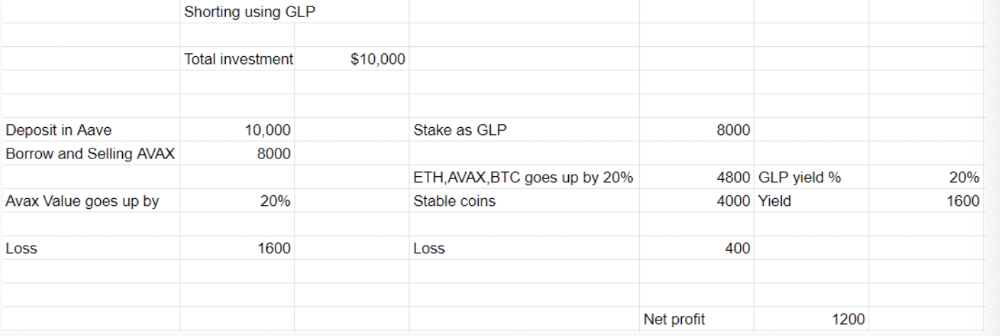
Short farming using GLP
Simple GLP short farming.
You use a stable asset as collateral to borrow AVAX. Sell it and buy GLP. Even if GLP rises, it won't rise as fast as AVAX, so we can get yields.
Let's do the maths
You deposit $10,000 USDT in Aave and borrow Avax. Say you borrow $8,000; you sell it, buy GLP, and risk 20%.
After a year, ETH, AVAX, and BTC rise 20%. GLP is $8800. $800 vanishes. 20% yields $1600. You're profitable. Shorting Avax costs $1600. (Assumptions-ETH, AVAX, BTC move the same, GLP yield is 20%. GLP has a 50:50 stablecoin/others ratio. Aave won't liquidate
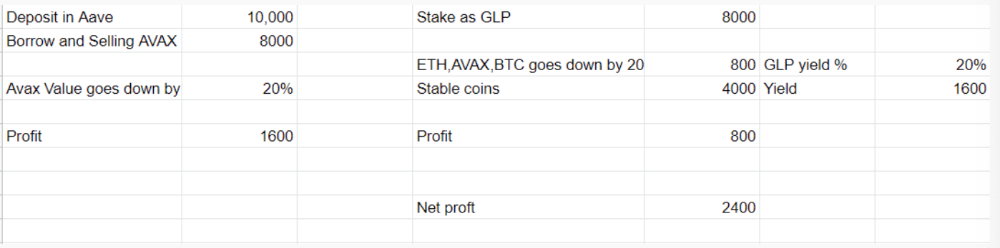
In naked Avax shorting, Avax falls 20% in a year. You'll make $1600. If you buy GLP and stake it using the sold Avax and BTC, ETH and Avax go down by 20% - your profit is 20%, but with the yield, your total gain is $2400.
Issues with GMX
GMX's historical funding rates are always net positive, so long always pays short. This makes long-term shorts less appealing.
Oracle price discovery isn't enough. This limitation doesn't affect Bitcoin and ETH, but it affects less liquid assets. Traders can buy and sell less liquid assets at a lower price than their actual cost as long as GMX exists.
As users must provide GLP liquidity, adding more assets to GMX will be difficult. Next iteration will have synthetic assets.
Gains Protocol
Best leveraged trading platform. Smart contract-based decentralized protocol. 46 crypto pairs can be leveraged 5–150x and 10 Forex pairs 5–1000x. $10 DAI @ 150x (min collateral x leverage pos size is $1500 DAI). No funding fees, no KYC, trade DAI from your wallet, keep funds.
DAI single-sided staking and the GNS-DAI pool are important parts of Gains trading. GNS-DAI stakers get 90% of trading fees and 100% swap fees. 10 percent of trading fees go to DAI stakers, which is currently 14 percent!
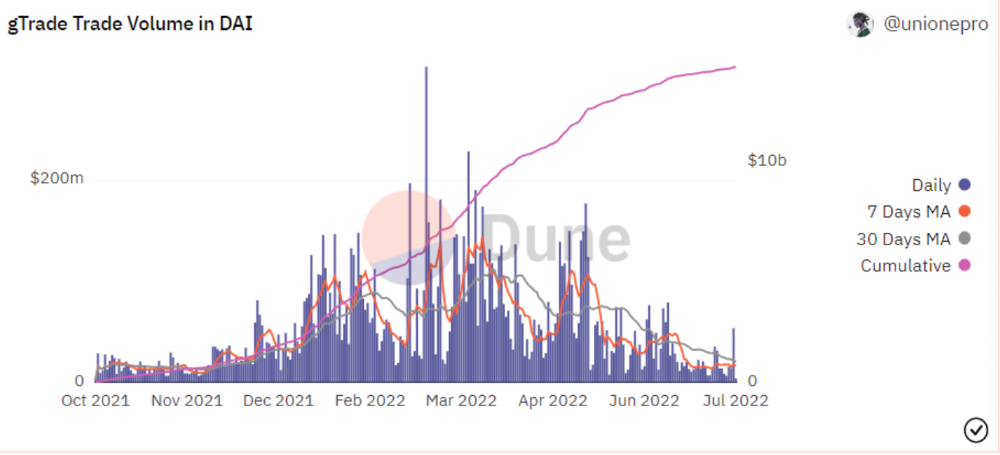
Trade volume
When a trader opens a trade, the leverage and profit are pulled from the DAI pool. If he loses, the protocol yield goes to the stakers.
If the trader's win rate is high and the DAI pool slowly depletes, the GNS token is minted and sold to refill DAI. Trader losses are used to burn GNS tokens. 25%+ of GNS is burned, making it deflationary.
Due to high leverage and volatility of crypto assets, most traders lose money and the protocol always wins, keeping GNS deflationary.
Gains uses a unique decentralized oracle for price feeds, which is better for leverage trading platforms. Let me explain.
Gains uses chainlink price oracles, not its own price feeds. Chainlink oracles only query centralized exchanges for price feeds every minute, which is unsuitable for high-precision trading.
Gains created a custom oracle that queries the eight chainlink nodes for the current price and, on average, for trade confirmation. This model eliminates every-second inquiries, which waste gas but are more efficient than chainlink's per-minute price.
This price oracle helps Gains open and close trades instantly, eliminate scam wicks, etc.
Other benefits include:
Stop-loss guarantee (open positions updated)
No scam wicks
Spot-pricing
Highest possible leverage
Fixed-spreads. During high volatility, a broker can increase the spread, which can hit your stop loss without the price moving.
Trade directly from your wallet and keep your funds.
>90% loss before liquidation (Some platforms liquidate as little as -50 percent)
KYC-free
Directly trade from wallet; keep funds safe
Further improvements
GNS-DAI liquidity providers fear the impermanent loss, so the protocol is migrating to its own liquidity and single staking GNS vaults. This allows users to stake GNS without permanent loss and obtain 90% DAI trading fees by staking. This starts in August.
Their upcoming improvements can be found here.
Gains constantly add new features and change pairs. It's an interesting protocol.
Conclusion
Next bull run, watch decentralized perpetual protocols. Effective tokenomics and non-inflationary yields may attract traders and liquidity providers. But still, there is a long way for them to develop, and I don't see them tackling the centralized exchanges any time soon until they fix their inherent problems and improve fast enough.
Read the full post here.