



More on Technology

Paul DelSignore
2 years ago
The stunning new free AI image tool is called Leonardo AI.
Leonardo—The New Midjourney?
Users are comparing the new cowboy to Midjourney.
Leonardo.AI creates great photographs and has several unique capabilities I haven't seen in other AI image systems.
Midjourney's quality photographs are evident in the community feed.

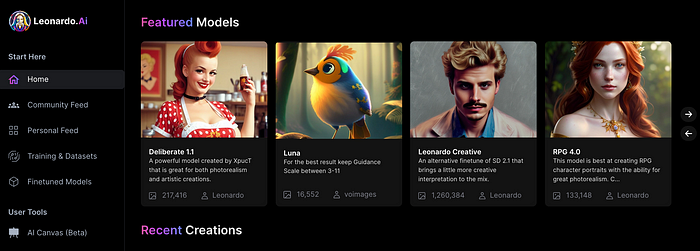
Create Pictures Using Models
You can make graphics using platform models when you first enter the app (website):
Luma, Leonardo creative, Deliberate 1.1.
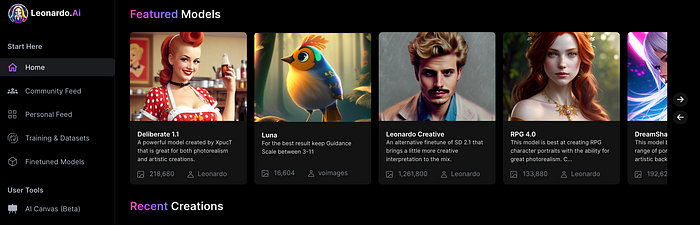
Clicking a model displays its description and samples:
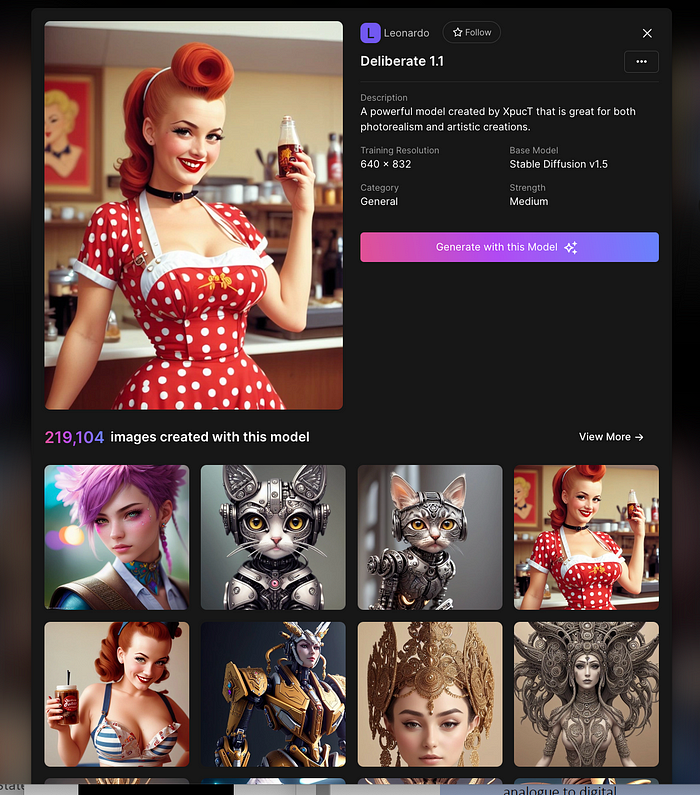
Click Generate With This Model.
Then you can add your prompt, alter models, photos, sizes, and guide scale in a sleek UI.
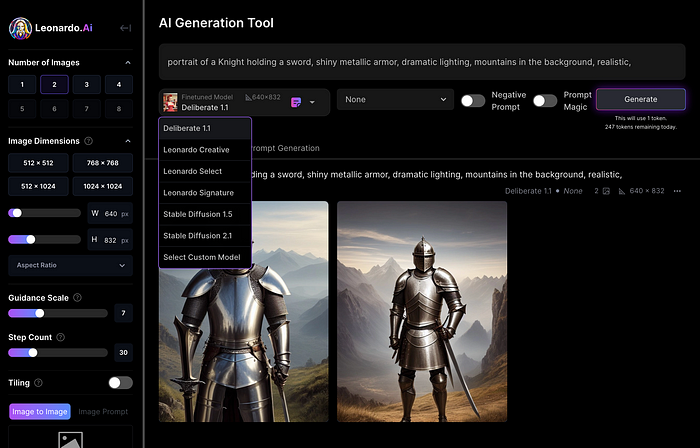
Changing Pictures
Leonardo's Canvas editor lets you change created images by hovering over them:

The editor opens with masking, erasing, and picture download.

Develop Your Own Models
I've never seen anything like Leonardo's model training feature.
Upload a handful of similar photographs and save them as a model for future images. Share your model with the community.
You can make photos using your own model and a community-shared set of fine-tuned models:
Obtain Leonardo access
Leonardo is currently free.
Visit Leonardo.ai and click "Get Early Access" to receive access.
Add your email to receive a link to join the discord channel. Simply describe yourself and fill out a form to join the discord channel.
Please go to 👑│introductions to make an introduction and ✨│priority-early-access will be unlocked, you must fill out a form and in 24 hours or a little more (due to demand), the invitation will be sent to you by email.
I got access in two hours, so hopefully you can too.
Last Words
I know there are many AI generative platforms, some free and some expensive, but Midjourney produces the most artistically stunning images and art.
Leonardo is the closest I've seen to Midjourney, but Midjourney is still the leader.
It's free now.
Leonardo's fine-tuned model selections, model creation, image manipulation, and output speed and quality make it a great AI image toolbox addition.

Will Lockett
3 years ago
The World Will Change With MIT's New Battery

It's cheaper, faster charging, longer lasting, safer, and better for the environment.
Batteries are the future. Next-gen and planet-saving technology, including solar power and EVs, require batteries. As these smart technologies become more popular, we find that our batteries can't keep up. Lithium-ion batteries are expensive, slow to charge, big, fast to decay, flammable, and not environmentally friendly. MIT just created a new battery that eliminates all of these problems. So, is this the battery of the future? Or is there a catch?
When I say entirely new, I mean it. This battery employs no currently available materials. Its electrodes are constructed of aluminium and pure sulfur instead of lithium-complicated ion's metals and graphite. Its electrolyte is formed of molten chloro-aluminate salts, not an organic solution with lithium salts like lithium-ion batteries.
How does this change in materials help?
Aluminum, sulfur, and chloro-aluminate salts are abundant, easy to acquire, and cheap. This battery might be six times cheaper than a lithium-ion battery and use less hazardous mining. The world and our wallets will benefit.
But don’t go thinking this means it lacks performance.
This battery charged in under a minute in tests. At 25 degrees Celsius, the battery will charge 25 times slower than at 110 degrees Celsius. This is because the salt, which has a very low melting point, is in an ideal state at 110 degrees and can carry a charge incredibly quickly. Unlike lithium-ion, this battery self-heats when charging and discharging, therefore no external heating is needed.
Anyone who's seen a lithium-ion battery burst might be surprised. Unlike lithium-ion batteries, none of the components in this new battery can catch fire. Thus, high-temperature charging and discharging speeds pose no concern.
These batteries are long-lasting. Lithium-ion batteries don't last long, as any iPhone owner can attest. During charging, metal forms a dendrite on the electrode. This metal spike will keep growing until it reaches the other end of the battery, short-circuiting it. This is why phone batteries only last a few years and why electric car range decreases over time. This new battery's molten salt slows deposition, extending its life. This helps the environment and our wallets.
These batteries are also energy dense. Some lithium-ion batteries have 270 Wh/kg energy density (volume and mass). Aluminum-sulfur batteries could have 1392 Wh/kg, according to calculations. They'd be 5x more energy dense. Tesla's Model 3 battery would weigh 96 kg instead of 480 kg if this battery were used. This would improve the car's efficiency and handling.
These calculations were for batteries without molten salt electrolyte. Because they don't reflect the exact battery chemistry, they aren't a surefire prediction.
This battery seems great. It will take years, maybe decades, before it reaches the market and makes a difference. Right?
Nope. The project's scientists founded Avanti to develop and market this technology.
So we'll soon be driving cheap, durable, eco-friendly, lightweight, and ultra-safe EVs? Nope.
This battery must be kept hot to keep the salt molten; otherwise, it won't work and will expand and contract, causing damage. This issue could be solved by packs that can rapidly pre-heat, but that project is far off.
Rapid and constant charge-discharge cycles make these batteries ideal for solar farms, homes, and EV charging stations. The battery is constantly being charged or discharged, allowing it to self-heat and maintain an ideal temperature.
These batteries aren't as sexy as those making EVs faster, more efficient, and cheaper. Grid batteries are crucial to our net-zero transition because they allow us to use more low-carbon energy. As we move away from fossil fuels, we'll need millions of these batteries, so the fact that they're cheap, safe, long-lasting, and environmentally friendly will be huge. Who knows, maybe EVs will use this technology one day. MIT has created another world-changing technology.

Nikhil Vemu
3 years ago
7 Mac Tips You Never Knew You Needed
Unleash the power of the Option key ⌥

#1 Open a link in the Private tab first.
Previously, if I needed to open a Safari link in a private window, I would:
copied the URL with the right click command,
choose File > New Private Window to open a private window, and
clicked return after pasting the URL.
I've found a more straightforward way.
Right-clicking a link shows this, right?
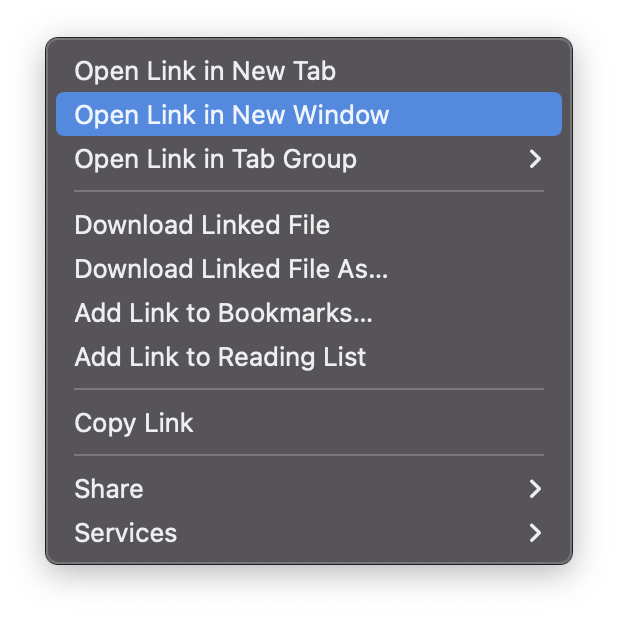
Hold option (⌥) for:
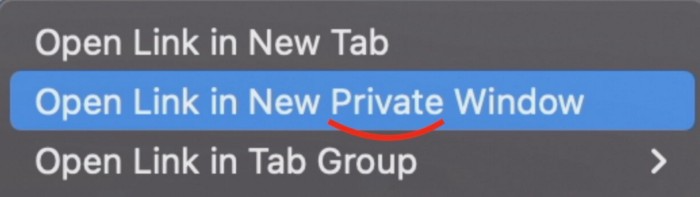
Click Open Link in New Private Window while holding.
Finished!
#2. Instead of searching for specific characters, try this
You may use unicode for business or school. Most people Google them when they need them.
That is lengthy!
You can type some special characters just by pressing ⌥ and a key.
For instance
• ⌥+2 -> ™ (Trademark)
• ⌥+0 -> ° (Degree)
• ⌥+G -> © (Copyright)
• ⌥+= -> ≠ (Not equal to)
• ⌥+< -> ≤ (Less than or equal to)
• ⌥+> -> ≥ (Greater then or equal to)
• ⌥+/ -> ÷ (Different symbol for division)#3 Activate Do Not Disturb silently.
Do Not Disturb when sharing my screen is awkward for me (because people may think Im trying to hide some secret notifications).
Here's another method.
Hold ⌥ and click on Time (at the extreme right on the menu-bar).

Now, DND is activated (secretly!). To turn it off, do it again.
Note: This works only for DND focus.#4. Resize a window starting from its center
Although this is rarely useful, it is still a hidden trick.
When you resize a window, the opposite edge or corner is used as the pivot, right?
However, if you want to resize it with its center as the pivot, hold while doing so.
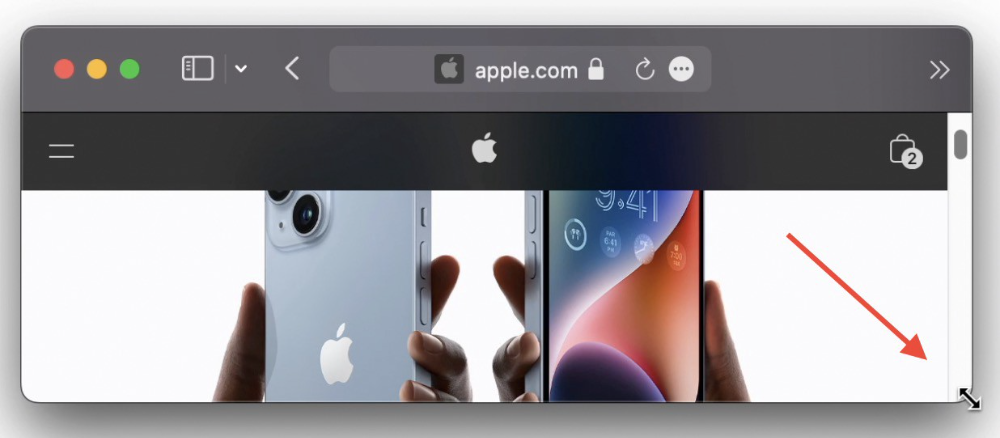
#5. Yes, Cut-Paste is available on Macs as well (though it is slightly different).
I call it copy-move rather than cut-paste. This is how it works.
Carry it out.
Choose a file (by clicking on it), then copy it (⌘+C).
Go to a new location on your Mac. Do you use ⌘+V to paste it? However, to move it, press ⌘+⌥+V.
This removes the file from its original location and copies it here. And it works exactly like cut-and-paste on Windows.
#6. Instantly expand all folders
Set your Mac's folders to List view.
Assume you have one folder with multiple subfolders, each of which contains multiple files. And you wanted to look at every single file that was over there.
How would you do?
You're used to clicking the ⌄ glyph near the folder and each subfolder to expand them all, right? Instead, hold down ⌥ while clicking ⌄ on the parent folder.
This is what happens next.
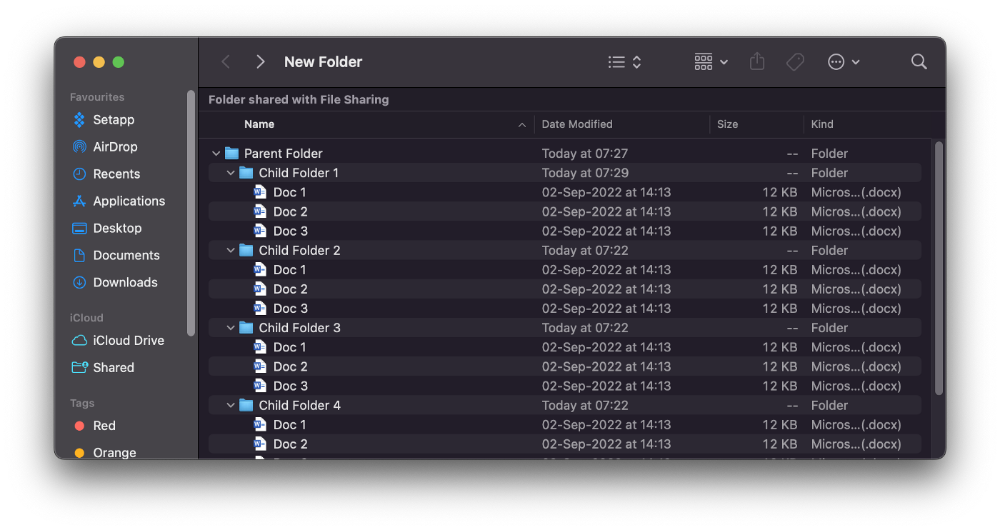
Everything expands.
View/Copy a file's path as an added bonus
If you want to see the path of a file in Finder, select it and hold ⌥, and you'll see it at the bottom for a moment.
To copy its path, right-click on the folder and hold down ⌥ to see this
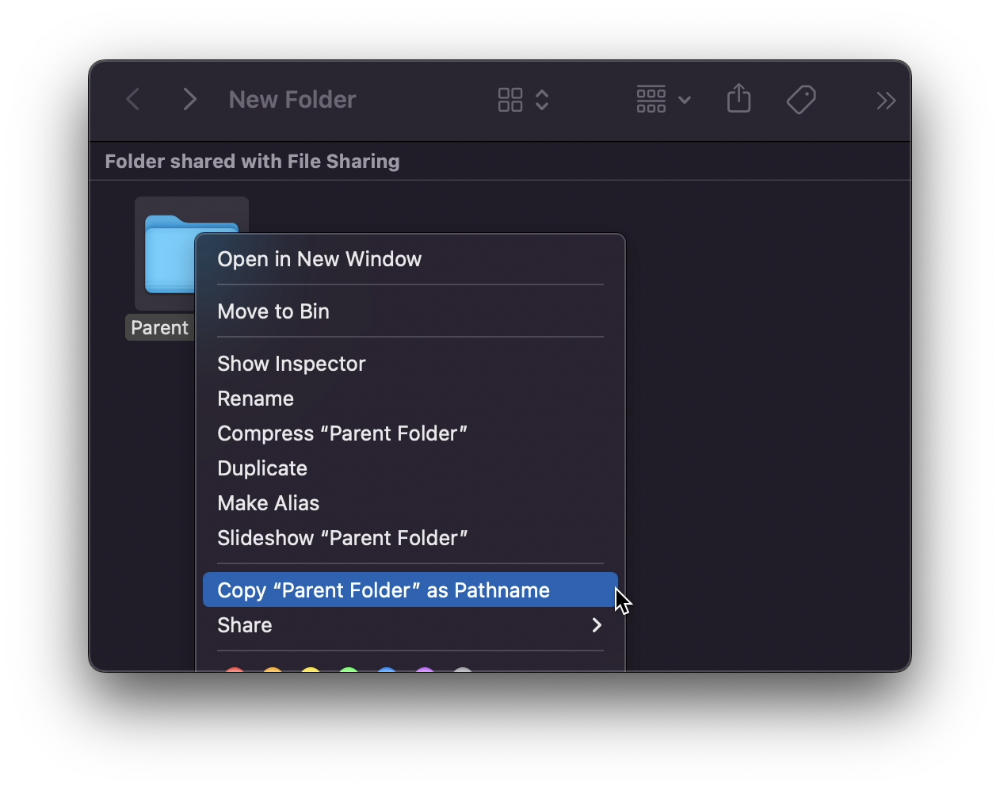
Click on Copy <"folder name"> as Pathname to do it.
#7 "Save As"
I was irritated by the lack of "Save As" in Pages when I first got a Mac (after 15 years of being a Windows guy).
It was necessary for me to save the file as a new file, in a different location, with a different name, or both.
Unfortunately, I couldn't do it on a Mac.
However, I recently discovered that it appears when you hold ⌥ when in the File menu.
Yay!
You might also like
Nate Kostar
3 years ago
# DeaMau5’s PIXELYNX and Beatport Launch Festival NFTs
Pixelynx, a music metaverse gaming platform, has teamed up with Beatport, an online music retailer focusing in electronic music, to establish a Synth Heads non-fungible token (NFT) Collection.
Richie Hawtin, aka Deadmau5, and Joel Zimmerman, nicknamed Pixelynx, have invented a new music metaverse game platform called Pixelynx. In January 2022, they released their first Beatport NFT drop, which saw 3,030 generative NFTs sell out in seconds.
The limited edition Synth Heads NFTs will be released in collaboration with Junction 2, the largest UK techno festival, and having one will grant fans special access tickets and experiences at the London-based festival.
Membership in the Synth Head community, day passes to the Junction 2 Festival 2022, Junction 2 and Beatport apparel, special vinyl releases, and continued access to future ticket drops are just a few of the experiences available.
Five lucky NFT holders will also receive a Golden Ticket, which includes access to a backstage artist bar and tickets to Junction 2's next large-scale London event this summer, in addition to full festival entrance for both days.
The Junction 2 festival will take place at Trent Park in London on June 18th and 19th, and will feature performances from Four Tet, Dixon, Amelie Lens, Robert Hood, and a slew of other artists. Holders of the original Synth Head NFT will be granted admission to the festival's guestlist as well as line-jumping privileges.
The new Synth Heads NFTs collection contain 300 NFTs.
NFTs that provide IRL utility are in high demand.
The benefits of NFT drops related to In Real Life (IRL) utility aren't limited to Beatport and Pixelynx.
Coachella, a well-known music event, recently partnered with cryptocurrency exchange FTX to offer free NFTs to 2022 pass holders. Access to a dedicated entry lane, a meal and beverage pass, and limited-edition merchandise were all included with the NFTs.
Coachella also has its own NFT store on the Solana blockchain, where fans can buy Coachella NFTs and digital treasures that unlock exclusive on-site experiences, physical objects, lifetime festival passes, and "future adventures."
Individual artists and performers have begun taking advantage of NFT technology outside of large music festivals like Coachella.
DJ Tisto has revealed that he would release a VIP NFT for his upcoming "Eagle" collection during the EDC festival in Las Vegas in 2022. This NFT, dubbed "All Access Eagle," gives collectors the best chance to get NFTs from his first drop, as well as unique access to the music "Repeat It."
NFTs are one-of-a-kind digital assets that can be verified, purchased, sold, and traded on blockchains, opening up new possibilities for artists and businesses alike. Time will tell whether Beatport and Pixelynx's Synth Head NFT collection will be successful, but if it's anything like the first release, it's a safe bet.

Matt Ward
3 years ago
Is Web3 nonsense?
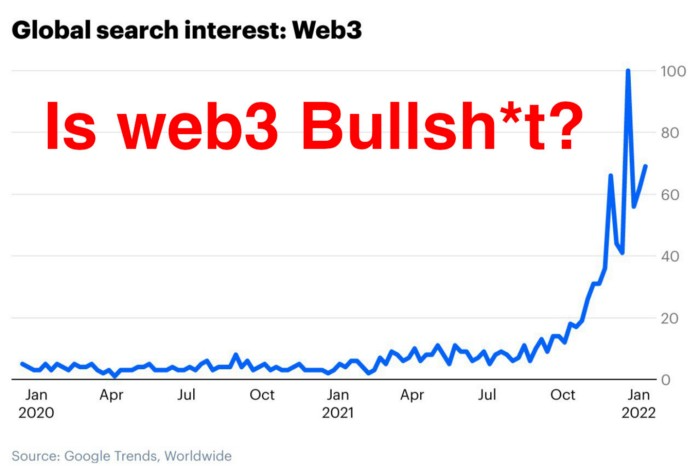
Crypto and blockchain have rebranded as web3. They probably thought it sounded better and didn't want the baggage of scam ICOs, STOs, and skirted securities laws.
It was like Facebook becoming Meta. Crypto's biggest players wanted to change public (and regulator) perception away from pump-and-dump schemes.
After the 2018 ICO gold rush, it's understandable. Every project that raised millions (or billions) never shipped a meaningful product.
Like many crazes, charlatans took the money and ran.
Despite its grifter past, web3 is THE hot topic today as more founders, venture firms, and larger institutions look to build the future decentralized internet.
Supposedly.
How often have you heard: This will change the world, fix the internet, and give people power?
Why are most of web3's biggest proponents (and beneficiaries) the same rich, powerful players who built and invested in the modern internet? It's like they want to remake and own the internet.
Something seems off about that.
Why are insiders getting preferential presale terms before the public, allowing early investors and proponents to flip dirt cheap tokens and advisors shares almost immediately after the public sale?
It's a good gig with guaranteed markups, no risk or progress.
If it sounds like insider trading, it is, at least practically. This is clear when people talk about blockchain/web3 launches and tokens.
Fast money, quick flips, and guaranteed markups/returns are common.
Incentives-wise, it's hard to blame them. Who can blame someone for following the rules to win? Is it their fault or regulators' for not leveling the playing field?
It's similar to oil companies polluting for profit, Instagram depressing you into buying a new dress, or pharma pushing an unnecessary pill.
All of that is fair game, at least until we change the playbook, because people (and corporations) change for pain or love. Who doesn't love money?
belief based on money gain
Sinclair:
“It is difficult to get a man to understand something when his salary depends upon his not understanding it.”
Bitcoin, blockchain, and web3 analogies?
Most blockchain and web3 proponents are true believers, not cynical capitalists. They believe blockchain's inherent transparency and permissionless trust allow humanity to evolve beyond our reptilian ways and build a better decentralized and democratic world.
They highlight issues with the modern internet and monopoly players like Google, Facebook, and Apple. Decentralization fixes everything
If we could give power back to the people and get governments/corporations/individuals out of the way, we'd fix everything.
Blockchain solves supply chain and child labor issues in China.
To meet Paris climate goals, reduce emissions. Create a carbon token.
Fixing online hatred and polarization Web3 Twitter and Facebook replacement.

Web3 must just be the answer for everything… your “perfect” silver bullet.
Nothing fits everyone. Blockchain has pros and cons like everything else.
Blockchain's viral, ponzi-like nature has an MLM (mid level marketing) feel. If you bought Taylor Swift's NFT, your investment is tied to her popularity.
Probably makes you promote Swift more. Play music loudly.
Here's another example:
Imagine if Jehovah’s Witnesses (or evangelical preachers…) got paid for every single person they converted to their cause.
It becomes a self-fulfilling prophecy as their faith and wealth grow.
Which breeds extremism? Ultra-Orthodox Jews are an example. maximalists

Bitcoin and blockchain are causes, religions. It's a money-making movement and ideal.
We're good at convincing ourselves of things we want to believe, hence filter bubbles.
I ignore anything that doesn't fit my worldview and seek out like-minded people, which algorithms amplify.
Then what?
Is web3 merely a new scam?
No, never!
Blockchain has many crucial uses.
Sending money home/abroad without bank fees;
Like fleeing a war-torn country and converting savings to Bitcoin;
Like preventing Twitter from silencing dissidents.
Permissionless, trustless databases could benefit society and humanity. There are, however, many limitations.
Lost password?
What if you're cheated?
What if Trump/Putin/your favorite dictator incites a coup d'état?
What-ifs abound. Decentralization's openness brings good and bad.
No gatekeepers or firefighters to rescue you.
ISIS's fundraising is also frictionless.
Community-owned apps with bad interfaces and service.
Trade-offs rule.
So what compromises does web3 make?
What are your trade-offs? Decentralization has many strengths and flaws. Like Bitcoin's wasteful proof-of-work or Ethereum's political/wealth-based proof-of-stake.
To ensure the survival and veracity of the network/blockchain and to safeguard its nodes, extreme measures have been designed/put in place to prevent hostile takeovers aimed at altering the blockchain, i.e., adding money to your own wallet (account), etc.
These protective measures require significant resources and pose challenges. Reduced speed and throughput, high gas fees (cost to submit/write a transaction to the blockchain), and delayed development times, not to mention forked blockchain chains oops, web3 projects.
Protecting dissidents or rogue regimes makes sense. You need safety, privacy, and calm.
First-world life?
What if you assumed EVERYONE you saw was out to rob/attack you? You'd never travel, trust anyone, accomplish much, or live fully. The economy would collapse.
It's like an ant colony where half the ants do nothing but wait to be attacked.
Waste of time and money.
11% of the US budget goes to the military. Imagine what we could do with the $766B+ we spend on what-ifs annually.
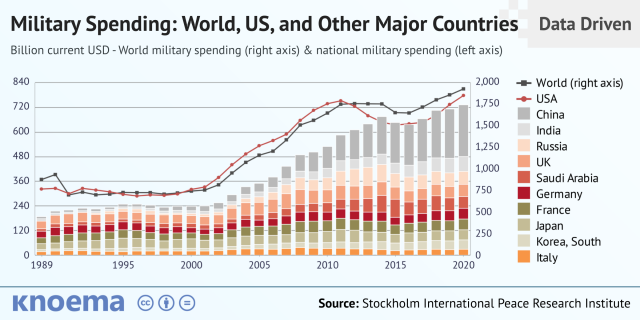
Is so much hypothetical security needed?
Blockchain and web3 are similar.
Does your app need permissionless decentralization? Does your scooter-sharing company really need a proof-of-stake system and 1000s of nodes to avoid Russian hackers? Why?
Worst-case scenario? It's not life or death, unless you overstate the what-ifs. Web3 proponents find improbable scenarios to justify decentralization and tokenization.
Do I need a token to prove ownership of my painting? Unless I'm a master thief, I probably bought it.
despite losing the receipt.
I do, however, love Web 3.
Enough Web3 bashing for now. Understand? Decentralization isn't perfect, but it has huge potential when applied to the right problems.
I see many of the right problems as disrupting big tech's ruthless monopolies. I wrote several years ago about how tokenized blockchains could be used to break big tech's stranglehold on platforms, marketplaces, and social media.
Tokenomics schemes can be used for good and are powerful. Here’s how.
Before the ICO boom, I made a series of predictions about blockchain/crypto's future. It's still true.
Here's where I was then and where I see web3 going:
My 11 Big & Bold Predictions for Blockchain
In the near future, people may wear crypto cash rings or bracelets.
While some governments repress cryptocurrency, others will start to embrace it.
Blockchain will fundamentally alter voting and governance, resulting in a more open election process.
Money freedom will lead to a more geographically open world where people will be more able to leave when there is unrest.
Blockchain will make record keeping significantly easier, eliminating the need for a significant portion of government workers whose sole responsibility is paperwork.
Overrated are smart contracts.

6. Tokens will replace company stocks.
7. Blockchain increases real estate's liquidity, value, and volatility.
8. Healthcare may be most affected.
9. Crypto could end privacy and lead to Minority Report.
10. New companies with network effects will displace incumbents.
11. Soon, people will wear rings or bracelets with crypto cash.
Some have already happened, while others are still possible.
Time will tell if they happen.
And finally:
What will web3 be?
Who will be in charge?
Closing remarks
Hope you enjoyed this web3 dive. There's much more to say, but that's for another day.
We're writing history as we go.
Tech regulation, mergers, Bitcoin surge How will history remember us?
What about web3 and blockchain?
Is this a revolution or a tulip craze?
Remember, actions speak louder than words (share them in the comments).
Your turn.

Sammy Abdullah
3 years ago
R&D, S&M, and G&A expense ratios for SaaS
SaaS spending is 40/40/20. 40% of operating expenses should be R&D, 40% sales and marketing, and 20% G&A. We wanted to see the statistics behind the rules of thumb. Since October 2017, 73 SaaS startups have gone public. Perhaps the rule of thumb should be 30/50/20. The data is below.
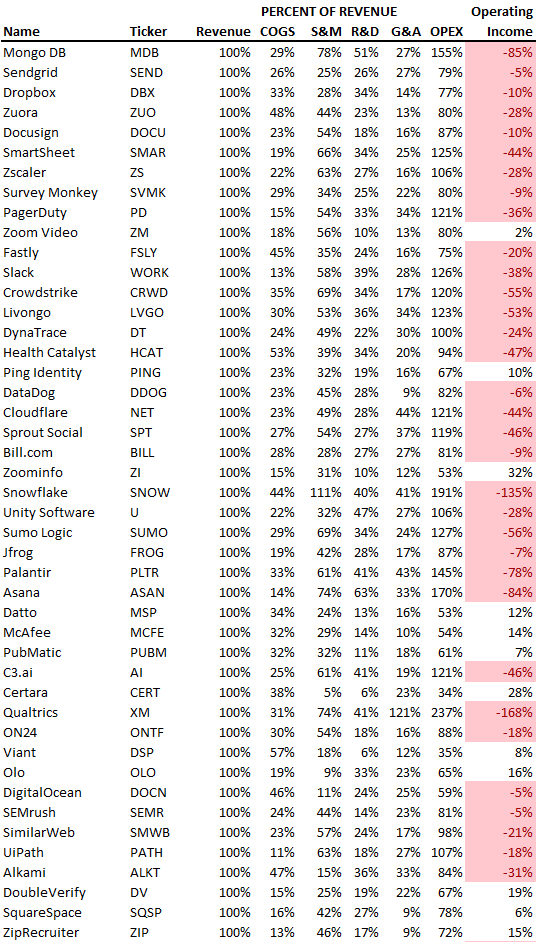
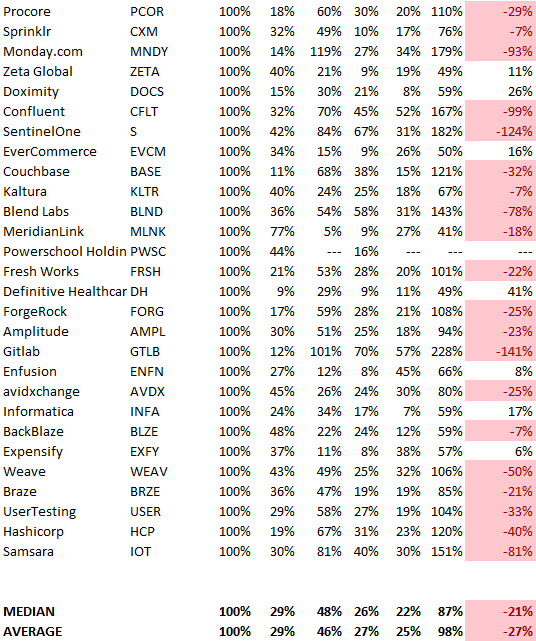
30/50/20. R&D accounts for 26% of opex, sales and marketing 48%, and G&A 22%. We think R&D/S&M/G&A should be 30/50/20.
There are outliers. There are exceptions to rules of thumb. Dropbox spent 45% on R&D whereas Zoom spent 13%. Zoom spent 73% on S&M, Dropbox 37%, and Bill.com 28%. Snowflake spent 130% of revenue on S&M, while their EBITDA margin is -192%.
G&A shouldn't stand out. Minimize G&A spending. Priorities should be product development and sales. Cloudflare, Sendgrid, Snowflake, and Palantir spend 36%, 34%, 37%, and 43% on G&A.
Another myth is that COGS is 20% of revenue. Median and averages are 29%.
Where is the profitability? Data-driven operating income calculations were simplified (Revenue COGS R&D S&M G&A). 20 of 73 IPO businesses reported operational income. Median and average operating income margins are -21% and -27%.
As long as you're growing fast, have outstanding retention, and marquee clients, you can burn cash since recurring income that doesn't churn is a valuable annuity.
The data was compelling overall. 30/50/20 is the new 40/40/20 for more established SaaS enterprises, unprofitability is alright as long as your business is expanding, and COGS can be somewhat more than 20% of revenue.