



More on Technology

Dmitrii Eliuseev
2 years ago
Creating Images on Your Local PC Using Stable Diffusion AI
Deep learning-based generative art is being researched. As usual, self-learning is better. Some models, like OpenAI's DALL-E 2, require registration and can only be used online, but others can be used locally, which is usually more enjoyable for curious users. I'll demonstrate the Stable Diffusion model's operation on a standard PC.

Let’s get started.
What It Does
Stable Diffusion uses numerous components:
A generative model trained to produce images is called a diffusion model. The model is incrementally improving the starting data, which is only random noise. The model has an image, and while it is being trained, the reversed process is being used to add noise to the image. Being able to reverse this procedure and create images from noise is where the true magic is (more details and samples can be found in the paper).
An internal compressed representation of a latent diffusion model, which may be altered to produce the desired images, is used (more details can be found in the paper). The capacity to fine-tune the generation process is essential because producing pictures at random is not very attractive (as we can see, for instance, in Generative Adversarial Networks).
A neural network model called CLIP (Contrastive Language-Image Pre-training) is used to translate natural language prompts into vector representations. This model, which was trained on 400,000,000 image-text pairs, enables the transformation of a text prompt into a latent space for the diffusion model in the scenario of stable diffusion (more details in that paper).
This figure shows all data flow:
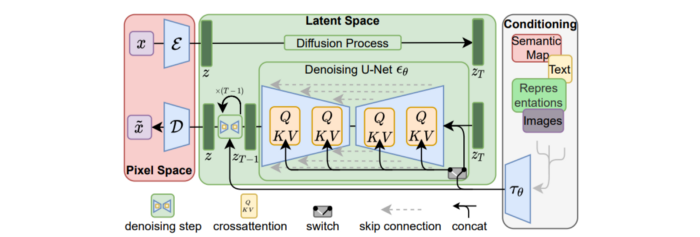
The weights file size for Stable Diffusion model v1 is 4 GB and v2 is 5 GB, making the model quite huge. The v1 model was trained on 256x256 and 512x512 LAION-5B pictures on a 4,000 GPU cluster using over 150.000 NVIDIA A100 GPU hours. The open-source pre-trained model is helpful for us. And we will.
Install
Before utilizing the Python sources for Stable Diffusion v1 on GitHub, we must install Miniconda (assuming Git and Python are already installed):
wget https://repo.anaconda.com/miniconda/Miniconda3-py39_4.12.0-Linux-x86_64.sh
chmod +x Miniconda3-py39_4.12.0-Linux-x86_64.sh
./Miniconda3-py39_4.12.0-Linux-x86_64.sh
conda update -n base -c defaults condaInstall the source and prepare the environment:
git clone https://github.com/CompVis/stable-diffusion
cd stable-diffusion
conda env create -f environment.yaml
conda activate ldm
pip3 install transformers --upgradeDownload the pre-trained model weights next. HiggingFace has the newest checkpoint sd-v14.ckpt (a download is free but registration is required). Put the file in the project folder and have fun:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Almost. The installation is complete for happy users of current GPUs with 12 GB or more VRAM. RuntimeError: CUDA out of memory will occur otherwise. Two solutions exist.
Running the optimized version
Try optimizing first. After cloning the repository and enabling the environment (as previously), we can run the command:
python3 optimizedSD/optimized_txt2img.py --prompt "hello world" --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1Stable Diffusion worked on my visual card with 8 GB RAM (alas, I did not behave well enough to get NVIDIA A100 for Christmas, so 8 GB GPU is the maximum I have;).
Running Stable Diffusion without GPU
If the GPU does not have enough RAM or is not CUDA-compatible, running the code on a CPU will be 20x slower but better than nothing. This unauthorized CPU-only branch from GitHub is easiest to obtain. We may easily edit the source code to use the latest version. It's strange that a pull request for that was made six months ago and still hasn't been approved, as the changes are simple. Readers can finish in 5 minutes:
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available at line 20 of ldm/models/diffusion/ddim.py ().
Replace if attr.device!= torch.device(cuda) with if attr.device!= torch.device(cuda) and torch.cuda.is available in line 20 of ldm/models/diffusion/plms.py ().
Replace device=cuda in lines 38, 55, 83, and 142 of ldm/modules/encoders/modules.py with device=cuda if torch.cuda.is available(), otherwise cpu.
Replace model.cuda() in scripts/txt2img.py line 28 and scripts/img2img.py line 43 with if torch.cuda.is available(): model.cuda ().
Run the script again.
Testing
Test the model. Text-to-image is the first choice. Test the command line example again:
python3 scripts/txt2img.py --prompt "hello world" --plms --ckpt sd-v1-4.ckpt --skip_grid --n_samples 1The slow generation takes 10 seconds on a GPU and 10 minutes on a CPU. Final image:

Hello world is dull and abstract. Try a brush-wielding hamster. Why? Because we can, and it's not as insane as Napoleon's cat. Another image:

Generating an image from a text prompt and another image is interesting. I made this picture in two minutes using the image editor (sorry, drawing wasn't my strong suit):
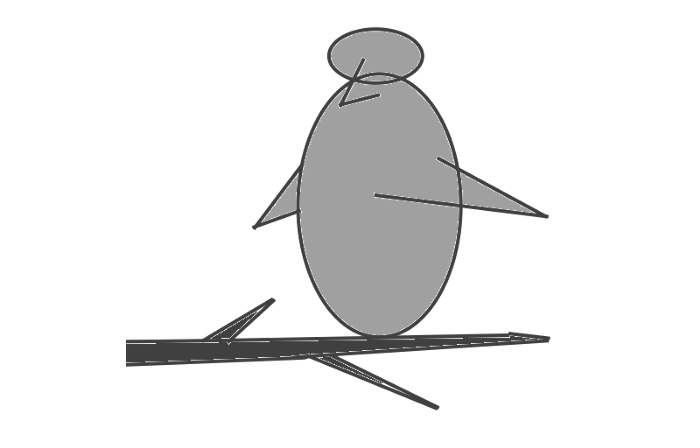
I can create an image from this drawing:
python3 scripts/img2img.py --prompt "A bird is sitting on a tree branch" --ckpt sd-v1-4.ckpt --init-img bird.png --strength 0.8It was far better than my initial drawing:

I hope readers understand and experiment.
Stable Diffusion UI
Developers love the command line, but regular users may struggle. Stable Diffusion UI projects simplify image generation and installation. Simple usage:
Unpack the ZIP after downloading it from https://github.com/cmdr2/stable-diffusion-ui/releases. Linux and Windows are compatible with Stable Diffusion UI (sorry for Mac users, but those machines are not well-suitable for heavy machine learning tasks anyway;).
Start the script.
Done. The web browser UI makes configuring various Stable Diffusion features (upscaling, filtering, etc.) easy:
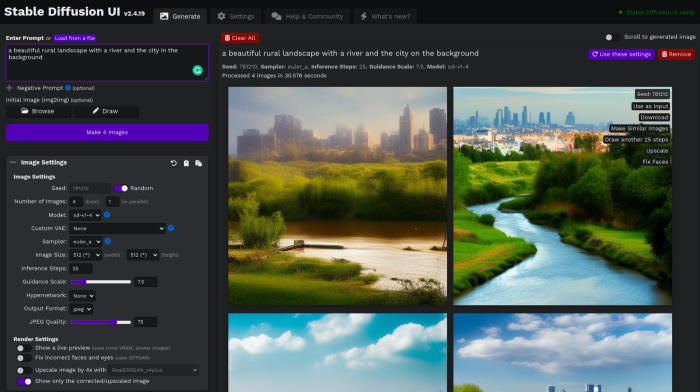
V2.1 of Stable Diffusion
I noticed the notification about releasing version 2.1 while writing this essay, and it was intriguing to test it. First, compare version 2 to version 1:
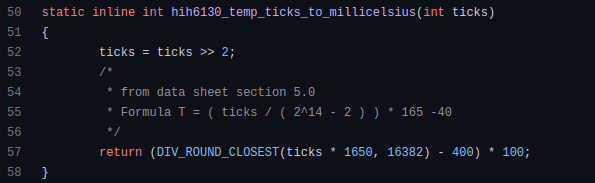
alternative text encoding. The Contrastive LanguageImage Pre-training (CLIP) deep learning model, which was trained on a significant number of text-image pairs, is used in Stable Diffusion 1. The open-source CLIP implementation used in Stable Diffusion 2 is called OpenCLIP. It is difficult to determine whether there have been any technical advancements or if legal concerns were the main focus. However, because the training datasets for the two text encoders were different, the output results from V1 and V2 will differ for the identical text prompts.
a new depth model that may be used to the output of image-to-image generation.
a revolutionary upscaling technique that can quadruple the resolution of an image.
Generally higher resolution Stable Diffusion 2 has the ability to produce both 512x512 and 768x768 pictures.
The Hugging Face website offers a free online demo of Stable Diffusion 2.1 for code testing. The process is the same as for version 1.4. Download a fresh version and activate the environment:
conda deactivate
conda env remove -n ldm # Use this if version 1 was previously installed
git clone https://github.com/Stability-AI/stablediffusion
cd stablediffusion
conda env create -f environment.yaml
conda activate ldmHugging Face offers a new weights ckpt file.
The Out of memory error prevented me from running this version on my 8 GB GPU. Version 2.1 fails on CPUs with the slow conv2d cpu not implemented for Half error (according to this GitHub issue, the CPU support for this algorithm and data type will not be added). The model can be modified from half to full precision (float16 instead of float32), however it doesn't make sense since v1 runs up to 10 minutes on the CPU and v2.1 should be much slower. The online demo results are visible. The same hamster painting with a brush prompt yielded this result:

It looks different from v1, but it functions and has a higher resolution.
The superresolution.py script can run the 4x Stable Diffusion upscaler locally (the x4-upscaler-ema.ckpt weights file should be in the same folder):
python3 scripts/gradio/superresolution.py configs/stable-diffusion/x4-upscaling.yaml x4-upscaler-ema.ckptThis code allows the web browser UI to select the image to upscale:
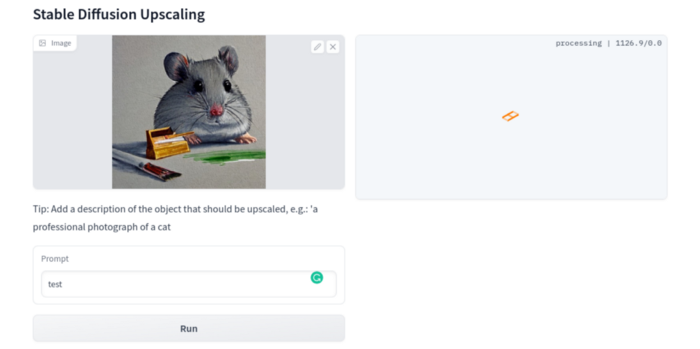
The copy-paste strategy may explain why the upscaler needs a text prompt (and the Hugging Face code snippet does not have any text input as well). I got a GPU out of memory error again, although CUDA can be disabled like v1. However, processing an image for more than two hours is unlikely:
Stable Diffusion Limitations
When we use the model, it's fun to see what it can and can't do. Generative models produce abstract visuals but not photorealistic ones. This fundamentally limits The generative neural network was trained on text and image pairs, but humans have a lot of background knowledge about the world. The neural network model knows nothing. If someone asks me to draw a Chinese text, I can draw something that looks like Chinese but is actually gibberish because I never learnt it. Generative AI does too! Humans can learn new languages, but the Stable Diffusion AI model includes only language and image decoder brain components. For instance, the Stable Diffusion model will pull NO WAR banner-bearers like this:
V1:

V2.1:

The shot shows text, although the model never learned to read or write. The model's string tokenizer automatically converts letters to lowercase before generating the image, so typing NO WAR banner or no war banner is the same.
I can also ask the model to draw a gorgeous woman:
V1:

V2.1:

The first image is gorgeous but physically incorrect. A second one is better, although it has an Uncanny valley feel. BTW, v2 has a lifehack to add a negative prompt and define what we don't want on the image. Readers might try adding horrible anatomy to the gorgeous woman request.
If we ask for a cartoon attractive woman, the results are nice, but accuracy doesn't matter:
V1:

V2.1:

Another example: I ordered a model to sketch a mouse, which looks beautiful but has too many legs, ears, and fingers:
V1:

V2.1: improved but not perfect.

V1 produces a fun cartoon flying mouse if I want something more abstract:

I tried multiple times with V2.1 but only received this:

The image is OK, but the first version is closer to the request.
Stable Diffusion struggles to draw letters, fingers, etc. However, abstract images yield interesting outcomes. A rural landscape with a modern metropolis in the background turned out well:
V1:

V2.1:

Generative models help make paintings too (at least, abstract ones). I searched Google Image Search for modern art painting to see works by real artists, and this was the first image:

I typed "abstract oil painting of people dancing" and got this:
V1:

V2.1:

It's a different style, but I don't think the AI-generated graphics are worse than the human-drawn ones.
The AI model cannot think like humans. It thinks nothing. A stable diffusion model is a billion-parameter matrix trained on millions of text-image pairs. I input "robot is creating a picture with a pen" to create an image for this post. Humans understand requests immediately. I tried Stable Diffusion multiple times and got this:

This great artwork has a pen, robot, and sketch, however it was not asked. Maybe it was because the tokenizer deleted is and a words from a statement, but I tried other requests such robot painting picture with pen without success. It's harder to prompt a model than a person.
I hope Stable Diffusion's general effects are evident. Despite its limitations, it can produce beautiful photographs in some settings. Readers who want to use Stable Diffusion results should be warned. Source code examination demonstrates that Stable Diffusion images feature a concealed watermark (text StableDiffusionV1 and SDV2) encoded using the invisible-watermark Python package. It's not a secret, because the official Stable Diffusion repository's test watermark.py file contains a decoding snippet. The put watermark line in the txt2img.py source code can be removed if desired. I didn't discover this watermark on photographs made by the online Hugging Face demo. Maybe I did something incorrectly (but maybe they are just not using the txt2img script on their backend at all).
Conclusion
The Stable Diffusion model was fascinating. As I mentioned before, trying something yourself is always better than taking someone else's word, so I encourage readers to do the same (including this article as well;).
Is Generative AI a game-changer? My humble experience tells me:
I think that place has a lot of potential. For designers and artists, generative AI can be a truly useful and innovative tool. Unfortunately, it can also pose a threat to some of them since if users can enter a text field to obtain a picture or a website logo in a matter of clicks, why would they pay more to a different party? Is it possible right now? unquestionably not yet. Images still have a very poor quality and are erroneous in minute details. And after viewing the image of the stunning woman above, models and fashion photographers may also unwind because it is highly unlikely that AI will replace them in the upcoming years.
Today, generative AI is still in its infancy. Even 768x768 images are considered to be of a high resolution when using neural networks, which are computationally highly expensive. There isn't an AI model that can generate high-resolution photographs natively without upscaling or other methods, at least not as of the time this article was written, but it will happen eventually.
It is still a challenge to accurately represent knowledge in neural networks (information like how many legs a cat has or the year Napoleon was born). Consequently, AI models struggle to create photorealistic photos, at least where little details are important (on the other side, when I searched Google for modern art paintings, the results are often even worse;).
When compared to the carefully chosen images from official web pages or YouTube reviews, the average output quality of a Stable Diffusion generation process is actually less attractive because to its high degree of randomness. When using the same technique on their own, consumers will theoretically only view those images as 1% of the results.
Anyway, it's exciting to witness this area's advancement, especially because the project is open source. Google's Imagen and DALL-E 2 can also produce remarkable findings. It will be interesting to see how they progress.
James Brockbank
3 years ago
Canonical URLs for Beginners
Canonicalization and canonical URLs are essential for SEO, and improper implementation can negatively impact your site's performance.
Canonical tags were introduced in 2009 to help webmasters with duplicate or similar content on multiple URLs.
To use canonical tags properly, you must understand their purpose, operation, and implementation.
Canonical URLs and Tags
Canonical tags tell search engines that a certain URL is a page's master copy. They specify a page's canonical URL. Webmasters can avoid duplicate content by linking to the "canonical" or "preferred" version of a page.
How are canonical tags and URLs different? Can these be specified differently?
Tags
Canonical tags are found in an HTML page's head></head> section.
<link rel="canonical" href="https://www.website.com/page/" />These can be self-referencing or reference another page's URL to consolidate signals.
Canonical tags and URLs are often used interchangeably, which is incorrect.
The rel="canonical" tag is the most common way to set canonical URLs, but it's not the only way.
Canonical URLs
What's a canonical link? Canonical link is the'master' URL for duplicate pages.
In Google's own words:
A canonical URL is the page Google thinks is most representative of duplicate pages on your site.
— Google Search Console Help
You can indicate your preferred canonical URL. For various reasons, Google may choose a different page than you.
When set correctly, the canonical URL is usually your specified URL.
Canonical URLs determine which page will be shown in search results (unless a duplicate is explicitly better for a user, like a mobile version).
Canonical URLs can be on different domains.
Other ways to specify canonical URLs
Canonical tags are the most common way to specify a canonical URL.
You can also set canonicals by:
Setting the HTTP header rel=canonical.
All pages listed in a sitemap are suggested as canonicals, but Google decides which pages are duplicates.
Redirects 301.
Google recommends these methods, but they aren't all appropriate for every situation, as we'll see below. Each has its own recommended uses.
Setting canonical URLs isn't required; if you don't, Google will use other signals to determine the best page version.
To control how your site appears in search engines and to avoid duplicate content issues, you should use canonicalization effectively.
Why Duplicate Content Exists
Before we discuss why you should use canonical URLs and how to specify them in popular CMSs, we must first explain why duplicate content exists. Nobody intentionally duplicates website content.
Content management systems create multiple URLs when you launch a page, have indexable versions of your site, or use dynamic URLs.
Assume the following URLs display the same content to a user:
A search engine sees eight duplicate pages, not one.
URLs #1 and #2: the CMS saves product URLs with and without the category name.
#3, #4, and #5 result from the site being accessible via HTTP, HTTPS, www, and non-www.
#6 is a subdomain mobile-friendly URL.
URL #7 lacks URL #2's trailing slash.
URL #8 uses a capital "A" instead of a lowercase one.
Duplicate content may also exist in URLs like:
https://www.website.com
https://www.website.com/index.php
Duplicate content is easy to create.
Canonical URLs help search engines identify different page variations as a single URL on many sites.
SEO Canonical URLs
Canonical URLs help you manage duplicate content that could affect site performance.
Canonical URLs are a technical SEO focus area for many reasons.
Specify URL for search results
When you set a canonical URL, you tell Google which page version to display.
Which would you click?
https://www.domain.com/page-1/
https://www.domain.com/index.php?id=2
First, probably.
Canonicals tell search engines which URL to rank.
Consolidate link signals on similar pages
When you have duplicate or nearly identical pages on your site, the URLs may get external links.
Canonical URLs consolidate multiple pages' link signals into a single URL.
This helps your site rank because signals from multiple URLs are consolidated into one.
Syndication management
Content is often syndicated to reach new audiences.
Canonical URLs consolidate ranking signals to prevent duplicate pages from ranking and ensure the original content ranks.
Avoid Googlebot duplicate page crawling
Canonical URLs ensure that Googlebot crawls your new pages rather than duplicated versions of the same one across mobile and desktop versions, for example.
Crawl budgets aren't an issue for most sites unless they have 100,000+ pages.
How to Correctly Implement the rel=canonical Tag
Using the header tag rel="canonical" is the most common way to specify canonical URLs.
Adding tags and HTML code may seem daunting if you're not a developer, but most CMS platforms allow canonicals out-of-the-box.
These URLs each have one product.
How to Correctly Implement a rel="canonical" HTTP Header
A rel="canonical" HTTP header can replace canonical tags.
This is how to implement a canonical URL for PDFs or non-HTML documents.
You can specify a canonical URL in your site's.htaccess file using the code below.
<Files "file-to-canonicalize.pdf"> Header add Link "< http://www.website.com/canonical-page/>; rel=\"canonical\"" </Files>301 redirects for canonical URLs
Google says 301 redirects can specify canonical URLs.
Only the canonical URL will exist if you use 301 redirects. This will redirect duplicates.
This is the best way to fix duplicate content across:
HTTPS and HTTP
Non-WWW and WWW
Trailing-Slash and Non-Trailing Slash URLs
On a single page, you should use canonical tags unless you can confidently delete and redirect the page.
Sitemaps' canonical URLs
Google assumes sitemap URLs are canonical, so don't include non-canonical URLs.
This does not guarantee canonical URLs, but is a best practice for sitemaps.
Best-practice Canonical Tag
Once you understand a few simple best practices for canonical tags, spotting and cleaning up duplicate content becomes much easier.
Always include:
One canonical URL per page
If you specify multiple canonical URLs per page, they will likely be ignored.
Correct Domain Protocol
If your site uses HTTPS, use this as the canonical URL. It's easy to reference the wrong protocol, so check for it to catch it early.
Trailing slash or non-trailing slash URLs
Be sure to include trailing slashes in your canonical URL if your site uses them.
Specify URLs other than WWW
Search engines see non-WWW and WWW URLs as duplicate pages, so use the correct one.
Absolute URLs
To ensure proper interpretation, canonical tags should use absolute URLs.
So use:
<link rel="canonical" href="https://www.website.com/page-a/" />And not:
<link rel="canonical" href="/page-a/" />If not canonicalizing, use self-referential canonical URLs.
When a page isn't canonicalizing to another URL, use self-referencing canonical URLs.
Canonical tags refer to themselves here.
Common Canonical Tags Mistakes
Here are some common canonical tag mistakes.
301 Canonicalization
Set the canonical URL as the redirect target, not a redirected URL.
Incorrect Domain Canonicalization
If your site uses HTTPS, don't set canonical URLs to HTTP.
Irrelevant Canonicalization
Canonicalize URLs to duplicate or near-identical content only.
SEOs sometimes try to pass link signals via canonical tags from unrelated content to increase rank. This isn't how canonicalization should be used and should be avoided.
Multiple Canonical URLs
Only use one canonical tag or URL per page; otherwise, they may all be ignored.
When overriding defaults in some CMSs, you may accidentally include two canonical tags in your page's <head>.
Pagination vs. Canonicalization
Incorrect pagination can cause duplicate content. Canonicalizing URLs to the first page isn't always the best solution.
Canonicalize to a 'view all' page.
How to Audit Canonical Tags (and Fix Issues)
Audit your site's canonical tags to find canonicalization issues.
SEMrush Site Audit can help. You'll find canonical tag checks in your website's site audit report.
Let's examine these issues and their solutions.
No Canonical Tag on AMP
Site Audit will flag AMP pages without canonical tags.
Canonicalization between AMP and non-AMP pages is important.
Add a rel="canonical" tag to each AMP page's head>.
No HTTPS redirect or canonical from HTTP homepage
Duplicate content issues will be flagged in the Site Audit if your site is accessible via HTTPS and HTTP.
You can fix this by 301 redirecting or adding a canonical tag to HTTP pages that references HTTPS.
Broken canonical links
Broken canonical links won't be considered canonical URLs.
This error could mean your canonical links point to non-existent pages, complicating crawling and indexing.
Update broken canonical links to the correct URLs.
Multiple canonical URLs
This error occurs when a page has multiple canonical URLs.
Remove duplicate tags and leave one.
Canonicalization is a key SEO concept, and using it incorrectly can hurt your site's performance.
Once you understand how it works, what it does, and how to find and fix issues, you can use it effectively to remove duplicate content from your site.
Canonicalization SEO Myths

Nikhil Vemu
3 years ago
7 Mac Apps That Are Exorbitantly Priced But Totally Worth It

Wish you more bang for your buck
By ‘Cost a Bomb’ I didn’t mean to exaggerate. It’s an idiom that means ‘To be very expensive’. In fact, no app on the planet costs a bomb lol.
So, to the point.
Chronicle
(Freemium. For Pro, $24.99 | Available on Setapp)
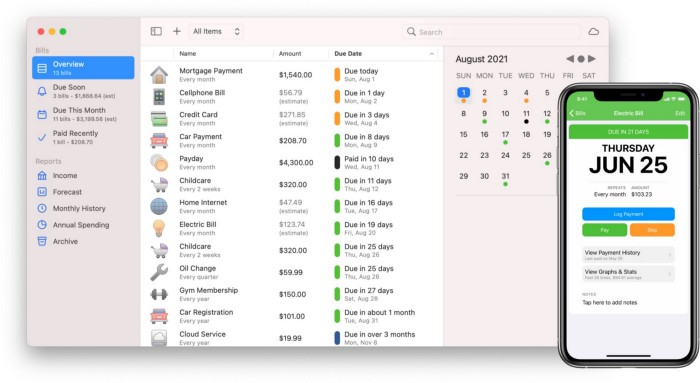
You probably have trouble keeping track of dozens of bills and subscriptions each month.
Try Chronicle.
Easy-to-use app
Add payment due dates and receive reminders,
Save payment documentation,
Analyze your spending by season, year, and month.
Observe expenditure trends and create new budgets.
Best of all, Chronicle features an integrated browser for fast payment and logging.
iOS and macOS sync.
SoundSource
($39 for lifetime)
Background Music, a free macOS program, was featured in #6 of this post last month.
It controls per-app volume, stereo balance, and audio over its max level.
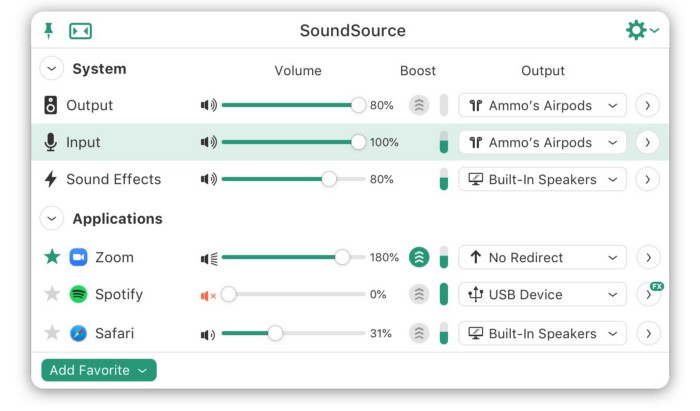
Background Music is fully supported. Additionally,
Connect various speakers to various apps (Wow! ),
change the audio sample rate for each app,
To facilitate access, add a floating SoundSource window.
Use its blocks in Shortcuts app,
On the menu bar, include meters for output/input devices and running programs.
PixelSnap
($39 for lifetime | Available on Setapp)
This software is heaven for UI designers.
It aids you.
quickly calculate screen distances (in pixels) ,
Drag an area around an object to determine its borders,

Measure the distances between the additional guides,

screenshots should be pixel-perfect.
What’s more.
You can
Adapt your tolerance for items with poor contrast and shadows.
Use your Touch Bar to perform important tasks, if you have one.
Mate Translation
($3.99 a month / $29.99 a year | Available on Setapp)
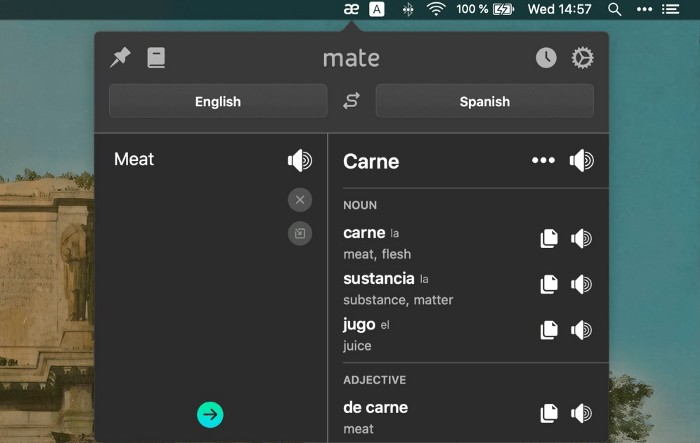
Mate Translate resembles a roided-up version of BarTranslate, which I wrote about in #1 of this piece last month.
If you translate often, utilize Mate Translate on macOS and Safari.
I'm really vocal about it.
It stays on the menu bar, and is accessible with a click or ⌥+shift+T hotkey.
It lets you
Translate in 103 different languages,
To translate text, double-click or right-click on it.
Totally translate websites. Additionally, Netflix subtitles,
Listen to their pronunciation to see how close it is to human.
iPhone and Mac sync Mate-ing history.
Swish
($16 for lifetime | Available on Setapp)
Swish is awesome!
Swipe, squeeze, tap, and hold movements organize chaotic desktop windows. Swish operates with mouse and trackpad.
Some gestures:
• Pinch Once: Close an app
• Pinch Twice: Quit an app
• Swipe down once: Minimise an app
• Pinch Out: Enter fullscreen mode
• Tap, Hold, & Swipe: Arrange apps in grids
and many more...

After getting acquainted to the movements, your multitasking will improve.
Unite
($24.99 for lifetime | Available on Setapp)
It turns webapps into macOS apps. The end.
Unite's functionality is a million times better.

Provide extensive customization (incl. its icon, light and dark modes)
make menu bar applications,
Get badges for web notifications and automatically refresh websites,
Replace any dock icon in the window with it (Wow!) by selecting that portion of the window.

Use PiP (Picture-in-Picture) on video sites that support it.
Delete advertising,
Throughout macOS, use floating windows
and many more…
I feel $24.99 one-off for this tool is a great deal, considering all these features. What do you think?
CleanShot X
(Basic: $29 one-off. Pro: $8/month | Available on Setapp)

CleanShot X can achieve things the macOS screenshot tool cannot. Complete screenshot toolkit.
CleanShot X, like Pixel Snap 2 (#3), is fantastic.
Allows
Scroll to capture a long page,
screen recording,
With webcam on,
• With mic and system audio,
• Highlighting mouse clicks and hotkeys.
Maintain floating screenshots for reference
While capturing, conceal desktop icons and notifications.
Recognize text in screenshots (OCR),
You may upload and share screenshots using the built-in cloud.
These are just 6 in 50+ features, and you’re already saying Wow!
You might also like

Isaiah McCall
3 years ago
There is a new global currency emerging, but it is not bitcoin.
America should avoid BRICS

Vladimir Putin has watched videos of Muammar Gaddafi's CIA-backed demise.
Gaddafi...
Thief.
Did you know Gaddafi wanted a gold-backed dinar for Africa? Because he considered our global financial system was a Ponzi scheme, he wanted to discontinue trading oil in US dollars.
Or, Gaddafi's Libya enjoyed Africa's highest quality of living before becoming freed. Pictured:

Vladimir Putin is a nasty guy, but he had his reasons for not mentioning NATO assisting Ukraine in resisting US imperialism. Nobody tells you. Sure.
The US dollar's corruption post-2008, debasement by quantitative easing, and lack of value are key factors. BRICS will replace the dollar.
BRICS aren't bricks.
Economy-related.
Brazil, Russia, India, China, and South Africa have cooperated for 14 years to fight U.S. hegemony with a new international currency: BRICS.
BRICS is mostly comical. Now. Saudi Arabia, the second-largest oil hegemon, wants to join.
So what?
The New World Currency is BRICS
Russia was kicked out of G8 for its aggressiveness in Crimea in 2014.
It's now G7.
No biggie, said Putin, he said, and I quote, “Bon appetite.”
He was prepared. China, India, and Brazil lead the New World Order.
Together, they constitute 40% of the world's population and, according to the IMF, 50% of the world's GDP by 2030.
Here’s what the BRICS president Marcos Prado Troyjo had to say earlier this year about no longer needing the US dollar: “We have implemented the mechanism of mutual settlements in rubles and rupees, and there is no need for our countries to use the dollar in mutual settlements. And today a similar mechanism of mutual settlements in rubles and yuan is being developed by China.”
Ick. That's D.C. and NYC warmongers licking their chops for WW3 nasty.
Here's a lovely picture of BRICS to relax you:

If Saudi Arabia joins BRICS, as President Mohammed Bin Salman has expressed interest, a majority of the Middle East will have joined forces to construct a new world order not based on the US currency.
I'm not sure of the new acronym.
SBRICSS? CIRBSS? CRIBSS?
The Reason America Is Harvesting What It Sowed
BRICS began 14 years ago.
14 years ago, what occurred? Concentrate. It involved CDOs, bad subprime mortgages, and Wall Street quants crunching numbers.
2008 recession
When two nations trade, they do so in US dollars, not Euros or gold.
What happened when 2008, an avoidable crisis caused by US banks' cupidity and ignorance, what happened?
Everyone WORLDWIDE felt the pain.
Mostly due to corporate America's avarice.
This should have been a warning that China and Russia had enough of our bs. Like when France sent a battleship to America after Nixon scrapped the gold standard. The US was warned to shape up or be dethroned (or at least try).

Nixon improved in 1971. Kinda. Invented PetroDollar.
Another BS system that unfairly favors America and possibly pushed Russia, China, and Saudi Arabia into BRICS.
The PetroDollar forces oil-exporting nations to trade in US dollars and invest in US Treasury bonds. Brilliant. Genius evil.
Our misdeeds are:
In conflicts that are not its concern, the USA uses the global reserve currency as a weapon.
Targeted nations abandon the dollar, and rightfully so, as do nations that depend on them for trade in vital resources.
The dollar's position as the world's reserve currency is in jeopardy, which could have disastrous economic effects.
Although we have actually sown our own doom, we appear astonished. According to the Bible, whomever sows to appease his sinful nature will reap destruction from that nature whereas whoever sows to appease the Spirit will reap eternal life from the Spirit.
Americans, even our leaders, lack caution and delayed pleasure. When our unsustainable systems fail, we double down. Bailouts of the banks in 2008 were myopic, puerile, and another nail in America's hegemony.
America has screwed everyone.
We're unpopular.
The BRICS's future
It's happened before.
Saddam Hussein sold oil in Euros in 2000, and the US invaded Iraq a month later. The media has devalued the word conspiracy. The Iraq conspiracy.
There were no WMDs, but NYT journalists like Judy Miller drove Americans into a warmongering frenzy because Saddam would ruin the PetroDollar. Does anyone recall that this war spawned ISIS?
I think America has done good for the world. You can make a convincing case that we're many people's villain.
Learn more in Confessions of an Economic Hitman, The Devil's Chessboard, or Tyranny of the Federal Reserve. Or ignore it. That's easier.
We, America, should extend an olive branch, ask for forgiveness, and learn from our faults, as the Tao Te Ching advises. Unlikely. Our population is apathetic and stupid, and our government is corrupt.
Argentina, Iran, Egypt, and Turkey have also indicated interest in joining BRICS. They're also considering making it gold-backed, making it a new world reserve currency.
You should pay attention.
Thanks for reading!

Jenn Leach
3 years ago
I created a faceless TikTok account. Six months later.
Follower count, earnings, and more

I created my 7th TikTok account six months ago. TikTok's great. I've developed accounts for Amazon products, content creators/brand deals education, website flipping, and more.
Introverted or shy people use faceless TikTok accounts.
Maybe they don't want millions of people to see their face online, or they want to remain anonymous so relatives and friends can't locate them.
Going faceless on TikTok can help you grow a following, communicate your message, and make money online.
Here are 6 steps I took to turn my Tik Tok account into a $60,000/year side gig.
From nothing to $60K in 6 months
It's clickbait, but it’s true. Here’s what I did to get here.
Quick context:
I've used social media before. I've spent years as a social creator and brand.
I've built Instagram, TikTok, and YouTube accounts to nearly 100K.
How I did it
First, select a niche.
If you can focus on one genre on TikTok, you'll have a better chance of success, however lifestyle creators do well too.
Niching down is easier, in my opinion.
Examples:
Travel
Food
Kids
Earning cash
Finance
You can narrow these niches if you like.
During the pandemic, a travel blogger focused on Texas-only tourism and gained 1 million subscribers.
Couponing might be a finance specialization.
One of my finance TikTok accounts gives credit tips and grants and has 23K followers.
Tons of ways you can get more specific.
Consider how you'll monetize your TikTok account. I saw many enormous TikTok accounts that lose money.
Why?
They can't monetize their niche. Not impossible to commercialize, but tough enough to inhibit action.
First, determine your goal.
In this first step, consider what your end goal is.
Are you trying to promote your digital products or social media management services?
You want brand deals or e-commerce sales.
This will affect your TikTok specialty.
This is the first step to a TikTok side gig.
Step 2: Pick a content style
Next, you want to decide on your content style.
Do you do voiceover and screenshots?
You'll demonstrate a product?
Will you faceless vlog?
Step 3: Look at the competition
Find anonymous accounts and analyze what content works, where they thrive, what their audience wants, etc.
This can help you make better content.
Like the skyscraper method for TikTok.
Step 4: Create a content strategy.
Your content plan is where you sit down and decide:
How many videos will you produce each day or each week?
Which links will you highlight in your biography?
What amount of time can you commit to this project?
You may schedule when to post videos on a calendar. Make videos.
5. Create videos.
No video gear needed.
Using a phone is OK, and I think it's preferable than posting drafts from a computer or phone.
TikTok prefers genuine material.
Use their app, tools, filters, and music to make videos.
And imperfection is preferable. Tik okers like to see videos made in a bedroom, not a film studio.
Make sense?
When making videos, remember this.
I personally use my phone and tablet.
Step 6: Monetize
Lastly, it’s time to monetize How will you make money? You decided this in step 1.
Time to act!
For brand agreements
Include your email in the bio.
Share several sites and use a beacons link in your bio.
Make cold calls to your favorite companies to get them to join you in a TikTok campaign.
For e-commerce
Include a link to your store's or a product's page in your bio.
For client work
Include your email in the bio.
Use a beacons link to showcase your personal website, portfolio, and other resources.
For affiliate marketing
Include affiliate product links in your bio.
Join the Amazon Influencer program and provide a link to your storefront in your bio.
$60,000 per year from Tik Tok?
Yes, and some creators make much more.
Tori Dunlap (herfirst100K) makes $100,000/month on TikTok.
My TikTok adventure took 6 months, but by month 2 I was making $1,000/month (or $12K/year).
By year's end, I want this account to earn $100K/year.
Imagine if my 7 TikTok accounts made $100K/year.
7 Tik Tok accounts X $100K/yr = $700,000/year

Andy Raskin
3 years ago
I've Never Seen a Sales Deck This Good

It’s Zuora’s, and it’s brilliant. Here’s why.
My friend Tim got a sales position at a Series-C software company that garnered $60 million from A-list investors. He's one of the best salespeople I know, yet he emailed me after starting to struggle.
Tim has a few modest clients. “Big companies ignore my pitch”. Tim said.
I love helping teams write the strategic story that drives sales, marketing, and fundraising. Tim and I had lunch at Amber India on Market Street to evaluate his deck.
After a feast, I asked Tim when prospects tune out.
He said, “several slides in”.
Intent on maximizing dining ROI, Tim went back to the buffet for seconds. When he returned, I pulled out my laptop and launched into a Powerpoint presentation.
“What’s this?” Tim asked.
“This,” I said, “is the greatest sales deck I have ever seen.”
Five Essentials of a Great Sales Narrative
I showed Tim a sales slide from IPO-bound Zuora, which sells a SaaS platform for subscription billing. Zuora supports recurring payments (e.g. enterprise software).
Ex-Zuora salesman gave me the deck, saying it helped him close his largest business. (I don't know anyone who works at Zuora.) After reading this, a few Zuora employees contacted me.)
Tim abandoned his naan in a pool of goat curry and took notes while we discussed the Zuora deck.
We remarked how well the deck led prospects through five elements:
(The ex-Zuora salesperson begged me not to release the Zuora deck publicly.) All of the images below originate from Zuora's website and SlideShare channel.)
#1. Name a Significant Change in the World
Don't start a sales presentation with mentioning your product, headquarters, investors, clients, or yourself.
Name the world shift that raises enormous stakes and urgency for your prospect.
Every Zuora sales deck begins with this slide:

Zuora coined the term subscription economy to describe a new market where purchasers prefer regular service payments over outright purchases. Zuora then shows a slide with the change's history.

Most pitch recommendation advises starting with the problem. When you claim a problem, you put prospects on the defensive. They may be unaware of or uncomfortable admitting the situation.
When you highlight a global trend, prospects open up about how it affects them, worries them, and where they see opportunity. You capture their interest. Robert McKee says:
…what attracts human attention is change. …if the temperature around you changes, if the phone rings — that gets your attention. The way in which a story begins is a starting event that creates a moment of change.
#2. Show There’ll Be Winners and Losers
Loss aversion affects all prospects. They avoid a loss by sticking with the status quo rather than risking a gain by changing.
To fight loss aversion, show how the change will create winners and losers. You must show both
that if the prospect can adjust to the modification you mentioned, the outcome will probably be quite favorable; and
That failing to do so is likely to have an unacceptable negative impact on the prospect's future
Zuora shows a mass extinction among Fortune 500 firms.

…and then showing how the “winners” have shifted from product ownership to subscription services. Those include upstarts…

…as well as rejuvenated incumbents:

To illustrate, Zuora asks:

Winners utilize Zuora's subscription service models.
#3. Tease the Promised Land
It's tempting to get into product or service details now. Resist that urge.
Prospects won't understand why product/service details are crucial if you introduce them too soon, therefore they'll tune out.
Instead, providing a teaser image of the happily-ever-after your product/service will assist the prospect reach.
Your Promised Land should be appealing and hard to achieve without support. Otherwise, why does your company exist?
Zuora shows this Promised Land slide after explaining that the subscription economy will have winners and losers.

Not your product or service, but a new future state.
(I asked my friend Tim to describe his Promised Land, and he answered, "You’ll have the most innovative platform for ____." Nope: the Promised Land isn't possessing your technology, but living with it.)
Your Promised Land helps prospects market your solution to coworkers after your sales meeting. Your coworkers will wonder what you do without you. Your prospects are more likely to provide a persuasive answer with a captivating Promised Land.
#4. Present Features as “Mystic Gifts” for Overcoming Difficulties on the Road to the Promised Land
Successful sales decks follow the same format as epic films and fairy tales. Obi Wan gives Luke a lightsaber to help him destroy the Empire. You're Gandalf, helping Frodo destroy the ring. Your prospect is Cinderella, and you're her fairy godmother.
Position your product or service's skills as mystical gifts to aid your main character (prospect) achieve the Promised Land.

Zuora's client record slide is shown above. Without context, even the most technical prospect would be bored.
Positioned in the context of shifting from an “old” to a “new world”, it's the foundation for a compelling conversation with prospects—technical and otherwise—about why traditional solutions can't reach the Promised Land.
#5. Show Proof That You Can Make the Story True.
In this sense, you're promising possibilities that if they follow you, they'll reach the Promised Land.
The journey to the Promised Land is by definition rocky, so prospects are right to be cautious. The final part of the pitch is proof that you can make the story come true.
The most convincing proof is a success story about how you assisted someone comparable to the prospect. Zuora's sales people use a deck of customer success stories, but this one gets the essence.

I particularly appreciate this one from an NCR exec (a Zuora customer), which relates more strongly to Zuora's Promised Land:

Not enough successful customers? Product demos are the next best evidence, but features should always be presented in the context of helping a prospect achieve the Promised Land.
The best sales narrative is one that is told by everyone.
Success rarely comes from a fantastic deck alone. To be effective, salespeople need an organization-wide story about change, Promised Land, and Magic Gifts.
Zuora exemplifies this. If you hear a Zuora executive, including CEO Tien Tzuo, talk, you'll likely hear about the subscription economy and its winners and losers. This is the theme of the company's marketing communications, campaigns, and vision statement.

According to the ex-Zuora salesperson, company-wide story alignment made him successful.
The Zuora marketing folks ran campaigns and branding around this shift to the subscription economy, and [CEO] Tien [Tzuo] talked it up all the time. All of that was like air cover for my in-person sales ground attack. By the time I arrived, prospects were already convinced they had to act. It was the closest thing I’ve ever experienced to sales nirvana.
The largest deal ever
Tim contacted me three weeks after our lunch to tell me that prospects at large organizations were responding well to his new deck, which we modeled on Zuora's framework. First, prospects revealed their obstacles more quickly. The new pitch engages CFOs and other top gatekeepers better, he said.
A week later, Tim emailed that he'd signed his company's biggest agreement.
Next week, we’re headed back to Amber India to celebrate.