



More on Technology

Al Anany
3 years ago
Notion AI Might Destroy Grammarly and Jasper
The trick Notion could use is simply Facebook-ing the hell out of them.

*Time travel to fifteen years ago.* Future-Me: “Hey! What are you up to?” Old-Me: “I am proofreading an article. It’s taking a few hours, but I will be done soon.” Future-Me: “You know, in the future, you will be using a google chrome plugin called Grammarly that will help you easily proofread articles in half that time.” Old-Me: “What is… Google Chrome?” Future-Me: “Gosh…”
I love Grammarly. It’s one of those products that I personally feel the effects of. I mean, Space X is a great company. But I am not a rocket writing this article in space (or am I?)…
No, I’m not. So I don’t personally feel a connection to Space X. So, if a company collapse occurs in the morning, I might write about it. But I will have zero emotions regarding it.
Yet, if Grammarly fails tomorrow, I will feel 1% emotionally distressed. So looking at the title of this article, you’d realize that I am betting against them. This is how much I believe in the critical business model that’s taking over the world, the one of Notion.
Notion How frequently do you go through your notes?
Grammarly is everywhere, which helps its success. Grammarly is available when you update LinkedIn on Chrome. Grammarly prevents errors in Google Docs.
My internal concentration isn't apparent in the previous paragraph. Not Grammarly. I should have used Chrome to make a Google doc and LinkedIn update. Without this base, Grammarly will be useless.
So, welcome to this business essay.
Grammarly provides a solution.
Another issue is resolved by Jasper.
Your entire existence is supposed to be contained within Notion.
New Google Chrome is offline. It's an all-purpose notepad (in the near future.)
How should I start my blog? Enter it in Note.
an update on LinkedIn? If you mention it, it might be automatically uploaded there (with little help from another app.)
An advanced thesis? You can brainstorm it with your coworkers.
This ad sounds great! I won't cry if Notion dies tomorrow.
I'll reread the following passages to illustrate why I think Notion could kill Grammarly and Jasper.
Notion is a fantastic app that incubates your work.
Smartly, they began with note-taking.
Hopefully, your work will be on Notion. Grammarly and Jasper are still must-haves.
Grammarly will proofread your typing while Jasper helps with copywriting and AI picture development.
They're the best, therefore you'll need them. Correct? Nah.
Notion might bombard them with Facebook posts.
Notion: “Hi Grammarly, do you want to sell your product to us?” Grammarly: “Dude, we are more valuable than you are. We’ve even raised $400m, while you raised $342m. Our last valuation round put us at $13 billion, while yours put you at $10 billion. Go to hell.” Notion: “Okay, we’ll speak again in five years.”
Notion: “Jasper, wanna sell?” Jasper: “Nah, we’re deep into AI and the field. You can’t compete with our people.” Notion: “How about you either sell or you turn into a Snapchat case?” Jasper: “…”
Notion is your home. Grammarly is your neighbor. Your track is Jasper.
What if you grew enough vegetables in your backyard to avoid the supermarket? No more visits.
What if your home had a beautiful treadmill? You won't rush outside as much (I disagree with my own metaphor). (You get it.)
It's Facebooking. Instagram Stories reduced your Snapchat usage. Notion will reduce your need to use Grammarly.
The Final Piece of the AI Puzzle
Let's talk about Notion first, since you've probably read about it everywhere.
They raised $343 million, as I previously reported, and bought four businesses
According to Forbes, Notion will have more than 20 million users by 2022. The number of users is up from 4 million in 2020.
If raising $1.8 billion was impressive, FTX wouldn't have fallen.
This article compares the basic product to two others. Notion is a day-long app.
Notion has released Notion AI to support writers. It's early, so it's not as good as Jasper. Then-Jasper isn't now-Jasper. In five years, Notion AI will be different.
With hard work, they may construct a Jasper-like writing assistant. They have resources and users.
At this point, it's all speculation. Jasper's copywriting is top-notch. Grammarly's proofreading is top-notch. Businesses are constrained by user activities.
If Notion's future business movements are strategic, they might become a blue ocean shark (or get acquired by an unbelievable amount.)
I love business mental teasers, so tell me:
How do you feel? Are you a frequent Notion user?
Do you dispute my position? I enjoy hearing opposing viewpoints.
Ironically, I proofread this with Grammarly.

Tom Smykowski
3 years ago
CSS Scroll-linked Animations Will Transform The Web's User Experience
We may never tap again in ten years.
I discussed styling websites and web apps on smartwatches in my earlier article on W3C standardization.
The Parallax Chronicles
Section containing examples and flying objects
Another intriguing Working Draft I found applies to all devices, including smartphones.
These pages may have something intriguing. Take your time. Return after scrolling:
What connects these three pages?
JustinWick at English Wikipedia • CC-BY-SA-3.0
Scroll-linked animation, commonly called parallax, is the effect.
WordPress theme developers' quick setup and low-code tools made the effect popular around 2014.
Parallax: Why Designers Love It
The chapter that your designer shouldn't read
Online video playback required searching, scrolling, and clicking ten years ago. Scroll and click four years ago.
Some video sites let you swipe to autoplay the next video from an endless list.
UI designers create scrollable pages and apps to accommodate the behavioral change.
Web interactivity used to be mouse-based. Clicking a button opened a help drawer, and hovering animated it.
However, a large page with more material requires fewer buttons and less interactiveness.
Designers choose scroll-based effects. Design and frontend developers must fight the trend but prepare for the worst.
How to Create Parallax
The component that you might want to show the designer
JavaScript-based effects track page scrolling and apply animations.
Javascript libraries like lax.js simplify it.
Using it needs a lot of human mathematical and physical computations.
Your asset library must also be prepared to display your website on a laptop, television, smartphone, tablet, foldable smartphone, and possibly even a microwave.
Overall, scroll-based animations can be solved better.
CSS Scroll-linked Animations
CSS makes sense since it's presentational. A Working Draft has been laying the groundwork for the next generation of interactiveness.
The new CSS property scroll-timeline powers the feature, which MDN describes well.
Before testing it, you should realize it is poorly supported:

Firefox 103 currently supports it.
There is also a polyfill, with some demo examples to explore.
Summary
Web design was a protracted process. Started with pages with static backdrop images and scrollable text. Artists and designers may use the scroll-based animation CSS API to completely revamp our web experience.
It's a promising frontier. This post may attract a future scrollable web designer.
Ps. I have created flashcards for HTML, Javascript etc. Check them out!

Waleed Rikab, PhD
3 years ago
The Enablement of Fraud and Misinformation by Generative AI What You Should Understand
Recent investigations have shown that generative AI can boost hackers and misinformation spreaders.

Since its inception in late November 2022, OpenAI's ChatGPT has entertained and assisted many online users in writing, coding, task automation, and linguistic translation. Given this versatility, it is maybe unsurprising but nonetheless regrettable that fraudsters and mis-, dis-, and malinformation (MDM) spreaders are also considering ChatGPT and related AI models to streamline and improve their operations.
Malign actors may benefit from ChatGPT, according to a WithSecure research. ChatGPT promises to elevate unlawful operations across many attack channels. ChatGPT can automate spear phishing attacks that deceive corporate victims into reading emails from trusted parties. Malware, extortion, and illicit fund transfers can result from such access.
ChatGPT's ability to simulate a desired writing style makes spear phishing emails look more genuine, especially for international actors who don't speak English (or other languages like Spanish and French).
This technique could let Russian, North Korean, and Iranian state-backed hackers conduct more convincing social engineering and election intervention in the US. ChatGPT can also create several campaigns and various phony online personas to promote them, making such attacks successful through volume or variation. Additionally, image-generating AI algorithms and other developing techniques can help these efforts deceive potential victims.
Hackers are discussing using ChatGPT to install malware and steal data, according to a Check Point research. Though ChatGPT's scripts are well-known in the cyber security business, they can assist amateur actors with little technical understanding into the field and possibly develop their hacking and social engineering skills through repeated use.
Additionally, ChatGPT's hacking suggestions may change. As a writer recently indicated, ChatGPT's ability to blend textual and code-based writing might be a game-changer, allowing the injection of innocent content that would subsequently turn out to be a malicious script into targeted systems. These new AI-powered writing- and code-generation abilities allow for unique cyber attacks, regardless of viability.
OpenAI fears ChatGPT usage. OpenAI, Georgetown University's Center for Security and Emerging Technology, and Stanford's Internet Observatory wrote a paper on how AI language models could enhance nation state-backed influence operations. As a last resort, the authors consider polluting the internet with radioactive or misleading data to ensure that AI language models produce outputs that other language models can identify as AI-generated. However, the authors of this paper seem unaware that their "solution" might cause much worse MDM difficulties.
Literally False News
The public argument about ChatGPTs content-generation has focused on originality, bias, and academic honesty, but broader global issues are at stake. ChatGPT can influence public opinion, troll individuals, and interfere in local and national elections by creating and automating enormous amounts of social media material for specified audiences.
ChatGPT's capacity to generate textual and code output is crucial. ChatGPT can write Python scripts for social media bots and give diverse content for repeated posts. The tool's sophistication makes it irrelevant to one's language skills, especially English, when writing MDM propaganda.
I ordered ChatGPT to write a news piece in the style of big US publications declaring that Ukraine is on the verge of defeat in its fight against Russia due to corruption, desertion, and exhaustion in its army. I also gave it a fake reporter's byline and an unidentified NATO source's remark. The outcome appears convincing:

Worse, terrible performers can modify this piece to make it more credible. They can edit the general's name or add facts about current wars. Furthermore, such actors can create many versions of this report in different forms and distribute them separately, boosting its impact.
In this example, ChatGPT produced a news story regarding (fictional) greater moviegoer fatality rates:
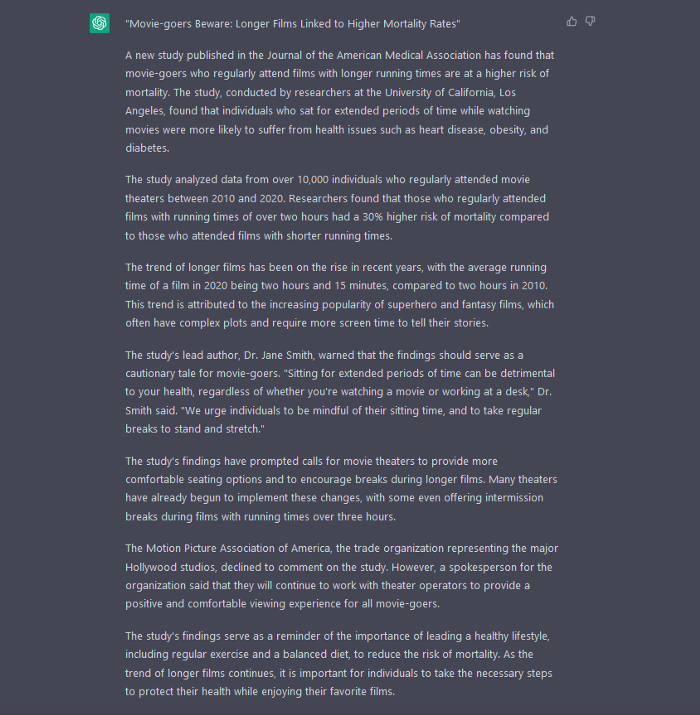
Editing this example makes it more plausible. Dr. Jane Smith, the putative author of the medical report, might be replaced with a real-life medical person or a real victim of this supposed medical hazard.
Can deceptive texts be found? Detecting AI text is behind AI advancements. Minor AI-generated text alterations can upset these technologies.
Some OpenAI individuals have proposed covert methods to watermark AI-generated literature to prevent its abuse. AI models would create information that appears normal to humans but would follow a cryptographic formula that would warn other machines that it was AI-made. However, security experts are cautious since manually altering the content interrupts machine and human detection of AI-generated material.
How to Prepare
Cyber security and IT workers can research and use generative AI models to fight spear fishing and extortion. Governments may also launch MDM-defence projects.
In election cycles and global crises, regular people may be the most vulnerable to AI-produced deceit. Until regulation or subsequent technical advances, individuals must recognize exposure to AI-generated fraud, dating scams, other MDM activities.
A three-step verification method of new material in suspicious emails or social media posts can help identify AI content and manipulation. This three-step approach asks about the information's distribution platform (is it reliable? ), author (is the reader familiar with them? ), and plausibility given one's prior knowledge of the topic.
Consider a report by a trusted journalist that makes shocking statements in their typical manner. AI-powered fake news may be released on an unexpected platform, such as a newly created Facebook profile. However, if it links to a known media source, it is more likely to be real.
Though hard and subjective, this verification method may be the only barrier against manipulation for now.
AI language models:
How to Recognize an AI-Generated Article ChatGPT, the popular AI-powered chatbot, can and likely does generate medium.com-style articles.
AI-Generated Text Detectors Fail. Do This. Online tools claim to detect ChatGPT output. Even with superior programming, I tested some of these tools. pub
Why Original Writers Matter Despite AI Language Models Creative writers may never be threatened by AI language models.
You might also like

Jenn Leach
3 years ago
This clever Instagram marketing technique increased my sales to $30,000 per month.
No Paid Ads Required

I had an online store. After a year of running the company alongside my 9-to-5, I made enough to resign.
That day was amazing.
This Instagram marketing plan helped the store succeed.
How did I increase my sales to five figures a month without using any paid advertising?
I used customer event marketing.
I'm not sure this term exists. I invented it to describe what I was doing.
Instagram word-of-mouth, fan engagement, and interaction drove sales.
If a customer liked or disliked a product, the buzz would drive attention to the store.
I used customer-based events to increase engagement and store sales.
Success!
Here are the weekly Instagram customer events I coordinated while running my business:
Be the Buyer Days
Flash sales
Mystery boxes
Be the Buyer Days: How do they work?
Be the Buyer Days are exactly that.
You choose a day to share stock selections with social media followers.
This is an easy approach to engaging customers and getting fans enthusiastic about new releases.
First, pick a handful of items you’re considering ordering. I’d usually pick around 3 for Be the Buyer Day.
Then I'd poll the crowd on Instagram to vote on their favorites.
This was before Instagram stories, polls, and all the other cool features Instagram offers today. I think using these tools now would make this event even better.
I'd ask customers their favorite back then.
The growing comments excited customers.
Then I'd declare the winner, acquire the products, and start selling it.
How do flash sales work?
I mostly ran flash sales.
You choose a limited number of itemsdd for a few-hour sale.
We wanted most sales to result in sold-out items.
When an item sells out, it contributes to the sensation of scarcity and can inspire customers to visit your store to buy a comparable product, join your email list, become a fan, etc.
We hoped they'd act quickly.
I'd hold flash deals twice a week, which generated scarcity and boosted sales.
The store had a few thousand Instagram followers when I started flash deals.
Each flash sale item would make $400 to $600.
$400 x 3= $1,200
That's $1,200 on social media!
Twice a week, you'll make roughly $10K a month from Instagram.
$1,200/day x 8 events/month=$9,600
Flash sales did great.
We held weekly flash deals and sent social media and email reminders. That’s about it!
How are mystery boxes put together?
All you do is package a box of store products and sell it as a mystery box on TikTok or retail websites.
A $100 mystery box would cost $30.
You're discounting high-value boxes.
This is a clever approach to get rid of excess inventory and makes customers happy.
It worked!
Be the Buyer Days, flash deals, and mystery boxes helped build my company without paid advertisements.
All companies can use customer event marketing. Involving customers and providing an engaging environment can boost sales.
Try it!

Sanjay Priyadarshi
3 years ago
Using Ruby code, a programmer created a $48,000,000,000 product that Elon Musk admired.
Unexpected Success

Shopify CEO and co-founder Tobias Lutke. Shopify is worth $48 billion.
World-renowned entrepreneur Tobi
Tobi never expected his first online snowboard business to become a multimillion-dollar software corporation.
Tobi founded Shopify to establish a 20-person company.
The publicly traded corporation employs over 10,000 people.
Here's Tobi Lutke's incredible story.
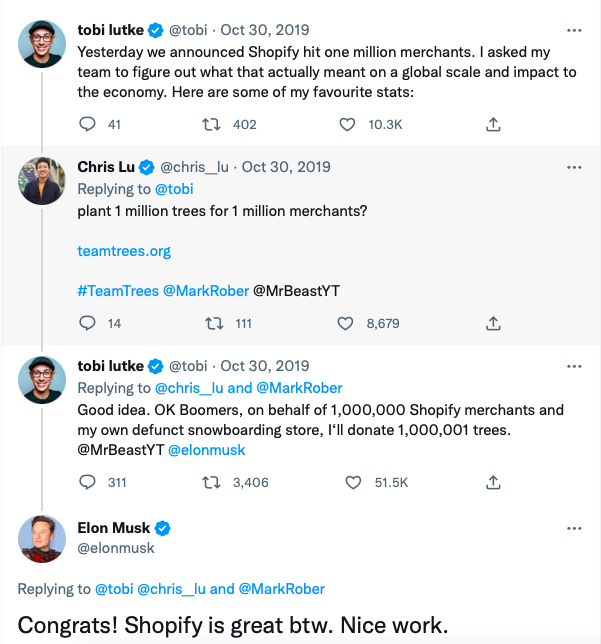
Elon Musk tweeted his admiration for the Shopify creator.
30-October-2019.
Musk praised Shopify founder Tobi Lutke on Twitter.
Happened:
Explore this programmer's journey.
What difficulties did Tobi experience as a young child?
Germany raised Tobi.
Tobi's parents realized he was smart but had trouble learning as a toddler.
Tobi was learning disabled.
Tobi struggled with school tests.
Tobi's learning impairments were undiagnosed.
Tobi struggled to read as a dyslexic.
Tobi also found school boring.
Germany's curriculum didn't inspire Tobi's curiosity.
“The curriculum in Germany was taught like here are all the solutions you might find useful later in life, spending very little time talking about the problem…If I don’t understand the problem I’m trying to solve, it’s very hard for me to learn about a solution to a problem.”
Studying computer programming
After tenth grade, Tobi decided school wasn't for him and joined a German apprenticeship program.
This curriculum taught Tobi software engineering.
He was an apprentice in a small Siemens subsidiary team.
Tobi worked with rebellious Siemens employees.
Team members impressed Tobi.
Tobi joined the team for this reason.
Tobi was pleased to get paid to write programming all day.
His life could not have been better.
Devoted to snowboarding
Tobi loved snowboarding.
He drove 5 hours to ski at his folks' house.
His friends traveled to the US to snowboard when he was older.
However, the cheap dollar conversion rate led them to Canada.
2000.
Tobi originally decided to snowboard instead than ski.
Snowboarding captivated him in Canada.
On the trip to Canada, Tobi encounters his wife.
Tobi meets his wife Fiona McKean on his first Canadian ski trip.
They maintained in touch after the trip.
Fiona moved to Germany after graduating.
Tobi was a startup coder.
Fiona found work in Germany.
Her work included editing, writing, and academics.
“We lived together for 10 months and then she told me that she need to go back for the master's program.”
With Fiona, Tobi immigrated to Canada.
Fiona invites Tobi.
Tobi agreed to move to Canada.
Programming helped Tobi move in with his girlfriend.
Tobi was an excellent programmer, therefore what he did in Germany could be done anywhere.
He worked remotely for his German employer in Canada.
Tobi struggled with remote work.
Due to poor communication.
No slack, so he used email.
Programmers had trouble emailing.
Tobi's startup was developing a browser.
After the dot-com crash, individuals left that startup.
It ended.
Tobi didn't intend to work for any major corporations.
Tobi left his startup.
He believed he had important skills for any huge corporation.
He refused to join a huge corporation.
Because of Siemens.
Tobi learned to write professional code and about himself while working at Siemens in Germany.
Siemens culture was odd.
Employees were distrustful.
Siemens' rigorous dress code implies that the corporation doesn't trust employees' attire.
It wasn't Tobi's place.
“There was so much bad with it that it just felt wrong…20-year-old Tobi would not have a career there.”
Focused only on snowboarding
Tobi lived in Ottawa with his girlfriend.
Canada is frigid in winter.
Ottawa's winters last.
Almost half a year.
Tobi wanted to do something worthwhile now.
So he snowboarded.
Tobi began snowboarding seriously.
He sought every snowboarding knowledge.
He researched the greatest snowboarding gear first.
He created big spreadsheets for snowboard-making technologies.
Tobi grew interested in selling snowboards while researching.
He intended to sell snowboards online.
He had no choice but to start his own company.
A small local company offered Tobi a job.
Interested.
He must sign papers to join the local company.
He needed a work permit when he signed the documents.
Tobi had no work permit.
He was allowed to stay in Canada while applying for permanent residency.
“I wasn’t illegal in the country, but my state didn’t give me a work permit. I talked to a lawyer and he told me it’s going to take a while until I get a permanent residency.”
Tobi's lawyer told him he cannot get a work visa without permanent residence.
His lawyer said something else intriguing.
Tobis lawyer advised him to start a business.
Tobi declined this local company's job offer because of this.
Tobi considered opening an internet store with his technical skills.
He sold snowboards online.
“I was thinking of setting up an online store software because I figured that would exist and use it as a way to sell snowboards…make money while snowboarding and hopefully have a good life.”
What brought Tobi and his co-founder together, and how did he support Tobi?
Tobi lived with his girlfriend's parents.
In Ottawa, Tobi encounters Scott Lake.
Scott was Tobis girlfriend's family friend and worked for Tobi's future employer.
Scott and Tobi snowboarded.
Tobi pitched Scott his snowboard sales software idea.
Scott liked the idea.
They planned a business together.
“I was looking after the technology and Scott was dealing with the business side…It was Scott who ended up developing relationships with vendors and doing all the business set-up.”
Issues they ran into when attempting to launch their business online
Neither could afford a long-term lease.
That prompted their online business idea.
They would open a store.
Tobi anticipated opening an internet store in a week.
Tobi seeks open-source software.
Most existing software was pricey.
Tobi and Scott couldn't afford pricey software.
“In 2004, I was sitting in front of my computer absolutely stunned realising that we hadn’t figured out how to create software for online stores.”
They required software to:
to upload snowboard images to the website.
people to look up the types of snowboards that were offered on the website. There must be a search feature in the software.
Online users transmit payments, and the merchant must receive them.
notifying vendors of the recently received order.
No online selling software existed at the time.
Online credit card payments were difficult.
How did they advance the software while keeping expenses down?
Tobi and Scott needed money to start selling snowboards.
Tobi and Scott funded their firm with savings.
“We both put money into the company…I think the capital we had was around CAD 20,000(Canadian Dollars).”
Despite investing their savings.
They minimized costs.
They tried to conserve.
No office rental.
They worked in several coffee shops.
Tobi lived rent-free at his girlfriend's parents.
He installed software in coffee cafes.
How were the software issues handled?
Tobi found no online snowboard sales software.
Two choices remained:
Change your mind and try something else.
Use his programming expertise to produce something that will aid in the expansion of this company.
Tobi knew he was the sole programmer working on such a project from the start.
“I had this realisation that I’m going to be the only programmer who has ever worked on this, so I don’t have to choose something that lots of people know. I can choose just the best tool for the job…There is been this programming language called Ruby which I just absolutely loved ”
Ruby was open-source and only had Japanese documentation.
Latin is the source code.
Tobi used Ruby twice.
He assumed he could pick the tool this time.
Why not build with Ruby?
How did they find their first time operating a business?
Tobi writes applications in Ruby.
He wrote the initial software version in 2.5 months.
Tobi and Scott founded Snowdevil to sell snowboards.
Tobi coded for 16 hours a day.
His lifestyle was unhealthy.
He enjoyed pizza and coke.
“I would never recommend this to anyone, but at the time there was nothing more interesting to me in the world.”
Their initial purchase and encounter with it
Tobi worked in cafes then.
“I was working in a coffee shop at this time and I remember everything about that day…At some time, while I was writing the software, I had to type the email that the software would send to tell me about the order.”
Tobi recalls everything.
He checked the order on his laptop at the coffee shop.
Pennsylvanian ordered snowboard.
Tobi walked home and called Scott. Tobi told Scott their first order.
They loved the order.
How were people made aware about Snowdevil?
2004 was very different.
Tobi and Scott attempted simple website advertising.
Google AdWords was new.
Ad clicks cost 20 cents.
Online snowboard stores were scarce at the time.
Google ads propelled the snowdevil brand.
Snowdevil prospered.
They swiftly recouped their original investment in the snowboard business because to its high profit margin.
Tobi and Scott struggled with inventories.
“Snowboards had really good profit margins…Our biggest problem was keeping inventory and getting it back…We were out of stock all the time.”
Selling snowboards returned their investment and saved them money.
They did not appoint a business manager.
They accomplished everything alone.
Sales dipped in the spring, but something magical happened.
Spring sales plummeted.
They considered stocking different boards.
They naturally wanted to add boards and grow the business.
However, magic occurred.
Tobi coded and improved software while running Snowdevil.
He modified software constantly. He wanted speedier software.
He experimented to make the software more resilient.
Tobi received emails requesting the Snowdevil license.
They intended to create something similar.
“I didn’t stop programming, I was just like Ok now let me try things, let me make it faster and try different approaches…Increasingly I got people sending me emails and asking me If I would like to licence snowdevil to them. People wanted to start something similar.”
Software or skateboards, your choice
Scott and Tobi had to choose a hobby in 2005.
They might sell alternative boards or use software.
The software was a no-brainer from demand.
Daniel Weinand is invited to join Tobi's business.
Tobis German best friend is Daniel.
Tobi and Scott chose to use the software.
Tobi and Scott kept the software service.
Tobi called Daniel to invite him to Canada to collaborate.
Scott and Tobi had quit snowboarding until then.
How was Shopify launched, and whence did the name come from?
The three chose Shopify.
Named from two words.
First:
Shop
Final part:
Simplify
Shopify
Shopify's crew has always had one goal:
creating software that would make it simple and easy for people to launch online storefronts.
Launched Shopify after raising money for the first time.
Shopify began fundraising in 2005.
First, they borrowed from family and friends.
They needed roughly $200k to run the company efficiently.
$200k was a lot then.
When questioned why they require so much money. Tobi told them to trust him with their goals. The team raised seed money from family and friends.
Shopify.com has a landing page. A demo of their goal was on the landing page.
In 2006, Shopify had about 4,000 emails.
Shopify rented an Ottawa office.
“We sent a blast of emails…Some people signed up just to try it out, which was exciting.”
How things developed after Scott left the company
Shopify co-founder Scott Lake left in 2008.
Scott was CEO.
“He(Scott) realized at some point that where the software industry was going, most of the people who were the CEOs were actually the highly technical person on the founding team.”
Scott leaving the company worried Tobi.
Tobis worried about finding a new CEO.
To Tobi:
A great VC will have the network to identify the perfect CEO for your firm.
Tobi started visiting Silicon Valley to meet with venture capitalists to recruit a CEO.
Initially visiting Silicon Valley
Tobi came to Silicon Valley to start a 20-person company.
This company creates eCommerce store software.
Tobi never wanted a big corporation. He desired a fulfilling existence.
“I stayed in a hostel in the Bay Area. I had one roommate who was also a computer programmer. I bought a bicycle on Craiglist. I was there for a week, but ended up staying two and a half weeks.”
Tobi arrived unprepared.
When venture capitalists asked him business questions.
He answered few queries.
Tobi didn't comprehend VC meetings' terminology.
He wrote the terms down and looked them up.
Some were fascinated after he couldn't answer all these queries.
“I ended up getting the kind of term sheets people dream about…All the offers were conditional on moving our company to Silicon Valley.”
Canada received Tobi.
He wanted to consult his team before deciding. Shopify had five employees at the time.
2008.
A global recession greeted Tobi in Canada. The recession hurt the market.
His term sheets were useless.
The economic downturn in the world provided Shopify with a fantastic opportunity.
The global recession caused significant job losses.
Fired employees had several ideas.
They wanted online stores.
Entrepreneurship was desired. They wanted to quit work.
People took risks and tried new things during the global slump.
Shopify subscribers skyrocketed during the recession.
“In 2009, the company reached neutral cash flow for the first time…We were in a position to think about long-term investments, such as infrastructure projects.”
Then, Tobi Lutke became CEO.
How did Tobi perform as the company's CEO?
“I wasn’t good. My team was very patient with me, but I had a lot to learn…It’s a very subtle job.”
2009–2010.
Tobi limited the company's potential.
He deliberately restrained company growth.
Tobi had one costly problem:
Whether Shopify is a venture or a lifestyle business.
The company's annual revenue approached $1 million.
Tobi battled with the firm and himself despite good revenue.
His wife was supportive, but the responsibility was crushing him.
“It’s a crushing responsibility…People had families and kids…I just couldn’t believe what was going on…My father-in-law gave me money to cover the payroll and it was his life-saving.”
Throughout this trip, everyone supported Tobi.
They believed it.
$7 million in donations received
Tobi couldn't decide if this was a lifestyle or a business.
Shopify struggled with marketing then.
Later, Tobi tried 5 marketing methods.
He told himself that if any marketing method greatly increased their growth, he would call it a venture, otherwise a lifestyle.
The Shopify crew brainstormed and voted on marketing concepts.
Tested.
“Every single idea worked…We did Adwords, published a book on the concept, sponsored a podcast and all the ones we tracked worked.”
To Silicon Valley once more
Shopify marketing concepts worked once.
Tobi returned to Silicon Valley to pitch investors.
He raised $7 million, valuing Shopify at $25 million.
All investors had board seats.
“I find it very helpful…I always had a fantastic relationship with everyone who’s invested in my company…I told them straight that I am not going to pretend I know things, I want you to help me.”
Tobi developed skills via running Shopify.
Shopify had 20 employees.
Leaving his wife's parents' home
Tobi left his wife's parents in 2014.
Tobi had a child.
Shopify has 80,000 customers and 300 staff in 2013.
Public offering in 2015
Shopify investors went public in 2015.
Shopify powers 4.1 million e-Commerce sites.
Shopify stores are 65% US-based.
It is currently valued at $48 billion.

Francesca Furchtgott
3 years ago
Giving customers what they want or betraying the values of the brand?
A J.Crew collaboration for fashion label Eveliina Vintage is not a paradox; it is a solution.

Eveliina Vintage's capsule collection debuted yesterday at J.Crew. This J.Crew partnership stopped me in my tracks.
Eveliina Vintage sells vintage goods. Eeva Musacchia founded the shop in Finland in the 1970s. It's recognized for its one-of-a-kind slip dresses from the 1930s and 1940s.
I wondered why a vintage brand would partner with a mass shop. Fast fashion against vintage shopping? Will Eveliina Vintages customers be turned off?
But Eveliina Vintages customers don't care about sustainability. They want Eveliina's Instagram look. Eveliina Vintage collaborated with J.Crew to give customers what they wanted: more Eveliina at a lower price.
Vintage: A Fashion Option That Is Eco-Conscious
Secondhand shopping is a trendy response to quick fashion. J.Crew releases hundreds of styles annually. Waste and environmental damage have been criticized. A pair of jeans requires 1,800 gallons of water. J.Crew's limited-time deals promote more purchases. J.Crew items are likely among those Americans wear 7 times before discarding.
Consumers and designers have emphasized sustainability in recent years. Stella McCartney and Eileen Fisher are popular eco-friendly brands. They've also flocked to ThredUp and similar sites.
Gap, Levis, and Allbirds have listened to consumer requests. They promote recycling, ethical sourcing, and secondhand shopping.
Secondhand shoppers feel good about reusing and recycling clothing that might have ended up in a landfill.
Eco-conscious fashionistas shop vintage. These shoppers enjoy the thrill of the hunt (that limited-edition Chanel bag!) and showing off a unique piece (nobody will have my look!). They also reduce their environmental impact.
Is Eveliina Vintage capitalizing on an aesthetic or is it a sustainable brand?
Eveliina Vintage emphasizes environmental responsibility. Vogue's Amanda Musacchia emphasized sustainability. Amanda, founder Eeva's daughter, is a company leader.
But Eveliina's press message doesn't address sustainability, unlike Instagram. Scarcity and fame rule.
Eveliina Vintages Instagram has see-through dresses and lace-trimmed slip dresses. Celebrities and influencers are often photographed in Eveliina's apparel, which has 53,000+ followers. Vogue appreciates Eveliina's style. Multiple publications discuss Alexa Chung's Eveliina dress.
Eveliina Vintage markets its one-of-a-kind goods. It teases future content, encouraging visitors to return. Scarcity drives demand and raises clothing prices. One dress is $1,600+, but most are $500-$1,000.
The catch: Eveliina can't monetize its expanding popularity due to exorbitant prices and limited quantity. Why?
Most people struggle to pay for their clothing. But Eveliina Vintage lacks those more affordable entry-level products, in contrast to other luxury labels that sell accessories or perfume.
Many people have trouble fitting into their clothing. The bodies of most women in the past were different from those for which vintage clothing was designed. Each Eveliina dress's specific measurements are mentioned alongside it. Be careful, you can fall in love with an ill-fitting dress.
No matter how many people can afford it and fit into it, there is only one item to sell. To get the item before someone else does, those people must be on the Eveliina Vintage website as soon as it becomes available.
A Way for Eveliina Vintage to Make Money (and Expand) with J.Crew Its following
Eveliina Vintages' cooperation with J.Crew makes commercial sense.
This partnership spreads Eveliina's style. Slightly better pricing The $390 outfits have multicolored slips and gauzy cotton gowns. Sizes range from 00 to 24, which is wider than vintage racks.
Eveliina Vintage customers like the combination. Excited comments flood the brand's Instagram launch post. Nobody is mocking the 50-year-old vintage brand's fast-fashion partnership.
Vintage may be a sustainable fashion trend, but that's not why Eveliina's clients love the brand. They only care about the old look.
And that is a tale as old as fashion.