


Plagiarism on OpenSea: humans and computers
OpenSea, a non-fungible token (NFT) marketplace, is fighting plagiarism. A new “two-pronged” approach will aim to root out and remove copies of authentic NFTs and changes to its blue tick verified badge system will seek to enhance customer confidence.
According to a blog post, the anti-plagiarism system will use algorithmic detection of “copymints” with human reviewers to keep it in check.
Last year, NFT collectors were duped into buying flipped images of the popular BAYC collection, according to The Verge. The largest NFT marketplace had to remove its delay pay minting service due to an influx of copymints.
80% of NFTs removed by the platform were minted using its lazy minting service, which kept the digital asset off-chain until the first purchase.
NFTs copied from popular collections are opportunistic money-grabs. Right-click, save, and mint the jacked JPEGs that are then flogged as an authentic NFT.
The anti-plagiarism system will scour OpenSea's collections for flipped and rotated images, as well as other undescribed permutations. The lack of detail here may be a deterrent to scammers, or it may reflect the new system's current rudimentary nature.
Thus, human detectors will be needed to verify images flagged by the detection system and help train it to work independently.
“Our long-term goal with this system is two-fold: first, to eliminate all existing copymints on OpenSea, and second, to help prevent new copymints from appearing,” it said.
“We've already started delisting identified copymint collections, and we'll continue to do so over the coming weeks.”
It works for Twitter, why not OpenSea
OpenSea is also changing account verification. Early adopters will be invited to apply for verification if their NFT stack is worth $100 or more. OpenSea plans to give the blue checkmark to people who are active on Twitter and Discord.
This is just the beginning. We are committed to a future where authentic creators can be verified, keeping scammers out.
Also, collections with a lot of hype and sales will get a blue checkmark. For example, a new NFT collection sold by the verified BAYC account will have a blue badge to verify its legitimacy.
New requests will be responded to within seven days, according to OpenSea.
These programs and products help protect creators and collectors while ensuring our community can confidently navigate the world of NFTs.
By elevating authentic content and removing plagiarism, these changes improve trust in the NFT ecosystem, according to OpenSea.
OpenSea is indeed catching up with the digital art economy. Last August, DevianArt upgraded its AI image recognition system to find stolen tokenized art on marketplaces like OpenSea.
It scans all uploaded art and compares it to “public blockchain events” like Ethereum NFTs to detect stolen art.
More on NFTs & Art

Sea Launch
3 years ago
A guide to NFT pre-sales and whitelists
Before we dig through NFT whitelists and pre-sales, if you know absolutely nothing about NFTs, check our NFT Glossary.
What are pre-sales and whitelists on NFTs?
An NFT pre-sale, as the name implies, allows community members or early supporters of an NFT project to mint before the public, usually via a whitelist or mint pass.
Coin collectors can use mint passes to claim NFTs during the public sale. Because the mint pass is executed by “burning” an NFT into a specific crypto wallet, the collector is not concerned about gas price spikes.
A whitelist is used to approve a crypto wallet address for an NFT pre-sale. In a similar way to an early access list, it guarantees a certain number of crypto wallets can mint one (or more) NFT.
New NFT projects can do a pre-sale without a whitelist, but whitelists are good practice to avoid gas wars and a fair shot at minting an NFT before launching in competitive NFT marketplaces like Opensea, Magic Eden, or CNFT.
Should NFT projects do pre-sales or whitelists? 👇
The reasons to do pre-sales or a whitelist for NFT creators:
Time the market and gain traction.
Pre-sale or whitelists can help NFT projects gauge interest early on.
Whitelist spots filling up quickly is usually a sign of a successful launch, though it does not guarantee NFT longevity (more on that later). Also, full whitelists create FOMO and momentum for the public sale among non-whitelisted NFT collectors.
If whitelist signups are low or slow, projects may need to work on their vision, community, or product. Or the market is in a bear cycle. In either case, it aids NFT projects in market timing.
Reward the early NFT Community members.
Pre-sale and whitelists can help NFT creators reward early supporters.
First, by splitting the minting process into two phases, early adopters get a chance to mint one or more NFTs from their collection at a discounted or even free price.
Did you know that BAYC started at 0.08 eth each? A serum that allowed you to mint a Mutant Ape has become as valuable as the original BAYC.
(2) Whitelists encourage early supporters to help build a project's community in exchange for a slot or status. If you invite 10 people to the NFT Discord community, you get a better ranking or even a whitelist spot.
Pre-sale and whitelisting have become popular ways for new projects to grow their communities and secure future buyers.
Prevent gas wars.
Most new NFTs are created on the Ethereum blockchain, which has the highest transaction fees (also known as gas) (Solana, Cardano, Polygon, Binance Smart Chain, etc).
An NFT public sale is a gas war when a large number of NFT collectors (or bots) try to mint an NFT at the same time.
Competing collectors are willing to pay higher gas fees to prioritize their transaction and out-price others when upcoming NFT projects are hyped and very popular.
Pre-sales and whitelisting prevent gas wars by breaking the minting process into smaller batches of members or season launches.
The reasons to do pre-sales or a whitelists for NFT collectors:
How do I get on an NFT whitelist?
- Popular NFT collections act as a launchpad for other new or hyped NFT collections.
Example: Interfaces NFTs gives out 100 whitelist spots to Deadfellaz NFTs holders. Both NFT projects win. Interfaces benefit from Deadfellaz's success and brand equity.
In this case, to get whitelisted NFT collectors need to hold that specific NFT that is acting like a launchpad.
- A NFT studio or collection that launches a new NFT project and rewards previous NFT holders with whitelist spots or pre-sale access.
The whitelist requires previous NFT holders or community members.
NFT Alpha Groups are closed, small, tight-knit Discord servers where members share whitelist spots or giveaways from upcoming NFTs.
The benefit of being in an alpha group is getting information about new NFTs first and getting in on pre-sale/whitelist before everyone else.
There are some entry barriers to alpha groups, but if you're active in the NFT community, you'll eventually bump into, be invited to, or form one.
- A whitelist spot is awarded to members of an NFT community who are the most active and engaged.
This participation reward is the most democratic. To get a chance, collectors must work hard and play to their strengths.
Whitelisting participation examples:
- Raffle, games and contest: NFT Community raffles, games, and contests. To get a whitelist spot, invite 10 people to X NFT Discord community.
- Fan art: To reward those who add value and grow the community by whitelisting the best fan art and/or artists is only natural.
- Giveaways: Lucky number crypto wallet giveaways promoted by an NFT community. To grow their communities and for lucky collectors, NFT projects often offer free NFT.
- Activate your voice in the NFT Discord Community. Use voice channels to get NFT teams' attention and possibly get whitelisted.
The advantage of whitelists or NFT pre-sales.
Chainalysis's NFT stats quote is the best answer:
“Whitelisting isn’t just some nominal reward — it translates to dramatically better investing results. OpenSea data shows that users who make the whitelist and later sell their newly-minted NFT gain a profit 75.7% of the time, versus just 20.8% for users who do so without being whitelisted. Not only that, but the data suggests it’s nearly impossible to achieve outsized returns on minting purchases without being whitelisted.” Full report here.
Sure, it's not all about cash. However, any NFT collector should feel secure in their investment by owning a piece of a valuable and thriving NFT project. These stats help collectors understand that getting in early on an NFT project (via whitelist or pre-sale) will yield a better and larger return.
The downsides of pre-sales & whitelists for NFT creators.
Pre-sales and whitelist can cause issues for NFT creators and collectors.
NFT flippers
NFT collectors who only want to profit from early minting (pre-sale) or low mint cost (via whitelist). To sell the NFT in a secondary market like Opensea or Solanart, flippers go after the discounted price.
For example, a 1000 Solana NFT collection allows 100 people to mint 1 Solana NFT at 0.25 SOL. The public sale price for the remaining 900 NFTs is 1 SOL. If an NFT collector sells their discounted NFT for 0.5 SOL, the secondary market floor price is below the public mint.
This may deter potential NFT collectors. Furthermore, without a cap in the pre-sale minting phase, flippers can get as many NFTs as possible to sell for a profit, dumping them in secondary markets and driving down the floor price.
Hijacking NFT sites, communities, and pre-sales phase
People try to scam the NFT team and their community by creating oddly similar but fake websites, whitelist links, or NFT's Discord channel.
Established and new NFT projects must be vigilant to always make sure their communities know which are the official links, how a whitelist or pre-sale rules and how the team will contact (or not) community members.
Another way to avoid the scams around the pre-sale phase, NFT projects opt to create a separate mint contract for the whitelisted crypto wallets and then another for the public sale phase.
Scam NFT projects
We've seen a lot of mid-mint or post-launch rug pulls, indicating that some bad NFT projects are trying to scam NFT communities and marketplaces for quick profit. What happened to Magic Eden's launchpad recently will help you understand the scam.
We discussed the benefits and drawbacks of NFT pre-sales and whitelists for both projects and collectors.
Finally, some practical tools and tips for finding new NFTs 👇
Tools & resources to find new NFT on pre-sale or to get on a whitelist:
In order to never miss an update, important pre-sale dates, or a giveaway, create a Tweetdeck or Tweeten Twitter dashboard with hyped NFT project pages, hashtags ( #NFTGiveaways , #NFTCommunity), or big NFT influencers.
Search for upcoming NFT launches that have been vetted by the marketplace and try to get whitelisted before the public launch.
Save-timing discovery platforms like sealaunch.xyz for NFT pre-sales and upcoming launches. How can we help 100x NFT collectors get projects? A project's official social media links, description, pre-sale or public sale dates, price and supply. We're also working with Dune on NFT data analysis to help NFT collectors make better decisions.
Don't invest what you can't afford to lose because a) the project may fail or become rugged. Find NFTs projects that you want to be a part of and support.
Read original post here

Web3Lunch
3 years ago
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.

The space had better days. Those greenish spikes...oh wow, haven't felt that in ages. Cryptocurrencies and NFTs have lost popularity. Google agrees. Both are declining.
As seen below, crypto interest spiked in May because of the Luna fall. NFT interest is similar to early October last year.
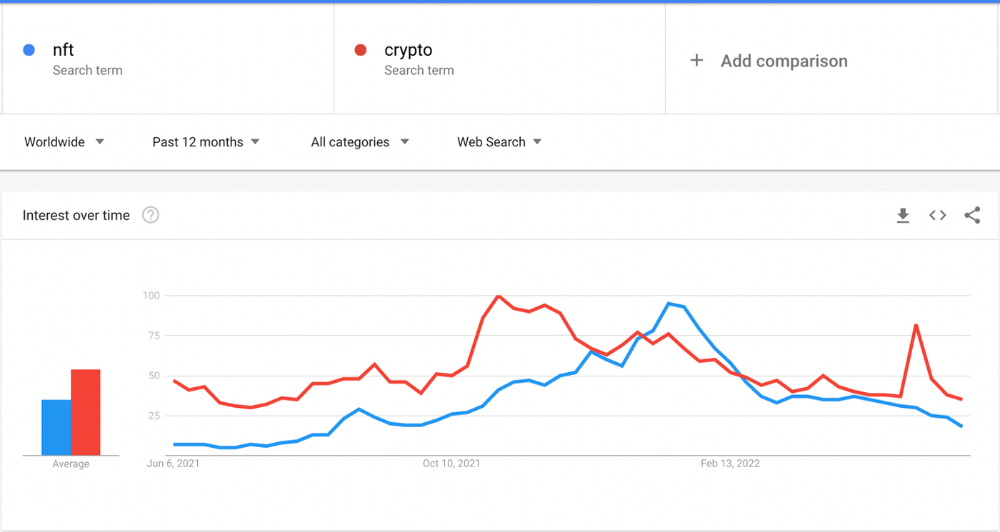
This makes me think NFTs are mostly hype and FOMO. No art or community. I've seen enough initiatives to know that communities stick around if they're profitable. Once it starts falling, they move on to the next project. The space has no long-term investments. Flip everything.
OpenSea trading volume has stayed steady for months. May's volume is 1.8 million ETH ($3.3 billion).
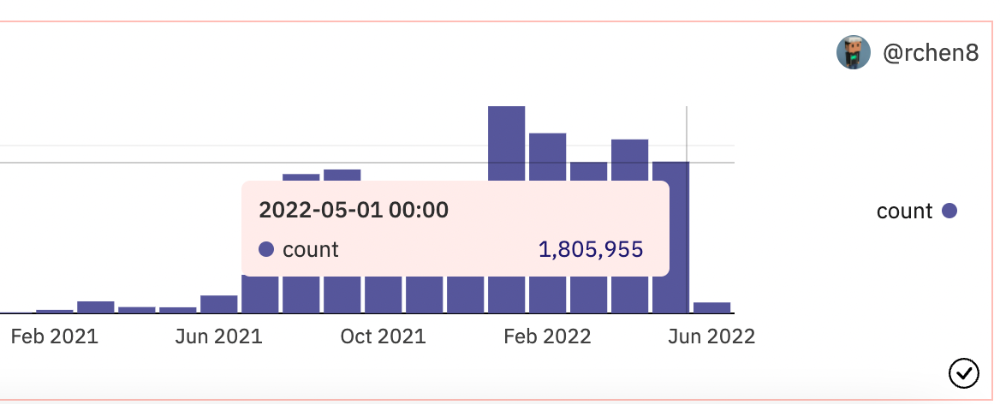
Despite this, I think NFTs and crypto will stick around. In bad markets, builders gain most.
Only 4k developers are active on Ethereum blockchain. It's low. A great chance for the space enthusiasts.
An employee of OpenSea might get a 40-year prison sentence for insider trading using NFTs.
Nathaniel Chastian, an OpenSea employee, traded on insider knowledge. He'll serve 40 years for that.
Here's what happened if you're unfamiliar.
OpenSea is a secondary NFT marketplace. Their homepage featured remarkable drops. Whatever gets featured there, NFT prices will rise 5x.
Chastian was at OpenSea. He chose forthcoming NFTs for OpenSeas' webpage.
Using anonymous digital currency wallets and OpenSea accounts, he would buy NFTs before promoting them on the homepage, showcase them, and then sell them for at least 25 times the price he paid.
From June through September 2021, this happened. Later caught, fired. He's charged with wire fraud and money laundering, each carrying a 20-year maximum penalty.
Although web3 space is all about decentralization, a step like this is welcomed since it restores faith in the area. We hope to see more similar examples soon.
Here's the press release.

Understanding smart contracts
@cantino.eth has a Twitter thread on smart contracts. Must-read. Also, he appears educated about the space, so follow him.


shivsak
3 years ago
A visual exploration of the REAL use cases for NFTs in the Future

In this essay, I studied REAL NFT use examples and their potential uses.
Knowledge of the Hype Cycle
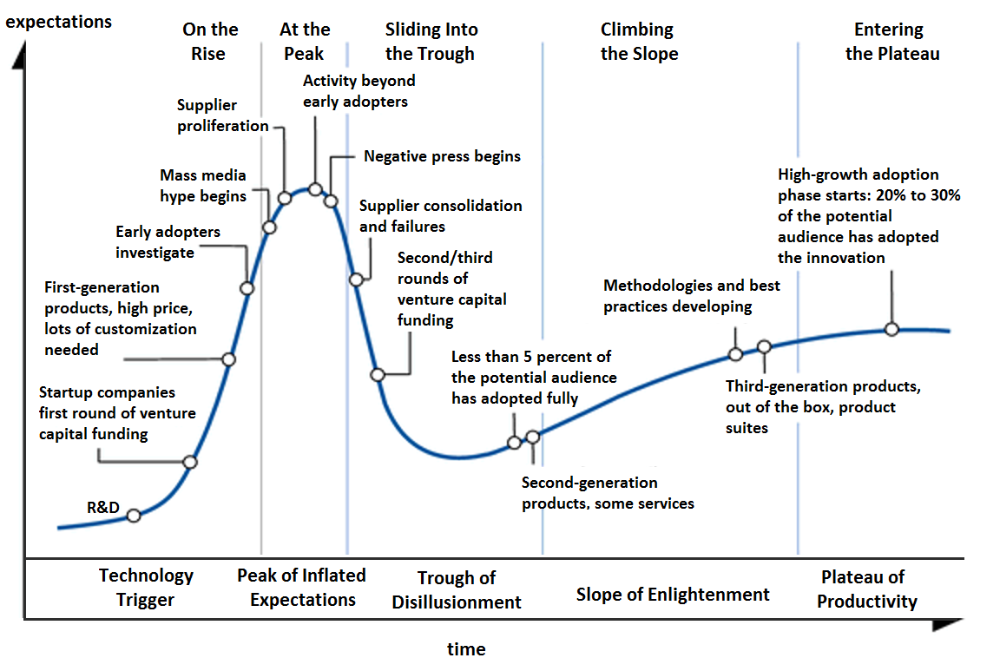
Gartner's Hype Cycle.
It proposes 5 phases for disruptive technology.
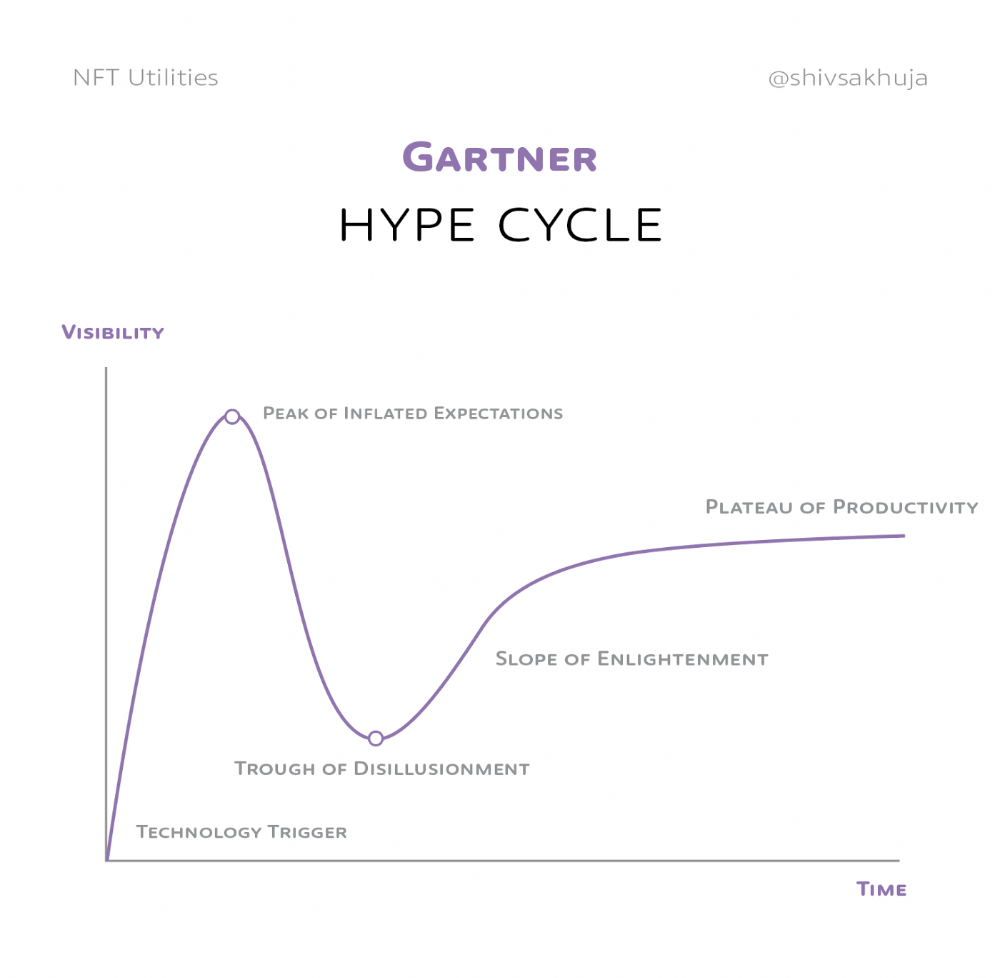
1. Technology Trigger: the emergence of potentially disruptive technology.
2. Peak of Inflated Expectations: Early publicity creates hype. (Ex: 2021 Bubble)
3. Trough of Disillusionment: Early projects fail to deliver on promises and the public loses interest. I suspect NFTs are somewhere around this trough of disillusionment now.
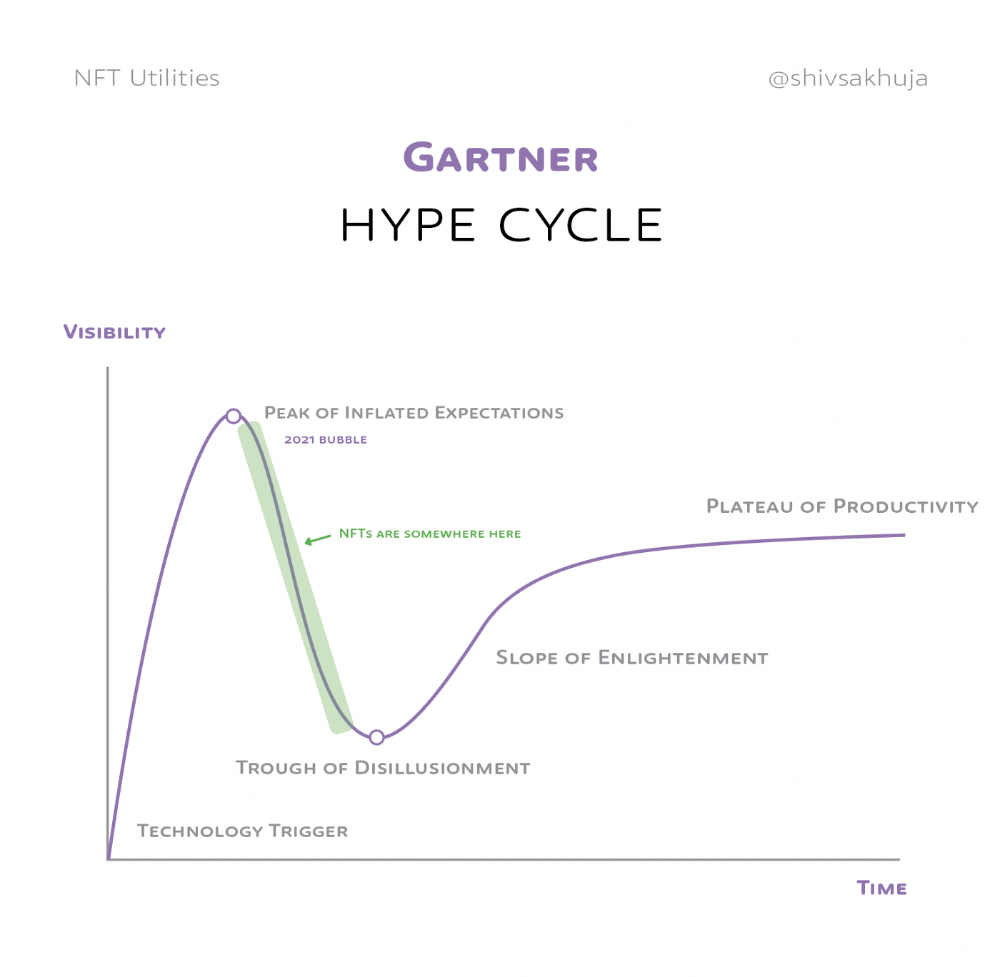
4. Enlightenment slope: The tech shows successful use cases.
5. Plateau of Productivity: Mainstream adoption has arrived and broader market applications have proven themselves. Here’s a more detailed visual of the Gartner Hype Cycle from Wikipedia.
In the speculative NFT bubble of 2021, @beeple sold Everydays: the First 5000 Days for $69 MILLION in 2021's NFT bubble.
@nbatopshot sold millions in video collectibles.
This is when expectations peaked.
Let's examine NFTs' real-world applications.
Watch this video if you're unfamiliar with NFTs.
Online Art
Most people think NFTs are rich people buying worthless JPEGs and MP4s.
Digital artwork and collectibles are revolutionary for creators and enthusiasts.
NFT Profile Pictures
You might also have seen NFT profile pictures on Twitter.
My profile picture is an NFT I coined with @skogards factoria app, which helps me avoid bogus accounts.

Profile pictures are a good beginning point because they're unique and clearly yours.
NFTs are a way to represent proof-of-ownership. It’s easier to prove ownership of digital assets than physical assets, which is why artwork and pfps are the first use cases.
They can do much more.
NFTs can represent anything with a unique owner and digital ownership certificate. Domains and usernames.
Usernames & Domains
@unstoppableweb, @ensdomains, @rarible sell NFT domains.

NFT domains are transferable, which is a benefit.
Godaddy and other web2 providers have difficult-to-transfer domains. Domains are often leased instead of purchased.
Tickets
NFTs can also represent concert tickets and event passes.
There's a limited number, and entry requires proof.
NFTs can eliminate the problem of forgery and make it easy to verify authenticity and ownership.

NFT tickets can be traded on the secondary market, which allows for:
marketplaces that are uniform and offer the seller and buyer security (currently, tickets are traded on inefficient markets like FB & craigslist)
unbiased pricing
Payment of royalties to the creator

4. Historical ticket ownership data implies performers can airdrop future passes, discounts, etc.
5. NFT passes can be a fandom badge.
The $30B+ online tickets business is increasing fast.
NFT-based ticketing projects:
Gaming Assets
NFTs also help in-game assets.
Imagine someone spending five years collecting a rare in-game blade, then outgrowing or quitting the game. Gamers value that collectible.

The gaming industry is expected to make $200 BILLION in revenue this year, a significant portion of which comes from in-game purchases.
Royalties on secondary market trading of gaming assets encourage gaming businesses to develop NFT-based ecosystems.
Digital assets are the start. On-chain NFTs can represent real-world assets effectively.
Real estate has a unique owner and requires ownership confirmation.
Real Estate
Tokenizing property has many benefits.
1. Can be fractionalized to increase access, liquidity
2. Can be collateralized to increase capital efficiency and access to loans backed by an on-chain asset
3. Allows investors to diversify or make bets on specific neighborhoods, towns or cities +++

I've written about this thought exercise before.
I made an animated video explaining this.
We've just explored NFTs for transferable assets. But what about non-transferrable NFTs?
SBTs are Soul-Bound Tokens. Vitalik Buterin (Ethereum co-founder) blogged about this.
NFTs are basically verifiable digital certificates.
Diplomas & Degrees
That fits Degrees & Diplomas. These shouldn't be marketable, thus they can be non-transferable SBTs.

Anyone can verify the legitimacy of on-chain credentials, degrees, abilities, and achievements.
The same goes for other awards.
For example, LinkedIn could give you a verified checkmark for your degree or skills.

Authenticity Protection
NFTs can also safeguard against counterfeiting.
Counterfeiting is the largest criminal enterprise in the world, estimated to be $2 TRILLION a year and growing.
Anti-counterfeit tech is valuable.
This is one of @ORIGYNTech's projects.

Identity
Identity theft/verification is another real-world problem NFTs can handle.
In the US, 15 million+ citizens face identity theft every year, suffering damages of over $50 billion a year.
This isn't surprising considering all you need for US identity theft is a 9-digit number handed around in emails, documents, on the phone, etc.
Identity NFTs can fix this.
NFTs are one-of-a-kind and unforgeable.
NFTs offer a universal standard.
NFTs are simple to verify.
SBTs, or non-transferrable NFTs, are tied to a particular wallet.
In the event of wallet loss or theft, NFTs may be revoked.

This could be one of the biggest use cases for NFTs.
Imagine a global identity standard that is standardized across countries, cannot be forged or stolen, is digital, easy to verify, and protects your private details.

Since your identity is more than your government ID, you may have many NFTs.
@0xPolygon and @civickey are developing on-chain identity.

Memberships
NFTs can authenticate digital and physical memberships.

Voting
NFT IDs can verify votes.
If you remember 2020, you'll know why this is an issue.
Online voting's ease can boost turnout.

Informational property
NFTs can protect IP.

This can earn creators royalties.
NFTs have 2 important properties:
Verifiability IP ownership is unambiguously stated and publicly verified.
Platforms that enable authors to receive royalties on their IP can enter the market thanks to standardization.
Content Rights

Monetization without copyrighting = more opportunities for everyone.
This works well with the music.

Spotify and Apple Music pay creators very little.
Crowdfunding
Creators can crowdfund with NFTs.
NFTs can represent future royalties for investors.
This is particularly useful for fields where people who are not in the top 1% can’t make money. (Example: Professional sports players)

Mirror.xyz allows blog-based crowdfunding.
Financial NFTs
This introduces Financial NFTs (fNFTs). Unique financial contracts abound.
Examples:
a person's collection of assets (unique portfolio)
A loan contract that has been partially repaid with a lender
temporal tokens (ex: veCRV)

Legal Agreements
Not just financial contracts.
NFT can represent any legal contract or document.

Messages & Emails
What about other agreements? Verbal agreements through emails and messages are likewise unique, but they're easily lost and fabricated.

Health Records
Medical records or prescriptions are another types of documentation that has to be verified but isn't.
Medical NFT examples:
Immunization records
Covid test outcomes
Prescriptions
health issues that may affect one's identity
Observations made via health sensors
Existing systems of proof by paper / PDF have photoshop-risk.
I tried to include most use scenarios, but this is just the beginning.
NFTs have many innovative uses.
For example: @ShaanVP minted an NFT called “5 Minutes of Fame” 👇
Here are 2 Twitter threads about NFTs:
This piece of gold by @chriscantino
2. This conversation between @punk6529 and @RaoulGMI on @RealVision“The World According to @punk6529”
If you're wondering why NFTs are better than web2 databases for these use scenarios, see this Twitter thread I wrote:
If you liked this, please share it.
You might also like

Yogesh Rawal
3 years ago
Blockchain to solve growing privacy challenges
Most online activity is now public. Businesses collect, store, and use our personal data to improve sales and services.
In 2014, Uber executives and employees were accused of spying on customers using tools like maps. Another incident raised concerns about the use of ‘FaceApp'. The app was created by a small Russian company, and the photos can be used in unexpected ways. The Cambridge Analytica scandal exposed serious privacy issues. The whole incident raised questions about how governments and businesses should handle data. Modern technologies and practices also make it easier to link data to people.
As a result, governments and regulators have taken steps to protect user data. The General Data Protection Regulation (GDPR) was introduced by the EU to address data privacy issues. The law governs how businesses collect and process user data. The Data Protection Bill in India and the General Data Protection Law in Brazil are similar.
Despite the impact these regulations have made on data practices, a lot of distance is yet to cover.
Blockchain's solution
Blockchain may be able to address growing data privacy concerns. The technology protects our personal data by providing security and anonymity. The blockchain uses random strings of numbers called public and private keys to maintain privacy. These keys allow a person to be identified without revealing their identity. Blockchain may be able to ensure data privacy and security in this way. Let's dig deeper.
Financial transactions
Online payments require third-party services like PayPal or Google Pay. Using blockchain can eliminate the need to trust third parties. Users can send payments between peers using their public and private keys without providing personal information to a third-party application. Blockchain will also secure financial data.
Healthcare data
Blockchain technology can give patients more control over their data. There are benefits to doing so. Once the data is recorded on the ledger, patients can keep it secure and only allow authorized access. They can also only give the healthcare provider part of the information needed.
The major challenge
We tried to figure out how blockchain could help solve the growing data privacy issues. However, using blockchain to address privacy concerns has significant drawbacks. Blockchain is not designed for data privacy. A ‘distributed' ledger will be used to store the data. Another issue is the immutability of blockchain. Data entered into the ledger cannot be changed or deleted. It will be impossible to remove personal data from the ledger even if desired.
MIT's Enigma Project aims to solve this. Enigma's ‘Secret Network' allows nodes to process data without seeing it. Decentralized applications can use Secret Network to use encrypted data without revealing it.
Another startup, Oasis Labs, uses blockchain to address data privacy issues. They are working on a system that will allow businesses to protect their customers' data.
Conclusion
Blockchain technology is already being used. Several governments use blockchain to eliminate centralized servers and improve data security. In this information age, it is vital to safeguard our data. How blockchain can help us in this matter is still unknown as the world explores the technology.

Sofien Kaabar, CFA
3 years ago
How to Make a Trading Heatmap
Python Heatmap Technical Indicator

Heatmaps provide an instant overview. They can be used with correlations or to predict reactions or confirm the trend in trading. This article covers RSI heatmap creation.
The Market System
Market regime:
Bullish trend: The market tends to make higher highs, which indicates that the overall trend is upward.
Sideways: The market tends to fluctuate while staying within predetermined zones.
Bearish trend: The market has the propensity to make lower lows, indicating that the overall trend is downward.
Most tools detect the trend, but we cannot predict the next state. The best way to solve this problem is to assume the current state will continue and trade any reactions, preferably in the trend.
If the EURUSD is above its moving average and making higher highs, a trend-following strategy would be to wait for dips before buying and assuming the bullish trend will continue.
Indicator of Relative Strength
J. Welles Wilder Jr. introduced the RSI, a popular and versatile technical indicator. Used as a contrarian indicator to exploit extreme reactions. Calculating the default RSI usually involves these steps:
Determine the difference between the closing prices from the prior ones.
Distinguish between the positive and negative net changes.
Create a smoothed moving average for both the absolute values of the positive net changes and the negative net changes.
Take the difference between the smoothed positive and negative changes. The Relative Strength RS will be the name we use to describe this calculation.
To obtain the RSI, use the normalization formula shown below for each time step.
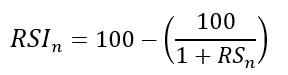
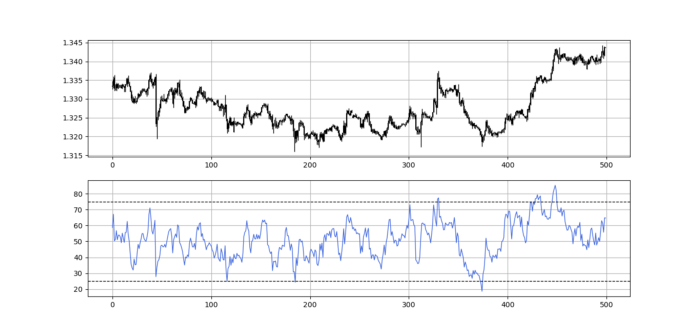
The 13-period RSI and black GBPUSD hourly values are shown above. RSI bounces near 25 and pauses around 75. Python requires a four-column OHLC array for RSI coding.
import numpy as np
def add_column(data, times):
for i in range(1, times + 1):
new = np.zeros((len(data), 1), dtype = float)
data = np.append(data, new, axis = 1)
return data
def delete_column(data, index, times):
for i in range(1, times + 1):
data = np.delete(data, index, axis = 1)
return data
def delete_row(data, number):
data = data[number:, ]
return data
def ma(data, lookback, close, position):
data = add_column(data, 1)
for i in range(len(data)):
try:
data[i, position] = (data[i - lookback + 1:i + 1, close].mean())
except IndexError:
pass
data = delete_row(data, lookback)
return data
def smoothed_ma(data, alpha, lookback, close, position):
lookback = (2 * lookback) - 1
alpha = alpha / (lookback + 1.0)
beta = 1 - alpha
data = ma(data, lookback, close, position)
data[lookback + 1, position] = (data[lookback + 1, close] * alpha) + (data[lookback, position] * beta)
for i in range(lookback + 2, len(data)):
try:
data[i, position] = (data[i, close] * alpha) + (data[i - 1, position] * beta)
except IndexError:
pass
return data
def rsi(data, lookback, close, position):
data = add_column(data, 5)
for i in range(len(data)):
data[i, position] = data[i, close] - data[i - 1, close]
for i in range(len(data)):
if data[i, position] > 0:
data[i, position + 1] = data[i, position]
elif data[i, position] < 0:
data[i, position + 2] = abs(data[i, position])
data = smoothed_ma(data, 2, lookback, position + 1, position + 3)
data = smoothed_ma(data, 2, lookback, position + 2, position + 4)
data[:, position + 5] = data[:, position + 3] / data[:, position + 4]
data[:, position + 6] = (100 - (100 / (1 + data[:, position + 5])))
data = delete_column(data, position, 6)
data = delete_row(data, lookback)
return dataMake sure to focus on the concepts and not the code. You can find the codes of most of my strategies in my books. The most important thing is to comprehend the techniques and strategies.
My weekly market sentiment report uses complex and simple models to understand the current positioning and predict the future direction of several major markets. Check out the report here:
Using the Heatmap to Find the Trend
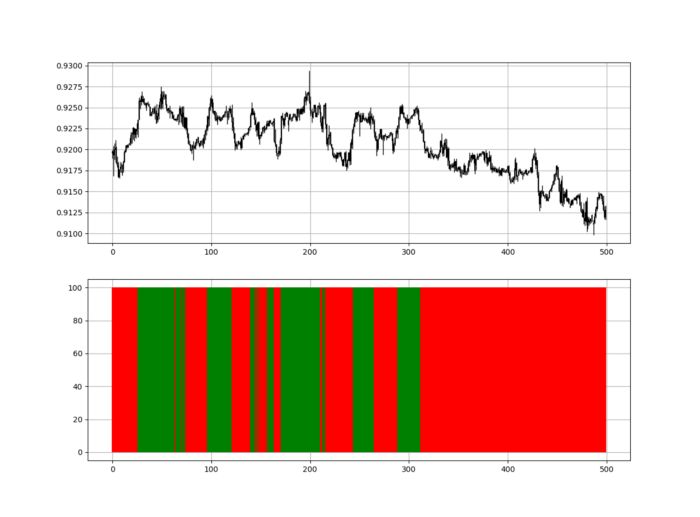
RSI trend detection is easy but useless. Bullish and bearish regimes are in effect when the RSI is above or below 50, respectively. Tracing a vertical colored line creates the conditions below. How:
When the RSI is higher than 50, a green vertical line is drawn.
When the RSI is lower than 50, a red vertical line is drawn.
Zooming out yields a basic heatmap, as shown below.
Plot code:
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
if sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)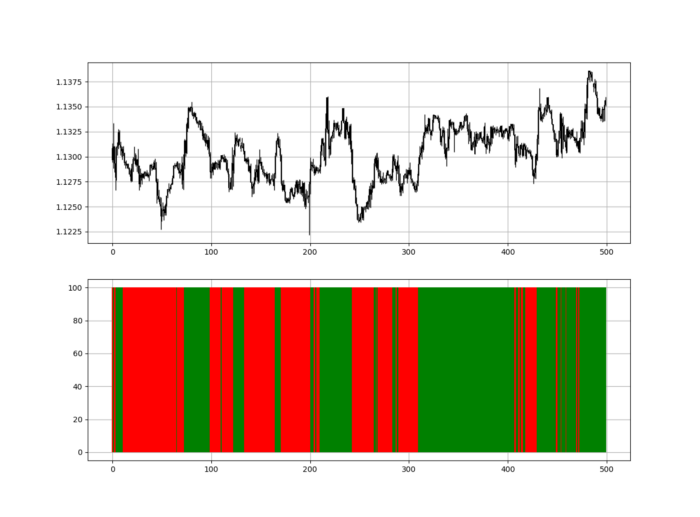
Call RSI on your OHLC array's fifth column. 4. Adjusting lookback parameters reduces lag and false signals. Other indicators and conditions are possible.
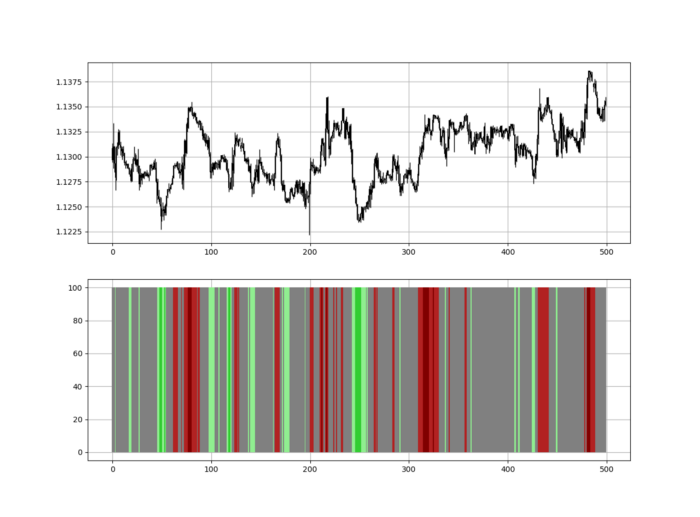
Another suggestion is to develop an RSI Heatmap for Extreme Conditions.
Contrarian indicator RSI. The following rules apply:
Whenever the RSI is approaching the upper values, the color approaches red.
The color tends toward green whenever the RSI is getting close to the lower values.
Zooming out yields a basic heatmap, as shown below.
Plot code:
import matplotlib.pyplot as plt
def indicator_plot(data, second_panel, window = 250):
fig, ax = plt.subplots(2, figsize = (10, 5))
sample = data[-window:, ]
for i in range(len(sample)):
ax[0].vlines(x = i, ymin = sample[i, 2], ymax = sample[i, 1], color = 'black', linewidth = 1)
if sample[i, 3] > sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 0], ymax = sample[i, 3], color = 'black', linewidth = 1.5)
if sample[i, 3] < sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
if sample[i, 3] == sample[i, 0]:
ax[0].vlines(x = i, ymin = sample[i, 3], ymax = sample[i, 0], color = 'black', linewidth = 1.5)
ax[0].grid()
for i in range(len(sample)):
if sample[i, second_panel] > 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'red', linewidth = 1.5)
if sample[i, second_panel] > 80 and sample[i, second_panel] < 90:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'darkred', linewidth = 1.5)
if sample[i, second_panel] > 70 and sample[i, second_panel] < 80:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'maroon', linewidth = 1.5)
if sample[i, second_panel] > 60 and sample[i, second_panel] < 70:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'firebrick', linewidth = 1.5)
if sample[i, second_panel] > 50 and sample[i, second_panel] < 60:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 40 and sample[i, second_panel] < 50:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'grey', linewidth = 1.5)
if sample[i, second_panel] > 30 and sample[i, second_panel] < 40:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'lightgreen', linewidth = 1.5)
if sample[i, second_panel] > 20 and sample[i, second_panel] < 30:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'limegreen', linewidth = 1.5)
if sample[i, second_panel] > 10 and sample[i, second_panel] < 20:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'seagreen', linewidth = 1.5)
if sample[i, second_panel] > 0 and sample[i, second_panel] < 10:
ax[1].vlines(x = i, ymin = 0, ymax = 100, color = 'green', linewidth = 1.5)
ax[1].grid()
indicator_plot(my_data, 4, window = 500)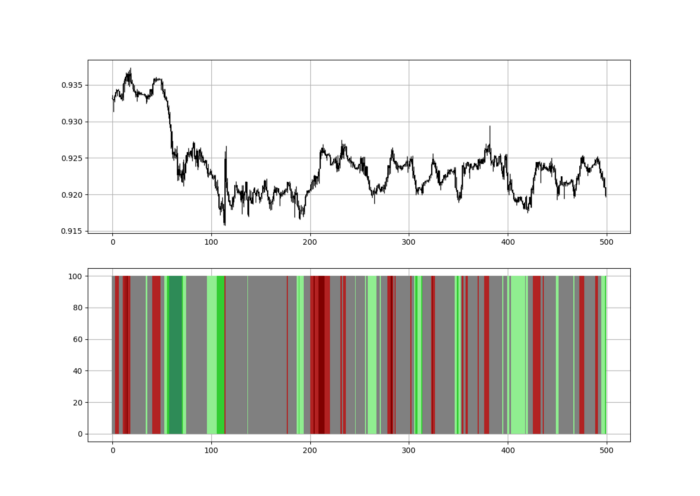
Dark green and red areas indicate imminent bullish and bearish reactions, respectively. RSI around 50 is grey.
Summary
To conclude, my goal is to contribute to objective technical analysis, which promotes more transparent methods and strategies that must be back-tested before implementation.
Technical analysis will lose its reputation as subjective and unscientific.
When you find a trading strategy or technique, follow these steps:
Put emotions aside and adopt a critical mindset.
Test it in the past under conditions and simulations taken from real life.
Try optimizing it and performing a forward test if you find any potential.
Transaction costs and any slippage simulation should always be included in your tests.
Risk management and position sizing should always be considered in your tests.
After checking the above, monitor the strategy because market dynamics may change and make it unprofitable.

Rishi Dean
3 years ago
Coinbase's web3 app
Use popular Ethereum dapps with Coinbase’s new dapp wallet and browser
Tl;dr: This post highlights the ability to access web3 directly from your Coinbase app using our new dapp wallet and browser.
Decentralized autonomous organizations (DAOs) and decentralized finance (DeFi) have gained popularity in the last year (DAOs). The total value locked (TVL) of DeFi investments on the Ethereum blockchain has grown to over $110B USD, while NFTs sales have grown to over $30B USD in the last 12 months (LTM). New innovative real-world applications are emerging every day.
Today, a small group of Coinbase app users can access Ethereum-based dapps. Buying NFTs on Coinbase NFT and OpenSea, trading on Uniswap and Sushiswap, and borrowing and lending on Curve and Compound are examples.
Our new dapp wallet and dapp browser enable you to access and explore web3 directly from your Coinbase app.
Web3 in the Coinbase app
Users can now access dapps without a recovery phrase. This innovative dapp wallet experience uses Multi-Party Computation (MPC) technology to secure your on-chain wallet. This wallet's design allows you and Coinbase to share the 'key.' If you lose access to your device, the key to your dapp wallet is still safe and Coinbase can help recover it.
Set up your new dapp wallet by clicking the "Browser" tab in the Android app's navigation bar. Once set up, the Coinbase app's new dapp browser lets you search, discover, and use Ethereum-based dapps.
Looking forward
We want to enable everyone to seamlessly and safely participate in web3, and today’s launch is another step on that journey. We're rolling out the new dapp wallet and browser in the US on Android first to a small subset of users and plan to expand soon. Stay tuned!