


Moonbirds NFT sells for $1 million in first week
On Saturday, Moonbird #2642, one of the collection's rarest NFTs, sold for a record 350 ETH (over $1 million) on OpenSea.
The Sandbox, a blockchain-based gaming company based in Hong Kong, bought the piece. The seller, "oscuranft" on OpenSea, made around $600,000 after buying the NFT for 100 ETH a week ago.
Owl avatars
Moonbirds is a 10,000 owl NFT collection. It is one of the quickest collections to achieve bluechip status. Proof, a media startup founded by renowned VC Kevin Rose, launched Moonbirds on April 16.
Rose is currently a partner at True Ventures, a technology-focused VC firm. He was a Google Ventures general partner and has 1.5 million Twitter followers.
Rose has an NFT podcast on Proof. It follows Proof Collective, a group of 1,000 NFT collectors and artists, including Beeple, who hold a Proof Collective NFT and receive special benefits.
These include early access to the Proof podcast and in-person events.
According to the Moonbirds website, they are "the official Proof PFP" (picture for proof).
Moonbirds NFTs sold nearly $360 million in just over a week, according to The Block Research and Dune Analytics. Its top ten sales range from $397,000 to $1 million.
In the current market, Moonbirds are worth 33.3 ETH. Each NFT is 2.5 ETH. Holders have gained over 12 times in just over a week.
Why was it so popular?
The Block Research's NFT analyst, Thomas Bialek, attributes Moonbirds' rapid rise to Rose's backing, the success of his previous Proof Collective project, and collectors' preference for proven NFT projects.
Proof Collective NFT holders have made huge gains. These NFTs were sold in a Dutch auction last December for 5 ETH each. According to OpenSea, the current floor price is 109 ETH.
According to The Block Research, citing Dune Analytics, Proof Collective NFTs have sold over $39 million to date.
Rose has bigger plans for Moonbirds. Moonbirds is introducing "nesting," a non-custodial way for holders to stake NFTs and earn rewards.
Holders of NFTs can earn different levels of status based on how long they keep their NFTs locked up.
"As you achieve different nest status levels, we can offer you different benefits," he said. "We'll have in-person meetups and events, as well as some crazy airdrops planned."
Rose went on to say that Proof is just the start of "a multi-decade journey to build a new media company."
More on NFTs & Art

Adrien Book
3 years ago
What is Vitalik Buterin's newest concept, the Soulbound NFT?
Decentralizing Web3's soul
Our tech must reflect our non-transactional connections. Web3 arose from a lack of social links. It must strengthen these linkages to get widespread adoption. Soulbound NFTs help.
This NFT creates digital proofs of our social ties. It embodies G. Simmel's idea of identity, in which individuality emerges from social groups, just as social groups evolve from people.
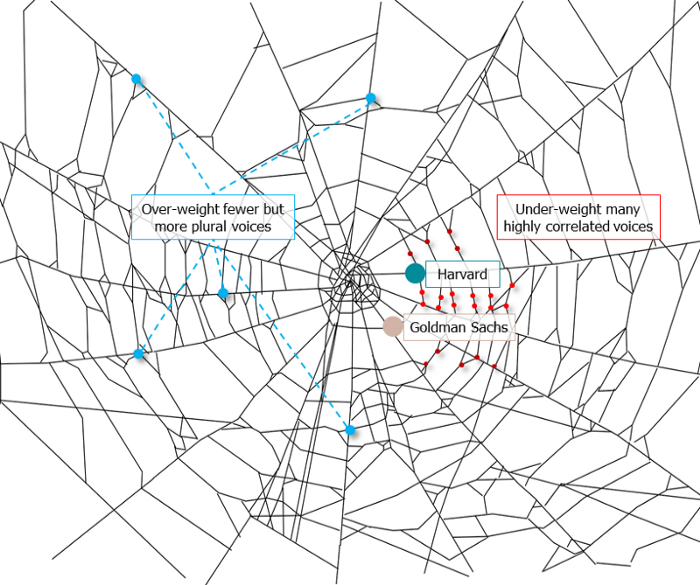
It's multipurpose. First, gather online our distinctive social features. Second, highlight and categorize social relationships between entities and people to create a spiderweb of networks.
1. 🌐 Reducing online manipulation: Only socially rich or respectable crypto wallets can participate in projects, ensuring that no one can create several wallets to influence decentralized project governance.
2. 🤝 Improving social links: Some sectors of society lack social context. Racism, sexism, and homophobia do that. Public wallets can help identify and connect distinct social groupings.
3. 👩❤️💋👨 Increasing pluralism: Soulbound tokens can ensure that socially connected wallets have less voting power online to increase pluralism. We can also overweight a minority of numerous voices.
4. 💰Making more informed decisions: Taking out an insurance policy requires a life review. Why not loans? Character isn't limited by income, and many people need a chance.
5. 🎶 Finding a community: Soulbound tokens are accessible to everyone. This means we can find people who are like us but also different. This is probably rare among your friends and family.
NFTs are dangerous, and I don't like them. Social credit score, privacy, lost wallet. We must stay informed and keep talking to innovators.
E. Glen Weyl, Puja Ohlhaver and Vitalik Buterin get all the credit for these ideas, having written the very accessible white paper “Decentralized Society: Finding Web3’s Soul”.

Tora Northman
3 years ago
Pixelmon NFTs are so bad, they are almost good!
Bored Apes prices continue to rise, HAPEBEAST launches, Invisible Friends hype continues to grow. Sadly, not all projects are as successful.
Of course, there are many factors to consider when buying an NFT. Is the project a scam? Will the reveal derail the project? Possibly, but when Pixelmon first teased its launch, it generated a lot of buzz.
With a primary sale mint price of 3 ETH ($8,100 USD), it started as an expensive project, with plenty of fans willing to invest in what was sold as a game. After it was revealed, it fell rapidly.
Why? It was overpromised and under delivered.
According to the project's creator[^1], the funds generated will be used to develop the artwork. "The Pixelmon reveal was wrong. This is what our Pixelmon look like in-game. "Despite the fud, I will not go anywhere," he wrote on Twitter. The goal remains. The funds will still be used to build our game. I will finish this project."
The project raised $70 million USD, but the NFTs buyers received were not the project's original teasers. Some call it "the worst NFT project ever," while others call it a complete scam.
But there's hope for some buyers. Kevin emerged from the ashes as the project was roasted over the fire.
A Minecraft character meets Salad Fingers - that's Kevin. He's a frog-like creature whose reveal was such a terrible NFT that it became part of history – and a meme.
If you're laughing at people paying $8K for a silly pixelated image, you might need to take it back. Precisely because of this, lucky holders who minted Kevin have been able to sell the now-memed NFT for over 8 ETH (around $24,000 USD), with some currently listed for 100 ETH.
Of course, Twitter has been awash in memes mocking those who invested in the project, because what else can you do when so many people lose money?
It's still unclear if the NFT project is a scam, but the team behind it was hired on Upwork. There's still hope for redemption, but Kevin's rise to fame appears to be the only positive outcome so far.
[^1] This is not the first time the creator (A 20-yo New Zealanders) has sought money via an online platform and had people claiming he under-delivered. He raised $74,000 on Kickstarter for a card game called Psycho Chicken. There are hundreds of comments on the Kickstarter project saying they haven't received the product and pleading for a refund or an update.

Jennifer Tieu
3 years ago
Why I Love Azuki
Azuki Banner (www.azuki.com)
Disclaimer: This is my personal viewpoint. I'm not on the Azuki team. Please keep in mind that I am merely a fan, community member, and holder. Please do your own research and pardon my grammar. Thanks!
Azuki has changed my view of NFTs.
When I first entered the NFT world, I had no idea what to expect. I liked the idea. So I invested in some projects, fought for whitelists, and discovered some cool NFTs projects (shout-out to CATC). I lost more money than I earned at one point, but I hadn't invested excessively (only put in what you can afford to lose). Despite my losses, I kept looking. I almost waited for the “ah-ha” moment. A NFT project that changed my perspective on NFTs. What makes an NFT project more than a work of art?
Answer: Azuki.
The Art
The Azuki art drew me in as an anime fan. It looked like something out of an anime, and I'd never seen it before in NFT.
The project was still new. The first two animated teasers were released with little fanfare, but I was impressed with their quality. You can find them on Instagram or in their earlier Tweets.
The teasers hinted that this project could be big and that the team could deliver. It was amazing to see Shao cut the Azuki posters with her katana. Especially at the end when she sheaths her sword and the music cues. Then the live action video of the young boy arranging the Azuki posters seemed movie-like. I felt like I was entering the Azuki story, brand, and dope theme.
The team did not disappoint with the Azuki NFTs. The level of detail in the art is stunning. There were Azukis of all genders, skin and hair types, and more. These 10,000 Azukis have so much representation that almost anyone can find something that resonates. Rather than me rambling on, I suggest you visit the Azuki gallery
The Team
If the art is meant to draw you in and be the project's face, the team makes it more. The NFT would be a JPEG without a good team leader. Not that community isn't important, but no community would rally around a bad team.
Because I've been rugged before, I'm very focused on the team when considering a project. While many project teams are anonymous, I try to find ones that are doxxed (public) or at least appear to be established. Unlike Azuki, where most of the Azuki team is anonymous, Steamboy is public. He is (or was) Overwatch's character art director and co-creator of Azuki. I felt reassured and could trust the project after seeing someone from a major game series on the team.
Then I tried to learn as much as I could about the team. Following everyone on Twitter, reading their tweets, and listening to recorded AMAs. I was impressed by the team's professionalism and dedication to their vision for Azuki, led by ZZZAGABOND.
I believe the phrase “actions speak louder than words” applies to Azuki. I can think of a few examples of what the Azuki team has done, but my favorite is ERC721A.
With ERC721A, Azuki has created a new algorithm that allows minting multiple NFTs for essentially the same cost as minting one NFT.
I was ecstatic when the dev team announced it. This fascinates me as a self-taught developer. Azuki released a product that saves people money, improves the NFT space, and is open source. It showed their love for Azuki and the NFT community.
The Community
Community, community, community. It's almost a chant in the NFT space now. A community, like a team, can make or break a project. We are the project's consumers, shareholders, core, and lifeblood. The team builds the house, and we fill it. We stay for the community.
When I first entered the Azuki Discord, I was surprised by the calm atmosphere. There was no news about the project. No release date, no whitelisting requirements. No grinding or spamming either. People just wanted to hangout, get to know each other, and talk. It was nice. So the team could pick genuine people for their mintlist (aka whitelist).
But nothing fundamental has changed since the release. It has remained an authentic, fun, and helpful community. I'm constantly logging into Discord to chat with others or follow conversations. I see the community's openness to newcomers. Everyone respects each other (barring a few bad apples) and the variety of people passing through is fascinating. This human connection and interaction is what I enjoy about this place. Being a part of a group that supports a cause.
Finally, I want to thank the amazing Azuki mod team and the kissaten channel for their contributions.
The Brand
So, what sets Azuki apart from other projects? They are shaping a brand or identity. The Azuki website, I believe, best captures their vision. (This is me gushing over the site.)
If you go to the website, turn on the dope playlist in the bottom left. The playlist features a mix of Asian and non-Asian hip-hop and rap artists, with some lo-fi thrown in. The songs on the playlist change, but I think you get the vibe Azuki embodies just by turning on the music.
The Garden is our next stop where we are introduced to Azuki.
A brand.
We're creating a new brand together.
A metaverse brand. By the people.
A collection of 10,000 avatars that grant Garden membership. It starts with exclusive streetwear collabs, NFT drops, live events, and more. Azuki allows for a new media genre that the world has yet to discover. Let's build together an Azuki, your metaverse identity.
The Garden is a magical internet corner where art, community, and culture collide. The boundaries between the physical and digital worlds are blurring.
Try a Red Bean.
The text begins with Azuki's intention in the space. It's a community-made metaverse brand. Then it goes into more detail about Azuki's plans. Initiation of a story or journey. "Would you like to take the red bean and jump down the rabbit hole with us?" I love the Matrix red pill or blue pill play they used. (Azuki in Japanese means red bean.)
Morpheus, the rebel leader, offers Neo the choice of a red or blue pill in The Matrix. “You take the blue pill... After the story, you go back to bed and believe whatever you want. Your red pill... Let me show you how deep the rabbit hole goes.” Aware that the red pill will free him from the enslaving control of the machine-generated dream world and allow him to escape into the real world, he takes it. However, living the “truth of reality” is harsher and more difficult.
It's intriguing and draws you in. Taking the red bean causes what? Where am I going? I think they did well in piqueing a newcomer's interest.
Not convinced by the Garden? Read the Manifesto. It reinforces Azuki's role.
Here comes a new wave…
And surfing here is different.
Breaking down barriers.
Building open communities.
Creating magic internet money with our friends.
To those who don’t get it, we tell them: gm.
They’ll come around eventually.
Here’s to the ones with the courage to jump down a peculiar rabbit hole.
One that pulls you away from a world that’s created by many and owned by few…
To a world that’s created by more and owned by all.
From The Garden come the human beans that sprout into your family.
We rise together.
We build together.
We grow together.
Ready to take the red bean?
Not to mention the Mindmap, it sets Azuki apart from other projects and overused Roadmaps. I like how the team recognizes that the NFT space is not linear. So many of us are still trying to figure it out. It is Azuki's vision to adapt to changing environments while maintaining their values. I admire their commitment to long-term growth.
Conclusion
To be honest, I have no idea what the future holds. Azuki is still new and could fail. But I'm a long-term Azuki fan. I don't care about quick gains. The future looks bright for Azuki. I believe in the team's output. I love being an Azuki.
Thank you! IKUZO!
Full post here
You might also like
Langston Thomas
3 years ago
A Simple Guide to NFT Blockchains
Ethereum's blockchain rules NFTs. Many consider it the one-stop shop for NFTs, and it's become the most talked-about and trafficked blockchain in existence.
Other blockchains are becoming popular in NFTs. Crypto-artists and NFT enthusiasts have sought new places to mint and trade NFTs due to Ethereum's high transaction costs and environmental impact.
When choosing a blockchain to mint on, there are several factors to consider. Size, creator costs, consumer spending habits, security, and community input are important. We've created a high-level summary of blockchains for NFTs to help clarify the fast-paced world of web3 tech.
Ethereum
Ethereum currently has the most NFTs. It's decentralized and provides financial and legal services without intermediaries. It houses popular NFT marketplaces (OpenSea), projects (CryptoPunks and the Bored Ape Yacht Club), and artists (Pak and Beeple).
It's also expensive and energy-intensive. This is because Ethereum works using a Proof-of-Work (PoW) mechanism. PoW requires computers to solve puzzles to add blocks and transactions to the blockchain. Solving these puzzles requires a lot of computer power, resulting in astronomical energy loss.
You should consider this blockchain first due to its popularity, security, decentralization, and ease of use.
Solana
Solana is a fast programmable blockchain. Its proof-of-history and proof-of-stake (PoS) consensus mechanisms eliminate complex puzzles. Reduced validation times and fees result.
PoS users stake their cryptocurrency to become a block validator. Validators get SOL. This encourages and rewards users to become stakers. PoH works with PoS to cryptographically verify time between events. Solana blockchain ensures transactions are in order and found by the correct leader (validator).
Solana's PoS and PoH mechanisms keep transaction fees and times low. Solana isn't as popular as Ethereum, so there are fewer NFT marketplaces and blockchain traders.
Tezos
Tezos is a greener blockchain. Tezos rose in 2021. Hic et Nunc was hailed as an economic alternative to Ethereum-centric marketplaces until Nov. 14, 2021.
Similar to Solana, Tezos uses a PoS consensus mechanism and only a PoS mechanism to reduce computational work. This blockchain uses two million times less energy than Ethereum. It's cheaper than Ethereum (but does cost more than Solana).
Tezos is a good place to start minting NFTs in bulk. Objkt is the largest Tezos marketplace.
Flow
Flow is a high-performance blockchain for NFTs, games, and decentralized apps (dApps). Flow is built with scalability in mind, so billions of people could interact with NFTs on the blockchain.
Flow became the NBA's blockchain partner in 2019. Flow, a product of Dapper labs (the team behind CryptoKitties), launched and hosts NBA Top Shot, making the blockchain integral to the popularity of non-fungible tokens.
Flow uses PoS to verify transactions, like Tezos. Developers are working on a model to handle 10,000 transactions per second on the blockchain. Low transaction fees.
Flow NFTs are tradeable on Blocktobay, OpenSea, Rarible, Foundation, and other platforms. NBA, NFL, UFC, and others have launched NFT marketplaces on Flow. Flow isn't as popular as Ethereum, resulting in fewer NFT marketplaces and blockchain traders.
Asset Exchange (WAX)
WAX is king of virtual collectibles. WAX is popular for digitalized versions of legacy collectibles like trading cards, figurines, memorabilia, etc.
Wax uses a PoS mechanism, but also creates carbon offset NFTs and partners with Climate Care. Like Flow, WAX transaction fees are low, and network fees are redistributed to the WAX community as an incentive to collectors.
WAX marketplaces host Topps, NASCAR, Hot Wheels, and cult classic film franchises like Godzilla, The Princess Bride, and Spiderman.
Binance Smart Chain
BSC is another good option for balancing fees and performance. High-speed transactions and low fees hurt decentralization. BSC is most centralized.
Binance Smart Chain uses Proof of Staked Authority (PoSA) to support a short block time and low fees. The 21 validators needed to run the exchange switch every 24 hours. 11 of the 21 validators are directly connected to the Binance Crypto Exchange, according to reports.
While many in the crypto and NFT ecosystems dislike centralization, the BSC NFT market picked up speed in 2021. OpenBiSea, AirNFTs, JuggerWorld, and others are gaining popularity despite not having as robust an ecosystem as Ethereum.

Jon Brosio
3 years ago
Every time I use this 6-part email sequence, I almost always make four figures.
(And you can have it for free)

Master email to sell anything.
Most novice creators don't know how to begin.
Many use online templates. These are usually fluff-filled and niche-specific.
They're robotic and "salesy."
I've attended 3 courses, read 10 books, and sent 600,000 emails in the past five years.
Outcome?
This *proven* email sequence assures me a month's salary every time I send it.
What you will discover in this article is that:
A full 6-part email sales cycle
The essential elements you must incorporate
placeholders and text-filled images
(Applies to any niche)
This can be a product introduction, holiday, or welcome sequence. This works for email-saleable products.
Let's start
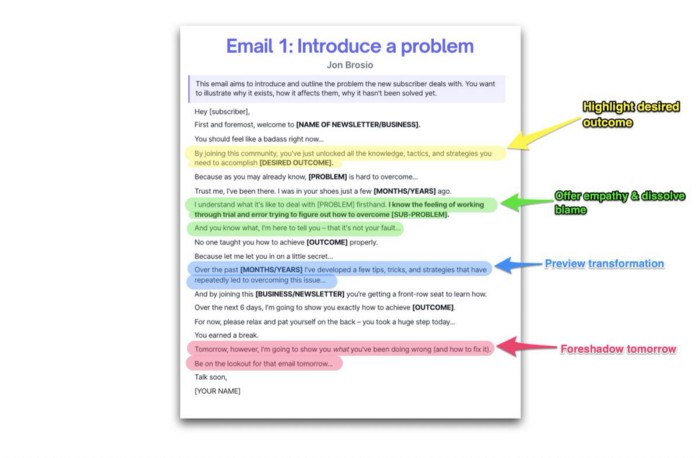
Email 1: Describe your issue
This email is crucial.
How to? We introduce a subscriber or prospect's problem. Later, we'll frame our offer as the solution.
Label the:
Problem
Why it still hasn't been fixed
Resulting implications for the customer
This puts our new subscriber in solve mode and queues our offer:
Email 2: Amplify the consequences
We're still causing problems.
We've created the problem, but now we must employ emotion and storytelling to make it real. We also want to forecast life if nothing changes.
Let's feel:
What occurs if it is not resolved?
Why is it crucial to fix it immediately?
Tell a tale of a person who was in their position. To emphasize the effects, use a true account of another person (or of yourself):

Email 3: Share a transformation story
Selling stories.
Whether in an email, landing page, article, or video. Humanize stories. They give information meaning.
This is where "issue" becomes "solution."
Let's reveal:
A tale of success
A new existence and result
tools and tactics employed
Start by transforming yourself.

Email 4: Prove with testimonials
No one buys what you say.
Emotionally stirred people buy and act. They believe in the product. They feel that if they buy, it will work.
Social proof shows prospects that your solution will help them.
Add:
Earlier and Later
Testimonials
Reviews
Proof this deal works:

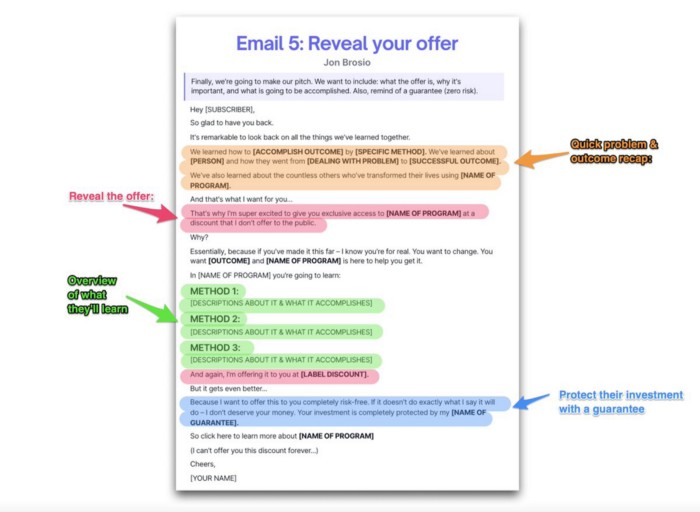
Email 5: Reveal your offer
It's showtime.
This is it. Until now, describing the offer and offering links to a landing page have been sparse in the email pictures.
We've been tense. Gaining steam. Building suspense. Email 5 reveals all.
In this email:
a description of the deal
A word about a promise
recapitulation of the transformation
and make a reference to the urgency Everything should be spelled out clearly:
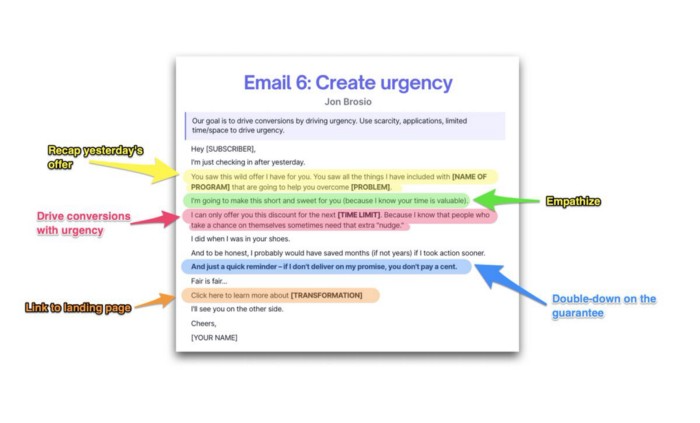
Email no. 6: Instill urgency
When there are stakes, humans act.
Creating and marketing with haste raises the stakes. Urgency makes a prospect act because they'll miss out or gain immensely.
Urgency converts. Use:
short time
Screening
Scarcity
Urgency and conversions. Limited-time offers are easy.
TL;DR
Use this proven 6-part email sequence (that turns subscribers into profit):
Introduce a problem
Amplify it with emotions
Share transformation story
Prove it works with testimonials
Value-stack and present your offer
Drive urgency and entice the purchase

Isaiah McCall
3 years ago
Is TikTok slowly destroying a new generation?
It's kids' digital crack

TikTok is a destructive social media platform.
The interface shortens attention spans and dopamine receptors.
TikTok shares more data than other apps.
Seeing an endless stream of dancing teens on my glowing box makes me feel like a Blade Runner extra.
TikTok did in one year what MTV, Hollywood, and Warner Music tried to do in 20 years. TikTok has psychotized the two-thirds of society Aldous Huxley said were hypnotizable.
Millions of people, mostly kids, are addicted to learning a new dance, lip-sync, or prank, and those who best dramatize this collective improvisation get likes, comments, and shares.
TikTok is a great app. So what?
The Commercial Magnifying Glass TikTok made me realize my generation's time was up and the teenage Zoomers were the target.
I told my 14-year-old sister, "Enjoy your time under the commercial magnifying glass."
TikTok sells your every move, gesture, and thought. Data is the new oil. If you tell someone, they'll say, "Yeah, they collect data, but who cares? I have nothing to hide."
It's a George Orwell novel's beginning. Look up Big Brother Award winners to see if TikTok won.

TikTok shares your data more than any other social media app, and where it goes is unclear. TikTok uses third-party trackers to monitor your activity after you leave the app.
Consumers can't see what data is shared or how it will be used. — Genius URL
32.5 percent of Tiktok's users are 10 to 19 and 29.5% are 20 to 29.
TikTok is the greatest digital marketing opportunity in history, and they'll use it to sell you things, track you, and control your thoughts. Any of its users will tell you, "I don't care, I just want to be famous."
TikTok manufactures mental illness
TikTok's effect on dopamine and the brain is absurd. Dopamine controls the brain's pleasure and reward centers. It's like a switch that tells your brain "this feels good, repeat."
Dr. Julie Albright, a digital culture and communication sociologist, said TikTok users are "carried away by dopamine." It's hypnotic, you'll keep watching."
TikTok constantly releases dopamine. A guy on TikTok recently said he didn't like books because they were slow and boring.
The US didn't ban Tiktok.
Biden and Trump agree on bad things. Both agree that TikTok threatens national security and children's mental health.
The Chinese Communist Party owns and operates TikTok, but that's not its only problem.
There’s borderline child porn on TikTok
It's unsafe for children and violated COPPA.
It's also Chinese spyware. I'm not a Trump supporter, but I was glad he wanted TikTok regulated and disappointed when he failed.
Full-on internet censorship is rare outside of China, so banning it may be excessive. US should regulate TikTok more.
We must reject a low-quality present for a high-quality future.
TikTok vs YouTube
People got mad when I wrote about YouTube's death.
They didn't like when I said TikTok was YouTube's first real challenger.
Indeed. TikTok is the fastest-growing social network. In three years, the Chinese social media app TikTok has gained over 1 billion active users. In the first quarter of 2020, it had the most downloads of any app in a single quarter.
TikTok is the perfect social media app in many ways. It's brief and direct.

Can you believe they had a YouTube vs TikTok boxing match? We are doomed as a species.
YouTube hosts my favorite videos. That’s why I use it. That’s why you use it. New users expect more. They want something quicker, more addictive.
TikTok's impact on other social media platforms frustrates me. YouTube copied TikTok to compete.
It's all about short, addictive content.
I'll admit I'm probably wrong about TikTok. My friend says his feed is full of videos about food, cute animals, book recommendations, and hot lesbians.
Whatever.
TikTok makes us bad
TikTok is the opposite of what the Ancient Greeks believed about wisdom.
It encourages people to be fake. It's like a never-ending costume party where everyone competes.
It does not mean that Gen Z is doomed.
They could be the saviors of the world for all I know.
TikTok feels like a step towards Mike Judge's "Idiocracy," where the average person is a pleasure-seeking moron.