

More on Technology

Shawn Mordecai
3 years ago
The Apple iPhone 14 Pill is Easier to Swallow
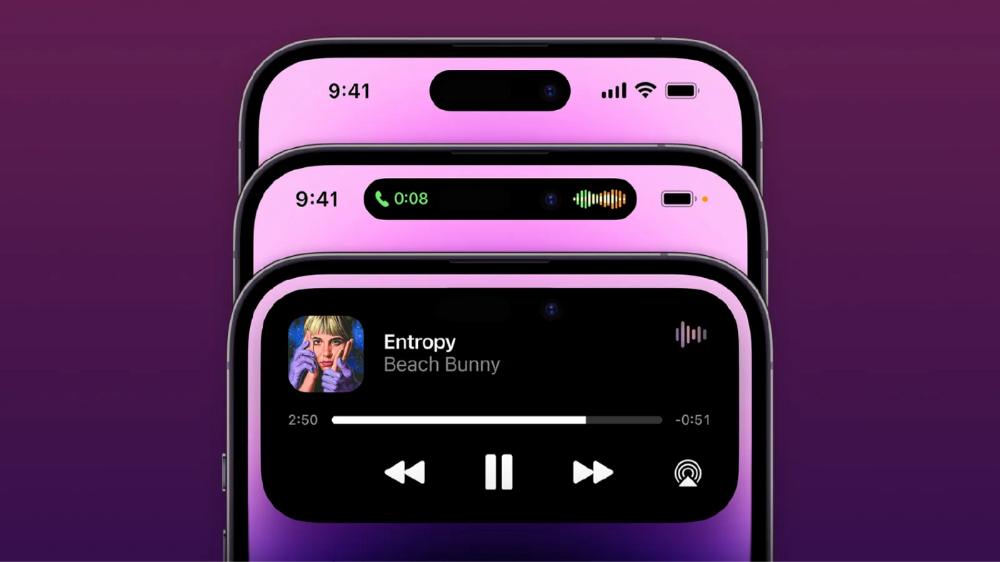
Is iPhone's Dynamic Island invention or a marketing ploy?
First of all, why the notch?
When Apple debuted the iPhone X with the notch, some were surprised, confused, and amused by the goof. Let the Brits keep the new meaning of top-notch.
Apple removed the bottom home button to enhance screen space. The tides couldn't overtake part of the top. This section contained sensors, a speaker, a microphone, and cameras for facial recognition. A town resisted Apple's new iPhone design.
From iPhone X to 13, the notch has gotten smaller. We expected this as technology and engineering progressed, but we hated the notch. Apple approved. They attached it to their other gadgets.
Apple accepted, owned, and ran with the iPhone notch, it has become iconic (or infamous); and that’s intentional.
The Island Where Apple Is
Apple needs to separate itself, but they know how to do it well. The iPhone 14 Pro finally has us oohing and aahing. Life-changing, not just higher pixel density or longer battery.
Dynamic Island turned a visual differentiation into great usefulness, which may not be life-changing. Apple always welcomes the controversy, whether it's $700 for iMac wheels, no charging block with a new phone, or removing the headphone jack.
Apple knows its customers will be loyal, even if they're irritated. Their odd design choices often cause controversy. It's calculated that people blog, review, and criticize Apple's products. We accept what works for them.
While the competition zigs, Apple zags. Sometimes they zag too hard and smash into a wall, but we talk about it anyways, and that’s great publicity for them.
Getting Dependent on the drug
The notch became a crop. Dynamic Island's design is helpful, intuitive, elegant, and useful. It increases iPhone usability, productivity (slightly), and joy. No longer unsightly.
The medication helps with multitasking. It's a compact version of the iPhone's Live Activities lock screen function. Dynamic Island enhances apps and activities with visual effects and animations whether you engage with it or not. As you use the pill, its usefulness lessens. It lowers user notifications and consolidates them with live and permanent feeds, delivering quick app statuses. It uses the black pixels on the iPhone 14's display, which looked like a poor haircut.

The pill may be a gimmick to entice customers to use more Apple products and services. Apps may promote to their users like a live billboard.
Be prepared to get a huge dose of Dynamic Island’s “pill” like you never had before with the notch. It might become so satisfying and addicting to use, that every interaction with it will become habit-forming, and you’re going to forget that it ever existed.
WARNING: A Few Potential Side Effects
Vision blurred Dynamic Island's proximity to the front-facing camera may leave behind grease that blurs photos. Before taking a selfie, wipe the camera clean.
Strained thumb To fully use Dynamic Island, extend your thumb's reach 6.7 inches beyond your typical, comfortable range.
Happiness, contentment The Dynamic Island may enhance Endorphins and Dopamine. Multitasking, interactions, animations, and haptic feedback make you want to use this function again and again.
Motion-sickness Dynamic Island's motions and effects may make some people dizzy. If you can disable animations, you can avoid motion sickness.
I'm not a doctor, therefore they aren't established adverse effects.
Does Dynamic Island Include Multiple Tasks?
Dynamic Islands is a placebo for multitasking. Apple might have compromised on iPhone multitasking. It won't make you super productive, but it's a step up.

iPhone is primarily for personal use, like watching videos, messaging friends, sending money to friends, calling friends about the money you were supposed to send them, taking 50 photos of the same leaf, investing in crypto, driving for Uber because you lost all your money investing in crypto, listening to music and hailing an Uber from a deserted crop field because while you were driving for Uber your passenger stole your car and left you stranded, so you used Apple’s new SOS satellite feature to message your friend, who still didn’t receive their money, to hail you an Uber; now you owe them more money… karma?
We won't be watching videos on iPhones while perusing 10,000-row spreadsheets anytime soon. True multitasking and productivity aren't priorities for Apple's iPhone. Apple doesn't to preserve the iPhone's experience. Like why there's no iPad calculator. Apple doesn't want iPad users to do math, but isn't essential for productivity?
Digressing.
Apple will block certain functions so you must buy and use their gadgets and services, immersing yourself in their ecosystem and dictating how to use their goods.
Dynamic Island is a poor man’s multi-task for iPhone, and that’s fine it works for most iPhone users. For substantial productivity Apple prefers you to get an iPad or a MacBook. That’s part of the reason for restrictive features on certain Apple devices, but sometimes it’s based on principles to preserve the integrity of the product, according to Apple’s definition.
Is Apple using deception?
Dynamic Island may be distracting you from a design decision. The answer is kind of. Elegant distraction
When you pull down a smartphone webpage to refresh it or minimize an app, you get seamless animations. It's not simply because it appears better; it's due to iPhone and smartphone processing speeds. Such limits reduce the system's response to your activity, slowing the experience. Designers and developers use animations and effects to distract us from the time lag (most of the time) and sometimes because it looks cooler and smoother.
Dynamic Island makes apps more useable and interactive. It shows system states visually. Turn signal audio and visual cues, voice assistance, physical and digital haptic feedbacks, heads-up displays, fuel and battery level gauges, and gear shift indicators helped us overcome vehicle design problems.
Dynamic Island is a wonderfully delightful (and temporary) solution to a design “problem” until Apple or other companies can figure out a way to sink the cameras under the smartphone screen.

Apple Has Returned to Being an Innovative & Exciting Company
Now Apple's products are exciting. Next, bring back real Apple events, not pre-recorded demos.
Dynamic Island integrates hardware and software. What will this new tech do? How would this affect device use? Or is it just hype?
Dynamic Island may be an insignificant improvement to the iPhone, but it sure is promising for the future of bridging the human and computer interaction gap.

Nitin Sharma
3 years ago
The result of my side-hustle blog post with ChatGPT is remarkable.
It's free now.

Most content writers—including me—write about side hustles because they do well.
I wrote several articles on a profitable programming side hustle.
Later, I learnt about AI content-generating platforms like Jasper.ai and Copy.ai, which I thought were terrible because they required subscriptions and had bad content. Even I dislike automatic online posting.
Since ChatGPT is becoming more popular, I tried it. It's free now.
Note: I wasn’t compensated to write this piece by this tool. In other words, I don’t receive any payment from their founders. There is no affiliate link, and right now it is free to use. Also, ChatGPT can do a lot more than what I ever did.
Begin.
OpenAI account registration requires visiting the website (if you don’t have one). Just write anything into the chatbot and get a response.
First, I wrote about the top 10 2023 side businesses.
This came in seconds.
2023 is shaping up to be a year of growth and opportunity for entrepreneurs and side hustlers. With the rise of remote work and the growing gig economy, there are many income streams to consider launching in the coming year. Here are the top 10 income streams to launch in 2023:
Virtual Assistant — The demand for virtual assistants is on the rise as more businesses move online. As a virtual assistant, you can offer administrative, technical, or creative services to clients remotely.
Online Tutoring — If you have expertise in a particular subject, consider becoming an online tutor. There are many platforms that connect tutors with students looking for help with their studies.
Freelance Writing — If you have a knack for writing, consider becoming a freelance writer. You can offer your services to businesses, bloggers, and individuals looking for content for their websites or social media platforms.
Graphic Design — If you have a talent for design, consider starting a graphic design side hustle. You can create logos, banners, and other visual content for businesses and individuals.
Social Media Management — Many businesses are looking for help with managing their social media accounts. As a social media manager, you can help businesses create and execute social media strategies to reach their target audience.
Dropshipping — Dropshipping is a business model where you sell products without actually holding any inventory. You can partner with suppliers and ship the products directly to the customer on behalf of the business.
Pet Sitting — If you love animals, consider starting a pet-sitting side hustle. You can offer your services to pet owners who need someone to take care of their pets while they are away.
Home Cleaning — With busy schedules, many people are looking for help with cleaning their homes. As a home cleaning service provider, you can offer your services to help keep homes tidy and organized.
Event Planning — If you have a talent for organization and planning, consider starting an event planning side hustle. You can offer your services to help plan and execute events for businesses and individuals.
Online Teaching — With the rise of online education, there is a growing demand for online teachers. If you have expertise in a particular subject, consider becoming an online teacher and offer your services to students looking for personalized instruction.
In conclusion, 2023 is shaping up to be a great year for launching new income streams. Whether you are looking to start a virtual assistant business, become an online tutor, or offer home cleaning services, there are many opportunities to turn your skills and expertise into a profitable side hustle.
Better than most online side hustle posts, right?
Write about the top 10 programming side hustles to start in 2023.
I got this.
If you are a programmer looking to start a side hustle, 2023 is the perfect time to launch your own business. With the growing demand for software and app development, there are many opportunities for programmers to turn their skills into a profitable side hustle. Here are the top 10 programming side hustles to start in 2023:
App Development — With the rise of smartphones and tablets, there is a growing demand for app development. You can offer your services to businesses and individuals looking to create custom apps for their needs.
Website Development — Many businesses and individuals are looking for help with creating and maintaining their websites. As a website developer, you can offer your services to help design, build, and manage websites for your clients.
Software Development — If you have expertise in a particular programming language, consider starting a software development side hustle. You can offer your services to businesses and individuals looking to create custom software solutions for their needs.
Game Development — The gaming industry is thriving, and there is a growing demand for game development. If you have experience in game development, you can offer your services to businesses and individuals looking to create custom games.
Data Analysis — With the rise of big data, there is a growing demand for data analysts. As a data analyst, you can offer your services to businesses and individuals looking to make sense of their data and gain insights from it.
Machine Learning — Machine learning is a rapidly growing field, and there is a growing demand for machine learning experts. If you have experience in machine learning, you can offer your services to businesses and individuals looking to develop custom machine learning solutions.
Cloud Computing — With the rise of cloud computing, there is a growing demand for cloud experts. If you have experience in cloud computing, you can offer your services to businesses and individuals looking to migrate their applications and data to the cloud.
Blockchain Development — Blockchain technology is gaining popularity, and there is a growing demand for blockchain developers. If you have experience in blockchain development, you can offer your services to businesses and individuals looking to develop custom blockchain solutions.
Artificial Intelligence — Artificial intelligence is a rapidly growing field, and there is a growing demand for AI experts. If you have experience in artificial intelligence, you can offer your services to businesses and individuals looking to develop custom AI solutions.
Virtual Reality — Virtual reality is an exciting and emerging technology, and there is a growing demand for VR developers. If you have experience in VR development, you can offer your services to businesses and individuals looking to create custom VR experiences.
In conclusion, 2023 is a great time to start a programming side hustle. Whether you are interested in app development, website development, or machine learning, there are many opportunities for programmers to turn their skills into a profitable business.
These two blogs show that AI can simplify blog authoring.
I asked some tough programming questions, and most were suitable.
The content may occasionally not be what we want, but it will almost always be very helpful to you.
Enjoy.

Ossiana Tepfenhart
3 years ago
Has anyone noticed what an absolute shitshow LinkedIn is?
After viewing its insanity, I had to leave this platform.

I joined LinkedIn recently. That's how I aim to increase my readership and gain recognition. LinkedIn's premise appealed to me: a Facebook-like platform for professional networking.
I don't use Facebook since it's full of propaganda. It seems like a professional, apolitical space, right?
I expected people to:
be more formal and respectful than on Facebook.
Talk about the inclusiveness of the workplace. Studies consistently demonstrate that inclusive, progressive workplaces outperform those that adhere to established practices.
Talk about business in their industry. Yep. I wanted to read articles with advice on how to write better and reach a wider audience.
Oh, sh*t. I hadn't anticipated that.

After posting and reading about inclusivity and pro-choice, I was startled by how many professionals acted unprofessionally. I've seen:
Men have approached me in the DMs in a really aggressive manner. Yikes. huge yikes Not at all professional.
I've heard pro-choice women referred to as infant killers by many people. If I were the CEO of a company and I witnessed one of my employees acting that poorly, I would immediately fire them.
Many posts are anti-LGBTQIA+, as I've noticed. a lot, like, a lot. Some are subtly stating that the world doesn't need to know, while others are openly making fun of transgender persons like myself.
Several medical professionals were posting explicitly racist comments. Even if you are as white as a sheet like me, you should be alarmed by this. Who's to guarantee a patient who is black won't unintentionally die?
I won't even get into how many men in STEM I observed pushing for the exclusion of women from their fields. I shouldn't be surprised considering the majority of those men I've encountered have a passionate dislike for women, but goddamn, dude.
Many people appear entirely too at ease displaying their bigotry on their professional profiles.

As a white female, I'm always shocked by people's open hostility. Professional environments are very important.
I don't know if this is still true (people seem too politicized to care), but if I heard many of these statements in person, I'd suppose they feel ashamed. Really.
Are you not ashamed of being so mean? Are you so weak that competing with others terrifies you? Isn't this embarrassing?
LinkedIn isn't great at censoring offensive comments. These people aren't getting warnings. So they were safe while others were unsafe.
The CEO in me would want to know if I had placed a bigot on my staff.

I always wondered if people's employers knew about their online behavior. If they know how horrible they appear, they don't care.
As a manager, I was picky about hiring. Obviously. In most industries, it costs $1,000 or more to hire a full-time employee, so be sure it pays off.
Companies that embrace diversity and tolerance (and are intolerant of intolerance) are more profitable, likely to recruit top personnel, and successful.
People avoid businesses that alienate them. That's why I don't eat at Chic-Fil-A and why folks avoid MyPillow. Being inclusive is good business.
CEOs are harmed by online bigots. Image is an issue. If you're a business owner, you can fire staff who don't help you.
On the one hand, I'm delighted it makes it simpler to identify those with whom not to do business.

Don’t get me wrong. I'm glad I know who to avoid when hiring, getting references, or searching for a job. When people are bad, it saves me time.
What's up with professionalism?
Really. I need to know. I've crossed the boundary between acceptable and unacceptable behavior, but never on a professional platform. I got in trouble for not wearing bras even though it's not part of my gender expression.
If I behaved like that at my last two office jobs, my supervisors would have fired me immediately. Some of the behavior I've seen is so outrageous, I can't believe these people have employment. Some are even leaders.
Like…how? Is hatred now normalized?
Please pay attention whether you're seeking for a job or even simply a side gig.

Do not add to the tragedy that LinkedIn comments can be, or at least don't make uninformed comments. Even if you weren't banned, the site may still bite you.
Recruiters can and do look at your activity. Your writing goes on your résumé. The wrong comment might lose you a job.
Recruiters and CEOs might reject candidates whose principles contradict with their corporate culture. Bigotry will get you banned from many companies, especially if others report you.
If you want a high-paying job, avoid being a LinkedIn asshole. People care even if you think no one does. Before speaking, ponder. Is this how you want to be perceived?
Better advice:
If your politics might turn off an employer, stop posting about them online and ask yourself why you hold such objectionable ideas.
You might also like

Joseph Mavericks
3 years ago
The world's 36th richest man uses a 5-step system to get what he wants.
Ray Dalio's super-effective roadmap

Ray Dalio's $22 billion net worth ranks him 36th globally. From 1975 to 2011, he built the world's most successful hedge fund, never losing more than 4% from 1991 to 2020. (and only doing so during 3 calendar years).
Dalio describes a 5-step process in his best-selling book Principles. It's the playbook he's used to build his hedge fund, beat the markets, and face personal challenges.
This 5-step system is so valuable and well-explained that I didn't edit or change anything; I only added my own insights in the parts I found most relevant and/or relatable as a young entrepreneur. The system's overview:
Have clear goals
Identify and don’t tolerate problems
Diagnose problems to get at their root causes
Design plans that will get you around those problems
Do what is necessary to push through the plans to get results
If you follow these 5 steps in a virtuous loop, you'll almost always see results. Repeat the process for each goal you have.
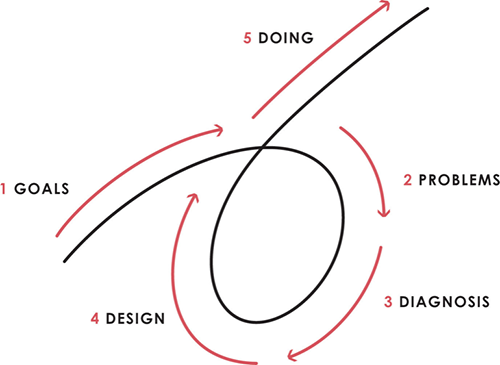
1. Have clear goals
a) Prioritize: You can have almost anything, but not everything.
I started and never launched dozens of projects for 10 years because I was scattered. I opened a t-shirt store, traded algorithms, sold art on Instagram, painted skateboards, and tinkered with electronics. I decided to try blogging for 6 months to see where it took me. Still going after 3 years.
b) Don’t confuse goals with desires.
A goal inspires you to act. Unreasonable desires prevent you from achieving your goals.
c) Reconcile your goals and desires to decide what you want.
d) Don't confuse success with its trappings.
e) Never dismiss a goal as unattainable.
Always one path is best. Your perception of what's possible depends on what you know now. I never thought I'd make money writing online so quickly, and now I see a whole new horizon of business opportunities I didn't know about before.
f) Expectations create abilities.
Don't limit your abilities. More you strive, the more you'll achieve.
g) Flexibility and self-accountability can almost guarantee success.
Flexible people accept what reality or others teach them. Self-accountability is the ability to recognize your mistakes and be more creative, flexible, and determined.
h) Handling setbacks well is as important as moving forward.
Learn when to minimize losses and when to let go and move on.
2. Don't ignore problems
a) See painful problems as improvement opportunities.
Every problem, painful situation, and challenge is an opportunity. Read The Art of Happiness for more.
b) Don't avoid problems because of harsh realities.
Recognizing your weaknesses isn't the same as giving in. It's the first step in overcoming them.
c) Specify your issues.
There is no "one-size-fits-all" solution.
d) Don’t mistake a cause of a problem with the real problem.
"I can't sleep" is a cause, not a problem. "I'm underperforming" could be a problem.
e) Separate big from small problems.
You have limited time and energy, so focus on the biggest problems.
f) Don't ignore a problem.
Identifying a problem and tolerating it is like not identifying it.
3. Identify problems' root causes
a) Decide "what to do" after assessing "what is."
"A good diagnosis takes 15 to 60 minutes, depending on its accuracy and complexity. [...] Like principles, root causes recur in different situations.
b) Separate proximate and root causes.
"You can only solve problems by removing their root causes, and to do that, you must distinguish symptoms from disease."
c) Knowing someone's (or your own) personality can help you predict their behavior.
4. Design plans that will get you around the problems
a) Retrace your steps.
Analyze your past to determine your future.
b) Consider your problem a machine's output.
Consider how to improve your machine. It's a game then.
c) There are many ways to reach your goals.
Find a solution.
d) Visualize who will do what in your plan like a movie script.
Consider your movie's actors and script's turning points, then act accordingly. The game continues.
e) Document your plan so others can judge your progress.
Accountability boosts success.
f) Know that a good plan doesn't take much time.
The execution is usually the hardest part, but most people either don't have a plan or keep changing it. Don't drive while building the car. Build it first, because it'll be bumpy.
5. Do what is necessary to push through the plans to get results
a) Great planners without execution fail.
Life is won with more than just planning. Similarly, practice without talent beats talent without practice.
b) Work ethic is undervalued.
Hyper-productivity is praised in corporate America, even if it leads nowhere. To get things done, use checklists, fewer emails, and more desk time.
c) Set clear metrics to ensure plan adherence.
I've written about the OKR strategy for organizations with multiple people here. If you're on your own, I recommend the Wheel of Life approach. Both systems start with goals and tasks to achieve them. Then start executing on a realistic timeline.
If you find solutions, weaknesses don't matter.
Everyone's weak. You, me, Gates, Dalio, even Musk. Nobody will be great at all 5 steps of the system because no one can think in all the ways required. Some are good at analyzing and diagnosing but bad at executing. Some are good planners but poor communicators. Others lack self-discipline.
Stay humble and ask for help when needed. Nobody has ever succeeded 100% on their own, without anyone else's help. That's the paradox of individual success: teamwork is the only way to get there.
Most people won't have the skills to execute even the best plan. You can get missing skills in two ways:
Self-taught (time-consuming)
Others' (requires humility) light
On knowing what to do with your life
“Some people have good mental maps and know what to do on their own. Maybe they learned them or were blessed with common sense. They have more answers than others. Others are more humble and open-minded. […] Open-mindedness and mental maps are most powerful.” — Ray Dalio
I've always known what I wanted to do, so I'm lucky. I'm almost 30 and have always had trouble executing. Good thing I never stopped experimenting, but I never committed to anything long-term. I jumped between projects. I decided 3 years ago to stick to one project for at least 6 months and haven't looked back.
Maybe you're good at staying focused and executing, but you don't know what to do. Maybe you have none of these because you haven't found your purpose. Always try new projects and talk to as many people as possible. It will give you inspiration and ideas and set you up for success.
There is almost always a way to achieve a crazy goal or idea.
Enjoy the journey, whichever path you take.

James White
3 years ago
Ray Dalio suggests reading these three books in 2022.
An inspiring reading list

I'm no billionaire or hedge-fund manager. My bank account doesn't have millions. Ray Dalio's love of reading motivates me to think differently.
Here are some books recommended by Ray Dalio. Each influenced me. Hope they'll help you.
Sapiens by Yuval Noah Harari
Page Count: 512
Rating on Goodreads: 4.39
My favorite nonfiction book.
Sapiens explores human evolution. It explains how Homo Sapiens developed from hunter-gatherers to a dominant species. Amazing!
Sapiens will teach you about human history. Yuval Noah Harari has a follow-up book on human evolution.

My favorite book quotes are:
The tendency for luxuries to turn into necessities and give rise to new obligations is one of history's few unbreakable laws.
Happiness is not dependent on material wealth, physical health, or even community. Instead, it depends on how closely subjective expectations and objective circumstances align.
The romantic comparison between today's industry, which obliterates the environment, and our forefathers, who coexisted well with nature, is unfounded. Homo sapiens held the record among all organisms for eradicating the most plant and animal species even before the Industrial Revolution. The unfortunate distinction of being the most lethal species in the history of life belongs to us.
The Power Of Habit by Charles Duhigg
Page Count: 375
Rating on Goodreads: 4.13
Great book: The Power Of Habit. It illustrates why habits are everything. The book explains how healthier habits can improve your life, career, and society.
The Power of Habit rocks. It's a great book on productivity. Its suggestions helped me build healthier behaviors (and drop bad ones).
Read ASAP!

My favorite book quotes are:
Change may not occur quickly or without difficulty. However, almost any behavior may be changed with enough time and effort.
People who exercise begin to eat better and produce more at work. They are less smokers and are more patient with friends and family. They claim to feel less anxious and use their credit cards less frequently. A fundamental habit that sparks broad change is exercise.
Habits are strong but also delicate. They may develop independently of our awareness or may be purposefully created. They frequently happen without our consent, but they can be altered by changing their constituent pieces. They have a much greater influence on how we live than we realize; in fact, they are so powerful that they cause our brains to adhere to them above all else, including common sense.
Tribe Of Mentors by Tim Ferriss
Page Count: 561
Rating on Goodreads: 4.06
Unusual book structure. It's worth reading if you want to learn from successful people.
The book is Q&A-style. Tim questions everyone. Each chapter features a different person's life-changing advice. In the book, Pressfield, Willink, Grylls, and Ravikant are interviewed.
Amazing!

My favorite book quotes are:
According to one's courage, life can either get smaller or bigger.
Don't engage in actions that you are aware are immoral. The reputation you have with yourself is all that constitutes self-esteem. Always be aware.
People mistakenly believe that focusing means accepting the task at hand. However, that is in no way what it represents. It entails rejecting the numerous other worthwhile suggestions that exist. You must choose wisely. Actually, I'm just as proud of the things we haven't accomplished as I am of what I have. Saying no to 1,000 things is what innovation is.

Yucel F. Sahan
3 years ago
How I Created the Day's Top Product on Product Hunt
In this article, I'll describe a weekend project I started to make something. It was Product Hunt's #1 of the Day, #2 Weekly, and #4 Monthly product.


How did I make Landing Page Checklist so simple? Building and launching took 3 weeks. I worked 3 hours a day max. Weekends were busy.
It's sort of a long story, so scroll to the bottom of the page to see what tools I utilized to create Landing Page Checklist :x
As a matter of fact, it all started with the startups-investments blog; Startup Bulletin, that I started writing in 2018. No, don’t worry, I won’t be going that far behind. The twitter account where I shared the blog posts of this newsletter was inactive for a looong time. I was holding this Twitter account since 2009, I couldn’t bear to destroy it. At the same time, I was thinking how to evaluate this account.
So I looked for a weekend assignment.
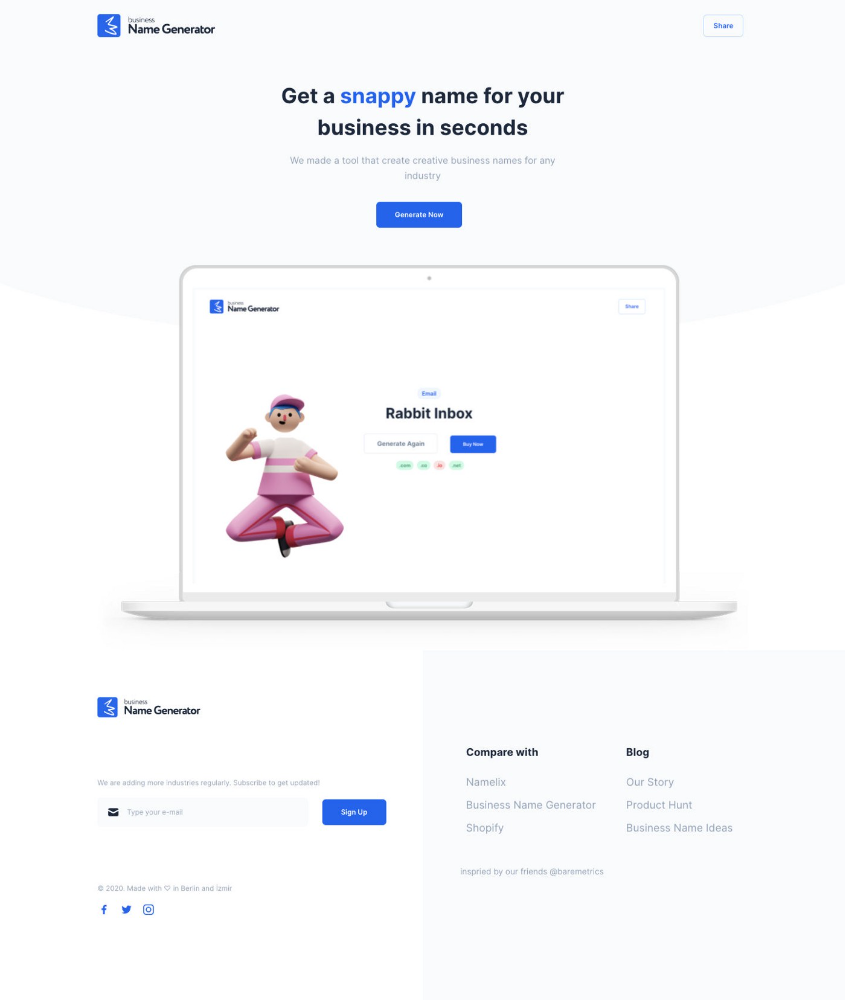
Weekend undertaking: Generate business names
Barash and I established a weekend effort to stay current. Building things helped us learn faster.
Simple. Startup Name Generator The utility generated random startup names. After market research for SEO purposes, we dubbed it Business Name Generator.
Backend developer Barash dislikes frontend work. He told me to write frontend code. Chakra UI and Tailwind CSS were recommended.
It was the first time I have heard about Tailwind CSS.
Before this project, I made mobile-web app designs in Sketch and shared them via Zeplin. I can read HTML-CSS or React code, but not write it. I didn't believe myself but followed Barash's advice.
My home page wasn't responsive when I started. Here it was:)
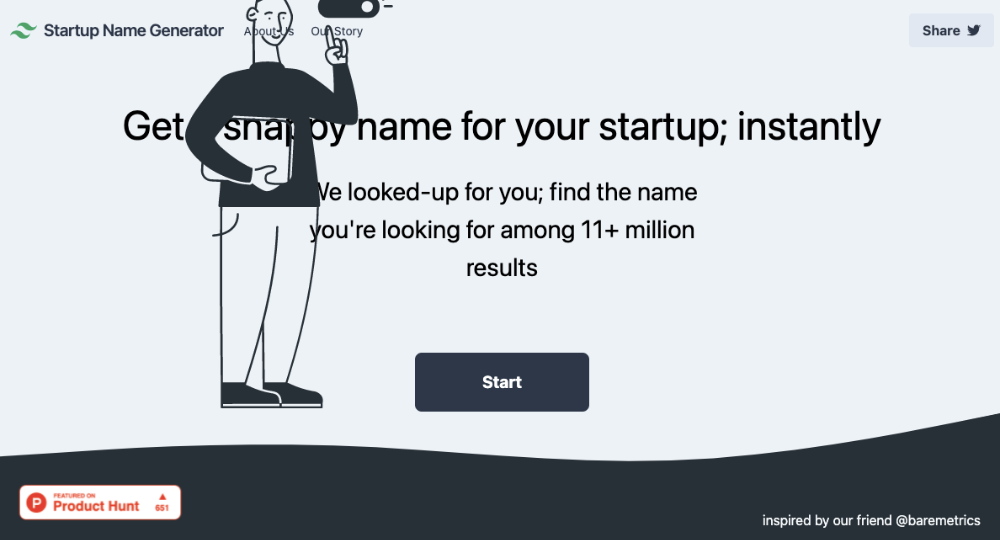
And then... Product Hunt had something I needed. Me-only! A website builder that gives you clean Tailwind CSS code and pre-made web components (like Elementor). Incredible.
I bought it right away because it was so easy to use. Best part: It's not just index.html. It includes all needed files. Like
postcss.config.js
README.md
package.json
among other things, tailwind.config.js
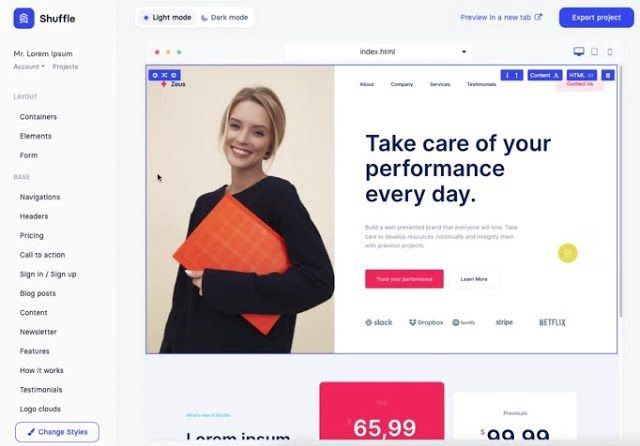
This is for non-techies.
Tailwind.build; which is Shuffle now, allows you to create and export projects for free (with limited features). You can try it by visiting their website.
After downloading the project, you can edit the text and graphics in Visual Studio (or another text editor). This HTML file can be hosted whenever.
Github is an easy way to host a landing page.
your project via Shuffle for export
your website's content, edit
Create a Gitlab, Github, or Bitbucket account.
to Github, upload your project folder.
Integrate Vercel with your Github account (or another platform below)
Allow them to guide you in steps.
Finally. If you push your code to Github using Github Desktop, you'll do it quickly and easily.
Speaking of; here are some hosting and serverless backend services for web applications and static websites for you host your landing pages for FREE!
I host landingpage.fyi on Vercel but all is fine. You can choose any platform below with peace in mind.
Vercel
Render
Netlify
After connecting your project/repo to Vercel, you don’t have to do anything on Vercel. Vercel updates your live website when you update Github Desktop. Wow!
Tails came out while I was using tailwind.build. Although it's prettier, tailwind.build is more mobile-friendly. I couldn't resist their lovely parts. Tails :)
Tails have several well-designed parts. Some components looked awful on mobile, but this bug helped me understand Tailwind CSS.
Unlike Shuffle, Tails does not include files when you export such as config.js, main.js, README.md. It just gives you the HTML code. Suffle.dev is a bit ahead in this regard and with mobile-friendly blocks if you ask me. Of course, I took advantage of both.
creativebusinessnames.co is inactive, but I'll leave a deployment link :)
Adam Wathan's YouTube videos and Tailwind's official literature helped me, but I couldn't have done it without Tails and Shuffle. These tools helped me make landing pages. I shouldn't have started over.
So began my Tailwind CSS adventure. I didn't build landingpage. I didn't plan it to be this long; sorry.
I learnt a lot while I was playing around with Shuffle and Tails Builders.
Long story short I built landingpage.fyi with the help of these tools;
Learning, building, and distribution
Shuffle (Started with a Shuffle Template)
Tails (Used components from here)
Sketch (to handle icons, logos, and .svg’s)
metatags.io (Auto Generator Meta Tags)
Vercel (Hosting)
Github Desktop (Pushing code to Github -super easy-)
Visual Studio Code (Edit my code)
Mailerlite (Capture Emails)
Jarvis / Conversion.ai (%90 of the text on website written by AI 😇 )
CookieHub (Consent Management)
That's all. A few things:
The Outcome
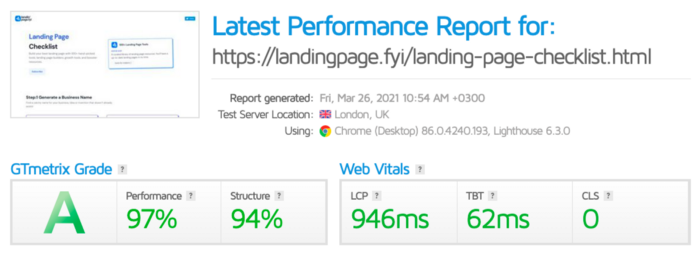
.fyi Domain: Why?

I'm often asked this.
I don't know, but I wanted to include the landing page term. Popular TLDs are gone. I saw my alternatives. brief and catchy.
CSS Tailwind Resources
I'll share project resources like Tails and Shuffle.
Beginner Tailwind (I lately enrolled in this course but haven’t completed it yet.)
Thanks for reading my blog's first post. Please share if you like it.