


More on NFTs & Art

shivsak
3 years ago
A visual exploration of the REAL use cases for NFTs in the Future

In this essay, I studied REAL NFT use examples and their potential uses.
Knowledge of the Hype Cycle
Gartner's Hype Cycle.
It proposes 5 phases for disruptive technology.
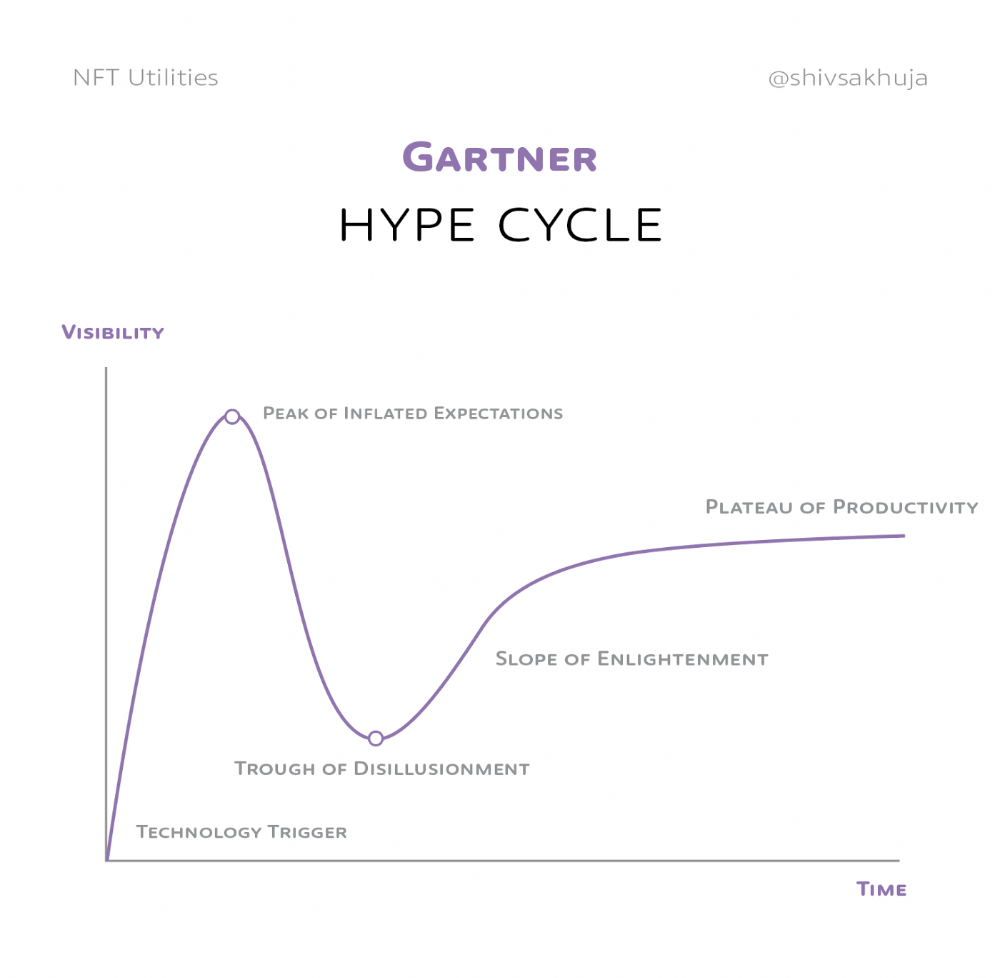
1. Technology Trigger: the emergence of potentially disruptive technology.
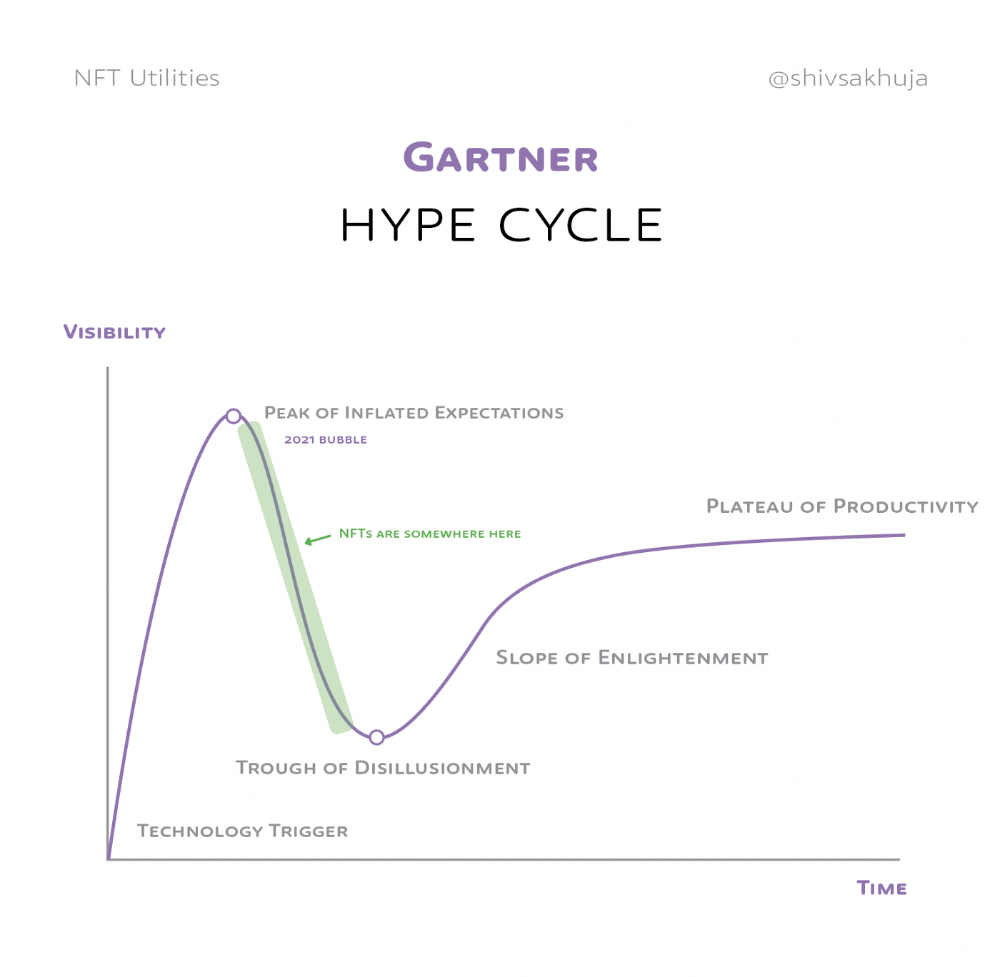
2. Peak of Inflated Expectations: Early publicity creates hype. (Ex: 2021 Bubble)
3. Trough of Disillusionment: Early projects fail to deliver on promises and the public loses interest. I suspect NFTs are somewhere around this trough of disillusionment now.
4. Enlightenment slope: The tech shows successful use cases.
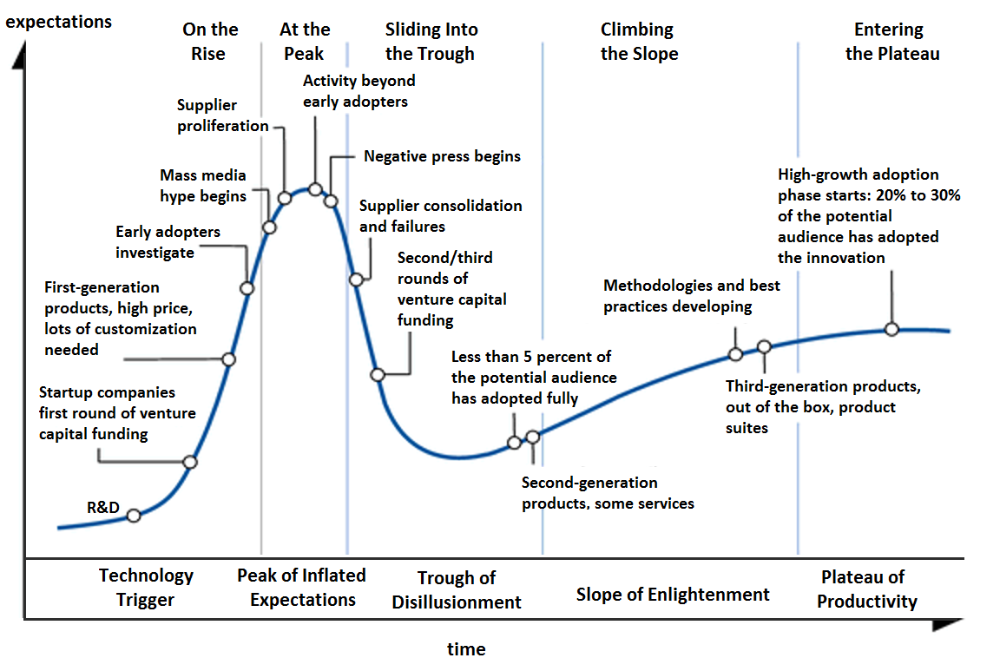
5. Plateau of Productivity: Mainstream adoption has arrived and broader market applications have proven themselves. Here’s a more detailed visual of the Gartner Hype Cycle from Wikipedia.
In the speculative NFT bubble of 2021, @beeple sold Everydays: the First 5000 Days for $69 MILLION in 2021's NFT bubble.
@nbatopshot sold millions in video collectibles.
This is when expectations peaked.
Let's examine NFTs' real-world applications.
Watch this video if you're unfamiliar with NFTs.
Online Art
Most people think NFTs are rich people buying worthless JPEGs and MP4s.
Digital artwork and collectibles are revolutionary for creators and enthusiasts.
NFT Profile Pictures
You might also have seen NFT profile pictures on Twitter.
My profile picture is an NFT I coined with @skogards factoria app, which helps me avoid bogus accounts.

Profile pictures are a good beginning point because they're unique and clearly yours.
NFTs are a way to represent proof-of-ownership. It’s easier to prove ownership of digital assets than physical assets, which is why artwork and pfps are the first use cases.
They can do much more.
NFTs can represent anything with a unique owner and digital ownership certificate. Domains and usernames.
Usernames & Domains
@unstoppableweb, @ensdomains, @rarible sell NFT domains.

NFT domains are transferable, which is a benefit.
Godaddy and other web2 providers have difficult-to-transfer domains. Domains are often leased instead of purchased.
Tickets
NFTs can also represent concert tickets and event passes.
There's a limited number, and entry requires proof.
NFTs can eliminate the problem of forgery and make it easy to verify authenticity and ownership.

NFT tickets can be traded on the secondary market, which allows for:
marketplaces that are uniform and offer the seller and buyer security (currently, tickets are traded on inefficient markets like FB & craigslist)
unbiased pricing
Payment of royalties to the creator

4. Historical ticket ownership data implies performers can airdrop future passes, discounts, etc.
5. NFT passes can be a fandom badge.
The $30B+ online tickets business is increasing fast.
NFT-based ticketing projects:
Gaming Assets
NFTs also help in-game assets.
Imagine someone spending five years collecting a rare in-game blade, then outgrowing or quitting the game. Gamers value that collectible.

The gaming industry is expected to make $200 BILLION in revenue this year, a significant portion of which comes from in-game purchases.
Royalties on secondary market trading of gaming assets encourage gaming businesses to develop NFT-based ecosystems.
Digital assets are the start. On-chain NFTs can represent real-world assets effectively.
Real estate has a unique owner and requires ownership confirmation.
Real Estate
Tokenizing property has many benefits.
1. Can be fractionalized to increase access, liquidity
2. Can be collateralized to increase capital efficiency and access to loans backed by an on-chain asset
3. Allows investors to diversify or make bets on specific neighborhoods, towns or cities +++

I've written about this thought exercise before.
I made an animated video explaining this.
We've just explored NFTs for transferable assets. But what about non-transferrable NFTs?
SBTs are Soul-Bound Tokens. Vitalik Buterin (Ethereum co-founder) blogged about this.
NFTs are basically verifiable digital certificates.
Diplomas & Degrees
That fits Degrees & Diplomas. These shouldn't be marketable, thus they can be non-transferable SBTs.

Anyone can verify the legitimacy of on-chain credentials, degrees, abilities, and achievements.
The same goes for other awards.
For example, LinkedIn could give you a verified checkmark for your degree or skills.

Authenticity Protection
NFTs can also safeguard against counterfeiting.
Counterfeiting is the largest criminal enterprise in the world, estimated to be $2 TRILLION a year and growing.
Anti-counterfeit tech is valuable.
This is one of @ORIGYNTech's projects.

Identity
Identity theft/verification is another real-world problem NFTs can handle.
In the US, 15 million+ citizens face identity theft every year, suffering damages of over $50 billion a year.
This isn't surprising considering all you need for US identity theft is a 9-digit number handed around in emails, documents, on the phone, etc.
Identity NFTs can fix this.
NFTs are one-of-a-kind and unforgeable.
NFTs offer a universal standard.
NFTs are simple to verify.
SBTs, or non-transferrable NFTs, are tied to a particular wallet.
In the event of wallet loss or theft, NFTs may be revoked.

This could be one of the biggest use cases for NFTs.
Imagine a global identity standard that is standardized across countries, cannot be forged or stolen, is digital, easy to verify, and protects your private details.

Since your identity is more than your government ID, you may have many NFTs.
@0xPolygon and @civickey are developing on-chain identity.

Memberships
NFTs can authenticate digital and physical memberships.

Voting
NFT IDs can verify votes.
If you remember 2020, you'll know why this is an issue.
Online voting's ease can boost turnout.

Informational property
NFTs can protect IP.

This can earn creators royalties.
NFTs have 2 important properties:
Verifiability IP ownership is unambiguously stated and publicly verified.
Platforms that enable authors to receive royalties on their IP can enter the market thanks to standardization.
Content Rights

Monetization without copyrighting = more opportunities for everyone.
This works well with the music.

Spotify and Apple Music pay creators very little.
Crowdfunding
Creators can crowdfund with NFTs.
NFTs can represent future royalties for investors.
This is particularly useful for fields where people who are not in the top 1% can’t make money. (Example: Professional sports players)

Mirror.xyz allows blog-based crowdfunding.
Financial NFTs
This introduces Financial NFTs (fNFTs). Unique financial contracts abound.
Examples:
a person's collection of assets (unique portfolio)
A loan contract that has been partially repaid with a lender
temporal tokens (ex: veCRV)

Legal Agreements
Not just financial contracts.
NFT can represent any legal contract or document.

Messages & Emails
What about other agreements? Verbal agreements through emails and messages are likewise unique, but they're easily lost and fabricated.

Health Records
Medical records or prescriptions are another types of documentation that has to be verified but isn't.
Medical NFT examples:
Immunization records
Covid test outcomes
Prescriptions
health issues that may affect one's identity
Observations made via health sensors
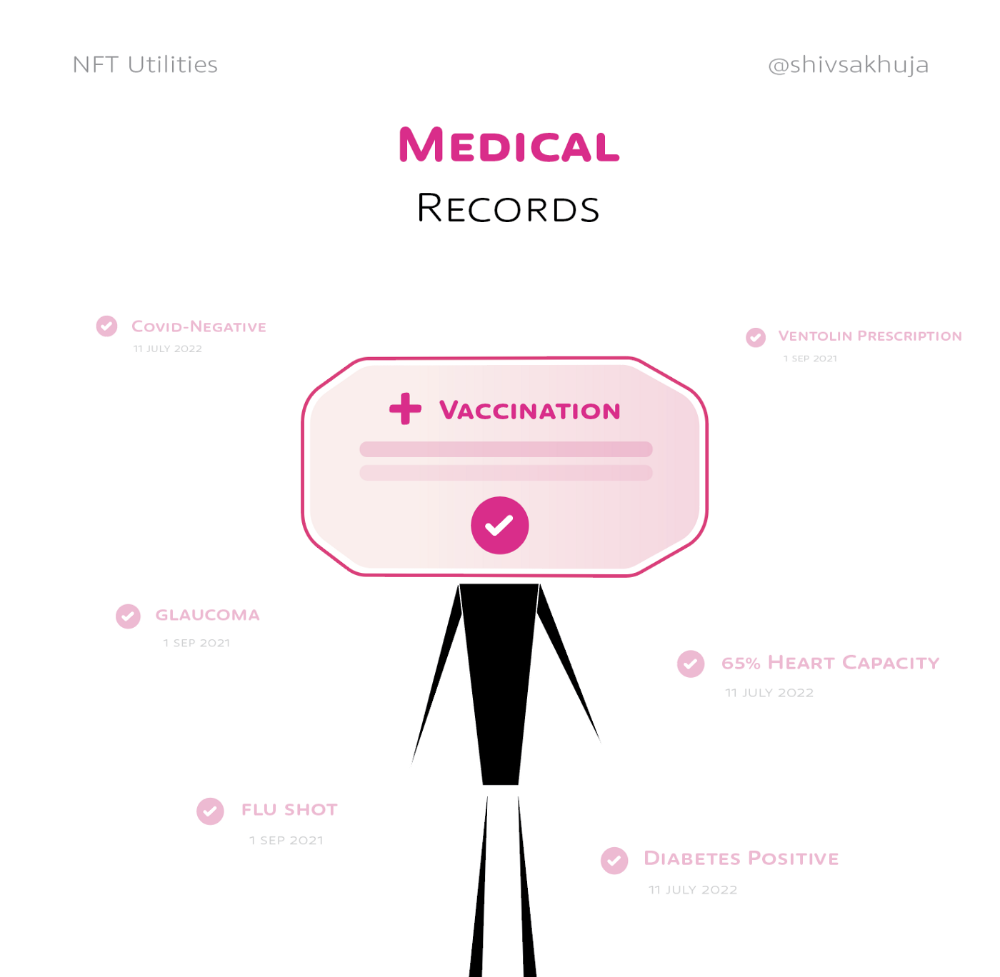
Existing systems of proof by paper / PDF have photoshop-risk.
I tried to include most use scenarios, but this is just the beginning.
NFTs have many innovative uses.
For example: @ShaanVP minted an NFT called “5 Minutes of Fame” 👇
Here are 2 Twitter threads about NFTs:
This piece of gold by @chriscantino
2. This conversation between @punk6529 and @RaoulGMI on @RealVision“The World According to @punk6529”
If you're wondering why NFTs are better than web2 databases for these use scenarios, see this Twitter thread I wrote:
If you liked this, please share it.

Ezra Reguerra
3 years ago
Yuga Labs’ Otherdeeds NFT mint triggers backlash from community
Unhappy community members accuse Yuga Labs of fraud, manipulation, and favoritism over Otherdeeds NFT mint.
Following the Otherdeeds NFT mint, disgruntled community members took to Twitter to criticize Yuga Labs' handling of the event.
Otherdeeds NFTs were a huge hit with the community, selling out almost instantly. Due to high demand, the launch increased Ethereum gas fees from 2.6 ETH to 5 ETH.
But the event displeased many people. Several users speculated that the mint was “planned to fail” so the group could advertise launching its own blockchain, as the team mentioned a chain migration in one tweet.
Others like Mark Beylin tweeted that he had "sold out" on all Ape-related NFT investments after Yuga Labs "revealed their true colors." Beylin also advised others to assume Yuga Labs' owners are “bad actors.”
Some users who failed to complete transactions claim they lost ETH. However, Yuga Labs promised to refund lost gas fees.
CryptoFinally, a Twitter user, claimed Yuga Labs gave BAYC members better land than non-members. Others who wanted to participate paid for shittier land, while BAYCS got the only worthwhile land.
The Otherdeed NFT drop also increased Ethereum's burn rate. Glassnode and Data Always reported nearly 70,000 ETH burned on mint day.

Tora Northman
3 years ago
Pixelmon NFTs are so bad, they are almost good!
Bored Apes prices continue to rise, HAPEBEAST launches, Invisible Friends hype continues to grow. Sadly, not all projects are as successful.
Of course, there are many factors to consider when buying an NFT. Is the project a scam? Will the reveal derail the project? Possibly, but when Pixelmon first teased its launch, it generated a lot of buzz.
With a primary sale mint price of 3 ETH ($8,100 USD), it started as an expensive project, with plenty of fans willing to invest in what was sold as a game. After it was revealed, it fell rapidly.
Why? It was overpromised and under delivered.
According to the project's creator[^1], the funds generated will be used to develop the artwork. "The Pixelmon reveal was wrong. This is what our Pixelmon look like in-game. "Despite the fud, I will not go anywhere," he wrote on Twitter. The goal remains. The funds will still be used to build our game. I will finish this project."
The project raised $70 million USD, but the NFTs buyers received were not the project's original teasers. Some call it "the worst NFT project ever," while others call it a complete scam.
But there's hope for some buyers. Kevin emerged from the ashes as the project was roasted over the fire.
A Minecraft character meets Salad Fingers - that's Kevin. He's a frog-like creature whose reveal was such a terrible NFT that it became part of history – and a meme.
If you're laughing at people paying $8K for a silly pixelated image, you might need to take it back. Precisely because of this, lucky holders who minted Kevin have been able to sell the now-memed NFT for over 8 ETH (around $24,000 USD), with some currently listed for 100 ETH.
Of course, Twitter has been awash in memes mocking those who invested in the project, because what else can you do when so many people lose money?
It's still unclear if the NFT project is a scam, but the team behind it was hired on Upwork. There's still hope for redemption, but Kevin's rise to fame appears to be the only positive outcome so far.
[^1] This is not the first time the creator (A 20-yo New Zealanders) has sought money via an online platform and had people claiming he under-delivered. He raised $74,000 on Kickstarter for a card game called Psycho Chicken. There are hundreds of comments on the Kickstarter project saying they haven't received the product and pleading for a refund or an update.
You might also like

Mike Tarullo
3 years ago
Even In a Crazy Market, Hire the Best People: The "First Ten" Rules
Hiring is difficult, but you shouldn't compromise on team members. Or it may suggest you need to look beyond years in a similar role/function.
Every hire should be someone we'd want as one of our first ten employees.
If you hire such people, your team will adapt, initiate, and problem-solve, and your company will grow. You'll stay nimble even as you scale, and you'll learn from your colleagues.
If you only hire for a specific role or someone who can execute the job, you'll become a cluster of optimizers, and talent will depart for a more fascinating company. A startup is continually changing, therefore you want individuals that embrace it.
As a leader, establishing ideal conditions for talent and having a real ideology should be high on your agenda. You can't eliminate attrition, nor would you want to, but you can hire people who will become your company's leaders.
In my last four jobs I was employee 2, 5, 3, and 5. So while this is all a bit self serving, you’re the one reading my writing — and I have some experience with who works out in the first ten!
First, we'll examine what they do well (and why they're beneficial for startups), then what they don't, and how to hire them.
First 10 are:
Business partners: Because it's their company, they take care of whatever has to be done and have ideas about how to do it. You can rely on them to always put the success of the firm first because it is their top priority (company success is strongly connected with success for early workers). This approach will eventually take someone to leadership positions.
High Speed Learners: They process knowledge quickly and can reach 80%+ competency in a new subject matter rather quickly. A growing business that is successful tries new things frequently. We have all lost a lot of money and time on employees who follow the wrong playbook or who wait for someone else within the company to take care of them.
Autodidacts learn by trial and error, osmosis, networking with others, applying first principles, and reading voraciously (articles, newsletters, books, and even social media). Although teaching is wonderful, you won't have time.
Self-scaling: They figure out a means to deal with issues and avoid doing the grunt labor over the long haul, increasing their leverage. Great people don't keep doing the same thing forever; as they expand, they use automation and delegation to fill in their lower branches. This is a crucial one; even though you'll still adore them, you'll have to manage their scope or help them learn how to scale on their own.
Free Range: You can direct them toward objectives rather than specific chores. Check-ins can be used to keep them generally on course without stifling invention instead of giving them precise instructions because doing so will obscure their light.
When people are inspired, they bring their own ideas about what a firm can be and become animated during discussions about how to get there.
Novelty Seeking: They look for business and personal growth chances. Give them fresh assignments and new directions to follow around once every three months.
Here’s what the First Ten types may not be:
Domain specialists. When you look at their resumes, you'll almost certainly think they're unqualified. Fortunately, a few strategically positioned experts may empower a number of First Ten types by serving on a leadership team or in advising capacities.
Balanced. These people become very invested, and they may be vulnerable to many types of stress. You may need to assist them in managing their own stress and coaching them through obstacles. If you are reading this and work at Banza, I apologize for not doing a better job of supporting this. I need to be better at it.
Able to handle micromanagement with ease. People who like to be in charge will suppress these people. Good decision-making should be delegated to competent individuals. Generally speaking, if you wish to scale.
Great startup team members have versatility, learning, innovation, and energy. When we hire for the function, not the person, we become dull and staid. Could this person go to another department if needed? Could they expand two levels in a few years?
First Ten qualities and experience level may have a weak inverse association. People with 20+ years of experience who had worked at larger organizations wanted to try something new and had a growth mentality. College graduates may want to be told what to do and how to accomplish it so they can stay in their lane and do what their management asks.
Does the First Ten archetype sound right for your org? Cool, let’s go hiring. How will you know when you’ve found one?
They exhibit adaptive excellence, excelling at a variety of unrelated tasks. It could be hobbies or professional talents. This suggests that they will succeed in the next several endeavors they pursue.
Successful risk-taking is doing something that wasn't certain to succeed, sometimes more than once, and making it do so. It's an attitude.
Rapid Rise: They regularly change roles and get promoted. However, they don't leave companies when the going gets tough. Look for promotions at every stop and at least one position with three or more years of experience.
You can ask them:
Tell me about a time when you started from scratch or achieved success. What occurred en route? You might request a variety of tales from various occupations or even aspects of life. They ought to be energized by this.
What new skills have you just acquired? It is not required to be work-related. They must be able to describe it and unintentionally become enthusiastic about it.
Tell me about a moment when you encountered a challenge and had to alter your strategy. The core of a startup is reinventing itself when faced with obstacles.
Tell me about a moment when you eliminated yourself from a position at work. They've demonstrated they can permanently solve one issue and develop into a new one, as stated above.
Why do you want to leave X position or Y duty? These people ought to be moving forward, not backward, all the time. Instead, they will discuss what they are looking forward to visiting your location.
Any questions? Due to their inherent curiosity and desire to learn new things, they should practically never run out of questions. You can really tell if they are sufficiently curious at this point.
People who see their success as being the same as the success of the organization are the best-case team members, in any market. They’ll grow and change with the company, and always try to prioritize what matters. You’ll find yourself more energized by your work because you’re surrounded by others who are as well. Happy teambuilding!

Alexandra Walker-Jones
3 years ago
These are the 15 foods you should eat daily and why.
Research on preventing disease, extending life, and caring for your body from the inside out

Grapefruit and pomegranates aren't on the list, so ignore that. Mostly, I enjoyed the visual, but those fruits are healthful, too.
15 (or 17 if you consider the photo) different foods a day sounds like a lot. If you're not used to it — it is.
These lists don't aim for perfection. Instead, use this article and the science below to eat more of these foods. If you can eat 5 foods one day and 5 the next, you're doing well. This list should be customized to your requirements and preferences.
“Every time you eat or drink, you are either feeding disease or fighting it” -Heather Morgan.
The 15 Foods That You Should Consume Daily and Why:
1. Dark/Red Berries
(blueberries, blackberries, acai, goji, cherries, strawberries, raspberries)
The 2010 Global Burden of Disease Study is the greatest definitive analysis of death and disease risk factors in history. They found the primary cause of both death, disability, and disease inside the United States was diet.
Not eating enough fruit, and specifically berries, was one of the best predictors of disease (1).
What's special about berries? It's their color! Berries have the most antioxidants of any fruit, second only to spices. The American Cancer Society found that those who ate the most berries were less likely to die of cardiovascular disease.
2. Beans
Soybeans, black beans, kidney beans, lentils, split peas, chickpeas.
Beans are one of the most important predictors of survival in older people, according to global research (2).
For every 20 grams (2 tablespoons) of beans consumed daily, the risk of death is reduced by 8%.
Soybeans and soy foods are high in phytoestrogen, which reduces breast and prostate cancer risks. Phytoestrogen blocks the receptors' access to true estrogen, mitigating the effects of weight gain, dairy (high in estrogen), and hormonal fluctuations (3).
3. Nuts
(almonds, walnuts, pecans, pistachios, Brazil nuts, cashews, hazelnuts, macadamia nuts)
Eating a handful of nuts every day reduces the risk of chronic diseases like heart disease and diabetes. Nuts also reduce oxidation, blood sugar, and LDL (bad) cholesterol, improving arterial function (4).
Despite their high-fat content, studies have linked daily nut consumption to a slimmer waistline and a lower risk of obesity (5).
4. Flaxseed
(milled flaxseed)
2013 research found that ground flaxseed had one of the strongest anti-hypertensive effects of any food. A few tablespoons (added to a smoothie or baked goods) lowered blood pressure and stroke risk 23 times more than daily aerobic exercise (6).
Flax shouldn't replace exercise, but its nutritional punch is worth adding to your diet.
5. Other seeds
(chia seeds, hemp seeds, pumpkin seeds, sesame seeds, fennel seeds)
Seeds are high in fiber and omega-3 fats and can be added to most dishes without being noticed.
When eaten with or after a meal, chia seeds moderate blood sugar and reduce inflammatory chemicals in the blood (7). Overall, a great daily addition.
6. Dates
Dates are one of the world's highest sugar foods, with 80% sugar by weight. Pure cake frosting is 60%, maple syrup is 66%, and cotton-candy jelly beans are 70%.
Despite their high sugar content, dates have a low glycemic index, meaning they don't affect blood sugar levels dramatically. They also improve triglyceride and antioxidant stress levels (8).
Dates are a great source of energy and contain high levels of dietary fiber and polyphenols, making 3-10 dates a great way to fight disease, support gut health with prebiotics, and satisfy a sweet tooth (9).
7. Cruciferous Veggies
(broccoli, Brussel sprouts, horseradish, kale, cauliflower, cabbage, boy choy, arugula, radishes, turnip greens)
Cruciferous vegetables contain an active ingredient that makes them disease-fighting powerhouses. Sulforaphane protects our brain, eyesight, against free radicals and environmental hazards, and treats and prevents cancer (10).
Unless you eat raw cruciferous vegetables daily, you won't get enough sulforaphane (and thus, its protective nutritional benefits). Cooking destroys the enzyme needed to create this super-compound.
If you chop broccoli, cauliflower, or turnip greens and let them sit for 45 minutes before cooking them, the enzyme will have had enough time to work its sulforaphane magic, allowing the vegetables to retain the same nutritional value as if eaten raw. Crazy, right? For more on this, see What Chopping Your Vegetables Has to Do with Fighting Cancer.
8. Whole grains
(barley, brown rice, quinoa, oats, millet, popcorn, whole-wheat pasta, wild rice)
Whole-grains are one of the healthiest ways to consume your daily carbs and help maintain healthy gut flora.
This happens when fibre is broken down in the colon and starts a chain reaction, releasing beneficial substances into the bloodstream and reducing the risk of Type 2 Diabetes and inflammation (11).
9. Spices
(turmeric, cumin, cinnamon, ginger, saffron, cloves, cardamom, chili powder, nutmeg, coriander)
7% of a person's cells will have DNA damage. This damage is caused by tiny breaks in our DNA caused by factors like free-radical exposure.
Free radicals cause mutations that damage lipids, proteins, and DNA, increasing the risk of disease and cancer. Free radicals are unavoidable because they result from cellular metabolism, but they can be avoided by consuming anti-oxidant and detoxifying foods.
Including spices and herbs like rosemary or ginger in our diet may cut DNA damage by 25%. Yes, this damage can be improved through diet. Turmeric worked better at a lower dose (just a pinch, daily). For maximum free-radical fighting (and anti-inflammatory) effectiveness, use 1.5 tablespoons of similar spices (12).
10. Leafy greens
(spinach, collard greens, lettuce, other salad greens, swiss chard)
Studies show that people who eat more leafy greens perform better on cognitive tests and slow brain aging by a year or two (13).
As we age, blood flow to the brain drops due to a decrease in nitric oxide, which prevents blood vessels from dilatation. Daily consumption of nitrate-rich vegetables like spinach and swiss chard may prevent dementia and Alzheimer's.
11. Fermented foods
(sauerkraut, tempeh, kombucha, plant-based kefir)
Miso, kimchi, and sauerkraut contain probiotics that support gut microbiome.
Probiotics balance the good and bad bacteria in our bodies and offer other benefits. Fermenting fruits and vegetables increases their antioxidant and vitamin content, preventing disease in multiple ways (14).
12. Sea vegetables
(seaweed, nori, dulse flakes)
A population study found that eating one sheet of nori seaweed per day may cut breast cancer risk by more than half (15).
Seaweed and sea vegetables may help moderate estrogen levels in the metabolism, reducing cancer and disease risk.
Sea vegetables make up 30% of the world's edible plants and contain unique phytonutrients. A teaspoon of these super sea-foods on your dinner will help fight disease from the inside out.
13. Water
I'm less concerned about whether you consider water food than whether you drink enough. If this list were ranked by what single item led to the best health outcomes, water would be first.
Research shows that people who drink 5 or more glasses of water per day have a 50% lower risk of dying from heart disease than those who drink 2 or less (16).
Drinking enough water boosts energy, improves skin, mental health, and digestion, and reduces the risk of various health issues, including obesity.
14. Tea
All tea consumption is linked to a lower risk of stroke, heart disease, and early death, with green tea leading for antioxidant content and immediate health benefits.
Green tea leaves may also be able to interfere with each stage of cancer formation, from the growth of the first mutated cell to the spread and progression of cancer in the body. Green tea is a quick and easy way to support your long-term and short-term health (17).
15. Supplemental B12 vitamin
B12, or cobalamin, is a vitamin responsible for cell metabolism. Not getting enough B12 can have serious consequences.
Historically, eating vegetables from untreated soil helped humans maintain their vitamin B12 levels. Due to modern sanitization, our farming soil lacks B12.
B12 is often cited as a problem only for vegetarians and vegans (as animals we eat are given B12 supplements before slaughter), but recent studies have found that plant-based eaters have lower B12 deficiency rates than any other diet (18).
Article Sources:

Eve Arnold
3 years ago
Your Ideal Position As a Part-Time Creator
Inspired by someone I never met

Inspiration is good and bad.
Paul Jarvis inspires me. He's a web person and writer who created his own category by being himself.
Paul said no thank you when everyone else was developing, building, and assuming greater responsibilities. This isn't success. He rewrote the rules. Working for himself, expanding at his own speed, and doing what he loves were his definitions of success.
Play with a problem that you have
The biggest problem can be not recognizing a problem.
Acceptance without question is deception. When you don't push limits, you forget how. You start thinking everything must be as it is.
For example: working. Paul worked a 9-5 agency work with little autonomy. He questioned whether the 9-5 was a way to live, not the way.
Another option existed. So he chipped away at how to live in this new environment.
Don't simply jump
Internet writers tell people considering quitting 9-5 to just quit. To throw in the towel. To do what you like.
The advice is harmful, despite the good intentions. People think quitting is hard. Like courage is the issue. Like handing your boss a resignation letter.
Nope. The tough part comes after. It’s easy to jump. Landing is difficult.
The landing
Paul didn't quit. Intelligent individuals don't. Smart folks focus on landing. They imagine life after 9-5.
Paul had been a web developer for a long time, had solid clients, and was respected. Hence if he pushed the limits and discovered another route, he had the potential to execute.
Working on the side
Society loves polarization. It’s left or right. Either way. Or chaos. It's 9-5 or entrepreneurship.
But like Paul, you can stretch polarization's limits. In-between exists.
You can work a 9-5 and side jobs (as I do). A mix of your favorites. The 9-5's stability and creativity. Fire and routine.
Remember you can't have everything but anything. You can create and work part-time.
My hybrid lifestyle
Not selling books doesn't destroy my world. My globe keeps spinning if my new business fails or if people don't like my Tweets. Unhappy algorithm? Cool. I'm not bothered (okay maybe a little).
The mix gives me the best of both worlds. To create, hone my skill, and grasp big-business basics. I like routine, but I also appreciate spending 4 hours on Saturdays writing.
Some days I adore leaving work at 5 pm and disconnecting. Other days, I adore having a place to write if inspiration strikes during a run or a discussion.
I’m a part-time creator
I’m a part-time creator. No, I'm not trying to quit. I don't work 5 pm - 2 am on the side. No, I'm not at $10,000 MRR.
I work part-time but enjoy my 9-5. My 9-5 has goodies. My side job as well.
It combines both to meet my lifestyle. I'm satisfied.
Join the Part-time Creators Club for free here. I’ll send you tips to enhance your creative game.